

機械学習は現代のビジネスや技術革新の中心にあり、その重要性は日々増しています。
しかし、機械学習の世界は広大で、初心者には複雑に感じられることがあります。
今回は、すべてのデータをビジネスに活用しようとする人が知っておくべき機械学習の3つの基本タイプに焦点を当て、その概要と応用例を紹介します。
これからビジネスや技術開発に機械学習を活用していこうという方々に、何となく知っているよ! という感じを目指しています。
機械学習の基礎を理解し、ビジネスや技術開発にどのように活用できるかを、とり急ぎ押さえておきましょう。
Contents [hide]
- 機械学習の重要性と基礎知識の必要性
- 機械学習の重要性
- 機械学習の基礎知識の必要性
- 機械学習の3つの基本タイプ
- 教師あり学習(Supervised Learning)の超概要
- 教師なし学習(Unsupervised Learning)の超概要
- 強化学習(Reinforcement Learning)の超概要
- 3つのタイプのアプローチによる違い
- 教師あり学習とは
- 分類(Classification)
- 回帰(Regression)
- 教師なし学習とは
- クラスタリング(Clustering)
- 次元削減(Dimensionality Reduction)
- 強化学習とは
- 強化学習の基本概念
- AIと機械学習の関係性
- ビジネス活用の簡易事例
- 教師あり学習のよくあるビジネス活用例
- 教師なし学習のよくあるビジネス活用例
- ビジネス活用時の実践的なポイント
- 学習ロードマップ
- 今回のまとめ
機械学習の重要性と基礎知識の必要性
近年、ビッグデータの時代を迎え、機械学習の重要性は飛躍的に高まっています。
機械学習は、データから学習し、パターンを見つけ出し、予測や意思決定を行う能力を持つコンピュータシステムを作り出す技術です。
この技術は、金融、医療、小売、製造など、あらゆる産業に革命をもたらしています。
機械学習の重要性
機械学習の重要性は以下の点にあります。
データ駆動型の意思決定
機械学習により、膨大なデータから有意義な洞察を得ることができ、より正確で効率的な意思決定が可能になります。
自動化と効率化
反復的なタスクや複雑な分析を自動化することで、業務効率を大幅に向上させることができます。
予測と最適化
将来のトレンドを予測し、プロセスを最適化することで、ビジネスの競争力を高めることができます。
パーソナライゼーション
顧客の行動や好みを理解し、個別化されたサービスを提供することが可能になります。
機械学習の基礎知識の必要性
このような重要性がある一方で、機械学習の基礎知識を身につけることは不可欠です。
適切なアプローチの選択
問題に応じて最適な機械学習手法を選択するためには、各手法の特徴と適用範囲を理解する必要があります。
結果の解釈
機械学習モデルの出力を正しく解釈し、ビジネスに活用するためには、その仕組みを理解していることが重要です。
エラーと限界の理解
機械学習にも限界があり、潜在的なバイアスやエラーを認識し、適切に対処するためには基礎知識が必要です。
イノベーションの促進
基礎を理解することで、新しいアイデアや応用方法を生み出す可能性が広がります。
機械学習の3つの基本タイプ
機械学習は大きく分けて3つの基本タイプに分類されます。
それぞれのタイプについて、その特徴と主な用途を簡潔に説明します。
教師あり学習(Supervised Learning)の超概要
特徴
- 入力データと正解(ラベル)のペアを用いて学習します。
- モデルは入力から正解を予測するよう訓練されます。
主な用途
- 分類問題(例:スパムメール検出、顧客セグメンテーション)
- 回帰問題(例:住宅価格予測、売上予測)
教師なし学習(Unsupervised Learning)の超概要
特徴
- ラベル付けされていないデータを使用します。
- データの隠れたパターンや構造を見つけ出すことを目的とします。
主な用途
- クラスタリング(例:顧客グループ化、異常検知)
- 次元削減(例:特徴量の圧縮、データの可視化)
強化学習(Reinforcement Learning)の超概要
特徴
- エージェントが環境と相互作用しながら、報酬を最大化する行動を学習します。
- 試行錯誤を通じて最適な戦略を見つけ出します。
主な用途
- ゲームAI(例:チェス、囲碁)
- ロボット制御
- 自動運転車の開発
3つのタイプのアプローチによる違い
これら3つのタイプは、それぞれ異なるアプローチで問題を解決します。
- 教師あり学習は、明確な目標(正解)が与えられている場合に適しています。
- 教師なし学習は、データの中に潜む構造や関係性を発見したい場合に有効です。
- 強化学習は、連続的な意思決定が必要な動的な環境での問題解決に適しています。
実際のビジネス活用では、これらのアプローチを組み合わせて使用することも多く、問題の性質に応じて適切な手法を選択することが重要です。
教師あり学習とは
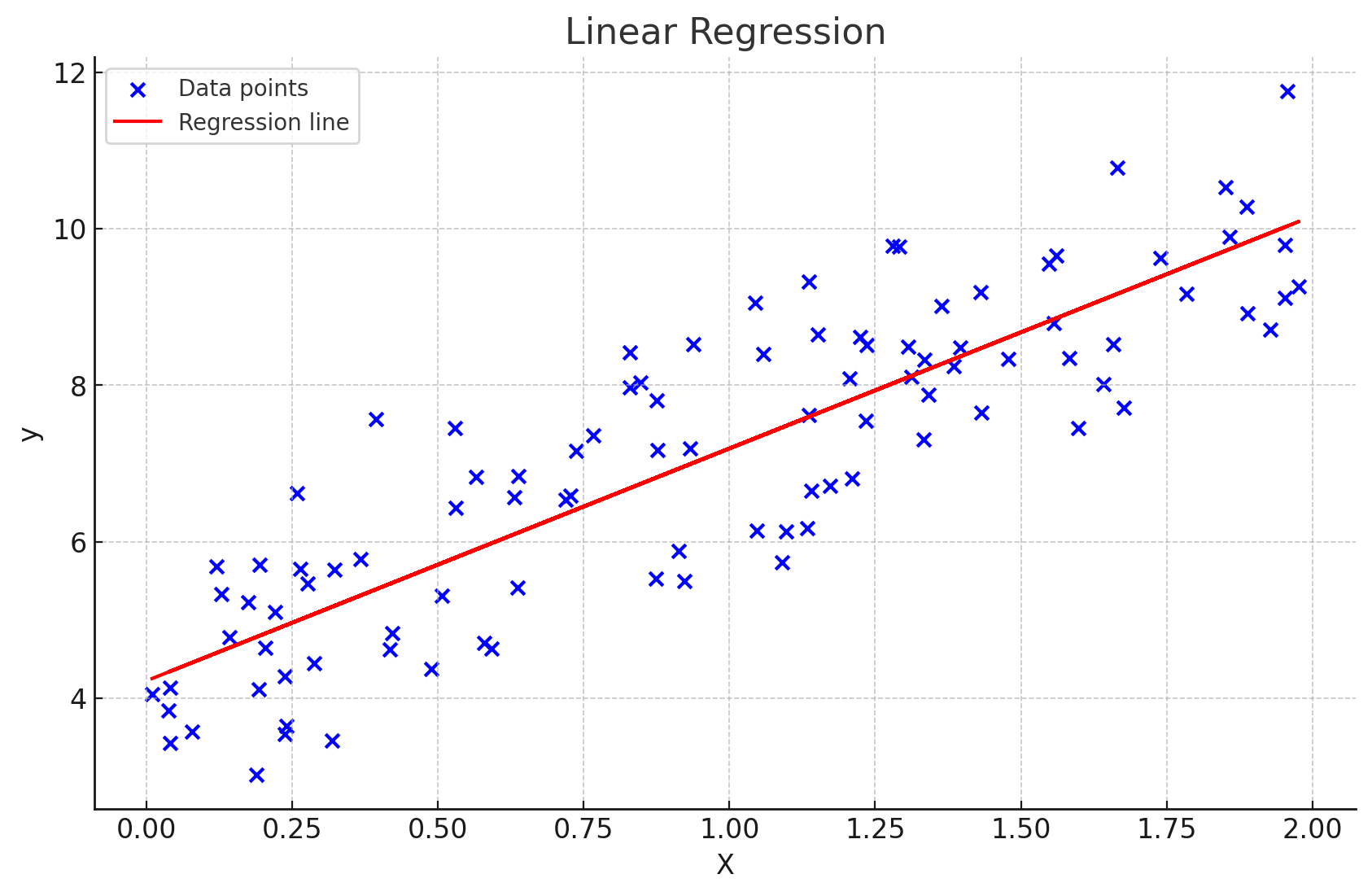
教師あり学習は、機械学習の中で最も広く使用されているアプローチの一つです。
教師あり学習の主要な2つのカテゴリー(分類と回帰)について見ていきます。
分類(Classification)
分類は、入力データを予め定義されたカテゴリーに分類する問題です。
特徴
- 離散的なカテゴリーを予測します。
- 二値分類(2クラス)と多クラス分類があります。
リードスコアリングを例に説明していきます。
ちなみに、リードスコアリングは、潜在顧客(リード)が実際に購入する可能性を予測する手法です。
プロセス
- 特徴量の収集:顧客の行動データ(ウェブサイトの閲覧履歴、メール開封率など)を収集。
- モデルの学習:過去の顧客データを使用して、購入した顧客と購入しなかった顧客の特徴を学習。
- スコアリング:新しいリードに対して、購入の可能性(0から1の間のスコア)を予測。
利点
- セールスチームは高スコアのリードに集中できる。
- マーケティングリソースを効率的に配分できる。
回帰(Regression)
回帰は、入力データから連続的な数値を予測する問題です。
特徴
- 連続的な値を予測します。
- 線形回帰や非線形回帰など、様々な手法があります。
売上予測を例に説明していきます。
ちなみに、売上予測は、ビジネスの将来の売上を推定する重要なタスクです。
プロセス
- データ収集:過去の売上データ、季節性、経済指標などの関連データを収集。
- 特徴量エンジニアリング:重要な特徴を抽出し、モデルに適した形に加工。
- モデル構築:線形回帰や時系列分析などの手法を用いてモデルを構築。
- 予測と評価:将来の売上を予測し、実績値と比較して精度を評価。
利点
- 在庫管理の最適化
- 効果的な予算計画
- 事業戦略の立案支援
教師あり学習には、ロジスティック回帰、決定木、ランダムフォレスト、サポートベクターマシン、ニューラルネットワークなど、様々なアルゴリズムが使用されます。
問題の性質や利用可能なデータに応じて、適切なアルゴリズムを選択することが重要です。
教師なし学習とは
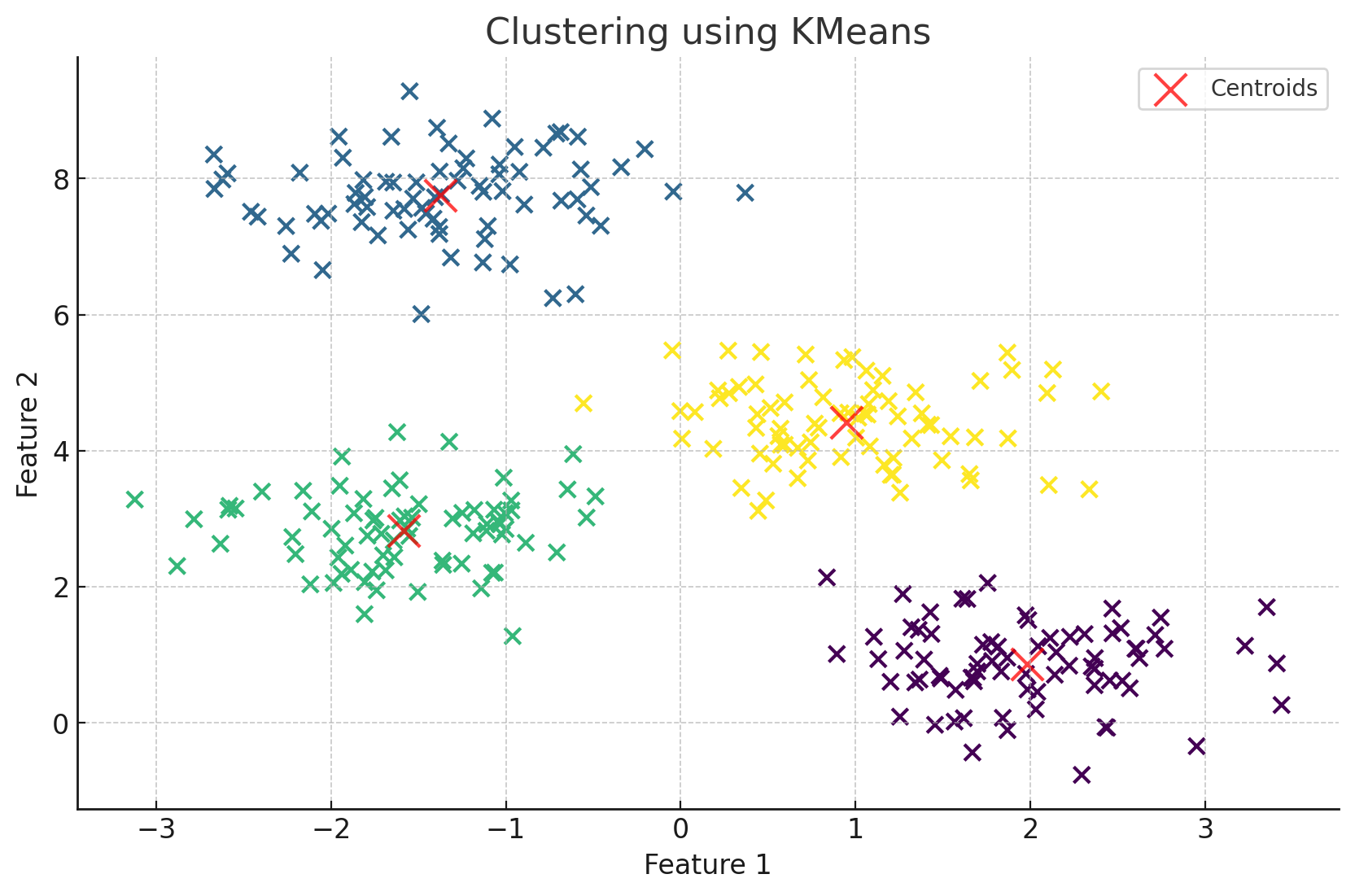
教師なし学習は、ラベル付けされていないデータから隠れたパターンや構造を見つけ出す手法です。
教師なし学習の主要な2つの手法(クラスタリングと次元削減)について見ていきます。
クラスタリング(Clustering)
クラスタリングは、データポイントを似た特徴を持つグループ(クラスタ)に分類する手法です。
特徴
- データの自然な構造を発見します。
- 事前にグループ数を指定する場合と、自動的に決定する場合があります。
K-meansを例に説明していきます。
ちなみに、K-meansは最も一般的なクラスタリングアルゴリズムの一つです。
プロセス
- クラスタ数(K)を指定します。
- K個の中心点をランダムに初期化します。
- 各データポイントを最も近い中心点に割り当てます。
- 各クラスタの新しい中心点を計算します。
- 中心点が収束するまで3と4を繰り返します。
応用例:顧客セグメンテーション
- 顧客の購買行動、人口統計データなどを基に顧客をグループ化します。
- 各セグメントの特徴を分析し、ターゲットマーケティングや商品開発に活用します。
利点
- 顧客理解の深化
- マーケティング戦略の最適化
- 製品ラインナップの改善
次元削減(Dimensionality Reduction)
次元削減は、データの本質的な構造を保ちながら、特徴量の数を減らす手法です。
特徴
- データの可視化を容易にします。
- モデルの学習速度と性能を向上させます。
主成分分析(PCA)を例に説明していきます。
ちなみに、PCAは最も広く使用される次元削減手法の一つです。
プロセス
- データの標準化を行います。
- 共分散行列を計算します。
- 共分散行列の固有値と固有ベクトルを計算します。
- 固有値の大きさに基づいて主成分を選択します。
- 元のデータを新しい低次元空間に射影します。
応用例:顧客データの可視化と分析
- 多次元の顧客データ(購買履歴、ウェブサイト行動、人口統計など)を2次元または3次元に圧縮します。
- 圧縮されたデータを視覚化し、顧客の傾向や異常値を発見します。
利点
- データの複雑性の削減
- 計算効率の向上
- パターンの視覚的理解の促進
教師なし学習は、データの探索的分析や前処理に非常に有効です。また、教師あり学習と組み合わせて使用することで、モデルの性能を向上させることができます。
強化学習とは
強化学習は、環境との相互作用を通じて最適な行動方針を学習する機械学習の一分野です。
強化学習の基本概念とAIとの関係性について説明します。
強化学習の基本概念
強化学習の基本要素
- エージェント:学習と意思決定を行う主体
- 環境:エージェントが相互作用する外部世界
- 状態:環境の現在の状況
- 行動:エージェントが取ることのできる選択肢
- 報酬:エージェントの行動に対する環境からのフィードバック
プロセス
- エージェントが現在の状態を観察
- 可能な行動から一つを選択
- 環境が新しい状態に遷移し、報酬を返す
- エージェントが報酬を基に行動方針を更新
- 1-4を繰り返し、最適な行動方針を学習
強化学習の特徴
- 試行錯誤を通じて学習
- 長期的な報酬の最大化を目指す
- 環境の不確実性に対応可能
AIと機械学習の関係性
強化学習は、人工知能(AI)の実現に向けた重要なアプローチの一つです。
自律的な意思決定
強化学習により、AIシステムが環境に適応し、自律的に意思決定を行うことが可能になります。
汎用AI
強化学習は、事前に全ての状況をプログラムすることなく、新しい環境や問題に対応できる汎用的なAIの開発につながる可能性があります。
複雑なタスクの習得
チェスや囲碁などの複雑なゲームで人間を上回る性能を示すAIシステムの多くは、強化学習を基盤としています。
応用例
- ゲームAI:チェス、囲碁、ビデオゲームなど
- ロボット制御:工場の自動化、災害救助ロボットなど
- 自動運転:交通状況に応じた最適な運転戦略の学習
- 資源管理:エネルギー効率の最適化、在庫管理など
課題と展望:
– 学習の効率性:大量の試行が必要なため、学習に時間がかかる
– 安全性の確保:実世界での試行錯誤には危険が伴う場合がある
– 倫理的考慮:自律的なAIシステムの意思決定に関する倫理的問題
強化学習は、複雑な問題に対する柔軟な解決策を提供する可能性を秘めていますが、実用化にはまだ多くの課題があります。
今後の研究開発により、より効率的で安全な強化学習アルゴリズムが開発されることが期待されています。
ビジネス活用の簡易事例
ビジネスにおいて実際に活用されている機械学習技術の例を紹介します。
教師あり学習と教師なし学習のそれぞれについて、見ていきましょう。
教師あり学習のよくあるビジネス活用例
顧客離反予測
- 手法:分類(ロジスティック回帰、ランダムフォレストなど)
- データ:過去の顧客行動、取引履歴、顧客属性
- 目的:離反しそうな顧客を特定し、早期対策を講じる
- 利点:顧客維持率の向上、マーケティング効率の改善
与信スコアリング
- 手法:分類(決定木、サポートベクターマシンなど)
- データ:申込者の財務情報、信用履歴、個人属性
- 目的:融資申込者のデフォルトリスクを評価
- 利点:リスク管理の向上、審査プロセスの効率化
需要予測
- 手法:回帰(時系列分析、ニューラルネットワークなど)
- データ:過去の販売データ、季節性、経済指標、イベント情報
- 目的:製品やサービスの将来需要を予測
- 利点:在庫最適化、生産計画の改善、収益性の向上
教師なし学習のよくあるビジネス活用例
異常検知
- 手法:クラスタリング(K-means、DBSCAN)、次元削減(PCA)
- データ:センサーデータ、ログデータ、取引データ
- 目的:通常とは異なるパターンや外れ値を検出
- 利点:不正検知、品質管理、システム障害の早期発見
レコメンデーションシステム
- 手法:協調フィルタリング、次元削減(SVD)
- データ:ユーザーの行動履歴、アイテムの特徴
- 目的:ユーザーの好みに合った商品やコンテンツを推奨
- 利点:顧客満足度の向上、交差販売の促進
市場セグメンテーション
- 手法:クラスタリング(K-means、階層的クラスタリング)
- データ:顧客属性、購買行動、ウェブサイト行動
- 目的:類似した特徴を持つ顧客グループを特定
- 利点:ターゲットマーケティングの効率化、製品開発戦略の改善
ビジネス活用時の実践的なポイント
ビジネスで機械学習を活用するときの、実践的なポイントです。
- データの品質確保:信頼性の高いデータ収集と前処理が重要
- ドメイン知識の活用:業界特有の知識をモデルに組み込む
- 解釈可能性の重視:結果を説明できるモデルを選択する
- 継続的なモニタリング:モデルの性能を定期的に評価し、必要に応じて更新する
- 倫理的配慮:プライバシーや公平性に注意を払う
これらの技術を適切に活用することで、データ駆動型の意思決定が可能となり、ビジネスの効率性と競争力を大幅に向上させることができます。
学習ロードマップ
これから機械学習を学んでビジネス実務で活用したい! と考えている初心者が取り組むべき順序と注意点です。
機械学習は広範な分野であり、効果的に学習を進めるためには、適切な順序と方法が重要です。
Step 1. 基礎知識の習得
- プログラミング言語(Python推奨)
- 統計学の基礎
- 線形代数の基本概念
※注意点:実践的なプログラミングスキルを身につけることが重要です。オンラインコースや書籍を活用し、基礎を固めましょう。
Step 2. データ分析・前処理スキルの向上
- データクレンジング
- 探索的データ分析(EDA)
- 特徴量エンジニアリング
※注意点:実際のデータセットを使って練習することで、データの扱い方に慣れることが大切です。
Step 3. 教師あり学習の基本アルゴリズム
- 線形回帰
- ロジスティック回帰
- 決定木
- ランダムフォレスト
- など
※注意点:各アルゴリズムの原理を理解し、適切な評価指標を用いてモデルの性能を評価する方法を学びましょう。
Step 4. 教師なし学習の基本手法
- K-meansクラスタリング
- 主成分分析(PCA)
- など
※注意点:結果の解釈に重点を置き、ビジネス上の意味を考察する習慣をつけましょう。
Step 5. モデル評価と選択
- クロスバリデーション
- ハイパーパラメータチューニング
- モデル比較と選択
※注意点:過学習を避け、汎化性能の高いモデルを作成することの重要性を理解しましょう。
Step 6. 深層学習の基礎
- ニューラルネットワークの基本構造
- CNNとRNNの概要理解
- フレームワーク(TensorFlowやPyTorch)の基本の習得
※注意点:深層学習には大量のデータと計算リソースが必要であることを認識し、適用可能な問題領域を理解しましょう。
Step 7. 実践的なプロジェクト
- 実プロジェクトへの参画
- 個人プロジェクトの実施
- オープンソースプロジェクトへの参加
- Kaggleなどのコンペティションへの参加
※注意点:理論と実践のバランスを取り、実際の問題解決に機械学習を適用する経験を積むことが重要です。
Step 8. 最新トレンドのフォロー
- オンラインコミュニティでの情報交換
- 学術論文の読解
- 業界カンファレンスへの参加
※注意点:技術の進歩が速いため、継続的な学習が必要です。ただし、基礎をしっかり固めてから最新技術に手を伸ばすことが大切です。
全般的な注意点
- 実践を重視し、小さなプロジェクトから始めて徐々に複雑なものに挑戦しましょう。
- エラーや失敗を恐れず、デバッグや問題解決のスキルを磨きましょう。
- 倫理的な考慮事項を常に意識し、責任ある機械学習の実践者を目指しましょう。
このロードマップは一般的な指針であり、個人の背景や目標に応じて適宜調整することが重要です。
自分のペースで着実に進めていくことで、機械学習の幅広い知識と実践的なスキルを身につけることができるでしょう。
今回のまとめ
今回は、機械学習の3つの基本タイプとその実践的応用について解説してきました。
ここで、主要なポイントを振り返り、今後の展望について考えてみましょう。
機械学習の3つの基本タイプ
- 教師あり学習:ラベル付きデータを使用し、予測や分類を行う
- 教師なし学習:ラベルなしデータからパターンや構造を見出す
- 強化学習:環境との相互作用を通じて最適な行動を学習する
各タイプの主要な応用例
- 教師あり学習:顧客離反予測、与信スコアリング、需要予測
- 教師なし学習:異常検知、レコメンデーションシステム、市場セグメンテーション
- 強化学習:ゲームAI、ロボット制御、自動運転
実務での活用
- データの品質と前処理の重要性
- ドメイン知識の活用
- モデルの解釈可能性と継続的な評価の必要性
学習アプローチ
- 基礎から応用へ段階的に学ぶ
- 理論と実践のバランスを取る
- 継続的な学習と最新トレンドのフォロー
今後の展望
- AIと機械学習のさらなる融合:より高度な自律システムの開発
- エッジコンピューティングの進化:デバイス上での機械学習の実行
- 説明可能AI(XAI)の発展:モデルの決定プロセスの透明性向上
- 倫理的AI:公平性、透明性、プライバシーに配慮したAIシステムの構築
- 自動機械学習(AutoML)の進化:モデル開発プロセスの自動化
機械学習は急速に発展し続ける分野であり、その可能性は計り知れません。しかし、技術の力を正しく活用するためには、基礎的な理解と倫理的な考慮が不可欠です。
今回扱った基本を出発点として、継続的に学習し、実践を重ねていくことで、機械学習の専門家として成長していくことができるでしょう。
技術の進歩とともに、私たちにはそれを責任を持って活用する義務があります。機械学習の力を通じて、ビジネスや社会に貢献する革新的なソリューションを生み出す未来を目指しましょう。