

データを入手したとき、最初に実施するタスクの1つが、探索的データ分析 (EDA) です。
探索的データ分析 (EDA) は、データをより深く理解するプロセスにおける重要なタスクです。
データの大まかな概要を把握するためのツールがいくつかあります。例えば、Tableauです。Tableauは無料ではありません。それなりにコストがかかります。
PandasやPolarsのデータフレーム(DataFrame)を、Tableau風のユーザーインターフェイスで操作できるようにするPythonライブラリーがあります。
PyGWalkerです。
PyGWalkerは、Tableauの代替品とも言われているオープンソースであるGraphic Walkerを利用したものです。
以前、Jupyter上でPyGWalkerを使う方法について簡単に説明しました。
いっそのこと、Jupyter上でPythonコードを入力することなく、Graphic Walkerを利用したいものです。
Streamlitに、この PyGWalker と連携する機能があります。
そのことで、ノーコードで簡単な探索的データ分析 (EDA)を、Tableau風ダッシュボードで実施できます。
ということで今回は、PyGWalker を Streamlit アプリケーションに埋め込む方法を説明します。
Streamlitそのものについては、以下の記事を参考にしてください。
Contents [hide]
PyGWalker と Streamlit のインストール
Streamlit アプリケーションを実行して PyGWalker を組み込むには、それらのパッケージをインストールする必要があります。
以下の2つです。
- streamlit
- pygwalker
インストールしていない場合には、インストールしていただければと思います。
condaでインストールするときは、以下です。
conda install -c conda-forge streamlit conda install -c conda-forge pygwalker
pipでインストールするときは、以下です。
pip install streamlit pip install pygwalker
これから作る Streamlit アプリ
次の2つのコンポーネントからなら Streamlit アプリを作ります。
- サイドパネル:CSVファイル取得
- メインパネル:Graphic Walker 操作
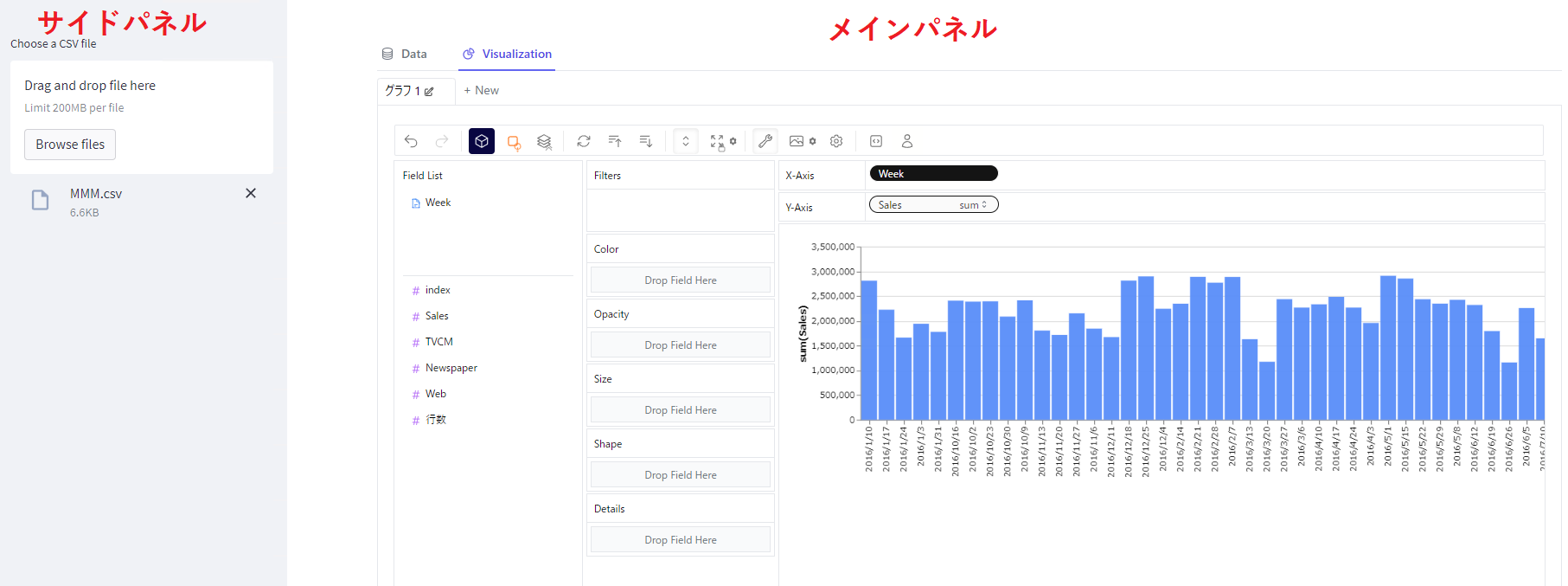
左側に表示されるサイドパネル上で、CSVファイルを取得します。CSVファイルは、データフレーム(DataFrame)として取得します。
このデータフレーム(DataFrame)を、メインパネル上でPyGWalkerを使い探索的データ分析 (EDA) を実施します。
要は、グラフ化です。格好良く言うと、データビジュアライゼーションです。
PyGWalker を Streamlit のダッシュボードアプリに埋め込む
必要なパッケージをすべてインストールしたら、Streamlit アプリの作成を開始できます。
最初のステップは、必要なパッケージをすべてインポートすることです。
# モジュールの読み込み import pandas as pd import streamlit as st import pygwalker as pyg
表示する幅が広くするため、st.set_page_config()で設定するlayoutをwideに設定します。
# 初期設定 st.set_page_config(layout="wide")
サイドパネルに、CSVファイルの読み込みを待つインターフェースを実装します。読み込んだCSVファイルは、データフレームにします。
# CSVファイル取得(サイドパネル)
df = None
with st.sidebar:
input = st.file_uploader("Choose a CSV file")
if input is not None:
df = pd.read_csv(input)
メインパネルに、このデータフレームに対し探索的データ分析を実施する、PyGWalkerを実装します。
# Graphic Walker 操作(メインパネル)
if df is not None:
output = pyg.walk(df, env='Streamlit')
st.write(output)
コードはこれだけです。
まとめると、次のようになります。
# モジュールの読み込み
import pandas as pd
import streamlit as st
import pygwalker as pyg
# 初期設定
st.set_page_config(layout="wide")
# CSVファイル取得(サイドパネル)
df = None
with st.sidebar:
input = st.file_uploader("Choose a CSV file")
if input is not None:
df = pd.read_csv(input)
# Graphic Walker 操作(メインパネル)
if df is not None:
output = pyg.walk(df, env='Streamlit')
st.write(output)
このコードをpyファイルとして保存します。
例えば、「graphic_walker.py」と名前をつけます。以下からこのファイルをダウンロードできます。
graphic_walker.pyのダウンロード
https://www.salesanalytics.co.jp/ovf7
Streamlit ダッシュボードアプリを立ち上げる
Streamlit アプリを立ち上げます。今回は、ローカル環境で実施していきます。
コマンドプロンプトに、以下のコードを記載し実行します。
streamlit run graphic_walker.py
ただ、graphic_walker.pyのあるディレクトリで実行する必要があるため、コマンドプロンプト上でディレクトリ移動しておきましょう。
実行すると、以下のようなStreamlit ダッシュボードアプリが立ち上がります。データを読み込んでないので、何も表示されていません。

利用するデータセット
DAT8コース(2015年にワシントンDCで開催されたデータサイエンスコース)のリポジトリにあるBike Sharing Demandのデータセット(CSV)を使います。
以下、データ項目です。
- datetime – 日時
- season
- 1 = 春
- 2 = 夏
- 3 = 秋
- 4 = 冬
- holiday – その日が休日であるかどうか
- workingday – その日が週末でも休日でもない日かどうか
- weather
- 1:晴れ、雲少ない、部分的に曇り、部分的に曇り
- 2: 霧+曇り、霧+切れ落ちた雲、霧+少ない雲、霧
- 3:小雪、小雨+雷雨+雲が散らばる、小雨+雲が散らばる
- 4:大雨+氷柱+雷雨+霧、雪+霧
- temp – 気温(摂氏)。
- atemp – 体感温度
- humidity – 相対湿度
- windspeed – 風の速さ
- casual – 非登録ユーザーによるレンタル開始数
- registered – 登録ユーザーによるレンタル開始数
- count – 総レンタル数
同じものを以下からダウンロードできます。
bikeshare.csv
https://www.salesanalytics.co.jp/y17x
Streamlit ダッシュボードアプリを操作する
データ読み込み
まず、データセット(bikeshare.csv)を読み込みます。
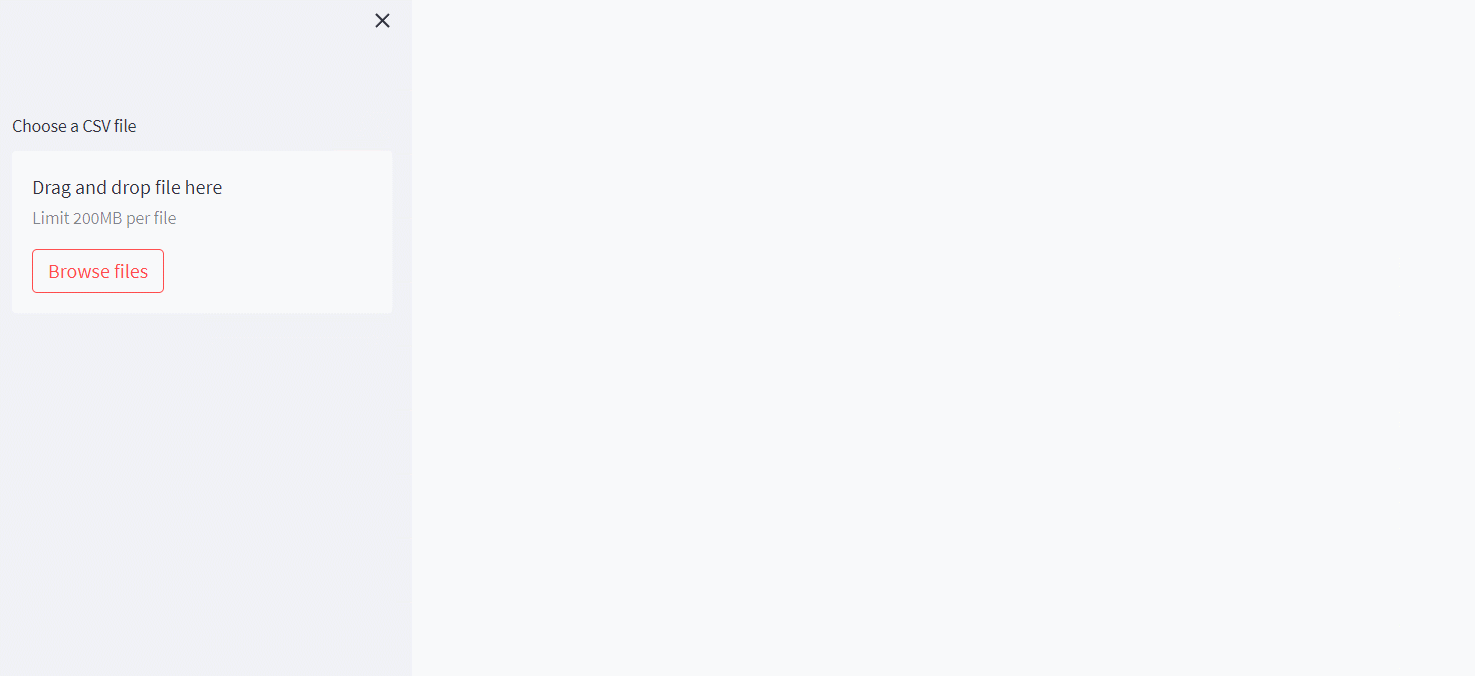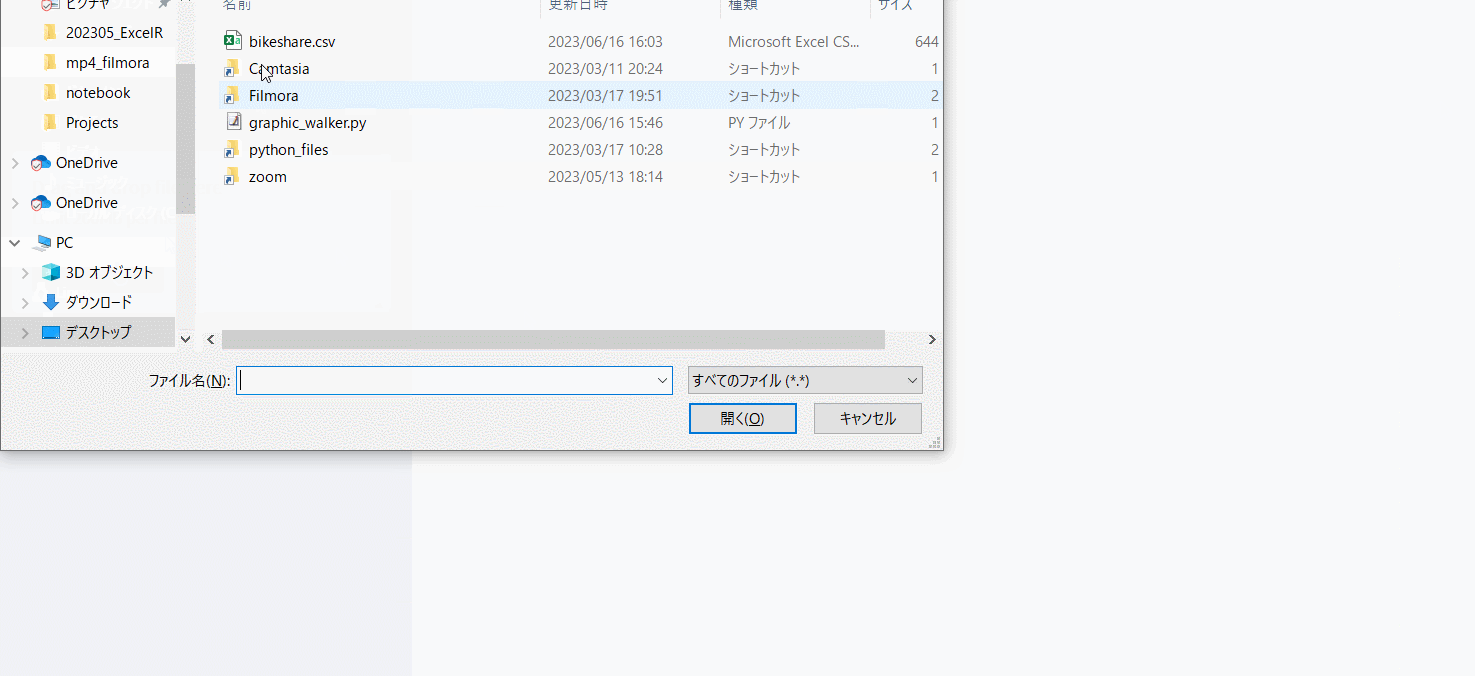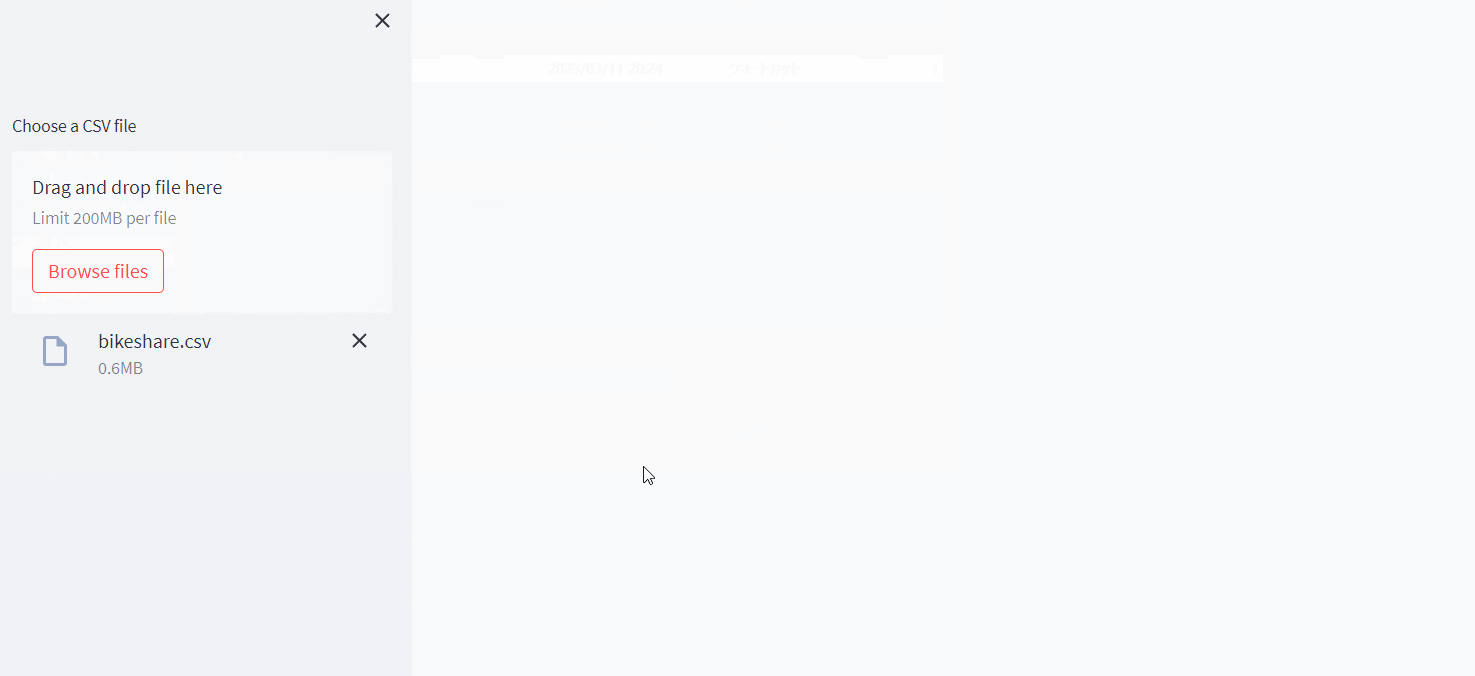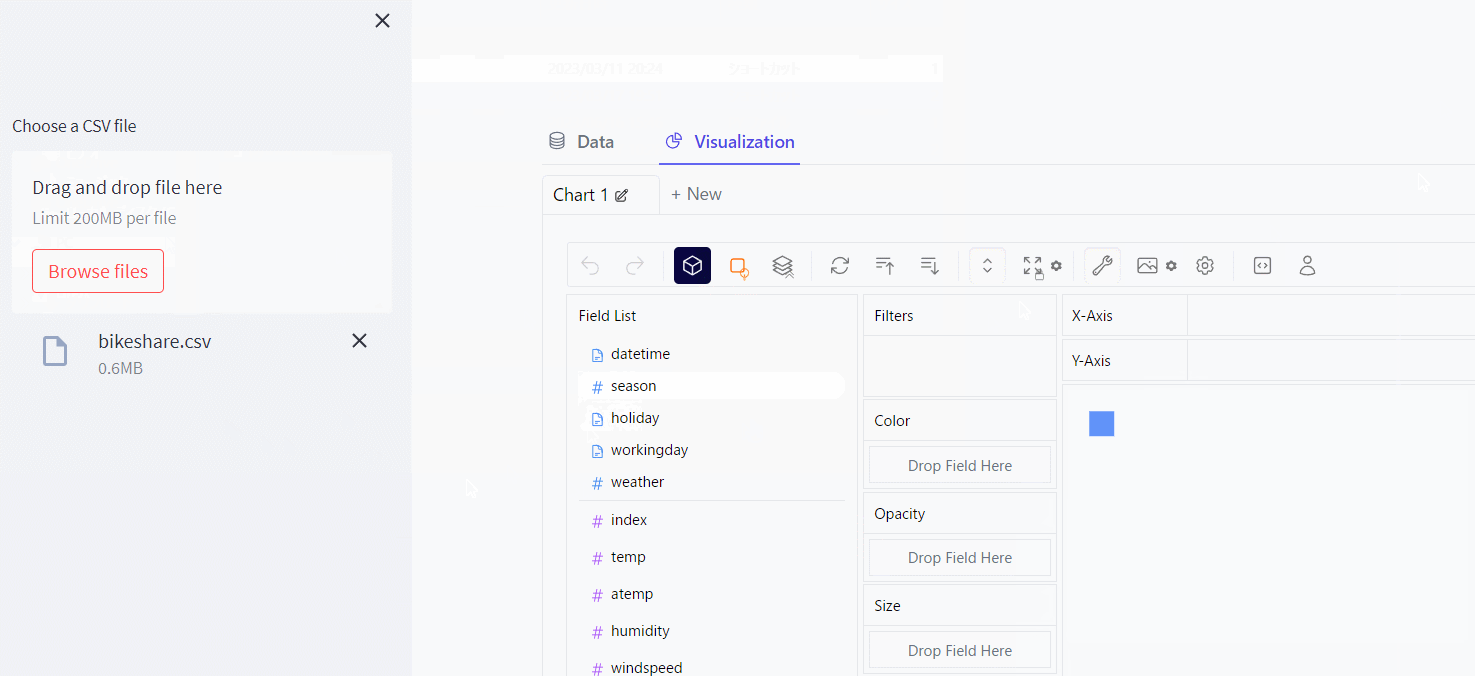
Data(データ)とVisualization(視覚化)の2つのメニュー(タブ)があります。
Data(データ)
Data(データ)をクリックすると、ローデータの内容をテーブル形式で確認することができます。※クリックすると拡大します
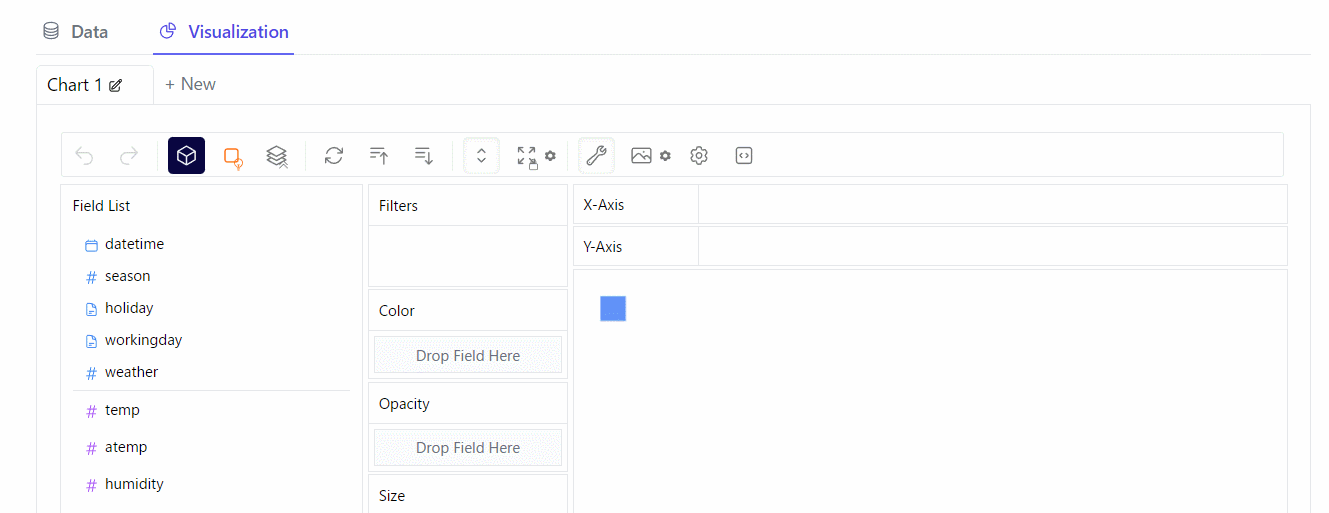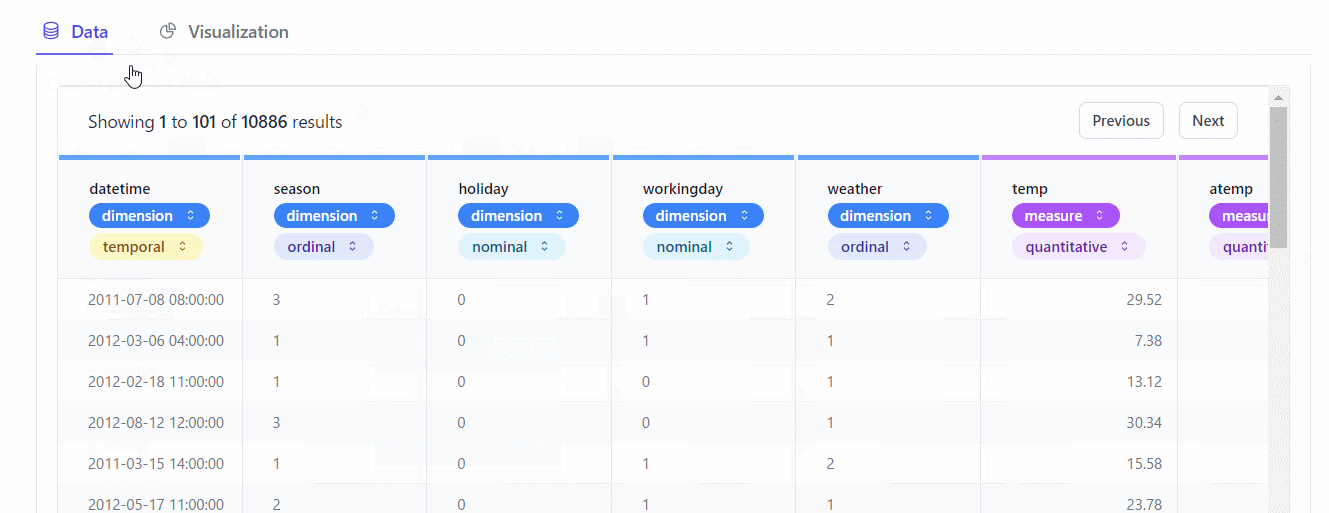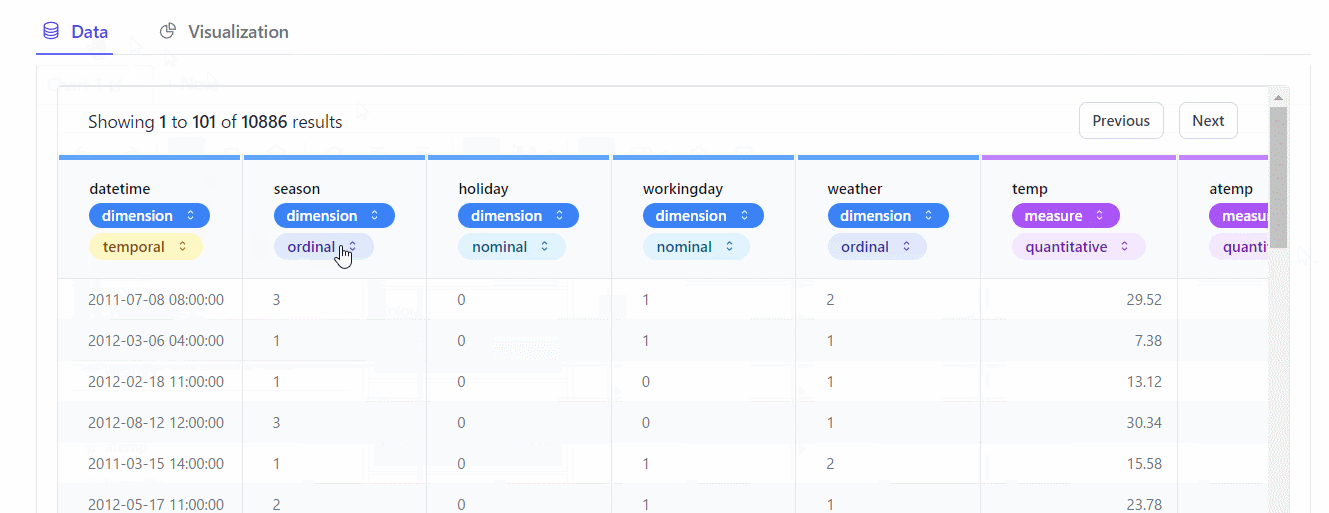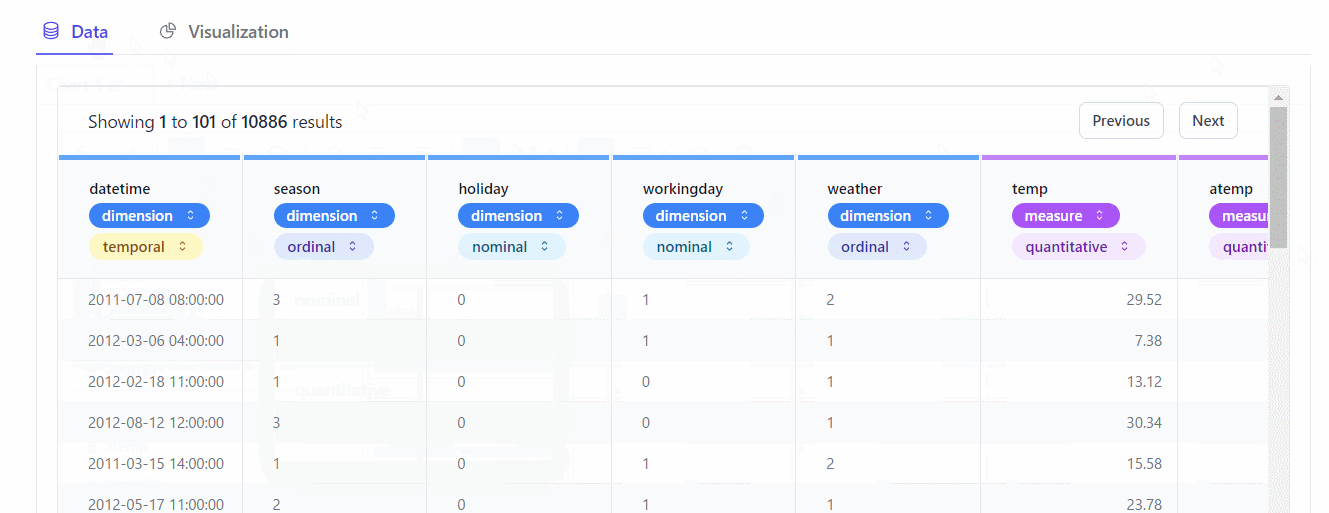
各変数が、どのようなデータなのか設定することもできます。
- この変数は、「集計軸」(dimension)なのか? 「集計対象」( measure)なのか?
- この変数は、「名義変数」(nominal)なのか? 「順序変数」(ordinal)なのか? 「量的変数」(quantitative)なのか? それ以外(temportal)なのか?
Visualization(視覚化)
散布図を作ってみます。※クリックすると拡大します
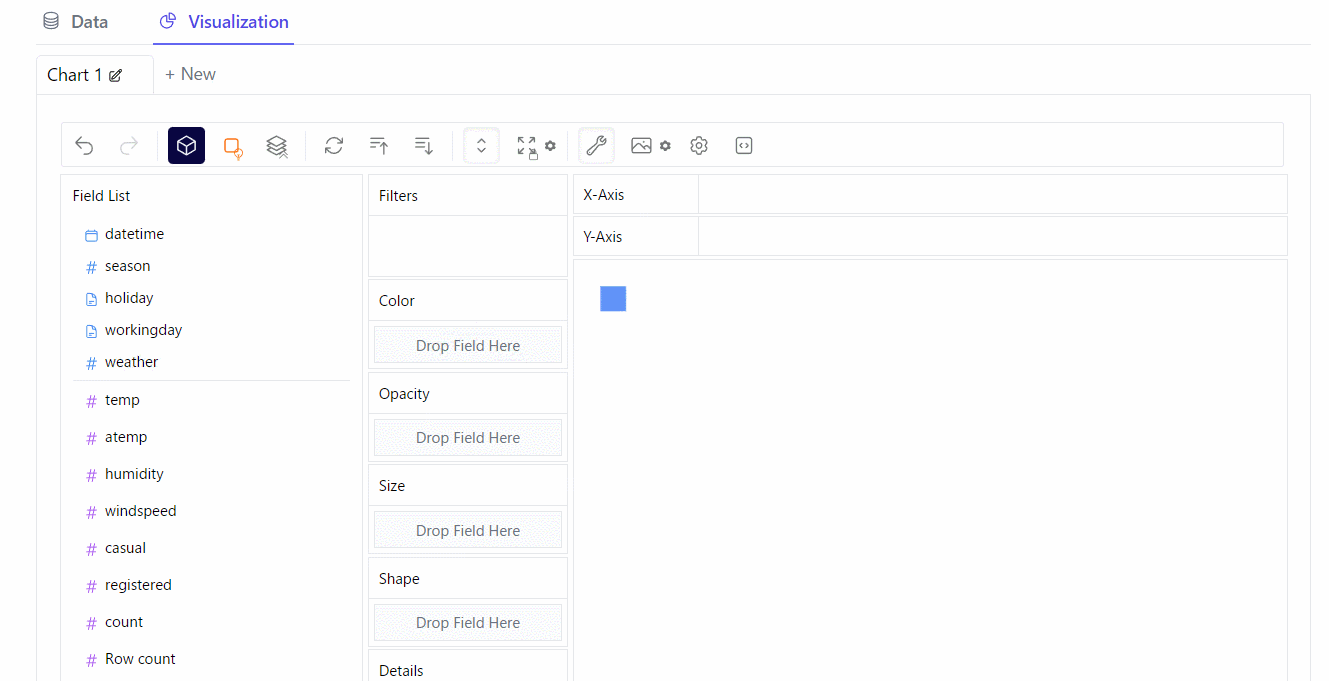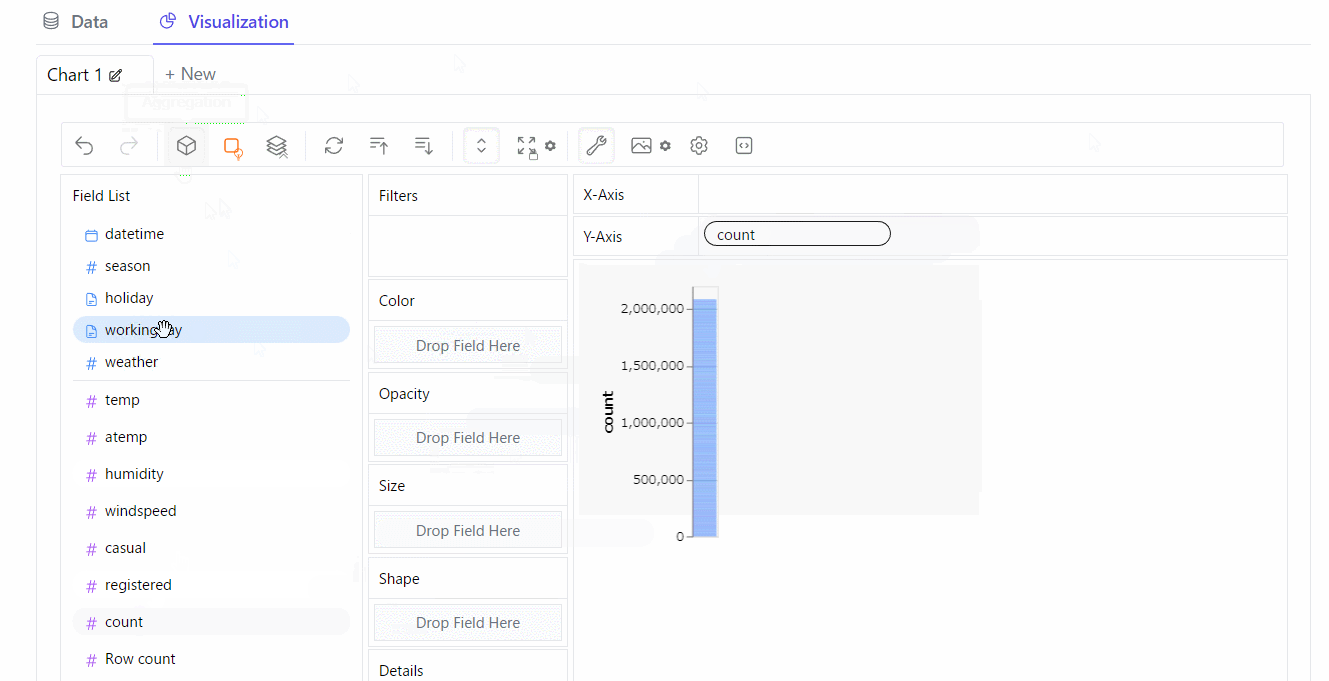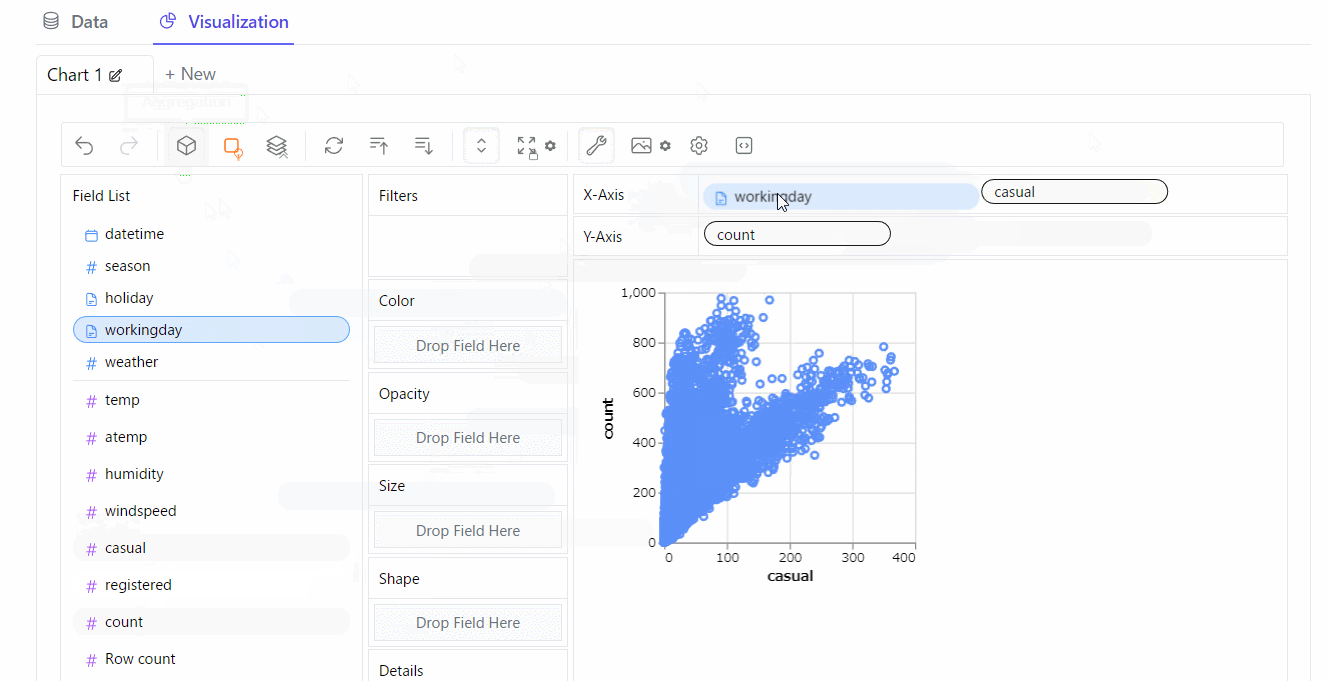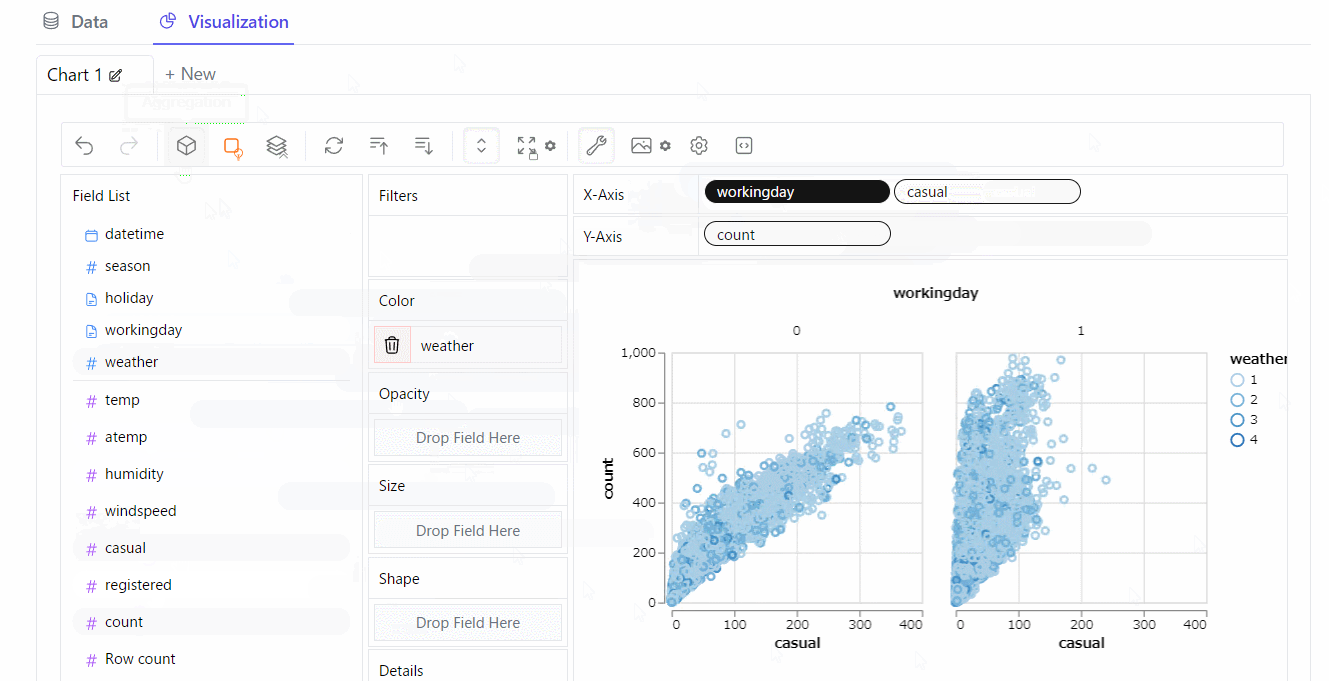
折れ線グラフを作ってみます。※クリックすると拡大します
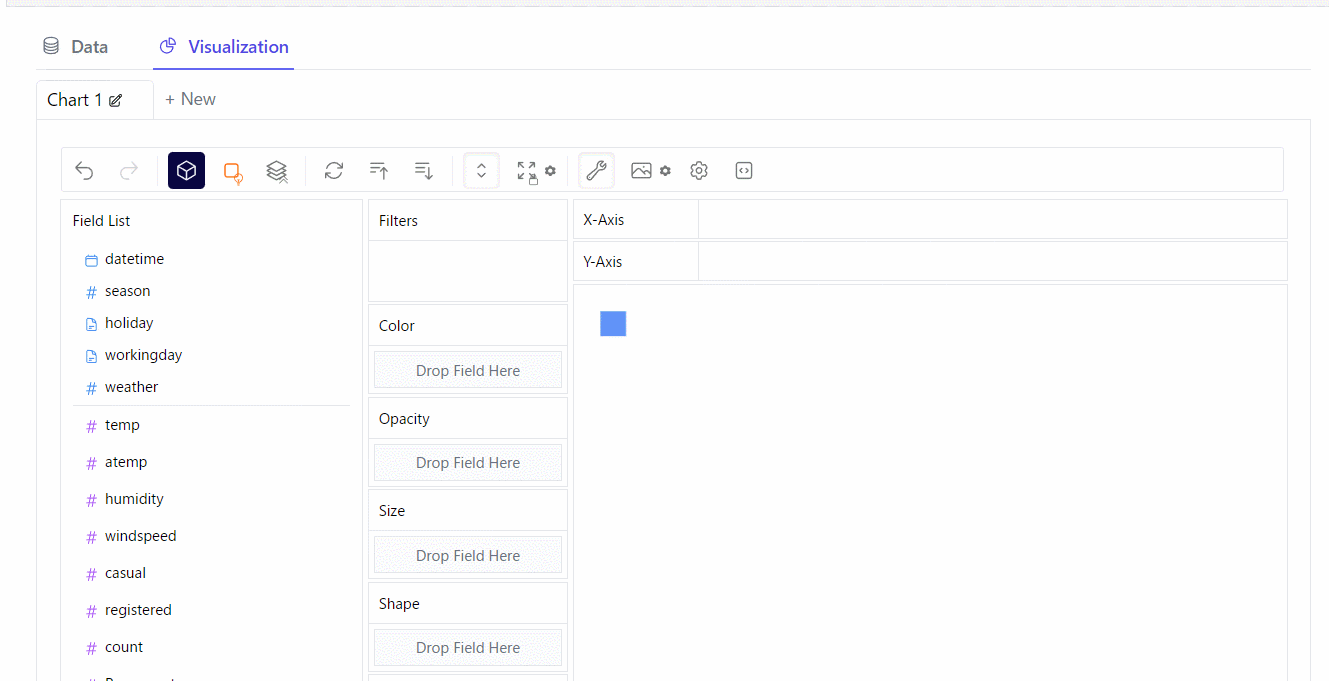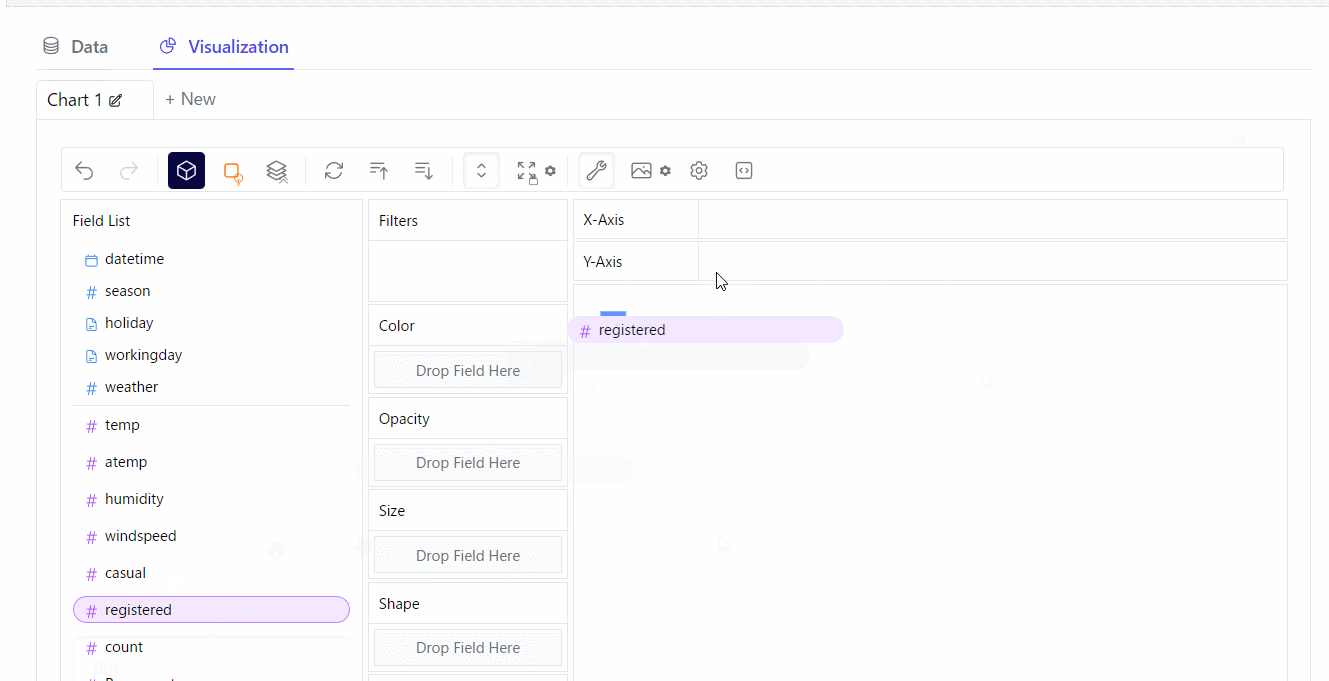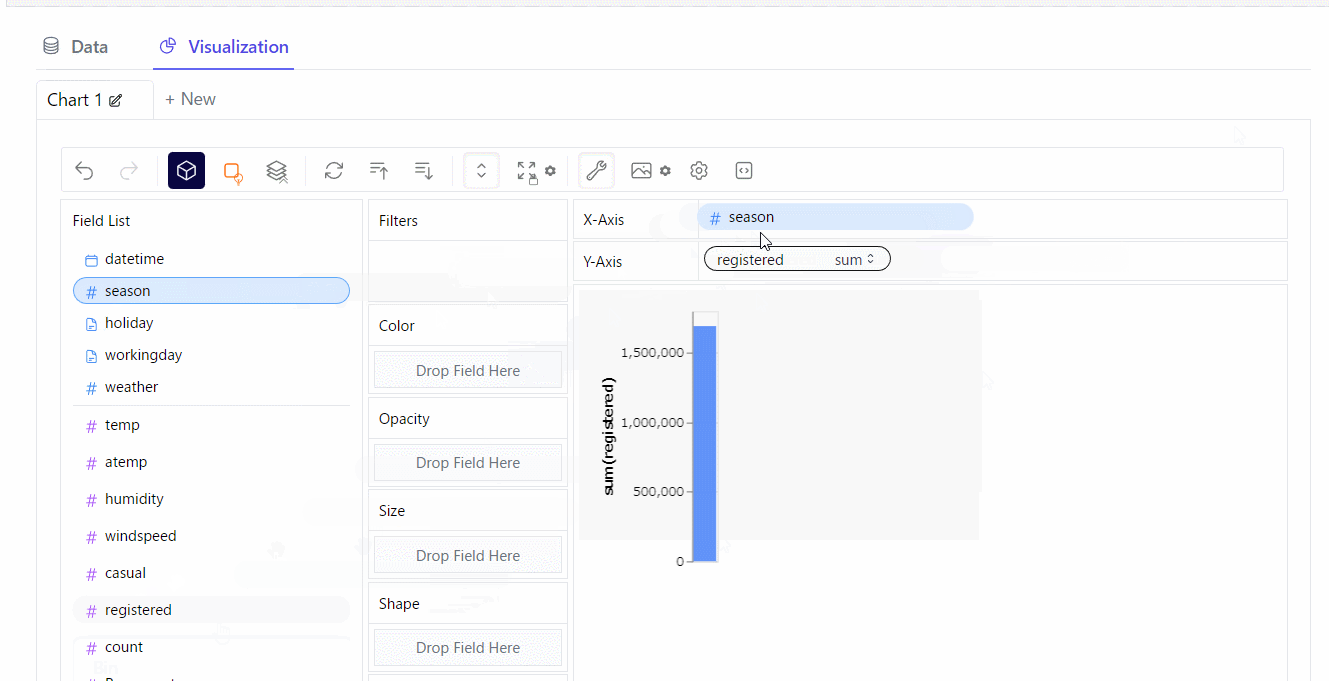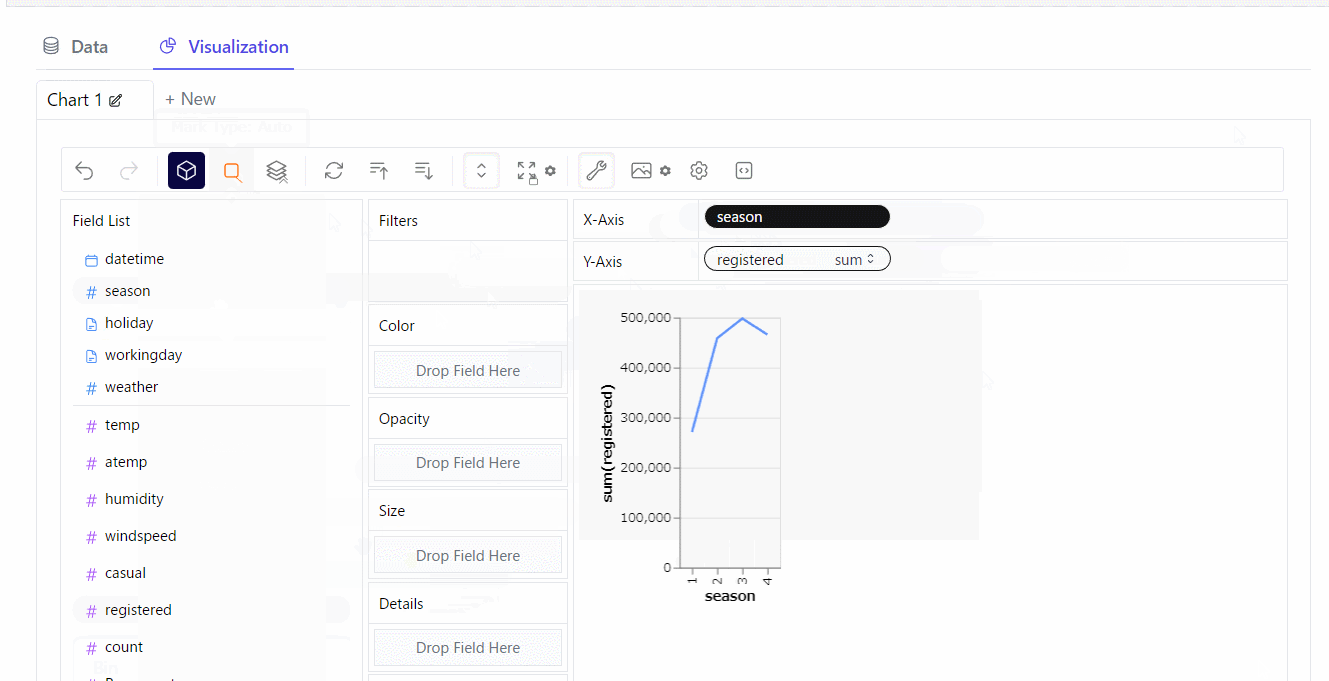
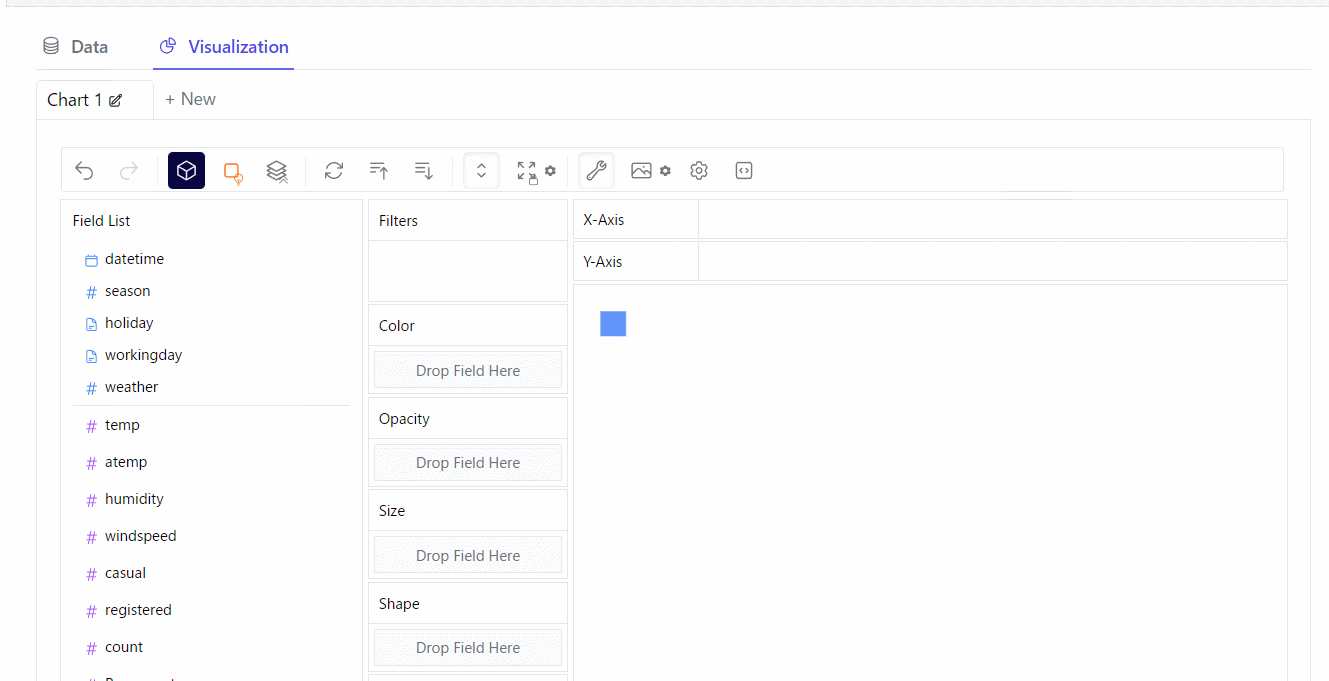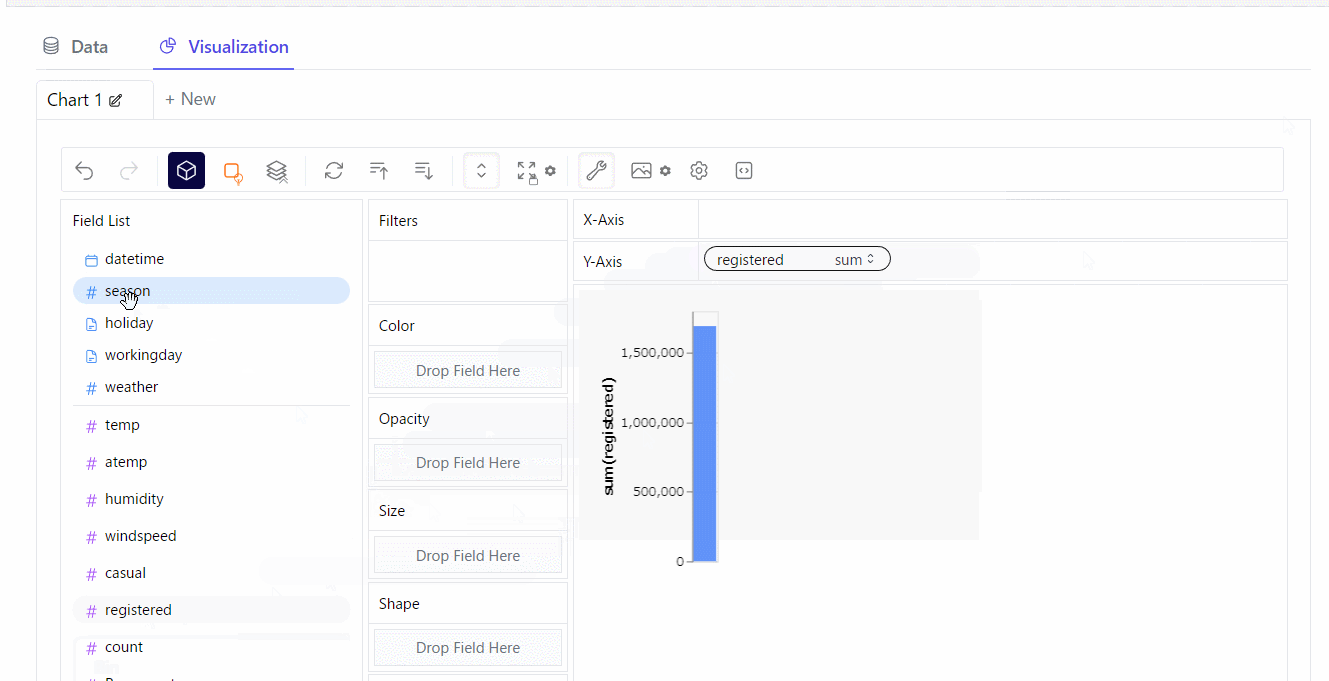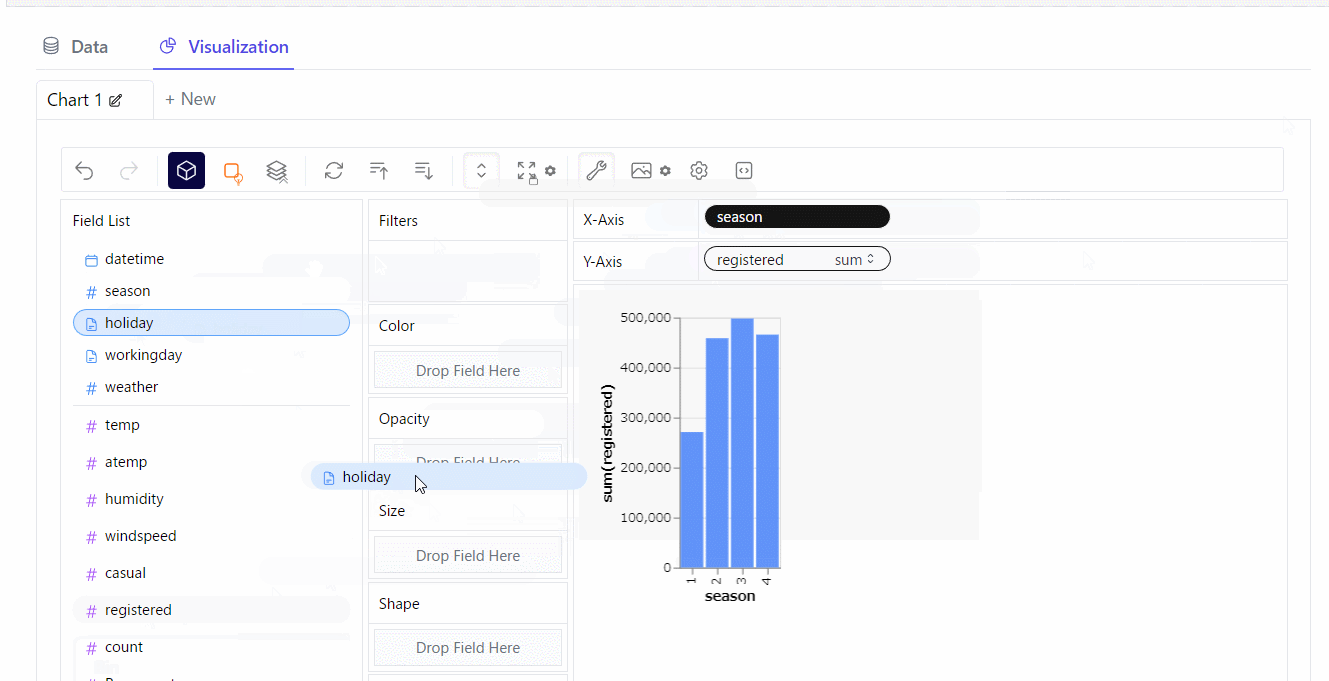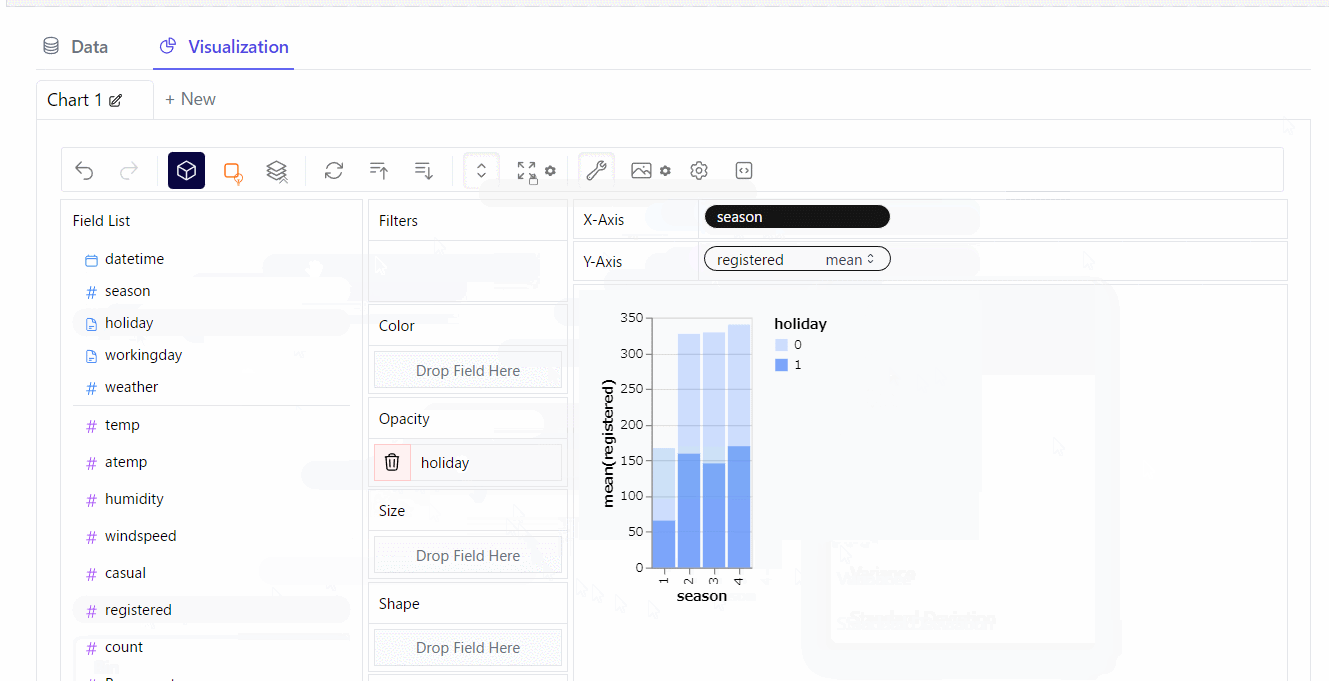
積み上げグラフを作ってみます。※クリックすると拡大します
まとめ
今回は、PyGWalker を Streamlit アプリケーションに埋め込む方法を説明しました。
ユーザはPythonコードを意識することなく、ノーコードで簡単な探索的データ分析 (EDA)を、Tableau風ダッシュボードで実施できます。
元のPythonファイル(pyファイル)のコメント部分を除くと、たったの12行です。
興味のある方は、試してみて下さい。