
Caretは構築できる数理モデルが200種類を超え(2021年4月30日現在)、線形回帰モデルから、決定木系、ニューラルネット系と幅広いです。
前回は、Caretの概要とインストール、そして回帰問題を例に使い方を簡単に説明しました。
今回は、分類問題を扱います。基本は、回帰問題と同じです。
Contents [hide]
利用するデータ
みんな大好きタイタニック(titanic)のデータを使います。

サンプルデータ(CSV形式)は、以下からダウンロードできます。
- survival:0 = No, 1 = Yes
- pclass:Ticket class(1 = 1st, 2 = 2nd, 3 = 3rd)
- sex:male, female
- embarked:Port of Embarkation(C = Cherbourg, Q = Queenstown, S = Southampton)
- age:Age in years
- sibsp:Number of siblings and spouses aboard Titanic
- parch:Number of parents and children aboard the Titanic.
- fare:Passenger fare
1番上の2値変数「survival」が目的変数で、それ以外が説明変数(特徴量)です。
カテゴリカル変数は以下です。数字のカテゴリカル変数と、文字のカテゴリカル変数があります。
- survival:0 = No, 1 = Yes
- pclass:Ticket class(1 = 1st, 2 = 2nd, 3 = 3rd)
- sex:male, female
- embarked:Port of Embarkation(C = Cherbourg, Q = Queenstown, S = Southampton)
量的変数は以下です。
- age:Age in years
- sibsp:Number of siblings and spouses aboard Titanic
- parch:Number of parents and children aboard the Titanic.
- fare:Passenger fare
全体の流れ
全体の流れです。
- データ読み込み
- データ分割(学習データとテストデータ)
- データの前処理
- 予測モデル構築(学習データ利用)
- 構築したモデルの検証(テストデータ)
今回は、次の3タイプのアルゴリズムで予測モデルを構築し検証します。
- ロジスティック回帰
- ニューラルネットワーク
- XGBoost(3種類)
XGBoostだけ、3種類のXGBoostのアルゴリズムを使います。実は、XGBoostと呼ばれるアルゴリズムは色々あり、考え方や基本的な流れは同じですが、細かいところで異なります。もちろん、予測結果も精度も変わってきます。
データ読み込み
では、早速データセットを読み込みます。
以下、コードです。Caret は、計算時間が掛かるケースが多いので、並列化演算するように設定しています。必須ではありません。
# # ライブラリー読み込み ---- # library(caret) library(readr) library(dplyr) library(summarytools) library(RANN) library(skimr) library(doParallel) # # 並列化演算 ---- # cl <- makePSOCKcluster(8) registerDoParallel(cl) # # データセットの読み込みと確認 ---- # ## 読み込み url = "https://www.salesanalytics.co.jp/e4ye" dataset = read_csv(url) ## 各変数の状況確認 skim(dataset) dfSummary(dataset) %>% view()
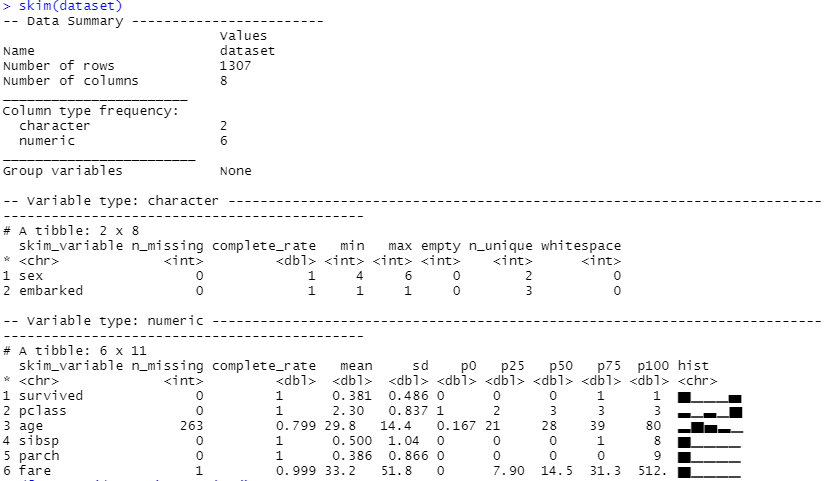
以下、実行結果(skimの出力)です。
以下、実行結果(dfSummaryの出力)です。クリックすると別のHTMLページが開きます。
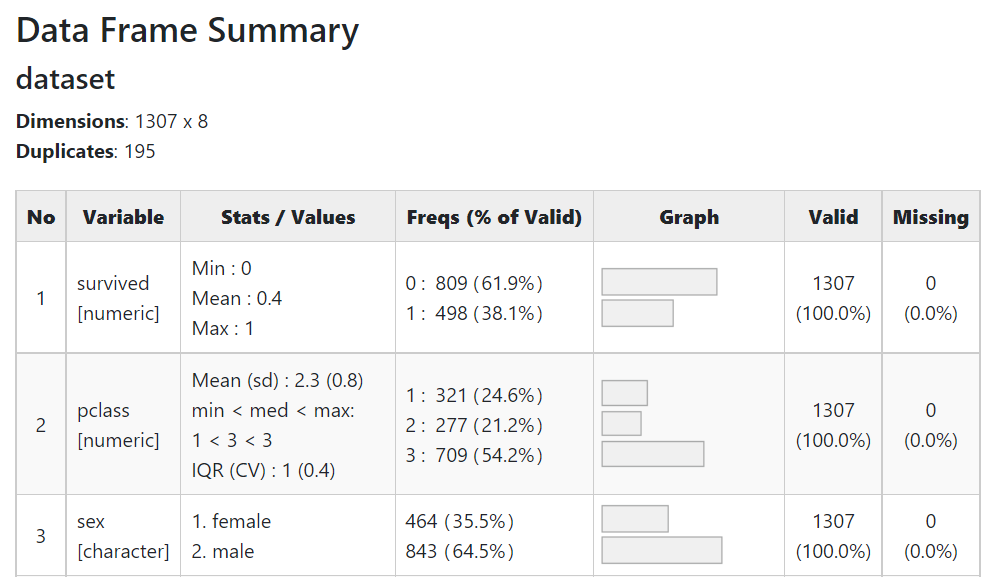
量的変数とカテゴリカル変数が混在し、さらにカテゴリカル変数も数字で表現されたものと文字で表現されたものがあります。そして、幾つかの変数に欠測値(missing)があることが分かります。
理想としては、次のように分かれていることです。
- カテゴリカル変数 ⇒ factor型
- 量的変数 ⇒ numeric型
数字で表現されているカテゴリカル変数は、numeric型になっていますので、そのままでは量的変数として扱われてしまいます。文字で表現されているカテゴリカル変数も、数字で表現した方がいいでしょう。
どちらもfactor型に変換し、数字で表現したカテゴリカル変数に変換します。
以下、コードです。
# # 型変換 ---- # ## カテゴリカル変数(因子型)へ変換 dataset$sex <- factor(dataset$sex) dataset$embarked <- factor(dataset$embarked) dataset$survived <- factor(dataset$survived) dataset$pclass <- factor(dataset$pclass)
本当に変換されたのか、確認してみます。
以下、コードです。
## 各変数の状況確認 skim(dataset)
以下、実行結果です。
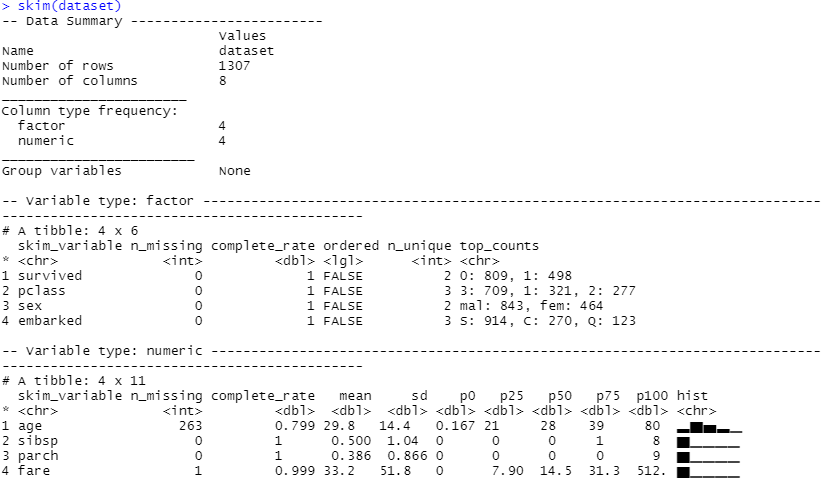
データ分割(学習データとテストデータ)
読み込んだデータセットを、モデルを構築するときに利用する学習データと、構築したモデルを検証するためのテストデータに分割します。
以下、コードです。
# # データ分割 ---- # ## データ分割用の行番号生成 set.seed(100) trainNum <- createDataPartition(dataset$survived, p=0.8, list=FALSE) ## 学習データ dataset_train <- dataset[trainNum,] y_train = dataset_train[,1] #目的変数 X_train = dataset_train[,-1] #説明変数(特徴量) ## テストデータ dataset_test <- dataset[-trainNum,] y_test = dataset_test[,1] #目的変数 X_test = dataset_test[,-1] #説明変数(特徴量)
データの前処理
次の2つの前処理を実施し、データセットを整えます。
- 欠測値の補完
- 量的変数の正規化
欠測値の補完と量的変数の正規化は、学習データで前処理用のモデルを構築し、それを使い学習データとテストデータの前処理を実施します。
欠測値の補完
今回は、k近傍法(k-nearest neighbor algorithm)で欠測値補完をします。
以下、コードです。
#
# 欠測値補完 ----
#
## 欠測値補完モデルの構築
missingdata_model <- preProcess(as.data.frame(X_train),
method='knnImpute')
## 学習データの欠測値補完
X_train <- predict(missingdata_model,
newdata = X_train)
## テストデータの欠測値補完
X_test <- predict(missingdata_model,
newdata = X_test)
量的変数の正規化
今回は、通常の正規化(平均値で引き標準偏差で割る)をします。
以下、コードです。
#
# 正規化(量的変数) ----
#
## 正規化モデルの構築
range_model <- preProcess(X_train, method = c("center", "scale"))
## 学習データの正規化
X_train <- predict(range_model, newdata = X_train)
## テストデータの正規化
X_test <- predict(range_model, newdata = X_test)
前処理状況の確認
これで前処理は終了です。確認してみます。
以下、コードです。
# # 各変数の状況確認 ---- # ## 学習データ skim(X_train) ## テストデータ skim(X_test)
以下、実行結果(学習データ)です。
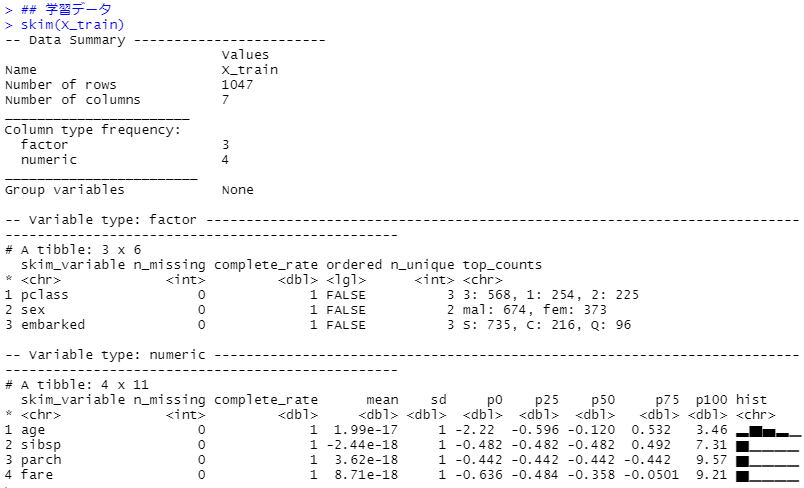
以下、実行結果(学習データ)です。

このデータセットを使い、モデルを構築し検証していきます。
モデルを構築し検証
train関数を使いモデルを構築します。
繰り返しになりますが、train関数の中で、以下の設定をします。
- formula:モデル式
- data:学習データ
- method:アルゴリズム
- preProcess:データの前処理
- tuneLength:パラメータチューニングの数
- tuneGrid:パラメータチューニングの範囲
- trControl:クロスバリデーションなどの諸設定
基本、「method」の設定を変えることで、数理モデルのアルゴリズムを変えることができます。今回は、次の3タイプのアルゴリズム、XGBoostに関しては3種類の計5種類のアルゴリズムで予測モデルを構築し検証します。
- ロジスティック回帰
- ニューラルネットワーク
- XGBoost(3種類)
ロジスティック回帰
最も一般的なロジスティック回帰です。
以下、コードです。
#
# Logistic Regression ----
#
## モデルの学習(学習データ)
model_plr <- train(
survived ~ .,
data = cbind(y_train, X_train),
method = 'plr',
tuneLength = 10,
trControl = trainControl(method = 'cv',
number = 10)
)
## 学習結果の確認
model_plr
varImp(model_plr, scale = TRUE)
## モデルの検証(テストデータ)
pred_plr <- predict(model_plr, X_test)
confusionMatrix(reference = y_test$survived,
data = pred_plr,
mode='everything',
positive="1")
今回は、正則化ロジスティック回帰モデル(Penalized Logistic Regression)を使っています。Ridge回帰です。
次に出力した結果を見ていきます。
- 学習結果の確認(学習データ)
- モデルの検証(テストデータ)
先ずは、学習結果の確認(学習データ)です。
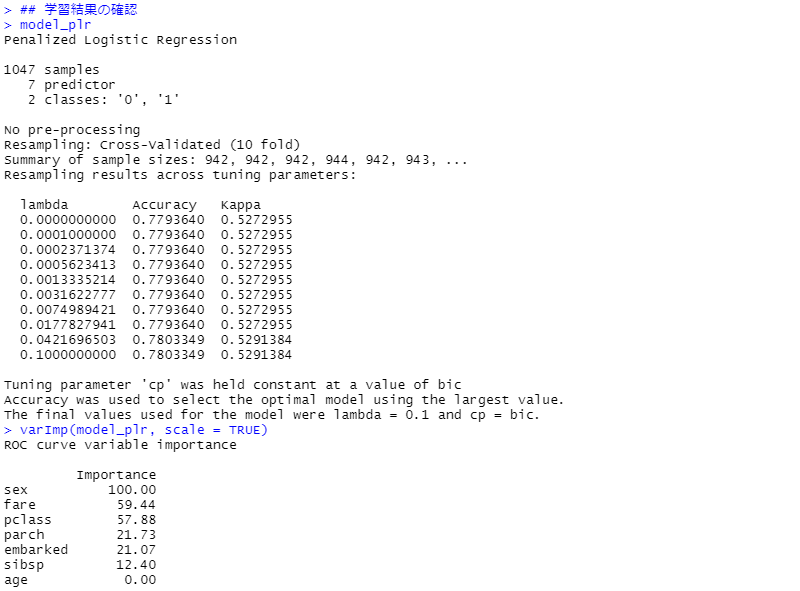
次に、モデルの検証(テストデータ)です。見方の説明は割愛しますが、混同行列(Confusion Matrix)と各指標を出力しています。
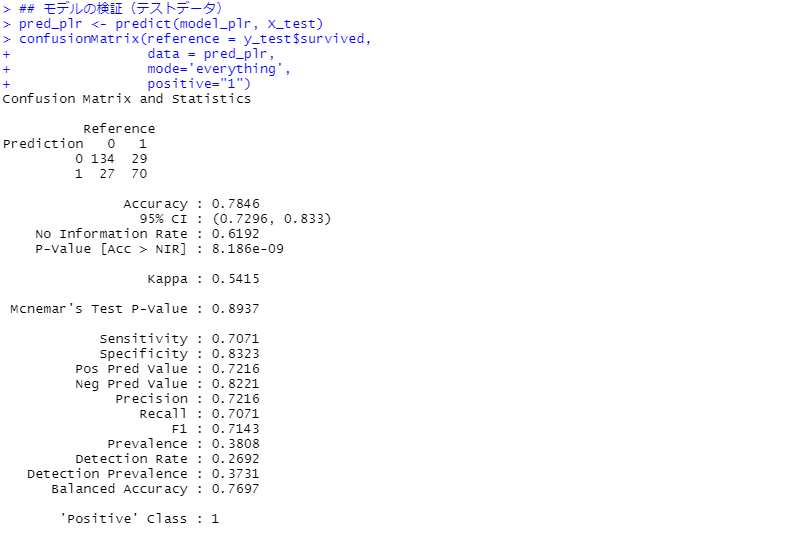
正答率(Accuracy)が約78%です。
ニューラルネットワーク
以下、コードです。
#
# Neural Network ----
#
model_nnet <- train(
survived ~ .,
data = cbind(y_train, X_train),
method = "nnet",
tuneGrid = expand.grid(size=c(1:10),
decay=seq(0.1, 1, 10)),
trControl = trainControl(method = 'cv',
number = 10),
linout = FALSE
)
## 学習結果の確認
model_nnet
varImp(model_nnet, scale = TRUE)
## モデルの検証(テストデータ)
pred_nnet <- predict(model_nnet, X_test)
confusionMatrix(reference = y_test$survived,
data = pred_nnet,
mode='everything',
positive="1")
今回は分類問題に対するニューラルネットワークですので「linout = FALSE」になります。回帰問題の場合は「linout = TRUE」です。
次に出力した結果を見ていきます。
- 学習結果の確認(学習データ)
- モデルの検証(テストデータ)
先ずは、学習結果の確認(学習データ)です。
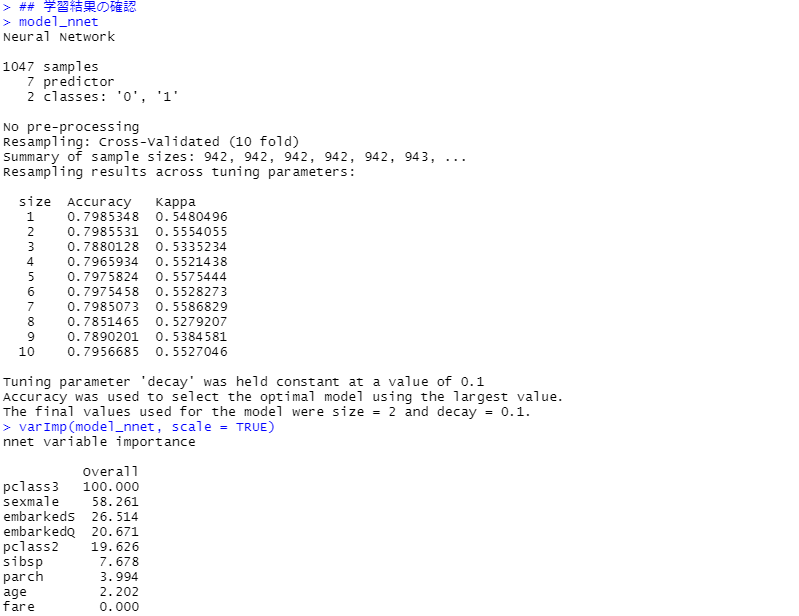
次に、モデルの検証(テストデータ)です。見方の説明は割愛しますが、混同行列(Confusion Matrix)と各指標を出力しています。
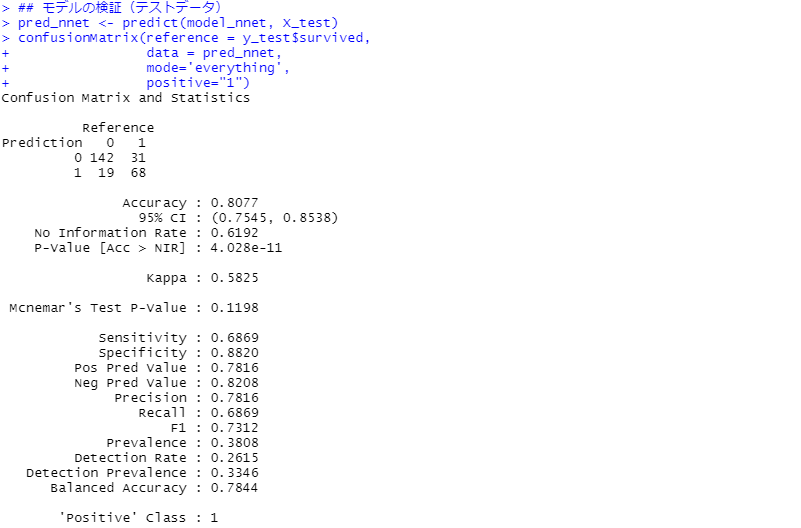
正答率(Accuracy)が約81%です。
最もシンプルなロジスティック回帰と比較すると、精度はやや向上しています。
XGBoostその1(xgbLinear)
以下、コードです。
#
# XGBoost1 ----
#
## モデルの学習(学習データ)
model_xgb1 <- train(
survived ~ .,
data = cbind(y_train, X_train),
method = 'xgbLinear',
tuneLength = 5,
trControl = trainControl(method = 'cv',
number = 10)
)
## 学習結果の確認
model_xgb1
varImp(model_xgb1, scale = TRUE)
## モデルの検証(テストデータ)
pred_xgb1 <- predict(model_xgb1, X_test)
confusionMatrix(reference = y_test$survived,
data = pred_xgb1,
mode='everything',
positive="1")
このXGBoostのチューニングできるパラメータは以下の4つです。
- nrounds
- lambda
- alpha
- eta
「tuneLength=5」で設定しているの、5×5×5×5 = 625通りのパラメタの組み合わせで検討されます。
次に出力した結果を見ていきます。
- 学習結果の確認(学習データ)
- モデルの検証(テストデータ)
先ずは、学習結果の確認(学習データ)です。

次に、モデルの検証(テストデータ)です。見方の説明は割愛しますが、混同行列(Confusion Matrix)と各指標を出力しています。
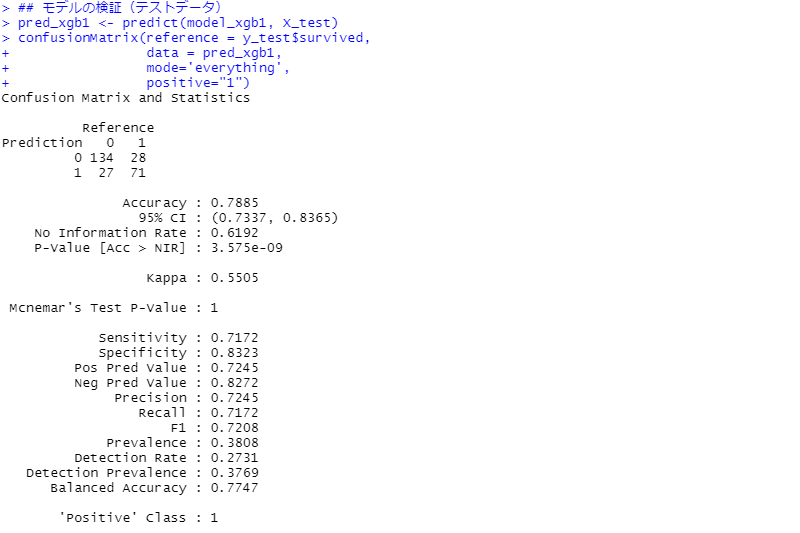
正答率(Accuracy)が約79%です。
最もシンプルなロジスティック回帰と比較して、それほど精度は向上していません。
XGBoostその2(xgbDART)
以下、コードです。
#
# XGBoost2 ----
#
## モデルの学習(学習データ)
model_xgb2 <- train(
survived ~ .,
data = cbind(y_train, X_train),
method = 'xgbDART',
tuneLength = 3,
trControl = trainControl(method = 'cv',
number = 10)
)
## 学習結果の確認
model_xgb2
varImp(model_xgb2, scale = TRUE)
## モデルの検証(テストデータ)
pred_xgb2 <- predict(model_xgb2, X_test)
confusionMatrix(reference = y_test$survived,
data = pred_xgb2,
mode='everything',
positive="1")
このXGBoostのチューニングできるパラメータは以下の9つです。
- nrounds
- max_depth
- eta
- gamma
- subsample
- colsample_bytree
- rate_drop
- skip_drop
- min_child_weight
「tuneLength=3」で設定しているの、3×3×3×3×3×3×3×3×3 =19,683通りのパラメタの組み合わせで検討されます。
次に出力した結果を見ていきます。
- 学習結果の確認(学習データ)
- モデルの検証(テストデータ)
先ずは、学習結果の確認(学習データ)です。

次に、モデルの検証(テストデータ)です。見方の説明は割愛しますが、混同行列(Confusion Matrix)と各指標を出力しています。
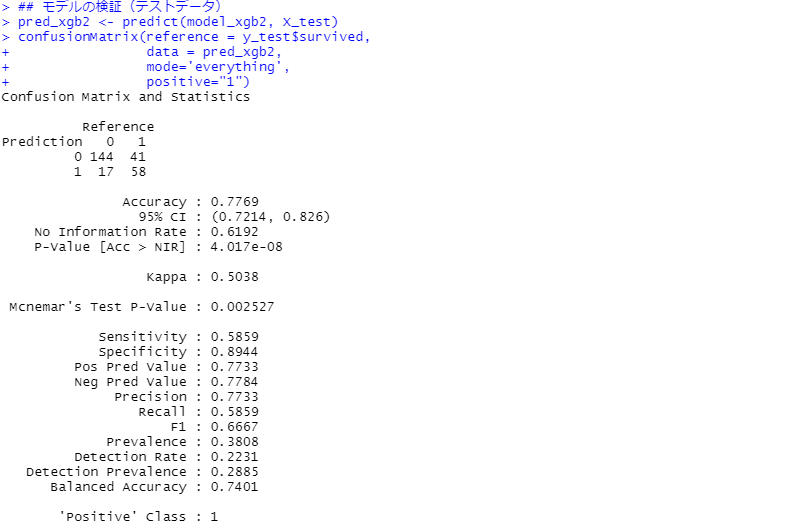
正答率(Accuracy)が約78%です。
最初のXGBoostのアルゴリズムと、それほど精度は変わりません。
XGBoostその3(xgbTree)
以下、コードです。
#
# XGBoost3 ----
#
## モデルの学習(学習データ)
model_xgb3 <- train(
survived ~ .,
data = cbind(y_train, X_train),
method = 'xgbTree',
tuneLength = 5,
trControl = trainControl(method = 'cv',
number = 10)
)
## 学習結果の確認
model_xgb3
varImp(model_xgb3, scale = TRUE)
## モデルの検証(テストデータ)
pred_xgb3 <- predict(model_xgb3, X_test)
confusionMatrix(reference = y_test$survived,
data = pred_xgb3,
mode='everything',
positive="1")
このXGBoostのチューニングできるパラメータは以下の7つです。
- nrounds
- max_depth
- eta
- gamma
- colsample_bytree
- min_child_weight
- subsample
「tuneLength=5」で設定しているの、5×5×5×5×5×5×5 = 78,125通りのパラメタの組み合わせで検討されます。
次に出力した結果を見ていきます。
- 学習結果の確認(学習データ)
- モデルの検証(テストデータ)
先ずは、学習結果の確認(学習データ)です。


次に、モデルの検証(テストデータ)です。見方の説明は割愛しますが、混同行列(Confusion Matrix)と各指標を出力しています。
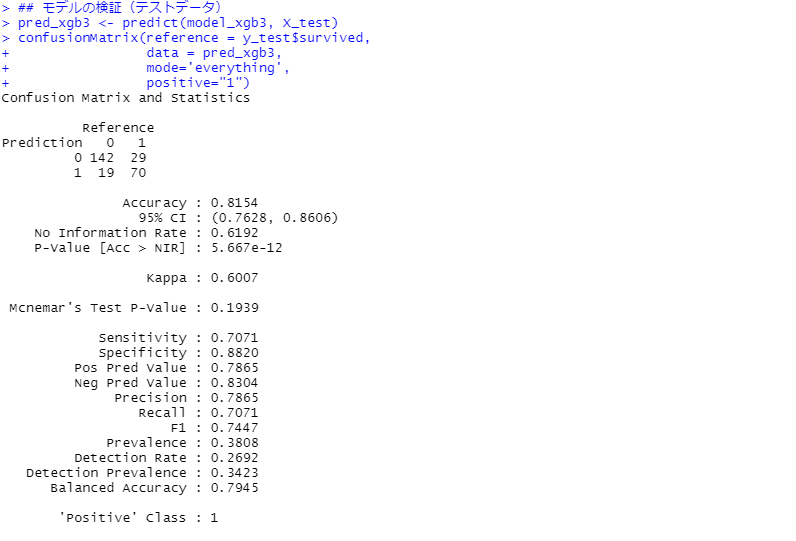
正答率(Accuracy)が約82%です。
3つのXGBoostの中で一番精度が高いです。また、今回実施してみたアルゴリズムの中で、一番高精度です。
まとめ
今回は、「R Caret によるシンプルな機械学習モデリング その2(分類問題編)」というお話しをしました。
Caret には、機械学習に必要なツールも一式整っています。さらに、200を超える色々なアルゴリズムを試せます。
興味のあり方は、試してみてください。
Caretの概要とインストール、そして回帰問題を例に使い方に関しては、前回の「R Caret によるシンプルな機械学習モデリング その1(回帰問題編)」を参考にしてください。