
売上などのビジネス系のデータの多くは、時間概念が紐付いた時系列データです。
時間概念を取っ払ったテーブルデータと異なり、時系列データは、過去の値に大きく依存する、という特徴があります。そのため、一工夫必要になります。例えば、予測モデルなどを構築するときです。
予測モデルなどを構築するとき、特徴量(説明変数)エンジニアリングは非常に重要です。適切な特徴量(説明変数)を作ることができれば、予測精度も解釈性も非常に向上します。
以下、時系列データで予測モデルなどを構築するときに用いる、5種類の主な特徴量(説明変数)です。
- ドメイン固有特徴量
- カレンダー特徴量
- ラグ特徴量
- ローリング特徴量
- エクスパンディング特徴量
個々の特徴量の説明は、以下の記事で説明しています。
ドメイン固有特徴量はデータ活用する現場の知見を元に構築する特徴量(説明変数)で、カレンダー特徴量は平日・休日・クリスマスなどの特徴量(説明変数)です。
今回は以下の3つの特徴量の作り方を、PythonのPandasを使った作り方に付いて説明します。
- ラグ特徴量(Lag Features)
- ローリング特徴量(Rolling Window Features)
- エクスパンディング特徴量(Expanding Window Features)
Contents [hide]
必要なライブラリーの読み込み
先ず、必要なライブラリーを読み込みます。
以下、コードです。
# 必要なライブラリーの読み込み from pandas import read_csv from pandas import DataFrame from pandas import concat
データセットの読み込み
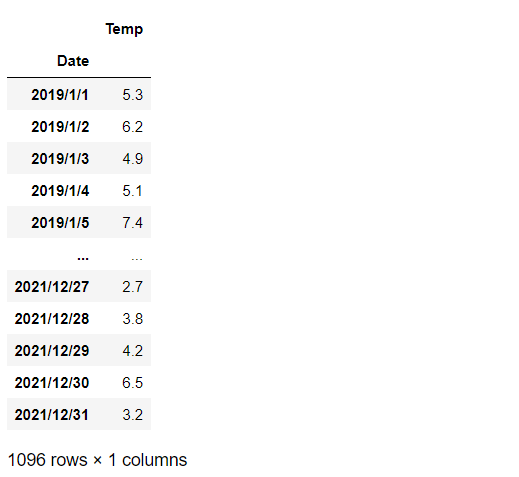
今回は、東京の平均気温(2019年1月1日~2021年12月31日)の時系列のデータセットを使います。日付と平均気温だけのデータセットです。
以下からダウンロードできます。
東京の平均気温(tokyo_daily-mean-temperatures.csv)
https://www.salesanalytics.co.jp/5kf2
では、読み込みます。以下、コードです。
# データ読み込み
series = read_csv('https://www.salesanalytics.co.jp/5kf2',index_col=0)
series #確認
以下、実行結果です。
ラグ特徴量(Lag Features)
例えば、t期の気温を予測したい場合、前日すなわちt-1期の気温を特徴量として使用したり、前々日すなわちt-2期の気温を特徴量として使用することがあります。t-1期の気温やt-2期の気温をラグ特徴量と言います。
shift()関数でラグ特徴量を作ることができます。ラグ1の特徴量(例:t-1期の気温)を作るときはshift(1)、ラグ2の特徴量(例:t-2期の気温)を作るときはshift(2)とします。
では、作ってみます。以下、コードです。
# ラグ特徴量(Lag Features) # shift()関数でラグ特徴量の生成 temps = DataFrame(series.values) print(temps.shift(1)) #ラグ1(1期前のデータ) print(temps.shift(2)) #ラグ2(2期前のデータ)
以下、実行結果です。

ラグ特徴量はデータをずらして作るため、NaN(Not a Number、非数)が登場します
元のデータに、ラグ特徴量を付けたデータセットを作ります。
以下、コードです。
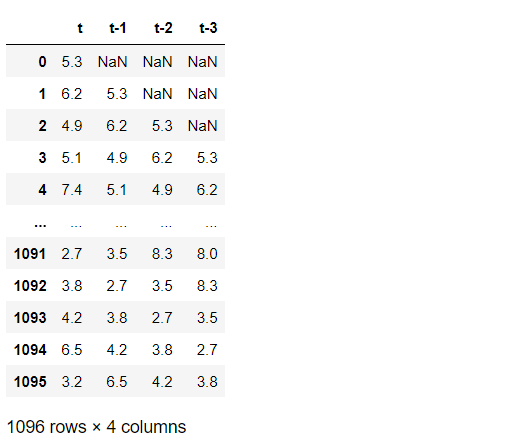
# ラグ特徴量付データセット
df = concat([temps,
temps.shift(1),
temps.shift(2),
temps.shift(3)
],
axis=1
)
df.columns = ['t',
't-1',
't-2',
't-3'
]
df
以下、実行結果です。
ローリング特徴量(Rolling Window Features)
ローリング特徴量とは、過去の一定期間(Rolling Window)の集計値を特徴量(説明変数)としたものです。
rolling()関数でローリング特徴量を作ることができます。例えば、過去3期を対象とする場合、rolling(3)とします。
過去3期平均(当期含む)のローリング特徴量を作ってみます。
以下、コードです。
# ローリング特徴量(Rolling Window Features) # 過去3期平均(当期含む)~ mean(t-2,t-1,t) window = temps.rolling(window=3) means_11 = window.mean() means_11
以下、実行結果です。

次に、過去3期平均(前期まで)のローリング特徴量を作ってみます。
以下、コードです。
# ローリング特徴量(Rolling Window Features) # 過去3期平均(前期まで)~ mean(t-3,t-2,t-1) shifted = temps.shift(1) window = shifted.rolling(window=3) means_12 = window.mean() means_12
以下、実行結果です。

元のデータに、ローリング特徴量を付けたデータセットを作ります。
以下、コードです。
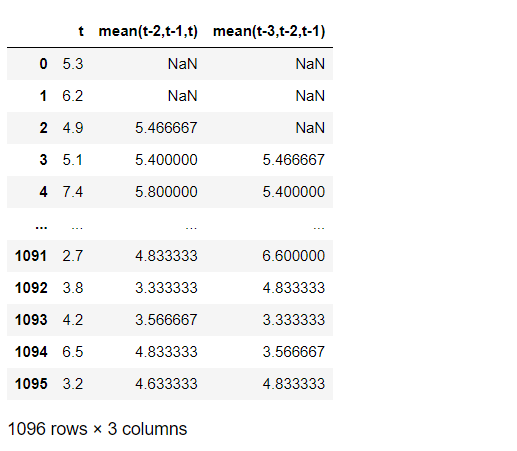
# ローリング特徴量付データセット
df = concat([temps,
means_11,
means_12],
axis=1)
df.columns = ['t',
'mean(t-2,t-1,t)',
'mean(t-3,t-2,t-1)']
df
以下、実行結果です。
エクスパンディング特徴量(Expanding Window Features)
エクスパンディング特徴量とは、過去すべての期間(Expanding Window)の集計値を特徴量(説明変数)としたものです。
expanding()関数でローリング特徴量を作ることができます。
全過去平均(当期含む)のエクスパンディング特徴量を作ってみます。
以下、コードです。
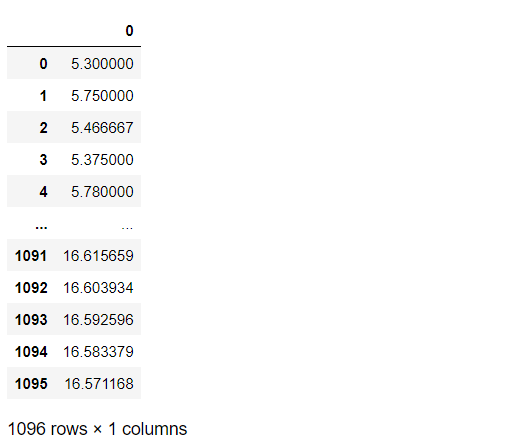
# エクスパンディング特徴量(Expanding Window Features) # 全過去平均(当期含む)~ mean(…,t) window = temps.expanding() means_21 = window.mean() means_21
以下、実行結果です。
次に、全過去平均(前期まで)のエクスパンディング特徴量を作ってみます。
以下、コードです。
# エクスパンディング特徴量(Expanding Window Features) # 全過去平均(前期まで)~ mean(…,t-1) shifted = temps.shift(1) window = shifted.expanding() means_22 = window.mean() means_22
以下、実行結果です。

元のデータに、エクスパンディング特徴量を付けたデータセットを作ります。
以下、コードです。
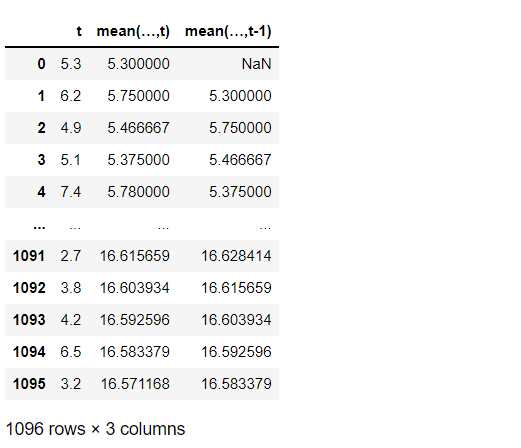
# エクスパンディング特徴量付データセット
df = concat([temps,
means_21,
means_22],
axis=1)
df.columns = ['t',
'mean(…,t)',
'mean(…,t-1)']
df
以下、実行結果です。
ラグ特徴量・ローリング特徴量・エクスパディング特徴量付データセット
最後に、3つの特徴量を付けたデータセットを作ります。
以下、コードです。
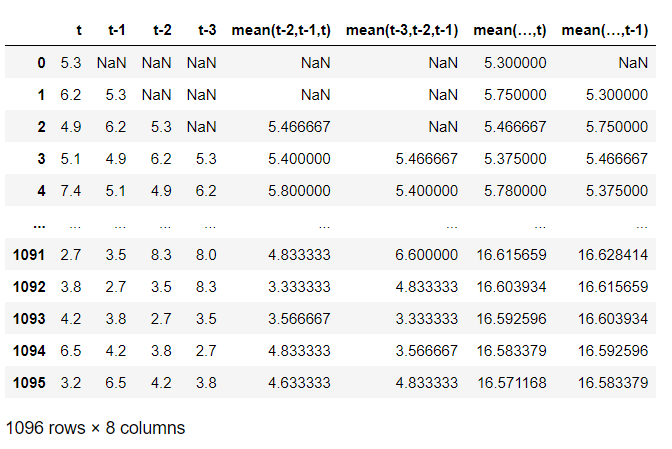
# ラグ特徴量+ローリング特徴量+エクスパディング特徴量付データセット
df = concat([temps,
temps.shift(1),
temps.shift(2),
temps.shift(3),
means_11,
means_12,
means_21,
means_22,
],
axis=1
)
df.columns = ['t',
't-1',
't-2',
't-3',
'mean(t-2,t-1,t)',
'mean(t-3,t-2,t-1)',
'mean(…,t)',
'mean(…,t-1)'
]
df
以下、実行結果です。
まとめ
今回は以下の3つの特徴量の作り方を、PythonのPandasを使った作り方に付いて説明しました。
- ラグ特徴量(Lag Features)
- ローリング特徴量(Rolling Window Features)
- エクスパンディング特徴量(Expanding Window Features)
時系列データで予測モデルなどを構築するときに参考にして頂ければと思います。