

H2O(エイチツーオー)は、H2O.ai社によって開発された、インメモリ型の機械学習プラットフォームです。
教師あり学習や教師なし学習などの機械学習系の数理モデルを構築することができます。
嬉しいのが、ノンコードで機械学習モデルを構築することのできるH2O FlowというGUI環境が用意されていることです。
さらに嬉しいことに、AutoML(自動機械学習)機能があるため、面倒なパラメータ調整などを全自動で実施してくれる機能がついています。
ノンコードな機械学習モデル構築を可能にする H2O Flow の簡単な使い方について、以下のような順番で説明していきます。
- その1 H2O Flow の起動
- その2 H2O Flow で実施する教師あり学習(回帰問題)
- その3 H2O Flow で実施する教師あり学習(分類問題)
- その4 H2O Flow で実施する自動機械学習AutoML(回帰問題)
- その5 H2O Flow で実施する自動機械学習AutoML(分類問題) ⇒ 今回
- その6 H2O Flow で実施する教師なし学習(次元削減・集約)
- その7 H2O Flow で実施する教師なし学習(異常検知)
- その8 H2O Flow で実施する教師なし学習(クラスタリング)
- その9 H2O Flow の保存と読込
前回は、その4 の「H2O Flow で実施する自動機械学習AutoML(回帰問題)」について説明しました。
今回は、その5 の「H2O Flow で実施する自動機械学習AutoML(分類問題)」について説明します。
Contents [hide]
H2O Flowの起動
まずは、H2O Flowの起動です。
「h2o.jar」というJARファイルをダブルクリックすることでH2O Flowが起動します。

もしくは、コマンドプロンプト上などで、「h2o.jar」ファイルのあるフォルダまで移動し、以下のコードを実行することでも実行できます。
java -jar h2o.jar
実行したら、ブラウザに以下のURLを入力しアクセスします。
そうすると、以下のようなH2O Flowの実行画面が表示されます。

今回利用するデータセット
今回利用するデータセットは、分類問題でよく登場するみんな大好き「乳がん(breast cancer)」データセットです。
目的変数yは、画像の分類結果良性(=1)と悪性(=0)の2クラス値です。
特徴量(説明変数X)は、次の10個特徴量の平均値、標準偏差、最低値を算出し30個の特徴量にしています。
| 項目名 | 詳細 |
| radius | 細胞核の中心から外周までの距離 |
| texture | 画像のグレースケールの標準偏差 |
| perimeter | 細胞核周囲の長さ |
| area | 細胞核の面積 |
| smoothness | 細胞核の直径の局所分散値 |
| compactness | perimeter^2/area – 1.0で計算される値 |
| concavity | 輪郭の凹面度の重大度 |
| concave point | 輪郭の凹面部の数 |
| symmetry | 対称性 |
| fractal dimension | フラクタル次元 |
CSVファイルは、以下からダウンロードできます。
breast_cancer.csv
https://www.salesanalytics.co.jp/0yye
データの読み込み
メニューから、[Data]⇒[Import Files…]を選択します。

以下のようなImport Filesの入力画面が現れます。
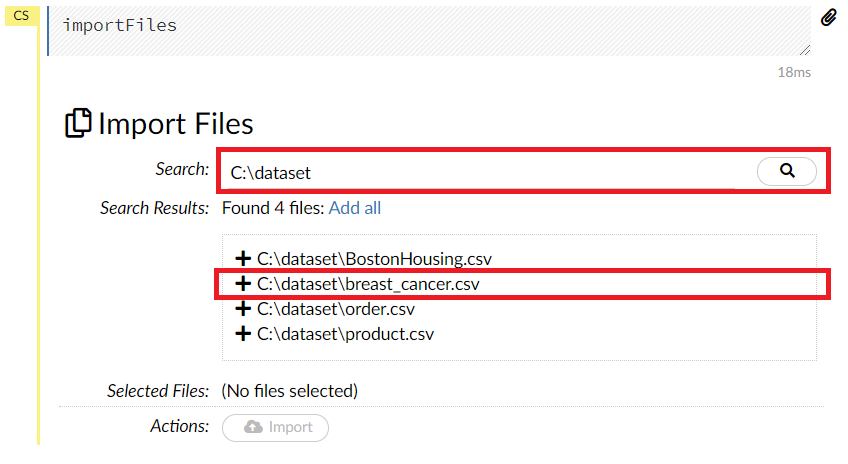
Searchにデータのあるフォルダ名(例 C:\dataset)などを入力し、虫眼鏡をクリックします。そうすると、そのフォルダ内にある候補ファイルが表示されます(例 C:\dataset\breast_cancer.csv)ので、読み込みたいファイルの左側の「+」をクリックします。
一番下のActionのところにあるImportがアクティブになりますので、このImportをクリックします。
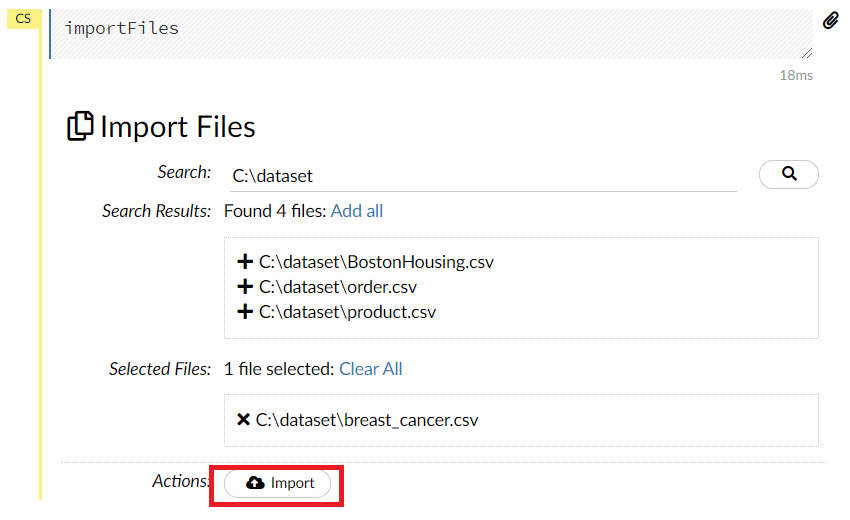
問題なければ、以下のような画面になり、Parse these files…がアクティブになりますので、このParse these files…をクリックします。
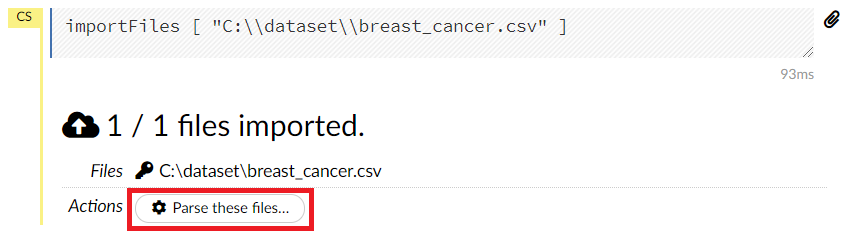
以下のような画面になります。
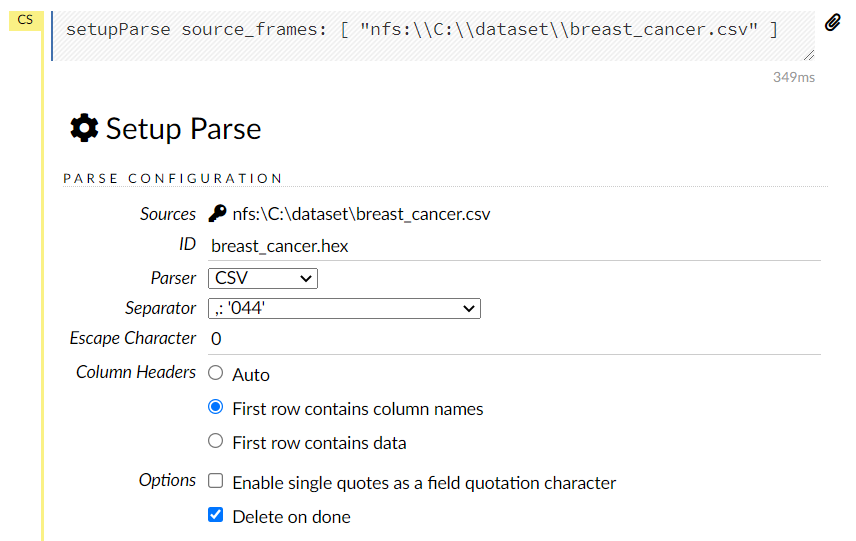
この画面を下にスクロールすると、変数設定を変更できる画面が登場しますので、必要があれば変更します。今回は、目的変数yがカテゴリカル変数(0:悪性, 1:良性)なので「Enum」に変更します。最後に、一番下のParseをクリックします。
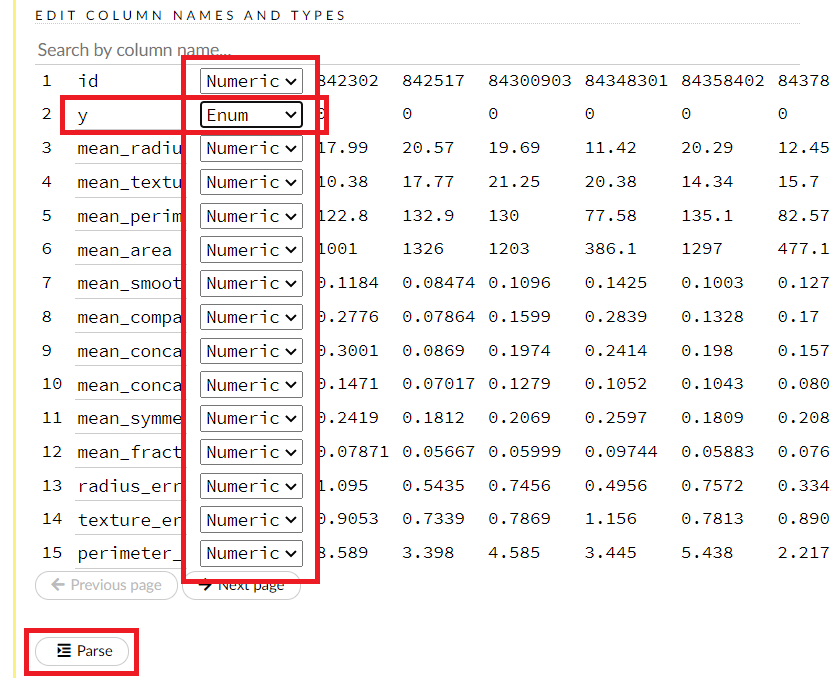
データの読み込みが開始されます。
上手くデータが読み込めると、以下のような画面になり、Viewがアクティブになりますので、このViewをクリックします。

以下のような画面が表示されます。この画面上で、データの分割やモデル構築などを実施していきます。
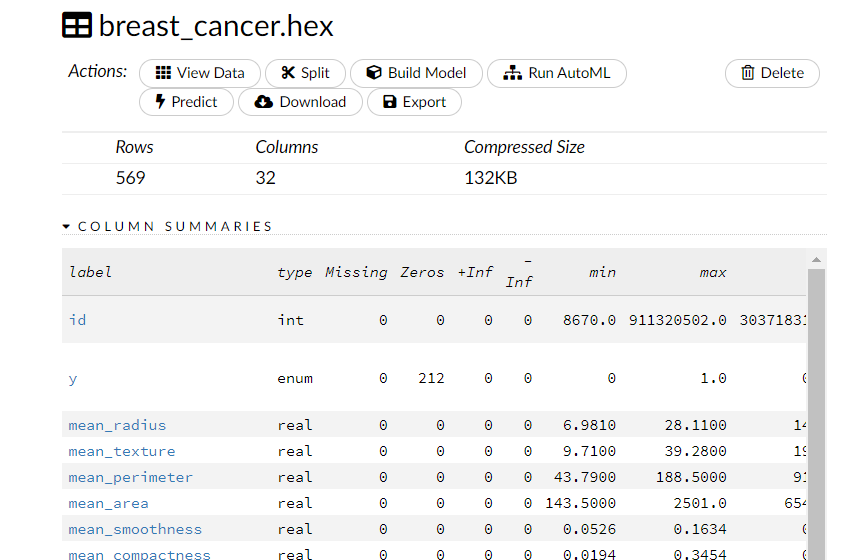
データセットの分割(学習データとテストデータ)
読み込んだデータを、モデルを構築する学習データと、構築したモデルを評価するテストデータに分割します。
上にあるSplitをクリックします。
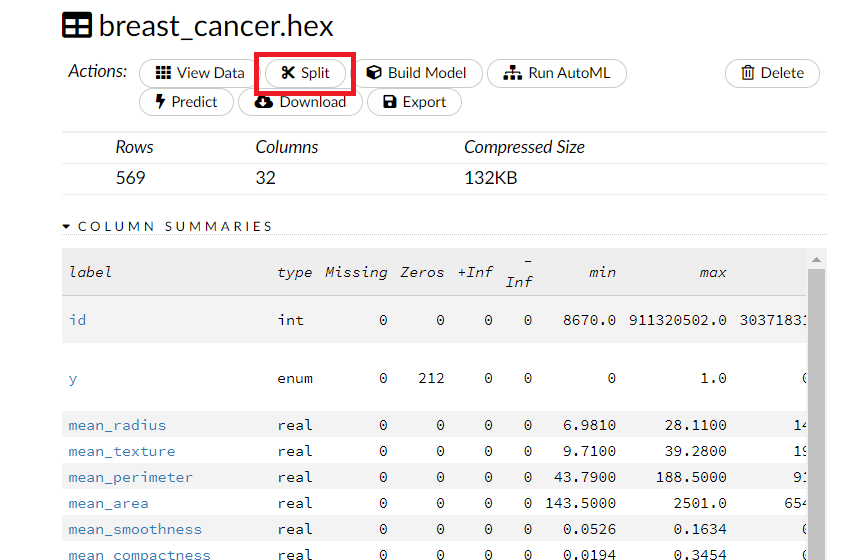
以下のようなデータ分割のための画面が表示されます。
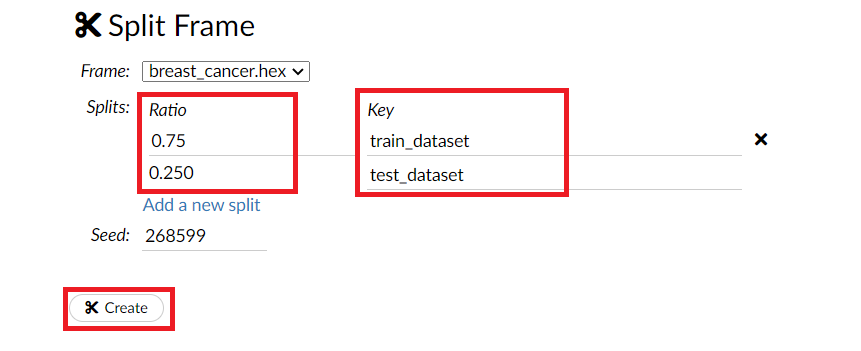
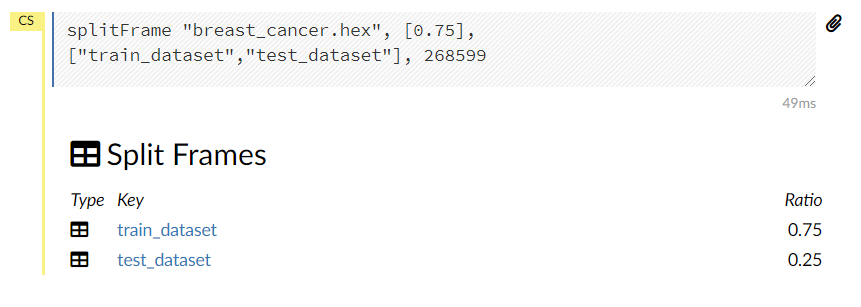
Ratioに分割比率を設定し、Keyに分割後のデータセット名を入力します。例では、75%が学習データで名称をtrain_datasetとし、残りの25%がテストデータで名称をtest_datasetとしています。
設定したら、一番下のCreateをクリックします。
問題なければ、以下のような画面が表示されます。
Auto ML(自動機械学習)の設定との実行
構築するモデルの設定、構築、評価を実施していきます。
先ほどの画面に戻り(上にスクロール)、Run AutoML をクリックします。
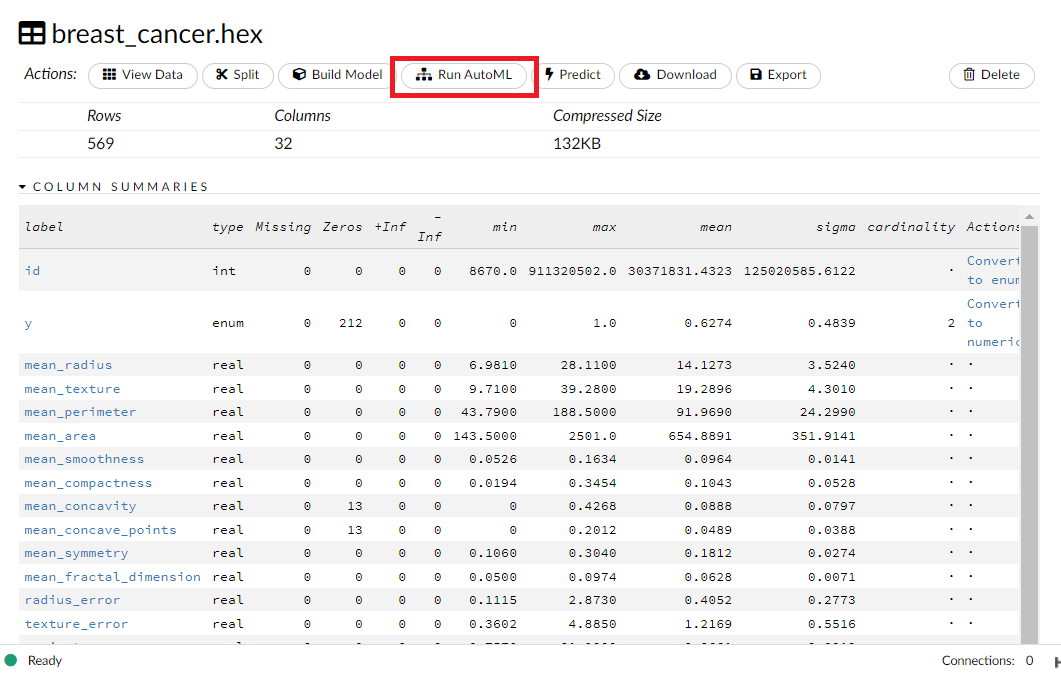
Auto ML で学習し評価するための設定をするための画面が表示されます。
今回は、学習データ(例 train_dataset)とテストデータ(例 test_dataset)の指定と、目的変数(例 medv)の設定、使用しない特徴量の設定(変数「id」にチェックを入れる)のみ実施しています(他はデフォルトの設定のまま)。
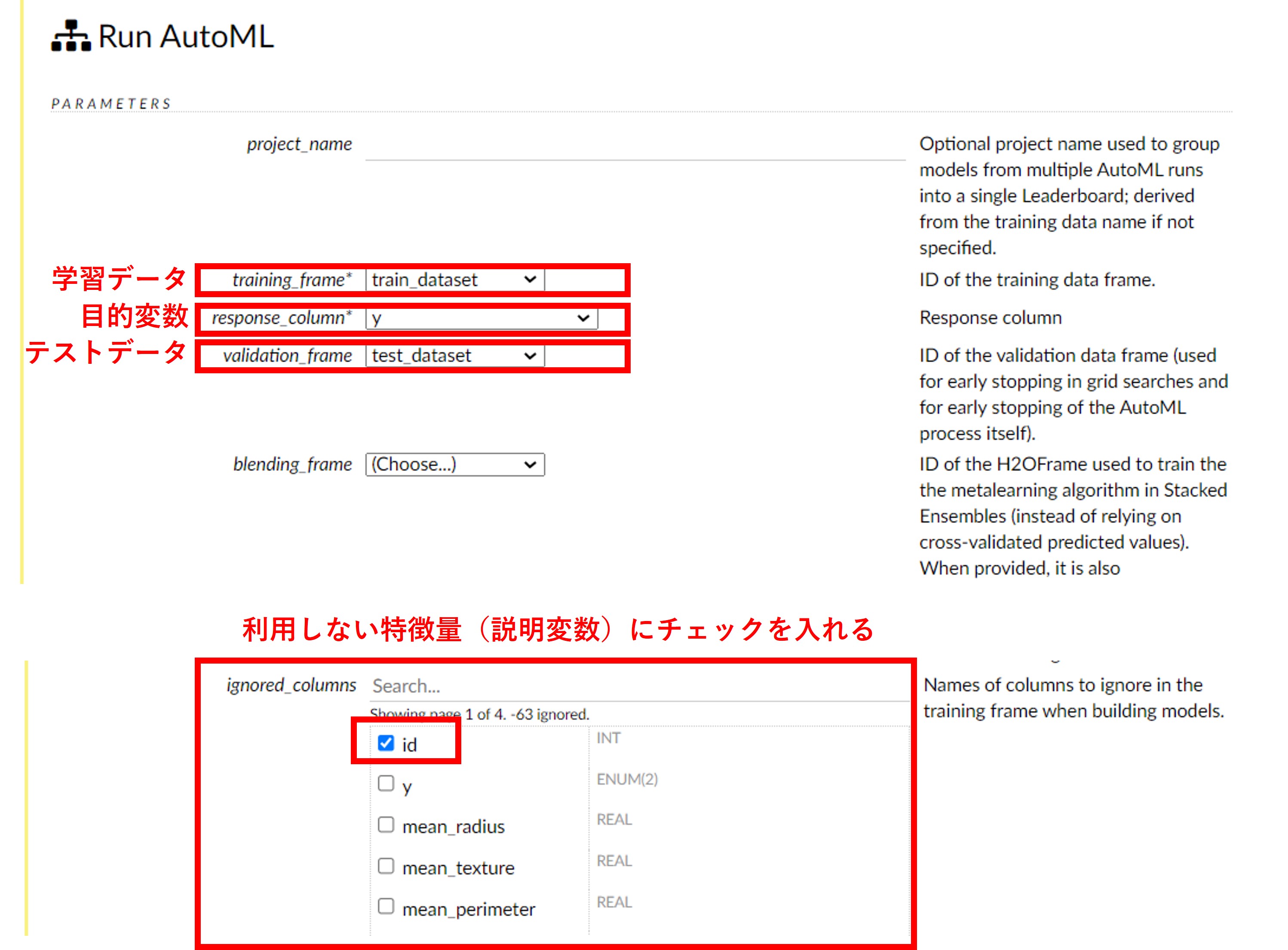
この画面を下にスクロールしていくと、一番下にBuild Modelというボタンがあるので、このBuild Modelをクリックします。

学習結果と検証結果
AutoMLが始まります。時間は結構かかりますので、気長に待ちましょう。Progressが100%になったら終了です。
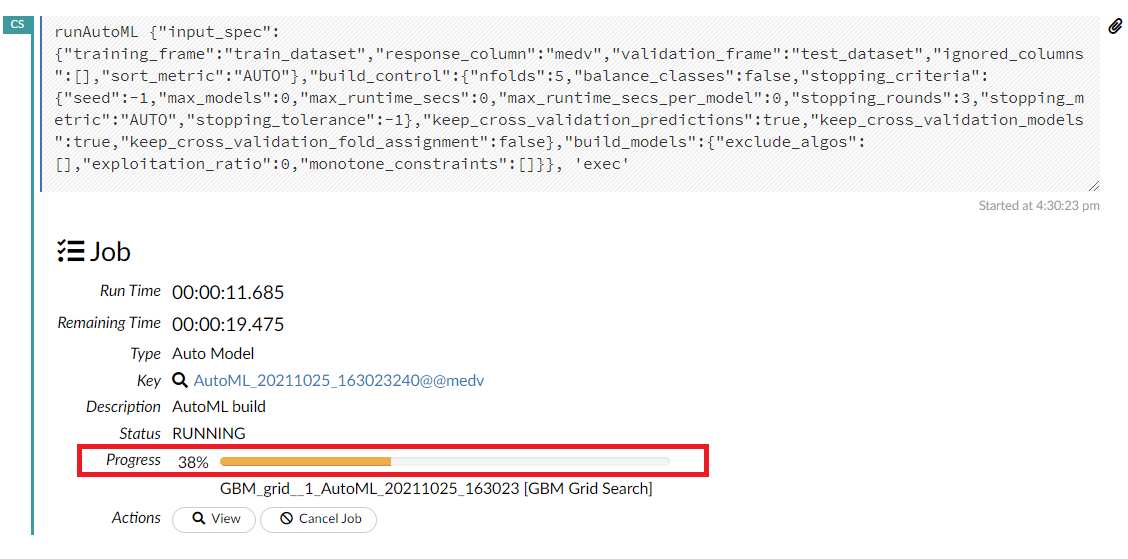{kind=link}
学習と評価が終了すると、以下のような画面になり、Viewがアクティブになりますので、このViewをクリックします。
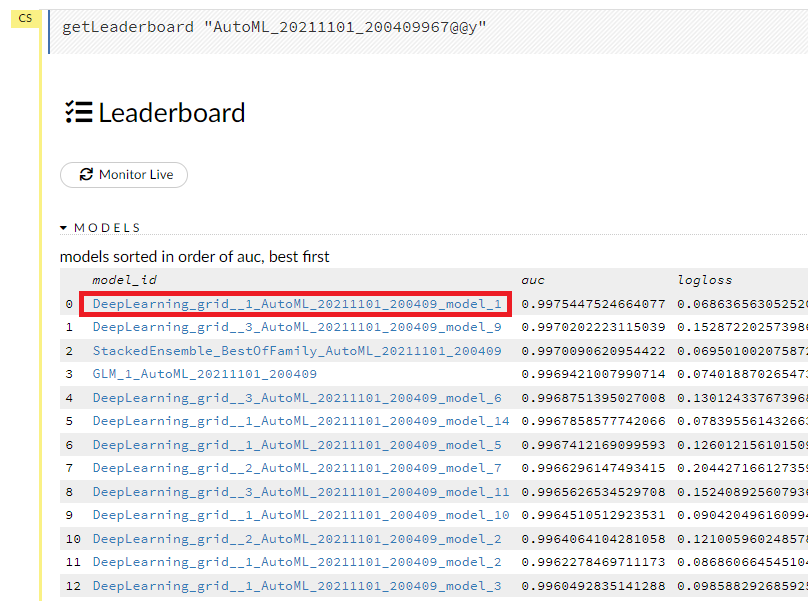
AutoMLで学習された全てのモデルが、より良いモデル順にソートされて表示されます。
一番上がベストなモデルです。このケースでは、ディープラーニングのモデル(DeepLearning_grid__1_AutoML_20211101_200409_model_1)がベストなモデルです。
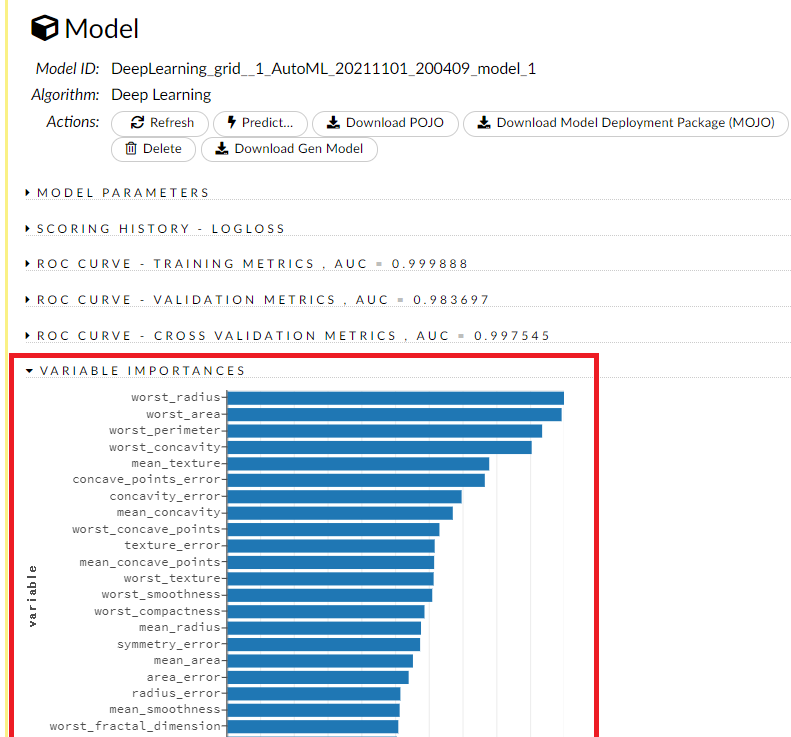
気になるモデルを見るときには model_id をクリックします。一番上のモデルをクリックすると、以下のようになります。各特徴量(説明変数)の重要度であるインポータンス(Importance)が表示されている状態になっています。
学習結果(学習データ)を見てみます。ROC CURVE – TRAINING METRICSのタブを開くと見れます。AUC(Area Under the Curve)は0.999888です。
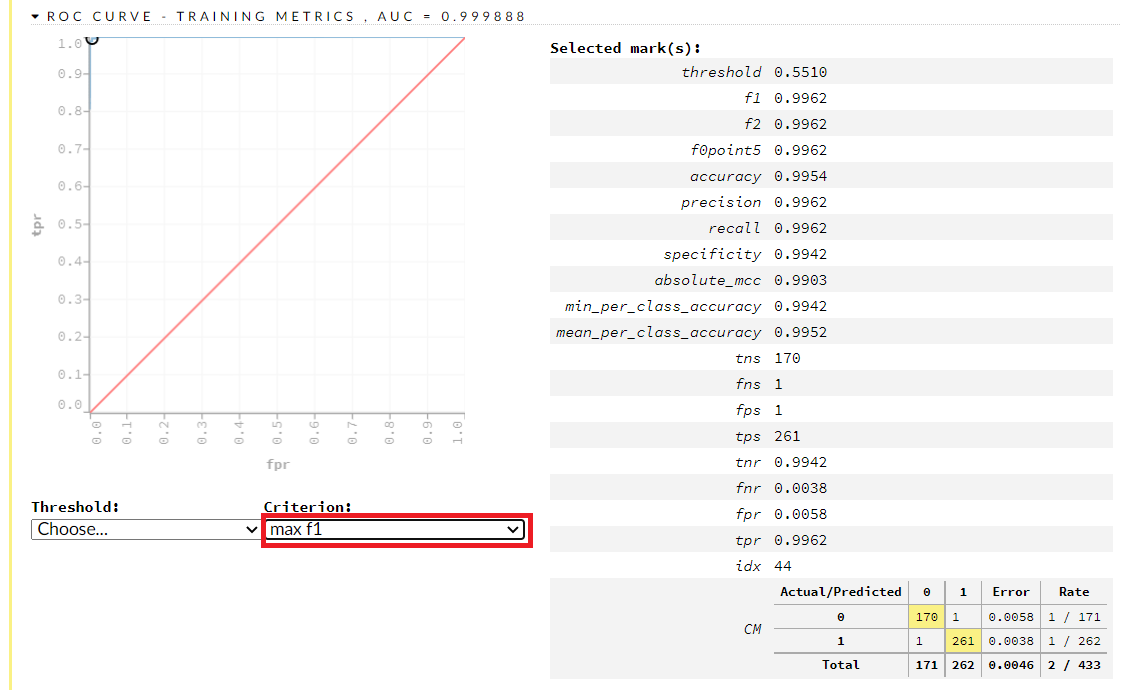
今回は、Criterionを「max_f1」(F値を重視する)に設定してみました。その場合の混同行列(Confusion Matrix)が右下に表示されますが、見にくいので拡大してみます。
以下です。誤分類率は0.46%(正解率は99.54%)であることが分かります。
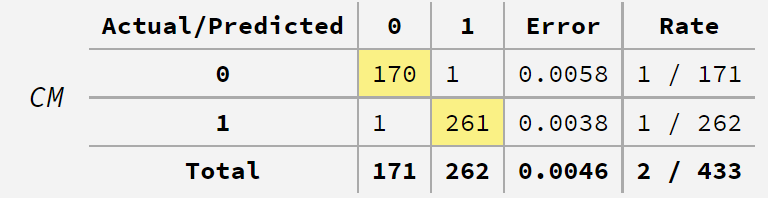
評価結果(テストデータ)を見てみます。ROC CURVE – VALIDATION METRICSのタブを開くと見れます。AUC(Area Under the Curve)は0.983697です。
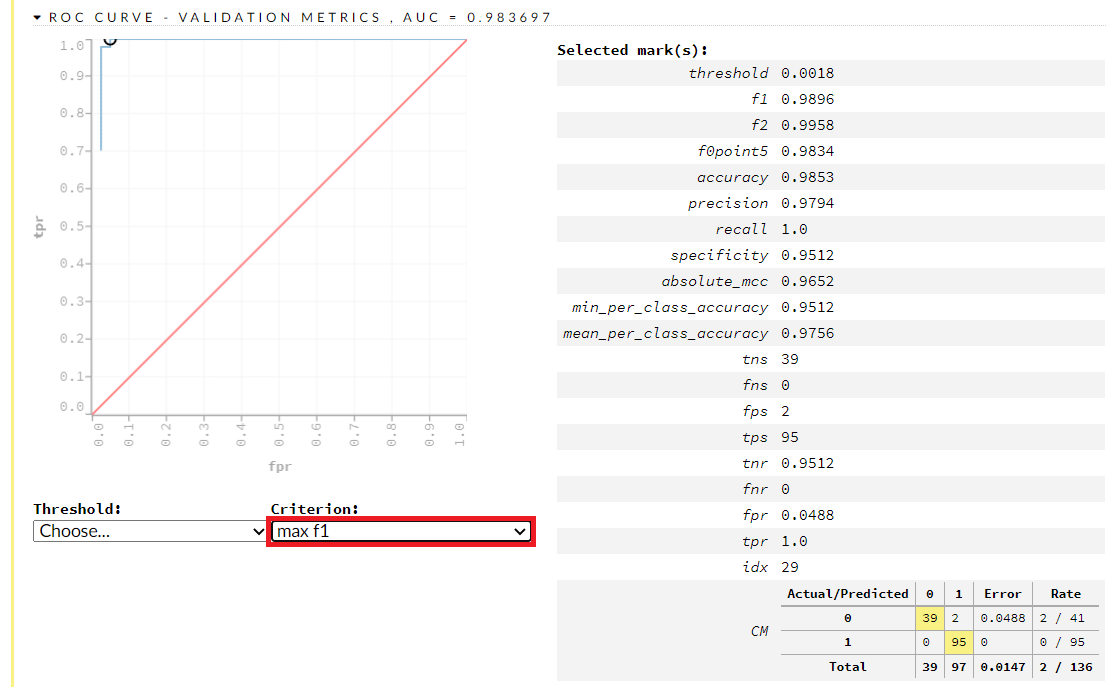
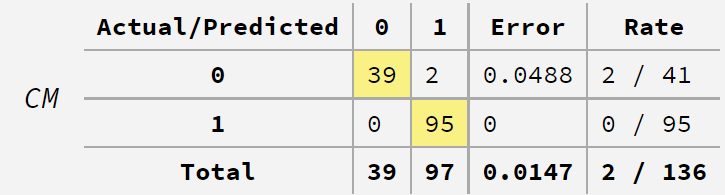
今回は、Criterionを「max_f1」(F値を重視する)に設定してみました。その場合の混同行列(Confusion Matrix)が右下に表示されますが、見にくいので拡大してみます。
以下です。誤分類率は1.47%(正解率は98.53%)であることが分かります。
次回
今回は、その5の「H2O Flow で実施する自動機械学習AutoML(分類問題)」について説明しました。
- その1 H2O Flow の起動
- その2 H2O Flow で実施する教師あり学習(回帰問題)
- その3 H2O Flow で実施する教師あり学習(分類問題)
- その4 H2O Flow で実施する自動機械学習AutoML(回帰問題)
- その5 H2O Flow で実施する自動機械学習AutoML(分類問題)
- その6 H2O Flow で実施する教師なし学習(次元削減・集約) ⇒ 次回
- その7 H2O Flow で実施する教師なし学習(異常検知)
- その8 H2O Flow で実施する教師なし学習(クラスタリング)
- その9 H2O Flow の保存と読込
次回は、その6の「H2O Flow で実施する教師なし学習(次元削減・集約)」について説明します。