前回は、非線形計画問題の基礎と、Pythonを使った定式化の方法について学びました。 非線形計画問題は、現実世界の様々な問題を数理的にモデル化するのに適していますが、その解法は一般に困難で、大域的最適解を求めることは容易...
ビジネスの意思決定に革命を起こす因果推論の力を、実践的に体験してみませんか? 企業が新たなマーケティング戦略を展開する際、医療専門家が治療法の効果を評価する時、または政策立案者が社会政策の成果を測る際に、単に「何が起こっ...
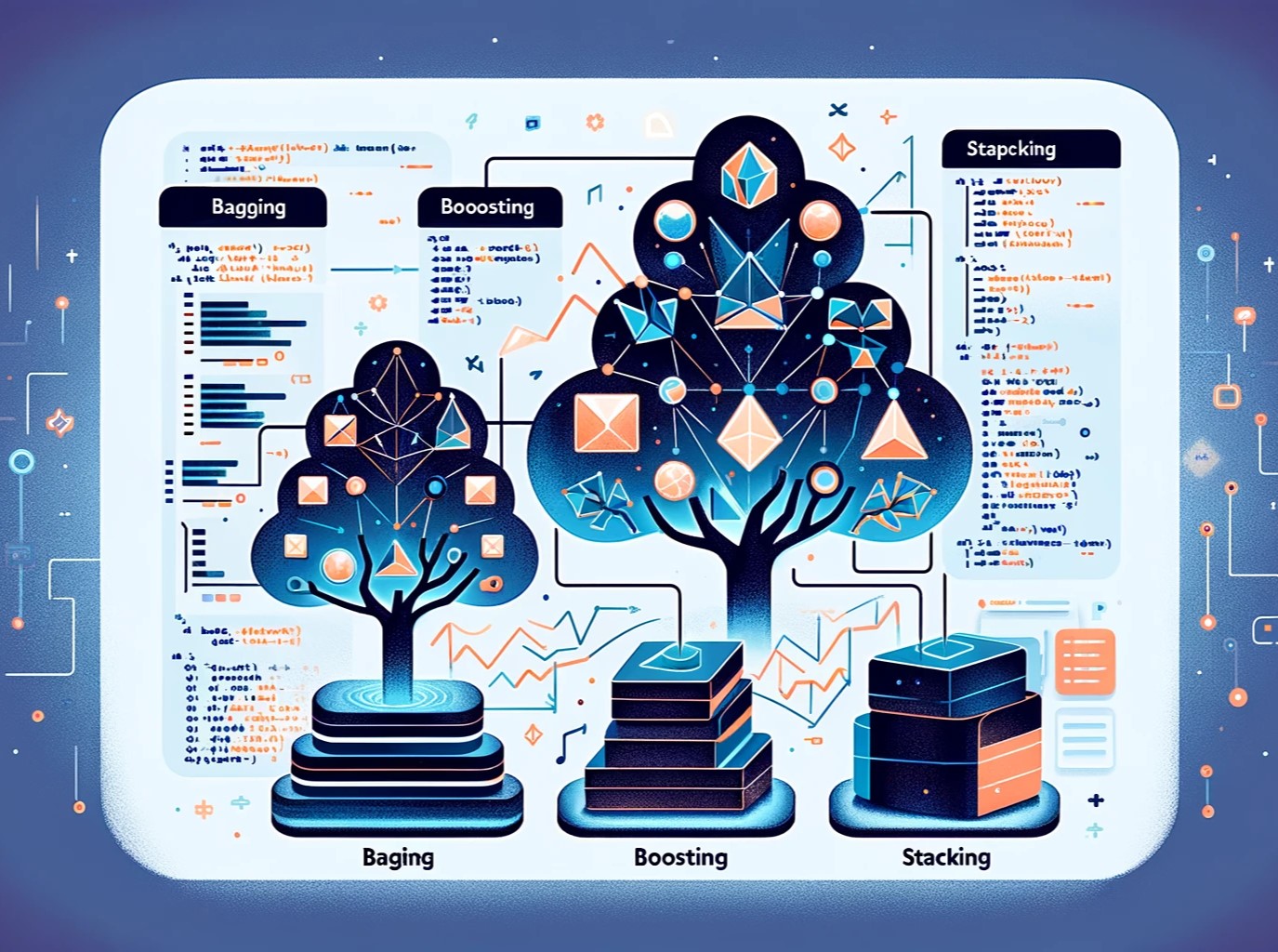
アンサンブル学習は、複数の機械学習モデルを組み合わせることで、単一のモデルよりも高い予測精度を達成する手法です。 アンサンブル学習は、現実世界の様々な問題に適用され、機械学習コンペティションでも常に上位を占める手法として...
最適化問題は、工学、経済学、物理学など様々な分野で登場します。機械学習のハイパーパラメータチューニング、構造設計の最適化、リソース配分の最適化など、最適な解を求めることは、多くの問題解決に不可欠です。 最適化問題の中でも...
データが語る物語の奥深くには、単なる相関関係を超えた「因果関係」が隠されています。 企業が新たなマーケティング戦略を展開する際、医療専門家が治療法の効果を評価する時、または政策立案者が社会政策の成果を測る際に、単に「何が...
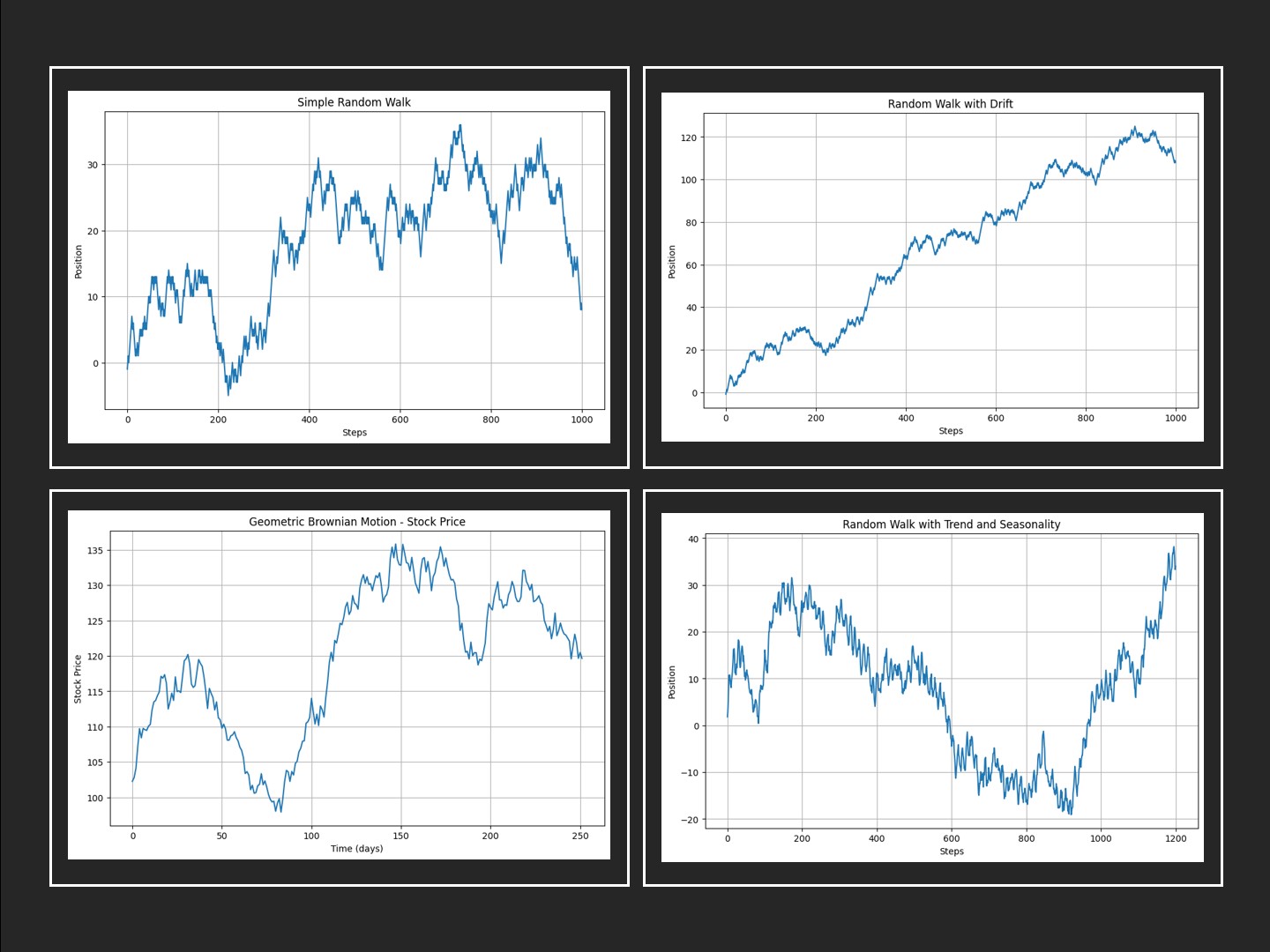
ビジネスの現場では時系列データは当然のごとく登場します。売上や販売データ、在庫データ、センサーデータなどすべて時系列データです。 そのような時系列データの中に、ランダムウォークと呼ばれる時系列データが登場することがありま...
Pythonプログラミングの世界におけるデバッグは、しばしば時間を要する煩雑なプロセスとなりがちです。 しかし、正しいツールを用いることで、このプロセスを大幅に簡素化し、より効率的かつ楽しいものに変えることができます。 ...
データサイエンスの進展に伴い、機械学習モデルの正確さを左右する重要な問題の一つがデータ不均衡です。 データ不均衡は、特定のクラスのサンプル数が他のクラスに比べて極端に少ない場合に発生し、予測モデルの性能に悪影響を及ぼしま...
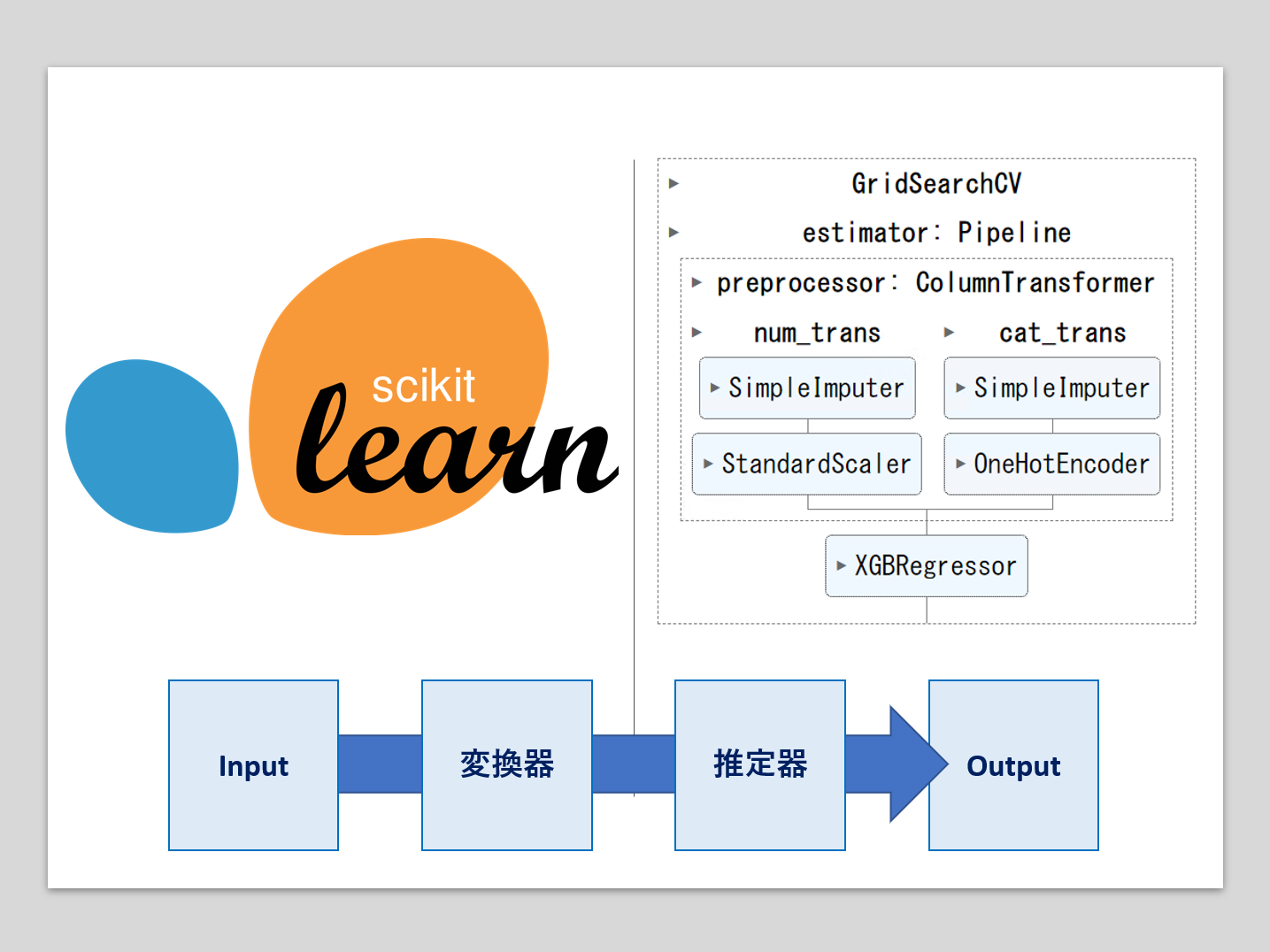
機械学習のパイプラインとは、複数の処理を直列に連結したものです。 最小構成は、1つの変換器と1つの推定器(予測器)を連結したものです。 変換器:特徴量X(説明変数)などの欠測値処理や変数変換などの、特徴量変換(Trans...
機械学習のパイプラインとは、複数の処理を直列に連結したものです。 最小構成は、1つの変換器と1つの推定器(予測器)を連結したものです。 変換器:特徴量X(説明変数)などの欠測値処理や変数変換などの、特徴量変換(Trans...