


集めるデータのイメージが付いたら、次にデータを集めなければなりません。
データ集める際にデータ品質が高いのが理想です。データ品質が低いと、後々のデータ分析やアクションなどに悪い影響を及ぼします。
データ品質を決めるのは、データの前提をきちんと認識しておくことです。
データの「収集」について全5回にわたってお話しいたします。
- その1 データソースの種類
- その2 まずはセカンダリーデータ ⇒ 今回
- その3 より正確にはプライマリーデータ
- その4 最重要なのはデータの前提
- その5 データは対で集める
前回は、その1の「データソースの種類」についてお話ししました。
今回は、その2の「まずはセカンダリーデータ」というお話しをします。
Contents
セカンダリーデータは必ず集める
集めるデータがプライマリーデータであろうがセカンダリーデータであろうが、セカンダリーデータを最初に集めます。
プライマリーデータを集める場合、セカンダリーデータは必要です。
「どのようなデータをプライマリーデータとして集めれば良いのか?」の参考にするためです。

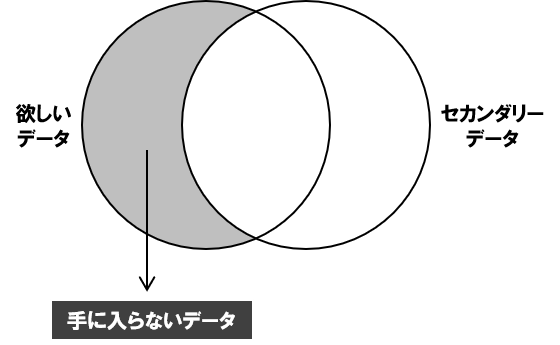
本当に欲しいデータが手に入らない
セカンダリーデータだけでことが済めば、それが一番です。
時間の節約になります。コストの節約になります。

しかし、本当に欲しいデータが手に入らないもどかしさがあります。

公的な統計データ
セカンダリーデータの代表は公的な統計データです。
国から色々なデータが公表されています。参考になるデータも多いです。客観的な数値データが豊富にあります。

e-stat(政府統計の総合窓口、http://www.e-stat.go.jp/)というインターネットサイトが非常に参考になります。
新聞などの記事
他には、新聞などの記事もセカンダリーデータです。

こちらは主観と客観が混じった定性データになります。
つまり、実際に起こった事実(客観データ)と記者の感じたこと(主観データ)が混じっています。
この点を意識する必要があります。色々な新聞の同じ話題の記事を見比べると、より鮮明に客観データと主観データが分かります。

世の中にセカンダリーデータが溢れている
セカンダリーデータは世の中に溢れています。
インターネットで検索し出てくるデータは、セカンダリーデータです。

辞書もセカンダリーデータです。

セカンダリーデータだけで十分にデータ分析は可能です。
しかし、本当に欲しいデータは発見できません。

何かしら問題点があります。
セカンダリーデータの問題点

例えば……
- データが古い
- データが大雑把
- データの範囲がせまい(首都圏だけのデータなど)
などなど。
要は、欲しいデータとピントが少しずれています。

つまり、セカンダリーデータを使った分析をするときには、本当に欲しいデータとのピントのずれを意識する必要があります。
そのずれがデータ分析の結果に大きく影響することがあります。気を付けましょう。
次回
今回は、その2の「まずはセカンダリーデータ」というお話しをしました。
- その1 データソースの種類
- その2 まずはセカンダリーデータ
- その3 より正確にはプライマリーデータ ⇒ 次回
- その4 最重要なのはデータの前提
- その5 データは対で集める
次回は、その3の「より正確にはプライマリーデータ」というお話しをします。
もっと知りたい方はこちら
 |
14のフレームワークで考える かんき出版 (2014/9/18) |