

前回は、RStudioでデータ分析を進めていくための準備として、RStudioでプロジェクトを構築する方法、データの読み込みなどについてご説明いたしました。
データを読み込んだら、次にするのはデータ分析です。
多くのデータ分析系のプロジェクトでは、いきなり高度な分析に入るわけではありません。簡単な集計レベルの分析から始めることが多いでしょう。
今回は、RStudioで1変量の特徴(平均値・標準偏差など)を捉えるためのデータ分析の方法についてご説明いたします。
サンプルデータ
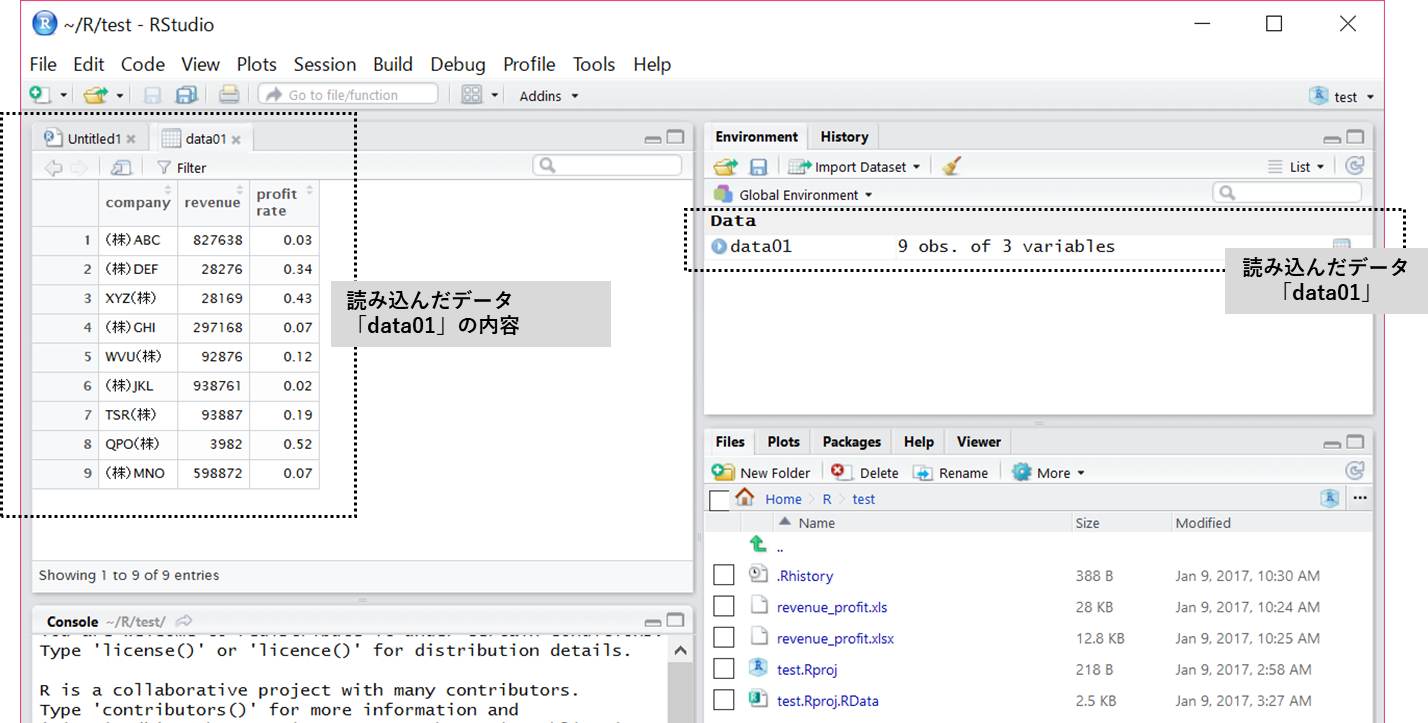
サンプルデータとして前回読み込んだデータセット「data01」の「revenue」(2列目のデータ)と「profit rate」(3列目のデータ)を使います。
まだデータセット「data01」を読み込んでいない方は、前回の記事を参考にRStudioにデータを読み込んで頂ければと思います。
データセット「data01」のダウンロードは、以下からお願いします。
↓↓↓
データダウンロード
特定のデータの抽出
先ずデータセット「data01」の列や行、セルのデータの抽出方法を説明します。
例として、以下の3つのデータへのアクセス方法について説明します。
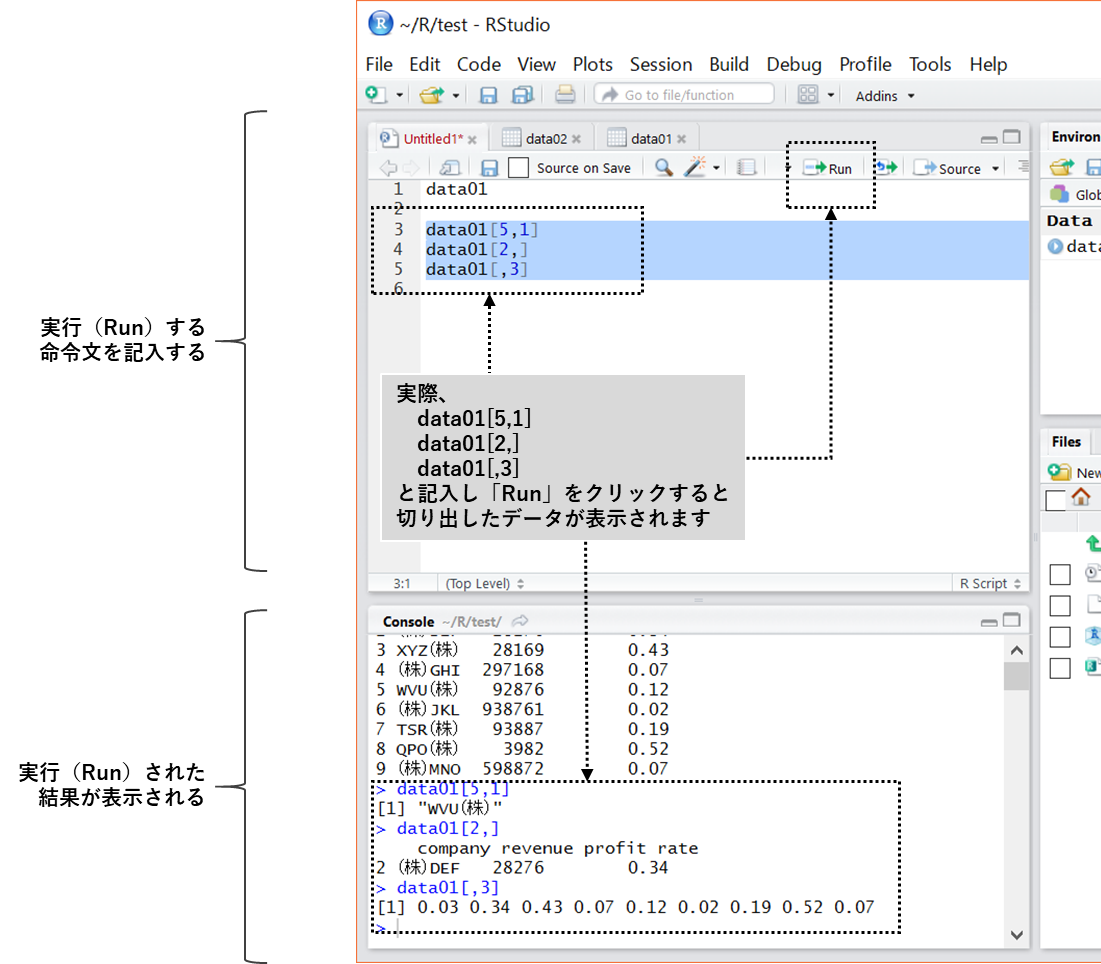
- 「data01」の5行目の1列目のセルのデータを抽出 → data01[5,1]
- 「data01」の2行目のすべてのデータを抽出 → data01[2,]
- 「data01」の3列目のすべてのデータを抽出 → data01[,3]
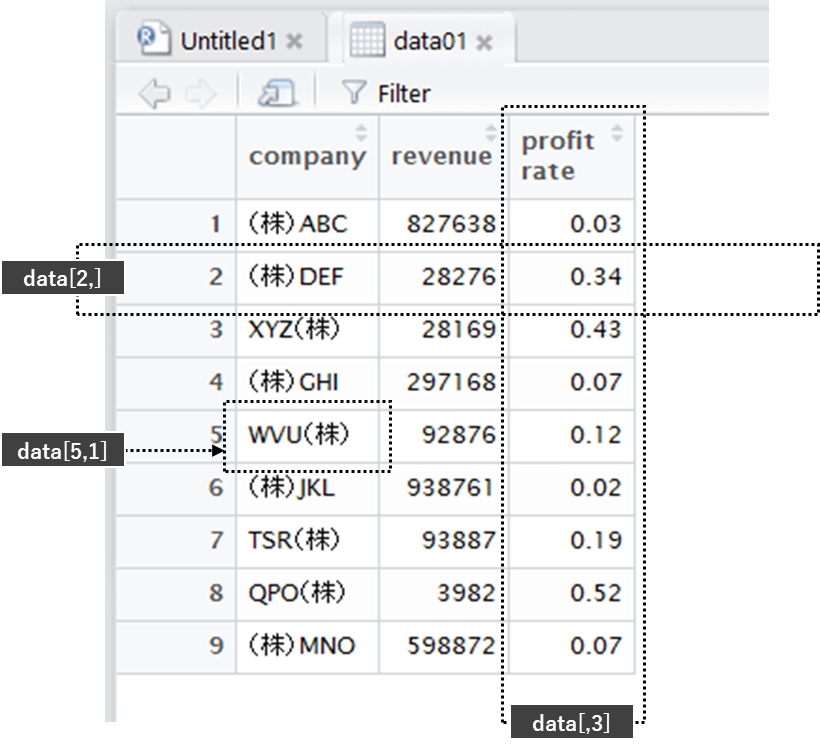
data01[行の指定,列の指定]となります。
試しに、データにアクセスできているか確認してみましょう。
今回実施する内容
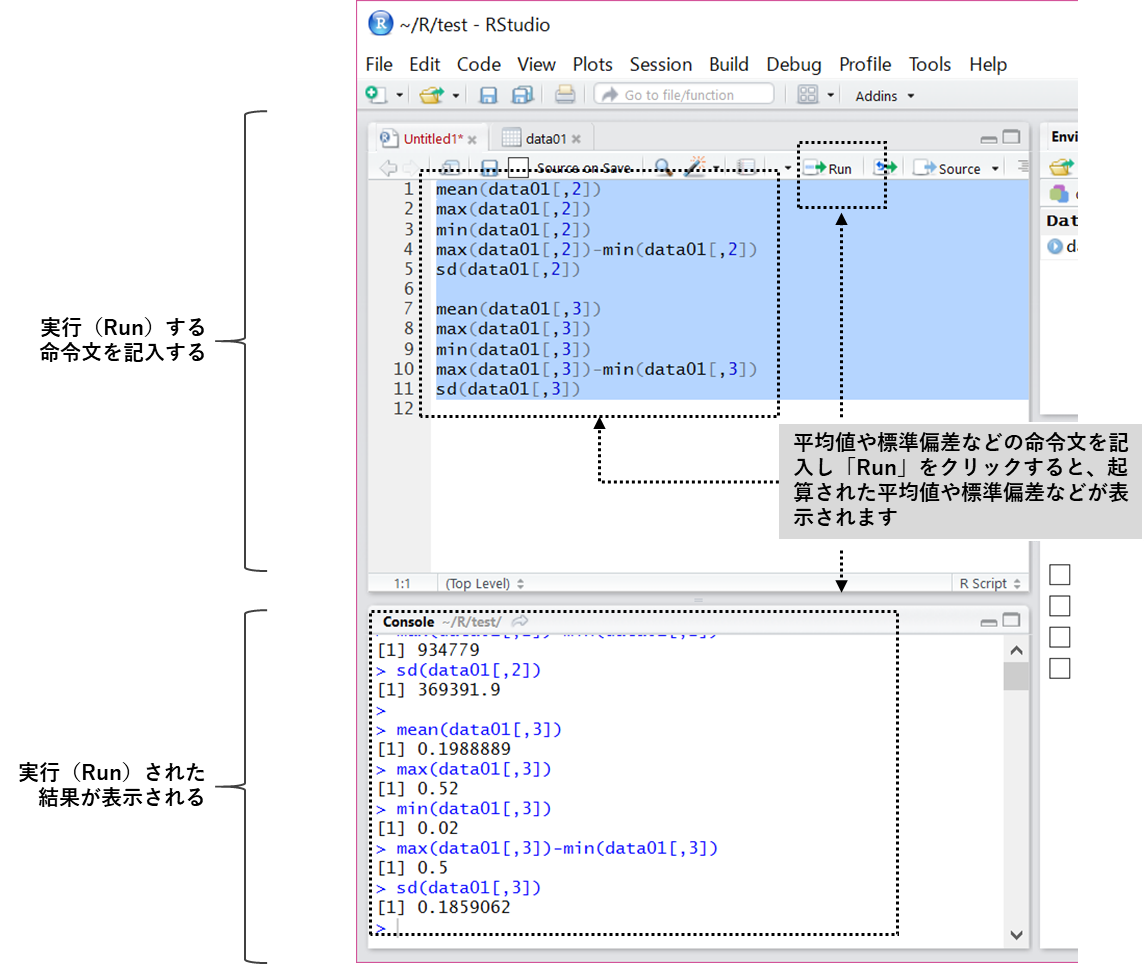
「data01」の「revenue」(2列目のデータ)と「profit rate」(3列目のデータ)に対し以下の5つの数字を出していきます。
- 平均値
- 最大値
- 最小値
- レンジ(最大値―最小値)
- 標準偏差
Rの命令文(スクリプト)の実行
上述の5つの数字は、以下の命令文で計算できます。
- 平均値 mean()
- 最大値 max()
- 最小値 min()
- レンジ(最大値-最小値) max()-min()
- 標準偏差 sd()
RStudioの左上のウィンドウ・ペインに次のような命令文を記入し、「Run」ボタをクリックすると、平均値や標準偏差などが計算されます。
max(data01[,2])
min(data01[,2])
max(data01[,2])-min(data01[,2])
sd(data01[,2])mean(data01[,3])
max(data01[,3])
min(data01[,3])
max(data01[,3])-min(data01[,3])
sd(data01[,3])
計算結果は、RStudioの左下にあるウィンドウ・ペインに表示されます。
今回のまとめ
今回は、RStudioで1変量の特徴(平均値・標準偏差など)を捉えるためのデータ分析の方法についてご説明いたしました。
1変量の特徴(平均値・標準偏差など)を把握したら、次にするのは変量間の関係の把握です。
変量間の把握で基礎となるのが、2変量の関係(散布図・相関係数など)の把握です。
次回は、RStudioで2変量の関係(散布図・相関係数など)を捉えるためのデータ分析の方法についてご説明いたします。