
統計解析や機械学習などで利用される数理モデルは多種多様です。
次から次へと新しいものが登場し、全体を捉えることはできません。
最新のものや流行のものを追うのもいいですが、先ずは基本的なものを抑えるのがいいでしょう。
基本的なものといっても、それはそれで色々あります。そのため、用途に応じて適切に選ぶ必要があります。
その選び方を示したチートシート(カンニングペーパー)があります。
今回は、「統計解析/機械学習モデルの選び方(チートシート)」というお話しをします。
チートシート(カンニングペーパー)
チートシート(カンニングペーパー)には幾つかありますが、もっともシンプルなものがMicrosoft社の次のチートシート(https://docs.microsoft.com/ja-jp/azure/machine-learning/studio/algorithm-cheat-sheet)です。
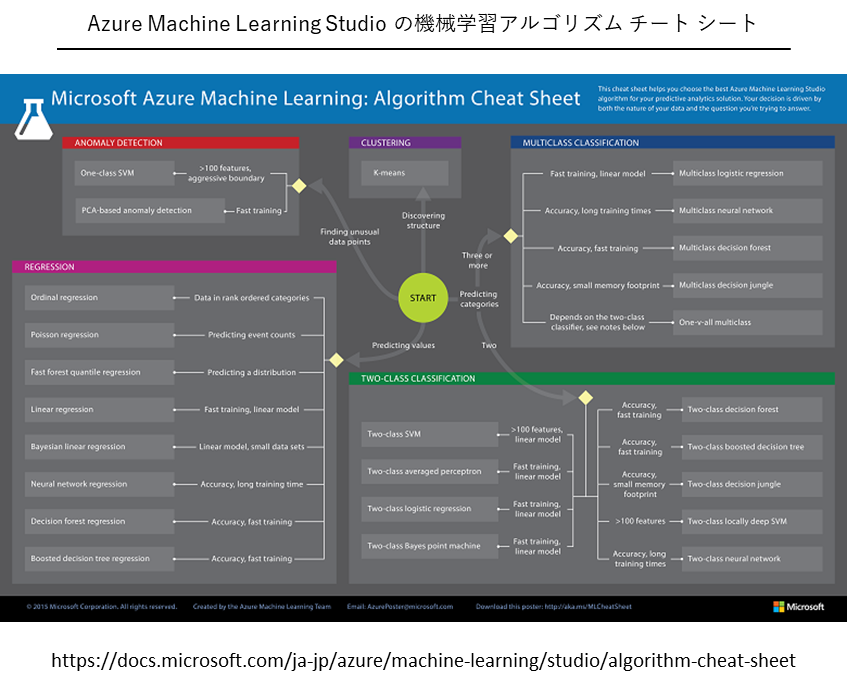
Microsoft社のAzure MLの中にある手法を選ぶときに利用します。
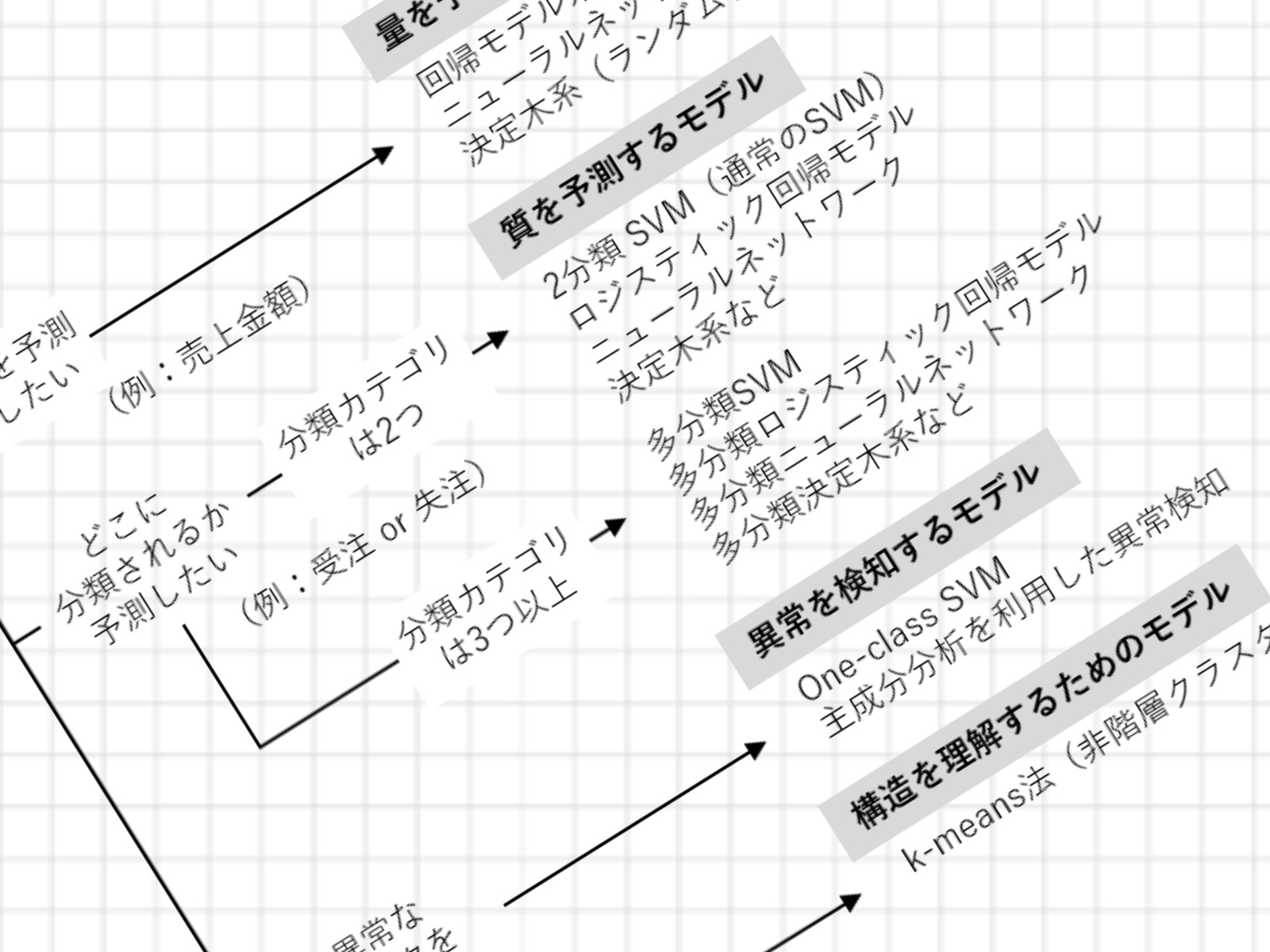
ざっくりチートシート
もっとシンプルにしたのが、次の「ざっくりチートシート」です。Microsoft社のチートシートを単純化し、用語も一般的ない葉で置き換えました。
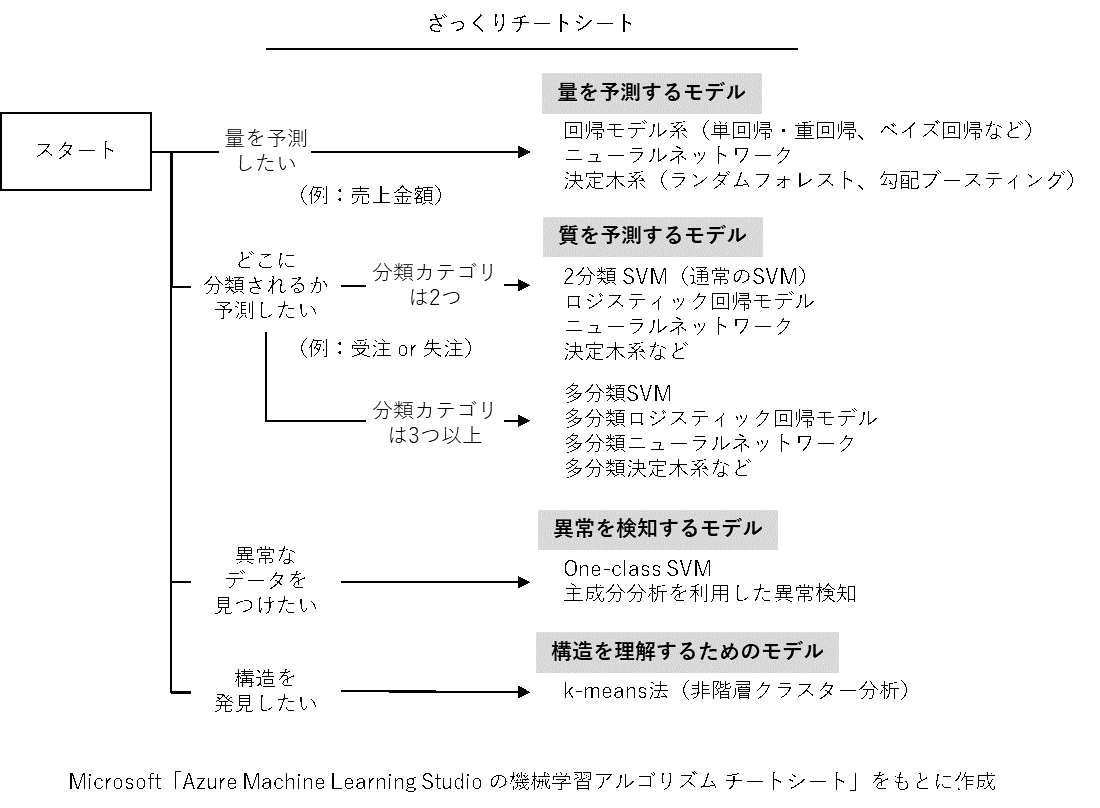
モデルの種類は以下の4つです。
- 量を予測するモデル
- 質を予測するモデル
- 異常を検知するモデル
- 構造を理解するためのモデル
量を予測するモデル
量を予測するモデルとは、売上金額や故障件数などの数量や件数(カウント数)を予測するためモデルです。
様々なモデルが考案されています。基本となるのが、単回帰モデルや重回帰モデルです。
単回帰モデルは説明変数が1つ、重回帰モデルは説明変数が2つ以上のケースです。
例えば、某店舗の日販(1日の売上金額)を目的変数とし、予測対象である日販に影響を及ぼす天候や販促などを説明変数にしたものです。
フィッシュボーンチャートで図示化すると、次のようになります。

フィッシュボーンチャート(魚の骨の図)とは、特性要因図とも呼ばれ、「特性」 (effect)と特性に影響を及ぼす「要因」 (factor)の関係を図示化したものです。
この例では、特性 (effect)が目的変数で、要因 (factor)が説明変数になります。
ある問題が起こったときに影響を及ぼした要因を「原因」 (cause) といいます。
フィッシュボーンチャートは非常に便利なもので、数理モデルの設計時や、問題の要因分析などに活用できます。
質を予測するモデル
質を予測するモデルとは、「受注 or 失注」や「良 or 不良」などの、どちらのカテゴリ(例:受注なのか失注なのか、良品なのか不良品なのか)に属するのかを予測するためのモデルです。
カテゴリの数は、「受注 or 失注」や「良 or 不良」などのように2種類である必要はありません。3種類でも、4種類でも問題ありません。基本は、2種類です。
こちらも、様々なモデルが考案されています。基本となるのが、線形判別モデルやロジスティック回帰モデルです。
例えば、予測対象である「受注の有無」(受注 or 失注)を目的変数とし、受注に影響を及ぼす営業活動や顧客行動などを説明変数にします。
フィッシュボーンチャートで図示化すると、次のようになります。

質を予測するモデルの多くは、確率(0以上1以下の数値)が出力されます。
「受注 or 失注」であれば受注確率もしくは失注確率、「良 or 不良」であれば良品確率もしくは不良品確率です。
どのカテゴリ(例:受注なのか失注なのか、良品なのか不良品なのか)に属するのか白黒つけたいときは、閾値を決める必要があります。
一番シンプルなのが0.5です。
受注確率が0.5を超えた段階で「受注カテゴリ」に分類する、などです。
よく量を予測するモデルと質を予測するモデルを一緒に使うことがあります。
例えば、次のように使い分けたりします。
- 「起こるかどうか」を予測(例:受注するかどうか) → 質を予測するモデル
- 受注した場合、「どの程度になりそうか」を予測(例:受注金額) → 量を予測するモデル
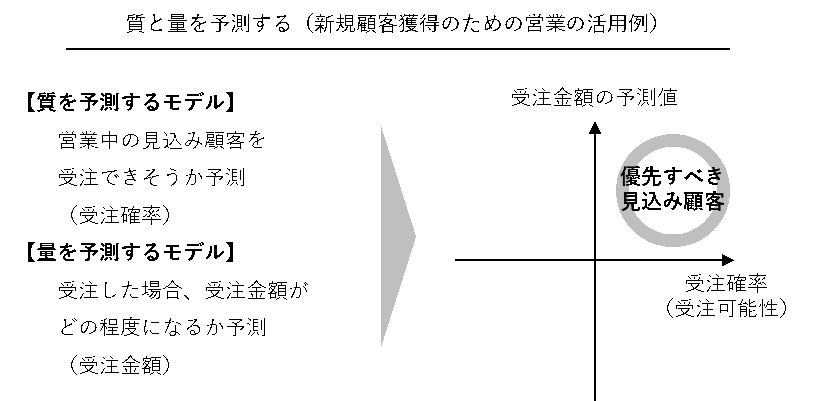
異常を検知するモデル
異常を検知するモデルは、機械に取り付けたセンサーの外れ値や機械そのものの故障、申込書の記入ミス、売上の変化点などを検知するためのモデルです。
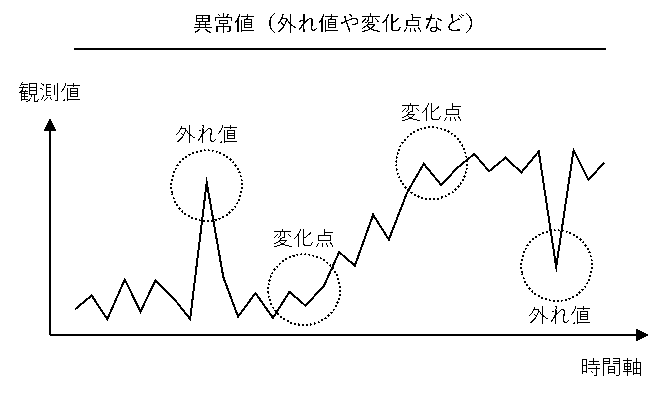
異常が悪いかどうかは、状況によるため注意が必要です。
故障の検知であれば異常は悪ですが、キャンペーンなどの効果測定であれば異常は善です。
例えば、キャンペーンの目的として一時的な売上アップがあるならば、そのキャンペーン期間中の売上は異常値になります。もし、売上が異常なぐらいアップしなければ、そのキャンペーンは失敗でしょう。

Microsoftのチートシートでは、2つの手法しか紹介されておりませんが、量を予測するモデルや質を予測するモデルも、異常を検知するモデルになりえます。
例えば、質を予測するモデルであれば、目的変数として「異常 or 正常」としモデルを構築することで、機械の故障の検知することができます。

例えば、量を予測するモデルであれば、目的変数として「見積金額」としモデルを構築することで、見積金額のミスを検知することができます。
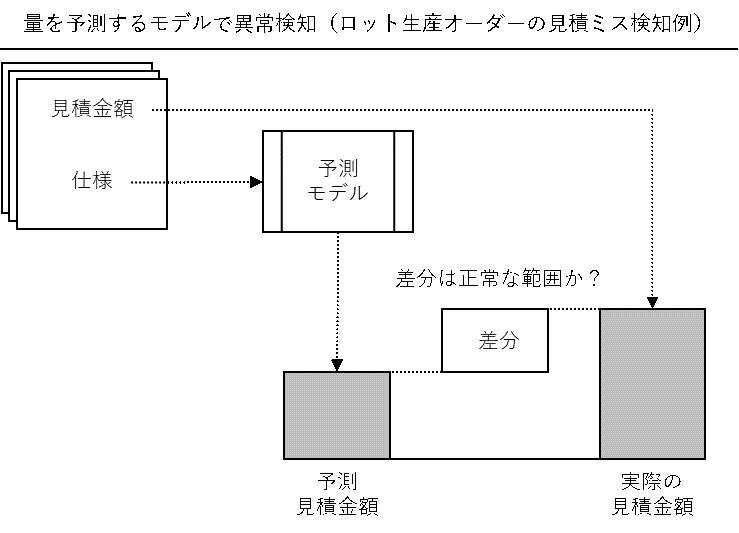
「モデルで予測した見積金額」と「提示された見積金額」が大きく異なる場合、異常と見なせます。
構造を理解するためのモデル
構造を理解するためのモデルとは、得られたデータの構造がどのようになっているのかを把握するためのものです。
直接何かの予測や検知に役立つというよりも、データそのものを理解するためであったり、思いがけない仮説を発見するためであったり、予測や検知のためのモデルを構築するための前段階の分析のためであったりすることが多いです。
Microsoftのチートシートで登場するのはクラスター分析(k-means法)だけです。
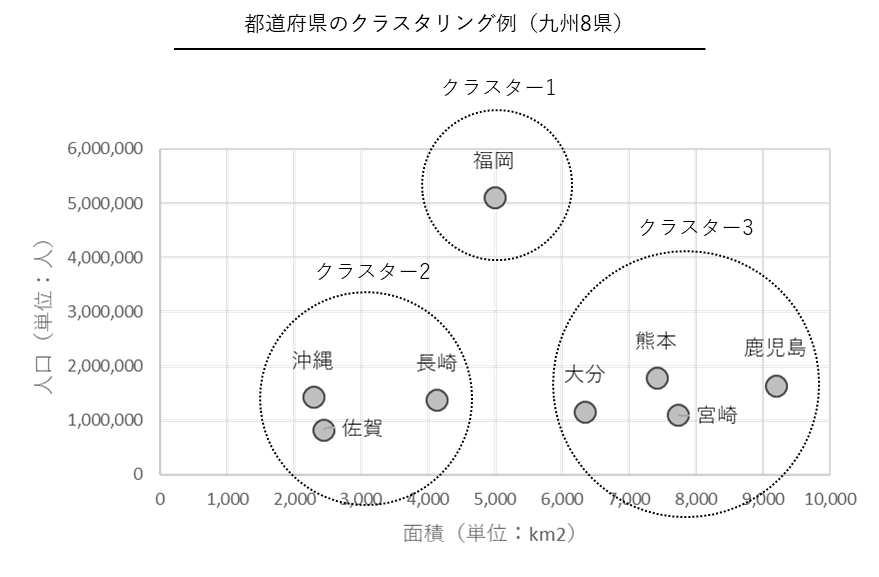
クラスター分析とは、個人や商品などをグループ分けする手法です。
同じグループに属する個人や商品などは、似たようなデータの値を持ちます。このグループをクラスターと呼びます。
今回のまとめ
今回は、「統計解析/機械学習モデルの選び方(チートシート)」というお話しをしました。
統計解析や機械学習などで利用される数理モデルは多種多様で、次から次へと新しいものが登場し、全体を捉えることはできません。
先ずは基本的なものを抑えるのがいいでしょう。
しかし、基本的なものといっても、それはそれで色々あり、用途に応じて適切に選ぶ必要があります。
その選び方を示したチートシート(カンニングペーパー)というものがあります。
もっともシンプルなものがMicrosoft社の次のチートシート(https://docs.microsoft.com/ja-jp/azure/machine-learning/studio/algorithm-cheat-sheet)です。
Microsoft社のAzure MLの中にある手法を選ぶときに利用します。
モデルの種類は以下の4つです。
- 量を予測するモデル
- 質を予測するモデル
- 異常を検知するモデル
- 構造を理解するためのモデル
今回は、この4つのモデルについて簡単に説明しましたが、Microsoftのチートシートに登場しない、構造を理解するためのモデルは、他にもたくさんあります。
例えば、似たような傾向を持つデータ項目(変数)を集約する主成分分析や、データ項目間(変数間)の構造を描くグラフィカルモデリングなどです。
このように、チートシートに掲載されていないモデルも多く、正直十分とは思えません。
しかし、どのような数理モデルがあるのか、という感覚は掴んで頂けたと思います。
もう一つ有名なチートシートがあります。
物足りない方は、こちらを参考にするのもいいでしょう。
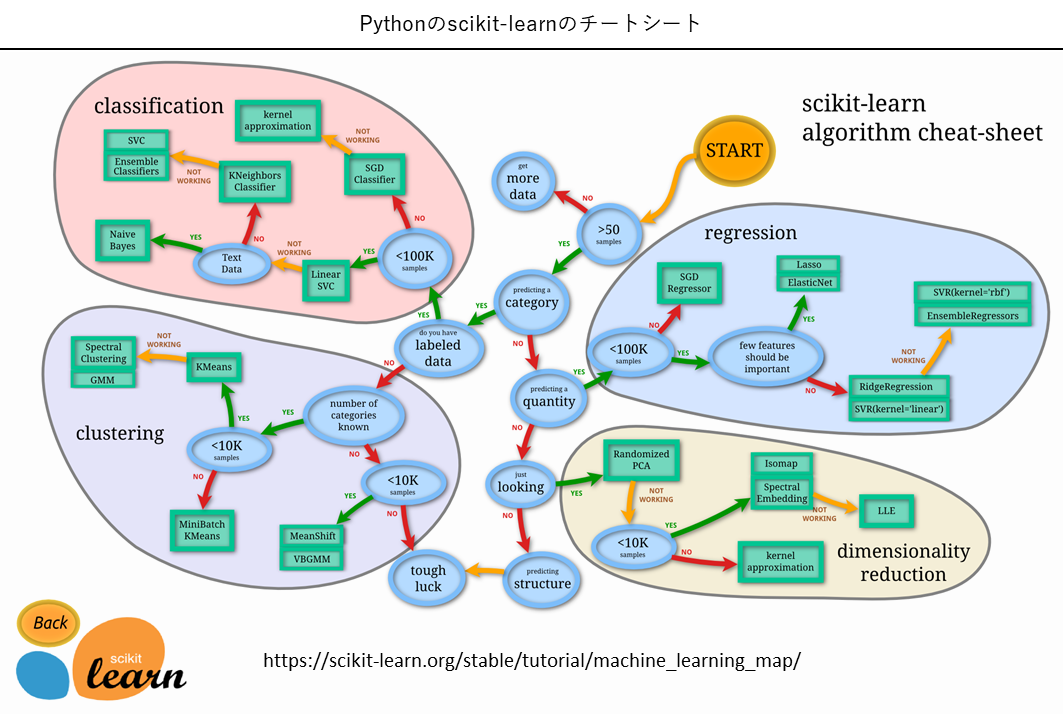
Pythonというプログラミング言語の機械学習のオープンソースライブラリscikit-learnの次のチートシート(https://scikit-learn.org/stable/tutorial/machine_learning_map/)です。
詳しくは説明しませんが、Microsoft社のチートシートは「用途」でモデルを選択する感じになっていたのに対し、Pythonのscikit-learnのチートシートは「データの状態」でモデルを選択する感じになっています。
ちなみに、Pythonは無料で使えるのが魅力で、データサイエンティストが好んで利用するツールの一つです。他には、Rもデータサイエンティストが好んで利用するツールで、こちらも無料で使えます。
Pythonは機械学習、Rは統計解析というイメージがありますが、最近ではできることも、構築できるモデルも似てきています。エンジニアよりの方はPythonが馴染みやすいかと思います。アナリストよりの方はRが馴染みやすいかと思います。
フリーツールが不安な方は、SPSSやSASなどの有料の分析ツールがあります。安く抑えたい方は、STATAがお勧めです。
STATAを扱うには、PythonやRを扱う程度のスキルが必要です。