

前編では、交絡バイアスの特定と対処の方法に焦点を当て、有向非巡回グラフ(DAG)を使用してこれらのバイアスを可視化し、対処する方法を簡単に説明しました。
後編では、選択バイアスとそのビジネス上の意思決定への影響と、その対処法についてお話しします。
選択バイアスは、データのサンプルが全体集団を適切に代表していない場合に生じ、データの解釈を歪める可能性があります。
ビジネスリーダーやデータサイエンティストにとって、選択バイアスを理解し、適切に対処することは、データに基づく正確な意思決定を行う上で不可欠です。
正しい対処法の選択と、選択バイアスの影響を最小限に抑える戦略の理解が、企業の戦略と成果に直接的な影響を及ぼします。
ちなみに、対処法はほぼ交絡バイアスのときに利用する手法と同じです。
Contents
選択バイアスとは?
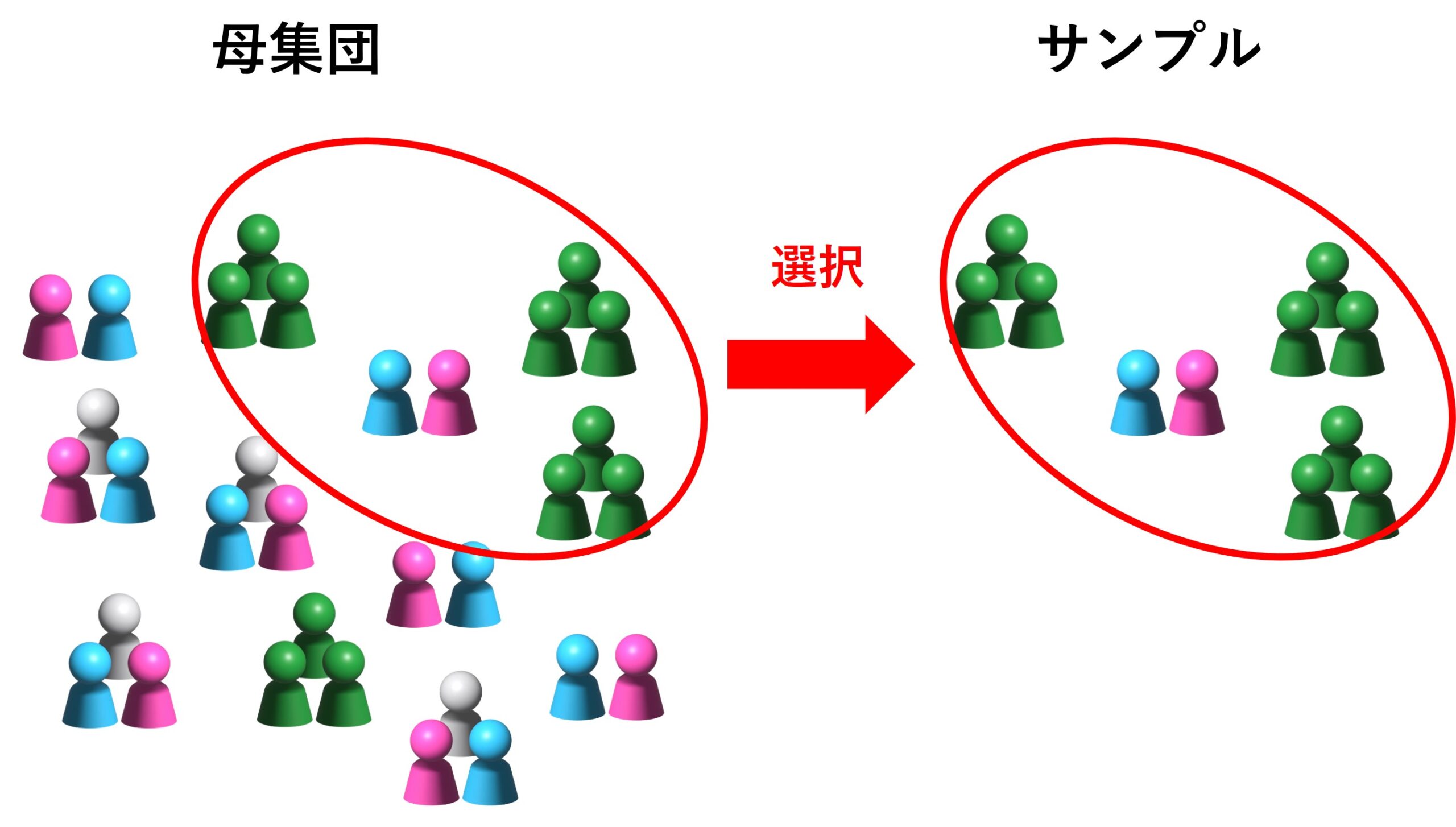
選択バイアスは、研究のサンプルが対象となる母集団を正しく反映していない場合に生じるバイアスです。
このバイアスは、研究結果の一般化を困難にし、誤った結論に導く可能性があります。
ビジネス環境においても、市場調査、顧客満足度調査、製品開発研究など、さまざまなシナリオで選択バイアスが発生することがあります。

例えば……
市場調査で起こる選択バイアスの例
- オンライン調査によるデータ収集では、インターネットを頻繁に使用する人々が過剰にサンプルに含まれる可能性があります。
- これにより、インターネットをあまり使用しない人々の意見が適切に反映されない可能性があります。
顧客満足度調査で起こる選択バイアスの例
- 満足した顧客(もしくは不満のある顧客)や特定の製品に対して強い意見を持つ顧客だけがアンケートに回答することが多い可能性があります。
- 全体の顧客満足度が実際よりも高くまたは低く報告されることがあります。
……などなどです。

ビジネス環境における選択バイアスの一般的な発生源として、主に以下のようなものがあります。
非応答バイアス
特定のタイプの応答者だけが回答すること。
利便性サンプリング
アクセスが容易な個人またはグループからデータを収集すること。
サバイバルバイアス
ある条件を生き延びた事例のみが分析され、全体像が歪められること。
選択バイアスを理解し、その発生源を特定することは、ビジネスにおけるデータドリブンな意思決定プロセスを向上させるために不可欠です。
因果ダイアグラム(DAG)の活用
因果ダイアグラム(DAG)は、変数間の直接的な因果関係を矢印で示すグラフです。
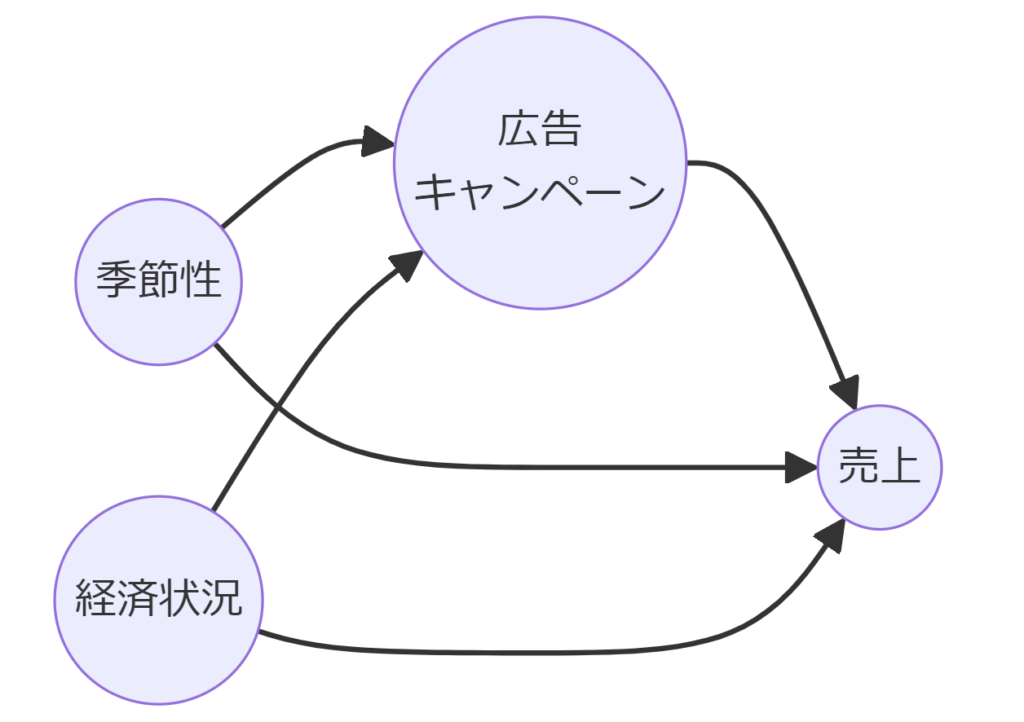
これにより、どの変数が介入(説明変数)やアウトカム(目的変数)に直接影響を与えるか、またはどの変数が介入(説明変数)とアウトカム(目的変数)の関係に影響を及ぼす可能性があるかを視覚的に把握できます。
ビジネスデータにおける適用を通じて、より正確なデータ分析と意思決定をサポートします。
例えば、ビジネスデータにDAGすることで……
変数の識別
ビジネス問題に関連する(必要な)変数(例:顧客の属性、購買行動、製品の特性など)を特定します。
関係の定義
これらの変数間の潜在的な因果関係を定義し、DAGを構築します。これには専門的知識や以前の研究結果が役立ちます。
バイアスの識別
DAGを分析して、選択バイアスや他のバイアスが生じる可能性のある経路を特定します。特に、誤って条件付けることでバイアスが生じる衝突(Collision)を引き起こす共通効果を識別することが重要です。
選択バイアスの識別という観点では……
バイアスの視覚化
DAGを使用して、どの変数が選択プロセスに関与しているかを明確にし、それがアウトカムにどのように影響を与えるかを視覚的に表現します。
識別と対処
DAGに基づき、選択バイアスを避けるためのデータ収集や分析戦略を策定します。例えば、特定の共変量に対する調整や、サンプリングプロセスの改善がこれに該当します。
因果ダイアグラムは、選択バイアスの問題を明らかにし、それを避けるための具体的な戦略を立てる際に非常に有効です。
正しく適用することで、ビジネス環境におけるデータ分析の正確性と信頼性を大幅に向上させることができます。
もう少し詳しく知りたい方は、以下の記事を参考にしてください。
選択バイアスの影響と事例分析
選択バイアスはビジネス決定において意思決定を誤らせる可能性があります。
選択バイアスが具体的にビジネス上の決定にどのような影響を与えるかを、幾つかの事例を通じて説明します。
事例:マーケティングキャンペーンの評価

背景
ある企業が新製品の市場投入を支援するための広範囲なマーケティングキャンペーンを実施しました。
このキャンペーンは、特定のオンラインプラットフォームと店舗でのプロモーションが含まれていました。キャンペーンの目的は、製品認知の向上と購入率の促進です。
データ収集
キャンペーン後、企業はキャンペーンに参加した顧客群からの購入データを収集しました。
このデータには、キャンペーン期間中に特定のプロモーションコード(例:購入者が特典を得るために使用するコード、など)を使用した顧客の購入履歴が含まれています。
バイアスの問題
分析において、以下の重要な側面が見落とされました。
自己選択の影響
- キャンペーンに積極的に参加した顧客は、元々この企業や製品に対して肯定的な見解を持っているか、新しい製品に対する関心が高い可能性があります。
- これにより、キャンペーン参加者は非参加者に比べて購入意欲が自然と高い傾向にあります。
非参加者の無視
- キャンペーンに参加しなかった顧客群の購入データが分析から除外されたため、キャンペーンの効果が全顧客に対してどのように影響したかの全体像が欠けています。
- 非参加者の中には、プロモーションの影響を受けずに製品を購入したり、または全く購入しなかったりした顧客が含まれます。
この自己選択の影響と非参加者の無視は、マーケティングキャンペーンの効果を過大評価するリスクを生み出します。
実際には、キャンペーンが購入意欲に与えた影響を正確に測定するには、参加者と非参加者の両方のデータを包括的に分析し、両群間の既存の行動差を考慮する必要があります。
対策
このような選択バイアスの問題に対処するためには、以下のアプローチが有効です。
比較群の設定
キャンペーン参加者と非参加者の両方を包含するデータセットを使用し、両群間での購入行動の違いを分析します。
統計的調整
傾向スコアマッチングなどの手法を用いて、参加者と非参加者の比較を調整し、より公正な比較が可能になります。
感度分析
異なるシナリオや仮定のもとでの分析を行い、結果のロバスト性を評価します。
このように選択バイアスを理解し、適切なデータ収集と分析手法を適用することで、マーケティングキャンペーンの真の効果をより正確に評価することが可能となります。
これにより、企業はデータに基づく正確なビジネス戦略を展開することができます。
事例:従業員満足度調査

従業員満足度調査における選択バイアスの問題を対処することで、ビジネスリーダーはこの問題の深刻さと、それが組織全体に与える潜在的影響を理解するのに役立ちます。
背景
この企業では、従業員の満足度を測定し、そのフィードバックを基に職場環境の改善を図るために定期的にアンケート調査を実施しています。
アンケートは通常、仕事の内容、労働条件、管理体制、職場のコミュニケーション、報酬や福利厚生など、さまざまな側面について質問を含みます。
バイアスの問題
非代表的な回答の問題
- 従業員アンケートにおいて、非常に満足している従業員や不満を強く感じている従業員が積極的に回答する傾向があります。
- これにより、平均的または中間的な満足度を持つ大多数の従業員の意見が無視される可能性があります。
自己選択バイアス
- 回答者自身が自分の意見を声に出すことに価値を見出すか、または自己表現の機会としてアンケートに答えるため、特定のタイプの従業員のみが回答を提供することで、結果にバイアスがかかります。
これらのバイアスによって、極端な意見だけが反映され、実際には必要ではない改善策を採用してしまうリスクがあり、不満を持つ少数派に焦点を当て過ぎることで、実際には多くの従業員が支持しているポリシーやプログラムを誤って変更してしまう可能性があります。
アンケートが一部の従業員によって支配されていると感じた場合、他の従業員は無視されていると感じることがあり、これが全体のエンゲージメントや満足度をさらに低下させる原因になります。
対策
全従業員の参加を促進
アンケートの重要性を強調し、すべての従業員に対して回答を促すコミュニケーション戦略を実施します。
インセンティブの提供
回答を促すために小さな報酬や抽選での賞品など、インセンティブを提供することが効果的です。
匿名性の保証
従業員が自由に意見を表明できるよう、アンケートの匿名性を保証します。
このようなアプローチにより、従業員からのフィードバックがよりバランスの取れたものになり、組織全体としてより正確かつ効果的な意思決定が可能になります。
この問題を解決することで、組織は全体の従業員満足度を真に把握し、改善のための適切な措置を講じることができます。
サンプリング戦略とデータ収集の改善
選択バイアスを最小化するためには、サンプリング戦略とデータ収集方法の工夫が必要です。
これにより、研究サンプルが母集団を正確に代表することが保証され、より信頼性の高いデータ分析が可能になります。
サンプリング戦略が適切であればあるほど、収集されたデータは母集団の特性を正確に反映し、バイアスのリスクが低減されます。

以下、代表的なサンプルの確保方法です。
無作為サンプリング
- 各個体が同じ確率で選ばれるサンプリング方法です。
- これにより、母集団の特性を平等に反映することが可能になり、選択バイアスが最小限に抑えられます。
- ただし、母集団からランダムにサンプルを抽出できる場合に限られます。
- ランダム化によって交絡要因が均等に分布するため、因果効果の推定値が得られます。
層別サンプリング
- 母集団を重要な特性(例:年齢、性別、地域)に基づいて複数の層に分け、各層から無作為にサンプルを抽出します。
- これにより、各層が適切に代表され、データの全体的なバランスが保たれます。
- ただし、母集団が異質な部分集団(層)に分けられ、各層の特性が既知の場合に限られます。
- 層内の交絡要因が均等に分布すれば、因果効果の推定値が得られます。
クラスターサンプリング
- 母集団をグループ(クラスター)に分け、ランダムにいくつかのクラスターを選んで、選ばれたクラスター内の全個体を調査します。
- これは地理的または組織的に分散した母集団に対して効率的な方法です。
- ただし、母集団が自然に集まったグループ(クラスター)で構成され、クラスター内の相関が高い場合に限られます。
- クラスター内の交絡要因が均等に分布すれば、因果効果の推定値が得られます。
さらに、以下のようなデータ収集方法の改善を実施すると効果的です。
多様なデータ収集チャネルの利用
オンライン調査だけでなく、郵送、電話インタビュー、フェイス・トゥ・フェイスのインタビューを組み合わせることで、さまざまな背景を持つ対象者からデータを収集します。
フォローアップの実施
非応答者に対するフォローアップを行い、彼らが調査に参加する機会を増やすことで、非応答によるバイアスを減らします。
統計的手法による選択バイアスの緩和

理想は、サンプリング戦略とデータ収集方法で選択バイアスに対処する方法です。
しかし、対処できない場合も少なくなりません。特に観察研究やビジネス活動で発生したデータなどの既に収集されたデータセットを使用している場合には、統計的手法を用いることが一般的です。
これらの手法は、データ分析段階でバイアスの影響を最小化するのに役立ちます。
回帰調整
回帰分析を用いて、選択バイアスの可能性がある共変量をコントロールします。
この方法は、バイアスが引き起こされる可能性がある特定の変数(例えば、年齢、性別、所得など)に対する影響を数学的に調整し、他の変数との関連性を明確にします。

たとえば、ある病院が患者の満足度を向上させるために新しいサービスを導入したとします。
この新しいサービスモデルの効果を評価するために、病院は患者満足度調査を実施しました。
しかし、患者の年齢、性別、病歴(慢性病の有無など)、治療の種類(外来または入院)、そして経済的背景が満足度に影響を及ぼす可能性があります。
特に、経済的背景がこのサービスを利用するかどうかという選択に影響を与えている可能性が拭えません。

以下、回帰調整の流れです。
1.データ収集
患者から得られるすべての関連データ(年齢、性別、病歴、治療の種類、経済的背景、満足度スコア)を収集します。
2.モデルの選定
満足度を従属変数とし、上記の変数を独立変数とする多変量線形回帰モデルまたはロジスティック回帰モデルを構築します。
3.変数の組み入れ
特に選択バイアスが疑われる変数(例えば、経済的背景がサービスにアクセスする能力に影響を及ぼす可能性がある場合)をモデルに含めます。
4.モデルの推定
回帰分析を行い、各変数の係数を推定します。これにより、他の全ての変数が一定の場合に、新しいサービスが満足度にどの程度影響を与えるかを数値的に評価できます。
5.結果の解釈
得られた係数を用いて、新しいサービスモデルの効果を他の共変量から独立して評価します。例えば、経済的背景の効果をコントロールした上で、サービスの導入が満足度に正の影響を与えているかどうかを検討します。
この分析により、新しいサービスが特定の患者群に対してどのような効果を持っているかを明確にすることができます。
また、どの患者群がこのサービスから恩恵を受けやすいか、あるいは逆に影響が少ないかも識別可能になります。
逆確率重み付け(IPW)
逆確率重み付け(IPW)は、観察研究において選択バイアスを調整するために広く使用される方法です。
この手法では、傾向スコアを用いて各個体が研究サンプルに含まれる確率を推定し、その逆数を重みとして使用して分析を行います。
これにより、非ランダムにサンプリングされたデータにおけるバイアスを効果的に緩和できます。

しかし、薬剤Aの処方は特定の臨床的特徴や医師の判断に基づいており、ランダムに割り当てられたわけではありません。
したがって、薬剤を使用する患者群と使用しない患者群の間には初めから差が存在する可能性があります。

以下、IPWの適用の流れです。
1.傾向スコアの推定
ロジスティック回帰モデルを使用して、患者が薬剤Aを処方される確率(傾向スコア)を推定します。このモデルには、年齢、性別、既存の健康状態、過去の治療歴などの変数が含まれます。
2.重みの計算
各患者の傾向スコアに基づいて、逆確率重みを計算します。具体的には、治療を受けた患者に対しては \frac{1}{傾向スコア} の重みを、治療を受けなかった患者に対しては \frac{1}{1-傾向スコア} の重みを割り当てます。
3.重み付き分析
重みを適用してデータ分析を行います。重み付きのデータセットを使用して、薬剤Aの治療効果に関する統計的分析を行い、薬剤Aが心血管疾患のアウトカムにどのように影響を与えるかを評価します。
重み付けを行うことで、薬剤Aを使用する患者群と使用しない患者群の間の選択バイアスが調整され、より正確な治療効果の推定が可能になります。
この分析により、薬剤Aの真の効果をより正確に理解し、その情報を基にさらなる臨床的判断や政策決定が行えるようになります。
傾向スコアマッチング
傾向スコアマッチングは、観察研究で広く使用される統計的手法です。
この方法では、処置群とコントロール群の間で類似した特性を持つケースをマッチングすることで、ランダム化試験のようなバランスの取れた比較を可能にします。
傾向スコアは、ある個体が処置を受ける確率を推定するスコアで、多くの場合ロジスティック回帰モデルを使用して計算されます。

そこで、既存の患者データベースを利用して、この新薬の効果を観察研究で評価することになりました。

以下、傾向スコアマッチングの適用の流れです。
1.傾向スコアの推定
ロジスティック回帰モデルを使用して、各患者が新薬を使用する確率(傾向スコア)を推定します。このモデルには、年齢、性別、病歴、その他の健康状態、生活習慣など、薬剤使用の選択に影響を与える可能性がある共変量が含まれます。
2.マッチングの実施
計算された傾向スコアを基に、処置群(薬剤を使用している患者群)の患者と最もスコアが近いコントロール群(薬剤を使用していない患者群)の患者をペアリングします。通常、1:1マッチングが行われ、最も近いスコアを持つケース同士が選ばれます。
3.比較分析
マッチング後のデータセットを用いて、新薬の効果(例:血糖コントロールの改善)を分析します。マッチングにより、両群間の基本的な特性が類似しているため、治療効果の比較がより公正に行われます。
新薬の使用が糖尿病患者の血糖値に有意な改善をもたらしたかどうかを評価します。
傾向スコアマッチングにより、選択バイアスが効果的に緩和されているため、得られた結果は新薬の真の効果をより正確に反映していると考えられます。
操作変数法
操作変数法(Instrumental Variable, IV)は、観察研究において潜在的な選択バイアスや交絡因子の問題を解決するために使用される統計的手法です。
この方法は、ランダム化試験が実施不可能または非現実的な場合に特に有効です。
操作変数は、目的変数(アウトカム)には直接的な影響を与えず、説明変数(介入または治療)にのみ影響を与える変数です。
この特性を利用して、因果関係の推定を行います。
ただし、教育レベルは自己選択に基づく可能性が高く、よりモチベーションが高い、または経済的に恵まれた個人が高等教育を受けることが多いため、単純な回帰分析では教育の真の効果を正確に把握することができません。
1.操作変数の選択
教育の効果を正確に把握するために、「大学からの距離」を操作変数として使用します。この変数は大学教育を受けるかどうかに影響を与える可能性がありますが、直接的にはその人の収入には影響を与えません(大学から遠いと高収入な職につけないわけではない)。
2.第一段階の回帰
大学からの距離を説明変数とし、教育レベル(学歴:中卒・高卒・専門卒・短大卒・大卒・院卒・博士)を目的変数とする回帰分析を実施します。
3.第二段階の回帰
第一段階で得られた予測値(学歴)を使用して、収入に対する教育の影響を評価する回帰分析を行います。
この手法により、選択バイアス(自己選択による教育受講)が調整され、教育が収入に与える真の影響がより正確に推定されます。
操作変数法は、単純な回帰分析では観察できない因果効果を明らかにするのに役立ちます。
選択バイアスへの感度分析

感度分析は、導き出した結果が特定の仮定や手法にどれほど依存しているかを評価するために用いられる手法です。
選択バイアスに対する感度分析は、バイアスが因果推論の結論に与える潜在的な影響を理解し、研究結果の堅牢性を検証するのに役立ちます。
異なる調整戦略の比較
- 結果に対する異なる統計的調整手法の影響を評価します。
- 例えば、回帰調整、IPW、傾向スコアマッチングなど、複数の手法を用いて同一のデータセットを分析し、結果がどれほど変化するかを調べます。
異なる仮定の下での分析
- 研究の結果が特定の仮定に依存しているかどうかを評価するために、仮定を変更して複数のシナリオを作成し、それぞれのシナリオで結果がどう変わるかを観察します。
- これにより、仮定が結果に与える影響の大きさを測定できます。
バウンダリ分析
- 最悪の場合と最良の場合のシナリオを設定し、これらの極端な条件下で結果がどう変化するかを調査します。
- これにより、研究結果の信頼性の限界を把握できます。
感度分析の結果、特定のバイアスが結果に大きな影響を及ぼしている可能性が示された場合、さらなるデータ収集や異なる方法論を用いた追加の分析を実施した方がいいでしょう。
感度分析は、研究結果の信頼性を評価し、報告する際の重要なツールです。これにより、選択バイアスを含む様々な潜在的な問題に対する研究の感受性を明らかにし、データに基づいた議論をより透明で信頼性のあるものにすることができます。
まとめ
今回は、選択バイアスのビジネスの意思決定への影響と、その対処手法について簡単にお話ししました。
選択バイアスを無視することは、誤った結論につながり、政策決定、ビジネス戦略、さらには医療介入の効果評価など、多岐にわたる現場での意思決定に悪影響を及ぼす可能性があります。
紹介した調整手法を適切に用いることで、より正確で信頼性の高いデータ分析が可能になります。
ビジネス環境においては、データに基づく意思決定が日々の業務に不可欠です。選択バイアスの理解とその対策は、ビジネス戦略を練るうえでの客観的な洞察の確保に寄与します。