

データ分析の世界で、「連続データの離散化」という言葉をご存知でしょうか?
一見すると複雑そうなこの手法が、実はビジネスデータ分析をより有効にする可能性を秘めています。
年齢、売上、時間といった連続的な数値データを、意味のあるカテゴリーに変換することで、これまで見えなかったパターンや傾向が浮かび上がってくるのです。
今回は、連続データの離散化がいかにして顧客セグメンテーションを精緻化し、リスク管理を高度化し、マーケティング施策を最適化するかを、ビジネス事例とともに簡単に説明していきます。
Contents [hide]
- 連続データの離散化とは
- 連続データと離散データの違い
- なぜ連続データを離散化するのか
- 離散化の手法
- 等幅分割法
- 等頻度分割法
- クラスタリングを用いた方法
- ドメイン知識(領域専門家の知見)を活用した方法
- ビジネスケース①: 顧客セグメンテーションの精緻化
- 年齢や所得などの連続変数を活用したセグメンテーション
- 離散化
- 小売り業での購買行動分析の事例
- ビジネスケース②: リスク管理の高度化
- 信用スコアリングにおける連続変数の離散化
- 離散化
- 金融機関での与信判断の改善事例
- ビジネスケース③: マーケティング施策の最適化
- 広告効果測定における連続変数の活用
- 離散化
- デジタル広告の投資対効果分析の事例
- 離散化の注意点
- 情報損失のリスク
- 適切な区分数の選択
- モデルの解釈可能性との兼ね合い
- データの性質に応じた手法の選択
- 時系列データの扱い
- 倫理的配慮
- 今回のまとめ
連続データの離散化とは
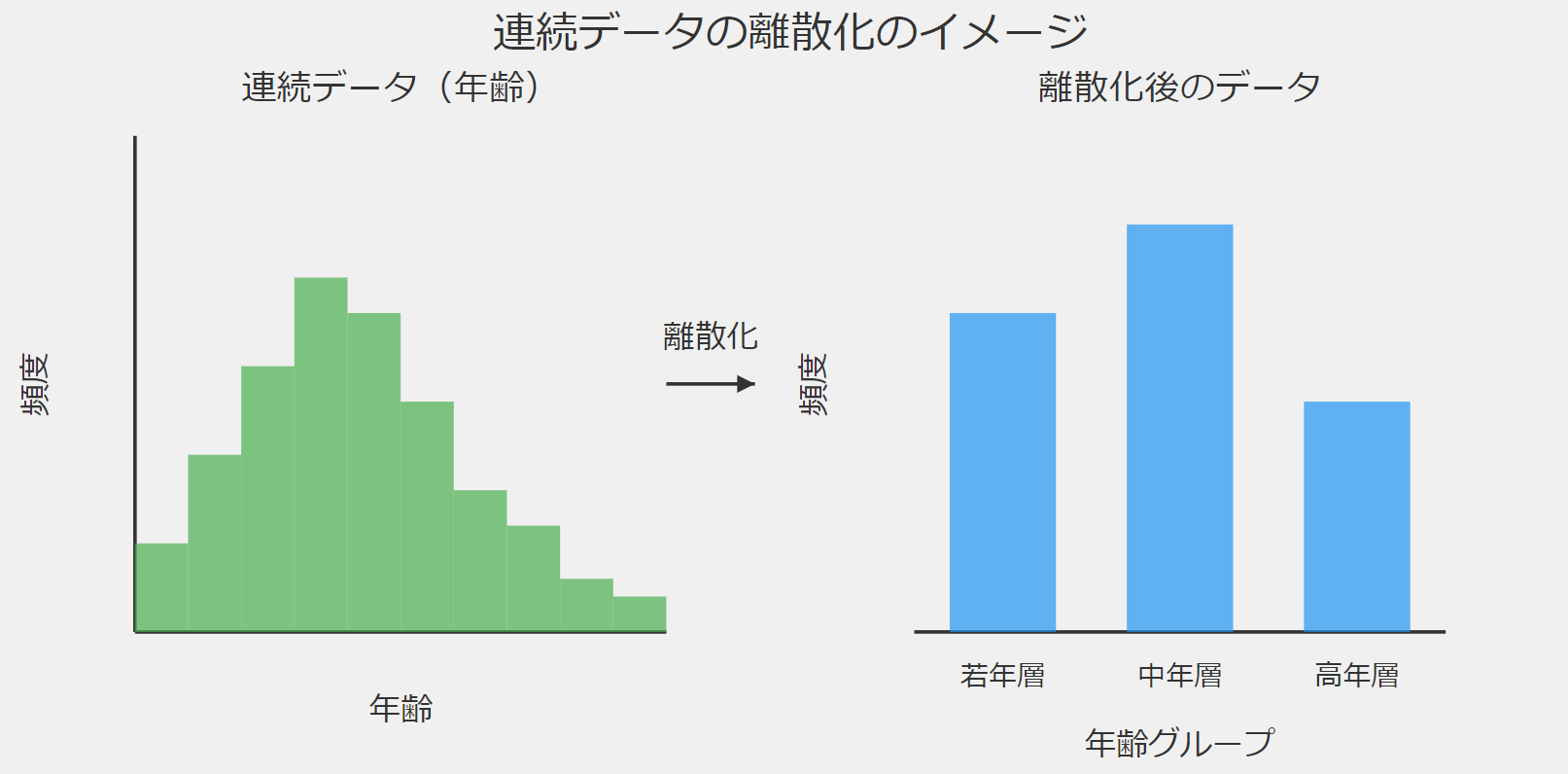
ビジネスの世界では、日々膨大なデータが生成されています。
売上高、顧客の年齢、商品の価格、取引の時間など、これらのデータの多くは「連続データ」と呼ばれるものです。連続データは、理論上、無限の値を取り得る数値データのことを指します。
しかし、このような連続データをそのまま分析に使用すると、重要なパターンや傾向を見逃してしまう可能性があります。
ここで登場するのが「連続データの離散化」という手法です。
連続データと離散データの違い
まず、連続データと離散データの違いを理解しましょう。
連続データとは、理論上、任意の値を取り得るデータです。例えば、身長、体重、時間、温度などです。
離散データとは、特定の値のみを取るデータです。例えば、年齢(整数)、商品のカテゴリー、顧客ランクなどです。
連続データの離散化とは、この連続データを意味のある区間やカテゴリーに分割し、離散データに変換する過程を指します。
なぜ連続データを離散化するのか
連続データを離散化する理由は複数あります。例えば、以下です。
パターンの発見
データをグループ化することで、大まかな傾向やパターンが見やすくなります。
モデルの性能向上
機械学習モデルによっては、離散化されたデータを使用することで予測精度が向上する場合があります。
解釈のしやすさ
「30歳未満」「30-50歳」「50歳以上」のように区分けすることで、ビジネス的な解釈が容易になります。
外れ値の影響軽減
極端な値をグループ化することで、分析結果への影響を抑えることができます。
非線形関係の捕捉
連続変数と目的変数の間の非線形な関係を、離散化によって表現できることがあります。
例えば、Eコマースサイトの分析で「購入金額」という連続データを考えてみましょう。
これを「5,000円未満」「5,000-10,000円」「10,000円以上」のように離散化することで、各価格帯での顧客の行動パターンや、マーケティング施策の効果を明確に把握できるようになります。
連続データの離散化は、データ分析の前処理として重要な役割を果たします。
しかし、適切な離散化の方法を選択しないと、かえって情報を失ってしまう可能性もあります。
離散化の手法
連続データの離散化には、様々な手法があります。
それぞれの手法には長所と短所があり、データの性質や分析の目的に応じて適切な方法を選択することが重要です。
ここでは、主要な離散化の手法について説明します。
等幅分割法
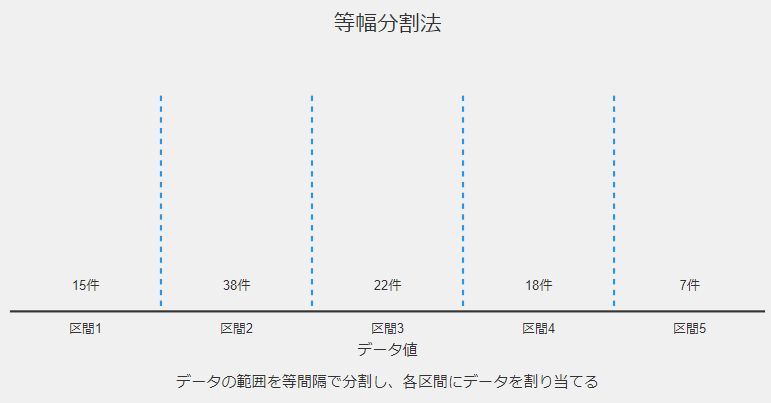
等幅分割法は、データの範囲を等しい幅の区間に分割する最も単純な方法です。
以下、手順です。
- データの最小値と最大値を確認
- 希望する区間の数を決定
- (最大値 – 最小値) ÷ 区間数 で区間幅を計算
- 最小値から順に区間幅を加えて、各区間の境界を決定
以下、年齢データ(最小20歳、最大80歳)を4区間に分ける例です。
- 区間幅 = (80 – 20) ÷ 4 = 15
- 区間: [20-35), [35-50), [50-65), [65-80]
長所は、実装が簡単で、結果が直観的に理解しやすいところです。
短所は、データの分布を考慮しないため、極端に偏った分布の場合に効果的でない場合があることです。
等頻度分割法
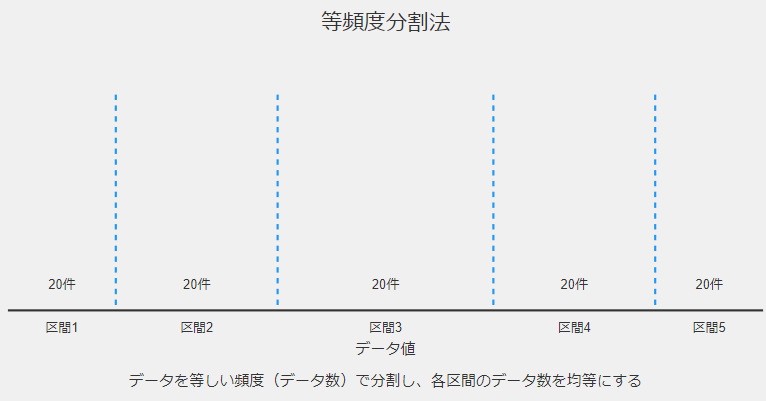
等頻度分割法は、各区間に含まれるデータ数が等しくなるように分割する方法です。
以下、手順です。
- データを昇順にソート
- 希望する区間の数を決定
- 総データ数 ÷ 区間数 で各区間に含めるデータ数を計算
- データを順に区間に振り分け、各区間の境界を決定
例えば、100件の売上データを4区間に分ける場合、各区間に25件ずつデータが入るように分割します。
長所は、データの分布を考慮するため、偏った分布でも効果的なところです。
短所は、外れ値の影響を受けやすいところです。
クラスタリングを用いた方法
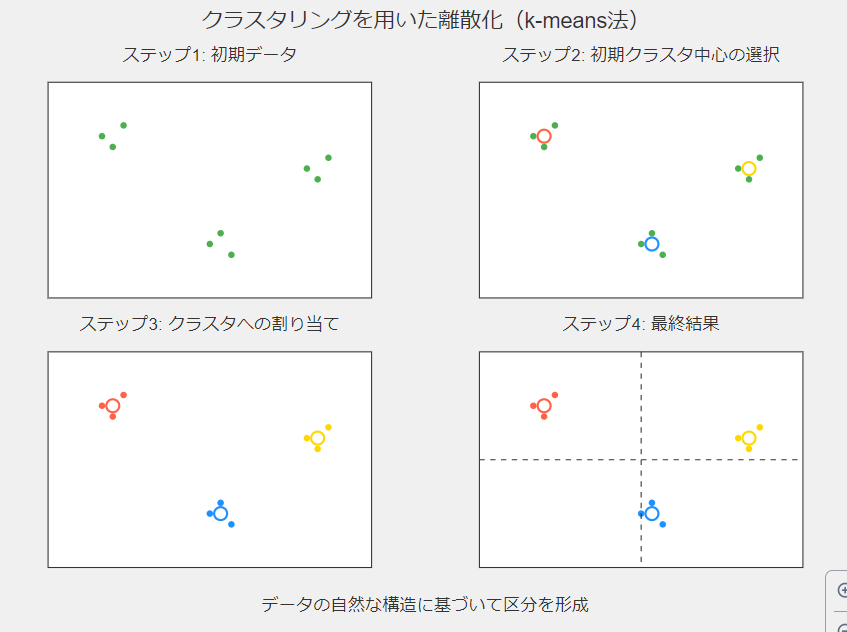
k-meansなどのクラスタリングアルゴリズムを使用して、データを自然なグループに分割する方法です。
以下、手順です。
- クラスタリングアルゴリズムを選択(例:k-means)
- クラスタ数(k)を決定
- アルゴリズムを実行し、データポイントをクラスタに割り当て
- 各クラスタを1つの区間とみなす
長所は、データの自然な構造を反映した分割が可能なところです。
短所は、計算コストが高く、結果の解釈が難しい場合があるところです。
ドメイン知識(領域専門家の知見)を活用した方法
ビジネスや分析の目的に基づいて、専門家が手動で区間を決定する方法です。
例えば、ビジネスの慣習をもとに、顧客の年齢を「若年層(30歳未満)」「中年層(30-50歳)」「シニア層(50歳以上)」に分類したりします。
長所は、ビジネスの文脈に即した意味のある分割が可能なところです。
短所は、主観的になる可能性があり、データの実際の分布を無視する可能性があるところです。
ビジネスケース①: 顧客セグメンテーションの精緻化

顧客セグメンテーションは、マーケティング戦略の要となる重要な分析手法です。
顧客を適切にグループ化することで、各グループの特性に合わせたアプローチが可能となり、マーケティング効率の向上やカスタマーエクスペリエンスの改善につながります。
ここでは、連続データの離散化を活用して、より精緻な顧客セグメンテーションを行う例を見ていきましょう。
年齢や所得などの連続変数を活用したセグメンテーション
従来の顧客セグメンテーションでは、年齢や所得といった連続変数を大まかなカテゴリーに分類することが一般的でした。
しかし、連続データの離散化の技術を用いることで、より洗練されたセグメンテーションが可能になります。
例えば、ある小売業の顧客データを使って、以下の連続変数を離散化してみましょう。
- 年齢
- 年間購買金額
- 平均購買間隔
離散化
年齢の離散化
- 方法:等頻度分割法
- 理由:年齢分布の偏りを考慮し、各セグメントの顧客数をバランスよく保つため
- 結果:[18-25), [25-35), [35-45), [45-55), [55+]
年間購買金額の離散化
- 方法:対数変換後の等幅分割法
- 理由:購買金額は通常、右に歪んだ分布を示すため、対数変換で正規分布に近づけてから分割
- 結果:[0-10,000円), [10,000-50,000円), [50,000-200,000円), [200,000円+]
平均購買間隔の離散化
- 方法:クラスタリング(k-means)
- 理由:購買サイクルの自然なパターンを見出すため
- 結果:[0-30日), [31-90日), [91-180日), [181日+]
小売り業での購買行動分析の事例
ある大手スーパーマーケットチェーンが、この手法を用いて顧客セグメンテーションを行い、より詳細な顧客セグメントを作成しました。
例えば……
- 「若年・高頻度・高額購入層」: 25-35歳、年間購買金額200,000円以上、購買間隔30日以内
- 「中年・中頻度・中額購入層」: 35-55歳、年間購買金額50,000-200,000円、購買間隔31-90日
- 「シニア・低頻度・低額購入層」: 55歳以上、年間購買金額50,000円未満、購買間隔181日以上
この顧客セグメンテーションより、以下のような具体的な施策を実施することができました。
ターゲティングの精緻化
- 「若年・高頻度・高額購入層」向けに、オーガニック食品や健康食品のプロモーションを強化
- 「シニア・低頻度・低額購入層」に対し、店舗への来店を促す特別クーポンを発行
商品配置の最適化
- 各年齢層の購買傾向に基づいて、店舗レイアウトを調整
- 例:若年層向け商品を入口近くに、シニア層向け商品をレジ近くに配置
パーソナライズドマーケティング
- 各セグメントの購買サイクルに合わせて、リマインダーメールやプッシュ通知を送信
- 例:最終購買から60日経過した中頻度顧客に、お得な情報を含むニュースレターを配信
新規サービスの開発
- 「中年・高頻度・高額購入層」向けに、時短・簡便な食事キットサービスを開発
これらの施策の結果、当該スーパーマーケットチェーンは以下の成果を得ることができました。
- 顧客単価が平均12%上昇
- 顧客維持率が8%向上
- 新規サービスの導入により、中年層の来店頻度が15%増加
このように、連続データの離散化を活用した精緻な顧客セグメンテーションは、マーケティング戦略の高度化と、それに伴う具体的なビジネス成果の向上につながります。
ビジネスケース②: リスク管理の高度化

金融機関におけるリスク管理は、ビジネスの根幹を成す重要な業務です。
特に、与信判断におけるリスク評価は、収益性と健全性のバランスを保つ上で極めて重要です。
ここでは、連続データの離散化を活用して、信用スコアリングモデルを改善し、リスク管理を高度化する例を見ていきましょう。
信用スコアリングにおける連続変数の離散化
信用スコアリングモデルでは、様々な顧客属性を用いてデフォルトリスクを予測します。
多くの変数が連続的な性質を持っていますが、これらを適切に離散化することで、モデルの精度向上や解釈性の改善が期待できます。
以下の連続変数を例に、離散化してみましょう。
- 年収
- 勤続年数
- 過去の借入返済実績
離散化
年収の離散化
- 方法:等頻度分割法と専門家の知見の組み合わせ
- 理由:所得分布の偏りを考慮しつつ、実務的に意味のある区分を設定するため
- 結果:[0-300万円), [300-500万円), [500-800万円), [800-1200万円), [1200万円+]
勤続年数の離散化
- 方法:等幅分割法と専門家の知見の組み合わせ
- 理由:一般的な雇用慣行や転職傾向を考慮するため
- 結果:[0-2年), [2-5年), [5-10年), [10年+]
過去の借入返済実績の離散化
- 方法:クラスタリング(k-means)
- 理由:返済行動の自然なパターンを見出すため
- 結果:[遅延なし], [軽微な遅延(1-30日)], [重大な遅延(31日以上)], [デフォルト経験あり]
金融機関での与信判断の改善事例
これらの離散化された変数を用いて信用スコアリングモデルを構築することで、ある中堅銀行で以下のような改善が見られました。
モデルの予測精度向上
- AUC (Area Under the Curve) が0.75から0.82に向上
- 不良債権率が前年比15%減少
リスク要因の可視化
- 各変数のリスクへの寄与度が明確になり、与信判断の根拠が説明しやすくなった
- 例:「年収500-800万円」かつ「勤続年数2-5年」の層で、デフォルトリスクが特に高いことが判明
この信用スコアリングモデルを活用した結果、以下のようになりました。
審査プロセスの効率化
- 自動審査可能な案件が20%増加し、審査時間が平均30%短縮
- 人的リソースを複雑な案件の精査に集中させることが可能に
リスクベース・プライシングの導入
- 顧客のリスクプロファイルに応じて、よりきめ細かな金利設定が可能に
- 低リスク顧客の獲得率が15%向上し、市場シェアが拡大
プロアクティブなリスク管理
- 早期警戒指標の精度が向上し、潜在的な不良債権の60%を事前に検知
- 債権回収チームと連携し、返済困難が予想される顧客への事前サポートを強化
規制対応の強化
- モデルの解釈性が向上したことで、規制当局への説明が容易に
- ストレステストのシナリオ分析がより精緻化され、資本計画の精度が向上
これらの施策の結果、当該銀行は以下の成果を得ることができました。
- 不良債権比率が前年比0.5ポイント低下
- リスク調整後収益率(RAROC)が8%向上
- 顧客満足度調査のスコアが10%改善
このように、連続データの離散化を活用した信用スコアリングモデルの改善は、リスク管理の高度化だけでなく、収益性の向上や顧客満足度の改善など、多面的なビジネス価値の創出につながります。
ビジネスケース③: マーケティング施策の最適化

デジタルマーケティングの世界では、データに基づいた意思決定が不可欠です。
特に、広告効果の測定と投資対効果(ROI)の最適化は、マーケティング予算を効果的に活用する上で極めて重要です。
ここでは、連続データの離散化を活用して、広告効果測定を改善し、マーケティング施策を最適化する例を見ていきましょう。
広告効果測定における連続変数の活用
デジタル広告の効果測定では、様々な連続的な指標が用いられます。
これらの指標を適切に離散化することで、より深い洞察を得ることができ、効果的なマーケティング戦略の立案が可能になります。
以下の連続変数を例に、離散化してみましょう。
- 広告露出回数
- クリック後の滞在時間
- 購入までの日数
離散化
広告露出回数の離散化
- 方法:等頻度分割法とマーケティング専門家の知見の組み合わせ
- 理由:露出回数の分布を考慮しつつ、実務的に意味のある区分を設定するため
- 結果:[1-3回), [3-7回), [7-15回), [15-30回), [30回以上]
クリック後の滞在時間の離散化
- 方法:クラスタリング(k-means)
- 理由:ユーザーの自然な閲覧パターンを見出すため
- 結果:[0-12秒), [12-34秒), [34秒-2分), [2分以上]
購入までの日数の離散化
- 方法:等幅分割法と業界知見の組み合わせ
- 理由:一般的な購買タイミングと商品特性を考慮するため
- 結果:[即日], [1-3日], [4-7日], [8-14日], [15日以上]
デジタル広告の投資対効果分析の事例
ある大手Eコマース企業が、これらの離散化された変数を用いて広告効果分析を行うことで、以下のような改善が見られました。
広告効果の可視化
- 露出回数と購買行動の関係が明確になり、最適な広告頻度が特定できた
- 例:7-15回の露出で購買確率が最も高くなることが判明
ユーザーエンゲージメントの理解
- クリック後の滞在時間と購買行動の関連性が明らかに
- 例:34秒-2分の滞在で最も購買確率が高いことが分かり、ランディングページの設計に活用
リターゲティング戦略の最適化
- 購入までの日数に基づいて、最適なリマインダー広告のタイミングを特定
- 例:4-7日のセグメントに対して、5日目にリマインダー広告を配信する戦略を立案
離散化された変数を用いて広告効果分析を行うことで、以下の成果を得ました。
広告予算の最適化
- セグメントごとの広告効果を精緻に分析し、ROIの高いセグメントに予算を重点配分
- 結果:全体の広告予算を10%削減しながら、売上は5%増加
クリエイティブの改善
- 滞在時間と購買行動の関係から、効果的なランディングページの特徴を特定
- 新デザインの導入により、コンバージョン率が平均15%向上
カスタマージャーニーの最適化
- 購入までの日数に基づいて、メールマーケティングとリターゲティング広告を連携
- カートの放棄率が20%減少し、リピート購入率が10%向上
LTV(顧客生涯価値)の向上
- 広告露出からLTVまでの関係を分析し、長期的な顧客価値を最大化する戦略を立案
- 新規顧客の1年後の継続率が15%向上
これらの施策の結果、以下の成果を得ることができました。
- マーケティングROIが前年比25%向上
- 新規顧客獲得コストが15%減少
- 顧客満足度スコア(NPS)が10ポイント上昇
このように、連続データの離散化を活用した広告効果測定の改善は、マーケティング施策の最適化だけでなく、コスト効率の向上や顧客満足度の改善など、多面的なビジネス価値の創出につながります。
連続データの離散化は、単なるデータ処理技術ではなく、ビジネスインサイトを引き出す強力なツールとなります。
適切に活用することで、データドリブンな意思決定を支援し、競争優位性の構築に貢献するのです。
離散化の注意点
連続データの離散化は強力なツールですが、適切に使用しないと分析の質を低下させる可能性があります。
ここでは、離散化を行う際の主な注意点と、効果的に活用するためのベストプラクティスについて解説します。
情報損失のリスク
離散化の最大の懸念点は、連続データが持つ詳細な情報が失われる可能性があることです。
注意点
- 過度に粗い区分けは、重要なパターンを見逃す原因となる
- 線形関係が非線形に見えたり、その逆が起こる可能性がある
対策
- 離散化前後でデータの分布を視覚化し、情報損失を確認する
- 可能な場合、元の連続変数と離散化変数の両方を分析に使用する
- 複数の離散化方法を試し、結果を比較検証する
適切な区分数の選択
区分数は分析の精度と解釈のしやすさに大きく影響します。
注意点
- 区分数が少なすぎると情報が失われ、多すぎると過学習のリスクがある
- データサイズに対して不適切な区分数を選ぶと、統計的信頼性が低下する
対策
- 一般的には5から7区分程度から始め、必要に応じて増やしたり減らしたり調整する
- クロスバリデーションなどの手法を用いて、最適な区分数を決定する
- ドメイン知識を活用し、ビジネス的に意味のある区分を考慮する
モデルの解釈可能性との兼ね合い
離散化はモデルの解釈可能性を向上させる一方で、モデルの複雑さを増す可能性もあります。
注意点
- 離散化により変数間の交互作用が複雑になる可能性がある
- 一部のアルゴリズムでは、離散化が不要または有害な場合がある
対策
- モデルの目的(予測 vs. 解釈)に応じて離散化の程度を調整する
- 離散化前後でモデルのパフォーマンスを比較し、改善を確認する
- 決定木やランダムフォレストなど、離散化が不要なアルゴリズムの使用も検討する
データの性質に応じた手法の選択
データの分布や特性に合わない離散化手法を選ぶと、誤った結論を導く可能性があります。
注意点
- 等幅分割法は外れ値の影響を受けやすい
- 等頻度分割法は、重要な閾値を見逃す可能性がある
対策
- データの分布を事前に確認し、適切な手法を選択する
- 複数の手法を組み合わせて使用する(例:等幅分割と専門家の知見の併用)
- 離散化の結果を可視化し、直感的に妥当性を確認する
時系列データの扱い
時系列データの離散化には特有の課題があります。
注意点
- 時間的な連続性や周期性が失われる可能性がある
- 将来的な変化に対応できない固定的な区分になりがち
対策
- 時系列の特性(トレンド、季節性など)を考慮した区分を設定する
- 動的な離散化手法(例:ローリングウィンドウ方式)の使用を検討する
- 時間的な文脈を保持するため、連続変数と離散変数を組み合わせて使用する
倫理的配慮
データの離散化が及ぼす社会的影響にも注意が必要です。
注意点
- 不適切な離散化により、特定のグループに対する差別を生む可能性がある
- プライバシー保護の観点から、過度に細かい区分は避けるべき場合がある
対策
- 離散化の結果が特定のグループに不利にならないか確認する
- 法的・倫理的ガイドラインに沿った離散化を行う
- 必要に応じて、専門家による倫理的レビューを受ける
連続データの離散化は、適切に行えばデータ分析に大きな価値をもたらします。しかし、ここで挙げた注意点を考慮し、対策することが重要です。
離散化はデータ分析のプロセス全体の一部であり、常にビジネスゴールと照らし合わせながら、その効果を検証し続けることが成功への鍵となります。
今回のまとめ
今回は、「ビジネスデータ分析を変える『連続データの離散化』で見えてくる新たな洞察」というお話しをしました。
連続データの離散化は、データ分析の基礎的な技術でありながら、ビジネスに大きなインパクトをもたらす可能性を秘めています。
データは21世紀の石油と言われます。しかし、その真の価値は適切に精製され、活用されてこそ発揮されます。
連続データの離散化は、その精製プロセスにおける重要な一歩なのです。データ駆動型の意思決定を目指す組織にとって、この手法の理解と適切な活用は、競争優位性を築く上で欠かせない要素となるでしょう。
データの海から意味ある洞察を掘り起こし、ビジネスの成功につなげる。その道のりにおいて、連続データの離散化が皆様の強力な武器となることを願っています。