

時系列の深層学習(ディープラーニング)モデルの代表格がRNN(Recurrent Neural Network、リカレントニューラルネットワーク)です。RNNの構築方法と1期先予測(1-Step ahead prediction)については、以下の記事でお話ししています。
Python Keras(TensorFlow)で作る
深層学習(Deep Learning)時系列予測モデル(その1)
RNNで1期先予測(1-Step ahead prediction)
RNNの長期記憶が保持できない問題点を改善する形で登場したのがLSTM(Long Short Term Memory)です。LSTMの構築方法と1期先予測(1-Step ahead prediction)については、以下の記事でお話ししています。
Python Keras(TensorFlow)で作る
深層学習(Deep Learning)時系列予測モデル(その2)
LSTMで1期先予測(1-Step ahead prediction)
LSTMには多くのバリエーションがあります。GRU(Gated Recurrent Unit)もその1つで、一般的なLSTMをシンプルにした感じのものです。シンプルにすることで、処理速度が速くなっています。
今回は、LSTMの計算コスト大きい問題を改善する形で登場したGRU(Gated Recurrent Unit)のモデル構築方法と1期先予測(1-Step ahead prediction)予測についてお話しします。
Contents [hide]
- GRU(Gated Recurrent Unit)とは?
- 構築するGRUモデル
- サンプルデータ(前回と同じです)
- 予測精度の評価指標(前回と同じです)
- 準備(前回と同じです)
- GRU(ラグ変数:features)
- GRU(ラグ変数:features)|データ準備
- GRU(ラグ変数:features)|モデル生成
- GRU(ラグ変数:features)|学習
- GRU(ラグ変数:features)|検証
- GRU(ラグ変数:time steps)
- GRU(ラグ変数:time steps)|データ準備
- GRU(ラグ変数:time steps)|モデル生成
- GRU(ラグ変数:time steps)|学習
- GRU(ラグ変数:time steps)|検証
- 次回
GRU(Gated Recurrent Unit)とは?
GRUはLSTMの1種ですが、一般的なLSTMをよりシンプルにした感じのものです。
一般的なLSTMと異なるポイントは……
- 記憶セルがない
- ゲートが1つ少ない
一般的なLSTMでは、ユニットの記憶セル(C)とユニットの出力値(h)の2つの状態を常に保持していました。これを1つにまとめ、記憶セル(C)というものがユニットの構造から消えました。
さらに、一般的なLSTMには、入力ゲート(input gate)および出力ゲート(output gate)、忘却ゲート(forget gate)の3つのゲートがありましたが、代わりに更新ゲート(update gate)とリセットゲート(reset gate)というものを導入することで2つのゲートに減らしました。
要するに、GRUはシンプルなLSTMということです。
モデル全般に言えることですが、複雑なモデルが良いわけでも、高精度な予測をするわけでもありません。理想は、シンプルだけど高精度なモデルです。
構築するGRUモデル
Keras(TensorFlow)のGRUのデータセットは、以下のような3元構造が基本になっています。
時系列データの特徴量の1つとして、ラグ変数というものがあります。例えば、日販(1日の売上)であれば、「ラグ1の変数」とは「1日前の日販の変数」、「ラグ2の変数」とは「2日前の日販の変数」などです。
今回は、説明変数のない目的変数が1変量の時系列データを扱いますので、目的変数のラグ変数を作り説明変数として利用します。このとき、ラグ変数を特徴量(features)として扱うこともできますし、タイムステップ(time steps)として扱うこともできます。
ということで、以下の2種類のデータセットそれぞれで、GRUモデルを構築します。
- ラグ変数を特徴量(features)とするGRUモデル
- ラグ変数をタイムステップ(time steps)とするGRUモデル
サンプルデータ(前回と同じです)
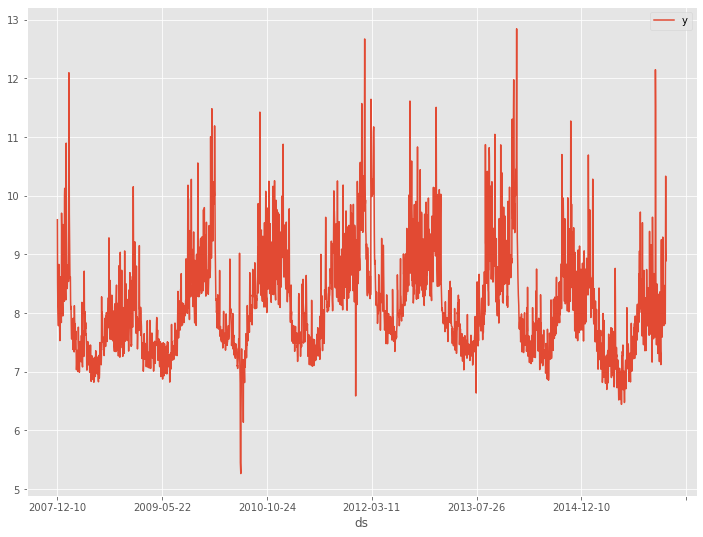
サンプルデータは、前回と同じPeyton ManningのWikipediaのPV(ページビュー)というProphetで提供されているサンプルデータ(example_wp_log_peyton_manning.csv)を使います。
facebook/prophetのGitHubからダウンロードして使って頂くか、弊社のHPからダウンロードして使って頂ければと思います。
facebook/prophetのGitHub上のデータ
https://github.com/facebook/prophet/blob/master/examples/example_wp_log_peyton_manning.csv弊社のHP上のURLからダウンロード
https://www.salesanalytics.co.jp/bgr8
このデータセットは、説明変数のない目的変数が1変量の時系列データです。もちろん、目的変数は、日単位のPV(ページビュー数)です。
PV(ページビュー数)のラグ変数を作り説明変数にします。要するに、過去のPVから未来のPVを予測する、ということです。
予測精度の評価指標(前回と同じです)
今回の予測精度の評価指標も前回と同じで、RMSE(二乗平均平方根誤差、Root Mean Squared Error)とMAE(平均絶対誤差、Mean Absolute Error)、MAPE(平均絶対パーセント誤差、Mean absolute percentage error)を使います。
以下の記号を使い精度指標の説明をします。
■ 二乗平均平方根誤差(RMSE、Root Mean Squared Error)
■ 平均絶対誤差(MAE、Mean Absolute Error)
■ 平均絶対パーセント誤差(MAPE、Mean absolute percentage error)
準備(前回と同じです)
もちろん、準備も前回と同じです。説明は、前回の記事を御覧ください。
以下、コードです。
#
# 必要なライブラリーの読み込み
#
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import *
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.utils import plot_model
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_percentage_error
import matplotlib.pyplot as plt
plt.style.use('ggplot') #グラフスタイル
plt.rcParams['figure.figsize'] = [12, 9] # グラフサイズ
#
# データセット読み込み
#
url = 'https://www.salesanalytics.co.jp/bgr8'
df = pd.read_csv(url)
#
# 前処理
#
## 変換
dataset = df.y.values #NumPy配列へ変換
dataset = dataset.astype('float32') #実数型へ変換
dataset = np.reshape(dataset, (-1, 1)) #1次元配列を2次元配列へ変換
## ラグ付きデータセット生成関数
def gen_dataset(dataset, lag_max):
X, y = [], []
for i in range(len(dataset) - lag_max):
a = i + lag_max
X.append(dataset[i:a, 0]) #ラグ変数
y.append(dataset[a, 0]) #目的変数
return np.array(X), np.array(y)
## 分析用データセットの生成
lag_max = 365
X, y = gen_dataset(dataset, lag_max)
#
# データ分割
#
test_length = 30 #テストデータの期間
X_train_0 = X[:-test_length,:] #学習データ
X_test_0 = X[-test_length:,:] #テストデータ
y_train_0 = y[:-test_length] #学習データ
y_test_0 = y[-test_length:] #テストデータ
y_train = y_train_0.reshape(-1,1)
y_test = y_test_0.reshape(-1,1)
#
# 正規化(0-1の範囲にスケーリング)
#
## 目的変数y
scaler_y = MinMaxScaler(feature_range=(0, 1))
y_train = scaler_y.fit_transform(y_train)
## 説明変数X
scaler_X = MinMaxScaler(feature_range=(0, 1))
X_train_0 = scaler_X.fit_transform(X_train_0)
X_test_0 = scaler_X.transform(X_test_0)
GRU(ラグ変数:features)
中間層にGRU層を持ったニューラルネットワークを、ラグ変数Xを特徴量(features)とした学習データで構築していきます。
構築したモデルは、テストデータで検証していきます。
GRU(ラグ変数:features)|データ準備
ラグ変数Xを特徴量(features)とした学習データとテストデータを準備します。
以下、コードです。
# モデル構築用にデータを再構成(サンプル数、タイムステップ, 特徴量数)
X_train = np.reshape(X_train_0, (X_train_0.shape[0],1,X_train_0.shape[1]))
X_test = np.reshape(X_test_0, (X_test_0.shape[0],1,X_test_0.shape[1]))
print('X_train:',X_train.shape) #確認
print('X_test:',X_test.shape) #確認
以下、実行結果です。

X_trainが(samples=2510, time_steps=1, features=365)で、X_testが(samples=30, time_steps=1, features=365)ということです。
要は、ラグ変数を特徴量(features)として扱うということです。
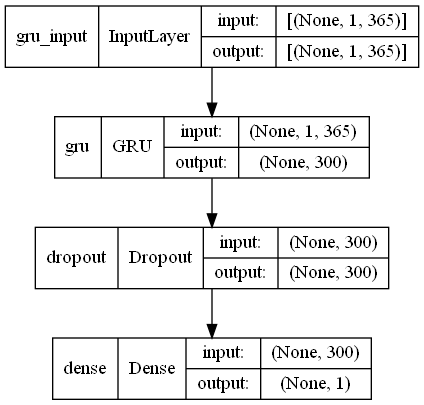
GRU(ラグ変数:features)|モデル生成
ニュラールネットワークモデルを定義し、定義したモデルをコンパイルしモデル生成します。
以下、コードです。LSTMの違いは3行目がLSTMからGRUに変わったところです。
# モデル定義 model = Sequential() model.add(GRU(300,input_shape=(X_train.shape[1], X_train.shape[2]))) model.add(Dropout(0.2)) model.add(Dense(1, activation='linear')) # コンパイル model.compile(loss='mean_squared_error', optimizer='adam') # モデルの視覚化 plot_model(model,show_shapes=True)
以下、実行結果です。
GRU(ラグ変数:features)|学習
学習データを使いモデルを学習します。
以下、コードです。
# EaelyStoppingの設定
early_stopping = EarlyStopping(monitor='val_loss',
min_delta=0.0,
patience=2)
# 学習の実行
history = model.fit(X_train, y_train,
epochs=1000,
batch_size=128,
validation_split=0.2,
callbacks=[early_stopping] ,
verbose=1,
shuffle=False)
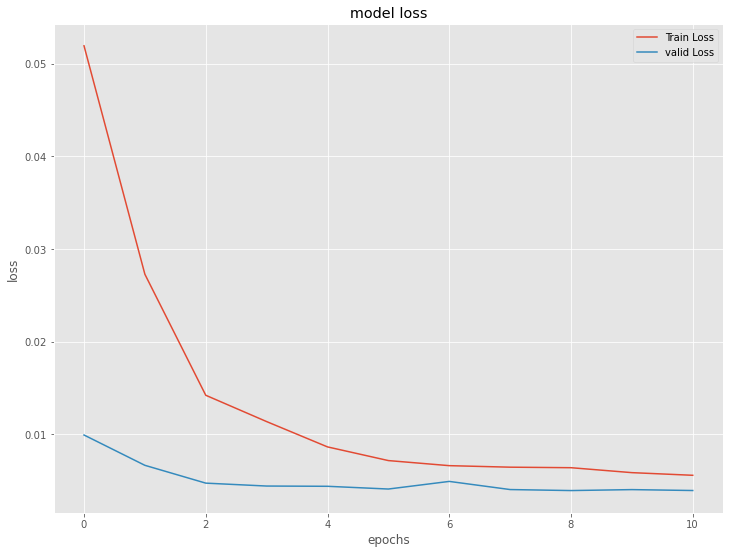
今学習したモデルの、学習結果を出力します。
以下、コードです。
# 学習結果の出力
model.summary()
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='valid Loss')
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend(loc='upper right')
plt.show()
{kind=link}

GRU(ラグ変数:features)|検証
学習したモデルを、テストデータで検証します。
以下、コードです。
# テストデータの目的変数を予測
y_test_pred = model.predict(X_test)
y_test_pred = scaler_y.inverse_transform(y_test_pred)
# テストデータの目的変数と予測結果を結合
df_test = pd.DataFrame(np.hstack((y_test,y_test_pred)),
columns=['y','Predict'])
# 指標出力
print('RMSE:')
print(np.sqrt(mean_squared_error(y_test, y_test_pred)))
print('MAE:')
print(mean_absolute_error(y_test, y_test_pred))
print('MAPE:')
print(mean_absolute_percentage_error(y_test, y_test_pred))
# グラフ化
df_test.plot(kind='line')
以下、実行結果です。

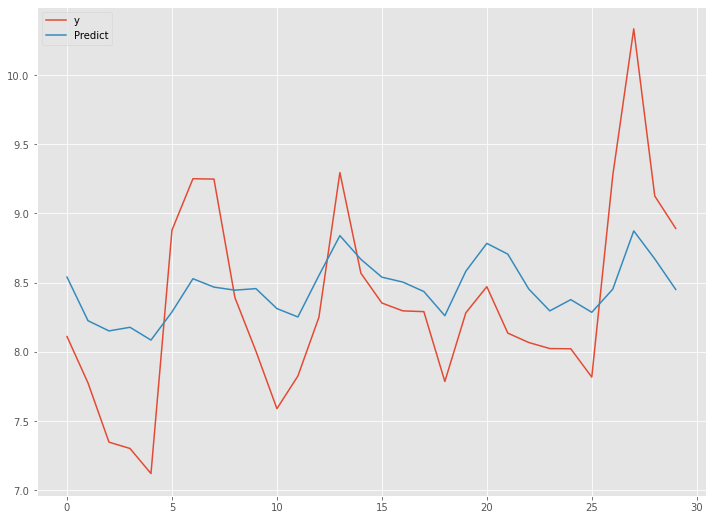
予測精度は、前回良かったLSTM(ラグ変数:time steps)と同等です。やや良いぐらいです。
GRU(ラグ変数:time steps)
中間層にGRU層を持ったニューラルネットワークを、ラグ変数Xをタイプステップ(time_steps)とした学習データで構築していきます。
構築したモデルは、テストデータで検証していきます。
GRU(ラグ変数:time steps)|データ準備
ラグ変数Xをタイプステップ(time_steps)とした学習データとテストデータを準備します。
以下、コードです。
# モデル構築用にデータを再構成(サンプル数、タイムステップ, 特徴量数)
X_train = np.reshape(X_train_0, (X_train_0.shape[0],X_train_0.shape[1],1))
X_test = np.reshape(X_test_0, (X_test_0.shape[0],X_test_0.shape[1],1))
print('X_train:',X_train.shape) #確認
print('X_test:',X_test.shape) #確認
以下、実行結果です。

X_trainが(samples=2510, time_steps=365, features=1)で、X_testが(samples=30, time_steps=365, features=1)ということです。
要は、ラグ変数をタイプステップ(time_steps)として扱うということです。
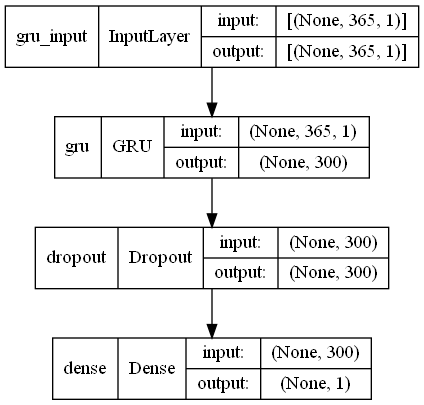
GRU(ラグ変数:time steps)|モデル生成
ニュラールネットワークモデルを定義し、定義したモデルをコンパイルしモデル生成します。
以下、コードです。
# モデル定義 model = Sequential() model.add(GRU(300,input_shape=(X_train.shape[1], X_train.shape[2]))) model.add(Dropout(0.2)) model.add(Dense(1, activation='linear')) # コンパイル model.compile(loss='mean_squared_error', optimizer='adam') # モデルの視覚化 plot_model(model,show_shapes=True)
以下、実行結果です。
GRU(ラグ変数:time steps)|学習
学習データを使いモデルを学習します。
以下、コードです。
# EaelyStoppingの設定
early_stopping = EarlyStopping(monitor='val_loss',
min_delta=0.0,
patience=2)
# 学習の実行
history = model.fit(X_train, y_train,
epochs=1000,
batch_size=128,
validation_split=0.2,
callbacks=[early_stopping] ,
verbose=1,
shuffle=False)
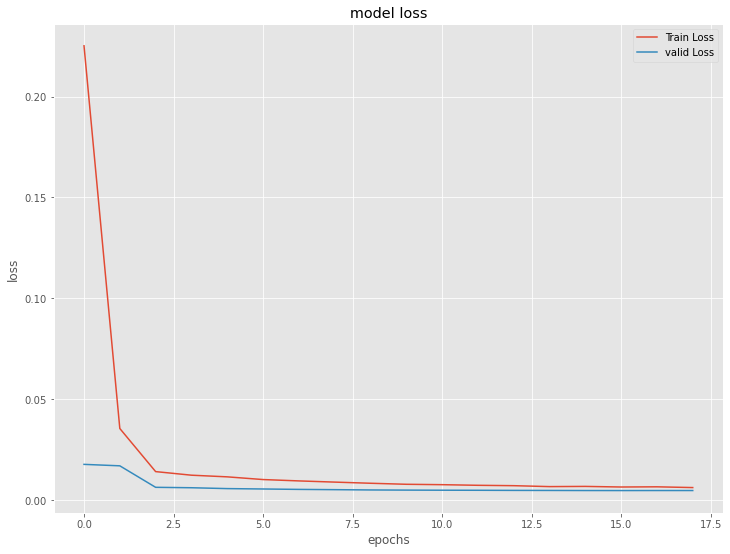
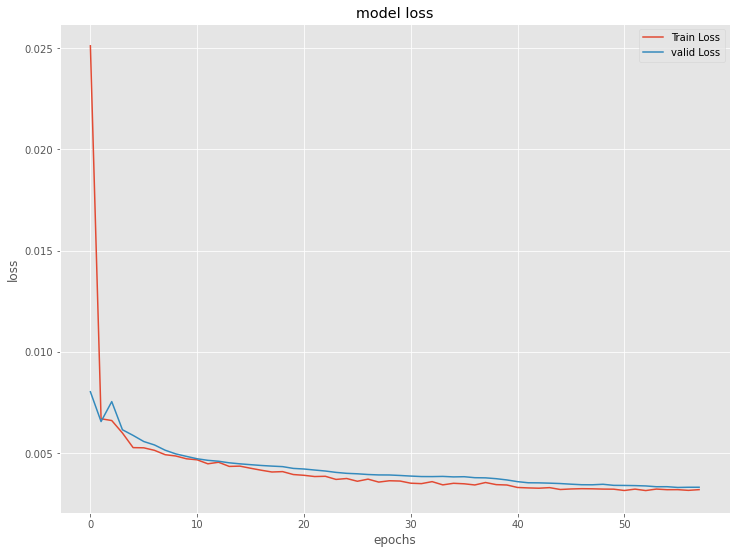
今学習したモデルの、学習結果を出力します。
以下、コードです。
# 学習結果の出力
model.summary()
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='valid Loss')
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend(loc='upper right')
plt.show()
以下、実行結果です。

GRU(ラグ変数:time steps)|検証
学習したモデルを、テストデータで検証します。
以下、コードです。
# テストデータの目的変数を予測
y_test_pred = model.predict(X_test)
y_test_pred = scaler_y.inverse_transform(y_test_pred)
# テストデータの目的変数と予測結果を結合
df_test = pd.DataFrame(np.hstack((y_test,y_test_pred)),
columns=['y','Predict'])
# 指標出力
print('RMSE:')
print(np.sqrt(mean_squared_error(y_test, y_test_pred)))
print('MAE:')
print(mean_absolute_error(y_test, y_test_pred))
print('MAPE:')
print(mean_absolute_percentage_error(y_test, y_test_pred))
# グラフ化
df_test.plot(kind='line')
以下、実行結果です。

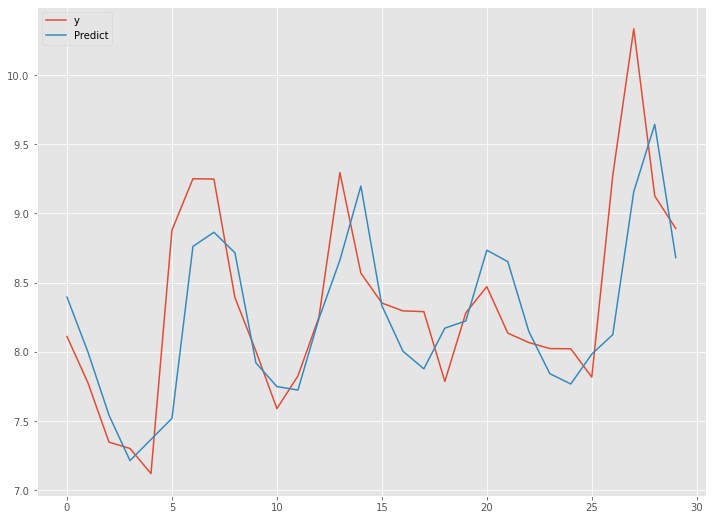
予測精度は、前回良かったLSTM(ラグ変数:time steps)より良くなっています。
前回および前々回含め、一番高精度だったのは、前々回のシンプルRNN(ラグ変数:time steps)です。
次回
今回は、LSTMの計算コスト大きい問題を改善する形で登場したGRU(Gated Recurrent Unit)のモデル構築方法と1期先予測(1-Step ahead prediction)予測についてお話ししました。
次回は、1期先予測(1-Step ahead prediction)を拡張した複数先予測(Multi-Step ahead prediction)についてお話しします。予測で利用するモデルは、シンプルRNNおよびLSTM、GRUの3つです。ラグ変数をtime stepsとして扱います。