

Pythonでデータ分析をするとき、Pandasを使わない人はいないぐらいです。
Pandasの幾つかの機能を高速化するライブラリーがあります。
計算処理を並列化するPandaralellです。
ただ、すべての処理が高速化されているわけではありません。
今回は、「2行追加するだけでPython Pandasを高速化するPandarallel」というお話しをします。
Contents [hide]
取り急ぎインストール
以下、コードです。
pip install pandarallel
現在(2021年4月25日現在)は、Pandasの以下の機能を高速化できます。
| 通常のPandas | Pandarallelを利用するとき |
|---|---|
| df.apply() | df.parallel_apply() |
| df.applymap() | df.parallel_applymap() |
| df.groupby(args).apply() | df.groupby(args).parallel_apply() |
| df.groupby().col_name.rolling().apply() | df.groupby().col_name.rolling().parallel_apply() |
| df.groupby().col_name.expanding().apply() | df.groupby().col_name.expanding().parallel_apply() |
| series.map() | series.parallel_map() |
| series.apply() | series.parallel_apply() |
| series.rolling(args).apply() | series.rolling(args).parallel_apply() |
PandasのDataFrameやSeriesに、関数を適用させる方法の1つに、applyやapplymap、mapなどを使う方法があります。基本、このあたりを高速化するようです。
実際に利用するときは、元の関数の前に「parallel_」を付ける感じです。
通常のPandas : df.apply(func)
↓
Pandarallelを利用するとき : df.parallel_apply(func)
使う前の準備は簡単で、次の2行を実行するだけです。ライブラリーの読み込みと初期化です。
from pandarallel import pandarallel # ライブラリー pandarallel.initialize() # 初期化
実際に動かしてみる
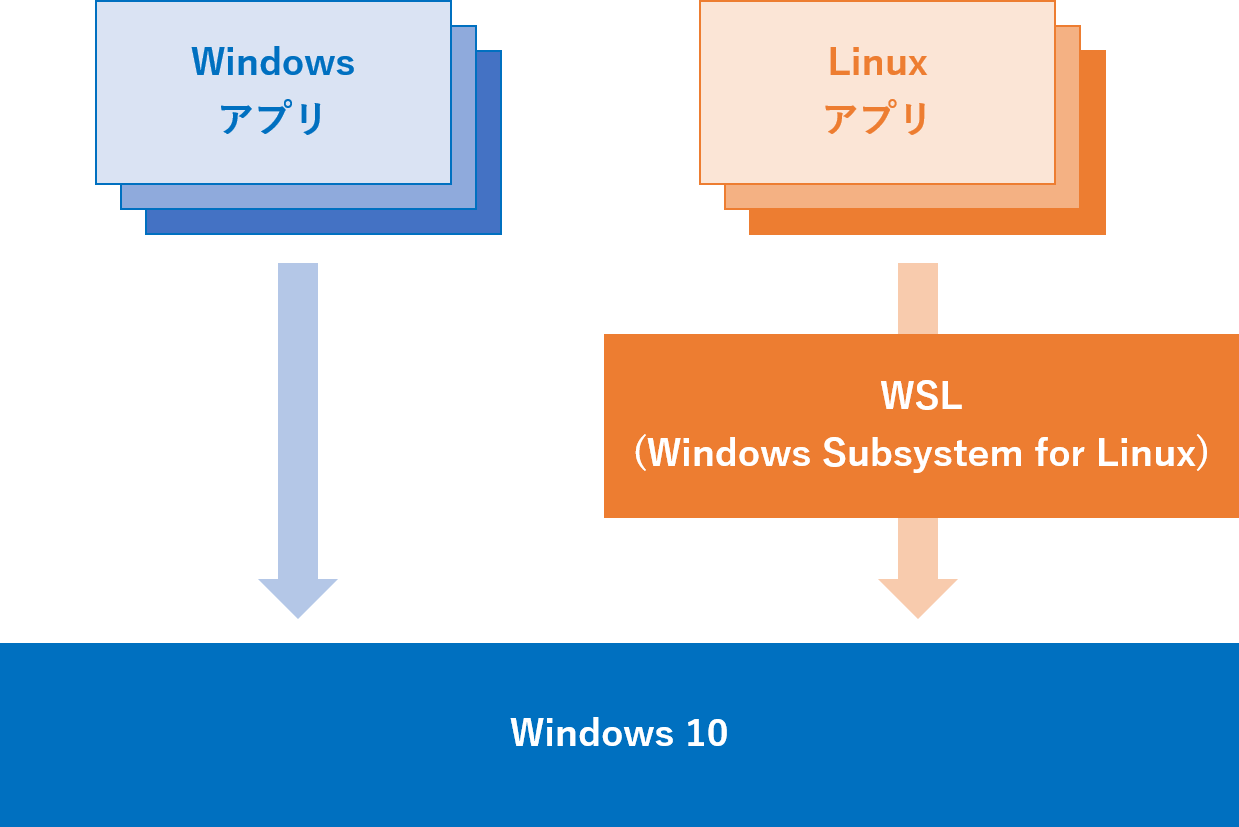
WindowsでもLinuxでもmacOSでも動かせますが、Windowsの方は注意が必要です。
Windows PC からPandarallelを使う場合には、WSL(Windows Subsystem for Linux)の設定が必要になります。
今回は、そういう煩わしさから逃れるために、すぐに使える環境であるGoogle Colaboratory(https://colab.research.google.com/notebooks/welcome.ipynb)上で動かしてみます。
Google Colaboratoryですので、Pandarallelを使っても、もしかしたら、それほどスピードに差が出ないかもしれません(多少出て欲しい……)。
ちなみに、どうしてもWindows PC上(Google Colaboratoryを通してではなく……)から動かしたい方は、以下を参考にWSL(Windows Subsystem for Linux)を設定していただければと思います。そうすると、Windows上でLinuxを動かすことができ、そのLinux上で動かしたPythonでPandarallelが使えます。
Windows PC上(Google Colaboratoryを通してではなく……)から動かしたい方
Windowsでは、WSL(Windows Subsystem for Linux)が必要になります。
以下を参考に設定して頂ければと思います。
Windows 10 用 Windows Subsystem for Linux のインストール ガイド
https://docs.microsoft.com/ja-jp/windows/wsl/install-win10
WSL (Windows Subsystem for Linux) とは、ざっくり言うとWindows上でLinuxプログラムを動作させ相互連携できるようにするためのものです。
WSL(Windows Subsystem for Linux)が設定されている方は、Windows上からLinux(例えばUbuntu)を起動させ、そこでPythonを動かすことでPandarallelを使うことができます。
Linux(例えばUbuntu)そのものは、Microsoft Store上からダウンロードできます。

Pandarallel
Google Colaboratoryのノートブック上で、最初に以下のコードを入力し、Pandarallelをインストールしてください。
pip install pandarallel

ライブラリーの読み込み
最初に必要なライブラリーを読み込み、Pandarallelを初期化します。
以下、コードです。
# 基本ライブラリー import numpy as np import pandas as pd import time import math # Pandarallelの準備 from pandarallel import pandarallel pandarallel.initialize()

流れ
データフレーム型のデータセットに対し、Pandasのapply関数を使い、定義した関数の処理を実施します。
定義する関数は、要素を2乗して足し平方根を求める簡単なものです。
手順は以下です。
- 関数を定義する
- サンプルデータを生成する
- apply関数で定義した関数の処理を実施する
- parallel_apply関数で定義した関数の処理を実施する
1. 関数の定義
要素を2乗して足し平方根を求める関数を作ります。特徴量は5つを想定しています。
以下、コードです。
# 関数の定義
def func(x):
return math.sqrt(x.x1**2 + x.x2**2 + x.x3**2 + x.x4**2 + x.x5**2)
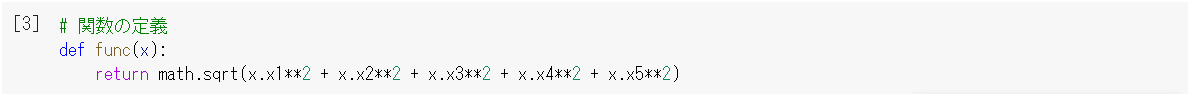
2. サンプルデータの生成
乱数を発生させてサンプルデータを生成します。特徴量は5つです。
以下、コードです。
# サンプルデータの生成
df_size = int(1e6)
df = pd.DataFrame(dict(x1=np.random.rand(df_size),
x2=np.random.rand(df_size),
x3=np.random.rand(df_size),
x4=np.random.rand(df_size),
x5=np.random.rand(df_size)))

3. apply関数で定義した関数の処理を実施する
先ず、通常のPandasのapply関数を使って、先ほど定義した関数の処理を実施したいと思います。
以下、コードです。
%%time res = df.apply(func, axis=1)
以下、実行結果です。

45.4秒でした。
ちなみに、プログレスバーを表示させたい方は、先ほどのコードを以下のようにします。
# Progressbarの表示 from tqdm import tqdm tqdm.pandas() %%time res = df.progress_apply(func, axis=1)
開発者のサイト(GitHub – nalepae/pandarallel: A simple and efficient tool to parallelize Pandas operations on all available CPUs)では、次のように表示されるようです。

4. parallel_apply関数で定義した関数の処理を実施する
次に、parallel_apply関数を使って、先ほど定義した関数の処理を実施したいと思います。並列処理化されているはずなので、少しは速くなっていると思います。
以下、コードです。
%%time res_parallel = df.parallel_apply(func, axis=1)
以下、実行結果です。

41.4秒でした。
確かに、少し速くなっているようです。
データ量を増やし、マシンのスペックを上げれば、差が出るかと思います。
開発者のサイト(GitHub – nalepae/pandarallel: A simple and efficient tool to parallelize Pandas operations on all available CPUs)では、次のようになっています。興味ある方は、確認してください。

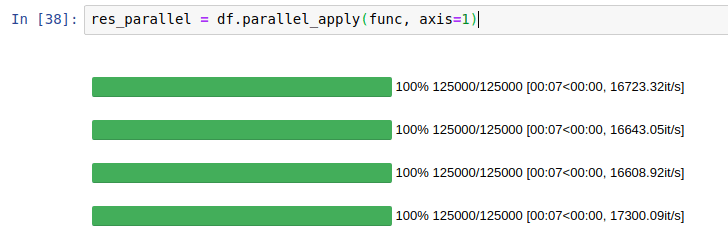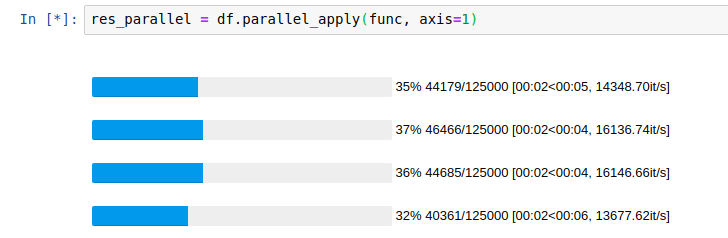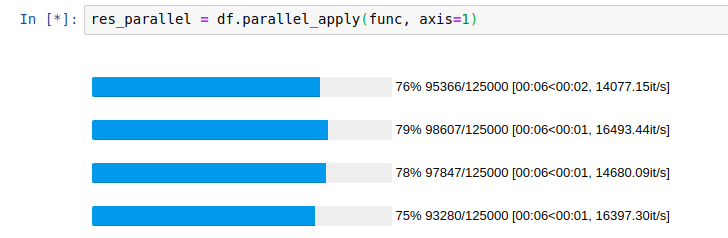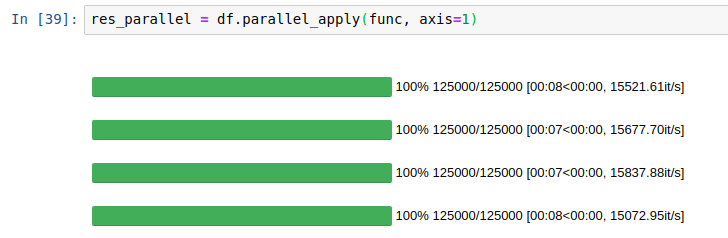
ちなみに、プログレスバーを表示させたい方は、先ほどのコードを以下のようにします。
# 初期化時にプログレスバーを表示させるようにする pandarallel.initialize(progress_bar=True) %%time res = df.progress_apply(func, axis=1)
開発者のサイト(GitHub – nalepae/pandarallel: A simple and efficient tool to parallelize Pandas operations on all available CPUs)によると、次のように表示されるようです。
注意点
並列処理による高速化です。
並列処理をするとき、「コアごとにプロセスを立ち上げ、データを各プロセスに受け渡し計算を実行し、その結果を各プロセスから受け取る」という感じで、計算処理の前後に別の処理が発生します。
例えば、データ量が少ない場合には、並列化することで処理速度が遅くなることがあります。
注意しましょう。
まとめ
今回は、「2行追加するだけでPython Pandasを高速化するPandarallel」というお話しをしました。
2行とは以下です。
from pandarallel import pandarallel pandarallel.initialize()
興味のある方は、試してみてください。