
- 問題
- 答え
- 解説
次の Python コードの出力はどれでしょうか?
Python コード:
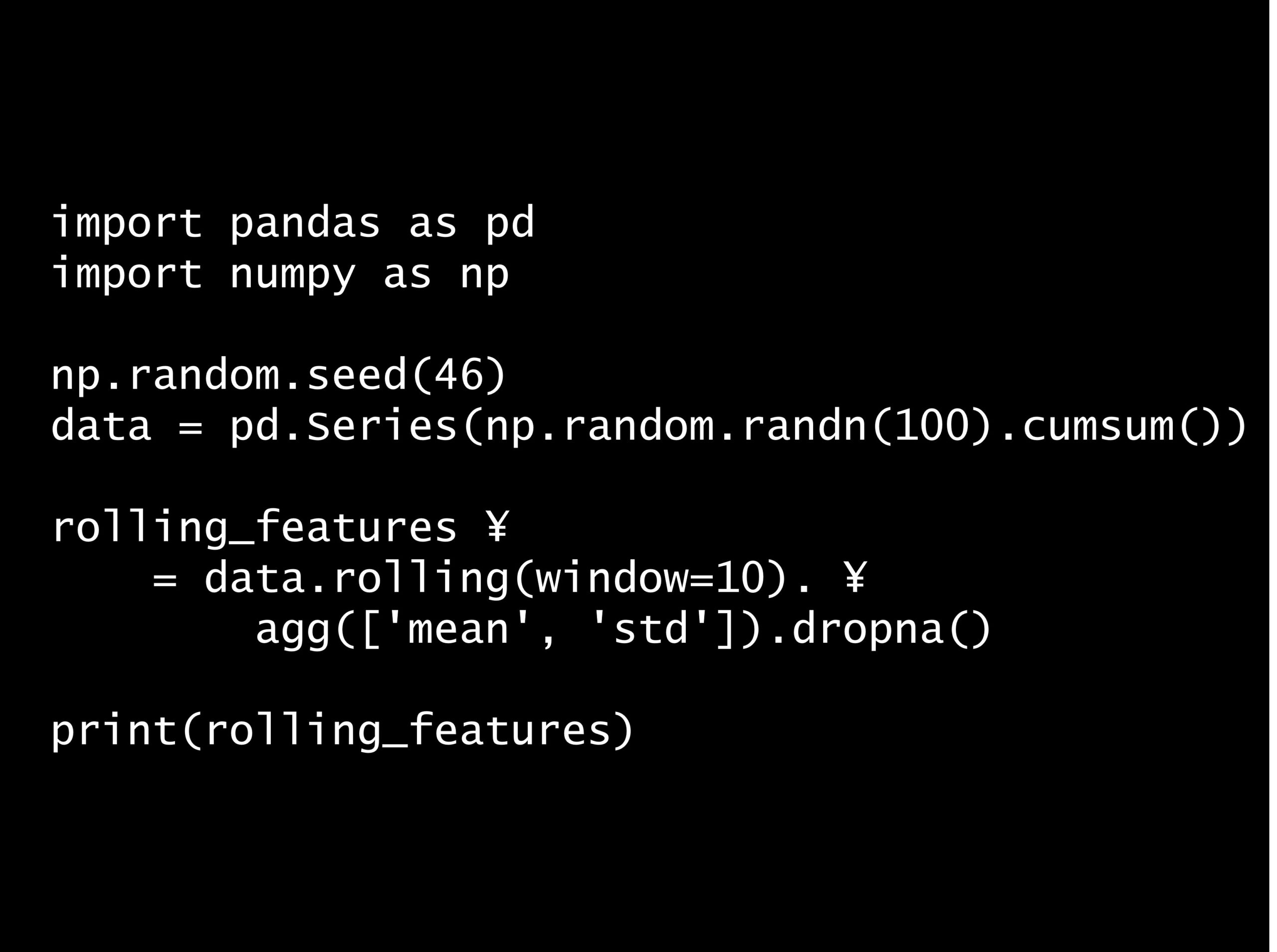
import pandas as pd
import numpy as np
np.random.seed(46)
data = pd.Series(np.random.randn(100).cumsum())
rolling_features \
= data.rolling(window=10). \
agg(['mean', 'std']).dropna()
print(rolling_features)
import pandas as pd
import numpy as np
np.random.seed(46)
data = pd.Series(np.random.randn(100).cumsum())
rolling_features \
= data.rolling(window=10). \
agg(['mean', 'std']).dropna()
print(rolling_features)
import pandas as pd
import numpy as np
np.random.seed(46)
data = pd.Series(np.random.randn(100).cumsum())
rolling_features \
= data.rolling(window=10). \
agg(['mean', 'std']).dropna()
print(rolling_features)
回答の選択肢:
(A) 各時点での各ウィンドウの平均と標準偏差
(B) データ全体の平均と標準偏差
(C) 各時点での過去データすべての平均と標準偏差
(D) 10個のランダムなサンプルの平均と標準偏差