非線形計画問題の大域的最適化は、工学や経済学など様々な分野で重要な役割を果たしています。特に、問題の規模が大きくなると、局所的な最適解ではなく、大域的な最適解を見つけることが求められます。 これまでの連載では、Pytho...
本連載では、Pythonを用いた非線形計画問題の大域的最適化手法について、これまで3回にわたって解説してきました。 第1回では非線形計画問題と大域的最適化の基礎的な概念を取り上げました。 第2回ではメタヒューリスティクス...
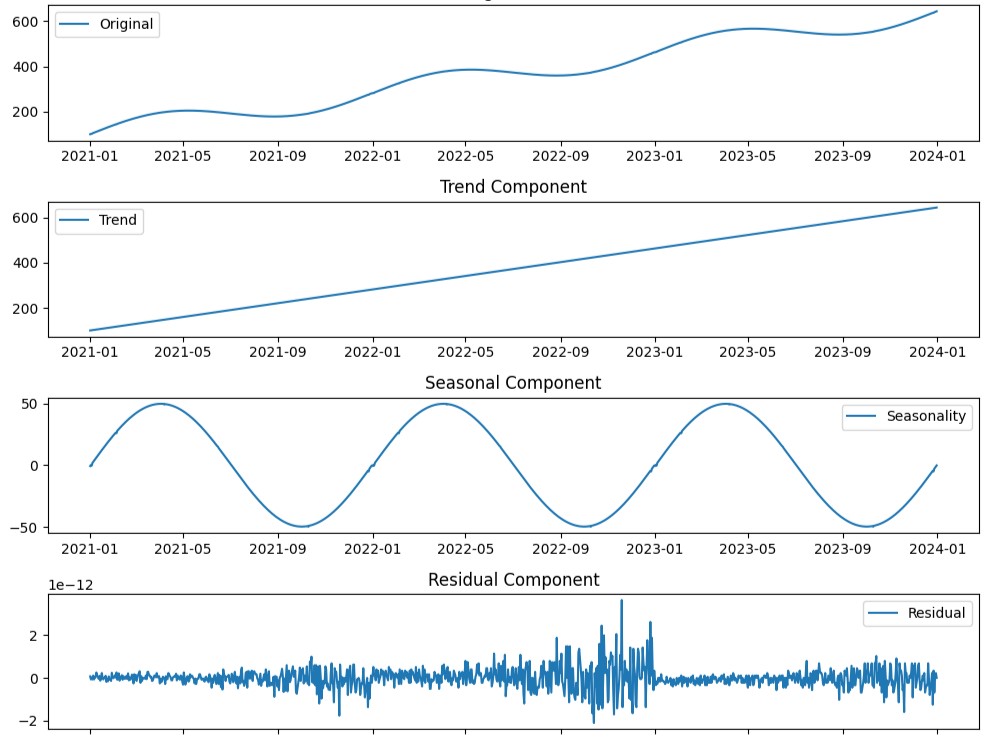
デジタル化の波が押し寄せる中で、ビジネスにおけるデータの重要性はますます高まっています。 特に、時系列データは経済指標、株価、気象情報など、あらゆる分野で収集されており、その分析から得られる洞察は企業の意思決定を大きく左...
ビジネス環境は常に変化しています。 市場の動向、消費者行動の変化、季節的な要因、経済の波など、多くの要素が企業の成長と収益性に影響を与えています。 これらの変化を理解し、将来のトレンドを予測するためには、時系列分析が不可...
前回は、メタヒューリスティクスを中心に、非線形計画問題の大域的最適化に挑戦しました。 メタヒューリスティクスは、問題依存性が低く、大域的最適解の探索に適した手法ですが、その性能はアルゴリズムの選択とパラメータ設定に大きく...
Pandasは、Pythonでデータ分析を行う際に広く使用されるオープンソースのライブラリです。 データサイエンスや機械学習の分野で必須のツールとされ、主にデータの前処理や探索的データ分析(EDA)に利用されます。 Pa...
前回は、非線形計画問題の基礎と、Pythonを使った定式化の方法について学びました。 非線形計画問題は、現実世界の様々な問題を数理的にモデル化するのに適していますが、その解法は一般に困難で、大域的最適解を求めることは容易...
ビジネスの意思決定に革命を起こす因果推論の力を、実践的に体験してみませんか? 企業が新たなマーケティング戦略を展開する際、医療専門家が治療法の効果を評価する時、または政策立案者が社会政策の成果を測る際に、単に「何が起こっ...
アンサンブル学習は、複数の機械学習モデルを組み合わせることで、単一のモデルよりも高い予測精度を達成する手法です。 アンサンブル学習は、現実世界の様々な問題に適用され、機械学習コンペティションでも常に上位を占める手法として...
最適化問題は、工学、経済学、物理学など様々な分野で登場します。機械学習のハイパーパラメータチューニング、構造設計の最適化、リソース配分の最適化など、最適な解を求めることは、多くの問題解決に不可欠です。 最適化問題の中でも...