
ビジネスでデータ活用をするとき、何かを予測をするために、数理統計学や機械学習などの数理モデル(分類問題・回帰問題)を構築することは、少なくありません。
例えば……
- 売上予測
- 受注予測
- 離反予測
- アップセル予測
- クロスセル予測
などなど。
このとき、試行錯誤しながら予測モデル(分類問題・回帰問題)を構築し、構築したモデルがどうなのかを解釈する必要がでてきます。
予測モデル(分類問題・回帰問題)を構築した後に実施する、数理モデルに対する分析は、ある程度定型化しています。
例えば……
- 予測精度を見る
- 特徴量(説明変数X)の重要度(目的変数Yとの関係性)を見る
- 個々の予測状況を見る
……などです。
さらに、もしある顧客が○○だったらどうなるのだろうかという、What-If分析を実施することもあります。
例えば……
- 問い合せから30分以内にメール連絡をしていたら、受注する可能性はどの程度増えたのか?
- 問い合せから30分以内にメール連絡ではなく電話連絡したら、受注の可能性はどうなったであろうか?
- 離反1カ月前までに1回コンタクトを取っていれば、離反される可能性はどの程度減ったのか?
- 買い替え時期の1カ月前に上位機種の説明資料を送ったら、上位機種にどの程度移ってくれそうか?
……などです。
もちろん定型化されない、探索的な分析もあります。しかし、いつもやるような分析も、このように多いです。
それを1つのダッシュボードでにまとめたのが、PythonのExplainer Dashboardです。
今回は、「Python の Explainer Dashboard で予測モデル(分類問題・回帰問題)の結果を半自動分析しよう」というお話しをします。
Contents [hide]
取り急ぎインストール
PythonのExplainer Dashboardを利用するためには、パッケージをインストールする必要があります。
以下、コードです。
conda install -c conda-forge explainerdashboard
pipでインストールされたい方は、以下です。
pip install explainerdashboard
サンプルデータ

Explainer Dashboardに、サンプルデータとして、みんな大好きタイタニックのデータセットが準備されています。
今回は、このタイタニックのデータセットをそのまま利用します。
次の3種類のデータセットを利用します。
- 生存予測用のデータセット(titanic_survive):2値の分類問題
- 出発港予測用のデータセット(titanic_embarked):多値の分類問題
- チケット運賃予測用のデータセット(titanic_fare):回帰問題
基本的な流れ
基本的な流れを簡単に説明します。
- 先ず、学習データとテストデータを作る
- 次に、学習データで予測モデルを構築する
- そして、構築したモデルをテストデータで検証する
最後の構築したモデルをテストデータで検証するところで、Explainer Dashboard を使います。
今回構築する予測モデル(分類問題・回帰問題)は、Pythonの有名な機械学習ライブラリーScikit-learn(sklearn)にあるランダムフォレストを使い構築します。
- 分類問題:RandomForestClassifier
- 回帰問題:RandomForestRegressor
Explainer Dashboard の表示項目

ランダムフォレスト(分類問題:RandomForestClassifier, 回帰問題:RandomForestRegressor)を使い構築した場合の、Explainer Dashboard のデフォルトの表示項目です。
- Feature Importances
- Classification Stats or Regression Stats
- Individual Predictions
- What if
- Feature Dependence
- Feature Interactions
- Decision Trees
色々カスタマイズできます。
ライブラリー読み込み
では、早速動かしてみたいと思います。最初に、必要なライブラリーの関数を読み込みます。
以下、コードです。
# ライブラリー読み込み from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor #数理モデル from explainerdashboard import ClassifierExplainer, RegressionExplainer, ExplainerDashboard, ExplainerHub #必要なExplainer Dashboardの関数 from explainerdashboard.datasets import titanic_survive, titanic_embarked, titanic_fare #サンプルデータ
予測モデルのダッシュボード構築
では、次の3つの問題で、Explainer Dashboard を実行していきたいと思います。
- 生存予測(titanic_survive):2値の分類問題
- 出発港予測(titanic_embarked):多値の分類問題
- チケット運賃予測(titanic_fare):回帰問題
最後に、3つのExplainer Dashboard のダッシュボードを1つにまとめたいと思います。
生存予測(titanic_survive):2値の分類問題
先ず、学習データとテストデータを作ります。
以下、コードです。
# 学習データとテストデータ X_train, y_train, X_test, y_test = titanic_survive()
学習データ(特徴量Xと目的変数Y)の中身を見てみます。
以下、特徴量Xの中を見るコードです。
X_train
以下、実行結果です。

以下、目的変数Yの中を見るコードです。
y_train
以下、実行結果です。

次に、学習データで予測モデルを構築します。
以下、コードです。
# モデル構築 model = RandomForestClassifier(n_estimators=50, max_depth=5) model.fit(X_train, y_train)
構築したモデルをテストデータで検証するために、Explainer Dashboard のダッシュボードを作ります。
以下、コードです。
# 数理モデルのダッシュボード
explainer = ClassifierExplainer(model, X_test, y_test)
db_cla = ExplainerDashboard(explainer,
title="Predicting survival on the Titanic")
db_cla.run()
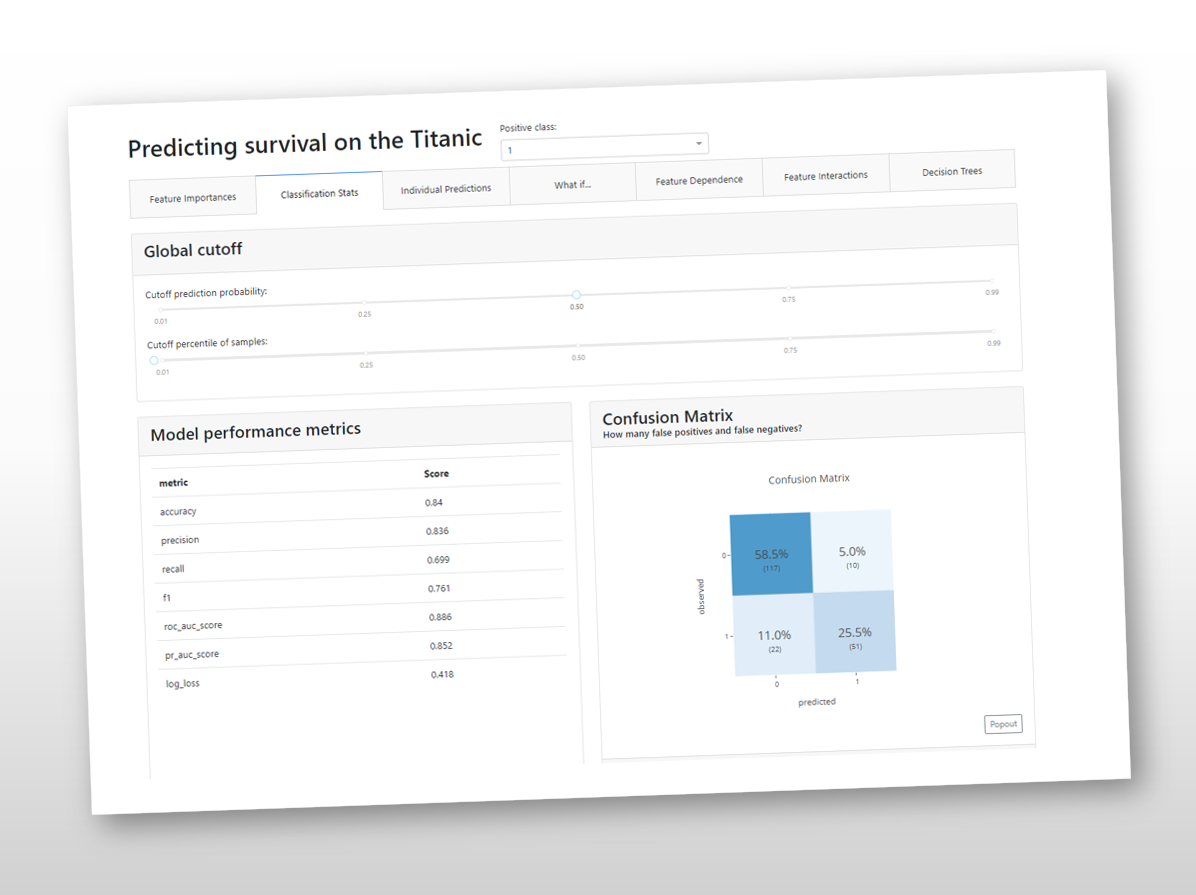
以下、実行結果です。
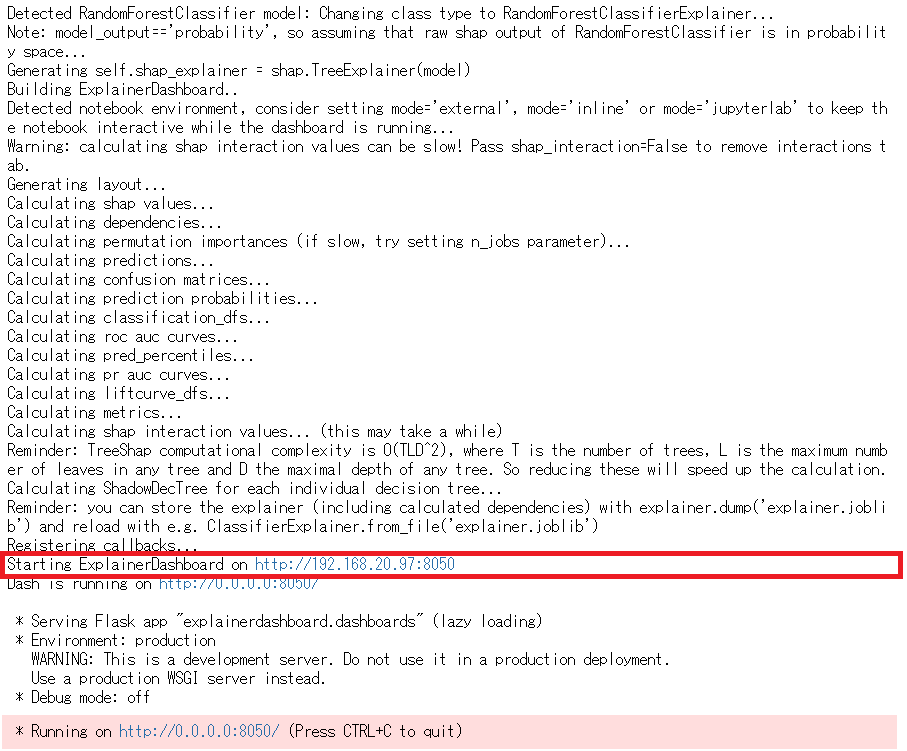
実行結果の中に「Starting ExplainerDashboard on (URLが表示)」という個所があります。そのなかの「(URLが表示)」のところをクリックすると、ダッシュボードが表示されます。
以下、表示されたダッシュボードです。
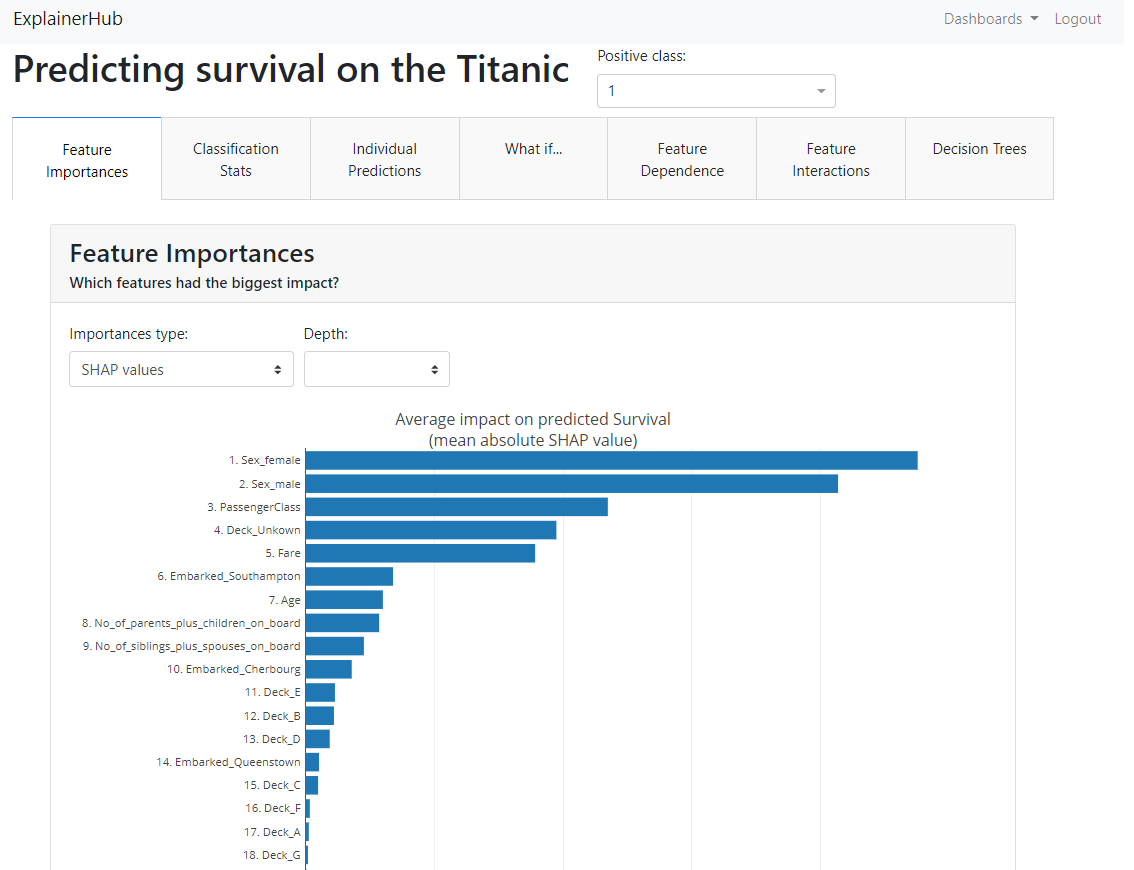
人によっては、Jupyter Notebookの中に、Explainer Dashboard を埋め込んで表示させたいという方もいることでしょう。可能です。
以下、コードです。
# 数理モデルのダッシュボード
explainer = ClassifierExplainer(model, X_test, y_test)
db_cla = ExplainerDashboard(explainer,
title="Predicting survival on the Titanic",
mode='inline')
db_cla.run()
違いは、5行目の「mode=‘inline’」にあります。これでJupyter Notebookの中に、Explainer Dashboard を埋め込んで表示させることができます。
ちなみに、表示されるものは変わりません。
出発港予測(titanic_embarked):多値の分類問題
先ず、学習データとテストデータを作ります。
以下、コードです。
# 学習データとテストデータ X_train, y_train, X_test, y_test = titanic_embarked()
学習データ(特徴量Xと目的変数Y)の中身を見てみます。
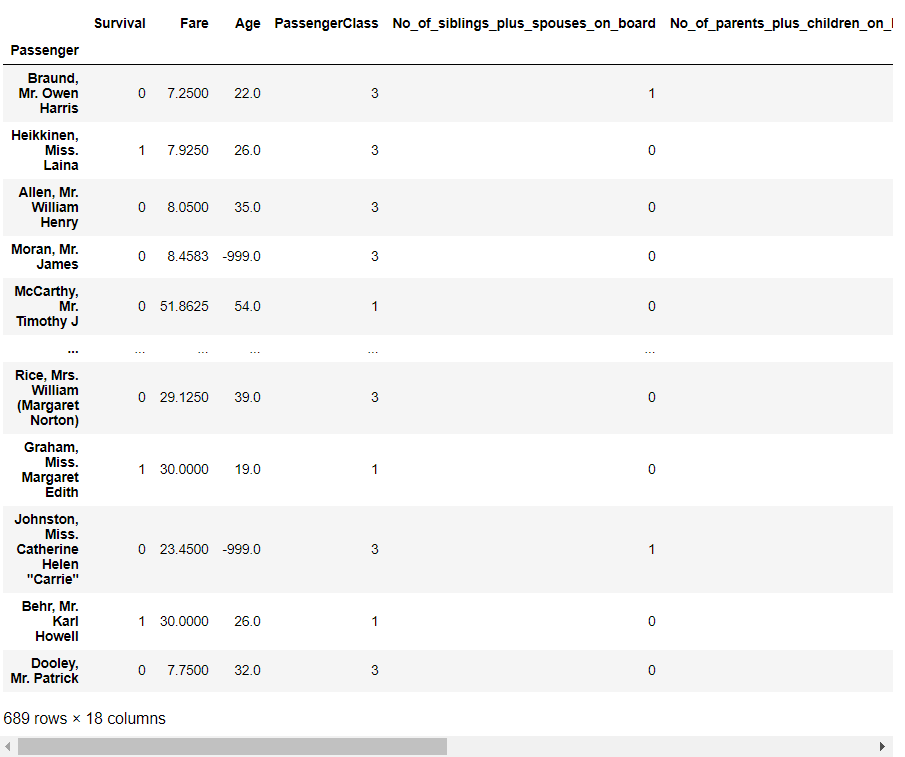
以下、特徴量Xの中を見るコードです。
X_train
以下、実行結果です。
以下、目的変数Yの中を見るコードです。
y_train
以下、実行結果です。

次に、学習データで予測モデルを構築します。
以下、コードです。
# モデル構築 model = RandomForestClassifier(n_estimators=50, max_depth=10) model.fit(X_train, y_train)
構築したモデルをテストデータで検証するために、Explainer Dashboard のダッシュボードを作ります。
以下、コードです。
# 数理モデルのダッシュボード
explainer = ClassifierExplainer(model, X_test, y_test)
db_mul = ExplainerDashboard(explainer,
title="Predicting departure port",
mode='inline')
db_mul.run()
以下、表示されたダッシュボードです。
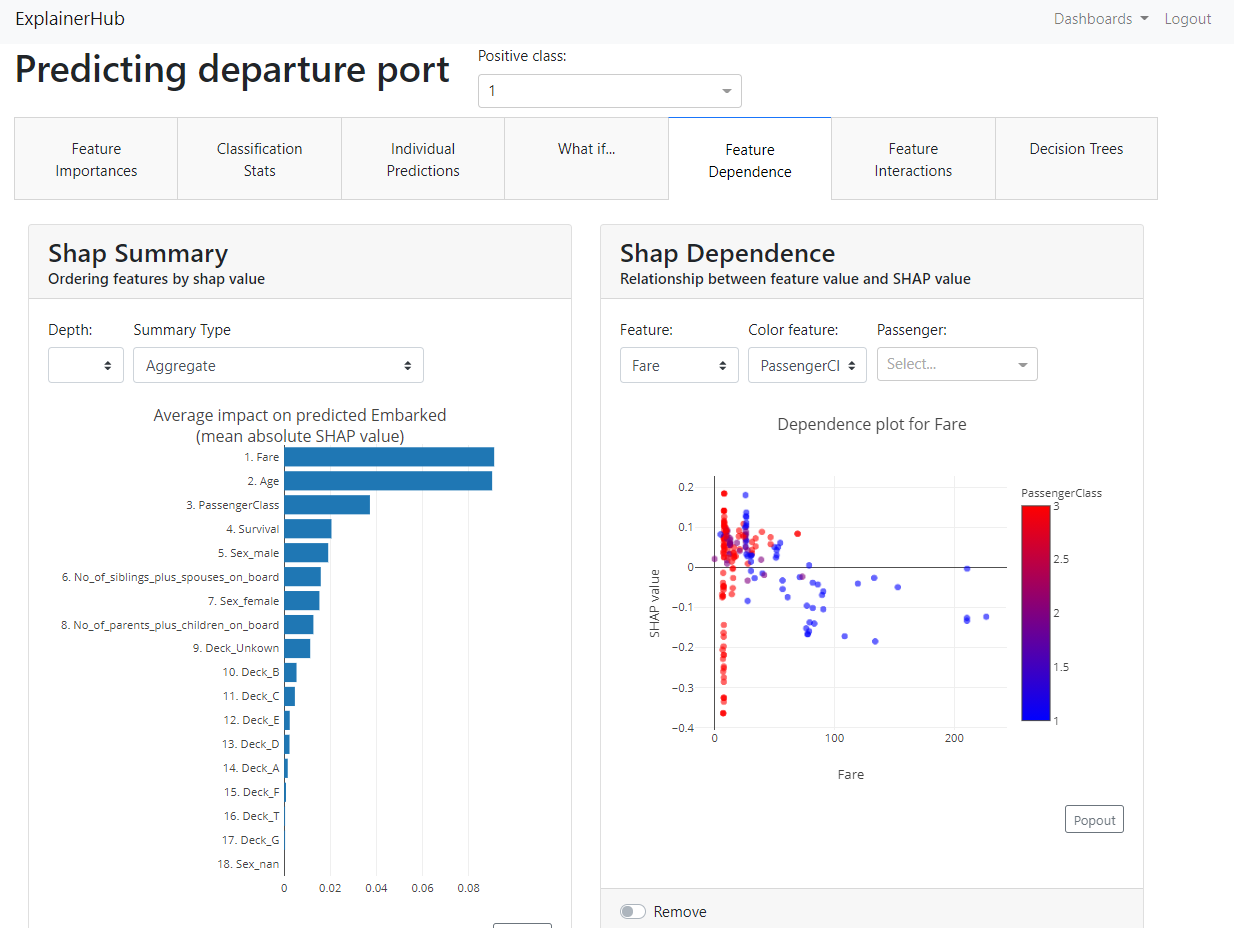
チケット運賃予測(titanic_fare):回帰問題
先ず、学習データとテストデータを作ります。
以下、コードです。
# 学習データとテストデータ X_train, y_train, X_test, y_test = titanic_fare()
学習データ(特徴量Xと目的変数Y)の中身を見てみます。
以下、特徴量Xの中を見るコードです。
X_train
以下、実行結果です。
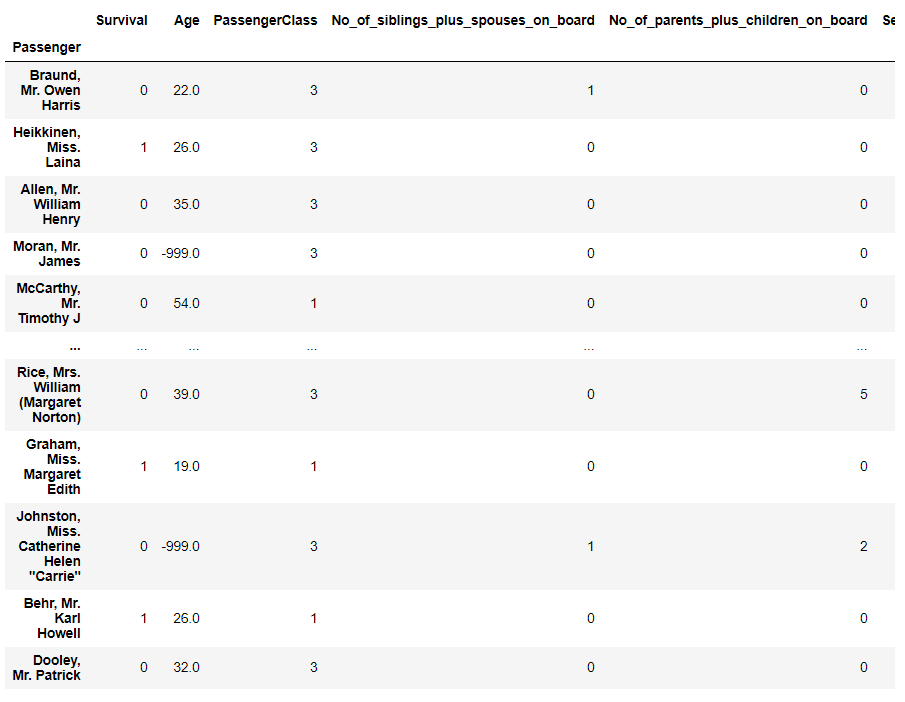
以下、目的変数Yの中を見るコードです。
y_train
以下、実行結果です。

次に、学習データで予測モデルを構築します。
以下、コードです。
# モデル構築 model = RandomForestRegressor() model.fit(X_train, y_train)
構築したモデルをテストデータで検証するために、Explainer Dashboard のダッシュボードを作ります。
以下、コードです。
# 数理モデルのダッシュボード
explainer = RegressionExplainer(model, X_test, y_test)
db_reg = ExplainerDashboard(explainer,
title="Predicting ticket fare",
mode='inline')
db_reg.run()
以下、表示されたダッシュボードです。
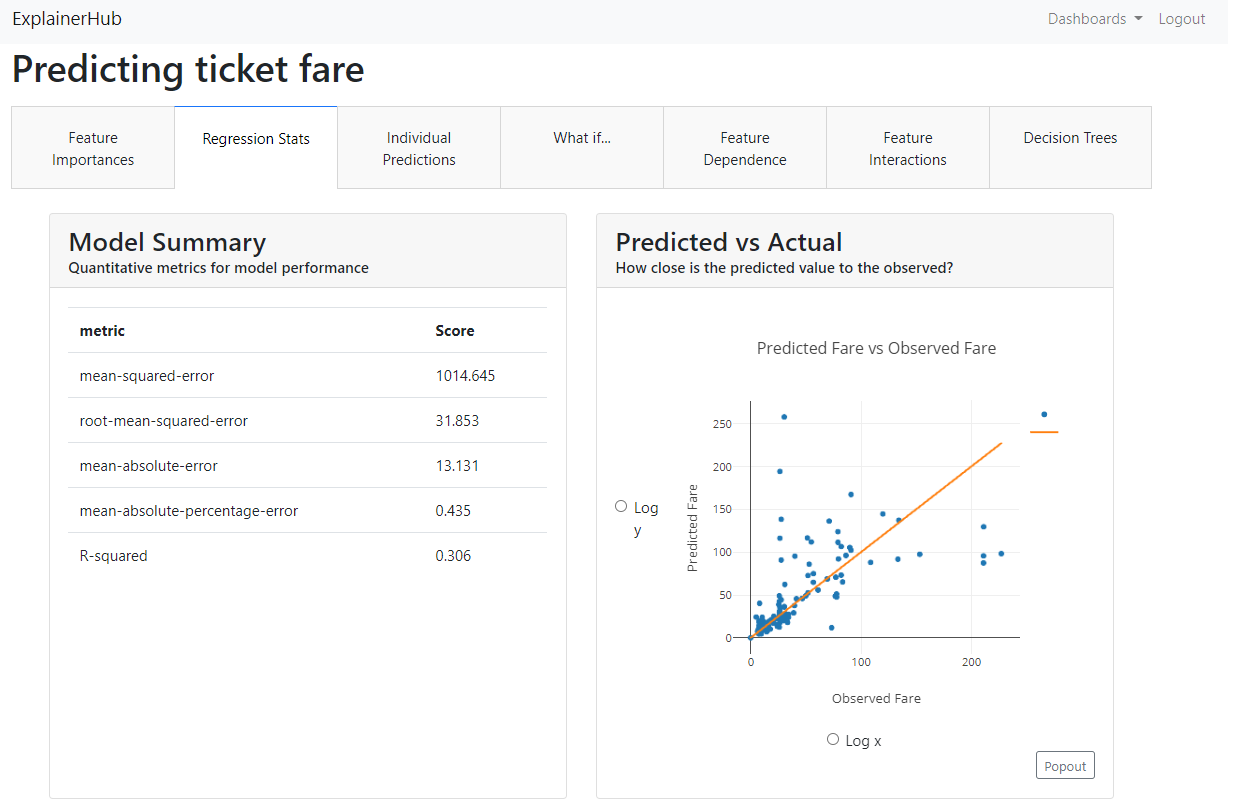
ダッシュボードの統合
今回、次の3つのダッシュボードを構築しました。
- 生存予測(titanic_survive):2値の分類問題
- 出発港予測(titanic_embarked):多値の分類問題
- チケット運賃予測(titanic_fare):回帰問題
最後に、3つのExplainer Dashboard のダッシュボードを1つにまとめたいと思います。
以下、コードです。
hub = ExplainerHub([db_cla, db_mul, db_reg]) hub.run()
以下、表示された統合化されたダッシュボードです。
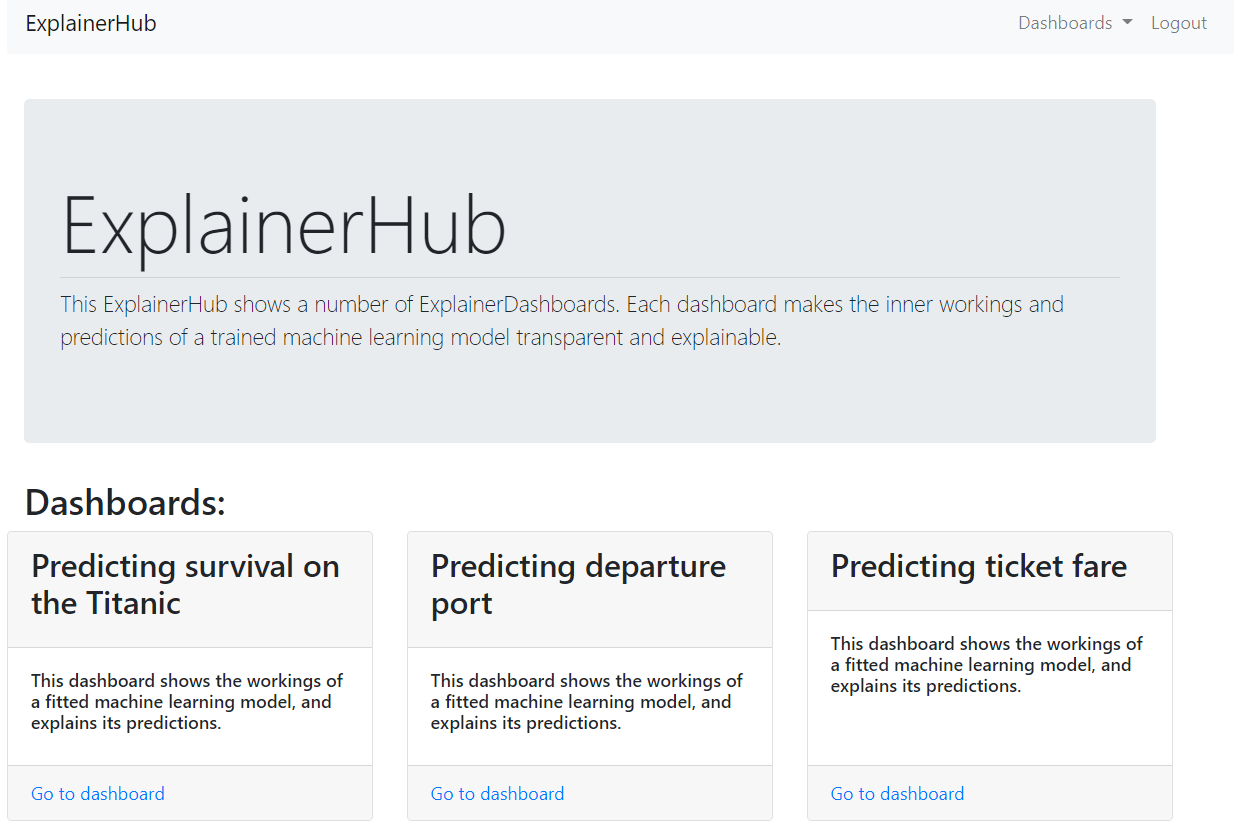
見たいダッシュボードの「Go to dashboard」をクリックすると、そのダッシュボードが表示されます。
まとめ
今回は、「Python の Explainer Dashboard で予測モデル(分類問題・回帰問題)の結果を半自動分析しよう」というお話しをしました。
予測モデル(分類問題・回帰問題)を構築し、構築したモデルがどうなのかを解釈する必要がでてきます。
予測モデル(分類問題・回帰問題)を構築した後に実施する、数理モデルに対する分析は、ある程度定型化しています。
それをまとめて表示できるようにしたのが、Explainer Dashboard です。
興味のある方は、試してみてください。