
クラスター分析で利用されるメジャーなアルゴリズムは、非階層型クラスタリングのk-means法か、階層型のWard法がよく使われます。
問題は、量的データ(数値変数)のみを使うというところにあります。質的データ(カテゴリカル変数)が混在するデータをクラスタリングするとき、困ってしまいます。
量質混在データ(数値変数とカテゴリカル変数)に対するクラスタリング手法が、幾つかあります。
今回は、「Gower距離による階層型クラスタリング(Python)」というお話しをします。
Contents [hide]
量質混在データの距離を測るGower距離
クラスター分析は、似たような顧客や企業、店舗などをグルーピングしプロファイリングする分析です。
似たような顧客や企業、店舗などをグルーピングするには、顧客間や企業間、店舗間の類似性もしくは非類似性を計算する必要があります。
量的データ(数値変数)のみであれば計算しやすいですが、質的データ(カテゴリカル変数)が混在するデータの場合、ちょっと工夫が必要があります。
古くは、Gowerの考案した量質混在データの距離計測方法があります。Gower距離と呼ばれるものです。
Gower, J.C. (1971) A general coefficent of similarity and some of its properties. Biometrics, 27, 857-874.
https://members.cbio.mines-paristech.fr/~jvert/svn/bibli/local/Gower1971general.pdf
Gower距離でクラスタリング
量質混在データ(数値変数とカテゴリカル変数)に対するクラスタリングで最もシンプルなやり方は、Gower距離でクラスタリングする方法です。
PythonのパッケージGowerを使うことで、量質混在データの距離を計算することができます。
手順は簡単です。
- Gower距離を計算
- 計算したGower距離でクラスター分析
Pythonのscikit-learn(sklearn)パッケージの中にある多くのクラスター分析の手法は、計算済みの距離を入力することでもクラスター分析を実施することができます。
今回は、視覚的にも分かりやすいという理由で、階層型クラスター分析(Ward法)で実施します。
サンプルデータ
あるトイレタリーメーカーで、現在発売している歯磨き粉のリニューアルのヒントを掴むため、「歯磨き粉に関するアンケート」を実施しました。
以下の6項目に対し、歯磨き粉への期待を7段階評価をしてもらいました。量的データ(数値変数)として扱います。
- v1:歯の美白
- v2:歯石予防
- v3:口臭予防
- v4:歯周病予防
- v5:知覚過敏ケア
- v6:歯槽膿漏予防
7段階評価とは、以下のようなものです。
- 3:期待している
- 2:
- 1:
- 0:どちらとも言えない
- -1:
- -2:
- -3:期待していない
この評価は、消費者によってバラバラです。歯の美白を期待する人もいれば、歯槽膿漏予防を期待する人もいます。
このアンケート結果に対しクラスター分析を実施することで、似たような期待を持った人をグルーピングし、どのような期待を持った人がどのくらいいるのか、を分析したいと思います。
さらに、属性情報として、以下の2項目についても情報が取れています。質的データ(カテゴリカル変数)です。
- age:年代
- gender:性別
まとめると……
- v1~v6:量的データ
- age、gender:質的データ
今回のクラスター分析で利用するサンプルデータは、以下からダウンロードできます。
Sampledata067.csv
https://www.salesanalytics.co.jp/6wqz
今回実施するクラスター分析
今回は2つのクラスター分析を実施します。
- 階層型クラスター分析(量的変数のみ)
- 階層型クラスター分析(量質混合)
前者は、普通の階層型クラスター分析です。後者は、質的変数を含めて実施するクラスター分析です。
この2つのクラスター分析の違いは、質的変数(age、gender)を含めるかどうかだけです。
Python Gowerのインストール
コマンドプロンプト上で、pipでインストールするときのコードは以下です。
pip install gower
必要なライブラリーの読み込み
以下、コードです。
# 必要なライブラリーの読み込み
import pandas as pd
import numpy as np
import gower
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import AgglomerativeClustering
# グラフのスタイルとサイズ
plt.style.use('ggplot')
plt.rcParams['figure.figsize'] = [12, 9]
デンドログラム描写用の関数の設定
デンドログラム描写用の関数を作ります。scikit-learnのサイトに記載されているものです。
以下、コードです。
# デンドログラム作成関数(Plot Hierarchical Clustering Dendrogram)
# https://scikit-learn.org/stable/auto_examples/cluster/plot_agglomerative_dendrogram.html
def plot_dendrogram(model, **kwargs):
counts = np.zeros(model.children_.shape[0])
n_samples = len(model.labels_)
for i, merge in enumerate(model.children_):
current_count = 0
for child_idx in merge:
if child_idx < n_samples:
current_count += 1 # leaf node
else:
current_count += counts[child_idx - n_samples]
counts[i] = current_count
linkage_matrix = np.column_stack([model.children_, model.distances_, counts]).astype(float)
dendrogram(linkage_matrix, **kwargs)
データセットの読み込み
データセットを読み込みます。
以下、コードです。
# データの読み込み filename = 'https://www.salesanalytics.co.jp/6wqz' df = pd.read_csv(filename) df
以下、実行結果です。

クラスター分析をするとき、回答者IDである「id」列は不要です。
さらに、量的データ(数値変数)である「v1~v6」を標準化((元のデーター平均)÷標準偏差)しクラスター分析を実施したいと思います。
以下、コードです。
# 前処理 ## id列の除去 df2 = df.drop(["id"], axis=1) ## 量的変数の標準化 var1 = ['v1','v2','v3','v4','v5','v6'] df2[var1] = StandardScaler().fit_transform(df[var1]) ## 確認 df2
以下、実行結果です。
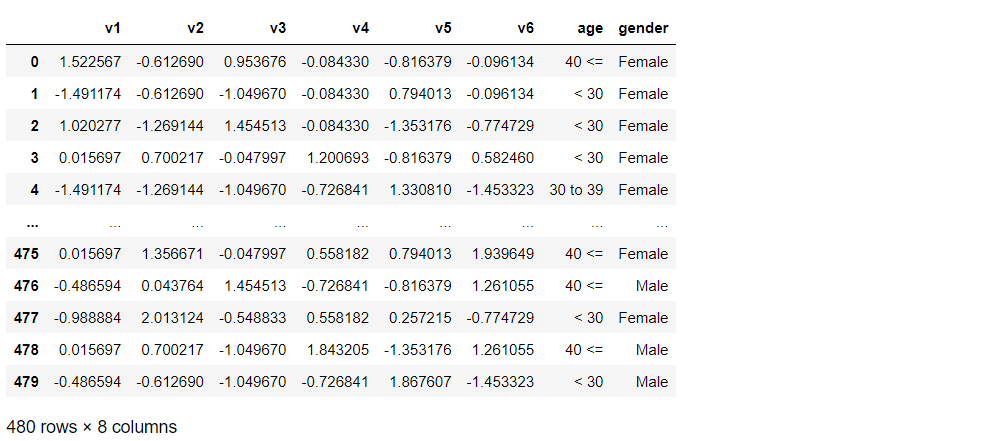
このデータを使い、クラスター分析を実施していきます。
階層型クラスター分析(量的変数のみ)
先ず、量的データ(数値変数)のみを使い階層型クラスター分析を実施します。
以下、コードです。
# 階層型クラスター分析の実施 model = AgglomerativeClustering(distance_threshold=0, n_clusters=None) model = model.fit(df2[var1].values)
クラスター分析の結果を、デンドログラムで見てみます。
以下、コードです。
# デンドログラムの描写(フルバージョン) plot_dendrogram(model)
以下、実行結果です。
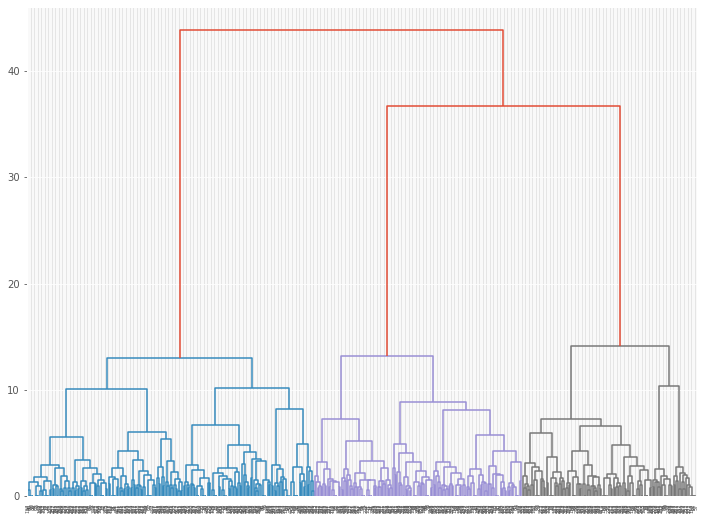
デンドログラムの下の方を切り捨てて見やすくします。約20のクラスターにまとめて見やすくします。
以下、コードです。
# デンドログラムの描写(クラスター数:約20) plot_dendrogram(model,truncate_mode='lastp',p=20)
以下、実行結果です。
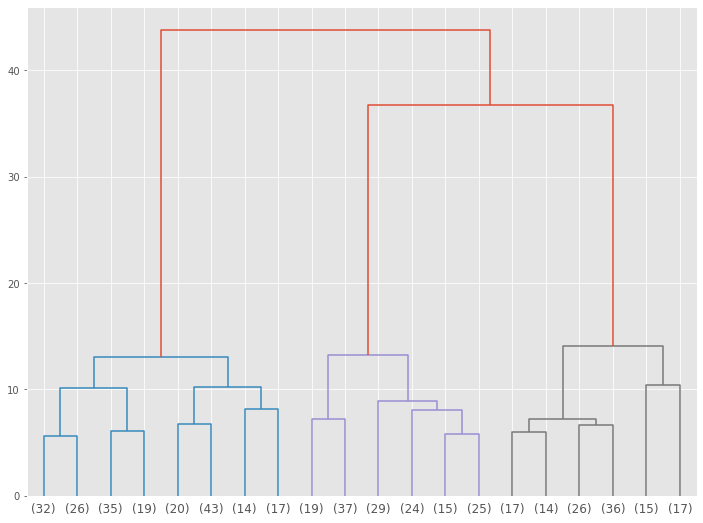
3クラスターに分かれそうです。
デンドログラムを3クラスターで表示してみます。
以下、コードです。
# デンドログラムの描写(クラスター数:3) plot_dendrogram(model,truncate_mode='lastp',p=3)
以下、実行結果です。
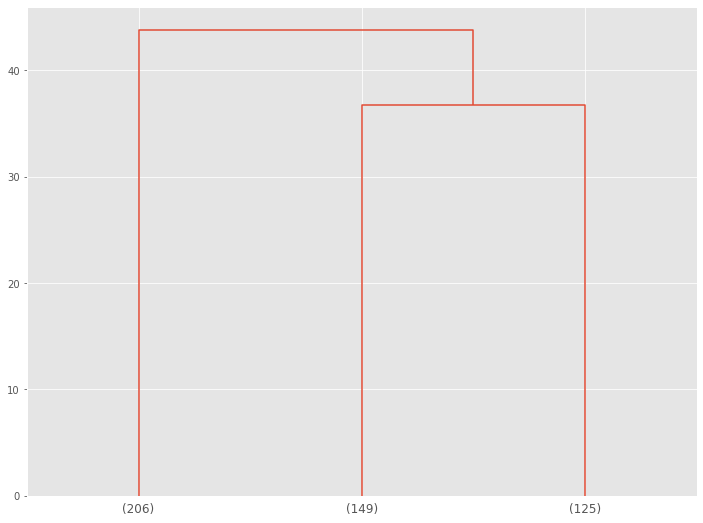
このデンドログラムの下の数字は、各クラスターのボリュームです。
クラスターID列を元データに追加します。
以下、コードです。
# 階層型クラスター分析の実施(クラスター数:3) model = AgglomerativeClustering(n_clusters=3) model = model.fit(df2[var1].values) # クラスターID列を元データに追加 df["cluster"] = model.labels_ df
以下、実行結果です。
クラスターのナンバーは、0から始まります。
各クラスターのボリュームを確認してみます。
以下、コードです。
# クラスターのボリューム df['cluster'].value_counts()
以下、実行結果です。

- CL0:125人
- CL1:206人
- CL2:149人
各クラスターの特徴を集計ベースで見ていきます。
以下、コードです。
# クラスター別集計(量的変数)※数表
var1_cl = ['v1','v2','v3','v4','v5','v6','cluster']
agg1 = ['mean','max','min','std']
df[var1_cl].groupby('cluster').agg(agg1).T
以下、実行結果です。
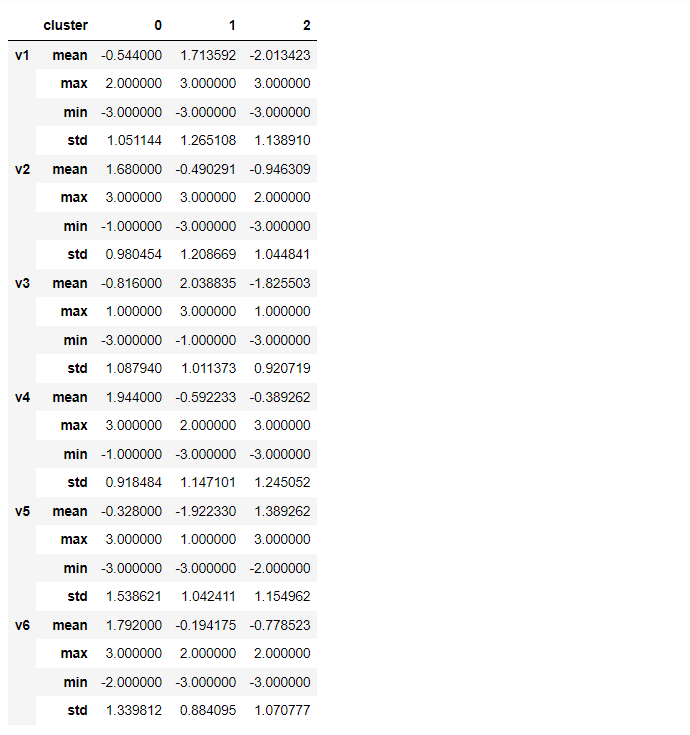
グラフ化します。
以下、コードです。
# クラスター別集計(量的変数)※グラフ(平均値)
cross_table = df[var1_cl].groupby('cluster').agg('mean')
cross_table.plot.bar()
以下、実行結果です。
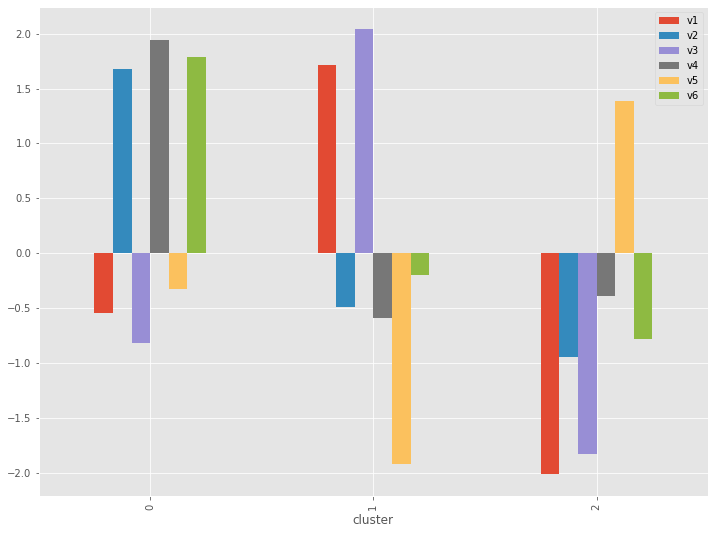
特徴が明確にでてきます。
- CL0:「v2:歯石予防」「v4:歯周病予防」「v6:歯槽膿漏予防」
- CL1:「v1:歯の美白」「v3:口臭予防」
- CL2:「v5:知覚過敏ケア」
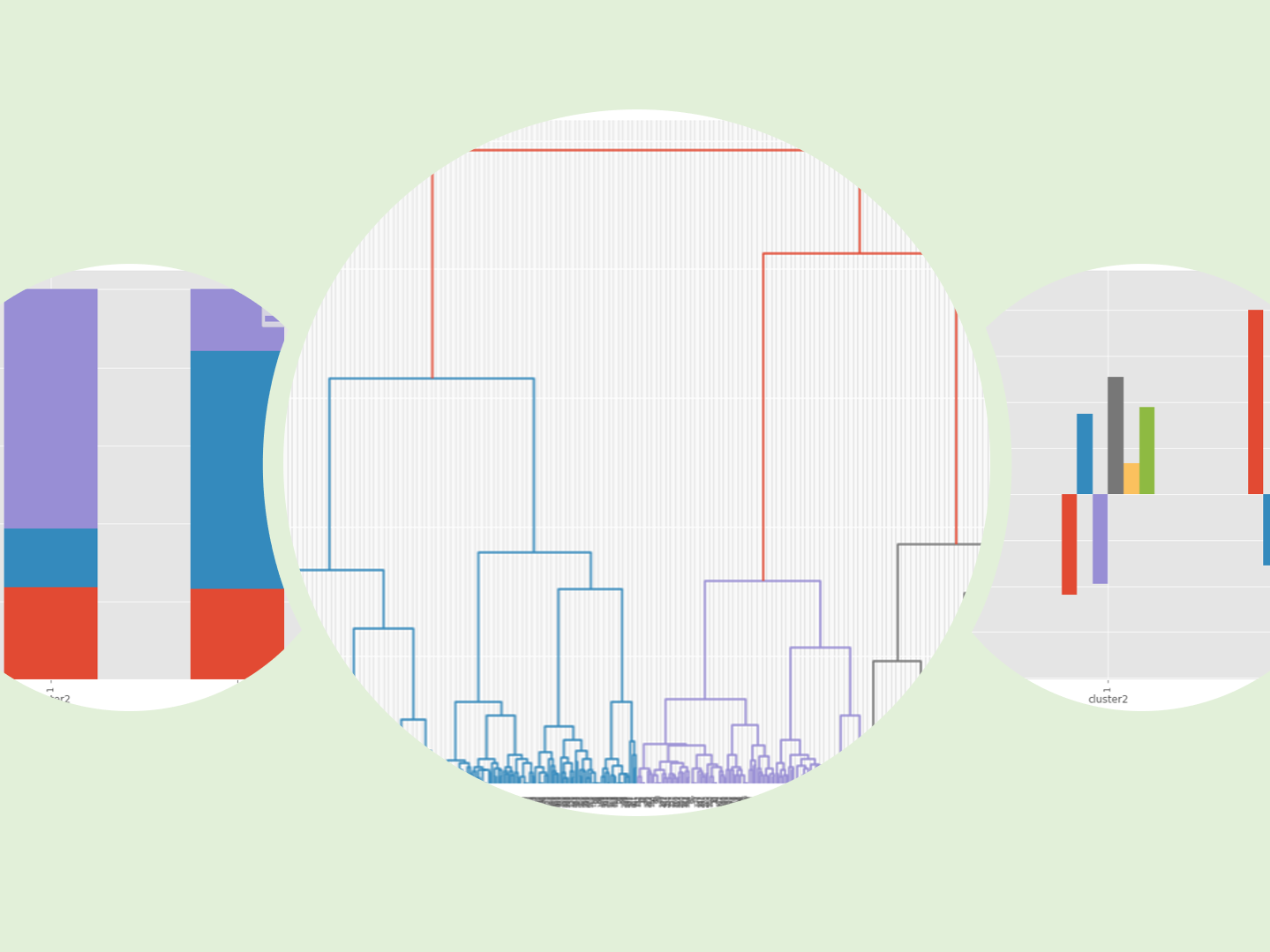
質的変数(age、gender)でもクラスターの特徴を見てみます。構成比です。
以下、コードです。
# クラスター別集計(質的変数) ※クロス集計(縦100%)CL別構成比
var2 = ['age','gender']
for varX in var2:
cross_table = pd.crosstab(df['cluster'], df[varX], normalize='index')
print(cross_table)
print()
cross_table.plot.bar(stacked=True)
以下、実行結果です。

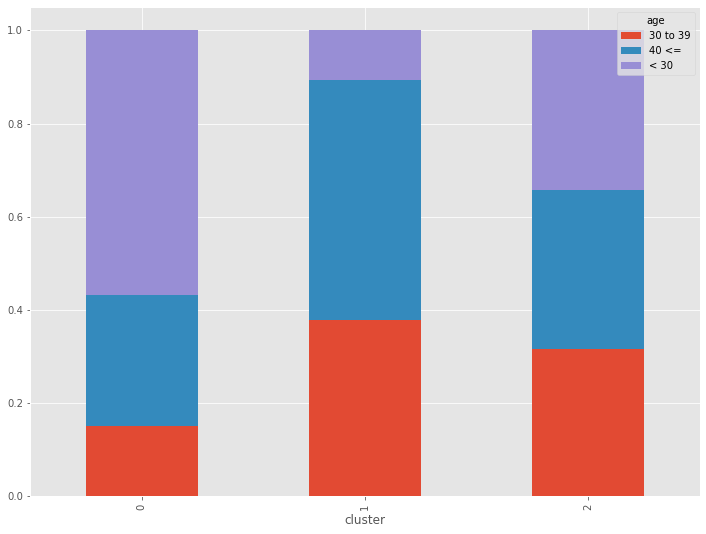
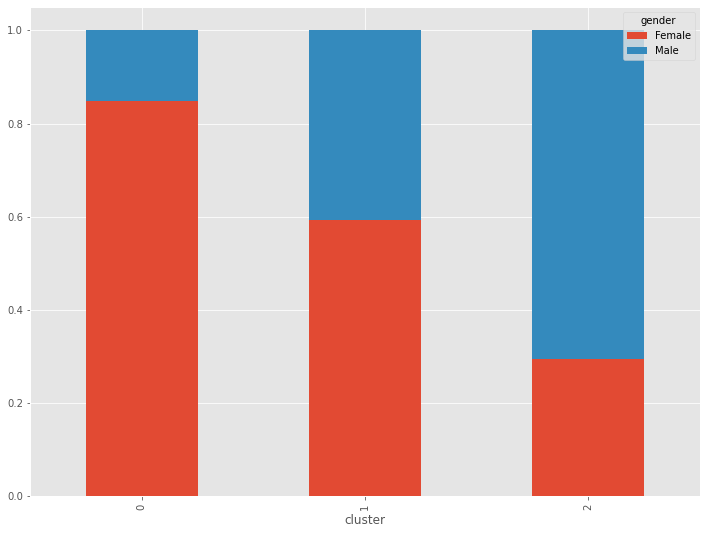
こちらも特徴がでてきます。
- CL0:30代以下・女性中心
- CL1:40代以上・男女半々
- CL2:年代均等・男性中心
質的変数(age、gender)を含めると、どうなるでしょうか?
階層型クラスター分析(量質混合)
次に、量質混在データ(数値変数とカテゴリカル変数)を使い階層型クラスター分析を実施します。
PythonのパッケージGowerを使い、量質混在データの距離を計算します。
以下、コードです。
# 距離の計算 distance_matrix = gower.gower_matrix(df2) distance_matrix
以下、実行結果です。

このGower距離を用いて、階層型クラスター分析を実施します。
以下、コードです。
# 階層型クラスター分析の実施 model = AgglomerativeClustering(compute_distances=True) model = model.fit(distance_matrix)
クラスター分析の結果を、デンドログラムで見てみます。
以下、コードです。
# デンドログラムの描写(フルバージョン) plot_dendrogram(model)
以下、実行結果です。
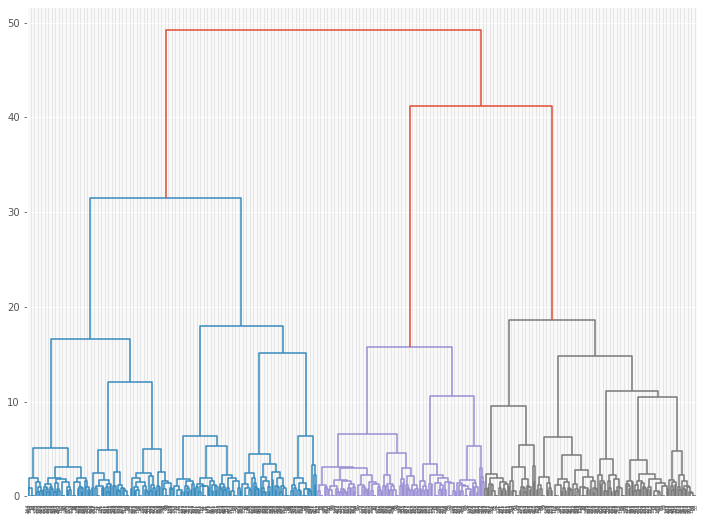
デンドログラムの下の方を切り捨てて見やすくします。約20のクラスターにまとめて見やすくします。
以下、コードです。
# デンドログラムの描写(クラスター数:約20) plot_dendrogram(model,truncate_mode='lastp',p=20)
以下、実行結果です。
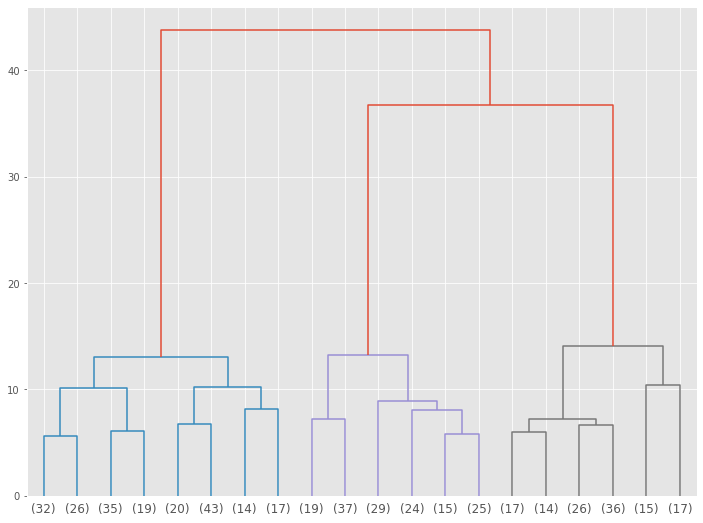
3クラスターに分かれそうです。
デンドログラムを3クラスターで表示してみます。
以下、コードです。
# デンドログラムの描写(クラスター数:3) plot_dendrogram(model,truncate_mode='lastp',p=3)
以下、実行結果です。
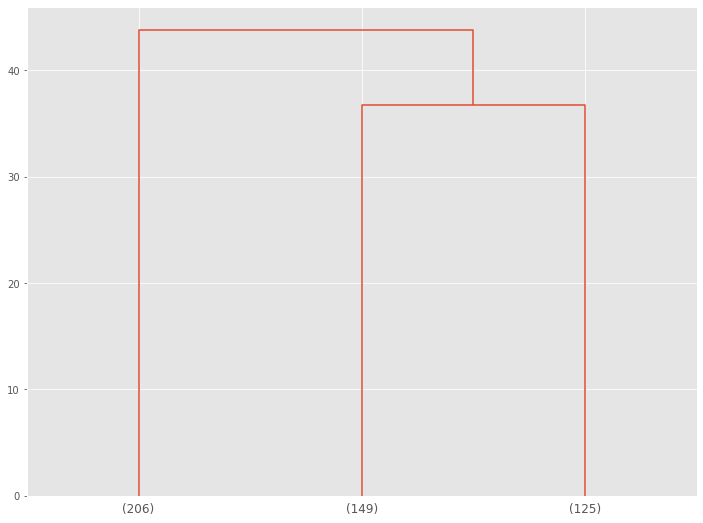
このデンドログラムの下の数字は、各クラスターのボリュームです。
クラスターID列を元データに追加します。
以下、コードです。
# 階層型クラスター分析の実施(クラスター数:3) model = AgglomerativeClustering(compute_distances=True,n_clusters=3) model = model.fit(distance_matrix) # クラスターID列を元データに追加 df["cluster2"] = model.labels_ df
以下、実行結果です。
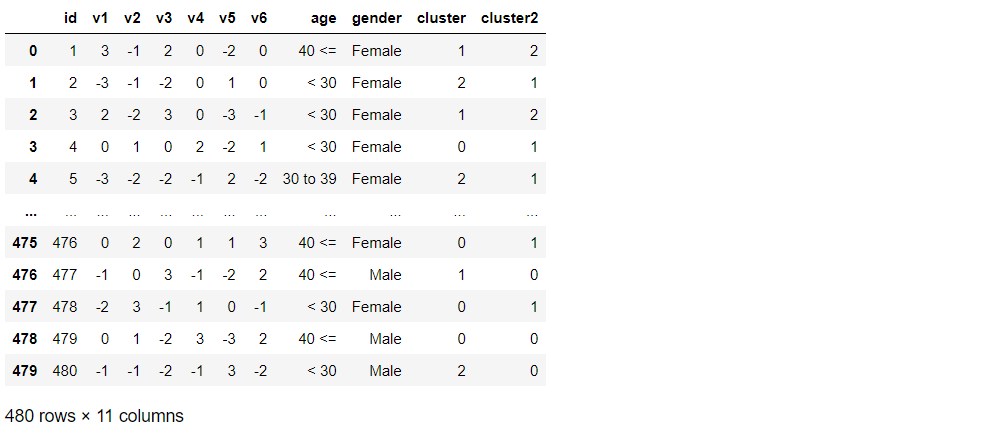
クラスターのナンバーは、0から始まります。
各クラスターのボリュームを確認してみます。
以下、コードです。
# クラスターのボリューム df['cluster2'].value_counts()
以下、実行結果です。

- CL0:208人
- CL1:152人
- CL2:120人
各クラスターの特徴を集計ベースで見ていきます。
以下、コードです。
# クラスター別集計(量的変数)※数表
var1_cl = ['v1','v2','v3','v4','v5','v6','cluster2']
agg1 = ['mean','max','min','std']
df[var1_cl].groupby('cluster2').agg(agg1).T
以下、実行結果です。
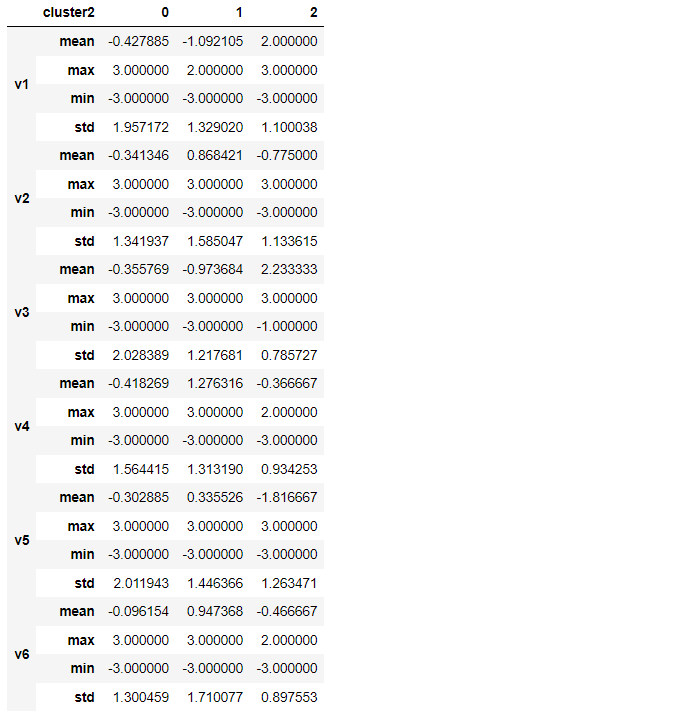
グラフ化します。
以下、コードです。
# クラスター別集計(量的変数)※グラフ(平均値)
cross_table = df[var1_cl].groupby('cluster2').agg('mean')
cross_table.plot.bar()
以下、実行結果です。
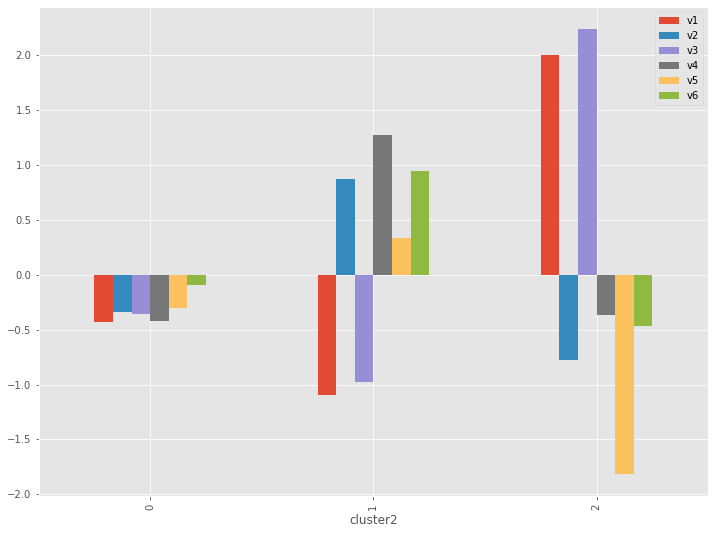
特徴が明確にでてきます。
- CL0:中庸
- CL1:「v2:歯石予防」「v4:歯周病予防」「v6:歯槽膿漏予防」
- CL2:「v1:歯の美白」「v3:口臭予防」
質的変数(age、gender)でもクラスターの特徴を見てみます。構成比です。
以下、コードです。
# クラスター別集計(質的変数) ※クロス集計(縦100%)CL別構成比
var2 = ['age','gender']
for varX in var2:
cross_table = pd.crosstab(df['cluster2'], df[varX], normalize='index')
print(cross_table.T)
print()
cross_table.plot.bar(stacked=True)
以下、実行結果です。

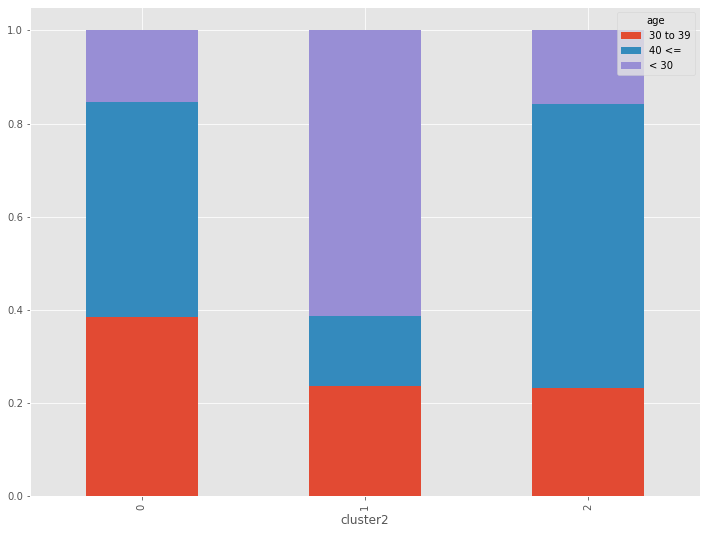
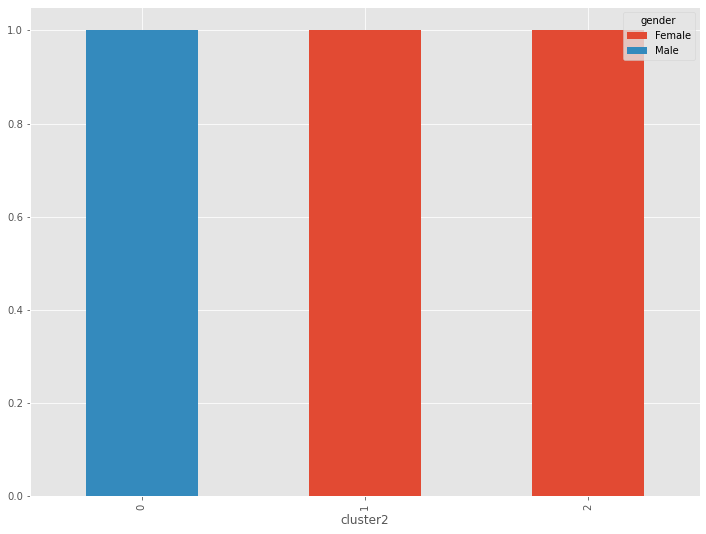
量的データ(数値変数)のみの階層型クラスター分析に比べ、特徴がくっきりと出ています。
- CL0:40代以上男性
- CL1:30代以下女性
- CL2:40代以上女性
まとめ
今回は、「Gower距離による階層型クラスタリング(Python)」というお話しをしました。
Gower距離を使うことで、量質混在データ(数値変数とカテゴリカル変数が混在)に対しクラスター分析を実施することができます。
今回はPythonのケースでしたが、もちろんRでも実施できます。
Gower距離を使わない方法もあります。有名なのはk-prototype法です。k-means法の親戚です。
どこかの機会に、Rで実施する方法と、k-prototype法による量質混在データに対するクラスター分析について説明します。
k-prototype法では、Gower距離とは異なる距離関数を使います。