

PythonでEDA(探索的データ分析)を実施するとき、PandasのQuery(クエリ―)を使う方も多いことでしょう。
ここで紹介するQuery(クエリ―)は、Pandasの関数の1つで、データフレームに対し条件抽出するときに利用したりします。
よく使う平凡な使い方を紹介します。
ということで、今回は「比較的よく使うPandas Query(クエリ―)の簡単な条件指定例(Python)」というお話しです。
Contents [hide]
numexprを使おう!
PandasのQuery(クエリ―)を処理を高速化するライブラリーに、numexprというものがあります。
高速化といっても、数万行を超えるようなデータに対してなので、データセットの行数が少ない場合には意味はありません。
気になる方は、以下のURLを参考にしてください。
Pandas User Guide Enhancing performance
https://pandas.pydata.org/pandas-docs/stable/user_guide/enhancingperf.html
これといって害はないので、PandasのQuery(クエリ―)を使う方はインストールしておきましょう。
以下、numexprのインストールするときのコードです。
pip install numexpr
ちなみに、numexprをインストールはしているけど使いたくない場合には、query()の引数engineで指定できます。
engine=’python’とするとnumexprを使いません。明示的にengine=’numexpr’とすることもできますが、numexprがインストールされている場合にはデフォルトでnumexprが指定されるので意味はありません。
numexprがインストールされていないときには、engine=’python’がデフォルトになります。
1点注意点があります。文字列メソッドを使うときには、engine=’python’とする必要があります。後ほど例示します。
また今回は、Pandas-Profilingを利用してデータセットの概況(欠測状況など)を見ますので、インストールされていない方はインストールして頂ければと思います。
以下、コードです。
pip install pandas-profiling
Pandas-Profilingは必須ではありません。
ライブラリーとサンプルデータの読み込み
先ず、必要なライブラリーを読み込みます。
以下、コードです。
# ライブラリーの読み込み ## 基礎ライブラリー import pandas as pd ## 例で利用するデータセット from sklearn.datasets import fetch_openml ## EDAツール from pandas_profiling import ProfileReport
今回は、みんな大好きタイタニック(titanic)のデータを使います。
では、タイタニックのサンプルデータを読み込みます。
以下、コードです。
# タイタニック(titanic)のデータセット
titanicXy = fetch_openml("titanic", version=1, as_frame=True, return_X_y=False).frame
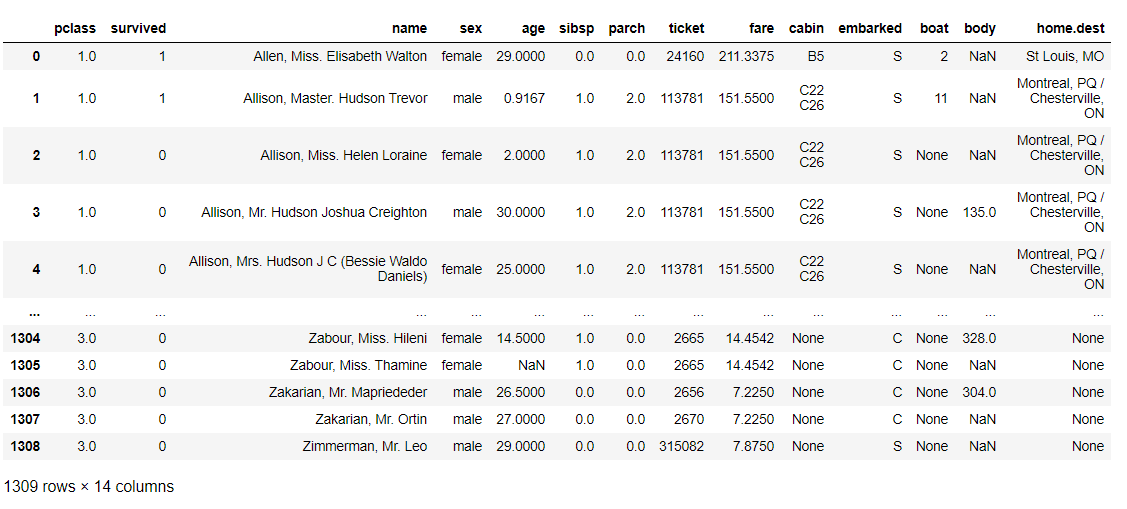
データセット「titanicXy」がどのようなデータなのかを見てみます。
以下、コードです。
titanicXy
以下、実行結果です。
次にPandas-Profilingを使い、どのようなデータなのか確認します。
以下、コードです。
profile_titanic = ProfileReport(titanicXy, explorative=True)
profile_titanic.to_file("profile_titanic.html")
profile_titanic
以下、実行結果です。
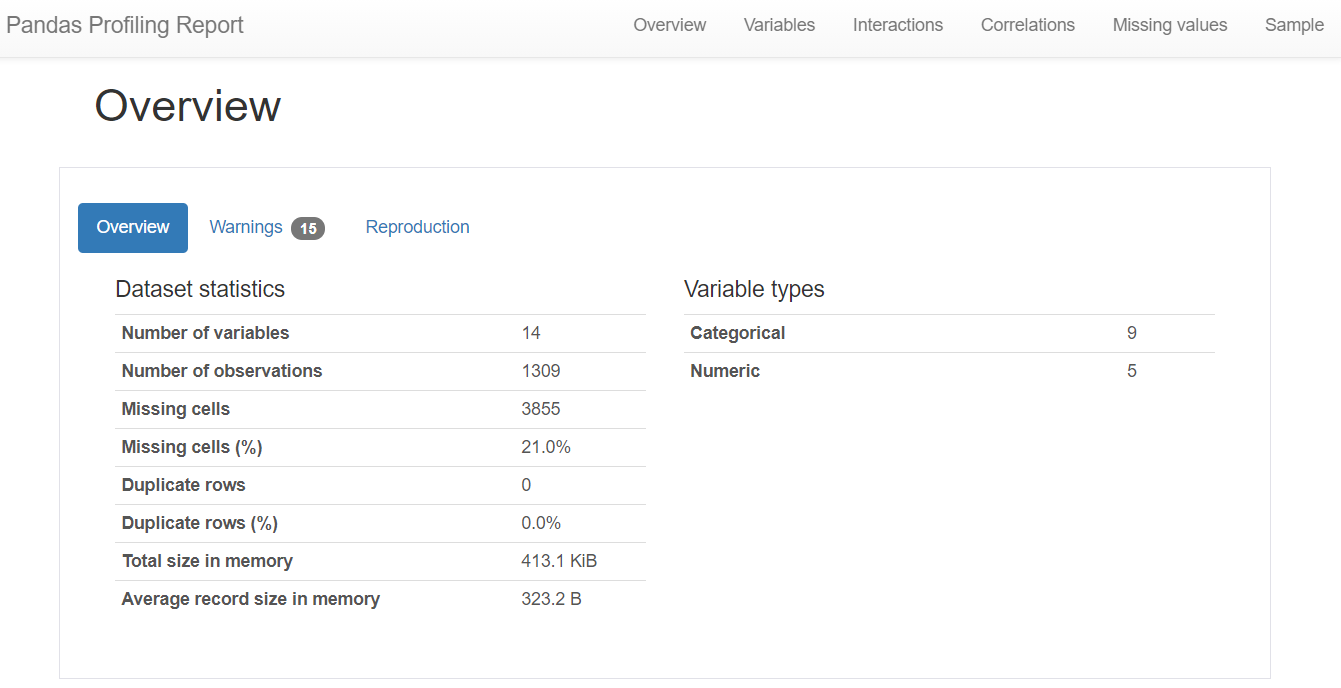
14変数(内、9変数がカテゴリカル、5変数が数値)×1309行のデータセットで、21%のデータが欠測しています。
紹介するquery()の条件指定例
今回紹介するquery()の条件指定例です。
- 欠測値指定によるデータ抽出
- 比較演算子で条件指定しデータ抽出
- in演算子(リスト)で条件指定しデータ抽出
- 文字列メソッドで条件指定しデータ抽出
- 変数を使って条件指定しデータ抽出
どれもオーソドックスな方法です。
欠測値指定によるデータ抽出
「age」に20.1%の欠測値が発生しています。
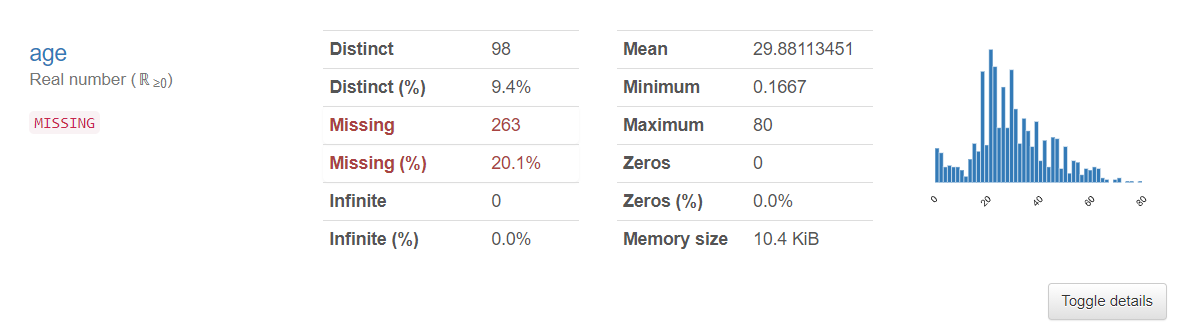
「age」が欠測している行を抽出してみます。
以下、コードです。
titanicXy.query('age != age')
以下、実行結果です。
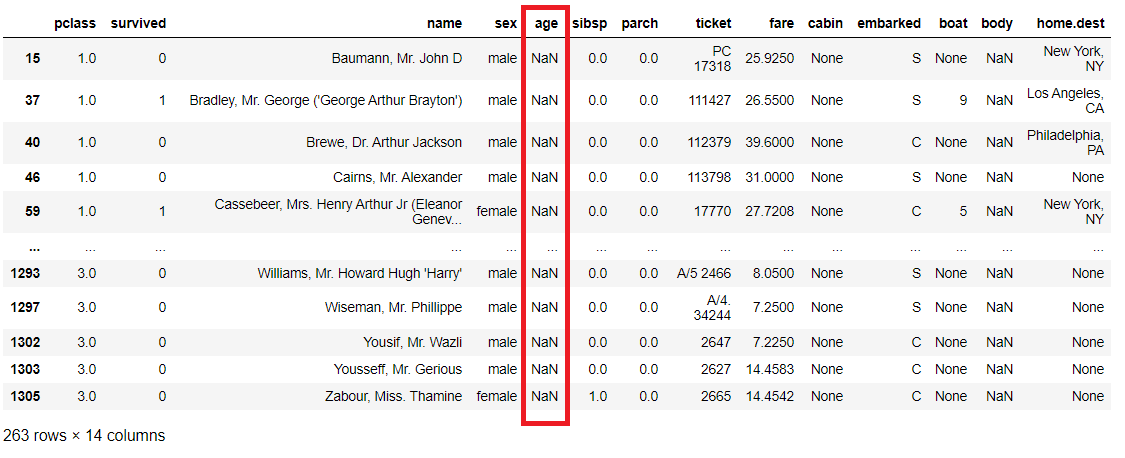
今度は、「age」が欠測していない行を抽出してみます。
以下、コードです。
titanicXy.query('age == age')
以下、実行結果です。
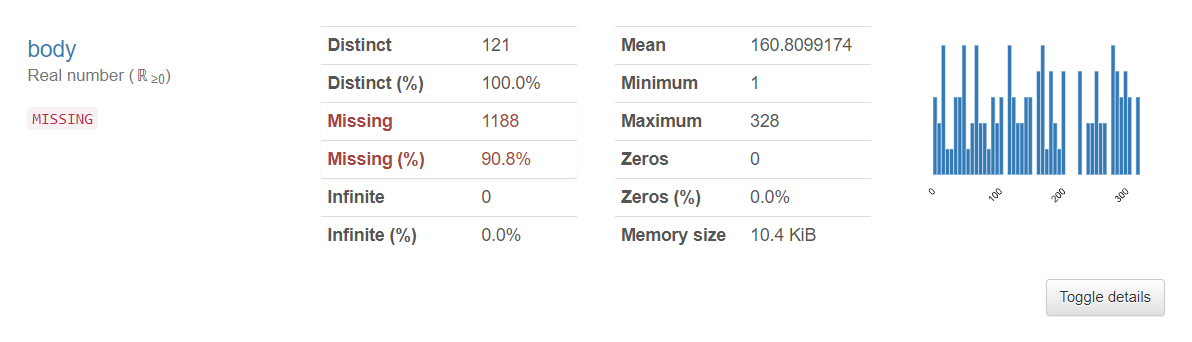
「body」に90.8%の欠測値が発生しています。
今度は、「age」と「body」の両方とも欠測していない行を抽出してみます。
以下、コードです。
titanicXy.query('age == age' and 'body == body')
以下、実行結果です。
比較演算子で条件指定しデータ抽出
比較演算子とは……
- ==
- !=
- <
- >
- <=
- >=
……などです。
今説明した「欠測値指定によるデータ抽出」で使っていました(==と!=)。
例えば、20歳未満のデータを抽出してみます。
以下、コードです。
titanicXy.query('age < 20')
以下、実行結果です。
否定するときは、notを使います。
以下、コードです。
titanicXy.query('not age < 20')
以下、実行結果です。
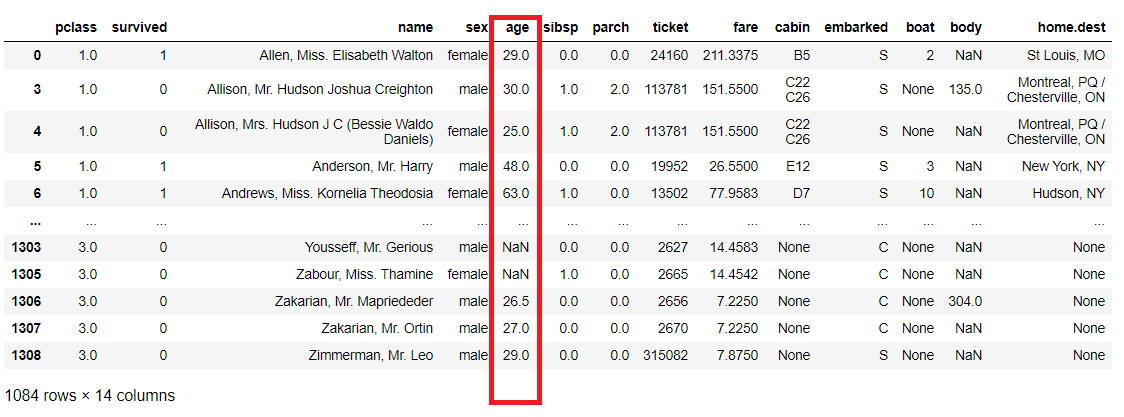
次に、20歳以上60歳以下のデータを抽出してみます。
以下、コードです。
titanicXy.query('20 <= age <= 60')
以下、実行結果です。
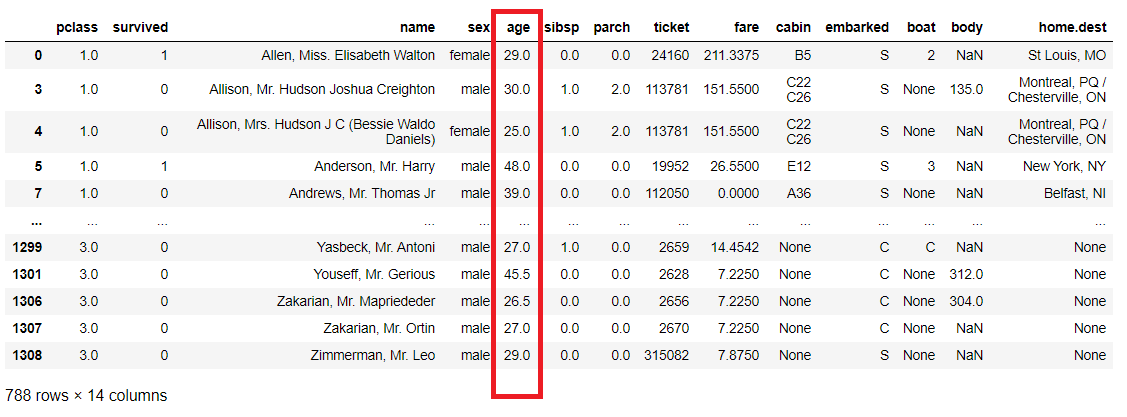
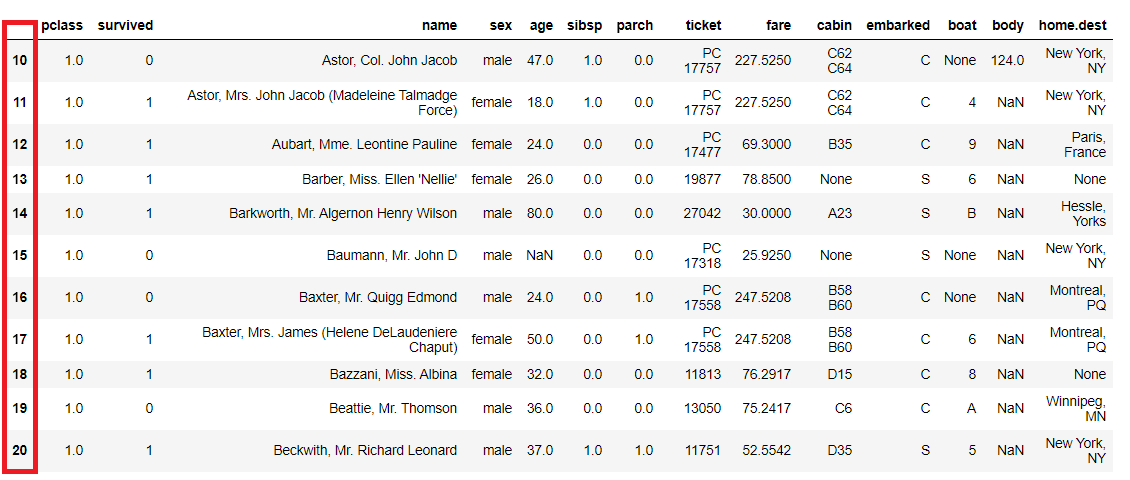
index列に対しても条件指定しデータ抽出できます。
以下、コードです。
titanicXy.query('10 <= index <= 20')
以下、実行結果です。
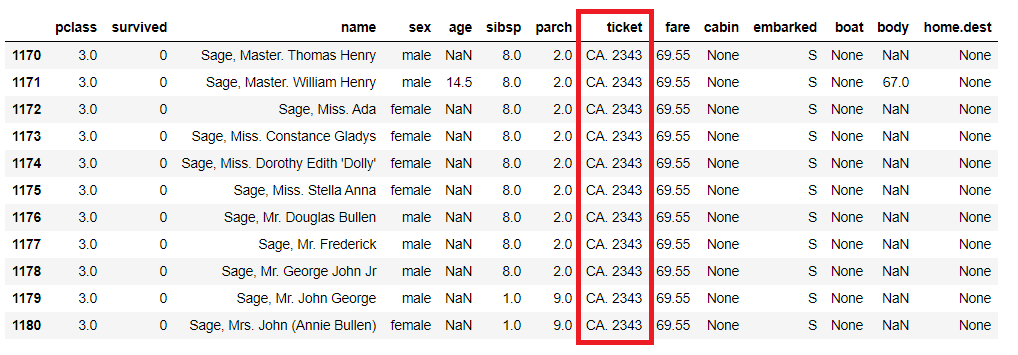
文字列に対しても使えます。
例えば、「ticket」が「CA. 2343」のデータを抽出してみます。
以下、コードです。
titanicXy.query('ticket == "CA. 2343"')
以下、実行結果です。
in演算子(リスト)で条件指定しデータ抽出
設定したリストに合致したデータを抽出します。
例えば、「ticket」が「CA. 2343」と「CA 2144」と「PC 17608」のデータを抽出してみます。文字列です。
以下、コードです。
titanicXy.query('ticket in ["CA. 2343","CA 2144","PC 17608"]')
以下、実行結果です。

例えば、「pclass」が「1」と「2」のデータを抽出してみます。数値データです。
以下、コードです。
titanicXy.query('pclass in [1,2]')
以下、実行結果です。
文字列メソッドで条件指定しデータ抽出
文字列に対する条件指定は、ここまで説明したような方法(==やin)で基本できます。このやり方は、完全一致する条件設定です。
ここで紹介するのは、部分一致する条件設定の方法です。
4つの文字列メソッドです。
- str.contains(): 指定した文字列を含む
- str.startswith(): 指定した文字列で始まる
- str.endswith(): 指定した文字列で終わる
- str.match(): 正規表現
ここで1つ注意点があります。query()の設定を「engine=’python’」とする必要があります。
例えば、「name」に「Hudson」が含まれるデータを抽出してみます。
以下、コードです。
titanicXy.query('name.str.contains("Hudson")', engine='python')
以下、実行結果です。

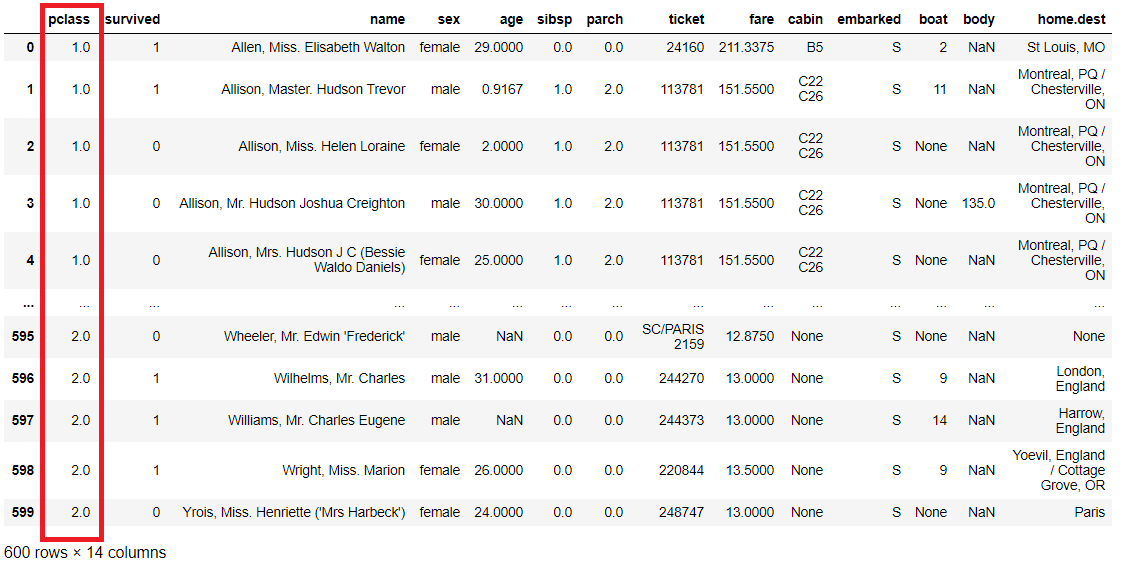
次に、「name」が「All」で始まるデータを抽出してみます。
以下、コードです。
titanicXy.query('name.str.startswith("All")', engine='python')
以下、実行結果です。

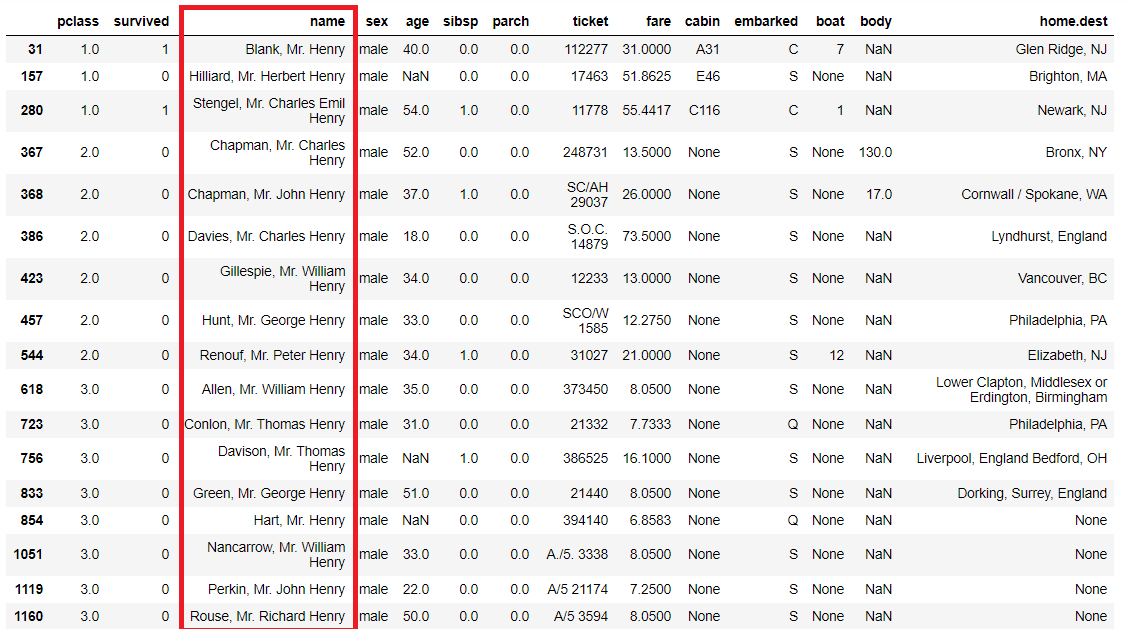
「name」が「Henry」で終わるデータを抽出してみます。
以下、コードです。
titanicXy.query('name.str.endswith("Henry")', engine='python')
以下、実行結果です。
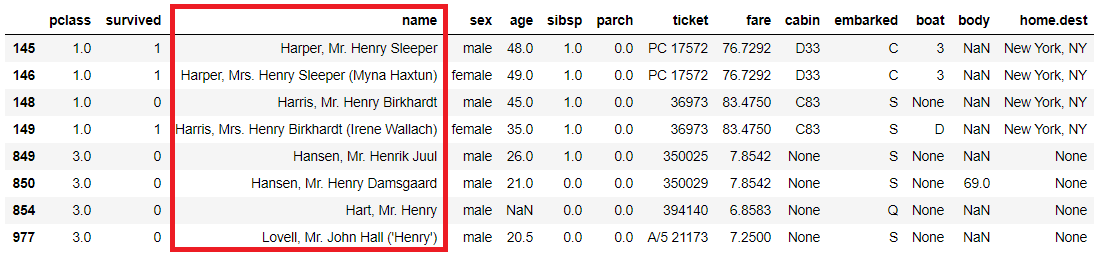
正規表現も使えます。
以下、コードです。
titanicXy.query('name.str.match(".*Ha.*He")', engine='python')
以下、実行結果です。
ここでは正規表現そのものの説明は割愛します。
変数を使って条件指定しデータ抽出
条件指定で変数を使用することもできます。変数名の前に@を付けます。
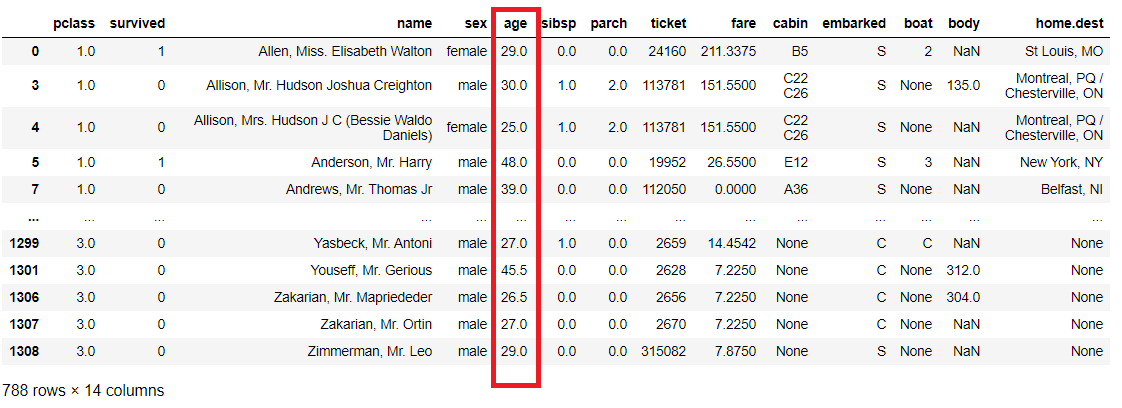
例えば、20歳以上60歳以下のデータを抽出してみます。
以下、コードです。
ageL = 20
ageU = 60
titanicXy.query('@ageL <= age <= @ageU')
以下、実行結果です。
まとめ
PythonでEDA(探索的データ分析)を実施するとき、PandasのQuery(クエリ―)を使う方も多いことでしょう。
今回は、比較的よく使うQuery(クエリ―)の条件抽出例を説明しました。