

機械学習モデルを構築する際、利用可能なデータセットを学習データとテストデータに分割することが一般的です。
学習データはモデルの訓練に使用され、モデルがデータからパターンを学ぶためのものです。
一方、テストデータはモデルがどれだけうまく一般化されたか、つまり未知のデータに対してどれだけ正確に予測できるかを評価するために使用されます。
この分割は、モデルの性能を正確に評価し、過学習を避けるために不可欠です。
では、説明変数を加工などする特徴量エンジニアリングは、どのタイミングにすべきでしょうか?
多くの場合、学習データとテストデータに分割する前がいいでしょう。
なぜでしょうか?
今回は、「なぜ特徴量エンジニアリングの前に、学習データとテストデータに分割するのか?」というお話しをします。
Contents [hide]
- データ分割の基本概念
- 学習データとテストデータの定義
- 分割の目的と利点
- 最も重要な利点
- 特徴量エンジニアリングの役割と重要性
- 特徴量エンジニアリングとは何か
- なぜ特徴量エンジニアリングが重要か
- データ分割前に特徴量エンジニアリングを行わない理由
- データ漏洩のリスクとその影響
- モデルの汎化能力と過学習の問題
- 実践的なデータ分割戦略
- ランダム分割と層化抽出
- 時系列データの取り扱い
- 不均衡データの取り扱い
- 特徴量エンジニアリングの適用方法
- 学習データに対する特徴量エンジニアリング
- テストデータに対する特徴量エンジニアリングの適用時点と方法
- ケーススタディと実例
- サンプルデータの概要
- データの前処理と分割
- 特徴量エンジニアリング
- モデルの訓練と評価
- 今回のまとめ
データ分割の基本概念
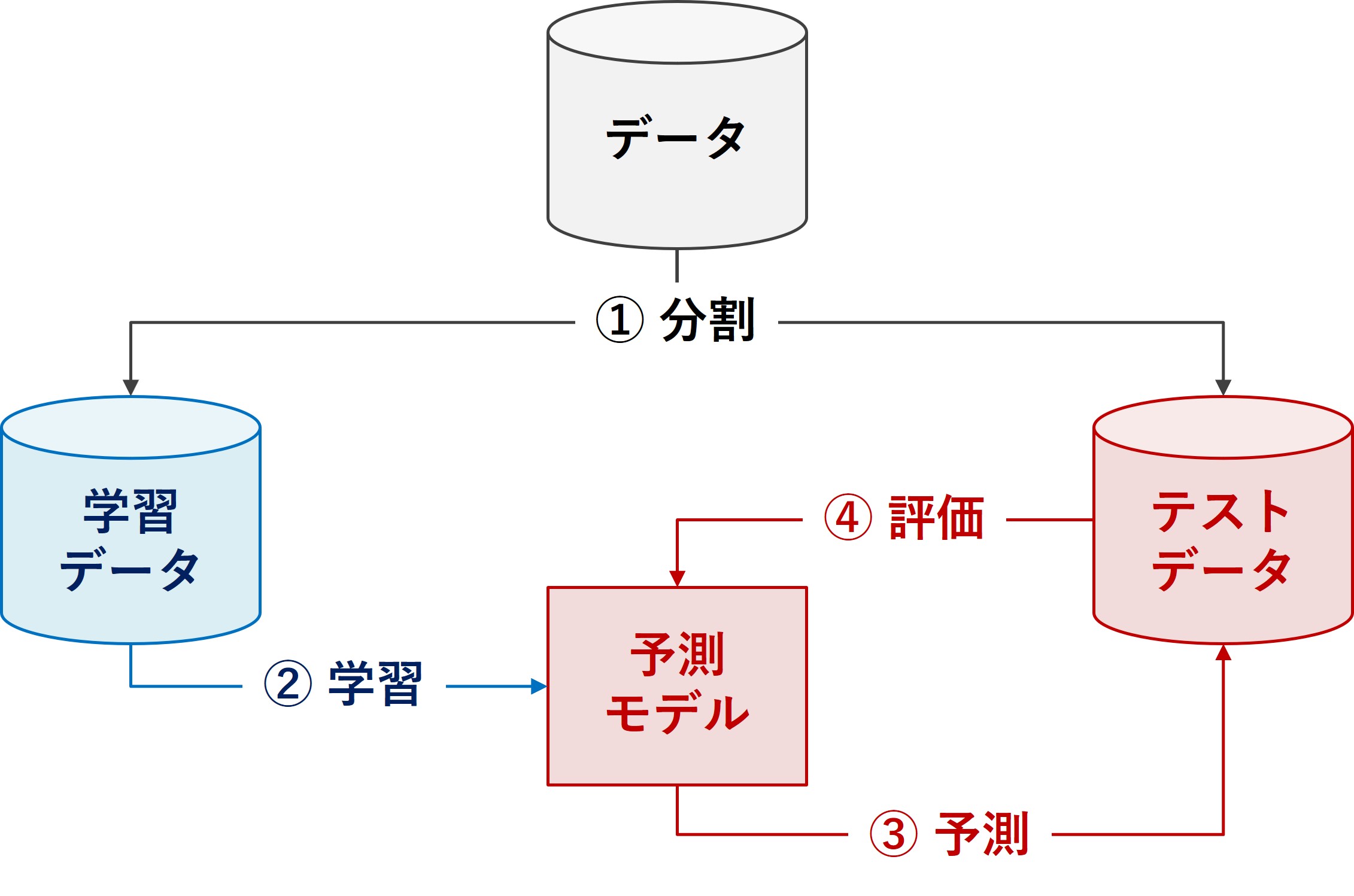
学習データとテストデータの定義
機械学習プロジェクトにおいて、データセットは通常、学習データとテストデータの二つに分割されます。
学習データは、モデルがパターンを識別し、学習するために使われます。このデータを通じて、モデルは特定の入力から出力を予測する方法を学びます。
一方、テストデータは、訓練済みのモデルがどれだけ効果的に新しいデータに対応できるかを評価するために使用されます。
このデータは、訓練プロセス中にはモデルに露見されず、最終的なモデルのパフォーマンスを公平にテストするために使われます。
分割の目的と利点
データ分割の主な目的は、モデルの汎化能力を評価することです。
モデルが学習データに対して高い精度を示しても、未知のデータに対して同様に機能するとは限りません。
学習データとテストデータを分離することで、モデルが単に訓練データを記憶しているのではなく、実際に有用なパターンを学習しているかどうかを確認できます。
最も重要な利点
分割には複数の利点があります。最も重要なのは、モデルの過学習を防ぐことです。
過学習は、モデルが訓練データの特定の特徴に過度に適応し、新しいデータに対してうまく機能しない状態を指します。
また、テストデータを使ってモデルの性能を評価することで、異なるモデルやアルゴリズムを客観的に比較することが可能になります。
特徴量エンジニアリングの役割と重要性

特徴量エンジニアリングとは何か
特徴量エンジニアリングは、機械学習においてデータから有意義な特徴量(説明変数)を作り出し、改善するプロセスです。
このプロセスには、既存のデータから新しい特徴量を導出する、不要または誤解を招く特徴量を削除する、特徴量の変換や正規化などが含まれます。
効果的な特徴量エンジニアリングは、モデルのパフォーマンスを大幅に向上させる可能性があります。
なぜ特徴量エンジニアリングが重要か
良質な特徴量は、モデルがデータ内の重要なパターンや関係性をより効率的に、より正確に把握するのを助けます。逆に、不適切な特徴量は、モデルの性能を損なう原因となり得ます。
特徴量の選択と変換は、モデルが複雑なデータセットを理解し、有意義な予測を行うための基盤となるため、このプロセスには特に注意が必要です。
さらに、特徴量エンジニアリングは、データの次元を減らすことで、計算資源の使用を最適化し、モデルのトレーニング時間を短縮することができます。
また、適切に実施された特徴量エンジニアリングは、モデルの解釈可能性を高めることにも寄与します。これは、特にビジネスの意思決定に機械学習モデルを用いる際に重要です。
データ分割前に特徴量エンジニアリングを行わない理由

データ漏洩のリスクとその影響
データ分割前に特徴量エンジニアリングを行うと、データ漏洩(data leakage)のリスクが生じます。
データ漏洩とは、テストデータに関する情報が誤って学習プロセス中に使用されることを指します。
例えば、全データセットを用いて特徴量の正規化を行うと、テストデータの統計情報が学習データに含まれることになります。
これはモデルがテストデータに対して実際よりも高い性能を示す原因となり、現実世界でのモデルのパフォーマンスを誤って評価することにつながります。
モデルの汎化能力と過学習の問題
モデルの汎化能力は、未知のデータに対するその性能を指します。
特徴量エンジニアリングを分割後に行うことで、モデルが学習データに特化しすぎることなく、より一般的なパターンを学習することができます。
これにより、過学習(overfitting)を防ぐことができます。
過学習は、モデルが学習データの特異性に過剰に適合し、新しいデータに対してうまく機能しない状態を指します。
適切に分割されたデータセットを使用することで、特徴量エンジニアリングはモデルの汎用性と信頼性を保証するための重要な手段となります。
実践的なデータ分割戦略
ランダム分割と層化抽出
データ分割には複数のアプローチが存在しますが、最も一般的な方法はランダム分割です。
これはデータセットから無作為にサンプルを選び、それを学習データとテストデータに割り当てる方法です。
しかし、特定のケースでは層化抽出(stratified sampling)がより適切です。
層化抽出は、データセットの異なるサブグループ(層)が、学習データとテストデータの両方に均等に代表されるようにサンプルを選択する方法です。
これは特に、ターゲット変数の分布が不均一な場合に重要です。
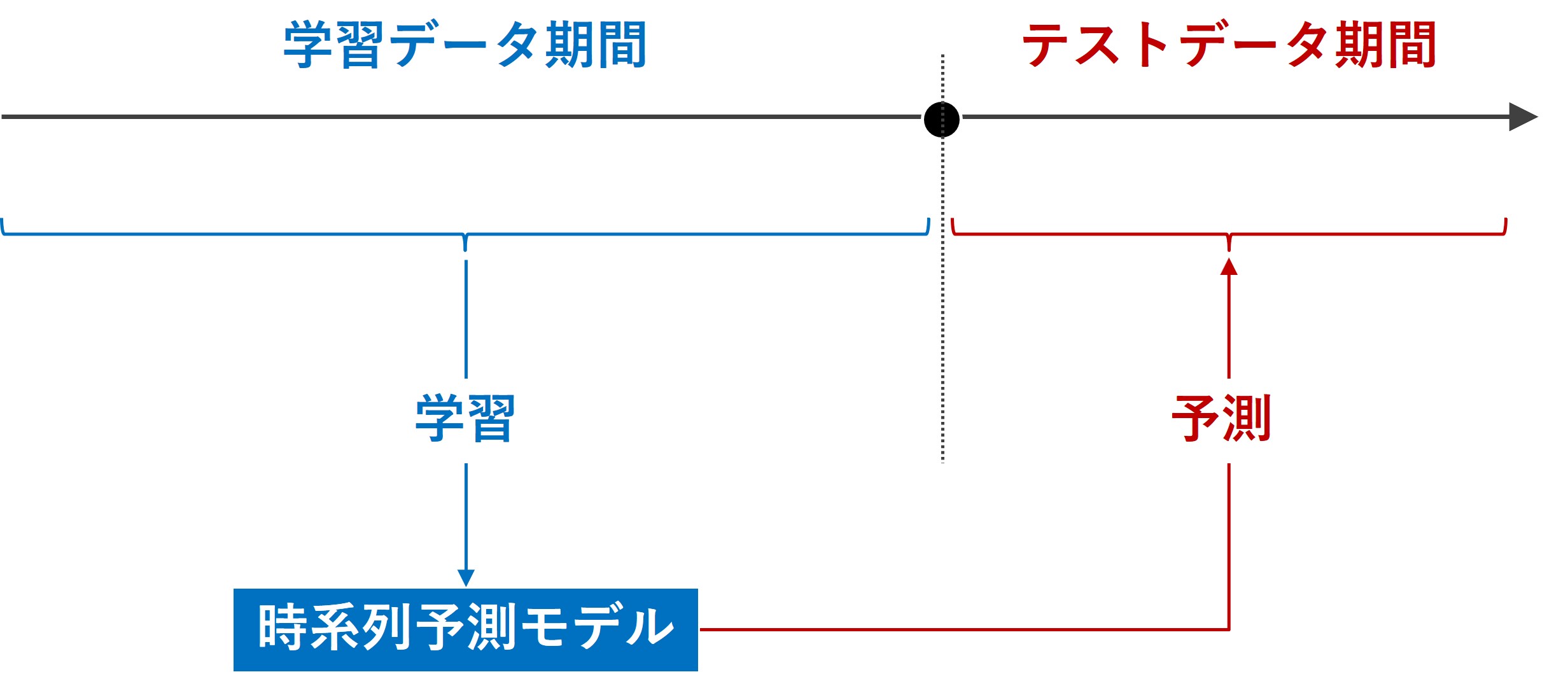
時系列データの取り扱い
時系列データの場合、ランダム分割は適切ではありません。
なぜなら、時系列データは時間的な順序が重要であり、ランダム分割はこの順序を破壊してしまうからです。
時系列データでは、特定の時点までのデータを学習用に、その後のデータをテスト用に使用するのが一般的です。
不均衡データの取り扱い
また、データセットが不均衡な場合(例えば、あるクラスのサンプルが他のクラスに比べて非常に少ない場合)、単純なランダム分割は不十分です。
このような場合、層化抽出を使用して、各クラスのサンプルが学習データとテストデータの両方に適切に反映されるようにする必要があります。
特徴量エンジニアリングの適用方法
学習データに対する特徴量エンジニアリング
特徴量エンジニアリングは主に学習データに適用されます。
この段階では、データの特性を把握し、モデルの学習に有効な特徴量を生成することが目的です。
学習データに対して行う特徴量エンジニアリングには、変数の変換、欠損値の処理、新しい変数の生成、カテゴリ変数のエンコーディングなどが含まれます。
これらの手法を適用することで、モデルがデータからパターンをより効率的に学習し、その予測精度を高めることができます。
テストデータに対する特徴量エンジニアリングの適用時点と方法
テストデータに対する特徴量エンジニアリングは、モデルの訓練が完了した後に行います。
重要な点は、テストデータに対しては、学習データで使用した同じ変換処理を適用することです。
例えば、学習データで行った正規化のパラメータ(平均と標準偏差など)をテストデータにも適用する必要があります。
これにより、モデルのパフォーマンスが現実のデータに対しても一貫していることを保証します。
テストデータに新しい特徴量を追加する際には、その特徴量が学習時には存在しなかった情報を含まないように注意が必要です。
ケーススタディと実例

サンプルデータの概要
ECの顧客データです。以下のような特徴が含まれています。
- 顧客ID
- 年齢
- 性別
- 過去の購買頻度(6か月間の購入回数)
- 過去の平均購買金額
- ウェブサイトの平均滞在時間
- 直近の購買からの経過日数
- ターゲット変数:次の1か月間に購買するかどうか(はい/いいえ)
データの前処理と分割
まず、データの前処理を行います。欠損値がある場合は適切な値で埋め、性別などのカテゴリ変数はワンホットエンコーディングを用いて数値化します。
次に、データを時間的順序に従って学習データ(最初の75%)とテストデータ(残りの25%)に分割します。
特徴量エンジニアリング
学習データに対する特徴量エンジニアリング
学習データに特徴量エンジニアリングを適用します。例えば、平均購買金額やウェブサイトの平均滞在時間などの数値データを正規化する場合、これらの特徴量の平均値と標準偏差を計算します。
新しい特徴量を生成します。例えば、「顧客の価値スコア」を、過去の購買行動から計算することができます。
テストデータに対する特徴量エンジニアリング
学習データで計算した平均値と標準偏差を使用して、テストデータの同じ特徴量を正規化します。要は、学習データで使用した同じパラメータを適用することで、モデルの評価が公平で一貫したものとなります。
テストデータに新しい特徴量を追加する場合、学習データで使用した同じ方法で計算する必要があります。
モデルの訓練と評価
モデルは学習データを用いて訓練され、テストデータを用いて評価されます。
この際、学習データで得た特徴量のパターンがテストデータにどの程度適用できるかを確認します。
特に、モデルが新しいデータに対しても正確に予測できるかどうかが重要です。
今回のまとめ
今回は、「なぜ特徴量エンジニアリングの前に、学習データとテストデータに分割するのか?」というお話しをしました。
- データ分割の重要性:学習データとテストデータの適切な分割は、モデルの汎化能力を評価し、過学習を防ぐために不可欠です。
- 特徴量エンジニアリングのタイミング:データ分割後に特徴量エンジニアリングを適用することで、データ漏洩を防ぎ、モデルの公平で正確な評価を保証します。
- 適切な特徴量の選択と変換:学習データに基づいて特徴量を適切に選択、生成、正規化し、同じ変換処理をテストデータに適用することが重要です。
データサイエンスにおいて、データの質は結果の質に直結します。
正確で一貫したデータ準備は、信頼できるモデルを構築するための基礎となります。
データ準備に対する注意深いアプローチは、データ駆動型の意思決定において、より良い結果をもたらすでしょう。