前回学んだ階層的クラスタリングは、データの階層構造を美しく可視化できる素晴らしい手法でした。 Pythonで学ぶ クラスター分析入門— 第2回 —樹形図で見える化 ― 階層的クラスタリング しかし...
前回は「似ている」を距離で測る方法を学びました。 Pythonで学ぶ クラスター分析入門— 第1回 —「似てる」を数値化しよう ― 距離の考え方 今回は、その距離を使って実際にデータをグループ分け...
ビジネスの現場において、データ活用や生成AIの導入は避けて通れないテーマとなっています。 しかし、「何から始めればいいのか」「専門知識がないと難しいのではないか」と足踏みされている方も多いのではないでしょうか。 テーマ:...
データ分析で「カテゴリごとに集計したい」という場面は非常に多いです。 「商品別の売上合計」「月別の平均値」「店舗ごとの顧客数」など、グループ化して集計する処理は日常茶飯事です。 pandasの groupby() は、そ...
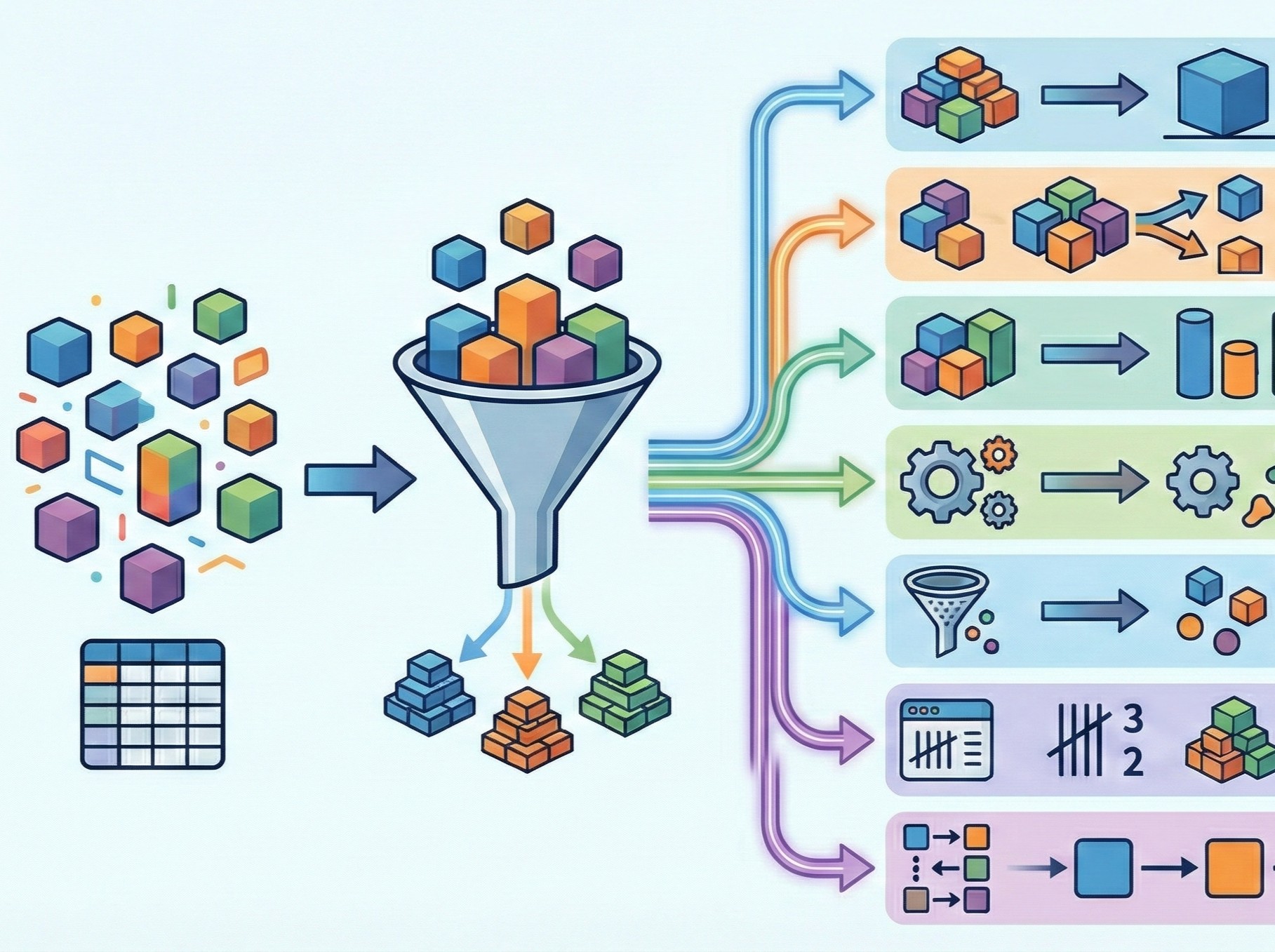
あなたは今日、無意識のうちに何回「似たものをまとめる」という行動をしたでしょうか。 朝起きてクローゼットを開ければ、シャツはシャツ、パンツはパンツでまとまっています。 本棚を見れば、小説、技術書、漫画がそれぞれのエリアに...
「マーケティング費用の効果を、数字で説明してください」 四半期ごとの経営会議で、この質問を投げかけられるたびに、J氏は言葉に詰まっていました。 SNS広告、インフルエンサー、PR、オウンドメディアなど複数の施策を同時に走...
このシリーズでは、第1回から第5回まで、PCAと因子分析の基礎を一歩ずつ学んできました。 — 第1回 — なぜ「次元を減らす」のか? 情報の海で溺れないために https://www.salesanalytics.co....
ここまで4回にわたって、主成分分析(PCA)を学んできました。 — 第1回 — なぜ「次元を減らす」のか? 情報の海で溺れないために https://www.salesanalytics.co.jp/datascienc...
ここまでの3回で、PCAの仕組みを一から学んできました。 — 第1回 — なぜ「次元を減らす」のか? 情報の海で溺れないために https://www.salesanalytics.co.jp/datascience/d...
前回は、共分散行列の固有値分解によって「主成分の方向」と「その方向での分散」が求まることを学びました。 Pythonで体感する次元削減入門 – PCAと因子分析の基礎のキソ— 第2回 —...
Pythonでデータを処理するとき、「リストの各要素に同じ処理を適用したい」という場面は非常に多いです。 このとき、書き方は主に3通りあります。 方法 特徴 一言で言うと for文 最も基本的で直感的 「一つずつ順番に処...
前回は、「次元削減」の考え方と、PCAの基本的なアイデアをお話しいたしました。 具体的には、2次元の従業員評価データを使って、様々な角度に射影したときの分散を計算し、「データが最も広がっている方向」を探しました。 Pyt...
EC事業を運営されている方であれば、こんな経験はないでしょうか。 「売上が足りないからクーポンを出そう」と施策を打ち、確かに売上は上がった。 しかし月末に収支を確認すると、利益はほとんど増えていない。 むしろ減っているか...
私たちは日々、膨大な情報に囲まれて生活しています。 スマートフォンには何百ものアプリがあり、ニュースサイトには無数の記事があふれ、SNSでは毎秒新しい投稿が生まれています。 この情報の洪水の中で、私たちは無意識のうちに「...
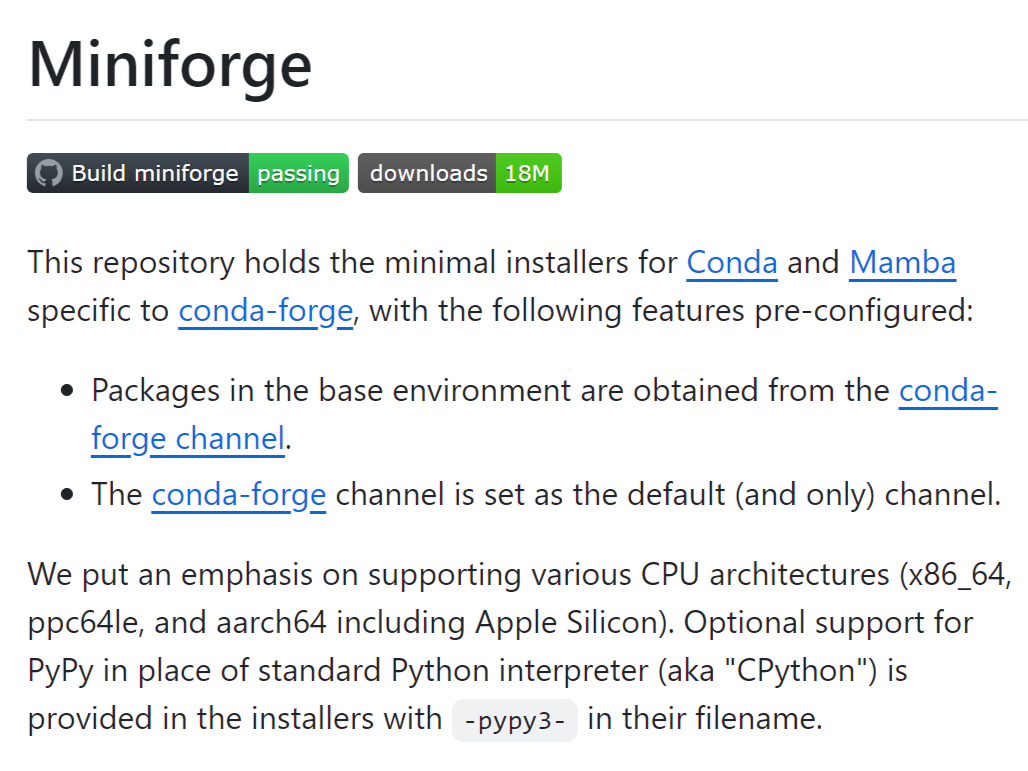
Pythonでのデータサイエンスや開発を効率的に行うためには、適切な環境構築が欠かせません。 Miniforgeは、Conda環境をシンプルかつ軽量に提供してくれるツールであり、特に余計なパッケージを省いた環境を構築した...
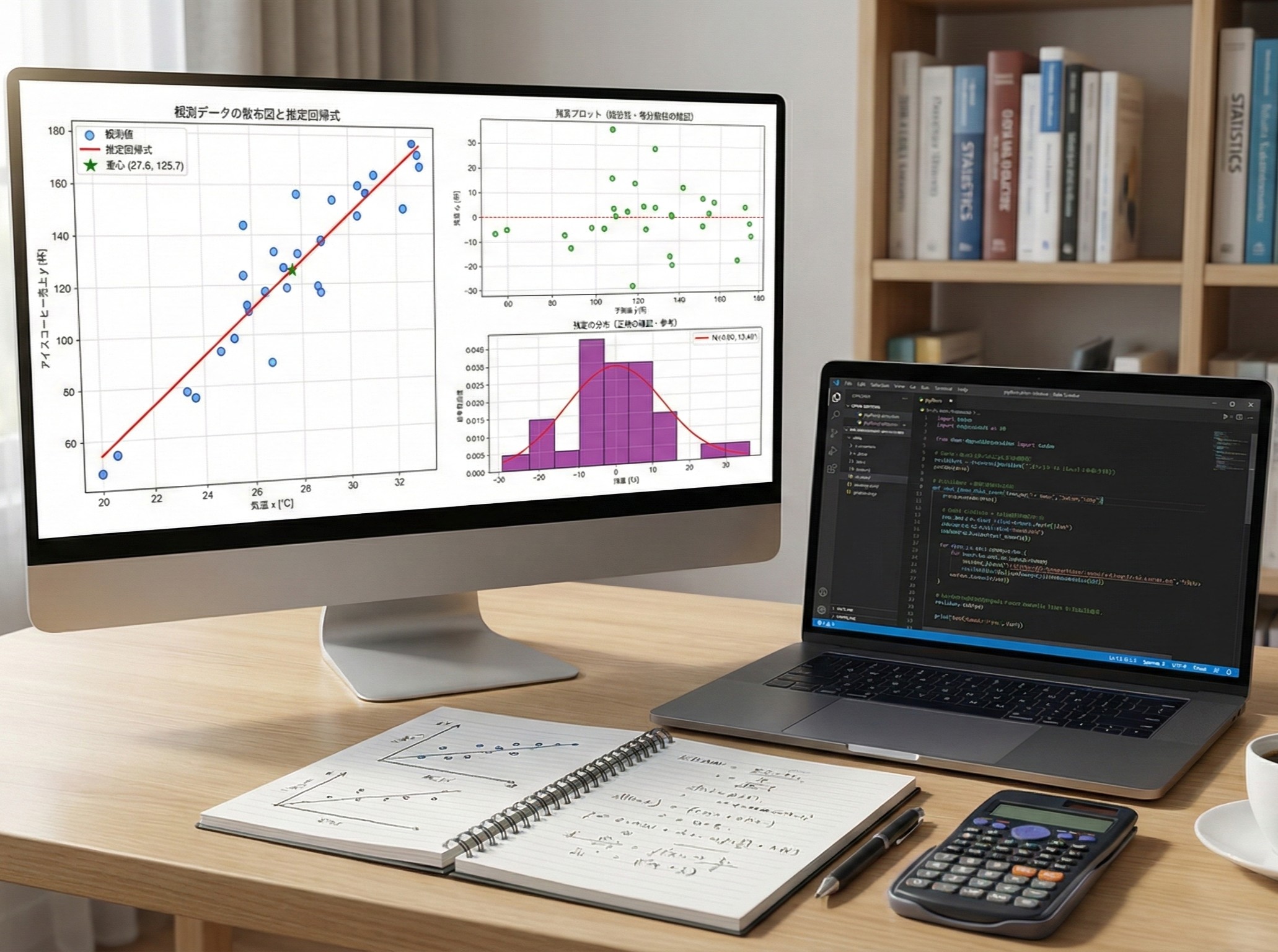
これまでの4回で、回帰分析の基本から重回帰分析まで説明しました。 — 第1回 — アイスコーヒーは何杯売れる? 単回帰分析で売上予測に挑戦 https://www.salesanalytics.co.jp/datasci...