
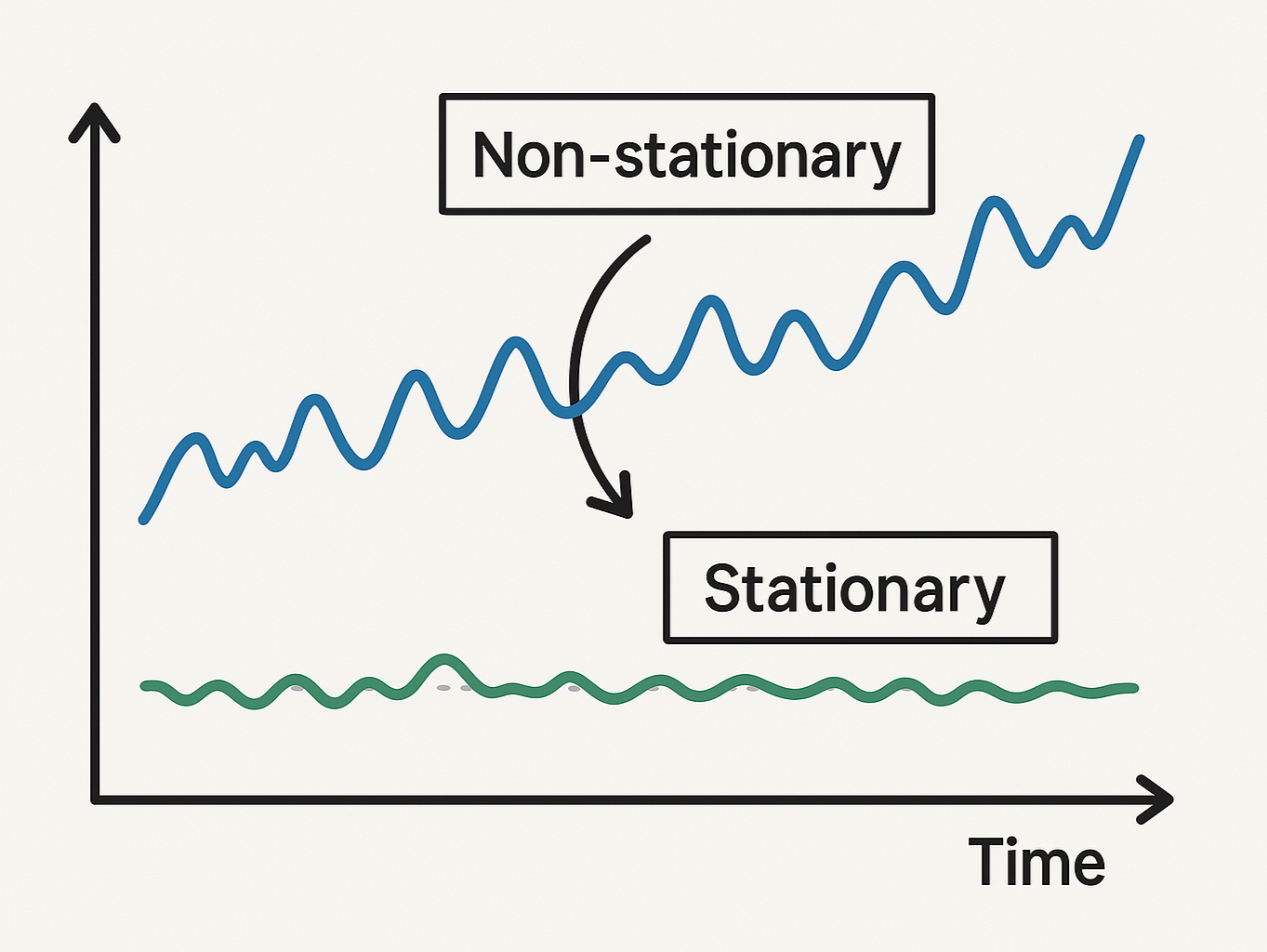
時系列データを分析したり時系列予測をする上で、私たちはしばしば「定常性」という概念に直面します。
定常性とは、簡単に言えば、時系列データの統計的性質が時間によって変化しないという性質です。
なぜこの性質が重要かというと、多くの時系列モデルや予測手法は、データが定常であることを前提としているからです。
時系列分析の世界では、データが非定常である場合、そのままでは従来の統計手法が適用できず、予測の精度も低下してしまいます。
株価の推移、気温の変動、企業の売上高など、私たちが日常的に扱う多くの時系列データは本来非定常です。
そのため、データを定常化するテクニックを身につけることは、時系列分析の基礎として欠かせないスキルとなります。
今回は、定常性の概念、Wold(ウォールド)分解定理、非定常成分、定常化手法、ARIMA(自己回帰和分移動平均)モデルなどの予測モデルへどうつなげていくかを、できるだけ簡単かつ簡易的にお話しします。
Contents [hide]
定常性とは何か
定常性の定義
時系列分析において「定常性」とは、時系列データの統計的性質が時間の経過によって変化しないという性質を指します。
厳密には「弱定常性(weak stationarity)」と「強定常性(strict stationarity)」の2種類がありますが、実践的な時系列分析では通常、弱定常性を指して「定常」と呼びます。
弱定常過程は、次の表に示す3つの条件を満たす時系列を指します。
| 条件 | 説明 |
|---|---|
| 平均が一定 | 時間によらず、常に同じ期待値を持つ |
| 分散が一定 | 時間によらず、データのばらつきが一定 |
| 自己共分散が時間差のみに依存 | 時系列データの2点間の共分散が、その時点間の距離(ラグ)のみに依存し、具体的な時点に依存しない |
これらの条件は、時系列が「安定した」状態であることを意味します。
なぜ定常性が重要かというと、多くの統計的手法や時系列モデルは定常過程を前提としているからです。
Wold(ウォールド)分解定理
定常時系列の理論的基礎として特に重要なのが「Wold(ウォールド)分解定理」です。
この定理は、任意の定常過程が以下の2つの部分に分解できることを示しています。
- 予測可能な部分:過去の情報から線形的に予測できる成分
- 予測不可能な部分:白色雑音(ホワイトノイズ)に相当する純粋にランダムな成分
数学的には、定常過程
ここで、
この定理は非常に重要で、ARMAモデル(自己回帰移動平均モデル)の理論的基礎となっています。
ARMAモデルは本質的に、Wold(ウォールド)分解定理が示す線形構造を有限次元で近似したものと考えることができます。
簡単に言えば、定常時系列は過去の情報に基づく予測可能な部分と、新たなショックや予測不可能なランダム変動から成り立っていると理解できます。
このような性質があるからこそ、時系列モデルによる将来予測が可能になるのです。
定常かどうかを判断する方法
時系列データが定常かどうかを判断するには、定性的な方法と定量的な方法があります。
グラフによる定性的な判断
グラフを使った視覚的な判断は、定常性の初期評価として非常に有用です。
主な方法を以下の表にまとめました。
| グラフ分析手法 | 判断のポイント | 定常過程の特徴 | 非定常過程の特徴 |
|---|---|---|---|
| 時系列プロット |
|
|
|
| 自己相関関数(ACF) |
|
|
|
| 偏自己相関関数(PACF) |
|
|
|
これらのグラフ分析ツールを併用することで、時系列データの特性をより包括的に理解できます。
例えば、ランダムウォークのような時系列のACFは非常にゆっくりと減衰します。
一方、定常なAR(1)プロセス(1期前のデータのみから若干の影響を受ける)のACFは指数関数的に減衰し、PACFはラグ1で急激に切断されます。
実務では、まず時系列プロットで全体像を把握し、次にACF/PACFでデータの相関構造を分析するという、段階的アプローチで実施されることが多いです。
ただし、グラフによる判断は主観的な側面があるため、次に説明する統計的検定と併用することで、より信頼性の高い判断ができます。
統計検定による定量的な判断
より厳密に定常性を評価するには、統計的検定が有効です。幾つかの手法が開発されています。
以下は主な手法です。
| 検定手法 | 帰無仮説 | 対立仮説 | 判断基準 | 特徴と留意点 |
|---|---|---|---|---|
| 拡張ディッキー・フラー (ADF)検定 |
単位根が存在する (非定常) |
単位根が存在しない (定常) |
p値 < 0.05 で定常と判断 |
|
| フィリップス・ペロン (PP)検定 |
単位根が存在する (非定常) |
単位根が存在しない (定常) |
p値 < 0.05 で定常と判断 |
|
| KPSS検定 | データは定常である | データは非定常である | p値 > 0.05 で定常と判断 |
|
これらの検定は相互補完的な関係にあり、単独ではなく複数の検定を組み合わせて使用することが推奨されます。
| 検定結果の組み合わせ | 判断 | 解釈と次のステップ |
|---|---|---|
| ADF検定:有意(p < 0.05) KPSS検定:非有意(p > 0.05) |
データは定常 |
|
| ADF検定:非有意 KPSS検定:有意 |
データは非定常 |
|
| 両方とも有意 | 結果が矛盾 |
|
| 両方とも非有意 | 結果が矛盾 |
|
検定結果が矛盾する場合は、データ特性をより詳細に分析する必要があります。
例えば、構造変化がある時系列では単一の検定結果が誤解を招く可能性があります。
また、検定の検出力は標本サイズに大きく依存するため、小サンプルでの結果解釈には特に注意が必要です。
定常性の評価プロセスのまとめ
ここまでの内容をもとに、定常性の評価プロセスと判断基準を整理すると、次のようになります。
| プロセスのステップ | 内容と方法 | 注意点 |
|---|---|---|
| グラフによる初期評価 |
|
視覚的判断は主観的要素を含むため、統計的検定で補完することが重要 |
| 統計的検定の実施 |
|
検定の前提条件や特性を考慮し、適切な検定仕様(ラグ次数など)を選択する |
| 矛盾する結果の解釈 |
|
検定の検出力やサンプルサイズの影響を考慮する必要がある |
実務では、統計的検定の結果に過度に依存するのではなく、グラフ分析と統計的検定の結果を総合的に判断し、モデルの目的(予測か説明か)に応じて適切な定常化アプローチを選択することが重要です。
非定常成分の具体例とモデル化
実際の時系列データでは、多くの場合、定常性を妨げる要素が含まれています。
ここでは、代表的な非定常成分とそのモデル化について解説します。
トレンドがあるケース
トレンドとは、時間の経過とともにデータの平均水準が一定方向に変化する傾向を指します。
トレンドがある場合、時系列の平均値は時間とともに変化するため、定常性の条件に反します。
トレンドには主に以下の表に示すようなタイプがあります。
| トレンドの種類 | サブタイプ | 数学的表現 | 説明 |
|---|---|---|---|
| 確定的トレンド | 線形トレンド | 時間 |
|
| 二次トレンド | 時間 |
||
| 確率的トレンド | ランダムウォーク | 前期の値にランダムなショックが加わる形で変動 | |
| ドリフト付きランダムウォーク | ランダムウォークに一定のドリフト |
||
| ローカルレベルモデル | 観測不可能な状態 |
確定的トレンドと確率的トレンドの大きな違いは、ショックの永続性にあります。
確定的トレンドでは、ショック
この違いは、トレンド除去の方法選択に重要な影響を与えます。
経済指標や株価など多くの実際のデータには、このようなトレンド成分が含まれています。
例えば、GDPや人口の長期的な増加傾向は確定的トレンドとして、株価の変動はランダムウォークとしてモデル化されることがあります。
季節性があるケース
季節性とは、一定の周期で繰り返し現れるパターンのことです。
例えば、小売業の売上高には年末に向けて増加し、年明けに減少するという季節パターンが見られることがよくあります。
季節性の主な特徴とモデル化方法は以下の通りです。
| モデルタイプ | 説明 | 数学的表現/特徴 |
|---|---|---|
| 確定的季節性 | 季節ダミー変数を用いた回帰モデル | ( |
| 確率的季節性 | 季節ARIMAモデル(SARIMA)による表現 | 季節周期 |
確定的季節性と確率的季節性の選択は、季節パターンの安定性に依存します。
季節パターンが時間を通じて安定している場合は確定的季節性モデルが適しており、季節パターン自体が変化する場合は確率的季節性モデルが有効です。
例えば、月次データの季節性は以下のようにモデル化できます。
ここで
主な定常化手法(非定常を定常にする手法)
データに含まれるトレンドや季節性などの非定常成分を扱い、非定常データから定常データに変換するための、非定常化手法が幾つかあります。
主な手法をまとめると、以下となります。
| 非定常成分 | 手法 | 内容 | 数学的表現/特徴 |
|---|---|---|---|
| トレンド除去 | 差分法 | 連続する観測値の差を取る | 1階差分: |
| 回帰法 | 時間 |
( |
|
| 季節調整 | 季節差分 | 前年同期との差を取る | 季節差分: ( |
| 季節ダミー変数 | 季節を表すダミー変数を用いた回帰モデル | 各季節期間に対応するダミー変数でモデル化 | |
| 季節分解法 | 専用の分解アルゴリズムを用いる | X-12-ARIMA、STLなど体系的な分解手法 |
これらの手法は単独でも使用できますが、多くの実際のデータでは複数の非定常成分(トレンドと季節性の両方)が存在するため、複数の手法を組み合わせて使用することが一般的です。
特に差分法は実装が容易で広く使われており、差分の次数を表すパラメータ
データの分散が一定でない場合(不均一分散)や、非線形の関係が見られる場合には、以下の表に示す変換法が効果的です。
| 変換法 | 数学的表現 | 適用対象 | 効果 |
|---|---|---|---|
| 対数変換 |
|
|
|
| 平方根変換 |
|
|
|
| ボックス・コックス変換 |
|
|
データから非定常と思われる成分を抽出するフィルタリング手法を以下の表にまとめました。
| フィルター名 | 主な機能 | 特徴と適用場面 |
|---|---|---|
| 移動平均フィルター | 短期的な変動を平滑化 |
|
| ホドリック・プレスコットフィルター(HP) | トレンド成分と循環成分を分離 |
|
| バンドパスフィルター(BP) | 特定の周期(周波数帯)の変動のみを抽出 |
|
| STL分解 (Seasonal and Trend decomposition using Loess) | トレンド成分・季節成分・残差成分への分解 |
|
| Baxter-Kingフィルター(BK) | 指定した周期帯域の景気循環を抽出 |
|
| Christiano-Fitzgeraldフィルター(CF) | 一般化されたバンドパスフィルター |
|
| LOESSフィルター (ローカル多項式回帰) | 局所的な平滑化によるトレンド抽出やノイズ除去 |
|
| カルマンフィルター (状態空間モデル) | 時間変化するトレンド・季節性・レベルを動的に推定 |
|
| EMD (Empirical Mode Decomposition) | データ駆動型で複数の固有モードを順次に分解 |
|
| ウェーブレット変換 | 周波数×時間軸の両面から局所的な特徴を抽出 |
|
以下の一覧表では、代表的なフィルタリング手法について、「どのような課題や目的に対してどれを選べばよいか」という視点で整理しました。
| 目的・課題 | 主な推奨フィルター | 特徴・注意点 |
|---|---|---|
| トレンドと周期成分を明確に分離したい 例:長期的な経済トレンドと循環成分を同時に把握したい |
|
|
| 変動の周波数帯を具体的に指定して抽出したい 例:2〜8年周期の景気循環だけを抽出して分析したい |
|
|
| 周期・周波数が固定的でない、あるいは明確でないケース 例:季節性や周期性が非線形的・非定常的に変化するデータ |
|
|
| 季節成分の変化が大きい、または外れ値・構造変化が頻繁に起こる 例:外れ値の多い小売データ、突発イベントがある時系列 |
|
|
| エンドポイント問題(端点付近の推定が不安定)への対策を重視したい 例:将来予測にも活用したいので端点推定精度を確保したい |
|
|
定常化後の注意点
定常化は時系列データ分析の重要なステップですが、いくつかの注意点があります。
| 注意点カテゴリ | 具体的な課題 | 対応策と考慮事項 |
|---|---|---|
| 過度な差分による情報損失 |
|
|
| モデル解釈への影響 |
|
|
| 定常化手法の選択 |
|
|
適切な定常化を行った後は、次に説明するARMAやARIMAといったモデルを適用したりします。
ARIMA系モデルとは
定常化されたデータに対して、時系列モデルを適用していきます。ここでは特に、ARIMA系モデルについて説明します。
ARIMA・SARIMAモデルの概要
ARIMA(自己回帰和分移動平均)モデルは、非定常時系列データを扱うための強力な考え方やモデリングなどのフレームワークです。
ARIMAモデルの構成要素
ARIMA(p,d,q)モデルは以下の表に示す3つのパラメータで特徴づけられます。
| パラメータ | 意味 | 数学的表現 | 役割 |
|---|---|---|---|
| p | 自己回帰(AR)項の次数 | 過去の値がどの程度現在の値に影響するかを表現 | |
| d | 差分の次数 | データを定常化するために必要な差分の回数を表現 (例: |
|
| q | 移動平均(MA)項の次数 | 過去のショック(誤差項)の影響の持続性を表現 |
ARIMAモデルの強みは、これら3つのパラメータを組み合わせることで、様々なタイプの時系列データに柔軟に対応できる点にあります。
実際のモデル構築では、まず適切な
つまり、ARIMAモデルは「定常部分のARMAモデル」と「差分操作による定常化」を組み合わせたものと言えます。
SARIMAモデルと季節性
季節性を持つデータには、SARIMA(季節性ARIMA)モデルが適しています。
SARIMA(p,d,q)(P,D,Q)
- P: 季節自己回帰項の次数
- D: 季節差分の次数
- Q: 季節移動平均項の次数
- s: 季節の周期(月次データなら12、四半期データなら4など)
このモデルは、短期的な依存性(通常のARIMA部分)と季節的な依存性(季節ARIMA部分)の両方を捉えることができます。
Wold(ウォールド)分解定理との関連性
Wold(ウォールド)分解定理は、ARIMA系モデルの理論的基礎となっています。
ARMAモデルは、Wold(ウォールド)分解定理が示す線形構造を有限次元で近似したものです。
| 分解要素 | モデル | 説明 |
|---|---|---|
| 予測可能な部分 | ARモデル | 過去の観測値の線形結合として、現在の値を予測する |
| 予測不可能な部分(ショック) | MAモデル | 過去のショック(予測誤差)が、現在の値に与える影響を表現する |
ARIMA(p,d,q)モデルでは、原系列に
これは、非定常成分を除去した後の「コア」となる定常過程をモデル化する方法と言えます。
モデル選択と診断
適切なARIMAモデルを選択するためのプロセスを簡単に説明します。
モデル選択のステップ
ARIMAモデルの構築と選択は、以下の表に示す段階的なプロセスで行われます:
| ステップ | 内容 | 方法 | 評価基準 |
|---|---|---|---|
| 差分次数(d)の決定 | 定常化に必要な差分次数を特定 |
|
|
| AR次数(p)とMA次数(q)の特定 | 定常化されたデータに最適なARMA構造を特定 |
|
|
| パラメータ推定 | モデルの係数を推定 |
|
|
季節性のあるデータを扱う場合は、季節差分次数(D)と季節AR/MA次数(P, Q)も同様のプロセスで決定します。
情報量規準(AICやBIC)は、モデルの適合度とパラメータ数(複雑さ)のバランスを評価するための重要な指標です。
一般にBICはAICよりもより単純なモデルを選択する傾向があり、大規模サンプルで一貫性のある結果が得られますが、小サンプルではAICの方が予測精度の観点から優れていることがあります。
実務では、両方の規準を計算し、モデルの用途(予測か説明か)に応じて適切に判断するのがいいでしょう。
モデル診断
ARIMAモデルによる適合が上手くいったかの評価するための診断項目を以下の表にまとめました。
| 診断手法 | 評価基準 | 目的 | |
|---|---|---|---|
| 残差分析 |
|
|
モデルが時系列の構造を適切に捉えているかを確認 |
| 予測精度の評価 |
|
|
モデルの予測能力を評価し、最適なモデルを選択 |
残差分析は特に重要で、残差が白色雑音(ランダムで自己相関がない)でなければ、モデルは時系列の構造を完全に捉えきれていないことを意味します。
Ljung-Box検定のp値が有意水準(通常0.05)を上回っていれば、残差に自己相関がないという帰無仮説が棄却されず、モデルが適切であると判断できます。
予測精度の評価では、複数のモデルを比較して最も精度の高いモデルを選択します。
特に時系列データでは、単純な訓練/テスト分割よりも、時間の経過を考慮した時系列クロスバリデーションがいいでしょう。
これにより、モデルの頑健性と将来データに対する一般化能力をより適切に評価できます。
適切なモデルが選択できたら、そのモデルを用いて将来予測を行うことができます。
ARIMAモデルは、短期・中期の予測において特に有効です。
ちょっと上を目指したい方へ
時系列分析を、さらっと学ぶための参考資料を以下の表にまとめました。
| 資料カテゴリ | 著者・タイトル | 特徴と推奨ポイント |
|---|---|---|
| 専門書・教科書 | Box, G.E.P., Jenkins, G.M., Reinsel, G.C., & Ljung, G.M. (2015). Time Series Analysis: Forecasting and Control. Wiley. PDF link |
|
| Brockwell, P.J., & Davis, R.A. (2016). Introduction to Time Series and Forecasting. Springer. PDF link |
|
|
| 沖本竜義 (2010). 経済・ファイナンスデータの計量時系列分析. 朝倉書店. |
|
|
| オンラインリソース | Rob J. Hyndman and George Athanasopoulos, Forecasting: Principles and Practice. https://otexts.com/fpp3/ |
|
| Duke University, Forecasting in STATA https://people.duke.edu/~rnau/411home.htm |
|
|
| 実践的なツール | R言語のforecastパッケージ https://pkg.robjhyndman.com/forecast/ |
|
| Pythonのstatsmodels https://www.statsmodels.org/stable/tsa.html |
|
初心者には、Hyndmanらの「Forecasting: Principles and Practice」がウェブ上で無料アクセス可能で、実践的な例も豊富なため特におすすめです。
より理論的な深堀りをしたい場合は、Box-Jenkinsの古典的教科書が依然として最も包括的な参考書となります。
日本語の資料としては、沖本竜義氏の「経済・ファイナンスデータの計量時系列分析」が、特に経済・金融分野での応用に焦点を当てた詳細な解説書として優れています。
これらの資料を活用して、時系列分析の理解を深め、実践的なスキルを磨いていくことをお勧めします。
今回のまとめ
今回は、時系列分析における定常性の重要性とWold(ウォールド)分解定理、非定常なデータをどのように扱うかについて、簡単にお話ししました。
まず、データの平均や分散、自己共分散が時間によって変化しない定常性は、予測の根拠となる重要な性質であり、多くの時系列モデルがこれを前提としていることをお話ししました。
また、トレンドや季節性といった非定常成分を特定し、ADF検定やKPSS検定などの視覚的・統計的手法で評価してから、差分法や変換法によって除去することが予測精度の向上につながる点もお話ししました。
さらに、定常化されたデータに対してARMAやARIMA、SARIMAなどのモデルを適用することで、多様な時系列の特性に柔軟に対応できる方法もお話ししました。
時系列分析の基本的な手順としては……
- (1)データの視覚化と特性把握
- (2)定常性の評価
- (3)適切な定常化
- (4)モデル構築と検証
- (5)予測と解釈
……の流れを踏むのが一般的であり、それぞれの段階でデータの特性に合わせた前処理やモデル選択を行うことが、分析を成功に導く鍵となります。