
現代のビジネス環境では、不確実性が高まり、市場の変化も加速しています。
このような状況下で、ビジネス上の判断や戦略の策定においてデータを活用した科学的な予測・意思決定の重要性が日々高まっています。
特に多くの企業が複数の地域、複数の商品カテゴリー、複数のチャネルなど、複雑な構造を持つ組織で事業を展開している中、各階層で整合性のとれた予測を行うことは容易ではありません。
例えば、全社の売上予測と各部門の売上予測が一致しない、本社が立てた販売計画と各地域の販売店が見込む数字に乖離がある、といった課題は多くの企業が日常的に直面している問題です。
このような課題に対応するためのアプローチとして注目されているのが「階層型時系列モデル」です。
今回は、「階層型時系列モデルで実現するビジネス予測の高度化」というお話しをします。
Contents [hide]
- 階層型時系列モデルとは
- 階層と時系列の統合
- 階層の例
- 活用メリット
- 代表的な手法
- トップダウンアプローチ
- ボトムアップアプローチ
- ミドルアウトアプローチ
- 最適組み合わせ(Optimal Combination)アプローチ
- ベイズ階層モデル
- 手法の違いと使い分け
- 予測モデルの構築ステップ
- ステップ1: データ構造の把握
- ステップ2: モデル選択と実装
- ステップ3: モデルの評価とチューニング
- 実務での課題とその対応
- 導入事例:全国店舗の売上・在庫最適化
- 企業プロフィール
- 導入前の課題
- 階層型時系列モデル導入プロジェクト
- 導入した予測モデル
- 導入効果
- 導入における課題と対応策
- 階層型時系列モデルの導入を検討される方へ
- 今回のまとめ
階層型時系列モデルとは
階層と時系列の統合
階層型時系列モデル(Hierarchical Time Series Model)とは、その名の通り「階層」と「時系列」の両方を考慮したデータ分析・予測モデルです。
時系列データとは、時間の経過とともに記録された連続的なデータポイントの集合を指します。
例えば、日次売上データ、月間ウェブサイト訪問者数、四半期ごとの生産量などが該当します。
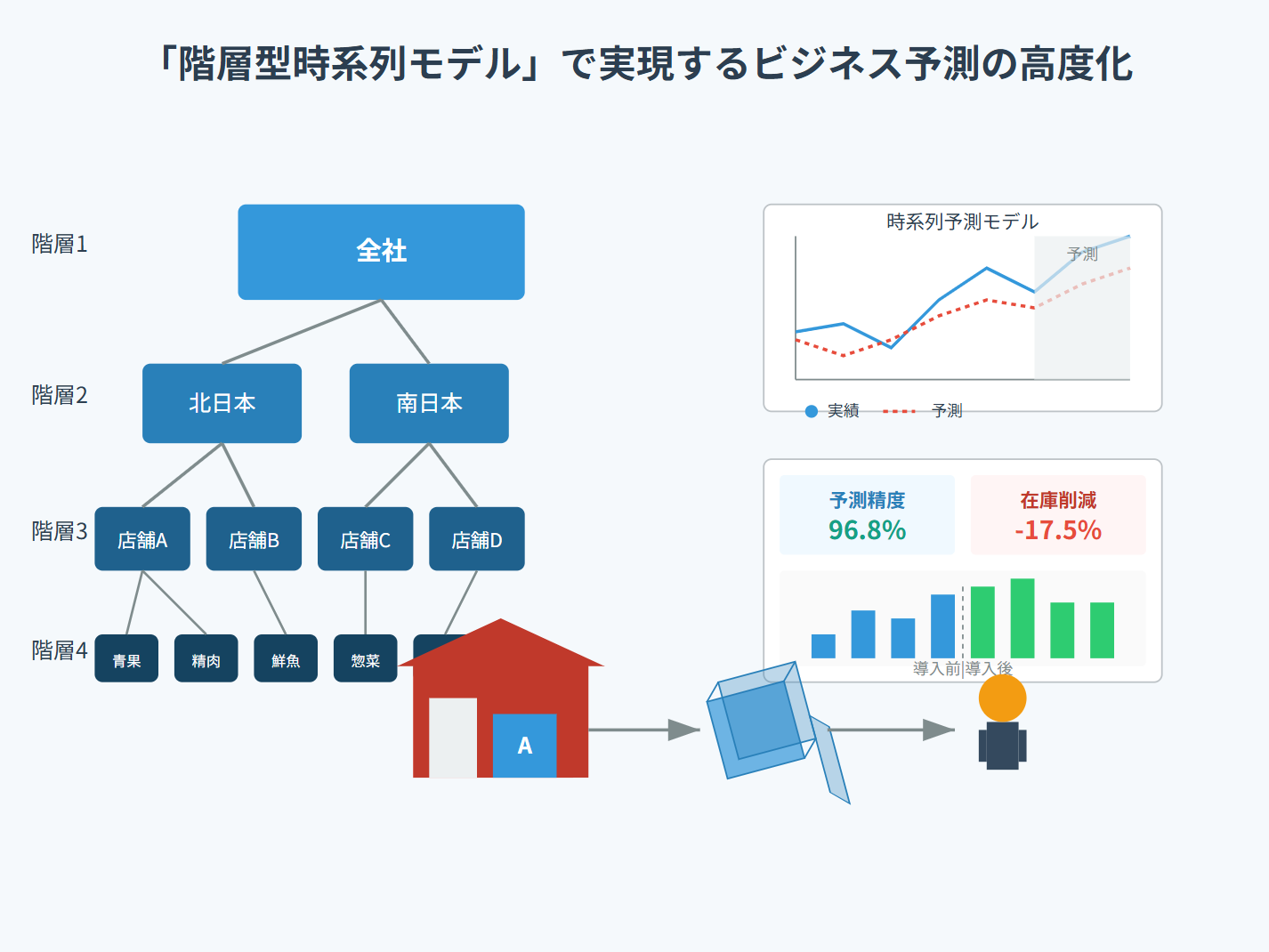
一方、階層構造とは、データが複数のレベルで集計可能な構造を持つことを意味します。
例えば、企業の売上データは「全社→事業部門→製品カテゴリ→個別製品」というように階層化することができます。
階層型時系列モデルは、これらの階層構造を持つデータを時間軸に沿って分析・予測するための手法です。
階層の例
ビジネスにおける階層構造の例としては、以下のようなものが考えられます。
- 組織階層: 企業全体 → 事業部門 → 部署 → チーム → 個人
- 地理的階層: 全国 → 地域ブロック → 都道府県 → 市区町村 → 店舗
- 製品階層: 全製品 → 製品カテゴリ → 製品シリーズ → 個別製品 → サイズ・カラー
- 顧客階層: 全顧客 → 顧客セグメント → 年齢層 → 個別顧客
実際のビジネスでは、これらの階層が複雑に絡み合っていることが一般的です。
例えば、小売業では「地域×店舗×商品カテゴリ」といった多次元の階層構造を持つデータを扱うことになります。
活用メリット
階層型時系列モデルを活用する主なメリットには以下のようなものがあります。
整合性の確保
異なる階層レベル間で予測値の整合性を保つことができます。例えば、各地域の予測売上の合計が全社予測と一致するなど、論理的な矛盾を防ぎます。
予測精度の向上
階層間の関連性を考慮することで、単独のモデルよりも予測精度が向上する場合があります。特に下位階層のデータが少ない場合、上位階層の情報を活用することで予測の安定性が増します。
情報共有の容易さ
組織内の様々なレベルで一貫性のある予測を共有できるため、各部門間のコミュニケーションや意思決定の効率が向上します。
代表的な手法
階層型時系列予測には、いくつかの代表的な手法があります。
トップダウンアプローチ
トップダウンアプローチは、最も上位の階層レベル(例:全社売上)を予測し、その結果を何らかの比率や重みに基づいて下位レベル(例:部門別売上)に分配する方法です。
次のような特徴があります。
- シンプルで実装が容易
- 上位レベルの予測が安定している場合に有効
- 下位レベルの特殊な動向を捉えにくい
例えば、全社売上を予測した後、過去の実績に基づく各部門の構成比率を使って部門別売上を算出します。
ボトムアップアプローチ
ボトムアップアプローチは、最も下位の階層レベル(例:個別製品の売上)をそれぞれ独立に予測し、その結果を集計して上位レベル(例:カテゴリ別、全社売上)を構築する方法です。
次のような特徴があります。
- 下位レベルの特性や変動を詳細に捉えられる
- 下位レベルの予測誤差が上位に累積する可能性がある
- データ量が十分にある場合に有効
例えば、各店舗の売上を個別に予測し、それらを合計して地域全体の売上予測とします。
ミドルアウトアプローチ
ミドルアウトアプローチは、中間レベルの階層(例:製品カテゴリ)で予測を行い、そこから上位レベルと下位レベルの両方を導出する方法です。
次のような特徴があります。
- 中間レベルが最も安定しているケースに有効
- 上位と下位の両方にバランスよく情報を反映できる
- 階層構造が複雑な場合に有用
例えば、都道府県別の需要予測を行い、それを合計して全国予測とする一方、人口比などに基づいて市区町村別の予測に分解します。
最適組み合わせ(Optimal Combination)アプローチ
最適組み合わせアプローチは、各階層レベルで独立に予測を行った後、それらの予測結果を統計的手法(例:線形回帰や最小二乗法)を用いて整合的に調整する方法です。
代表的な手法としては、Hyndmanらが提案したForecast Reconciliationのアルゴリズムがあります。
次のような特徴があります。
- 各階層の情報をバランスよく活用できる
- 理論的に優れた特性を持つ
- 実装がやや複雑になる場合がある
例えば、全社、部門、製品カテゴリの各レベルで独立に予測を行い、それらの予測値から最小二乗法によって整合性のある予測セットを導出する。
ベイズ階層モデル
ベイズ階層モデルは、ベイズ統計学の枠組みを用いて階層構造を明示的にモデル化する方法です。
各階層の予測が確率分布として表現され、上位階層と下位階層の情報が統合されます。
次のような特徴があります。
- 不確実性の評価が可能
- データが少ない階層でも安定した予測が可能
- 複雑なパターンやトレンドの捕捉に優れる
- 計算負荷が高い場合がある
例えば、新店舗の売上予測において、類似店舗のデータを参考にしつつ、全体的な傾向も考慮した確率的予測を行います。
手法の違いと使い分け
各手法の使い分けは、以下のような要素を考慮して決定するとよいでしょう。
| アプローチ | 適している状況 | 向いていない状況 |
|---|---|---|
| トップダウン | ・下位レベルのデータが少ない ・上位レベルが安定している ・シンプルな実装を優先したい |
・下位レベルの変動が大きい ・下位レベルに固有の傾向がある |
| ボトムアップ | ・下位レベルのデータが豊富 ・下位レベルに固有の傾向がある ・詳細な予測が必要 |
・下位レベルのデータにノイズが多い ・下位レベルのデータが少ない |
| 最適組み合わせ | ・各階層でそれぞれ特徴がある ・予測精度を最大化したい ・理論的な裏付けを重視する |
・実装の簡便さを優先したい ・計算リソースが限られている |
| ベイズ階層モデル | ・不確実性の評価が重要 ・データが不足している階層がある ・複雑な依存関係がある |
・実装の容易さを優先したい ・解釈のしやすさが重要 |
予測モデルの構築ステップ
階層型時系列モデルを実際にビジネスに導入するためのステップと、各段階での注意点について解説します。
ステップ1: データ構造の把握
まず最初に、自社のデータがどのような階層構造を持っているかを明確に把握することが重要です。
以下、ポイントです。
- どのような階層レベルが存在するか(組織、地域、製品、顧客など)
- 各階層レベルでのデータの粒度と品質(欠損値、異常値の有無)
- 階層間の関係性(単純な集計関係か、複雑な依存関係があるか)
以下、注意点です。
- 分析の目的に合わない階層設計になっていないか確認する
- データ収集頻度が階層によって異なる場合の対処法を検討する
- 階層が多すぎると複雑化するため、重要な階層に絞ることも検討する
ステップ2: モデル選択と実装
データ構造の把握後、適切なモデルアプローチを選択し実装します。
以下、ポイントです。
- 前述のアプローチ(トップダウン、ボトムアップ、最適組み合わせなど)から適切なものを選択
- 利用可能なツールやライブラリの検討(R、Python、専用ソフトウェアなど)
- 具体的な実装方法の決定(単純な比率法、統計モデル、機械学習モデルなど)
以下、注意点です。
- 複雑すぎるモデルは解釈が難しく、メンテナンスも大変になる
- 将来的な拡張性も考慮してモデル設計を行う
- 実装言語やライブラリの選択は、社内のスキルセットも考慮する
【Rを利用する場合の代表的なパッケージ】
hts: 階層型時系列モデリングの基本的な機能を提供(Hyndmanらが開発)prophet: Facebookが開発した時系列予測ツール(階層と組み合わせて利用可能)forecast: 様々な時系列予測手法を含むパッケージ(Hyndmanらが開発)
【Pythonを利用する場合の代表的なライブラリ】
scikit-hts: 階層型時系列モデリング専用のライブラリstatsmodels: 統計モデルを提供(階層モデルと組み合わせて利用可能)pmdarima: 自動ARIMAモデリングのためのライブラリ
このあたりのモデリング環境は、PythonよりもRの方が充実しています。
ステップ3: モデルの評価とチューニング
構築したモデルの精度を評価し、必要に応じてチューニングを行います。
以下、ポイントです。
- 適切な評価指標の選定(MAPE、RMSE、MAEなど)
- テストデータセットによる予測精度の検証
- 階層レベル別の予測精度評価と全体の整合性確認
以下、注意点です。
- 下位レベルと上位レベルで評価指標のバランスを取る
- 単純な精度だけでなく、ビジネス上の意思決定への影響も評価する
- 階層間の整合性と個別の予測精度はトレードオフの関係にあることを理解する
実務での課題とその対応
実務で階層型時系列モデルを導入・運用する際によく直面する課題とその対応策について解説します。
| 課題 | 内容 | 対応策 |
|---|---|---|
| 下位レベルのデータ不足・欠損 | 新商品や新店舗など、十分な履歴データがない場合がある | 類似する既存データを活用する、ベイズ階層モデルで不確実性を考慮する |
| 上位レベルとの不整合 | 下位レベルの合計が上位レベルと一致しない場合がある(計測誤差、タイミングのずれなど) | データクレンジングを徹底する、矛盾を許容したモデリング手法を選択する |
| モデルの複雑化と過学習 | 階層が多くなるとモデルが複雑化し、過学習のリスクが高まる | 正則化手法の導入、階層構造のシンプル化、重要な階層に焦点を当てる |
| 解釈性の低下 | 高度なモデルほど「ブラックボックス化」しやすく、非技術者への説明が難しくなる | 可視化ツールの活用、重要な要素に絞った説明資料の作成、段階的な導入 |
導入事例:全国店舗の売上・在庫最適化
階層型時系列モデルの導入事例として、全国展開する小売業での活用例を紹介します。
企業プロフィール
「スーパーマーケットチェーンA社」は、全国47都道府県に約300店舗を展開する中堅の食品スーパーマーケットチェーンです。
取扱商品数は食品、日用品を中心に約15,000品目に及びます。A社の組織構造は以下のような階層になっています。
- 本社(経営企画部、商品部、物流部など)
- 7つの地域本部(北海道・東北、関東、甲信越、中部、関西、中国・四国、九州・沖縄)
- 47都道府県の各エリア
- 300店舗(大型店、標準店、小型店の3フォーマット)
- 商品カテゴリ(青果、精肉、鮮魚、惣菜、加工食品、日用品など8大カテゴリ)
- 細分化された商品サブカテゴリと個別商品
生鮮食品の品質の高さと地域に密着した品揃えを強みとしています。
導入前の課題
A社は階層型時系列モデル導入前、以下のような課題を抱えていました。
| 分類 | 課題・問題点 | 具体例 | |
|---|---|---|---|
| 予測の不整合と情報の分断 | 全社レベル |
|
|
| 地域・店舗レベル |
|
|
|
| 商品カテゴリレベル |
|
|
|
| 在庫管理の非効率性 |
|
|
|
| データ活用の技術的課題 |
|
|
|
階層型時系列モデル導入プロジェクト
A社は2023年4月から、外部の力を活用しつつ社内のプロジェクトチームを編成し、約6ヶ月かけて階層型時系列モデルの導入を実施しました。
| 役割 | 担当者・構成 |
|---|---|
| プロジェクトオーナー | 経営企画部担当役員 |
| プロジェクトリーダー | 経営企画部次長(データ分析担当) |
| コアメンバー | IT部門、商品部門、物流部門、店舗運営部門から各1名 |
| 外部コンサルタント | データサイエンス専門のコンサルティング会社1名 |
| 協力メンバー | パイロット実施店舗の店長5名 |
以下のようなプロセスで進めました。
| フェーズ | 期間 | 主な内容 | 詳細・補足 |
|---|---|---|---|
| Phase 1: データ整備と階層構造の定義 | 2ヶ月 |
|
|
| Phase 2: モデル選定と実装 | 2ヶ月 |
|
|
| Phase 3: パイロット実施と検証 | 1ヶ月 |
|
|
| Phase 4: 本格導入と運用体制構築 | 1ヶ月 |
|
|
導入した予測モデル
A社の採用した階層型時系列予測モデルは、次のような最適組み合わせ(Optimal Combination)アプローチです。
- 各階層レベルで独立に予測モデルを構築
- それらの予測値を階層構造の制約下で整合的に調整
- 調整には線形回帰に基づく統計的手法を使用
階層構造を表す行列
ここで、htsパッケージのドキュメントを読んでみてください。
| 分類 | 文献・リソース | 内容・ポイント |
|---|---|---|
| 基本理論 | Hyndman, R. J., Ahmed, R. A., Athanasopoulos, G., & Shang, H. L. (2011), “Optimal combination forecasts for hierarchical time series.” Computational Statistics & Data Analysis, 55(9), 2579-2589. | 階層型時系列の最適組み合わせ手法(OLS、WLS)を提案 |
| MinT理論 | Wickramasuriya, S. L., Athanasopoulos, G., & Hyndman, R. J. (2019),“Optimal forecast reconciliation for hierarchical and grouped time series through trace minimization.” Journal of the American Statistical Association, 114(526), 804-819. | MinT(最小トレース)による予測精度の分散最小化アプローチ |
| 実装 | Rパッケージ hts ドキュメント(https://cran.r-project.org/web/packages/hts/hts.pdf) |
htsパッケージでのOptimal Combination実装方法(method指定など) |
R言語のhtsパッケージとforecastパッケージを組み合わせて実装しました。
単に、htsパッケージを使って構築したわけではなく、次のような工夫をしています。
- 地域特性を反映するための特徴量エンジニアリング
- 地域イベントカレンダーの統合
- 気象データと売上の関係性モデリング
- 店舗周辺の競合状況の定量化
- 商品の季節性パターンのクラスタリングによる類似商品グループの特定
- 新商品予測のための類似商品ベースの転移学習手法の開発
A社がMicrosoftのOffice 365を導入していたということもあり、予測結果と実績の可視化はPower BIのダッシュボードを活用しました。
導入効果
A社は階層型時系列モデルの導入から6ヶ月後、以下のような成果を達成しました。
| 分類 | 指標・効果 | 詳細・結果 |
|---|---|---|
| 予測精度の向上 |
全社売上予測誤差(MAPE) | 従来8.5% → 3.2%へ改善 |
| 店舗売上予測誤差(MAPE) | 従来15.3% → 6.7%へ改善 | |
| カテゴリ売上予測誤差(MAPE) | 従来18.7% → 9.1%へ改善 | |
| 季節商品カテゴリ例 | アイスクリームの予測誤差22% → 7%へ改善 | |
| 在庫・物流の最適化 |
在庫コスト | 前年同期比17.5%削減(約15億円削減) |
| 欠品率 | 3.8% → 1.2%へ改善 | |
| 廃棄ロス(生鮮食品) | 前年同期比25%削減 | |
| 配送効率(積載率) | 平均12%向上 | |
| 業務効率と組織改善 |
予測関連業務工数 | 全社で約30%削減(月間約2,000時間) |
| 店長の計画策定時間 | 週4時間 → 週1.5時間に削減 | |
| 本部・店舗間コミュニケーション | 共通予測データに基づく議論が可能に | |
| データドリブン文化醸成 | KPI設定・業績評価の客観性向上 | |
| 財務インパクト |
粗利益率 | 前年同期比1.2ポイント向上 |
| キャッシュフロー改善 | 運転資金約20億円圧縮 | |
| 投資回収期間 | 約4ヶ月で回収(投資額約1億円) |
導入における課題と対応策
A社がプロジェクト推進中に直面した主な課題と、その対応策は以下の通りです。
| 分類 | 課題 | 対応策 |
|---|---|---|
| データ品質の問題 | 店舗ごとのデータ入力品質にばらつきがあり、一部欠損や異常値が多数発見された | データクレンジング自動化スクリプトの開発、店舗担当者向けデータ品質管理トレーニング実施 |
| 組織の抵抗 | 店長・地域マネージャーが「数字より経験」を重視し、新手法への抵抗があった | パイロット店舗の成功事例可視化、現場の声を交えた社内発表会開催、ハイブリッドアプローチ採用 |
| 技術的複雑さ | 高度な統計モデルを維持・発展できる専門人材が不足 | IT部門内にデータサイエンスチーム新設、外部研修と社内育成プログラムを並行実施 |
階層型時系列モデルの導入を検討される方へ
このような階層型の時系列予測モデルを導入する企業は増えています。
ただし幾つかの注意点があります。
階層型時系列モデル導入を検討する際、以下のようなことに気を付けるといいでしょう。
| 分類 | ポイント | 詳細 |
|---|---|---|
| 段階的アプローチの重要性 | パイロット導入から成功体験を積み上げる | データ品質向上、モデル構築、組織浸透を段階的に管理 |
| 技術と業務の融合 | 現場知見をモデルに取り込む仕組みが成功の鍵 | データサイエンティストとビジネス側をつなぐ「翻訳者」役割が重要 |
| 継続的な改善サイクル | 定期的な予測精度評価と改善が必須 | モデルの再調整・追加学習の仕組みを構築 |
| 全社的なデータ文化の醸成 | トップマネジメントのコミットメントが重要 | 予測結果の可視化と成功事例共有でデータドリブン文化を促進 |
階層型時系列モデルは決して難解な技術ではなく、ビジネスにおける予測の質を高め、より効果的な意思決定を支援するための実用的なアプローチです。
小さくはじめ大きくすることが重要です。
今回のまとめ
今回は、「階層型時系列モデルで実現するビジネス予測の高度化」というお話しをしました。
階層型時系列モデルは、企業活動における様々な階層レベルで整合性のあるデータ予測を実現する強力なアプローチです。
階層型時系列モデルの主な利点です。
- 階層間の整合性確保: 全社から部門、製品、地域など様々なレベルで矛盾のない予測が可能
- 予測精度の向上: 階層間の情報を活用することで、単独のモデルよりも精度が向上する場合が多い
- 効率的な意思決定: 組織の各レベルで共通の予測に基づいた意思決定が可能になる
階層型時系列モデルの分野は、技術の進化とともに今後さらなる発展が期待されます。
- 高度なAI・機械学習の活用: ディープラーニングなどの先進的手法を階層モデルに取り入れることで、より複雑なパターンの把握が可能に
- リアルタイムデータ処理との統合: IoTやセンサーデータなどのリアルタイムデータを取り込み、階層予測をよりダイナミックに更新する手法の発展
- 因果推論との融合: 単なる予測だけでなく、「なぜその予測結果になるのか」の因果関係を解明する手法との融合
- 不確実性のより精緻な評価: ベイズモデリングの発展により、予測の確信度や信頼区間をより正確に評価できるようになる
とは言え、時系列予測モデルを作ったことも活用したこともない…… という方は、まずは階層型にこだわらず、無階層型の時系列予測モデル構築をチャレンジしてみてください。