次の Python コードの出力はどれでしょうか?
Python コード:
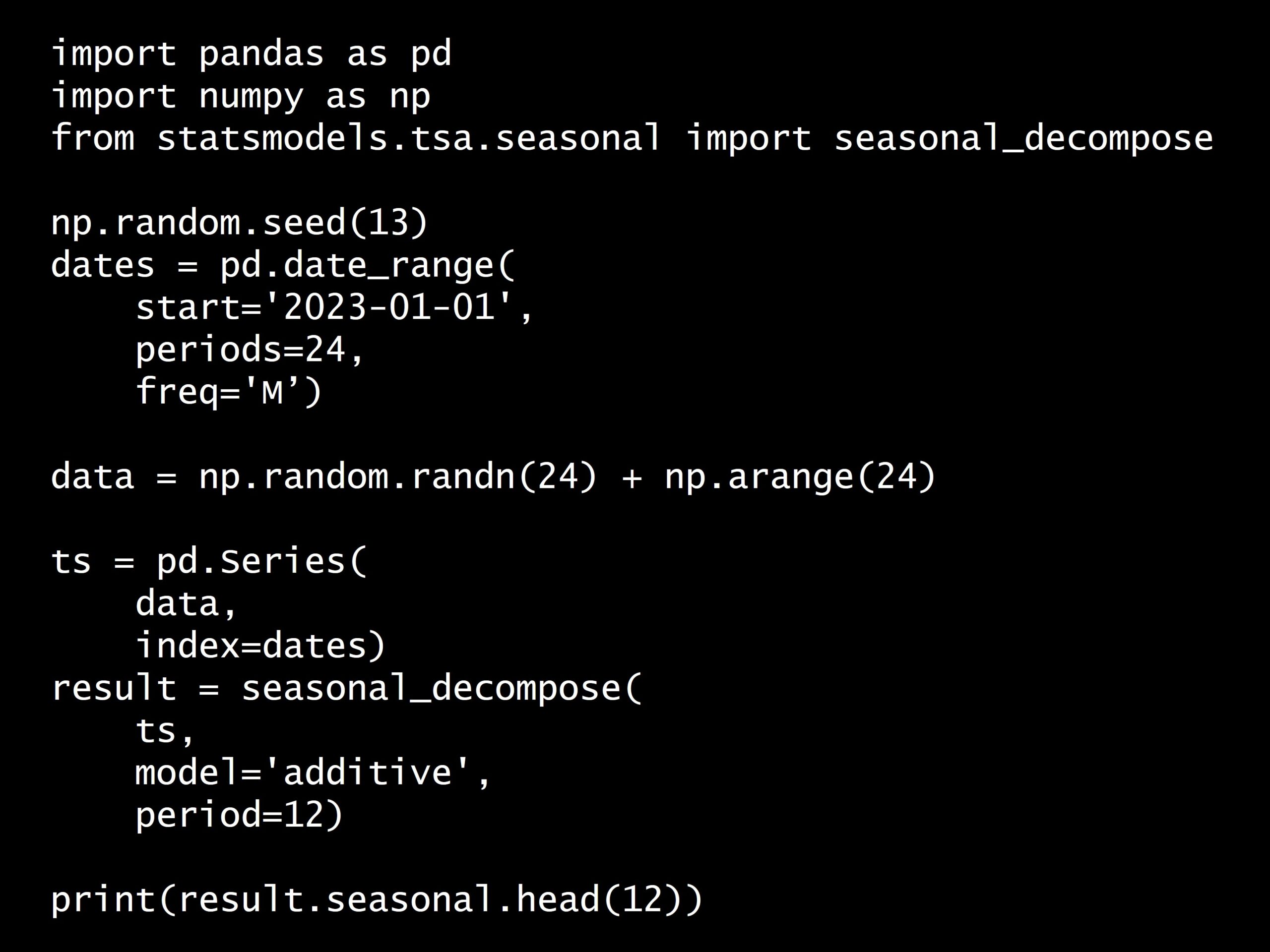
import pandas as pd
import numpy as np
from statsmodels.tsa.seasonal import seasonal_decompose
np.random.seed(13)
dates = pd.date_range(
start='2023-01-01',
periods=24,
freq='M')
data = np.random.randn(24) + np.arange(24)
ts = pd.Series(
data,
index=dates)
result = seasonal_decompose(
ts,
model='additive',
period=12)
print(result.seasonal.head(12))
回答の選択肢:
(A) 季節性成分の最初の12ヶ月の値
(B) 最初の12ヶ月の季節成分の平均値
(C) 季節成分の値を12月開始にした時系列データ
(D) 最初の12月の季節性成分の値
出力例:
2023-01-31 0.135702
2023-02-28 -0.602476
2023-03-31 0.694209
2023-04-30 0.107268
2023-05-31 -0.248526
2023-06-30 1.694710
2023-07-31 0.964094
2023-08-31 0.463528
2023-09-30 1.082621
2023-10-31 -1.475766
2023-11-30 -1.163034
2023-12-31 -1.652328
Freq: M, Name: seasonal, dtype: float64
正解: (A)
回答の選択肢:
(A) 季節性成分の最初の12ヶ月の値
(B) 最初の12ヶ月の季節成分の平均値
(C) 季節成分の値を12月開始にした時系列データ
(D) 最初の12月の季節性成分の値
このコードは、時系列データの季節調整を行うときに行う、季節成分を分解する例です。
import pandas as pd
import numpy as np
from statsmodels.tsa.seasonal import seasonal_decompose
np.random.seed(13)
dates = pd.date_range(
start='2023-01-01',
periods=24,
freq='M')
data = np.random.randn(24) + np.arange(24)
ts = pd.Series(
data,
index=dates)
result = seasonal_decompose(
ts,
model='additive',
period=12)
print(result.seasonal.head(12))
詳しく説明します。
24期間の日付インデックスを生成します。スタート日付は’2023-01-01’で、期間(つまり日数)は24、頻度は月ごと(’M’)に設定しています。
dates = pd.date_range(
start='2023-01-01',
periods=24,
freq='M')
datesに格納されているデータは次のようになっています。
DatetimeIndex(['2023-01-31', '2023-02-28', '2023-03-31', '2023-04-30',
'2023-05-31', '2023-06-30', '2023-07-31', '2023-08-31',
'2023-09-30', '2023-10-31', '2023-11-30', '2023-12-31',
'2024-01-31', '2024-02-29', '2024-03-31', '2024-04-30',
'2024-05-31', '2024-06-30', '2024-07-31', '2024-08-31',
'2024-09-30', '2024-10-31', '2024-11-30', '2024-12-31'],
dtype='datetime64[ns]', freq='M')
この日付インデックスと、乱数の配列を用いて時系列データを作成します。乱数の配列はnumpyのrandom.randn(正規分布)を用いて生成し、そこに単純に範囲関数arangeを合わせたものになっています。
data = np.random.randn(24) + np.arange(24)
dataに格納されているデータは次のようになっています。
[-0.71239066 1.75376638 1.95549692 3.45181234 5.34510171 5.53233789
7.3501879 7.86121137 9.47868574 7.95462287 9.21101098 9.73839405
12.56284679 12.75667375 14.9137407 15.31735092 16.12730328 19.15038297
18.60628866 18.97322835 19.01583922 22.19070527 22.95283061 21.91281841]
このデータをpandasのSeriesに変換します。Seriesは1次元のデータフレームで、label付けされたデータを保持できます。この例では、日付インデックスをラベルとし、生成したデータを値としています。
ts = pd.Series(
data,
index=dates)
tsに格納されているデータは次のようになっています。
2023-01-31 -0.712391
2023-02-28 1.753766
2023-03-31 1.955497
2023-04-30 3.451812
2023-05-31 5.345102
2023-06-30 5.532338
2023-07-31 7.350188
2023-08-31 7.861211
2023-09-30 9.478686
2023-10-31 7.954623
2023-11-30 9.211011
2023-12-31 9.738394
2024-01-31 12.562847
2024-02-29 12.756674
2024-03-31 14.913741
2024-04-30 15.317351
2024-05-31 16.127303
2024-06-30 19.150383
2024-07-31 18.606289
2024-08-31 18.973228
2024-09-30 19.015839
2024-10-31 22.190705
2024-11-30 22.952831
2024-12-31 21.912818
Freq: M, dtype: float64
この時系列データに対し、statsmodelsパッケージのseasonal_decompose関数を用い、時系列データをトレンド成分、季節性成分、残差成分に分解します。この結果を使うことで、季節調整を行うことができます。
result = seasonal_decompose(
ts,
model='additive',
period=12)
その結果から季節性成分だけを取り出すため、result.seasonalを用いています。また、head(12)を通じて最初の12行だけを表示しています。
print(result.seasonal.head(12))
2023-01-31 0.135702
2023-02-28 -0.602476
2023-03-31 0.694209
2023-04-30 0.107268
2023-05-31 -0.248526
2023-06-30 1.694710
2023-07-31 0.964094
2023-08-31 0.463528
2023-09-30 1.082621
2023-10-31 -1.475766
2023-11-30 -1.163034
2023-12-31 -1.652328
Freq: M, Name: seasonal, dtype: float64
補足です。
結果の格納され散るresultは、以下の公開属性やメソッドを持っています。
nobs: 元の時系列データに含まれる観測値の数を返します。observed: 元の時系列データを返します。plot: 分解結果のプロットを行うためのメソッドです。トレンド成分、季節性成分、残差を視覚的に確認することができます。resid: 分解後の残差成分を返します。これは、観測データからトレンドと季節性が除かれたものです。seasonal: 分解後の季節性成分を返します。これは、データの中に反復するパターンを表しています。trend: 分解後のトレンド成分を返します。これは、データの中に見られる長期的な上昇または下降のパターンを表しています。weights: 分解の際に使用した重みを返します。結果の分解にどの程度影響を及ぼすかを示します。
今回は、seasonal属性を使い、resultから季節成分を抽出しました。