
- 問題
- 答え
- 解説
Python コード:
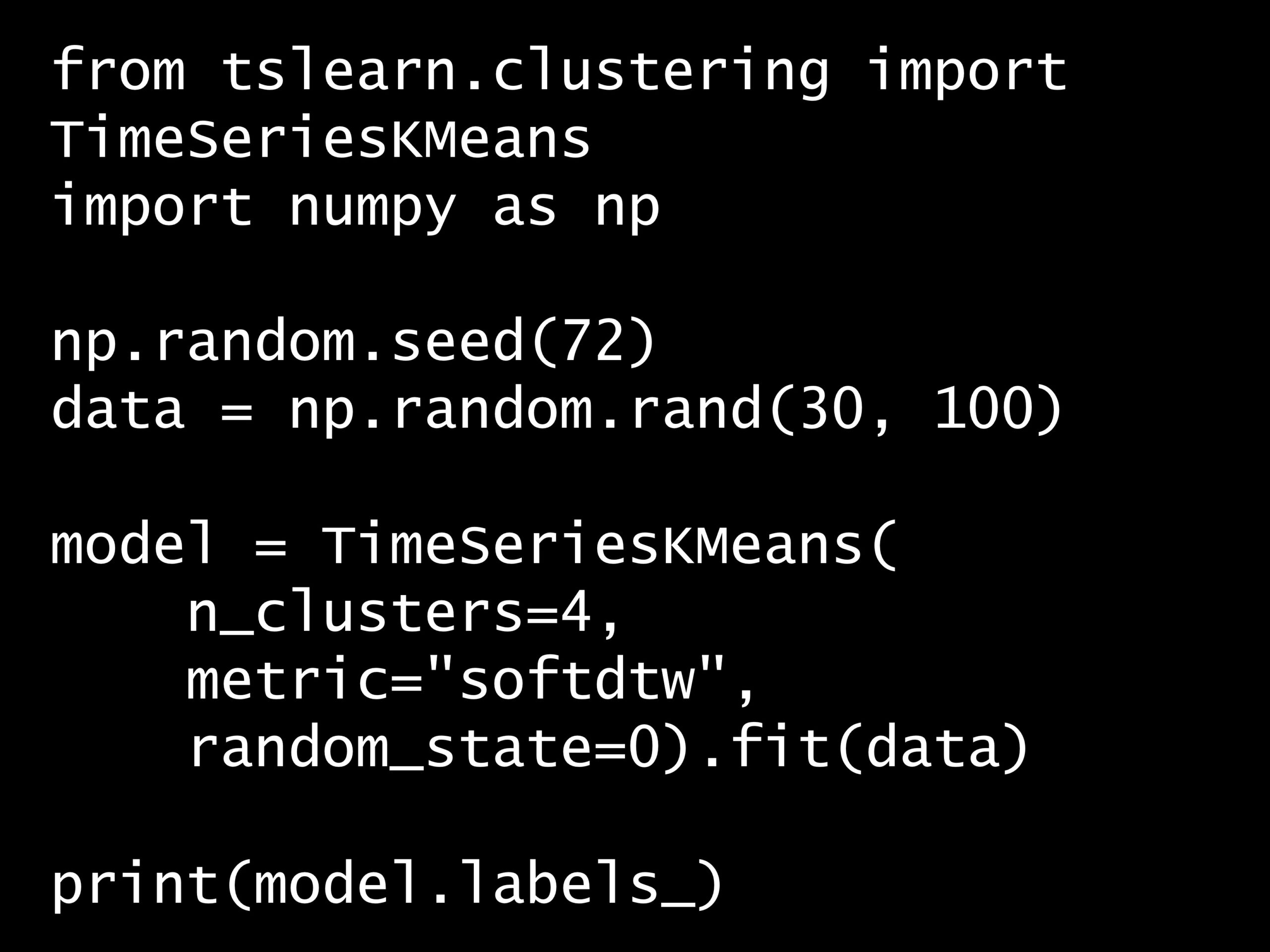
from tslearn.clustering import TimeSeriesKMeans
import numpy as np
np.random.seed(72)
data = np.random.rand(30, 100)
model = TimeSeriesKMeans(
n_clusters=4,
metric="softdtw",
random_state=0).fit(data)
print(model.labels_)
回答の選択肢:
(A) 各クラスタに属する時系列データの数
(B) 各時系列データのクラスタ番号
(C) 各クラスタの中心座標
(D) 各時系列データのクラスタ中心までの距離
[0 3 2 0 0 2 2 0 2 0 2 3 0 2 0 2 2 1 2 2 2 0 1 0 2 2 2 2 0 2]
正解: (B)
回答の選択肢:
(A) 各クラスタに属する時系列データの数
(B) 各時系列データのクラスタ番号
(C) 各クラスタの中心座標
(D) 各時系列データのクラスタ中心までの距離
- コードの解説
-
このコードは、時系列データのクラスタリングを行うものです。具体的には、
tslearnライブラリのTimeSeriesKMeansを使用しています。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighterfrom tslearn.clustering import TimeSeriesKMeansimport numpy as npnp.random.seed(72)data = np.random.rand(30, 100)model = TimeSeriesKMeans(n_clusters=4,metric="softdtw",random_state=0).fit(data)print(model.labels_)from tslearn.clustering import TimeSeriesKMeans import numpy as np np.random.seed(72) data = np.random.rand(30, 100) model = TimeSeriesKMeans( n_clusters=4, metric="softdtw", random_state=0).fit(data) print(model.labels_)from tslearn.clustering import TimeSeriesKMeans import numpy as np np.random.seed(72) data = np.random.rand(30, 100) model = TimeSeriesKMeans( n_clusters=4, metric="softdtw", random_state=0).fit(data) print(model.labels_)詳しく説明します。
numpyを使用して、ランダムな30個の時系列データを生成しています。各時系列データは100の要素を持ちます。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighternp.random.seed(72)data = np.random.rand(30, 100)np.random.seed(72) data = np.random.rand(30, 100)np.random.seed(72) data = np.random.rand(30, 100)
dataに格納されているデータは次のようになっています。[[0.1067382 0.68434263 0.53496262 ... 0.14005319 0.4712315 0.22707353] [0.56276446 0.75814751 0.54965165 ... 0.20997429 0.14159995 0.91710362] [0.86377745 0.76908284 0.07527334 ... 0.83841769 0.57459806 0.14829337] ... [0.27665138 0.43189108 0.50082834 ... 0.92422157 0.73402193 0.27326355] [0.19706356 0.73540849 0.76055268 ... 0.62951545 0.44131405 0.95808032] [0.00923056 0.08399516 0.78240248 ... 0.8264984 0.87501962 0.56296203]]
TimeSeriesKMeansを用いて、4つのクラスタに分けるためのモデルを作成します。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlightermodel = TimeSeriesKMeans(n_clusters=4,metric="softdtw",random_state=0).fit(data)model = TimeSeriesKMeans( n_clusters=4, metric="softdtw", random_state=0).fit(data)model = TimeSeriesKMeans( n_clusters=4, metric="softdtw", random_state=0).fit(data)ここで使用されている距離計算方法は
softdtw(Soft Dynamic Time Warping)で、時系列データの類似性を計算する際に柔軟性を持たせることができます。fit(data)メソッドを使用して、生成したランダムデータに対してクラスタリングを実行しています。最後に、
model.labels_を出力しています。これは、各時系列データがどのクラスタに属するかを示すラベルの配列です。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighterprint(model.labels_)print(model.labels_)print(model.labels_)
[0 3 2 0 0 2 2 0 2 0 2 3 0 2 0 2 2 1 2 2 2 0 1 0 2 2 2 2 0 2]
今回は、各時系列データに割り当てられたクラスター番号(ラベル)を表示しましたが、
modelの属性には他のものもあります。以下、
labels_も含めた主な属性です。- cluster_centers_:各クラスタの中心時系列を格納する配列です。クラスタリングの結果として形成された各クラスタの代表的な時系列パターンを表します。
- labels_:訓練データセットの各サンプルに対するクラスタラベルを格納する配列です。このラベルは、サンプルがどのクラスタに属するかを示します。
- inertia_:モデルの最終的な慣性値を示します。慣性は、クラスタ内のサンプルとそのクラスタの中心との距離の総和であり、クラスタリングの品質を評価するために使用されます。慣性が小さいほど、クラスタ内のサンプルが中心に近く、より密接していることを示します。
- n_iter_:アルゴリズムが収束するまでの繰り返し回数です。この値は、アルゴリズムが設定した収束条件に到達するまでに要した反復処理の回数を反映します。
今回は、
fit()メソッドで時系列クラスターの学習をしましたが、modelのメソッドには他のものもあります。以下、
fit()も含めた主なメソッドです。- fit(X[, y]):時系列データセット
Xに対してモデルを訓練(フィット)します。オプションでyを指定することもできますが、教師なし学習モデルであるため、通常は使用しません。 - predict(X):訓練済みモデルを使用して、与えられたデータセット
Xの各サンプルに対するクラスタラベルを予測します。 - fit_predict(X[, y]):データセット
Xに対してモデルを訓練し、そのデータセットのサンプルに対するクラスタラベルを予測します。fitとpredictを一連の操作として実行します。 - transform(X):与えられたデータセット
Xの各サンプルに対して、そのサンプルと各クラスタ中心との距離を格納した配列を返します。クラスタリングにおいて、各サンプルがクラスタ中心からどの程度離れているかを示します。 - partial_fit(X[, y]):オンライン学習をサポートする場合に使用します。新しいデータセット
Xをモデルに順次提供し、モデルを段階的に更新します。
単に時系列のクラスタリングをするだけでなく、新たに時系列データを入手したとき、その時系列データがどのクラスターに属するか予測(分類)することができます。
- 時系列クラスタリングとは?
-
Contents [hide]
時系列クラスタリングとは?
時系列クラスタリングは、時系列データのセットから類似したパターンや動きを持つグループを識別し、分類するプロセスです。
この手法は、異なる時系列データ間の類似性を測定し、それに基づいてデータをクラスタに割り当てます。
時系列クラスタリングは、大量の時系列データを効率的に理解し、分析するための強力なツールです。
主な特徴と用途
パターンの識別
時系列クラスタリングは、データ内の隠れたパターンや構造を発見するのに役立ちます。例えば、株価の動きが似ている株式、類似の季節性を持つ販売データ、または同様の消費行動を示す顧客グループなどです。異常検出
クラスタリングによって生成されたグループを分析することで、異常なパターンや外れ値を識別することができます。これは、システムの監視、品質管理、セキュリティ分野で特に有用です。データの圧縮と簡略化
類似の時系列をクラスタにまとめることで、データを圧縮し、その複雑さを減らすことができます。これにより、データの理解やさらなる分析が容易になります。予測モデルの改善
クラスタリングによって類似のデータをグループ化することで、予測モデルの精度を向上させることができます。モデルは、より均質なデータセットに対して訓練されるため、特定のパターンや傾向を捉えやすくなります。クラスタリング手法
時系列クラスタリングには、様々な距離尺度(ユークリッド距離、動的時間伸縮(DTW)、ソフトDTWなど)とアルゴリズム(K-means、階層的クラスタリング、DBSCANなど)が用いられます。
選択される手法は、データの特性や分析の目的によって異なります。
ユークリッド距離
各時点の値の差の二乗和の平方根を計算します。時系列が同じ長さで、位相的なずれがない場合に適しています。動的時間伸縮(DTW)
時系列間の類似性を測る際に、時系列の伸縮やシフトを許容することで、より柔軟な比較を可能にします。 - 時系列ライブラリ
tslearn -
時系列ライブラリ
tslearnによるクラスタリングtslearnは時系列データを扱うデータサイエンティストや研究者にとって、非常に強力かつ使いやすいツールを提供するライブラリであり、時系列データの分析やモデリングを行う際の必要性に対応するために設計されています。tslearnは、時系列データをクラスタリングするためのアルゴリズム(例えばTimeSeriesKMeans)や、時系列データを分類するためのアルゴリズムを提供しています。tslearnのTimeSeriesKMeansで、時系列データのクラスタリングを行うことができます。TimeSeriesKMeansを使用した時系列クラスタリングの流れは、以下のステップに分けて実行されます。これらのステップを通じて、時系列データの類似性に基づくグループ化を行い、データ内のパターンや構造を発見することができます。
1. ライブラリのインポート
まず、
tslearnと他の必要なライブラリをインポートします。tslearnがまだインストールされていない場合は、pipを使用してインストール(pip install tslearn)してください。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighterfrom tslearn.clustering import TimeSeriesKMeansfrom tslearn.datasets import CachedDatasetsimport numpy as npfrom tslearn.clustering import TimeSeriesKMeans from tslearn.datasets import CachedDatasets import numpy as npfrom tslearn.clustering import TimeSeriesKMeans from tslearn.datasets import CachedDatasets import numpy as np
2. データの準備
時系列データセットを準備します。
今回は、
tslearnが提供するものを利用します。一般的には、時系列ごとに配列を用意し、これらを3次元のNumPy配列に格納します(サンプル数, 時系列の長さ, 次元数)。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighter# 例として、tslearnが提供するサンプルデータセットを使用X_train, y_train, X_test, y_test = CachedDatasets().load_dataset("Trace")# 例として、tslearnが提供するサンプルデータセットを使用 X_train, y_train, X_test, y_test = CachedDatasets().load_dataset("Trace")# 例として、tslearnが提供するサンプルデータセットを使用 X_train, y_train, X_test, y_test = CachedDatasets().load_dataset("Trace")X_train,y_train,X_test,y_testは、CachedDatasets().load_dataset("Trace")によって読み込まれたデータセットです。これらのデータは、時系列分析やクラスタリングなどの機械学習タスクに使用されるサンプルデータです。
X_trainとX_testは、それぞれ訓練データとテストデータの特徴量を含む多次元配列です。これらのデータは時系列データであり、各時系列は複数の時点における観測値を持っています。X_train形状: (サンプル数, 時系列の長さ, 次元数)=(100, 275, 1)X_test形状: (サンプル数, 時系列の長さ, 次元数)=(100, 275, 1)
要するに、時系列データが100個あり、各時系列データの変数の数が1つで長さが275時点ということです。
y_trainとy_testは、それぞれ訓練データとテストデータが属するクラスまたはカテゴリを示しています。今回の例では使いません。クラスタリングの精度評価に利用するものです。y_train形状:(サンプル数)=(100)y_test形状: (サンプル数)=(100)
このデータセットは、時系列データの分類やクラスタリングを行うための実験や学習に使用されることが一般的です。
例えば、
TimeSeriesKMeansを使用したクラスタリングでは、X_trainの時系列データをいくつかのグループに分けることが目的となります。また、分類タスクでは、新しい時系列データ(
X_test)が与えられたときに、それがどのクラス(y_testのラベル)に属するかを予測します。3. モデルの初期化(インスタンス生成)
TimeSeriesKMeansクラスのインスタンスを作成し、クラスタの数(n_clusters)や距離尺度(metric)などのパラメータを設定します。Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighter# 例として、クラスタ数を3に、距離尺度をDTWに設定model = TimeSeriesKMeans(n_clusters=3, metric="dtw")# 例として、クラスタ数を3に、距離尺度をDTWに設定 model = TimeSeriesKMeans(n_clusters=3, metric="dtw")# 例として、クラスタ数を3に、距離尺度をDTWに設定 model = TimeSeriesKMeans(n_clusters=3, metric="dtw")
距離尺度には、
"euclidean"、"dtw"(動的時間伸縮)、"softdtw"(ソフト動的時間伸縮)が利用可能です。距離関数 概要 使用シナリオ metric設定ユークリッド距離 二点間の直線距離。時系列データでは、ポイントごとの差の二乗和の平方根を計算。 時系列が同じ長さで、局所的な変動よりも全体の形状が重要な場合。位相的なずれや時間的な伸縮には対応できない。 "euclidean"動的時間伸縮 (DTW) 時系列間の最適なマッチングを見つけ出し、時系列の位相的なずれや時間的な伸縮に対応。 位相的なずれや時間的な伸縮を含む時系列データのクラスタリング。音声データの分析やセンサーデータの分析などに適している。 "dtw"ソフトDTW DTWの変種で、滑らかな勾配を提供し、最適化を容易にする。微分可能な近似を使用。 DTWと同様のシナリオで、特にアルゴリズムの最適化や微分可能性が重要な場合に有効。 "softdtw"4. モデルの訓練
準備したデータセットを用いて、モデルを訓練(フィット)します。
Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlightermodel.fit(X_train)model.fit(X_train)model.fit(X_train)
5. クラスタリング結果の利用
訓練されたモデルを使用して、新しいデータポイントのクラスタを予測したり、各クラスタの中心を確認したりします。
Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighter# 新しいデータポイントのクラスタを予測predictions = model.predict(X_test)# 予測結果を表示print(predictions)# 新しいデータポイントのクラスタを予測 predictions = model.predict(X_test) # 予測結果を表示 print(predictions)# 新しいデータポイントのクラスタを予測 predictions = model.predict(X_test) # 予測結果を表示 print(predictions)
以下、実行結果です。
Plain textCopy to clipboardOpen code in new windowEnlighterJS 3 Syntax Highlighter[0 1 0 2 1 0 2 2 2 0 0 2 0 0 0 0 2 0 1 1 0 0 0 1 2 0 0 0 0 0 0 2 2 2 1 0 01 2 0 0 0 2 2 0 2 1 0 0 0 2 0 2 1 0 1 0 1 0 0 0 1 0 2 0 1 2 1 2 1 1 2 0 01 2 2 0 0 2 2 1 0 1 2 2 0 1 1 1 0 1 1 2 0 0 2 2 0 0][0 1 0 2 1 0 2 2 2 0 0 2 0 0 0 0 2 0 1 1 0 0 0 1 2 0 0 0 0 0 0 2 2 2 1 0 0 1 2 0 0 0 2 2 0 2 1 0 0 0 2 0 2 1 0 1 0 1 0 0 0 1 0 2 0 1 2 1 2 1 1 2 0 0 1 2 2 0 0 2 2 1 0 1 2 2 0 1 1 1 0 1 1 2 0 0 2 2 0 0][0 1 0 2 1 0 2 2 2 0 0 2 0 0 0 0 2 0 1 1 0 0 0 1 2 0 0 0 0 0 0 2 2 2 1 0 0 1 2 0 0 0 2 2 0 2 1 0 0 0 2 0 2 1 0 1 0 1 0 0 0 1 0 2 0 1 2 1 2 1 1 2 0 0 1 2 2 0 0 2 2 1 0 1 2 2 0 1 1 1 0 1 1 2 0 0 2 2 0 0]
クラスタリングの結果を分析し、時系列データ間の類似性や異なるクラスタ間の特性を理解します。可視化ツール(例えば、matplotlib)を使用して、クラスタの中心やクラスタに属する時系列データをプロットすることが有効です。