

時系列の予測モデリングは、未来のデータを正確に予測するために不可欠な技術です。
しかし、このプロセスには注意が必要です。
なぜなら、データリークという問題が存在するからです。
データリークは、テストデータを不正に使用することで、モデルのパフォーマンスが過剰に評価される問題です。
特に時系列データにおいては、予測に利用できない未来のデータがトレーニングに使われることがあり、これが大きな問題となります。
今回は、予測モデリングにおけるデータリークのリスクとその回避方法について簡単に解説します。
Contents [hide]
- はじめに
- データリークとは何か?
- 時系列予測で頻発するデータリーク問題
- なぜ、時系列予測でデータリークが発生しやすいのか?
- 時系列予測と他の機械学習タスクの違い
- テーブルデータとの比較
- ローリング予測によるデータの移動
- テストデータのトレーニングデータへの混入
- ラグやウィンドウによる特徴生成時のデータ移動
- 平滑化、分解、正規化の際のデータリーク
- データ処理によるデータリーク
- 平滑化、分解、正規化の際のデータリーク
- 変換パラメータの学習とデータスプリットの関係
- データリーク防止のためのフレームワーク構築
- フレームワーク設計の注意点
- 外生データの有無による違い
- データリーク防止のためのフレームワーク例
- 今回のまとめ
はじめに

データリークとは何か?
データリーク問題とは、モデルの学習をしている段階で使用しているデータの中に、学習では利用できないデータを使ってしまう問題です。
例えば、モデルのトレーニングプロセス中にテストデータからの情報が不正に使用される現象を指します。
時系列の予測モデルであれば、本来得られずはずではない未知のデータ(学習データから見たら未来のデータ)が学習データでに漏れ出し(リーク)、学習データに混じってしまう現象です。
これは、モデルの性能を実際よりも高く評価してしまう原因となり、実際の運用環境でのパフォーマンスが低下するリスクを伴います。
以下は、典型的なデータリーク状態です。
- トレーニングデータとテストデータの混在:テストデータがトレーニングデータに含まれる、またはその逆の状態。
- 未来の情報の利用:予測に利用できない未来のデータがトレーニングプロセスで使用されること。
時系列予測で頻発するデータリーク問題
時系列予測において、データリーク問題はよく起こります。
具体例は以下のようなものです。
- ラグ特徴量の誤用:未来の時点のデータを過去のデータとして誤って使用すること。
- 平滑化や正規化の問題:全期間のデータを使用して平滑化や正規化を行うと、未来の情報が漏れる(リーク)ことがある。
- ローリング予測の誤設定:テスト期間のデータがトレーニング期間に含まれる設定ミス。
なぜ、時系列予測でデータリークが発生しやすいのか?

時系列予測と他の機械学習タスクの違い
時系列予測は、他の機械学習タスクとは異なる違いがあります。
それは、データの時間的な順序と依存関係にあります。
これが、データリークを引き起こしやすい要因の一つです。
テーブルデータとの比較
テーブルデータでは、データの独立性が保たれていることが多く、トレーニングデータとテストデータの明確な分割が可能です。
しかし、時系列データでは、データポイントが時間に沿って連続しており、過去のデータが未来のデータに影響を与えるため、データの分割が難しくなります。
そのため、テーブルデータのように、レコード(行)をランダムにトレーニングデータとテストデータに割り当て分割することができません。
ランダムにデータ分割すると、時間による連続性が失われ、過去と未来の関係がでたらめになります。
ローリング予測によるデータの移動
時系列予測には、ローリング予測(時点をずらしながら予測を繰り返す方法)がよく用いられます。
この手法では、トレーニングデータセットを繰り返し更新するため、テストデータがトレーニングデータに含まれるリスクがあります。
また、特徴量生成の際に、未来のデータを誤って使用することもあります。
例えば、1日前の過去データを使い売上を予測するときはどうでしょうか?
予測する売上が1週間後のある日の売上のとき、そのある日の1日前の過去データは存在しません。なぜならば、その1日前も未来だからです。
例えば、売上が天候を左右する場合、その売上を予測するときはどうでしょうか?
予測する売上が来月であった場合、来月の天候に関するデータは存在しません。なぜならば、その来月は未来だからです。
テストデータのトレーニングデータへの混入

時系列予測において、最も一般的なデータリークのパターンは、テストデータがトレーニングデータに混入することです。
これにより、モデルがテストデータに対して過度に最適化され、テストデータで検証したときは好成績だったのに、実際のビジネス現場で利用すると予測精度が低下します。
例えば、あるオンライン小売業者が次月の売上を予測するモデルを構築するとします。
この場合、テスト期間である来月の売上データがトレーニングデータに含まれてしまうと、モデルは実際には利用できない未来の売上情報を基に予測を行います。
これにより、モデルのパフォーマンスが過剰に評価され、実際の運用では低い精度を示すことになります。
このような初歩的なミスは本当にあるのか? と思われるかもしれませんが、そのようなことは実際にあります。
高精度な予測モデルができた! と喜び勇んだモデルをよくよくデータの処理レベルから見てみたら(どのようにデータを持ってきて処理しているのかを細かく見る)、思いっきりデータリークしているケースです。
例えば、ラグ特徴量を作る際に、過去方向のラグ(1期前のデータ)ではなく、未来方向のラグ(1期後のデータ)で作ってしまっているケースです。
単なる前処理や時系列特徴量の生成過程の、初歩的なミスなのですが、実際に起こっているケースもあります。
ラグやウィンドウによる特徴生成時のデータ移動
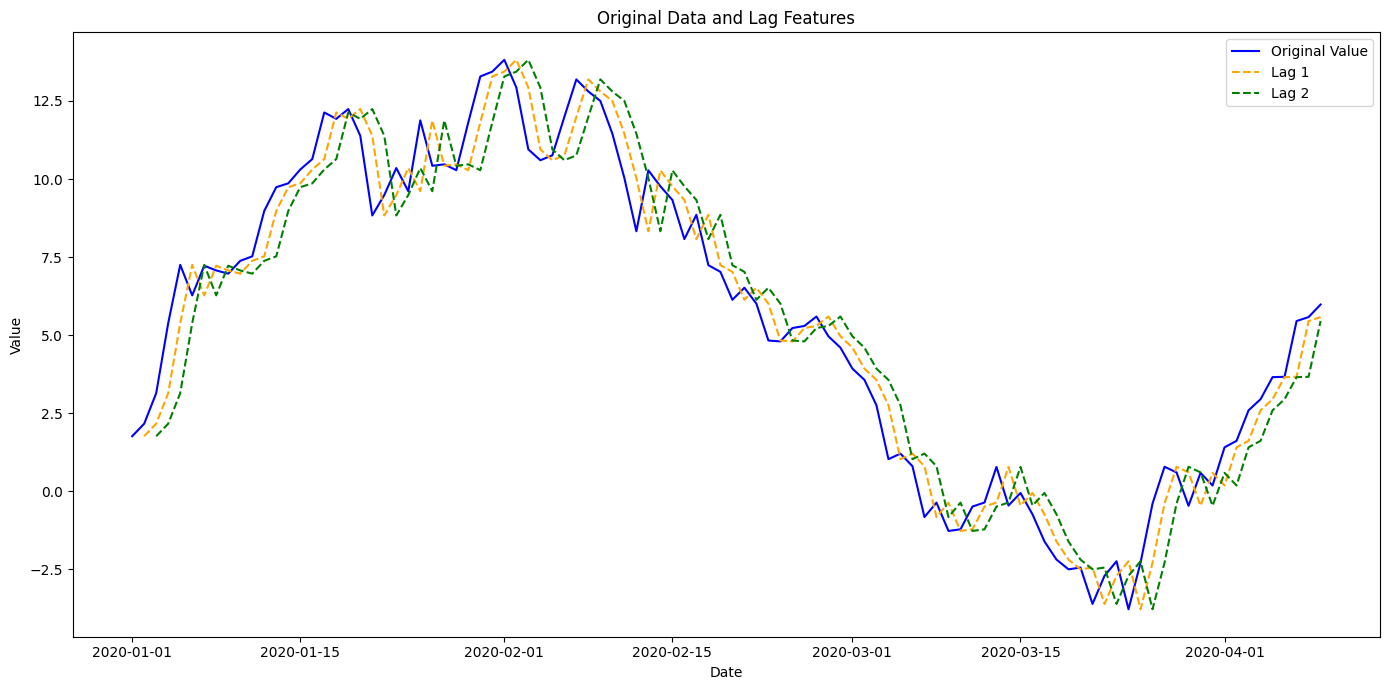
ラグ特徴量やローリング特徴量(ウィンドウ特徴量)を生成する際、未来のデータを誤って使用することがあります。
先ほど説明した、未来方向のラグではありません。過去方向のラグでも起こります。
例えば、電力需要予測モデルを構築する際、過去の電力消費量のラグ特徴量(例:1時間前、2時間前の消費量)を使用します。
しかし、来週の予測を行うために、未来の電力消費量データを誤ってラグ特徴量として使用すると、モデルは実際の運用環境で利用できない情報を基に学習してしまいます。
この結果、モデルの予測精度が不当に高く評価されます。
過去データを使った予測モデルであっても、予測するタイミングによっては、その過去データが未来であるケースがあるということです。
ラグ特徴量の場合には発見しやすいですが、意外と見逃されるのがローリング特徴量(ウィンドウ特徴量)です。
ローリング特徴量(ウィンドウ特徴量)の典型例が移動平均です。
移動平均の計算に、予測対象時期の値を入れてしまっているケースです。
ある日の売上を予測するのに、トレンドを説明変数に入れたいがために、移動平均の値を説明変数に組み込むことがあります。
ただ、その移動平均の計算に、予測対象日の売上の値を入れてしまうと、データリークが起こります。
予測対象の売上データを予測するのに、その予測結果を持ちいないと計算できない移動平均の値を、説明変数に含めているからです。そうならないためには、例えば1期前の移動平均の値を説明変数に入れるべきです。
さらに、予測対象の売上データが移動平均の計算に含まれていなくても、ラグ特徴量と同様のデータリークの問題が起こることがあります。
例えば、1期前の移動平均の値を説明変数に入れたとき、1週間後の予測をする場合には、1期前の移動平均の値そのものが未来のデータを使わなければ計算できません。
このように、データ処理の各段階でデータリークが発生するリスクがあります。
平滑化、分解、正規化の際のデータリーク

データ処理によるデータリーク
データ処理の各段階でデータリークは、他にも色々あります。
例えば、平滑化、分解、正規化といった処理を行う際に、データの未来の情報が漏れないよう(混じらないよう)注意する必要があります。
平滑化、分解、正規化の際のデータリーク
データの平滑化、分解(トレンド季節や季節成分への分解など)、正規化は時系列データの解析において一般的な手法です。
ここには、トレンド調整(元の時系列データからトレンド成分の除去)や季節調整(元の時系列データから季節成分の除去)も含まれます。
しかし、これらの処理を行う際に全期間のデータを使用すると、未来の情報が含まれてしまうことがあります。
例えば、月次売上データを平滑化するために、全期間のデータを使用して移動平均を計算するとします。
この場合、来月の売上データが平滑化プロセスに含まれるため、過去の売上データにも未来の情報が反映されます。
結果として、モデルは実際の運用環境では利用できない未来の情報を基に予測を行い、過剰に高い精度を示すことになります。
要は、全期間のデータの移動平均を計算した後で、その移動平均したデータを使い予測モデルを構築すると、よろしくないということです。
例えば、在庫管理システムのデータを分析する際に、全期間のデータを使用して季節調整を行うとします。
この場合、未来の在庫データが調整プロセスに含まれ、過去のデータにもその影響が反映されます。
これにより、モデルは実際の運用環境では利用できない情報を基に予測を行うことになり、実際のパフォーマンスが低下します。
このように、全体の時系列データを使用して処理を行うと、未来の情報が含まれてしまい、過去のデータにも影響を与えます。
変換パラメータの学習とデータスプリットの関係
再度言いますが、データを変換する際に使用するパラメータ(例:正規化処理をする際の平均値や標準偏差など)を全期間のデータから学習すると、未来の情報がトレーニングデータに含まれるリスクがあります。
よく、元のデータセットをトレーニングデータとテストデータに分割し、予測モデルの検討を実施したりします。
この検討時に、テストデータがトレーニングデータへ漏れ出し(混じり)、意味のない予測モデルの検討になってしまうことがあります。
例えば、エネルギー消費量のデータを正規化するために、全期間のデータを使用して平均値と標準偏差を計算するとします。
この場合、未来のデータが計算に含まれ、過去のデータの正規化にもその影響が反映されます。
結果として、モデルは未来の情報を含むデータでトレーニングされ、過剰に良いパフォーマンスを示すことになります。
このようなデータリークした状態で検討した予測モデルが、どんなに高精度でも、実際に使えるモデルかどうかの検討にはなっていません。
データリーク防止のためのフレームワーク構築

データリークを防止するためには、予測モデルのフレームワーク(モデル構築の一連の方法論や手順)を慎重に設計することが重要です。
具体的には、予測モデルの検討時のために実施する、データの分割、前処理、特徴量生成、およびモデル評価の各ステップにおいて、データリークを防ぐための対策を組み込むということです。
フレームワーク設計の注意点
データリークを防止するためのフレームワークを設計する際の主な注意点は以下の通りです。
- データの分割:トレーニングデータとテストデータを明確に分割し、交差汚染(テストデータのリーク)を防ぐ。
- 特徴量生成の順序:特徴量を生成する際に、未来の情報が含まれないように注意する。
- 前処理のタイミング:データの前処理(平滑化、正規化、分解など)は、データを分割した後に行う。
外生データの有無による違い
外生データ(例:経済指標、天候データなど)が予測に使用される場合、その取り扱いにも注意が必要です。
例えば、気象データを利用して農作物の収穫量を予測する場合、気象データが予測期間中に利用可能かどうかを確認すべきです。
未来の気象データを誤って使用しないようにする必要があるからです。
気温から収穫量を上手く予測できたとしても、気温そのものが分からなければ、その予測モデルは「予測という意味では無価値」です。
データリーク防止のためのフレームワーク例
以上の考慮事項をまとめると、以下のようになります。あくまでも一例です。
1. データの分割⇒適切なデータスプリット
- トレーニングデータとテストデータを明確に分割し、交差汚染を防ぐ。
- 時系列データの場合、過去のデータをトレーニングデータ、未来のデータをテストデータとする。
2. 前処理のタイミング⇒分割後の前処理
- データの正規化、平滑化、分解などの前処理は、データを分割した後に行う。
- これにより、未来の情報がトレーニングデータに混入するのを防ぐ。
3. 特徴量生成の順序⇒時間順序の保護
- ラグ特徴量やローリング特徴量(ウィンドウ特徴量)を生成する際に、未来のデータを含めないように注意する。
- 過去のデータのみを基に特徴量を生成し、未来のデータを参照しない。
- 気が付かないケースも多いので、予測精度が高いときほど疑う。
4. モデル評価⇒ローリング予測法の利用
- 時系列データに対しては、ローリング予測法を用いてモデルを評価する。
- ローリング予測法とは、元の説明変数を使うのではなく、未来のデータが含まれないように説明変数を適時更新し予測すること。
- 例えば、1期前のラグ特徴量を説明変数として利用するのであれば、前の期の予測値を使い、それを1期前のラグ特徴量とする、など。
- これにより、各評価ステップで新しいデータがテストセットとして使用される。
- スト期間が逐次更新されるため、より現実的な評価が可能になる。
5. 外生データの取り扱い⇒外生データの予測可能性の見極め
- 外生データ(例:経済指標、気象データなど)を使用する場合、そのデータが予測期間中に利用可能かどうかを確認する。
- 未来の外生データを誤ってトレーニングに使用しないように注意する。
- どうしても必要な場合は、外生データの予測値を用いる。
6. 複数の時系列データの処理⇒相互依存関係を考慮
- 複数の時系列データを扱う場合、各時系列データ間の依存関係を考慮し、それぞれ独立して処理する。
- 各時系列データがトレーニングデータとテストデータに分割された後に処理を行うことで、データリークを防止する。
今回のまとめ
今回は、「時系列予測モデリングのデータリーク問題と対処法」というお話しをしました。
データリークは、予測モデルの性能を過剰に評価する原因となり、実際の運用環境でのパフォーマンスを低下させるリスクがあります。
データの分割、前処理、特徴量生成、およびモデル評価の各ステップで適切な方法を実施することで、データリークを防ぎ、信頼性の高い予測モデルを構築することができます。