

データが未来を形作る今日、ビジネスリーダーたちは常により良い意思決定のための新しい手法を模索しています。
その答えの一つが、シャープレイバリューとツリー系モデルの組み合わせによるアプローチです。
シャープレイバリューは、ゲーム理論を扱う経済学者や心理学者だけのものではありません。最近は、データサイエンティストや機械学習エンジニアがビジネスの実務に適用し、意外なほど成果を出し始めています。
今回は、この先進的な技術がデータ駆動型の意思決定をどのように支援し、ビジネスモデルへの応用から実際のチャレンジまで、簡単な活用事例を通じてそのポテンシャルを探ります。
さらに、技術の進化とともに進む継続的な学習の重要性についても触れ、データサイエンスとビジネス戦略が未来にどう融合していくのか、その将来展望を探ります。
データの海を航海するすべてのビジネスリーダーにとって、この記事が羅針盤となることを願っています。
Contents [hide]
- はじめに
- シャープレイバリューの基礎
- シャープレイバリューとは?
- シャープレイバリューの例
- データサイエンスにおけるシャープレイバリュー
- シャープレイバリューの計算方法
- データサイエンスにおける例(顧客離反予測モデル)
- ツリー系モデルとシャープレイバリューの組み合わせ
- ツリー系モデルの概要と動作原理
- シャープレイバリューを用いたツリー系モデルの結果解釈
- 特徴量の寄与度に基づく意思決定の改善
- ビジネスでの活用事例
- 顧客セグメンテーションとターゲティング
- リスク評価とクレジットスコアリング
- 在庫管理と需要予測
- マーケティングキャンペーンの効果分析
- ビジネス実装における課題
- 計算コスト
- 解釈の難しさ
- データの前処理
- 将来展望
- シャープレイバリューがビジネス意思決定に与える影響
- 今後のデータサイエンスとビジネス戦略への応用
- 継続的な学習と技術の進化への適応
- 今回のまとめ
はじめに

データサイエンスとビジネス意思決定は、現代の経営戦略において中心的な役割を果たしています。
企業は日々膨大な量のデータを生成し、そのデータを分析して競争上の優位性を確保しようと試みています。
この過程で、ランダムフォレストや決定木などのツリー系アルゴリズムが重要なツールとして登場します。これらのアルゴリズムは、その柔軟性と解釈可能性により、多くのビジネス問題に対する有効な解決策を提供します。
しかし、モデルの予測がどのように導き出されたかを理解することは、特に複雑なモデルの場合、依然として挑戦的です。
ここでシャープレイバリューの概念が役立ちます。
シャープレイバリューは、ゲーム理論から派生した概念で、各プレイヤー(この場合は特徴量)がゲーム(モデルの予測)の結果にどの程度貢献しているかを数値化します。
これにより、モデルの予測に対する各特徴量の相対的な重要性を明らかにし、ビジネス上の意思決定をよりデータ駆動型にします。
シャープレイバリューの基礎

シャープレイバリューとは?
シャープレイバリューは、ゲーム理論において、複数のプレイヤーが協力して生成した利得を、各プレイヤーが公平に分配すべき割合を決定するための概念です。この概念は、Lloyd Shapleyによって1953年に提案されました。
シャープレイバリューは、プレイヤーの寄与を評価するために、すべての可能なプレイヤーの組み合わせを考慮に入れます。
ここでいう「プレイヤー」とは、ゲーム理論における参加者であり、ビジネスや経済学では、個人、企業、株式などがこれに当たります。
シャープレイバリューの例
シャープレイバリューの概念を理解するために、簡単な例を用いて説明します。
想定するゲームは、3人のプレイヤー(A、B、C)がいるとします。彼らはそれぞれ独立して利益を生み出すことができますが、互いに協力することでさらに大きな利益を生み出すことが可能です。
以下のような利得を考えます。
- A、B、Cが単独で行動した場合、それぞれの利得は100、200、300です。
- AとBが協力した場合、合計で400の利得を生み出すことができます。
- AとCが協力した場合、合計で500の利得を生み出します。
- BとCが協力した場合、合計で600の利得を生み出します。
- A、B、Cが全員で協力した場合、合計で900の利得を生み出します。
この状況で、シャープレイバリューを用いて各プレイヤーの貢献度を計算します。
計算の過程では、全ての可能なプレイヤーの組み合わせとその結果生じる利得の増分を考慮に入れます。
例えば、Aのシャープレイバリューを計算する場合、Aが参加することでどの程度利得が増加するかを、全ての組み合わせについて計算します。これをBとCについても行い、最終的に全てのプレイヤーの貢献度の合計がゲーム全体で生み出された利得と等しくなるようにします。
具体的な計算には、各プレイヤーがいない場合といる場合の利得の差分をすべての可能な組み合わせについて計算し、それらの平均を取ることが含まれます。この計算を通じて、各プレイヤーがゲーム全体の利得にどれだけ貢献しているか、つまり「公平な分配」とは何かを数値化できます。
この例では、シャープレイバリューを具体的に計算するには多くのステップを踏む必要がありますが、核心は全てのプレイヤーの貢献を公平に評価しようとする点にあります。この方法は、ビジネスや経済学だけでなく、データサイエンスの分野でも、特に複雑なモデルの解釈や特徴量の重要度を評価する際に応用されています。
データサイエンスにおけるシャープレイバリュー
シャープレイバリューは、ゲーム理論の分野で初めて導入されました。この理論は、複数のプレイヤーがいる協力ゲームにおいて、各プレイヤーのゲームに対する貢献度を公平に評価する方法を提供します。
データサイエンスにおいて、これらの「プレイヤー」とはモデルの予測に影響を与える特徴量(変数)を指し、シャープレイバリューはこれらの特徴量の貢献度を評価するのに使われます。
これにより、モデルがどのように決定を下しているか、どの変数が重要であるかを理解することが可能になります。
特に、ランダムフォレストや勾配ブースティングマシンなどの複雑なモデルの解釈に有効です。
シャープレイバリューの計算方法
シャープレイバリューを計算するプロセスは、全ての可能な特徴量の組み合わせに対してモデルの予測を評価し、各特徴量が予測にどれだけ影響を与えるかを平均化することを含みます。
具体的には、特徴量のサブセットを生成し、特定の特徴量が存在する場合と存在しない場合の予測値の差を計算します。これを全てのサブセットに対して行い、最終的に特徴量の平均貢献度を求めます。
この計算は非常に計算量が多いため、実際には近似的な方法が用いられることが多いです。
データサイエンスにおける例(顧客離反予測モデル)

ある通信会社は、顧客がサービスを解約するかどうかを予測するモデルを開発しました。このモデルは、顧客の月額支払額(monthly_payment)、契約期間(contract_period)、利用データ量(data_usage)、カスタマーサポートへの問い合わせ回数(contact_support)など、複数の特徴量を基にランダムフォレストアルゴリズムを使用しています。
| monthly_payment | contract_period | contact_support | data_usage | churned |
| 126.63 | 33 | 1 | 358.33 | 1 |
| 114.31 | 23 | 3 | 388.05 | 0 |
| 69.09 | 23 | 2 | 513.45 | 0 |
| 99.83 | 31 | 6 | 413.09 | 0 |
| 112.43 | 31 | 4 | 517.63 | 0 |
シャープレイバリューを使って、離反予測後に、各特徴量が顧客の離反予測にどれだけ影響を与えているかを定量化し、具体的なアクションに結ぶ付けることができまます。
離反予測
ある顧客がサービスを解約する確率を70%と予測したとします。
シャープレイバリューの計算
各特徴量のシャープレイバリューを計算することで、その顧客の離反予測における各特徴量の重要性を数値化します。例えば、月額支払額が高いことが離反確率を20%上昇させる主要因であることが判明したとします。一方で、カスタマーサポートへの問い合わせ回数は、予測に対して比較的小さい、たとえば5%の影響しか与えていないことがわかります。
結果分析
この情報をもとに、通信会社は高額の月額プランを見直したり、顧客サポートの改善による影響が限定的であることを認識するなど、具体的な行動を取ることができます。
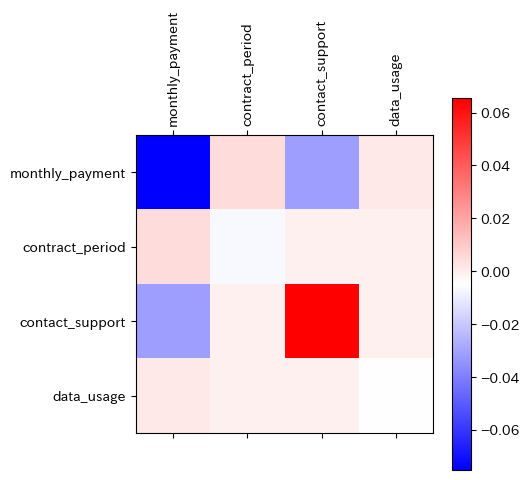
上の図は、相互作用シャープレイバリューの結果で、青が濃いほど離反に影響を与える要因(赤は、その逆で離反を減らす要因)。対角線は、各要因の単独でもたらす影響で、顧客の月額支払額(monthly_payment)が離反要因としては非常に大きい。これをもとに、さらなる分析を実施します。例えば、顧客の月額支払額(monthly_payment)を動かしたときにモデルの出力(離反)がどう変化するかを見るPDP(Partial Dependency Plot、部分従属プロット)を描くことで、離反をもたらす閾値などを割り出したりします。
このようなシャープレイバリューを用いることで、この通信会社は以下のようなビジネス上の意思決定を行いました。
プランの再設計
支払金額がある金額を超えると顧客の離反が急激に増えることが明らかなったため、価格体系やサービス内容を見直すことができます。
カスタマーサポートの戦略
電話によるカスタマーサポートへの問い合わせ回数が離反予測に大きな影響を与えないため、サポートチャネルの最適化や質の向上に資源を再配分した。
このように、シャープレイバリューをデータサイエンスに応用することで、モデルの予済みに対する特徴量の寄与を理解し、より効果的なビジネス戦略を立てるための洞察を得ることができます。
ツリー系モデルとシャープレイバリューの組み合わせ

ツリー系モデルの概要と動作原理
ツリー系モデル、特にランダムフォレストや勾配ブースティングツリーなどは、データサイエンスで広く使用される強力な機械学習アルゴリズムです。
これらのモデルは、データを分割する一連のルール(決定ノード)を通じて、予測を行います。
例えば、ランダムフォレストは、多くの決定木を統合して予測を行うことで、個々のツリーの過学習を避け、モデルの精度を向上させます。
一方、勾配ブースティングツリーは、前のツリーの誤差を修正する新しいツリーを順次追加することにより、モデルの性能を徐々に改善します。
| モデル名 | アルゴリズムの仕組み | メリット | デメリット |
|---|---|---|---|
| 決定木 (Decision Tree) | データを分類または回帰するための質問や条件の階層構造を構築。各ノードで最適な分割を選択。 |
|
|
| ランダムフォレスト (Random Forest) | 複数の決定木を組み合わせて予測を行う。各木はデータセットのランダムなサブセットから生成される。 |
|
|
| 勾配ブースティングツリー (Gradient Boosting Trees) | 逐次的に木を構築し、前の木の予測誤差を修正する。勾配降下法を使用して最適化。 |
|
|
| XGBoost | 勾配ブースティングを高速化・最適化したもの。並列計算と正則化を導入。 |
|
|
| LightGBM | XGBoostに似ているが、葉先重視の成長戦略を採用し、計算効率を改善。 |
|
|
| CatBoost | カテゴリー特徴量を自動で扱える勾配ブースティングライブラリ。 |
|
(他のモデルに比べて新しいため、情報が少ない) |
シャープレイバリューを用いたツリー系モデルの結果解釈
ツリー系モデルの結果を解釈する上で、シャープレイバリューは特に有効なツールです。
シャープレイバリューは、各特徴量がモデルの予測にどれだけ影響を与えているかを定量化し、モデルの内部動作を透明にします。
例えば、ランダムフォレストにおけるある顧客のクレジットスコア予測に対して、収入、クレジット履歴、利用可能なクレジットの量などの特徴量がどの程度影響しているかをシャープレイバリューによって理解することができます。
これにより、どの特徴量が予測に最も貢献しているのか、またその影響の大きさを知ることが可能になります。
特徴量の寄与度に基づく意思決定の改善
シャープレイバリューの利用により、ツリー系モデルの予測における各特徴量の相対的な重要性を定量的に評価できます。
これは、ビジネス上の意思決定において非常に価値があります。
たとえば、クレジットスコアリングモデルであれば、どの顧客属性がリスク評価に最も大きな影響を与えるのかを明らかにし、より効果的なリスク管理戦略を立てることができます。また、マーケティングにおいては、キャンペーンの成果に最も影響を与える顧客の特性を特定し、ターゲティングを最適化するための洞察を提供します。
ツリー系モデルとシャープレイバリューの組み合わせは、データ駆動型のアプローチによる意思決定プロセスを強化し、ビジネス戦略の精度と効果を高めるための強力な手段です。
このアプローチにより、データサイエンティストやビジネスリーダーは、複雑なモデルの予測をより深く理解し、根拠に基づいた決定を行うことが可能になります。
ビジネスでの活用事例
ツリー系モデルとシャープレイバリューを組み合わせることで、様々なビジネス領域での意思決定がデータ駆動型でより効果的になります。いくつかの事例を紹介します。
顧客セグメンテーションとターゲティング

ある通販企業です。製品の販売戦略を改善し、マーケティング効率を高めるために、顧客セグメンテーションとターゲティングを最適化したいと考えています。
この企業は、顧客の過去の購買履歴、ウェブサイト上での行動データ、顧客が提供したデモグラフィック情報(年齢、性別、地域など)を持っています。
これらのデータを用い、顧客セグメントを正確に識別、特定の製品カテゴリーに関心が高い顧客グループに対して、パーソナライズされたマーケティングキャンペーンを実施したいと考え、シャープレイバリューをビジネス実装しました。
以下は、ターゲティング戦略へ活用するまでの流れです。
データの準備
顧客データセットを整理し、購買履歴、ウェブサイトの行動パターン、デモグラフィック情報を含む特徴量を作成
Age Gender Region Site Visit Frequency Page Stay Time Past Purchase Amount Purchased 0 18 0 B 10 5 853 1 1 21 1 D 7 6 241 1 2 21 1 D 5 10 372 1 3 57 0 A 10 2 910 1 4 27 0 D 4 1 140 1 ... ... ... ... ... ... ... ... 9995 22 0 D 1 2 75 1 9996 43 1 E 4 4 969 0 9997 59 0 D 9 6 999 1 9998 25 0 A 2 9 848 0 9999 21 1 A 2 7 563 0 [10000 rows x 7 columns]
モデルの構築
ランダムフォレストと勾配ブースティングツリーを使用して、顧客が特定の製品カテゴリーを購入する確率を予測するモデルを構築
シャープレイバリューの計算
モデルの予測に対する各特徴量の寄与度をシャープレイバリューを用いて評価し、購買確率に最も影響を与える特徴量を特定
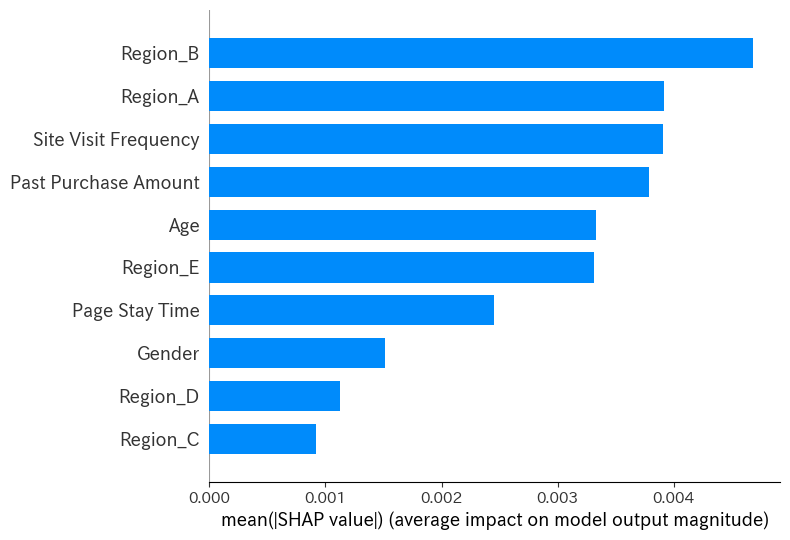
結果分析
ランダムフォレストモデルを使用して分析を行った結果、特定の製品カテゴリーに関心が高い顧客セグメントを識別、シャープレイバリューの計算により、特定の地域(Region Bなど)と「サイト訪問頻度」と「過去の購買額」が購買確率に大きな影響を与えていることが判明
ターゲティング戦略へ活用
特定の地域に絞り「サイト訪問頻度」が多く、「過去の購買額」が高い顧客グループに対して、特定の製品カテゴリーに関連するパーソナライズされたメールやウェブ広告を送信、キャンペーンの効果はクリック率、コンバージョン率、キャンペーン前後の購買額の変化を測定することで評価
このアプローチにより、企業は顧客のセグメントをより正確に識別し、マーケティングの効果を最大化することができました。シャープレイバリューの分析は、特定の特徴量が顧客の購買行動にどのように影響しているかを理解するのに役立ち、より効率的なターゲティング戦略の策定に寄与しました。
リスク評価とクレジットスコアリング

ある金融機関です。
ローンやクレジットカードの申請者のリスクを評価し、申請者のクレジットスコアを決定するために、ツリー系モデルの活用を検討していました。
この金融機関は、申請者の収入、雇用状況、過去のクレジット履歴、他の負債情報などのデータを持っています。
これらのデータを用い、申請者のクレジットスコアに最も影響を与える要因を特定し、金融機関がリスクをより正確に評価し、適切な貸出条件を設定できるよう、シャープレイバリューをビジネス実装しました。
以下は、リスク評価戦略へ活用するまでの流れです。
データの準備
申請者データセットを整理し、収入、雇用状況、過去のクレジット履歴、他の負債情報を含む特徴量を作成
Income Employment Status Past Credit History Other Debts Credit Score 0 93601.687991 Unemployed Average 26985.166962 528.680964 1 114398.670797 Unemployed Average 43371.681502 364.986847 2 100345.422009 Employed Good 31514.271577 742.576757 3 93110.397875 Employed Bad 45429.334314 611.195052 4 77956.849917 Employed Bad 32927.213344 560.255908 .. ... ... ... ... ... 995 37209.545931 Unemployed Average 19659.431428 680.351891 996 89365.275242 Unemployed Bad 28557.833492 733.257909 997 142301.502712 Employed Good 49816.865030 825.680854 998 53580.818873 Employed Average 37850.440410 462.281956 999 109642.643014 Unemployed Average 16529.572604 478.340391 [1000 rows x 5 columns]
モデルの構築
ランダムフォレストと勾配ブースティングツリーを使用して、申請者のクレジットスコアを予測するモデルを構築
シャープレイバリューの計算
モデルの予測に対する各特徴量の寄与度をシャープレイバリューを用いて評価し、クレジットスコアに最も影響を与える特徴量を特定
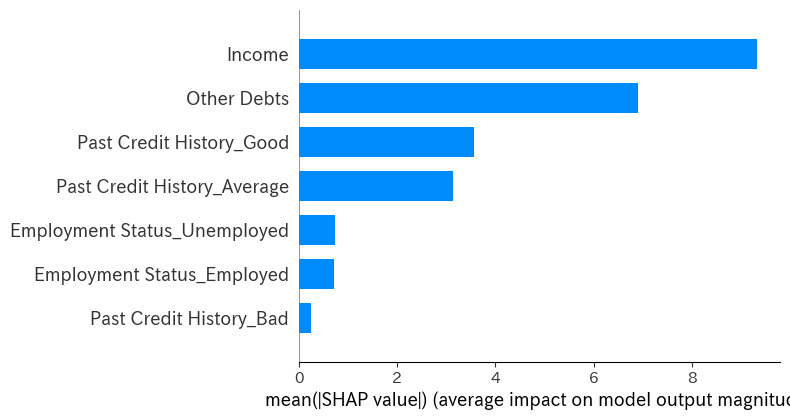
結果分析
ランダムフォレストモデルを使用して分析を行った結果、特に「過去のクレジット履歴」と「収入」がクレジットスコアに大きな影響を与えていることが判明
リスク評価戦略へ活用
シャープレイバリューの結果を基に、金融機関は過去のクレジット履歴や収入が安定している申請者に対して、より良い貸出条件を提供することを決定
このアプローチにより、金融機関は申請者のリスクをより正確に評価し、適切な貸出条件を設定することができました。シャープレイバリューの分析は、クレジットスコアに最も影響を与える要因を理解するのに役立ち、リスク管理と貸出プロセスの効率化に寄与しました。
在庫管理と需要予測

ある小売業者です。
季節性、価格変動、プロモーション活動など多様な因子に基づいて商品の需要を予測し、最適な在庫レベルを維持しようとしています。
過剰在庫を避けることでコストを削減し、一方で品切れを防ぐことで顧客満足度を保つためです。
そのため、最も影響力のある需要予測因子を特定し、より正確な予測モデルを構築することで、在庫コストを最小化し、売上を最大化することを目指します。
以下は、在庫管理と需要予測へ活用するまでの流れです。
データの準備
過去の販売データ、価格変動、季節性、プロモーション活動などのデータを集め、整理
Month Price Promotion Holiday Sales 0 1 548.818016 1 1 1010 1 2 715.192214 0 0 1067 2 3 602.767348 1 0 987 3 4 544.887734 0 0 1018 4 5 423.660563 0 1 1015 5 6 645.897654 1 0 971 6 7 437.592835 0 1 983 7 8 891.774083 1 0 1006 8 9 963.663124 1 1 971 9 10 383.447684 1 1 1014
モデルの構築
ランダムフォレストや勾配ブースティングツリーなどのツリー系モデルを使用して、商品の需要予測モデルを構築
シャープレイバリューの計算
構築したモデルに対してシャープレイバリューを計算し、各特徴量の寄与度を評価
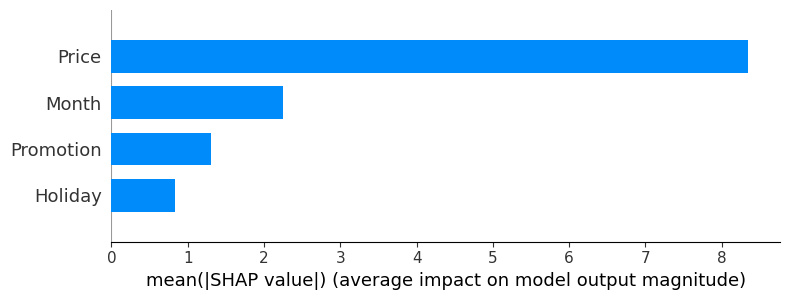
結果分析
ランダムフォレストモデルを構築し、シャープレイバリューを計算することで、プロモーション活動よりも価格変動や月が特に需要予測に大きな影響を与えていることが判明
需要予測の精度向上
シャープレイバリューの結果を基に、価格戦略やプロモーション計画を調整し、需要予測の精度が向上
在庫の最適化へ活用
精度の高い需要予測を基に、在庫レベルを最適化し、在庫コストの削減と売上の最大化が実現
シャープレイバリューを用いることで、需要予測における各特徴量の影響度を定量的に評価し、在庫管理と需要予測の精度を向上させることが可能です。これにより、小売業者はより効率的な在庫管理戦略を実施し、コスト削減と売上の最大化を実現できます。
マーケティングキャンペーンの効果分析

あるECサイトを運営している消費財メーカーです。
新製品の販売促進のために複数のマーケティングキャンペーンを実施しました。
このキャンペーンにはメールマーケティング、ソーシャルメディア広告、オンライン広告が含まれていました。
同社は、これらのキャンペーンの効果を分析し、今後のマーケティング戦略に生かしたいと考えています。
そこで、各マーケティングキャンペーンのROIを計算し、最も効果的なチャネルを特定するため、シャープレイバリューを使用して、各キャンペーン要素の販売促進への寄与度を定量化しました。
以下は、マーケティングキャンペーンに活かすまでの流れです。
データの準備
キャンペーンのタイプ(メール、ソーシャルメディア、オンライン広告)、キャンペーンによるウェブサイト訪問者数、購入に至った顧客数、キャンペーン費用などが含まれたデータセットを収集(期間は3ヶ月とし、合計で30万の顧客データを収集)
Age Gender Campaign Type Website Visits Purchased Campaign Cost 0 62 Male Social Media 5 1 161.030845 1 65 Male Social Media 9 0 377.298490 2 71 Male Social Media 5 0 281.914931 3 18 Female Social Media 6 0 198.377530 4 21 Male Online Ads 3 1 119.083135 ... ... ... ... ... ... ... 299995 24 Male Social Media 9 0 104.826047 299996 37 Female Online Ads 8 1 399.706624 299997 29 Female Email 10 0 161.428809 299998 53 Female Online Ads 6 0 455.193183 299999 64 Female Social Media 3 0 198.395011 [300000 rows x 6 columns]
モデルの構築
キャンペーンタイプ、顧客のデモグラフィック情報(年齢、性別)、過去の購買履歴などを特徴量としたランダムフォレストモデルを使用して、キャンペーンタイプごとに購入確率を予測するモデルを構築
シャープレイバリューの計算
モデルの予測に対する各キャンペーン要素の寄与度をシャープレイバリューで評価
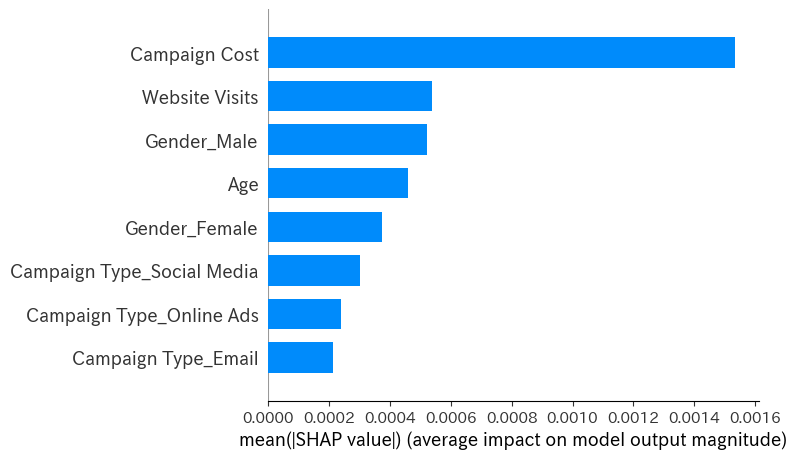
結果分析
特にあるソーシャルメディア広告のシャープレイバリューが高く、メールマーケティングとオンライン広告よりも顕著に販売促進に寄与していることが判明
パーソナライズされたキャンペーンの実施
シャープレイバリューの結果を基に、ソーシャルメディア広告を中心としたパーソナライズされたマーケティング施策(ターゲットとなる顧客セグメントに合わせてメッセージをカスタマイズ)を展開、コンバージョン率が向上し全体の売上が20%増加
シャープレイバリューを活用することで、各マーケティングキャンペーン要素の販売促進への寄与度を正確に把握し、ROIを最大化するマーケティング戦略を立てることができました。この分析は、将来のキャンペーン設計において重要な指針となります。
ビジネス実装における課題

シャープレイバリューの計算とツリー系モデルの利用は、データ駆動型意思決定を強化する強力な手段ですが、ビジネス実装にはいくつかの課題が伴います。
計算コスト
シャープレイバリューは、モデルの解釈性を向上させるために広く利用されていますが、その計算プロセスは非常にリソース集約的であり、大規模なデータセットや複雑なモデルを扱う場合には計算コストが高くなります。
計算コストの高さの原因
- 多数のパーミュテーションが必要: シャープレイバリューを計算する際には、データセット内の特徴量のすべての可能な組み合わせについてモデルの予測を評価する必要があります。これは、特徴量の数が増えると、指数関数的に計算量が増加することを意味します。
- 複雑なモデルの処理: ランダムフォレストや勾配ブースティングツリーのような複雑なモデルでは、一つ一つの予測を生成するためにも多くの計算が必要です。これらのモデルを用いてシャープレイバリューを計算する場合、モデルの複雑さが計算時間をさらに延長させます。
計算時間の削減策
- サンプリング: 全ての可能な特徴量の組み合わせについて計算を行う代わりに、ランダムサンプリングまたは重要度サンプリングを用いて、計算を必要とする組み合わせの数を減らします。
- 近似手法: 完全なシャープレイバリューの計算を行う代わりに、近似値を計算するためのアルゴリズムを使用します。これにより、計算時間を大幅に短縮できる場合があります。
- 並列計算と分散計算: 計算を複数のCPUコアやサーバー間で分割することで、全体の計算時間を短縮します。
- モデル固有の最適化: 特定のモデルタイプに対して最適化されたシャープレイバリュー計算手法を使用します。例えば、ツリーベースのモデルに対する効率的なシャープレイバリュー計算アルゴリズムが開発されています。
シャープレイバリューはモデルの予測における特徴量の寄与度を理解する強力なツールですが、その計算は非常に時間がかかる可能性があります。
計算コストを管理するためには、サンプリング、近似手法、並列計算、モデル固有の最適化などの戦略を駆使することが重要です。これにより、実用的な時間内に有用な洞察を得ることが可能になります。
解釈の難しさ
シャープレイバリューは、特徴量間の相互作用が複雑な場合、解釈の難しさが増すことがあります。
解釈の難しさの原因
- 高度な専門知識が必要: シャープレイバリューの概念はゲーム理論に基づいており、その計算結果を正確に理解するには、統計学や機械学習、ゲーム理論に関する高度な知識が必要となる場合があります。
- 特徴量間の相互作用: モデルの予測には、単一の特徴量だけでなく、複数の特徴量間の相互作用が影響を及ぼすことがあります。シャープレイバリューは各特徴量の個別の寄与を評価しますが、特徴量間の複雑な相互作用を解明することは困難な場合があります。
- ビジネスの文脈への適用: シャープレイバリューが提供する数値情報をビジネス上の意思決定や戦略に直接適用するには、データの背景やビジネスプロセスへの深い理解が必要です。特に、データに隠された因果関係や外部の影響を考慮する必要があります。
解釈の改善策
- ビジュアライゼーション: シャープレイバリューの結果をグラフやチャートで視覚化することで、特徴量の寄与度を直感的に理解しやすくなります。特徴量間の相互作用を示すビジュアライゼーションも有効です。
- ドメイン知識の活用: データ科学者とビジネスエキスパートが協力して、シャープレイバリューの結果をビジネスの文脈で解釈することが重要です。ドメイン知識を持つ専門家の意見を取り入れることで、より実践的な洞察を得ることができます。
- シンプルなモデルへの適用: 非常に複雑なモデルよりも、比較的シンプルなモデルにシャープレイバリューを適用することで、解釈性を向上させることが可能です。モデルの複雑さを必要最小限に抑えることで、特徴量の寄与をより明確に理解できます。
シャープレイバリューは、モデルの解釈性を向上させる有力な手段ですが、その解釈には注意が必要です。
特徴量間の相互作用の理解、ビジネスの文脈への適切な適用、専門知識の活用が、有効な解釈には欠かせません。
データの前処理
シャープレイバリューを計算する前のデータ前処理は、モデルの性能と解釈可能性に大きな影響を及ぼします。
適切な前処理手順を行うことで、データの品質を向上させ、より正確なシャープレイバリューの計算を可能にします。
以下に幾つかの、シャープレイバリューを計算する前のデータ前処理方法を紹介します。
欠損値の取り扱い
- 削除: データから欠損値を含む行や列を削除する方法です。これはデータ量を減少させる可能性があるため、欠損値が少ない場合に適しています。
- 代入: 欠損値を平均値、中央値、最頻値などで置き換える方法です。また、より複雑な代入方法として、予測モデルを使用して欠損値を推定する方法もあります。欠損値のパターンがランダムである場合に適しています。
カテゴリカル変数のエンコーディング
- ワンホットエンコーディング: カテゴリカル変数の各カテゴリーに対して一意の列を作成し、該当するカテゴリーには1、それ以外には0を割り当てます。これにより、モデルがカテゴリカルデータを数値として扱うことができますが、変数の数が多い場合は次元の呪いを引き起こす可能性があります。
- ラベルエンコーディング: カテゴリカル変数の各カテゴリーに一意の整数を割り当てます。順序特性を持つカテゴリカルデータに適していますが、数値間の大小関係がモデルに誤解を与える可能性があります。
スケーリング
- 正規化: データを0と1の範囲にスケーリングする方法です。外れ値に影響されにくく、複数の特徴量を比較可能にします。
- 標準化: データの平均を0、標準偏差を1にスケーリングする方法です。外れ値の影響を受けやすいが、多くの機械学習アルゴリズムで良好な結果を得やすいです。
特徴量選択
- 不要または冗長な特徴量を取り除くことで、モデルの複雑さを減少させ、計算効率を向上させます。また、解釈性を高めることも可能です。
データの前処理は、シャープレイバリューを含む機械学習モデルの性能に大きく影響します。
欠損値の適切な取り扱い、カテゴリカル変数の適切なエンコーディング、データのスケーリング、そして重要な特徴量の選択は、正確で解釈可能なシャープレイバリューの計算に不可欠です。
これらのステップを適切に実行することで、モデルの予測精度を高め、ビジネス上の意思決定に役立つ洞察を提供することができます。
将来展望

シャープレイバリューがビジネス意思決定に与える影響
シャープレイバリューは、データサイエンスと機械学習モデルの解釈性を高めることで、適切に取り入れた企業や団体の意思決定プロセスに革命をもたらしました。
これにより、企業はデータから得られる洞察をより深く理解し、それを戦略的な意思決定に活用することが可能になります。
例えば、顧客セグメンテーション、リスク管理、マーケティング戦略など、多岐にわたる分野でシャープレイバリューの応用が見られます。
将来的には、この手法がさらに普及し、企業が直面する複雑な問題を解決するための主要なツールとなることが期待されます。
今後のデータサイエンスとビジネス戦略への応用
データサイエンスの進化は止まることなく、シャープレイバリューのような解釈可能性を高める技術は、今後もビジネス戦略の形成において中心的な役割を果たすでしょう。
特に、AIと機械学習の技術が企業の各部門で広く採用されるにつれて、これらのモデルから得られる洞察をビジネスの文脈でどのように活用するかが、競争優位性を確立する鍵となります。
シャープレイバリューを含む解釈可能性の高いモデルが、新しい市場の機会を発見し、リスクを管理し、顧客体験を向上させるための戦略的な意思決定に貢献することが期待されます。
継続的な学習と技術の進化への適応
テクノロジーの進化は加速度的に進んでおり、ビジネスにおけるデータサイエンスの応用もまた、常に変化しています。
企業がこの変化に対応するためには、継続的な学習と技術の進化への適応が不可欠です。
シャープレイバリューをはじめとする先進的なデータ分析手法を活用するためには、最新の研究やケーススタディに常に目を向け、社内のスキルを更新し続ける必要があります。
また、新しいツールやプラットフォームの導入によって、データ分析のプロセスを効率化し、より洗練された分析を行うことが可能になります。
これらの取り組みを通じて、企業はデータ駆動型の意思決定を強化し、変化するビジネス環境においても競争力を維持することができます。
今回のまとめ
今回は、「データ駆動型意思決定を支援するシャープレイバリュー」というお話しをしました。
具体的には、シャープレイバリューの基礎から、ランダムフォレストや勾配ブースティングツリーといったツリー系モデルとの組み合わせ、ビジネスでの具体的な活用事例、そして計算コストや解釈の難しさといった課題に至るまで、取り上げました。
データドリブンな意思決定が今後のビジネス戦略と技術の進化にどのように貢献していくのか、そして私たちがどのようにしてこれらの進化に適応していくのかについて、言及しました。
データサイエンスの進歩は、ビジネス意思決定のプロセスを根本から変えています。
特に、シャープレイバリューとツリー系モデルを組み合わせることで、企業はデータからより深い洞察を引き出し、精度の高い意思決定を実現できるようになりました。
継続的な学習と技術の進化への適応は、これからの時代を生き抜く上での鍵となります。
データサイエンスとビジネスの融合はまだ始まったばかりであり、これからも革新的な手法と戦略が登場することでしょう。