
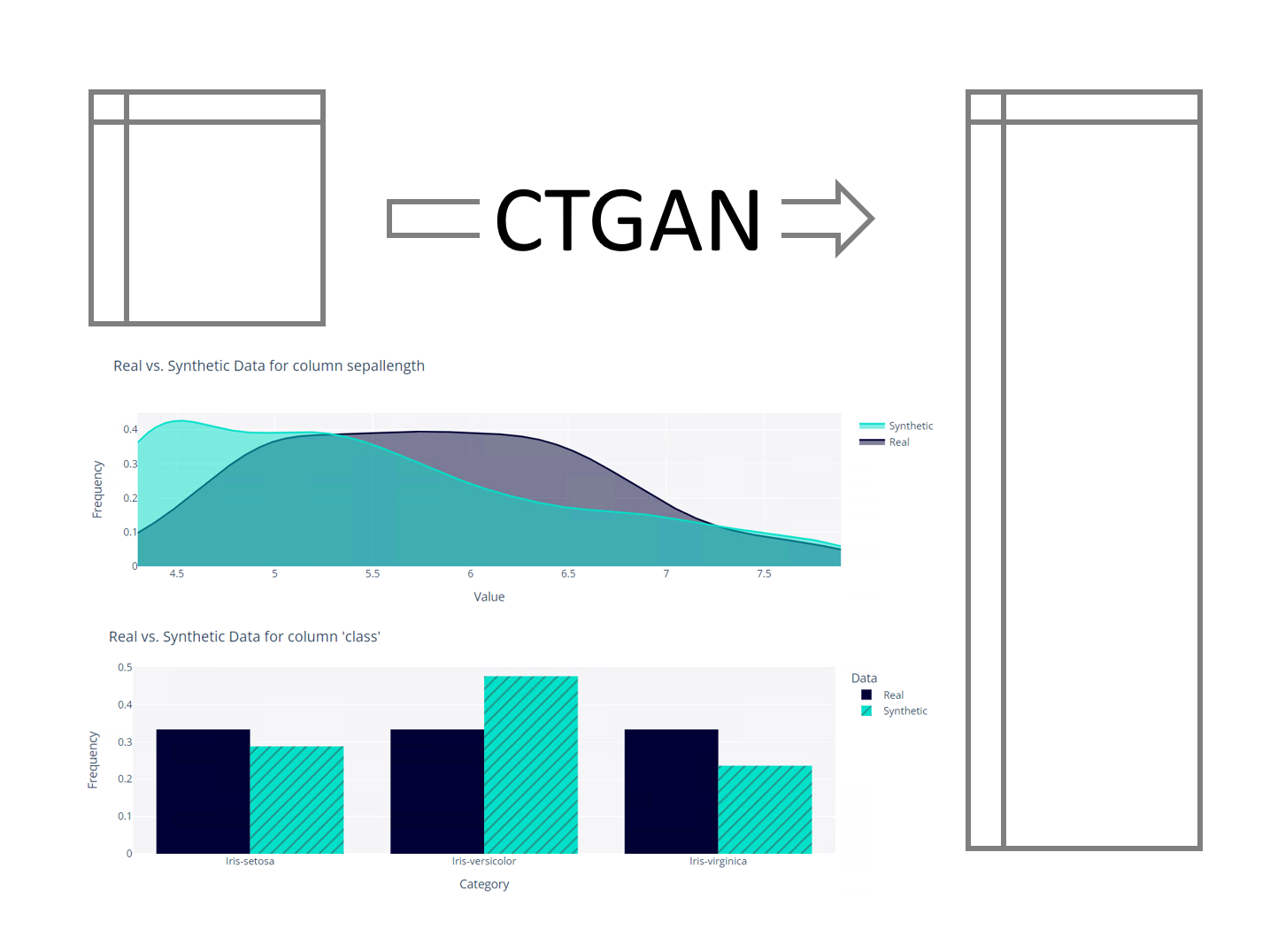
テーブルデータを生成するGANもあります。CTGAN(Conditional General Adversarial Networks)です。
あらかじめ準備されたデータをもとに、擬似的なテーブルデータを生成することができます。
CTGAN(Conditional General Adversarial Networks)で、手軽にテーブルデータを生成することができますが、無邪気に生成すると、ちょっと変なデータが生成されることがあります。
例えば、データセットの主キーです。
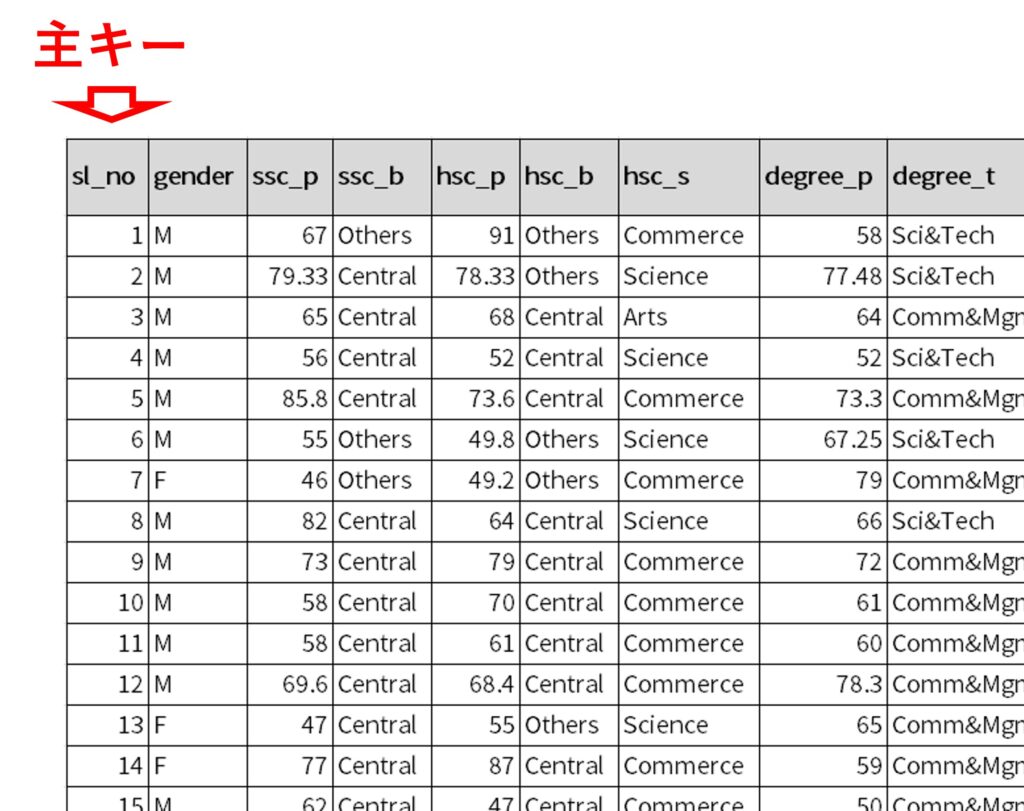
無邪気に生成すると、主キーが一意でないデータセットが生成される危険性があります。
前回、主キーを指定しテーブルデータ生成AI CTGANで、テーブルデータを生成する方法を説明しました。
他にも、生成するテーブルデータに守って欲しい制約やルールがあることでしょう。
そこで今回は、テーブルデータ生成AI CTGANに、カスタム制約を与えテーブルデータを生成する方法を説明します。
Contents [hide]
(前回と同じ)利用するデータセット
今回利用する データセットは、大学の学生の就職状況に関するデータ(Campus Recruitment)です。
以下からもダウンロードできます。
Placement_Data_Full_Class.csv
https://www.salesanalytics.co.jp/su1r
このデータセットは、学生の学業成績、科目、仕事の経験、専門分野など、学生の就職に影響を与える要因や、学生の就職を予測するモデルを構築するために使用されたりします。
以下の、変数sl_noを主キーとするデータセットです。
- sl_no: 学生番号 ※主キー
- gender: 学生の性別
- ssc_p: 義務教育10年目の試験の得点率
- ssc_b: 義務教育10年目の試験を実施する委員会
- hsc_p:義務教育12年目の試験の得点率
- hsc_b: 義務教育12年目の試験を実施する委員会
- hsc_s:義務教育12年目の試験の専攻
- degree_p: 工学学位の試験で得た得点の割合
- degree_t: 工学学位の専攻
- workex: 学生の職務経験の有無
- etest_p: 入学試験における学生の得点率
- specialisation: 学生の専門分野
- mba_p: MBA試験における学生の得点率
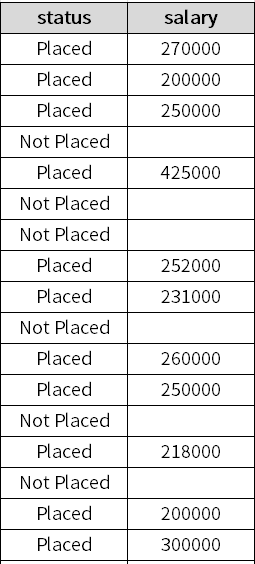
- status: 学生が就職したかどうか(Placed:内定した、Not Placed:内定しなかった)
- salary: 学生に提示された給与
このデータセットには、次の2つの制約もしくはルールがあります。
- sl_no(学生番号)は、レコードごとに異なり重複しない
- salary(提示された給与)は、statusがPlaced(内定)のときのみデータがある
前回、sl_no(学生番号)が重複しないように、テーブルデータ生成することを考えました。
今回はその続きで、sl_no(学生番号)が重複しないようにメタデータを変更した後に、カスタム制約を作り「salary(提示された給与)は、statusがPlaced(内定)のときのみデータがある」ようにします。
必要なモジュールの読み込み
必要なモジュールを読み込みます。
以下、コードです。
# 基本モジュール
import pandas as pd
import numpy as np
# SVD
from sdv.single_table import CTGANSynthesizer
from sdv.metadata import SingleTableMetadata
import warnings
warnings.simplefilter('ignore')
データセット読み込み
データセットを読み込みます。
以下、コードです。
dataset = 'Placement_Data_Full_Class.csv' real_data = pd.read_csv(dataset) print(real_data)
以下、実行結果です。
sl_no gender ssc_p ssc_b hsc_p hsc_b hsc_s degree_p \
0 1 M 67.00 Others 91.00 Others Commerce 58.00
1 2 M 79.33 Central 78.33 Others Science 77.48
2 3 M 65.00 Central 68.00 Central Arts 64.00
3 4 M 56.00 Central 52.00 Central Science 52.00
4 5 M 85.80 Central 73.60 Central Commerce 73.30
.. ... ... ... ... ... ... ... ...
210 211 M 80.60 Others 82.00 Others Commerce 77.60
211 212 M 58.00 Others 60.00 Others Science 72.00
212 213 M 67.00 Others 67.00 Others Commerce 73.00
213 214 F 74.00 Others 66.00 Others Commerce 58.00
214 215 M 62.00 Central 58.00 Others Science 53.00
degree_t workex etest_p specialisation mba_p status salary
0 Sci&Tech No 55.0 Mkt&HR 58.80 Placed 270000.0
1 Sci&Tech Yes 86.5 Mkt&Fin 66.28 Placed 200000.0
2 Comm&Mgmt No 75.0 Mkt&Fin 57.80 Placed 250000.0
3 Sci&Tech No 66.0 Mkt&HR 59.43 Not Placed NaN
4 Comm&Mgmt No 96.8 Mkt&Fin 55.50 Placed 425000.0
.. ... ... ... ... ... ... ...
210 Comm&Mgmt No 91.0 Mkt&Fin 74.49 Placed 400000.0
211 Sci&Tech No 74.0 Mkt&Fin 53.62 Placed 275000.0
212 Comm&Mgmt Yes 59.0 Mkt&Fin 69.72 Placed 295000.0
213 Comm&Mgmt No 70.0 Mkt&HR 60.23 Placed 204000.0
214 Comm&Mgmt No 89.0 Mkt&HR 60.22 Not Placed NaN
[215 rows x 15 columns]
レコード数は215で、変数の数は15です。
メタデータの設定
テーブルデータを生成するために、先程読み込んだデータセットからメタデータを取得します。
以下、コードです。
# データフレームからメタデータを自動抽出 metadata = SingleTableMetadata() metadata.detect_from_dataframe(real_data)
メタデータを見てみます。
以下、コードです。
metadata
以下、実行結果です。各変数の型が定義されています。
{
"METADATA_SPEC_VERSION": "SINGLE_TABLE_V1",
"columns": {
"sl_no": {
"sdtype": "numerical"
},
"gender": {
"sdtype": "categorical"
},
"ssc_p": {
"sdtype": "numerical"
},
"ssc_b": {
"sdtype": "categorical"
},
"hsc_p": {
"sdtype": "numerical"
},
"hsc_b": {
"sdtype": "categorical"
},
"hsc_s": {
"sdtype": "categorical"
},
"degree_p": {
"sdtype": "numerical"
},
"degree_t": {
"sdtype": "categorical"
},
"workex": {
"sdtype": "categorical"
},
"etest_p": {
"sdtype": "numerical"
},
"specialisation": {
"sdtype": "categorical"
},
"mba_p": {
"sdtype": "numerical"
},
"status": {
"sdtype": "categorical"
},
"salary": {
"sdtype": "numerical"
}
}
}
メタデータを修正し主キーを設定します。
主キーに設定する変数は、例えば「id」型である必要があるため、先ず型変換を行い、次に主キー設定をします。
以下、コードです。
# 変数の型の変更
metadata.update_column(
column_name='sl_no',
sdtype='id')
# 主Key設定
metadata.set_primary_key(column_name="sl_no")
メターデータを確認してみます。
以下、コードです。
metadata
以下、実行結果です。
{
"primary_key": "sl_no",
"METADATA_SPEC_VERSION": "SINGLE_TABLE_V1",
"columns": {
"sl_no": {
"sdtype": "id"
},
"gender": {
"sdtype": "categorical"
},
"ssc_p": {
"sdtype": "numerical"
},
"ssc_b": {
"sdtype": "categorical"
},
"hsc_p": {
"sdtype": "numerical"
},
"hsc_b": {
"sdtype": "categorical"
},
"hsc_s": {
"sdtype": "categorical"
},
"degree_p": {
"sdtype": "numerical"
},
"degree_t": {
"sdtype": "categorical"
},
"workex": {
"sdtype": "categorical"
},
"etest_p": {
"sdtype": "numerical"
},
"specialisation": {
"sdtype": "categorical"
},
"mba_p": {
"sdtype": "numerical"
},
"status": {
"sdtype": "categorical"
},
"salary": {
"sdtype": "numerical"
}
}
}
primary_keyが主キーを表します。sl_noになっているのが分かるかと思います。
sl_noの型(sdtype)がidになっているのも分かるかと思います。
この状態で、テーブルデータを生成します。
データ生成その1(カスタム制約なし)
sl_noを主キーに設定したメタデータを使い、テーブルデータを生成します。
以下、コードです。
# インスタンス生成 ctgan = CTGANSynthesizer(metadata,epochs=10) # 学習 ctgan.fit(real_data) # データ生成 synthetic_data = ctgan.sample(20000) # 生成したデータを確認 print(synthetic_data)
以下、実行結果です。
sl_no gender ssc_p ssc_b hsc_p hsc_b hsc_s degree_p \
0 0 M 63.32 Central 51.18 Others Arts 78.93
1 1 F 65.35 Others 66.10 Central Science 67.23
2 2 F 40.89 Central 47.76 Central Science 67.20
3 3 F 40.89 Others 60.37 Others Commerce 89.05
4 4 F 56.19 Central 39.60 Central Commerce 63.17
... ... ... ... ... ... ... ... ...
19995 19995 M 64.25 Central 43.54 Others Arts 77.72
19996 19996 F 76.01 Central 70.35 Others Commerce 71.96
19997 19997 F 72.59 Central 97.70 Others Arts 67.86
19998 19998 M 51.43 Others 56.94 Central Science 59.97
19999 19999 M 56.75 Central 52.63 Central Commerce 50.00
degree_t workex etest_p specialisation mba_p status salary
0 Sci&Tech Yes 65.37 Mkt&Fin 65.79 Placed 282434.0
1 Sci&Tech Yes 84.75 Mkt&HR 57.03 Placed 374237.0
2 Sci&Tech No 58.12 Mkt&Fin 51.21 Placed NaN
3 Comm&Mgmt Yes 82.79 Mkt&Fin 52.39 Placed 200000.0
4 Sci&Tech No 71.98 Mkt&HR 53.52 Not Placed NaN
... ... ... ... ... ... ... ...
19995 Sci&Tech Yes 92.09 Mkt&Fin 53.48 Placed NaN
19996 Comm&Mgmt Yes 82.98 Mkt&HR 55.71 Not Placed NaN
19997 Sci&Tech Yes 59.22 Mkt&HR 62.57 Placed 457765.0
19998 Sci&Tech Yes 75.93 Mkt&HR 51.21 Placed 293694.0
19999 Others No 50.00 Mkt&Fin 51.21 Placed 394105.0
[20000 rows x 15 columns]
生成したテーブルデータのsl_noが重複していいないかどうかを確認します。
以下、コードです。
synthetic_data['sl_no'].duplicated().sum()
以下、実行結果です。
0
0です。sl_noが重複していません。
ここで、もう1つの制約というかルールであった「salary(提示された給与)は、statusがPlaced(内定)のときのみデータがある」が保持されているかどうか見てみます。
先ず、statusとsalaryの変数だけ抜き出して見てみます。
以下、コードです。
print(synthetic_data.loc[:,['status','salary']])
以下、実行結果です。
status salary 0 Placed 282434.0 1 Placed 374237.0 2 Placed NaN 3 Placed 200000.0 4 Not Placed NaN ... ... ... 19995 Placed NaN 19996 Not Placed NaN 19997 Placed 457765.0 19998 Placed 293694.0 19999 Placed 394105.0 [20000 rows x 2 columns]
status変数がPlaced(内定)なのにsalary変数が欠測しているなど、上手く行っていない様子が分かります。
Placed(内定)かNot Placedどうかで、salary変数の基本統計量がどうなっているか見てみます。
以下、コードです。
print(synthetic_data.loc[:,['status','salary']].groupby('status').describe())
以下、実行結果です。
salary \
count mean std min 25%
status
Not Placed 6134.0 397787.475383 158847.556333 200000.0 296821.75
Placed 7679.0 399903.842427 158153.818051 200000.0 297113.00
50% 75% max
status
Not Placed 363193.0 452395.5 940000.0
Placed 368274.0 457405.0 940000.0
Not Placed(内定がでていない)なのにsalary変数に値のある(給与が提示された)レコードがあることが分かります。
要するに、「salary(提示された給与)は、statusがPlaced(内定)のときのみデータがある」が保持されていません。
制約を課すための関数
制約が課すために必要な3つの関数
ここで、以下の3つの関数を定義します。
- 妥当性チェック(Validity Check)関数
- 変換(transform)関数
- 逆変換(reverse transform)関数
妥当性チェック(Validity Check)関数は、制約・ルール通りになっていかどうかをチェックするための関数です。
変換(transform)関数は、学習で利用するテーブルデータを、学習しやすい形に変換する関数です。この関数で変換されたデータセットは、制約・ルールから逸脱したものになります。
逆変換(reverse transform)関数は、変換(transform)関数の逆変換で、制約・ルール通りのデータセットに戻すための関数です。
https://docs.sdv.dev/sdv/reference/constraint-logic/custom-logic
流れを簡単に説明します。
- 学習で利用するリアルデータ(real data)に対し、妥当性チェック(Validity Check)を実施(通常は問題なく通過)
- チェック済みのリアルデータ(valid real data)を学習で利用しやすいデータセットに変換(transform)
- 変換済みのリアルデータ(transformed real data)を学習し生成モデルを構築し、その生成モデル(SDVモデル)で新たにテーブルデータを生成、この生成されたデータセットは変換処理の施された状態になっている
- 変換処理の施された状態の生成されたデータセット(transformed synthetic data)に対し、逆変換し制約・ルール通りのデータセットに戻す(reverse transform)
- 制約・ルール通りのデータセットに戻されたデータセット(synthetic data)に対し、妥当性チェック(Validity Check)を実施
- 妥当性チェック(Validity Check)の結果、問題なければ生成されたテーブルデータ(valid synthetic data)として採用
変換(transform)関数が、学習しやすい形に変換するとは、どういうことでしょうか?
簡単に言うと、制約・ルールがない状態のデータセットに変換する、ということです。
今回の例の場合、「salary(提示された給与)は、statusがPlaced(内定)のときのみデータがある」という制約・ルールを破り、「salary(提示された給与)は、statusに関係なくデータがある」という状態にします。
処理的には、salaryの欠測値補完処理です。
この変換(transform)関数に対する、逆変換(reverse transform)関数はどうなるでしょうか?
「salary(提示された給与)は、statusがPlaced(内定)のときのみデータがある」という制約・ルールを適用し、「statusがPlaced(内定)でない場合、salaryを欠測値にする」という処理をする関数になります。
妥当性チェック(Validity Check)関数
妥当性チェック(Validity Check)関数を作ります。
以下、コードです。
# 妥当性チェック(Validity Check)関数
def is_valid(column_names, data):
status = column_names[0]
salary = column_names[1]
rule1 = (data[status] == 'Not Placed') & (data[salary].isnull())
rule2 = (data[status] == 'Placed') & (data[salary].notnull())
return (rule1) | (rule2)
以下、この関数の簡単な説明です。
このPythonコードは、入力されたデータの妥当性をチェックする関数 is_valid を定義しています。関数 is_valid の入力は次の2つです:
column_names: これは列名を含むリストで、statusとsalaryの2つの列を意味します。statusは値として ‘Placed’ または ‘Not Placed’ を持つことを期待し、salaryは何らかの数値(おそらく給与情報)を持つことを期待します。data: これは入力データを含む pandas DataFrame を指します。statusとsalaryの両方の列を持つことを期待します。
関数の内部では、次の2つのルールを適用しています:
rule1:statusが ‘Not Placed’ であり、salaryが NaN(すなわち、欠損値)である場合、データは有効と見なします。rule2:statusが ‘Placed’ であり、salaryが NaNでない(すなわち、何らかの値を持つ)場合、データは有効と見なします。
関数は、各行がこれらのルールのいずれかを満たす場合に True を返します。これは、ビット単位の OR 演算子 | を使用して達成されます。つまり、ルール1またはルール2のいずれかが True の場合、その行は True と評価されます。
全体として、この関数は、求人のステータスと給与情報が一貫性を持つことを確認するためのものです。すなわち、個々が ‘Not Placed’ のステータスを持つ場合は給与情報がなく、’Placed’ のステータスを持つ場合は給与情報が存在することを確認しています。
変換(transform)関数
変換(transform)関数を作ります。
以下、コードです。
# 変換(transform)関数 ※欠測値補完処理
def transform(column_names, data):
status = column_names[0]
salary = column_names[1]
trans_data = data.copy()
typical_value = trans_data[salary].median()
trans_data[salary] = trans_data[salary].mask(trans_data[status] == 'Not Placed', typical_value)
return trans_data
以下、この関数の簡単な説明です。
このPythonコードは、入力データを変換する transform 関数を定義しています。具体的には、この関数は ‘Not Placed’ とマークされたエントリの salary 列について欠損値を補完しています。関数 transform の入力は以下の2つです:
column_names: これは列名を含むリストで、statusとsalaryの2つの列を意味します。statusは値として ‘Placed’ または ‘Not Placed’ を持つことを期待し、salaryは何らかの数値(おそらく給与情報)を持つことを期待します。data: これは入力データを含む pandas DataFrame を指します。statusとsalaryの両方の列を持つことを期待します。
関数の内部で次の操作が行われています:
trans_data = data.copy(): 元のデータセットdataのコピーを作成します。これは、元のデータを直接変更せずに変換処理を行うためです。typical_value = trans_data[salary].median():salary列の中央値を計算し、これをtypical_valueに格納します。中央値は、データの中心傾向を示すために使用されます。trans_data[salary] = trans_data[salary].mask(trans_data[status] == 'Not Placed', typical_value):mask関数を使って、status列が ‘Not Placed’ のときにsalary列の値をtypical_value(salary列の中央値)に置き換えます。
関数は、変換後のデータセット trans_data を返します。
逆変換(reverse transform)関数
逆変換(reverse transform)関数を作ります。
以下、コードです。
# 逆変換(reverse transform)関数 ※欠測値生成処理
def reverse_transform(column_names, data):
status = column_names[0]
salary = column_names[1]
rev_data = data.copy()
rev_data[salary] = rev_data[salary].mask(rev_data[status] == 'Not Placed', np.nan)
return rev_data
以下、この関数の簡単な説明です。
このPythonコードは、入力データを逆変換する reverse_transform 関数を定義しています。具体的には、この関数は ‘Not Placed’ とマークされたエントリの salary 列について、欠損値(NaN)を生成します。関数 reverse_transform の入力は以下の2つです:
column_names: これは列名を含むリストで、statusとsalaryの2つの列を意味します。statusは値として ‘Placed’ または ‘Not Placed’ を持つことを期待し、salaryは何らかの数値(おそらく給与情報)を持つことを期待します。data: これは入力データを含む pandas DataFrame を指します。statusとsalaryの両方の列を持つことを期待します。
関数の内部で次の操作が行われています:
rev_data = data.copy(): 元のデータセットdataのコピーを作成します。これは、元のデータを直接変更せずに逆変換処理を行うためです。rev_data[salary] = rev_data[salary].mask(rev_data[status] == 'Not Placed', np.nan):mask関数を使って、status列が ‘Not Placed’ のときにsalary列の値をnp.nan(欠損値)に置き換えます。
関数は、逆変換後のデータセット rev_data を返します。
この関数全体の目的は、ステータスが ‘Not Placed’ のエントリに対する salary 列の値を欠損値(NaN)に戻すことです。この処理は、欠損値の補完を行った後の結果を元に戻す際などに利用されます。
3つの関数を試しに使ってみよう
学習で利用するリアルデータ(real data)に対し、妥当性チェック(Validity Check)を実施します。
以下、コードです。
validity_check=is_valid(["status","salary"],real_data) validity_check
以下、実行結果です。
0 True
1 True
2 True
3 True
4 True
...
210 True
211 True
212 True
213 True
214 True
Length: 215, dtype: bool
Trueの数を合計してみます。
以下、コードです。
validity_check.sum()
以下、実行結果です。
215
レコード数が215行なので、リアルデータ(real data)のレコードが全て妥当性チェック(Validity Check)を通過していることが分かります。
次に、このリアルデータ(valid real data)を学習で利用しやすいデータセットに変換(transform)してみます。
以下、コードです。
transformed_data=transform(["status","salary"],real_data) print(transformed_data.loc[:,["status","salary"]])
以下、実行結果です。
status salary 0 Placed 270000.0 1 Placed 200000.0 2 Placed 250000.0 3 Not Placed 265000.0 4 Placed 425000.0 .. ... ... 210 Placed 400000.0 211 Placed 275000.0 212 Placed 295000.0 213 Placed 204000.0 214 Not Placed 265000.0 [215 rows x 2 columns]
この変換済みのリアルデータ(transformed real data)に対し、妥当性チェック(Validity Check)を実施します。
以下、コードです。
is_valid(["status","salary"],transformed_data)
以下、実行結果です。
0 True
1 True
2 True
3 False
4 True
...
210 True
211 True
212 True
213 True
214 False
Length: 215, dtype: bool
Falseのレコードがあることより、妥当性チェック(Validity Check)を通過していないレコードがあることが分かります。
この変換済みのリアルデータ(transformed real data)に対し、逆変換(reverse transform)します。
以下、コードです。
inv_transformed_data=reverse_transform(["status","salary"],transformed_data) print(inv_transformed_data.loc[:,["status","salary"]])
以下、実行結果です。
status salary 0 Placed 270000.0 1 Placed 200000.0 2 Placed 250000.0 3 Not Placed NaN 4 Placed 425000.0 .. ... ... 210 Placed 400000.0 211 Placed 275000.0 212 Placed 295000.0 213 Placed 204000.0 214 Not Placed NaN [215 rows x 2 columns]
この逆変換(reverse transform)したデータセットに対し、妥当性チェック(Validity Check)を実施します。
以下、コードです。
is_valid(["status","salary"],inv_transformed_data)
以下、実行結果です。
0 True
1 True
2 True
3 True
4 True
...
210 True
211 True
212 True
213 True
214 True
Length: 215, dtype: bool
Trueの数を合計してみます。
以下、コードです。
is_valid(["status","salary"],inv_transformed_data).sum()
以下、実行結果です。
215
レコード数が215行なので、リアルデータ(real data)のレコードが全て妥当性チェック(Validity Check)を通過していることが分かります。
データ生成その2(カスタム制約あり・手動)
カスタム制約を施したテーブルデータ生成を行う流れを、再掲します。
- 学習で利用するリアルデータ(real data)に対し、妥当性チェック(Validity Check)を実施(通常は問題なく通過)
- チェック済みのリアルデータ(valid real data)を学習で利用しやすいデータセットに変換(transform)
- 変換済みのリアルデータ(transformed real data)を学習し生成モデルを構築し、その生成モデル(SDVモデル)で新たにテーブルデータを生成、この生成されたデータセットは変換処理の施された状態になっている
- 変換処理の施された状態の生成されたデータセット(transformed synthetic data)に対し、逆変換し制約・ルール通りのデータセットに戻す(reverse transform)
- 制約・ルール通りのデータセットに戻されたデータセット(synthetic data)に対し、妥当性チェック(Validity Check)を実施
- 妥当性チェック(Validity Check)の結果、問題なければ生成されたテーブルデータ(valid synthetic data)として採用
この流れに沿って、テーブルデータを生成します。
以下、コードです。
# 妥当性チェック ※学習データが制約通りかどうか、Trueの数をカウント
print('valid real data',is_valid(["status","salary"],real_data).sum())
# 変換(欠測値補完処理)
trans_data=transform(["status","salary"],real_data)
# インスタンス生成
ctgan = CTGANSynthesizer(metadata,epochs=10)
# 学習
ctgan.fit(trans_data)
# データ生成
synthetic_trans_data = ctgan.sample(20000)
# 逆変換(欠測値生成処理)
synthetic_data=reverse_transform(["status","salary"],synthetic_trans_data)
# 妥当性チェック ※生成データが制約通りかどうか、Trueの数をカウント
print('valid synthetic data',is_valid(["status","salary"],synthetic_data).sum())
# 生成したデータを確認
print(synthetic_data)
以下、実行結果です。
valid real data 215
valid synthetic data 20000
sl_no gender ssc_p ssc_b hsc_p hsc_b hsc_s degree_p \
0 0 M 59.02 Central 79.69 Central Arts 89.74
1 1 F 89.40 Central 71.15 Central Arts 74.43
2 2 F 56.92 Others 69.97 Central Science 75.76
3 3 M 40.96 Others 73.26 Others Commerce 75.73
4 4 M 65.05 Central 58.23 Central Commerce 77.28
... ... ... ... ... ... ... ... ...
19995 19995 M 63.13 Central 67.74 Others Commerce 61.32
19996 19996 F 52.79 Central 71.52 Central Arts 70.94
19997 19997 F 79.25 Others 73.67 Central Science 78.36
19998 19998 F 78.94 Others 80.96 Central Arts 50.00
19999 19999 M 49.22 Others 97.70 Central Commerce 88.95
degree_t workex etest_p specialisation mba_p status salary
0 Others Yes 69.31 Mkt&Fin 72.23 Placed 245489.0
1 Sci&Tech Yes 82.61 Mkt&HR 73.56 Not Placed NaN
2 Sci&Tech No 76.93 Mkt&Fin 67.48 Placed 200000.0
3 Comm&Mgmt Yes 80.98 Mkt&Fin 75.62 Placed 200000.0
4 Sci&Tech Yes 71.18 Mkt&HR 61.24 Placed 206572.0
... ... ... ... ... ... ... ...
19995 Sci&Tech Yes 69.10 Mkt&HR 59.45 Placed 200000.0
19996 Sci&Tech No 58.02 Mkt&HR 55.98 Not Placed NaN
19997 Comm&Mgmt No 83.73 Mkt&Fin 62.52 Placed 218500.0
19998 Sci&Tech Yes 83.85 Mkt&HR 77.11 Not Placed NaN
19999 Sci&Tech Yes 50.00 Mkt&HR 61.14 Placed 478682.0
[20000 rows x 15 columns]
生成したテーブルデータのsl_noが重複していいないかどうかを確認します。
以下、コードです。
# 'sl_no'の重複確認 synthetic_data['sl_no'].duplicated().sum()
以下、実行結果です。
0
0です。sl_noが重複していません。
ここで、もう1つの制約というかルールであった「salary(提示された給与)は、statusがPlaced(内定)のときのみデータがある」が保持されているかどうか見てみます。
Placed(内定)かNot Placedどうかで、salary変数の基本統計量が計算します。
以下、コードです。
# 'status'と'salary'の関係性の確認
print(synthetic_data.loc[:,['status','salary']].groupby('status').describe())
以下、実行結果です。
salary \
count mean std min 25%
status
Not Placed 0.0 NaN NaN NaN NaN
Placed 11885.0 243674.863105 94363.086493 200000.0 200000.0
50% 75% max
status
Not Placed NaN NaN NaN
Placed 204420.0 246276.0 940000.0
Not Placed(内定がでていない)場合にはsalary変数に値はないことが分かります。
「salary(提示された給与)は、statusがPlaced(内定)のときのみデータがある」という制約・ルールが保持されていそうです。
制約Pythonファイル(pyファイル)
制約クラスの定義
通常は、先程定義した3つの関数を含んだ制約クラス(create_custom_constraint_class)を作ります。
以下、コードです。
# 制約クラス
from sdv.constraints import create_custom_constraint_class
constraint1 = create_custom_constraint_class(
is_valid_fn=is_valid,
transform_fn=transform,
reverse_transform_fn=reverse_transform
)
では、制約Pythonファイル(pyファイル)を作ろう!
3つの関数を定義した後に、制約クラスを定義するpyファイルを作り、そのpyファイルを読み込むことで、テーブルデータを生成します。
ということで、制約Pythonファイル(pyファイル)を作りましょう。
以下、コードです。
#
# custom_constraint.py
#
import pandas as pd
from sdv.constraints import create_custom_constraint_class
# 妥当性チェック(Validity Check)関数
def is_valid(column_names, data):
status = column_names[0]
salary = column_names[1]
rule1 = (data[status] == 'Not Placed') & (data[salary].isnull())
rule2 = (data[status] == 'Placed') & (data[salary].notnull())
return (rule1) | (rule2)
# 変換(transform)関数 ※欠測値補完処理
def transform(column_names, data):
status = column_names[0]
salary = column_names[1]
trans_data = data.copy()
typical_value = trans_data[salary].median()
trans_data[salary] = trans_data[salary].mask(trans_data[status] == 'Not Placed', typical_value)
return trans_data
# 逆変換(reverse transform)関数 ※欠測値生成処理
def reverse_transform(column_names, data):
status = column_names[0]
salary = column_names[1]
rev_data = data.copy()
rev_data[salary] = rev_data[salary].mask(rev_data[status] == 'Not Placed', np.nan)
return rev_data
# 制約クラス
constraint1 = create_custom_constraint_class(
is_valid_fn=is_valid,
transform_fn=transform,
reverse_transform_fn=reverse_transform
)
これは、custom_constraint.pyという名前で保存していると想定しています。
データ生成その3(カスタム制約あり・通常)
制約Pythonファイル(custom_constraint.py)を読み込み、テーブルデータを生成します。こちらの方が通常のやり方です。
以下、コードです。
# インスタンス生成
ctgan = CTGANSynthesizer(metadata,epochs=10)
# ファイルから制約ルールの読み込み
ctgan.load_custom_constraint_classes(
filepath='custom_constraint.py',
class_names=['constraint1']
)
# 追加する制約の設定
custom_constraint = {
'constraint_class': 'constraint1',
'constraint_parameters': {
'column_names': ["status","salary"],
}
}
# インスタンスへ制約を追加
ctgan.add_constraints([custom_constraint])
# 学習
ctgan.fit(real_data)
# データ生成
synthetic_data = ctgan.sample(20000)
# 生成したデータを確認
print(synthetic_data)
以下、実行結果です。
sl_no gender ssc_p ssc_b hsc_p hsc_b hsc_s degree_p \
0 0 M 51.34 Central 70.34 Others Arts 83.88
1 1 F 77.12 Central 60.58 Central Science 83.71
2 3 M 50.61 Others 55.21 Others Commerce 50.82
3 4 F 70.58 Central 52.28 Central Commerce 87.64
4 6 M 62.73 Others 47.94 Others Arts 78.64
... ... ... ... ... ... ... ... ...
19995 38390 F 40.89 Central 62.01 Central Commerce 76.76
19996 38394 M 50.21 Others 53.59 Others Arts 56.31
19997 38398 F 42.31 Central 64.25 Others Science 57.38
19998 38400 F 41.03 Others 48.03 Central Science 75.45
19999 38401 F 69.76 Central 85.86 Central Science 76.44
degree_t workex etest_p specialisation mba_p status salary
0 Sci&Tech No 66.49 Mkt&Fin 71.98 Placed 297500.0
1 Sci&Tech Yes 98.00 Mkt&HR 67.44 Placed 297221.0
2 Comm&Mgmt Yes 66.26 Mkt&Fin 59.69 Placed 339997.0
3 Sci&Tech No 55.36 Mkt&HR 62.44 Not Placed NaN
4 Sci&Tech No 57.68 Mkt&Fin 63.36 Placed 200000.0
... ... ... ... ... ... ... ...
19995 Comm&Mgmt Yes 68.44 Mkt&Fin 53.85 Not Placed NaN
19996 Others Yes 73.21 Mkt&HR 70.46 Placed 212362.0
19997 Comm&Mgmt No 83.55 Mkt&HR 68.74 Placed 488986.0
19998 Others Yes 68.47 Mkt&HR 68.74 Not Placed NaN
19999 Comm&Mgmt Yes 75.74 Mkt&Fin 54.92 Not Placed NaN
[20000 rows x 15 columns]
生成したテーブルデータのsl_noが重複していいないかどうかを確認します。
以下、コードです。
# 'sl_no'の重複確認 synthetic_data['sl_no'].duplicated().sum()
以下、実行結果です。
0
0です。sl_noが重複していません。
ここで、もう1つの制約というかルールであった「salary(提示された給与)は、statusがPlaced(内定)のときのみデータがある」が保持されているかどうか見てみます。
Placed(内定)かNot Placedどうかで、salary変数の基本統計量が計算します。
以下、コードです。
# 'status'と'salary'の関係性の確認
print(synthetic_data.loc[:,['status','salary']].groupby('status').describe())
以下、実行結果です。
salary \
count mean std min 25%
status
Not Placed 0.0 NaN NaN NaN NaN
Placed 14641.0 295535.630968 110861.541471 200000.0 210209.0
50% 75% max
status
Not Placed NaN NaN NaN
Placed 272783.0 332899.0 940000.0
Not Placed(内定がでていない)場合にはsalary変数に値はないことが分かります。
「salary(提示された給与)は、statusがPlaced(内定)のときのみデータがある」という制約・ルールが保持されていそうです。
まとめ
今回は、テーブルデータ生成AI CTGANに、カスタム制約を与えテーブルデータを生成する方法を説明しました。
CTGAN(Conditional General Adversarial Networks)で、手軽にテーブルデータを生成することができますが、無邪気に生成すると、ちょっと変なデータが生成されることがあります。
カスタム制約を設定する方法が分かれば、ある程度対応ができますが、もう少しライトな制約・ルールの与え方もあります。
次回は、ライトな制約・ルールの与え方を説明します。