

Pandasは非常に優れたライブラリーで、データフレームに対し色々なことができます。ただ、すべての機能を知り使いこなすのは至難の業です。
幸運なことに、よく利用する機能は決まっており(人によって違いとは思いますが……)、その機能を知り使いこなすだけで十分なケースも多々あります。
今回は、PythonのPandasでよく使う機能と思われるものを、幾つか紹介します。
Contents [hide]
- データフレームの生成|DataFrame
- データの読み込み|read_csv
- データの書き込み|to_csv
- データセットのサイズ|shape
- データセットの一部を見る|head、tail、sample
- 各カラム(変数)のデータ型の確認|dtypes
- データセットのサマリー|info
- データセットの基礎統計|describe
- グラフ化|plot
- 並べ替え(ソート)|sort_values
- データ連結|concat、merge
- 抽出|iloc、loc
- フィルタリング|df[条件]
- カラム(変数)の一意な値リスト|unique
- グルーピング集計|groupby
- カラム(変数)のドロップ(除外)|drop
- 行方向に集計|sum(axis = 1)
- カラム(変数)へ関数適用
- 新規カラム(新規変数)の追加|df[新しいカラム名]
- カラム(変数)名の変更|rename
- まとめ
データフレームの生成|DataFrame
Pandasでは、データフレーム形式のデータセットを扱います。先ずは、DataFrame関数でデータフレームを作ることから初めます。
以下、辞書形式のデータからデータフレームを作成する例です。
#
# 辞書形式のデータからデータフレームを作成する
#
# 辞書形式のデータ
dataset = {"col1" : [1,2,3,4,5],
"col2" : [6,7,8,9,10],
"col3" : [11,12,13,14,15]
}
# データフレーム化
df = pd.DataFrame(dataset)
df #確認
以下、実行結果です。

以下、リスト形式のデータからデータフレームを作成する例です。
#
# リスト形式のデータからデータフレームを作成する
#
# 辞書形式のデータ
dataset = [[1, 6,11],
[2, 7,12],
[3, 8,13],
[4, 9,14],
[5,10,15]
]
# データフレーム化
df = pd.DataFrame(dataset,
columns = ["col1","col2","col3"])
df #確認
以下、実行結果です。

データの読み込み|read_csv
Pandasを活用した多くのデータ分析は、一からデータセットを作るのではなく、外部ファイルを読み込んで利用します。
以下、CSVファイルをデータフレームとして読み込む例です。read_csv関数でCSVファイルを読み込みます。
# # CSVファイルをデータフレームとして読み込む # # 読み込むファイル名 file = "MMM.csv" # CSVファイルの読み込み df = pd.read_csv(file) df #確認
ファイル名ではなく、データのあるURLを指定し読み込むこともできます。以下、コードです。
# # CSVファイルをデータフレームとして読み込む # # 読み込むファイル名(データのあるURLを指定) file = "https://www.salesanalytics.co.jp/4zdt" # CSVファイルの読み込み df = pd.read_csv(file) df #確認
以下、実行結果です。
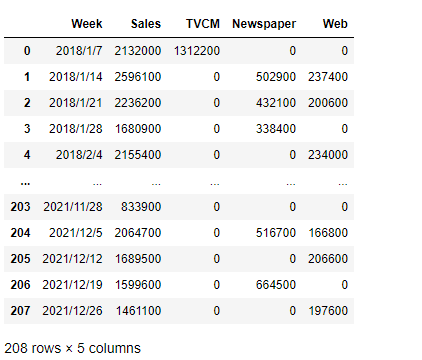
データの書き込み|to_csv
外部ファイルを読み込むのではなく、Pandasのデータフレームを外部ファイルとして保存することもあります。
以下、コードです。to_csv関数でCSVファイルとして書き出します。
# # データフレームをCSVファイルとして保存 # # 保存するCSVファイル名 file = "dataset.csv" # CSVファイルとして保存 df.to_csv(file)
データセットのサイズ|shape
データフレームが何行何列なのか、サイズを確認することは多々あります。
以下、コードです。shapeメソッドでサイズを出力します。
df.shape
以下、実行結果です。(行数、列数)です。
![]()
データセットの一部を見る|head、tail、sample
データフレームの一部を確認することも多々あります。
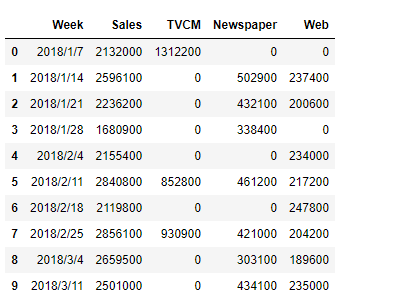
以下、最初の方のレコード10行を見るときの例です。headメソッドで出力します。
# 最初の方のレコード10行 df.head(10)
以下、実行結果です。
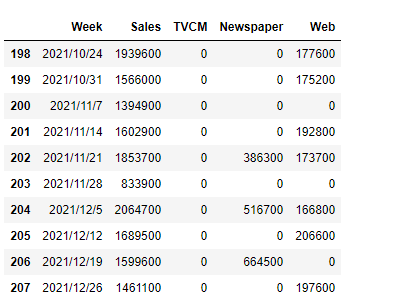
以下、最後の方のレコード10行を見るときの例です。tailメソッドで出力します。
# 最後の方のレコード10行 df.tail(10)
以下、実行結果です。
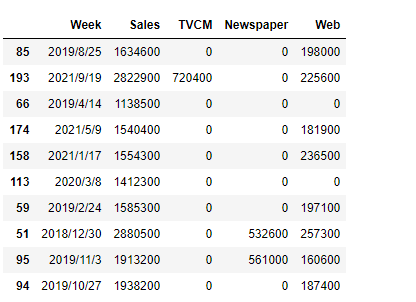
以下、ランダムにレコード10行を見るときの例です。sampleメソッドで出力します。
# ランダムにレコード10行 df.sample(10)
以下、実行結果です。
各カラム(変数)のデータ型の確認|dtypes
データフレームの各カラム(変数)のデータ型も気になるところでしょう。
以下、コードです。dtypesメソッドで出力します。
df.dtypes
以下、実行結果です。

データセットのサマリー|info
型だけでなく、もう少し情報が欲しいときがあります。
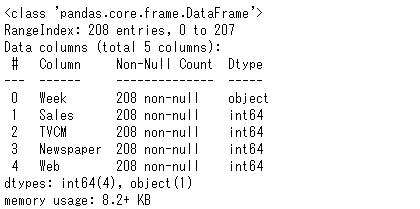
データセットのサマリーです。以下、コードです。infoメソッドで出力します。
df.info()
以下、実行結果です。
データセットの基礎統計|describe
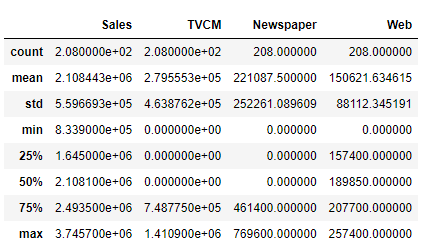
どのようなデータセットなのかを理解するには、生のデータセットを見るだけでなく、カラム(変数)の基礎統計(平均値など)を計算し見ることも大事です。
以下、コードです。describeメソッドで出力します。
df.describe()
以下、実行結果です。
グラフ化|plot
グラフで見ると、データのイメージが付きます。
以下、コードです。plotメソッドで出力します。
df.plot()
以下、実行結果です。
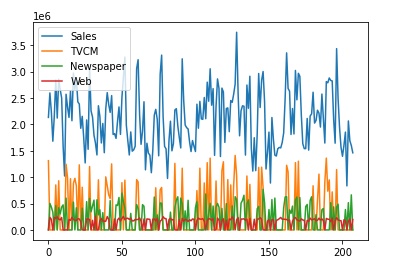
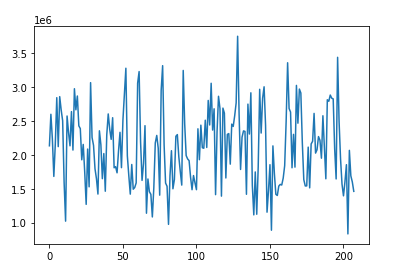
すべてのカラム(変数)がプロットされています。特定のカラム(変数)を指定しプロットします。
以下、コードです。
df["Sales"].plot()
以下、実行結果です。
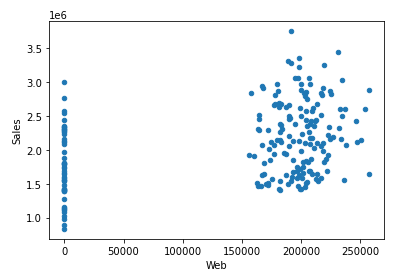
カラム(変数)間の関係性をプロット(散布図)することもあります。
以下、コードです。
df.plot.scatter(x="Web", y="Sales")
以下、実行結果です。
並べ替え(ソート)|sort_values
データセットを並べ替え(ソート)です。sort_valuesメソッドで実施します。
以下、昇順例です。
# 昇順 df.sort_values(by="Sales")
以下、実行結果です。

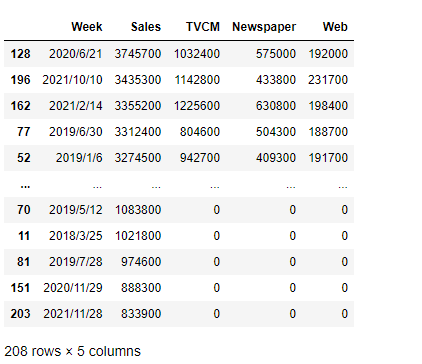
以下、降順例です。
# 降順 df.sort_values(by="Sales", ascending=False)
以下、実行結果です。
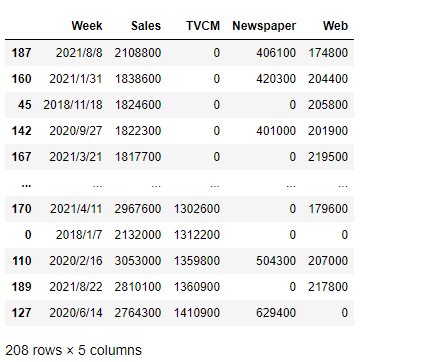
複数のカラム(変数)の例です。
df.sort_values(by="Sales", ascending=False).sort_values(by="TVCM")
以下、実行結果です。
データ連結|concat、merge
2つのデータフレームの連結です。concat関数やmerge関数などで実施します。
縦の連結例です。
#
# 縦に連結
#
# データフレーム1
df1 = pd.DataFrame(
{
"col1" : [1,2,3,4,5],
"col2" : [6,7,8,9,10],
"col3" : [11,12,13,14,15]
}
)
# データフレーム2
df2 = pd.DataFrame(
{
"col1" : [6,7],
"col2" : [8,9],
"col3" : [1,2]
}
)
# df1に縦にdf2を結合
df = pd.concat([df1, df2], axis=0)
df #確認
以下、実行結果です。
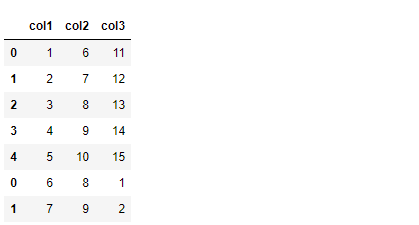
横の連結例です。
#
# 横に連結
#
# データフレーム1
df1 = pd.DataFrame(
{
"col1" : [1,2,3,4,5],
"col2" : [6,7,8,9,10],
"col3" : [11,12,13,14,15]
}
)
# データフレーム2
df2 = pd.DataFrame(
{
"col4" : [16,17,18,19,20],
"col5" : [21,22,23,24,25]
}
)
# df1の横にdf2を結合
df = pd.concat([df1, df2], axis=1)
df #確認
以下、実行結果です。
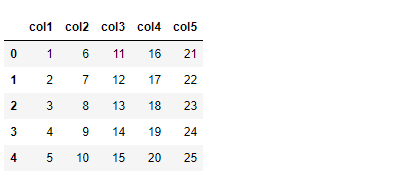
横に連結するとき、あるカラム(変数)をキーに連結することもあります。
先ず、データフレームを生成します。
# データフレーム1
df1 = pd.DataFrame(
{
"Name": ["tanaka", "hayashi", "sato", "miura"],
"Age": [33, 46, 25, 32],
"City": ["sapporo", "nagoya", "sendai", "kagoshima"],
}
)
# データフレーム2
df2 = pd.DataFrame(
{
"City": ["sapporo", "sendai", "nagoya"],
"Population": [195, 108, 230]
}
)
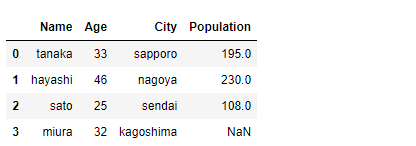
df1にCityをキーにdf2のデータを結合します。
# df1にCityをキーにdf2のデータを結合 df_merged1 = pd.merge(df1, df2, how="left", on="City") df_merged1 #確認
以下、実行結果です。
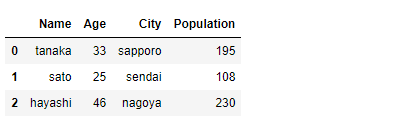
df2にCityをキーにdf1のデータを結合します。
# df2にCityをキーにdf1のデータを結合 df_merged2 = pd.merge(df1, df2, how="right", on="City") df_merged2 #確認
以下、実行結果です。
抽出|iloc、loc
データフレームの一部を抽出することは非常に多いです。ilocメソッドやlocメソッドなどで実施します。
抽出例は、先程生成した以下のデータフレームを使います。
df_merged1
特定の行と列を指定しデータを抽出します。ilocで何行目や何列目かを指定し抽出することができます。
df_merged1.iloc[3, 2]
PythonのPandasのフレームワークは、行や列は0,1,2,…と0から始まります。つまり、データフレームの一番左上のセルは、0行目かつ0列目となります。
以下、実行結果です。3行目かつ2列目です。
![]()
インデックス(レコード名やカラム名)で指定し抽出することも出来ます。
df_merged1.loc[3, "City"]
以下、実行結果です。
![]()
以下のようなコードでも問題ありません。同じ結果が得られます。
rows = [3] cols = ["City"] df_merged1.loc[rows, cols]
特定のセルではなく、範囲などでも指定できます。ilocの例です。
df_merged1.iloc[2:4, 1:3]
以下、実行結果です。

locの例です。同じ結果が得られます。
df_merged1.loc[[2,3], ["Age","City"]]
以下のようなコードでも問題ありません。同じ結果が得られます。
rows = [2,3] cols = ["Age","City"] df_merged1.loc[rows, cols]
すべての列やすべての行を指定するときは「:」で表現します。
すべての列を指定した例です。
df_merged1.iloc[2:4, :]
以下、実行結果です。

すべての行を指定した例です。
df_merged1.iloc[:, 1:3]
以下、実行結果です。

フィルタリング|df[条件]
ある条件に一致したデータを抽出します。条件を”[]”の中に記載します。
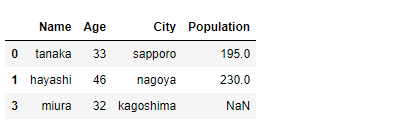
以下、カラム(変数)Ageが30より大きいデータを抽出するときの例です。
df_merged1[df_merged1.Age > 30]
以下、実行結果です。
特定の値を指定し条件にあったものを抽出することもできます。
# フィルター条件 filter_list = ["tanaka", "hayashi"] # フィルタリングの実施 df_merged1[df_merged1.Name.isin(filter_list)]
以下、実行結果です。
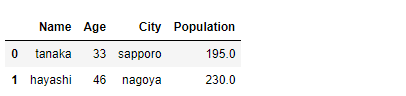
複数の条件も指定できます。
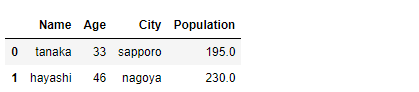
df_merged1[
(df_merged1.Age > 30) &
(df_merged1.Name.isin(filter_list))
]
以下、実行結果です。
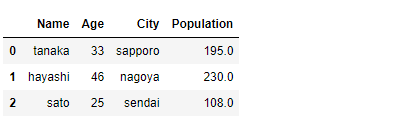
NA(欠測値)以外という条件を指定するときは、次のようにします。
df_merged1[df_merged1["Population"].notna()]
以下、実行結果です。
カラム(変数)の一意な値リスト|unique
カラム(変数)がカテゴリカル変数(質的変数)の場合、一意な値のリストを作ることもあります。uniqueメソッドで出力します。
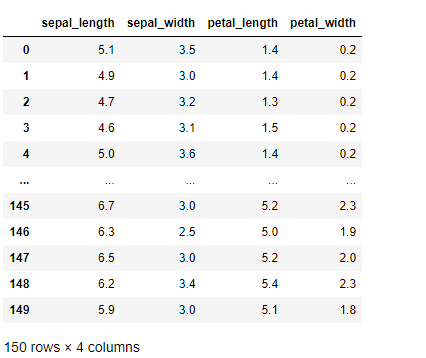
ここで、カテゴリカル変数(質的変数)の存在するデータセットである「アヤメ(iris)」のデータセットを先ず読み込みます。
以下、コードです。
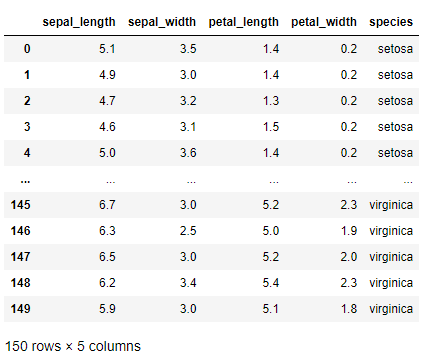
# データの読み込み
df = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
df #確認
実行結果です。speciesがカテゴリカル変数(質的変数)です。
カラム(変数)speciesの一意な値のリストを作ります。
df.species.unique()
以下、実行結果です。
![]()
グルーピング集計|groupby
あやめ(iris)の基礎統計量を見てみます。
df.describe()
以下、実行結果です。量的変数の基礎統計量です。
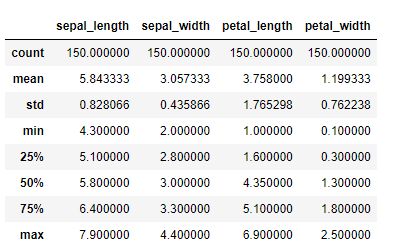
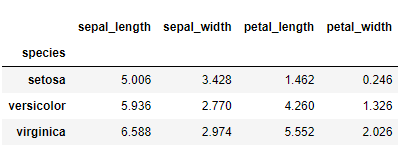
この基礎統計量を、カラム(変数)speciesの値別に集計するとき、groupbyメソッドを使います。
df.groupby("species").mean()
以下、実行結果です。
カラム(変数)のドロップ(除外)|drop
特定のカラム(変数)を抽出するとき、以下のようになります。
df["species"]
以下、実行結果です。

以下のコードでも、同様の結果が得られます。
df.species
逆に、特定のカラム(変数)を除外(drop)するとき、以下のようになります。dropメソッドを使います。
df_drop = df.drop(columns = ["species"]) df_drop #確認
以下、実行結果です。
行方向に集計|sum(axis = 1)
先程の基礎郎計量などは、カラム(変数)ごとの集計、つまり列方向の集計でした。
列方向の集計を明示的に表現するとき、以下のように「axis = 0」と指定します。
# 列方向に集計 df_drop.sum(axis = 0)
以下、実行結果です。

行方向の集計例です。「axis = 1」と指定します。
# 行方向に集計 df_drop.sum(axis = 1)
以下、実行結果です。

カラム(変数)へ関数適用
定義した関数をカラム(変数)に適用することもできます。applyメソッドで実施します。
# 関数定義
def f(num):
return num*num
# 関数適用
df_drop.sepal_length.apply(f)
以下、実行結果です。

新規カラム(新規変数)の追加|df[新しいカラム名]
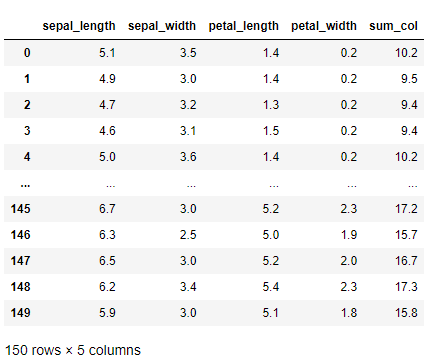
元のデータフレームから計算し、それを新たなカラム(変数)として追加することも少なくありません。
行方向で合計した値を、新たなカラム(変数)(sum_col)として、元のデータフレームに追加します。
df_drop["sum_col"] = df_drop.sum(axis = 1) df_drop #確認
以下、実行結果です。
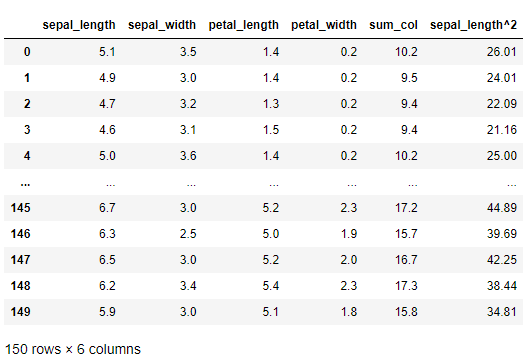
さらに、先程定義した関数をカラム(変数)sepal_lengthに適用し、新たなカラム(変数)(sepal_length^2)として追加します。
df_drop["sepal_length^2"] = df_drop.sepal_length.apply(f) df_drop #確認
以下、実行結果です。
カラム(変数)名の変更|rename
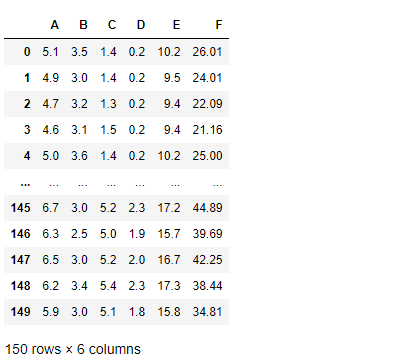
カラム(変数)名を分かりやすく変更することも多いです。renameメソッドで実施します。「:」の左側に変更前のカラム(変数)名、「:」の右側に変更後のカラム(変数)名を指定します。
df_drop.rename(columns = {
"sepal_length":"A",
"sepal_width":"B",
"petal_length":"C",
"petal_width":"D",
"sum_col":"E",
"sepal_length^2":"F"
})
以下、実行結果です。
まとめ
今回は、PythonのPandasでよく使う機能と思われるものを、幾つか紹介しました。
- データフレームの生成|DataFrame
- データの読み込み|read_csv
- データの書き込み|to_csv
- データセットのサイズ|shape
- データセットの一部を見る|head、tail、sample
- 各カラム(変数)のデータ型の確認|dtypes
- データセットのサマリー|info
- データセットの基礎統計|describe
- グラフ化|plot
- 並べ替え(ソート)|sort_values
- データ連結|concat、merge
- 抽出|iloc、loc
- フィルタリング|df[条件]
- カラム(変数)の一意な値リスト|unique
- グルーピング集計|groupby
- カラム(変数)のドロップ(除外)|drop
- 行方向に集計|sum(axis = 1)
- カラム(変数)へ関数適用
- 新規カラム(新規変数)の追加|df[新しいカラム名]
- カラム(変数)名の変更|rename