
- 問題
- 答え
- 解説
- ADF検定とは?
- 単位根過程と定常性
Python コード:
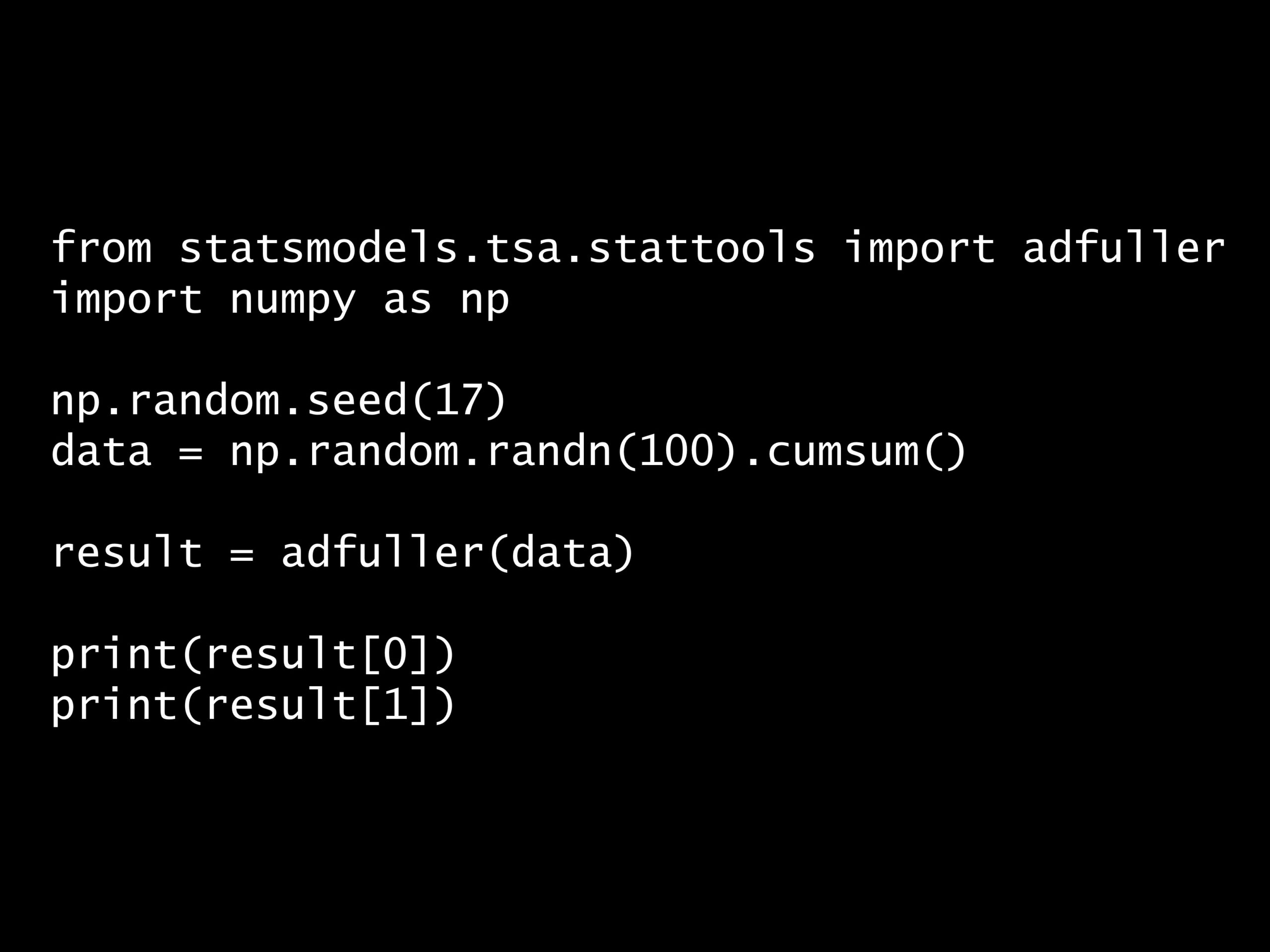
from statsmodels.tsa.stattools import adfuller import numpy as np np.random.seed(17) data = np.random.randn(100).cumsum() result = adfuller(data) print(result[0]) print(result[1])
回答の選択肢:
(A) 平均値と標準偏差
(B) 最大値と最小値
(C) ADF統計量とp値
(D) 分散と標準偏差
-1.2708902183488542 0.6423826498878334
正解: (C)
回答の選択肢:
(A) 平均値と標準偏差
(B) 最大値と最小値
(C) ADF統計量とp値
(D) 分散と標準偏差
from statsmodels.tsa.stattools import adfuller import numpy as np np.random.seed(17) data = np.random.randn(100).cumsum() result = adfuller(data) print(result[0]) print(result[1])
詳しく説明します。
Numpyの乱数生成関数を用いてランダムデータを生成し、`.cumsum()`によって累積和を取り、時系列データを生成します。
np.random.seed(17) data = np.random.randn(100).cumsum()
dataに格納されているデータは次のようになっています。
[ 0.27626589 -1.57836219 -0.95446108 0.19085021 1.22804068 3.11467961 3.00298132 2.64087998 2.78955503 2.35177187 4.52302887 5.67533912 3.85652678 3.71847744 4.25831706 2.48303477 3.7979113 3.32446326 2.23223336 1.98220592 0.99991161 2.0311807 2.52251448 2.07586788 1.26950779 1.40077555 0.18821531 0.34820617 -0.40701687 -0.05712088 0.92042089 0.78183564 0.88569194 1.18628298 2.15448828 3.02411212 3.59189521 4.05717755 2.89180447 0.85580968 -0.29960362 3.04555378 3.17228099 2.47810209 3.03577652 3.13492312 3.7728493 4.47595998 3.55986682 2.77385259 3.89303439 2.90963828 3.1541583 2.57274856 3.00231247 3.80071445 3.19064441 4.37604861 3.66521461 2.88408568 2.6537127 2.77390778 1.98543795 -0.97468467 -1.77026579 -1.48568354 -0.96314626 -0.87959181 1.84120378 2.45221166 1.61626766 1.61257162 2.0056663 2.69016139 3.46536307 4.02136596 3.48038606 5.0048033 6.21318843 6.26446572 5.83783451 6.64577474 6.7030545 5.66288292 6.59703101 6.47699647 8.68401278 5.284082 6.51761089 5.92973006 4.95279314 5.42086343 8.29199036 7.08390468 8.08750786 9.2182343 9.77827399 9.15987669 8.93507797 11.15097942]
Augmented Dickey-Fuller (ADF) 検定を行います。具体的には、`adfuller`関数に生成した時系列データを渡します。これにより時系列データが単位根過程を持つのか(つまり非定常か)、あるいは定常かを検定します。
result = adfuller(data)
ADF検定の結果として得られたADF統計量(`result[0]`)とP値(`result[1]`)を出力します。
print(result[0]) print(result[1])
-1.2708902183488542 0.6423826498878334
result は、時系列データdataに対して行われた Augmented Dickey-Fuller (ADF) 検定の出力を含むタプルです。このタプルには、ADF 検定統計量、p 値、回帰で使用したラグの数、ADF 回帰と臨界値辞書に使用したオブザベーションの数、autolag が None でない場合は最大化情報量規準が含まれる。ADF検定は,時系列が定常であるかどうかを決定するために使用されます。
P値は、帰無仮説が正しい場合に、標本データがこの検定統計量以上の値を示す確率を表します。一般的に、P値がある閾値(例えば0.05)より小さい場合、帰無仮説を棄却し、対立仮説を採択します。つまり、このコードではP値が0.05以下であれば、データは定常と考えます。
このコードの場合、P値は0.64となり、これは一般的に用いられる閾値(例えば0.05)よりもかなり高いです。したがって、このデータは単位根を持つと結論付けられ、つまりデータは非定常であると結論付けることができます。
ちなみに、以下はAugmented Dickey-Fuller (ADF) 検定の実行結果を格納したタプルresultの各要素です。
- ADF Test Statistic(ADF統計量)(
result[0]): これはADF検定の結果から得られる主要な値です。ADF統計量が臨界値よりも小さい(絶対値が大きい)場合、帰無仮説(データが単位根過程を持つ、つまり非定常である)を棄却します。 - p-value(p値)(
result[1]): ADF統計量に基づいたp値です。一般的に、p値が0.05より小さいとき、我々は帰無仮説を棄却します。つまり、p値が0.05よりも小さければ、データは定常とみなすことができます。 - Used Lag(使用されたラグ)(
result[2]): ADF検定で使用されたラグの数。ラグは、自己相関を考慮するために使用されます。 - Number of Observations Used for ADF Regression and Critical Values(ADF回帰と臨界値の計算に使用された観測値の数)(
result[3]): これは、ADF統計量と臨界値を計算するために使用されたデータポイントの数を示します。 - Critical Values(臨界値)(
result[4]): 各信頼水準のADF統計量の臨界値を示す辞書。これは1%、5%、10%の信頼水準での臨界値を含む辞書です。 - Maximized Information Criterion(最大化情報量規準)(
result[5]): 最善のラグを選択するために使用される情報量規準の値。この値は、`autolag`引数に何らかの値(’AIC’,’BIC’,’t-stat’等)が設定されているときにのみ出力されます。ただし、今回のコードでは`autolag`引数に値は設定されていません。
このタプルresultから読み取れる情報を使えば、データの定常性を判断し、その結果に基づいたさらなる分析を行うことができます。
非定常性のデータは、時間の経過とともにその統計的な特性(如何に平均や分散が変化するか等)が変化する傾向があります。一方、定常性を持つデータはこれらの特性が一定のままで、時間の影響を受けません。
ADF検定は、Dickey-Fuller検定の拡張版であり、ラグ項を取り込むことでより一般的な自己相関の構造を持つ時系列に対応できます。ADF検定の帰無仮説は、「データは単位根過程を持つ」つまり「データは非定常である」です。したがって、検定結果が一定の閾値以下であれば、帰無仮説を棄却し、代わりに対立仮説「データは単位根過程を持たない」つまり「データは定常である」を採用します。
ADF検定はこのように時系列分析の初期ステップとして重要で、データが非定常な場合、さらなる手続き(例えば差分取得等)を行って定常性を取り戻す必要があります。定常性を持つデータに対しては、さらなる時系列分析(例えばARMAモデルなど)が可能となります。
具体的には、ある時点tでの値
ここで、
単位根過程は、時間の経過とともにデータの特性(平均や分散など)が変化する非定常な過程となります。すなわち、非定常な時系列データは一般にその統計的特性が時間によって変わります。一方、定常性を持つデータはこれらの特性が一定のままで、時間の影響を受けません。
定常性というのは、時系列データが時間の経過に伴ってその統計的特性(平均や分散など)が不変である状態を指します。定常性を持つ時系列データでは、任意の時間点でのデータの分布(または確率密度関数)が時間によらず一定であり、特定の時間間隔だけずらした時系列(ラグ)間の相関(自己相関)も時間によらず一定となります。
定常性は、時系列分析の手法を用いる際の基本的な前提条件であります。非定常なデータに対しては、差分取得や対数変換などの前処理を行い、データを定常な状態に変換することが一般的です。
定常なデータであれば、過去のデータパターンが将来も継続すると予想することが可能となり、予測モデルの作成やその他の時系列分析が適切に行えます。