

「明日の売上は?」
「人員は足りる?」
「在庫は何個追加すべき?」
ビジネスの現場では毎日、このような問いが絶え間なく飛び交います。
これまでは熟練メンバーの経験や勘で決める場面も多く、それ自体が強みでもありました。
しかし、データが蓄積され、外部環境がめまぐるしく変わる今、「なんとなく」では取りこぼす機会コストが急速に大きくなっています。
そこで登場するのが、時系列分析と数理最適化という2つの強力なツールです。
時系列分析は「未来を数字で予測する」望遠鏡のような役割を果たし、数理最適化は「限られた資源で最善手を選ぶ」羅針盤として機能します。
この2つを組み合わせることで、天気予報を見て傘を持つか決めるように、企業活動も「先を読んでから動く」サイクルを持てるようになります。
今回は、これらの専門的な手法を、難しい数式や専門用語を最小限に抑えながらお話しします。
読み終える頃には「自社でも小さく試してみよう」と思えるような、具体的な一歩を踏み出せる内容をお届できたらと思います。
Contents [hide]
- 時系列分析で「未来を読む」
- 時系列分析とは?
- 最初にデータを磨く
- 欠測補完
- 外れ値処理
- カレンダー特徴量の生成
- モデル選びは「三兄弟」から
- 移動平均・指数平滑系のモデル
- SARIMA/Prophet系のモデル
- 機械学習モデル
- シンプルなものから始めよう!
- 予測精度をどう評価するか
- MAPE
- RMSE
- 未来を一本の線ではなく「帯」で示す
- 小さく回すための確認事項
- 予測を最適化モデルへ橋渡しする
- ステップ 1:KPIと制約を言語化する
- ステップ 2:粒度と集計をそろえる
- ステップ 3:不確実性をシナリオに変換する
- ステップ 4:最適化前チェックリスト
- 数理最適化で「行動を決める」
- 数理最適化とは?
- 最適化アルゴリズム早見表
- 線形系計画法・非線形計画法
- 整数計画法
- 動的計画法
- モデル化から結果利用までの4ステップ
- ステップ1:モデル化
- ステップ2:データ結合
- ステップ3:ソルバー実行
- ステップ4:結果検証
- 不確実性を考慮したロバスト最適化
- 確率制約最適化
- 頑健(ロバスト)最適化
- シナリオ平均化
- 現実的な組み合わせ
- サイクル自動化:MLOps × OptOps
- パイプライン全体像を描く
- データ&特徴量レイヤー
- 予測モデル(MLOps)レイヤー
- 最適化モデル(OptOps)レイヤー
- デプロイ&オーケストレーションレイヤー
- デプロイ
- ブルーグリーンデプロイ
- シャドーデプロイ
- モニタリングとアラート設計
- ガバナンスと説明責任
- 事例紹介:カフェチェーンの在庫×シフト最適化
- 背景と課題
- データ概要と需要予測
- KPIと制約の整理
- 最適化モデル設計
- 結果とビジネスインパクト
- 振り返りと教訓
- よくある落とし穴と対策
- データ収集・前処理の落とし穴
- 予測モデルの落とし穴
- 整形・シナリオ化の落とし穴
- 最適化モデルの落とし穴
- 運用(MLOps/OptOps)の落とし穴
- ネクストステップ
- 取り急ぎ、持ち帰ってほしい3つの視点
- 予測は「帯」で語る
- 最適化は問題定義が8割
- 運用は「検知速度」が命
- スモールスタートのロードマップ
- フェーズ1:ビジネス課題の発見
- フェーズ2:プロトタイプモデルの構築とPoC
- フェーズ3:小規模なパイロット展開と改善
- フェーズ4:価値生産の継続
- フィードバックループを設計する
- 今回のまとめ
時系列分析で「未来を読む」
時系列分析とは?

レジを締めたあとに並ぶ日次売上の一覧を思い浮かべてください。
1行1日分、カレンダー順に並んだ列はそのまま時系列データです。
時系列分析で、この時間軸に沿ったデータをもとに、次の日、次の週、次の月の値を推し量ることができます。
なぜ推し量ることができるのでしょうか?
それは、ビジネスには繰り返しのパターンが存在するからです。
例えば、過去2年のクリスマス前に売上が必ず跳ね上がった事実を知っていれば、今年の同時期に仕入れを増やす判断がしやすくなります。
つまり、「繰り返し観測されたパターンは将来も再現されやすい」という直観を、統計的に裏づける作業が時系列分析なのです。
最初にデータを磨く
データ分析で最も重要な作業は、実は入力データの品質を整えることです。
どんなに優れたモデルも、質の悪いデータからは有用な結果を導き出せません。
主要な前処理作業には以下のようなものがあります。
欠測補完
まず欠測の補完です。
POS障害などで特定の日付のデータが欠けている場合、そのままにしておくとモデルが誤ってゼロを学習してしまいます。
これを防ぐため、周辺データの平均値や最頻値で埋めるなどの処理が必要です。
外れ値処理
次に外れ値の確認が重要です。
異常に高いピークや急激な落ち込みが見られる場合、それがセール効果なのか、単なる入力ミスなのかを区別する必要があります。
原因を特定し、適切な処理を施すことで、モデルの精度が大きく向上します。
カレンダー特徴量の生成
さらにカレンダー特徴量の追加も効果的です。
曜日、祝日、給料日などの情報を列として追加することで、モデルが季節性や周期性をより良く捉えられるようになります。
モデル選びは「三兄弟」から
時系列分析には様々なモデルが存在しますが、実務では以下の「三兄弟」から選ぶのが効果的です。
移動平均・指数平滑系のモデル
最もシンプルなのが移動平均・指数平滑モデルです。
過去数日の平均を取るという基本的な手法で、Excelでも10分程度で実装できます。
変動が小さく、直近の値が最も参考になるようなデータに向いています。
例えば、安定した需要のある日用品の売上予測などに適しています。
SARIMA/Prophet系のモデル
次に、季節性を考慮したSARIMA/Prophetモデルがあります。
月次や曜日など、決まったリズムがあるデータに最適で、Pythonで30分程度で実装可能です。
コンビニの曜日別来客数や、季節商品の販売予測などに威力を発揮します。
外部要因も組み込むことができます。
機械学習モデル
最も手間のかかるのが機械学習モデル(LightGBMやLSTMなど)です。
時系列のためだけに作られたモデルでないため、ちょっと工夫が必要になります。
ただ、店舗、価格、天気など多数の要因を同時に扱える強力な手法で、最も高い精度が期待できます。
ただし、実装には1〜2時間程度かかり、チューニングにも専門知識が必要です。
シンプルなものから始めよう!
重要なのは、最初から複雑なモデルを狙うのではなく、シンプルな移動平均などから始めて段階的に高度なモデルへ移行するアプローチです。
まず移動平均で80点を確保し、必要に応じてSARIMAや機械学習へと深掘りすることで、効率的にモデル開発を進められます。
移動平均などのシンプルなモデルがベンチマークとなります。
SARIMA×機械学習や、時系列状態空間モデル、時系列トランスフォーマーなど、より高度なモデルもあります。
予測精度をどう評価するか
予測の当たり外れを測るには、適切な指標の選択が欠かせません。
ビジネス現場でよく使われる2つの代表的な指標を理解しておきましょう。
MAPE
MAPE(平均絶対パーセント誤差)は、実績と予測の差を実績値で割った平均です。
需要予測など「パーセント誤差」で語りたいときに最適です。
例えば、BtoCの日次需要であれば、MAPEが20%程度に収まると、在庫や人員計画に十分使えるケースが多いと言われます。
ただし、「許容できる誤差」は金額インパクトによって大きく変わることに注意が必要です。
100円の商品で20%の誤差と、100万円の商品で20%の誤差では、ビジネスへの影響が全く異なります。
RMSE
一方、RMSE(二乗平均平方根誤差)は、二乗誤差の平方根で、大きな外れ値を厳しく罰したいときに使用します。
高額商品の在庫管理など、大きな予測ミスのコストが特に高い場合に適しています。
未来を一本の線ではなく「帯」で示す
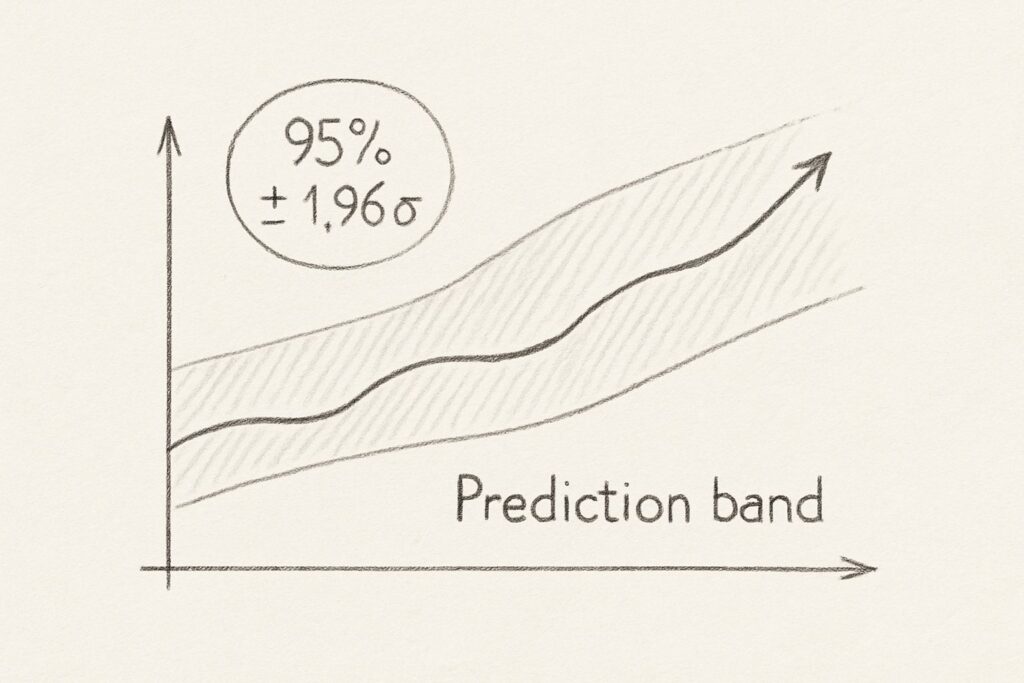
予測には必ずブレがあります。
そのため、平均値だけでなく「上下どこまでずれる可能性が高いか」を示す予測区間を算出することが重要です。
この情報は、最適化において、安全在庫や余剰シフトを決める際に非常に役立ちます。
簡易的な方法として、平均予測に対し過去誤差の標準偏差を1.96倍して上下に加減すれば、おおむね95%区間を得られます。
例えば、来週の需要予測が100個で、標準偏差が10個の場合、95%の確率で80.4個から119.6個の間に収まると予測できます。
小さく回すための確認事項
学んだ内容をすぐ現場で試せるよう、以下のチェックリストで準備状況を確認しましょう。
欠測値と外れ値を処理しましたか?
曜日・祝日などの特徴量を追加しましたか?
移動平均でベンチマーク精度を測定しましたか?
平均値に加え予測区間を保存しましたか?
予測を最適化モデルへ橋渡しする
時系列モデルが出力する予測値は、生のままでは単なる数字の羅列に過ぎません。
これらをビジネス実行に耐える「計画」へ昇華させるには、慎重な準備が必要です。
以下の4つのステップを踏むことで、予測結果を効果的な意思決定につなげることができます。
ステップ 1:KPIと制約を言語化する
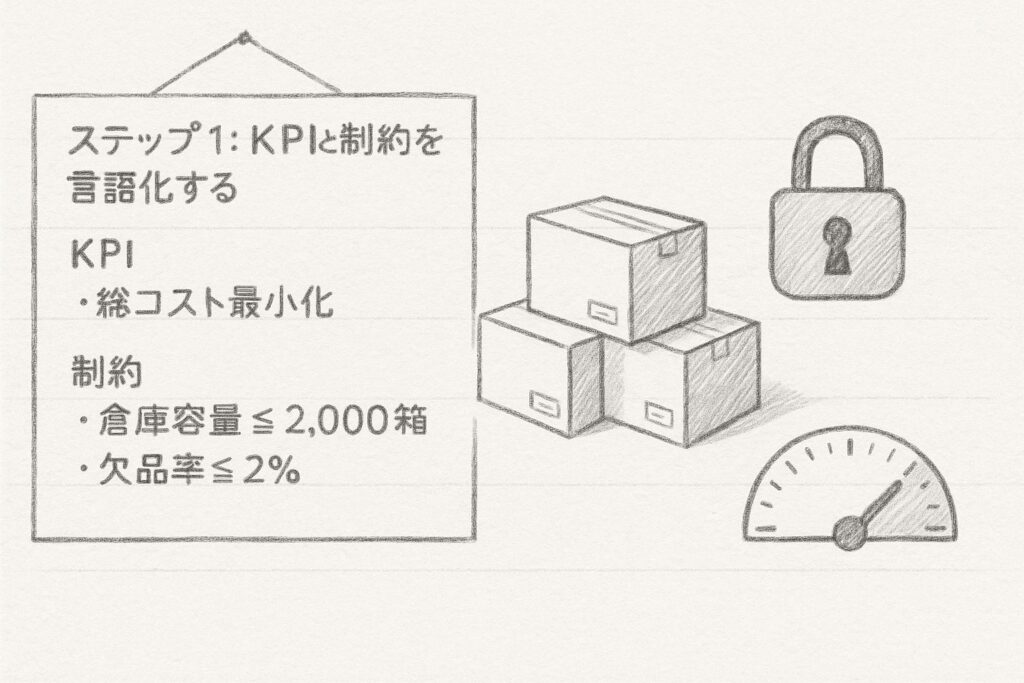
最適化モデルを作る第一歩は、組織が達成したい指標(KPI)と守るべき制約を明文化することです。
この作業は想像以上に重要で、プロジェクトの成否を左右します。
例えば在庫管理の場合、目的(KPI)は「総コスト最小化」となります。
これは仕入れコスト、保管コスト、欠品ペナルティの合計を最小にするという明確な目標です。
制約条件としては、「倉庫容量2,000箱以下」というハード制約(物理的な限界で絶対に守らなければならない)と、「欠品率2%以下」というソフト制約(多少の超過は許容できるが、顧客満足度に影響する)があります。
特に重要なのは、ハード制約とソフト制約の区別を早い段階で明確にすることです。
この区別が曖昧だと、後々モデル設計で混乱が生じ、実用性の低い結果が出てしまう可能性があります。
ステップ 2:粒度と集計をそろえる
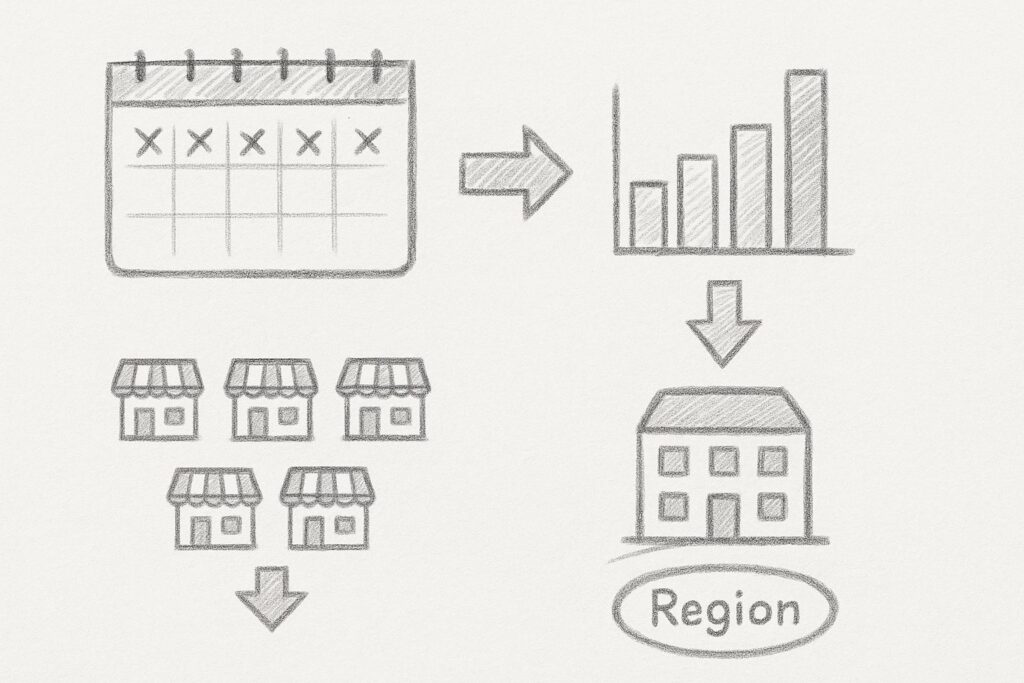
予測データと最適化モデルとでは、しばしば異なる粒度の情報を扱うことがあります。
そのような場合、この不一致を解消するためのデータ整形が必要になります。
よくあるケースとして、日次の予測データを週次の発注計画に使用する場合があります。
この場合、7日分の予測値を合計する必要があります。
また、店舗別の売上データをエリア別に集約する必要がある場合は、店舗コードなどでグループ化して合算します。
このような粒度変換は一見単純に見えますが、データの特性を考慮しないと精度が大きく損なわれることがあります。
例えば、単純な合計や平均ではなく、ピーク値や累積値を考慮する必要がある場合もあります。
ステップ 3:不確実性をシナリオに変換する
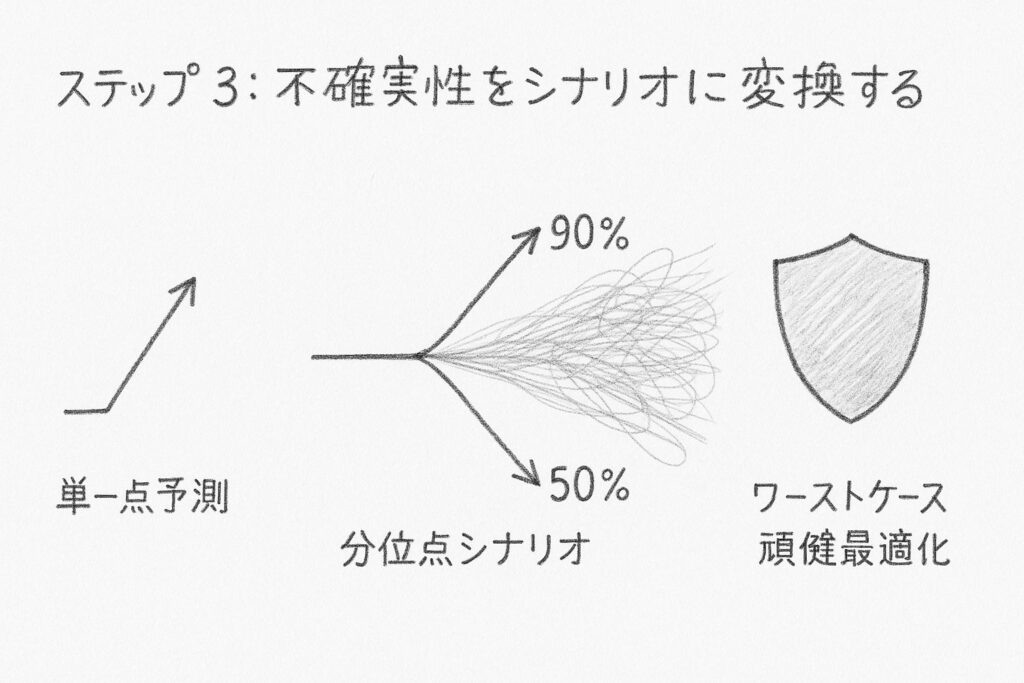
予測が外れることを前提に、複数の未来シナリオを描き、それぞれに対して最適化を行うことで、より頑健な施策を得ることができます。
最もシンプルなのは単一点予測(平均値のみ)を使う方法です。
計算が速く実装も容易ですが、予測が外れたときのリスクを考慮できません。
より現実的なアプローチは、分位点シナリオ(10パーセンタイル、50パーセンタイル、90パーセンタイル)を使う方法です。
これは上中下の3つのシナリオで未来を表現し、バランスの取れた計画を立てることができます。
さらに高度な手法として、モンテカルロ法があります。
数百から数千のシナリオを生成し、不確実性を滑らかに近似できますが、計算負荷が高くなります。
ワーストケース頑健最適化は、最悪の事態でも実行可能な解を保証しますが、解が保守的になりすぎる傾向があります。
ステップ 4:最適化前チェックリスト

整形とシナリオ化を終えたら、最適化問題を解く前に品質チェックを行います。
この段階での確認が不十分だと、最適化の結果が意味をなさなくなる可能性があります。
まず、外れ値の再検査を行います。
異常値が含まれていると、最適化が誤った方向に導かれる危険があります。Box PlotやIQR比を使用して、外れ値が5%以内に収まっているか確認します。
次に欠測値の確認です。
欠測セルが残っていると、制約式が壊れて最適化ソルバー(最適化を行うツール)がエラーを起こす可能性があります。必ず欠測数がゼロであることを確認します。
単位の整合性も重要なチェックポイントです。
KPIと制約で使用する単位が混在していると、モデルが意味をなしません。すべての数値をkgまたは箱に統一するなど、一貫性を確保します。
最後に、計算負荷の予測を行います。
問題サイズ(行数×列数)が大きすぎると、最適化ソルバーが時間内に解を見つけられない可能性があります。目安として、問題サイズが10^7を超えないようにします。
数理最適化で「行動を決める」
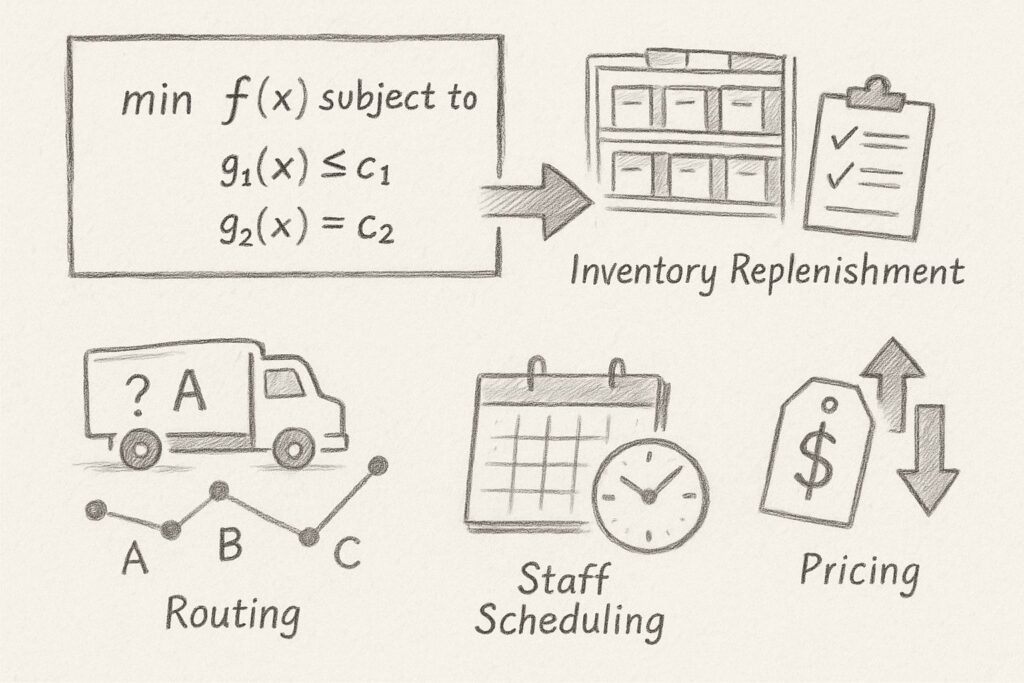
数理最適化とは?
数理最適化は、目的関数と制約条件を数式で表現し、その条件下で最良の解を探索する強力な方法論です。
わかりやすく言えば、「やりたいことを数式で書き切れば、あとはソフトウェアが最善手を見つけてくれる」という考え方です。
この手法は、ビジネスの様々な場面で活用されています。
在庫補充では「いつ、何を、どれだけ発注するか」を決定し、輸配送では最適なルートを選択します。
人員シフトでは限られた人員で最大のパフォーマンスを発揮できる配置を見つけ、価格設定では利益最大化と顧客満足度のバランスを取ります。
最適化アルゴリズム早見表
数理最適化には複数の解法ファミリーがあり、問題の性質に応じて適切な手法を選択する必要があります。
線形系計画法・非線形計画法
線形計画(LP)・非線形計画(NLP)は、連続値の最適化に適しています。
原料のブレンド比率や広告予算の配分など、量を決める問題に向いています。
GLPKのような無料ツールから、GurobiやCPLEXのような商用ソルバーまで、選択肢も豊富です。
整数計画法
整数計画(IP/MIP)は、0-1変数や個数を扱うのに最適です。
簡単にいうと、LPやNLPの変数の中に、整数値を取るものが混ざっている問題です。
シフト表の作成、発注量の決定、ルート選択など、「する/しない」や「何個」といった離散的な意思決定に使われます。
動的計画法
動的計画(DP)は、時系列の依存関係を考慮する必要がある問題に適しています。
在庫補充のタイミングや設備更新計画など、現在の決定が将来の選択肢に影響を与える場合に有効です。
実務的には、LP・NLPとMIPがビジネス最適化の8割を占めると言われています。
まずはこの2つをマスターすることで、多くの問題に対応できるようになります。
モデル化から結果利用までの4ステップ
最適化プロジェクトでは、数式を書く前後のプロセスが成功を左右します。
以下の4つのステップを着実に進めることが重要です。
ステップ1:モデル化
目的関数と制約を言葉やフローチャートで整理してから数式に変換します。
この作業は、ホワイトボードで関係者と一緒に行うと効果的です。
視覚的に共有することで、認識の齟齬を防ぎ、実務に即したモデルを作成できます。
ステップ2:データ結合
時系列予測モデルの出力である予測値をパラメータとして取り込みます。
この段階で時間粒度や単位の不一致に再度注意を払います。
よくある失敗として、日次データを週次モデルに直接入力してしまうケースがあります。
ステップ3:ソルバー実行
まずは無料のオープンソースの最適化ソルバーで試し、必要に応じて商用ソルバーへ移行します。
無料のオープンソースの最適化ソルバーには、RやPythonで実行できるものが多数あります。
最適化問題は、いきなり大規模な問題(変数やパラメータの数が多い)を解くのではなく、小規模な問題で試算を行い、計算時間と解の品質を確認することが重要です。
商用ソルバーは確かに高価ですが、計算速度や安定性の面で大きな差があります。
ステップ4:結果検証
KPIの達成度や制約の充足率を確認します。
数値だけでなく、結果をExcelに貼り付けて「人間の目」でも常識チェックを行うことが重要です。
ソルバーが返す数値は「数学的には最適」でも、現場で実行可能とは限りません。
不確実性を考慮したロバスト最適化
予測には必ず誤差が伴います。
この不確実性に対処するため、複数のアプローチが開発されています。
確率制約最適化
確率制約最適化は、「95%の確率で制約を満たす」という条件を数式に組み込む方法です。
直感的に理解しやすい反面、問題サイズが急増しやすいという課題があります。
頑健(ロバスト)最適化
頑健最適化(RO)は、予測誤差を区間で定義し、最悪のケースに備える手法です。
解釈が容易で計算も比較的高速ですが、解が保守的になりがちです。
シナリオ平均化
シナリオ平均化は、複数シナリオの目的関数を平均して最小化するシンプルな方法です。
実装は容易ですが、極端なシナリオへの耐性が弱いという欠点があります。
現実的な組み合わせ
実務では、「頑健最適化+シナリオ平均」のハイブリッドアプローチが増えています。
このアプローチにより、リスクとコストのバランスを取りながら、現実的な解を得ることができます。
サイクル自動化:MLOps × OptOps
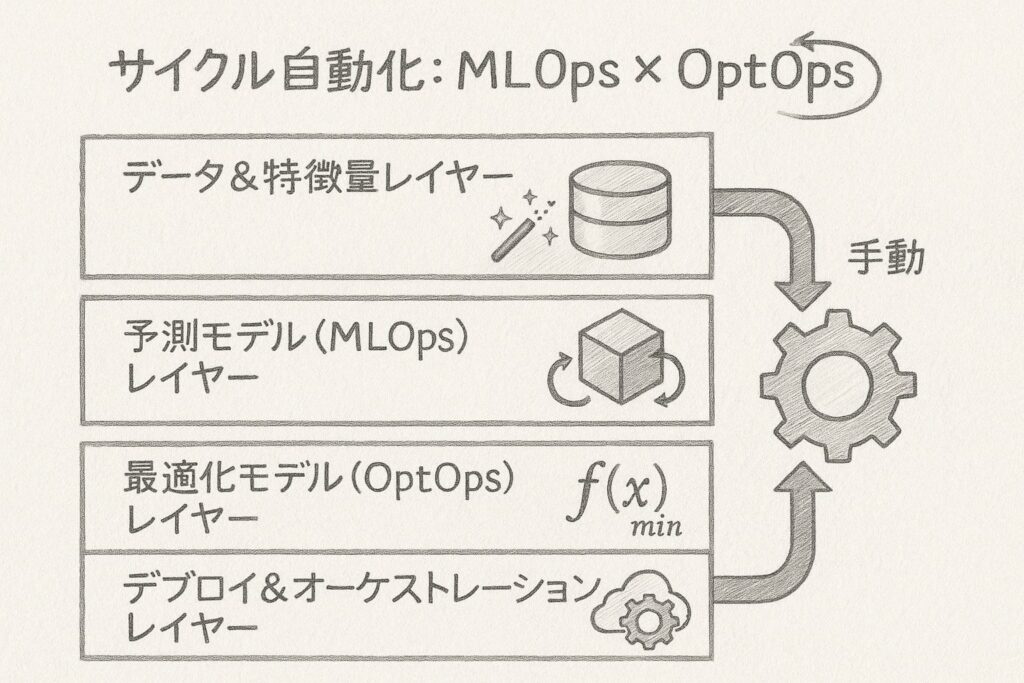
パイプライン全体像を描く
データ駆動型の意思決定を継続的に行うためには、データ取得から最適化までの一連の流れを自動化する必要があります。
このパイプラインを設計する際、最も重要なのは「変更が起きる場所」を特定し、それに応じて自動化と手動操作の境界線を引くことです。
パイプラインは、例えば大きく4つのレイヤーで構成されます。
データ&特徴量レイヤー
まずデータ&特徴量レイヤーでは、ローデータの取り込み、前処理、特徴量の生成を行います。
ここでは、例えばAirflowやPrefectといったスケジューラーを活用し、データの品質チェックを自動化します。
ただ、AirflowやPrefectなどのツールの導入は必須ではなく、そのような仕組みを整える、ということです。
予測モデル(MLOps)レイヤー
次に予測モデル(MLOps)レイヤーでは、モデルの学習、テスト、登録を管理します。
例えば、MLflowやVertex AIなどのツールを使用し、CI/CDパイプラインと再学習トリガーを設定します。
ただ、MLflowやVertex AIなどのツールの導入は必須ではなく、そのような仕組みを整える、ということです。
最適化モデル(OptOps)レイヤー
最適化モデル(OptOps)レイヤーは、予測結果を受け取り、最適な意思決定を導き出します。
パラメータの更新、制約の反映、ソルバーの実行を管理し、問題サイズの監視も行います。
デプロイ&オーケストレーションレイヤー
最後にデプロイ&オーケストレーションレイヤーで、API化やジョブスケジューリング、A/Bテストの切り替えを管理します。
例えば、DockerやKubernetesを活用し、柔軟な運用を実現します。
ただ、DockerやKubernetesなどのツールの導入は必須ではなく、そのような仕組みを整える、ということです。
デプロイ
モデルを更新する際の切替戦略には、主に2つのパターンがあります。
ブルーグリーンデプロイ
ブルーグリーンデプロイは、旧環境(Blue)と新環境(Green)を並列に運用し、準備が整ったら一気に切り替える方法です。
切り替え後にロールバックが容易という大きな利点がありますが、一時的にリソースが倍必要になるというデメリットもあります。
日次バッチで実行される発注最適化APIなど、定期的に実行されるシステムに適しています。
シャドーデプロイ
シャドーデプロイは、新モデルを本番と同じデータで非公開実行し、結果を比較検証する方法です。
実際のKPIに影響を与えずにA/Bテストが可能という利点がありますが、データ転送とストレージのコストが増加します。
リアルタイム価格最適化の試験運用など、慎重な検証が必要な場面で活用されます。
モニタリングとアラート設計
運用開始後、最も重要なのは「劣化に気づく速度」です。
モデルの品質低下を早期に検知し、迅速に対応することが、システムの信頼性を維持する鍵となります。
予測モデルについては、精度指標(MAPE、RMSE)を継続的に監視します。
例えば、直近7日の移動平均MAPEが過去60日平均の1.2倍を超えた場合にアラートを発報します。
また、データ分布の変化(ドリフト)も重要な監視対象です。
KS距離やPSI(Population Stability Index)を使用し、PSIが0.2を超えたら注意、0.3を超えたら自動再学習を行うといったルールを設定します。
最適化モデルでは、計算時間と実行可能解率を監視します。
ソルバーの実行時間の95パーセンタイルが基準値の1.5倍を超えた場合や、実行可能解率が98%を下回った場合にアラートを出します。
ガバナンスと説明責任
モデルによる意思決定の自動化が進むほど、「なぜその結果になったのか」を説明できる体制の重要性が増します。
バージョン管理は最も基本的かつ重要な要素です。
学習データ、コード、制約ファイルのハッシュ値を紐付けて管理することで、いつ、誰が、何を変更したかを追跡可能にします。
審査フローの確立も欠かせません。
モデル更新前にレビューと承認のステップを設けることで、リスクの事前検知とヒューマンチェックを実現します。
シミュレーションログの保存も重要です。
更新版モデルで過去期間を再現シミュレーションし、KPIの変化を定量的に把握することで、説明材料を確保します。
さらに監査証跡として、APIの呼び出しと出力を時刻・ユーザー情報とともに保存することで、外部監査や説明責任の要求に備えます。
これらの仕組みを整えることで、データ駆動サイクルは「作って終わり」ではなく、「回して改善する」持続可能なシステムへと進化します。
事例紹介:カフェチェーンの在庫×シフト最適化
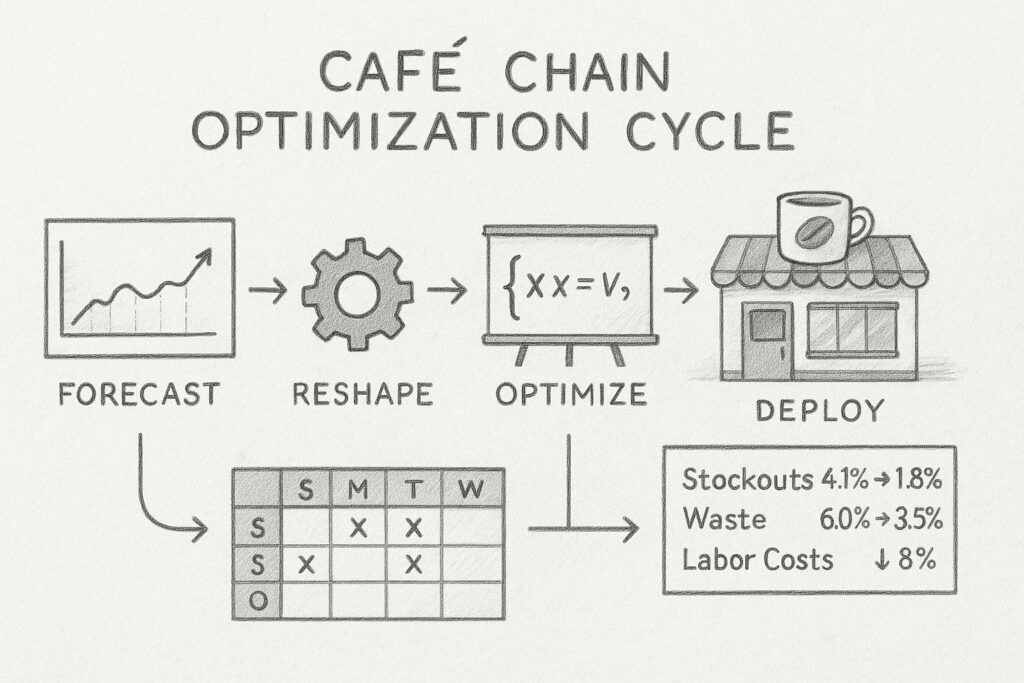
これまでにお話しした「予測→整形→最適化→運用」のサイクルを、具体的な事例を通じて理解を深めていきます。
50店舗を展開するカフェチェーンです。
背景と課題
このカフェチェーンは、2つの深刻な問題を抱えていました。
週末やイベント日にはドリンクが欠品し、販売機会を逃してしまう一方で、平日のアイドルタイムには人員が余り気味で人件費効率が低下していました。
さらに問題を複雑にしていたのが、発注量とシフトの決定が各店長の経験と勘に依存していたことです。
ノウハウが店舗ごとに属人化し、ベストプラクティスの共有が困難な状況でした。
この状況を「需要の波に合わせた在庫と人員の同期が取れていない」と整理し、予測と最適化の導入による解決を図ることにしました。
データ概要と需要予測
プロジェクトの第一歩として、過去2年間のデータを収集・整理しました。
POSシステムから日次×店舗×商品別の売上データを抽出し、気象データAPIから最高気温と降水確率のデータを取得しました。
さらに、イベント情報としてプロモーションフラグと祝日フラグを手動で追加しました。
予測モデルにはProphetを選択しました。
このモデルは、曜日や月次の季節性を自動的に検出し、イベント効果も考慮できる柔軟性を持っています。
結果として、テスト期間でMAPE 8%という許容範囲内の精度を達成できました。
また、95%予測区間も併せて保存し、後述するロバスト最適化のシナリオとして活用しました。
KPIと制約の整理
次に、ビジネス上の目標と制約を明文化しました。
目的関数は「欠品コスト+廃棄コスト+人件費」の総和を最小化することと定めました。
制約条件については、ハード制約とソフト制約を明確に区別しました。
ハード制約には……
- 物理的な限界である「冷蔵300L/常温500L以内」の在庫容量制限
- 労働基準法の「週40時間/人を超えない」という条件
- 「早番・遅番とも最少2名」というサービス品質維持のための人員配置
……を設定しました。
ソフト制約としては……
- 「欠品率2%以下」
……を設定し、これをペナルティ関数として組み込みました。
これにより、完全な欠品ゼロを目指すのではなく、コストとサービスレベルのバランスを取ることが可能になりました。
最適化モデル設計
最適化モデルの構築では、決定変数として「発注量[店舗、SKU、日付]」と「シフト人員[店舗、日付、シフト種別]」を定義しました。
目的関数は前述のKPIのコスト総和を線形化して表現しました。
制約条件には、在庫容量、需要充足、シフト人数、労働時間、発注ロットなどを設定しました。
解法には混合整数計画(MIP)を採用し、商用ソルバーのGurobi 10.0を使用しました。
ロバスト性を確保するため、予測のp50(中央値、50パーセンタイル)とp90(90パーセンタイル)の2つのシナリオを組み込み、p90シナリオでも欠品率が2%以内に収まるような制約を追加しました。
結果として、全50店舗×7日×30SKUの問題でも、約45秒で解を得ることができました。
結果とビジネスインパクト
最適化導入の効果は顕著でした。欠品率は4.1%から1.8%へと2.3ポイント改善し、廃棄率も6.0%から3.5%へと2.5ポイント減少しました。
人件費は週あたり7.4百万円から6.8百万円へと8%削減され、総コストは10.4%の削減を実現しました。
これらの数値改善以上に重要だったのは、意思決定プロセスの標準化と透明化が実現したことです。
店長間のスキル差による店舗間格差が縮小し、新人店長でも一定以上の成果を出せるようになりました。
振り返りと教訓
プロジェクトを通じて得られた重要な教訓は3つあります。
第一に、安全在庫は特殊日に動的に設定する必要があることが分かりました。
予測誤差が大きいイベント日には、ロバスト制約を緩めて欠品リスクよりコスト増を許容した方が、結果的に総コストを抑制できました。
第二に、シフトと在庫は同時最適化が鍵となることが判明しました。
発注とシフトを別々に最適化すると、納品受け入れや棚補充が繁忙時間帯に重なり、人件費削減効果が半減してしまいました。
第三に、計算時間の壁は想像より低いことが分かりました。
50店舗×1週間のMIPでも1分以内で解が得られ、日次実行に十分耐えられました。
むしろ課題はデータ準備と検証フローに時間がかかる点にあり、この部分の自動化が次の課題となりました。
このケーススタディから分かるように、予測精度よりもKPIと制約の適切な言語化がプロジェクトの成否を分けます。
数理最適化は「正しい問題」さえ渡せば、高速に価値を生み出すことができるのです。
よくある落とし穴と対策
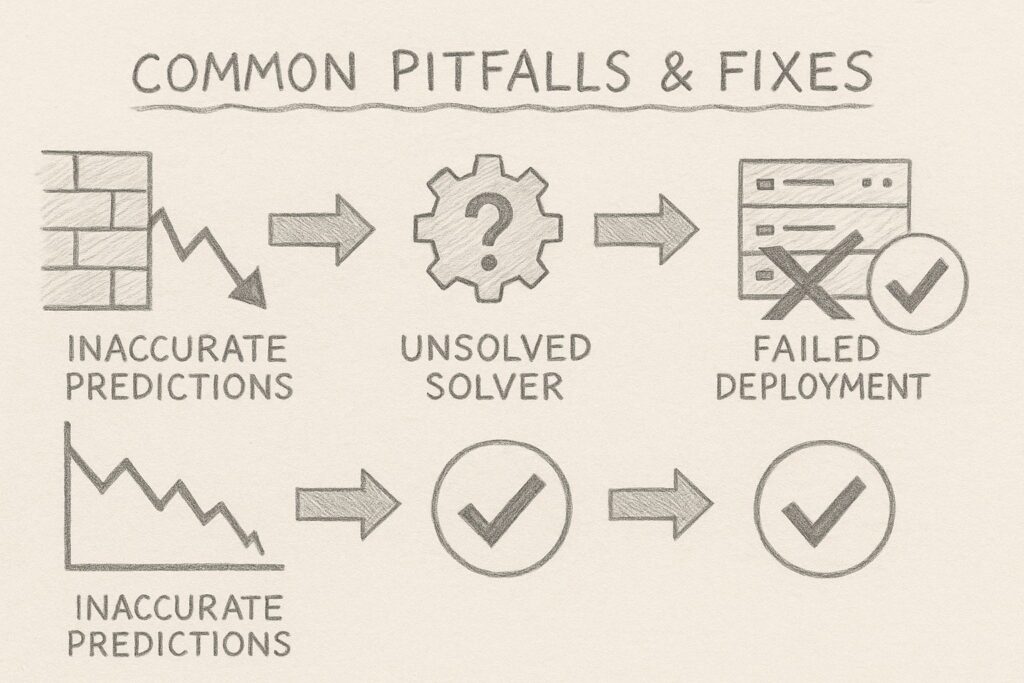
プロジェクトを進めていると、様々な障壁に直面します。
「予測が当たらない」「ソルバーが解けない」「運用に乗らない」といった問題は、多くの企業が経験する共通の課題です。
ここでは、よくある落とし穴とその対策を整理し、克服例を示します。
データ収集・前処理の落とし穴
データ関連で最も頻繁に遭遇する問題は、欠測や外れ値の見落としです。
これらは後になって発覚すると、精度が日によって乱高下する原因となります。
センサー障害や手入力ミスが主な原因ですが、対策として品質ゲートを設定し、日次で異常件数をアラートする仕組みを構築します。
外れ値についてはIQR(四分位範囲)ベースで自動フラグを立てることが効果的です。
もう一つの深刻な問題が特徴量リークです。
テスト期間で異様に高い精度が出た場合、未来の情報が学習データに混入している可能性があります。
これを防ぐには、時系列専用のクロスバリデーションを徹底し、未来のデータが混じらないように仕組みレベルでブロックする必要があります。
予測モデルの落とし穴
予測モデルでよく見られる失敗は、精度にこだわりすぎることです。
モデルの複雑化と学習コストの増大を招き、ビジネスへの影響を無視した改善競争に陥ってしまいます。
対策として、KPIインパクト試算表を作成し、「誤差○%→コスト△円」という形で可視化することが重要です。
さらに深刻なのがドリフト(データ分布の変化)の未検知です。
リリース後に精度が崩壊することで、ビジネスに大きな損害を与える可能性があります。
週次でPSIやKS距離を監視し、閾値を超えたら自動再学習を走らせる仕組みを導入することで、この問題に対処できます。
整形・シナリオ化の落とし穴
データ整形で特に注意すべきは粒度の不一致です。
予測粒度と制約粒度がズレていると、ソルバーが可行解を見つけられない事態に陥ります。
中間テーブルでの粒度変換をユニットテストでカバーすることで、この問題を防げます。
シナリオ過多による計算時間の爆発も見過ごせない問題です。
1000本を超えるモンテカルロシミュレーションを投入すると、計算が現実的な時間内に終わらなくなります。
p10、p50、p90などの代表値に縮約し、重要なシナリオのみを採用することで、計算負荷を管理可能な範囲に抑えられます。
最適化モデルの落とし穴
最適化モデルで最もよく見られる問題は、制約が増えすぎることです。
「満たせたら嬉しいかも」的な条件まですべてハード制約として組み込むと、計算が終わらなかったり、実行可能解が存在しなくなったりします。
制約を「必須」「優先」「希望」でタグ付けし、ハード→ソフト→削除の順で三段階テストを行うことで、この問題に対処できます。
もう一つの問題は「黒魔術パラメータ」の存在です。
ペナルティ係数などの重要パラメータが、根拠不明のまま手動チューニングで決められているケースが散見されます。
これらの係数を設定ファイルに切り出し、感度分析でレンジ管理することで、透明性と再現性を確保できます。
運用(MLOps/OptOps)の落とし穴
運用フェーズで最も深刻なのは、モデル劣化に気づけないことです。
現場からクレームが来て初めて問題が発覚するようでは遅すぎます。
精度、計算時間、可行率のSLAを定義し、Slackなどに自動通知する仕組みを構築することが不可欠です。
ガバナンスの欠如も長期的には大きな問題となります。
監査で説明できない、再現できないといった事態を避けるため、データとモデルのハッシュ値をMLflowとGitで一元管理し、変更履歴を追跡可能にすることが重要です。
これらの落とし穴に共通するのは、「放置時間が長いほどダメージが大きくなる」という特性です。
早期検知と自動アラートの仕組みを整えることで、問題が深刻化する前に対処することが可能になります。
ネクストステップ
ここまで、「時系列分析で未来を読み、数理最適化で行動を決め、それを自動で回す」というデータ駆動サイクルの全体像のお話しをしてきました。
読者が明日から着手できる具体的なステップを示します。
取り急ぎ、持ち帰ってほしい3つの視点
予測は「帯」で語る
第一に、予測は「帯」で語るという視点です。
単点予測だけでは不確実性に対処できません。
上限・下限をセットで示すことで、より頑健な意思決定が可能になります。
これは、天気予報が「降水確率30%」と伝えるように、不確実性を前提とした計画立案の基礎となります。
最適化は問題定義が8割
第二に、最適化は問題定義が8割という認識です。
数式の難易度よりも、KPIと制約を適切に言語化するプロセスがボトルネックになることが多いのです。
関係者との認識合わせに時間をかけることで、後々の手戻りを大幅に減らせます。
運用は「検知速度」が命
第三に、運用は「検知速度」が命という考え方です。
モデルが劣化してから修正するのでは遅すぎます。
精度、計算時間、可行率を常時モニタリングし、閾値を超えたら自動リカバリを走らせる体制が不可欠です。
スモールスタートのロードマップ
データ駆動サイクルを導入する際は、段階的なアプローチが効果的です。
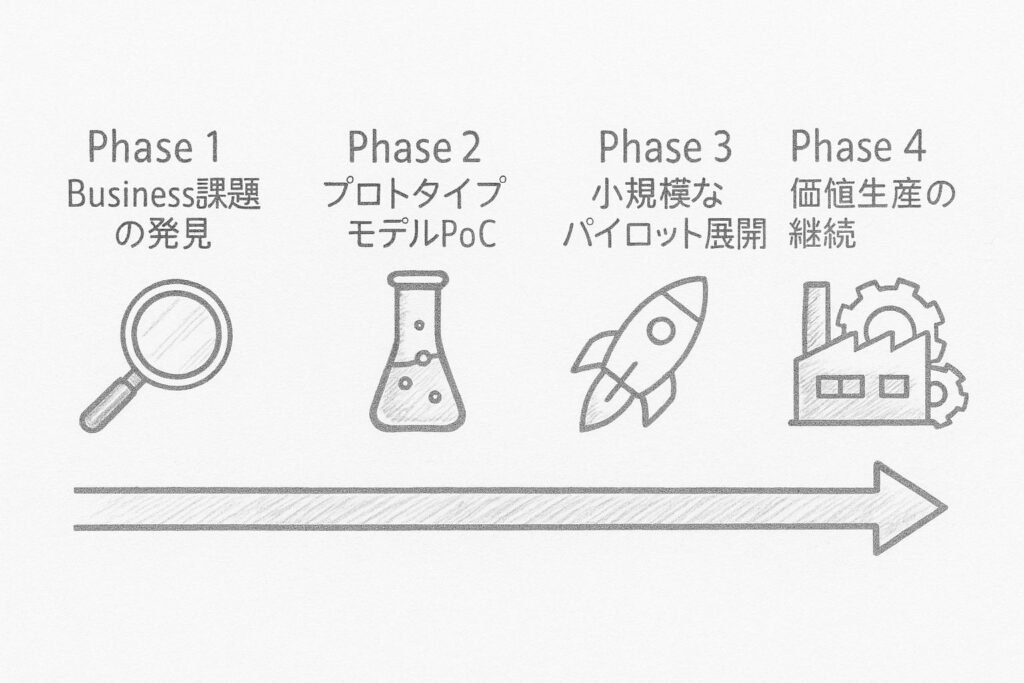
フェーズ1:ビジネス課題の発見
まずDiscovery(1週間)では、ビジネスの”痛み”を特定します。
欠品や残業など、具体的な課題を数字で可視化し、改善による金額インパクトを算出します。
この段階で「コスト削減○○万円」といった具体的な目標を設定することが重要です。
フェーズ2:プロトタイプモデルの構築とPoC
次にPrototype(2-3週間)で、技術的実現性を検証します。
1商品・1店舗といった小規模なデータで予測と最適化のPoC(概念実証)を行い、5%以上の改善が見込めるかを確認します。
この段階で技術的な障壁を洗い出し、解決策を検討します。
フェーズ3:小規模なパイロット展開と改善
続くPilot(1-2か月)では、小規模運用で実務フローを磨きます。
対象を5-10店舗に拡大し、週次バッチで実運用を開始します。
システム外での手修正が10%未満になるまで、プロセスを改善し続けます。
フェーズ4:価値生産の継続
最後にProduction(継続)段階で、全店舗への展開と自動運用を実現します。
API化し、MLOps/OptOps基盤に統合することで、継続的なKPI改善とSLA遵守を目指します。
MLOps/OptOps基盤と書いていますが、そのためのアプリやシステムを購入は必須ではなく、そのような基盤を整える、ということです。
フィードバックループを設計する
運用を始めたら、「測定→分析→改善」のループを仕組み化することが重要です。
週次では、例えばMAPE、可行率、計算時間などの主要指標をモニタリングします。
月次では、例えばKPIの3か月移動平均を更新し、トレンドを把握します。
異常日や外れ値が発生した場合は、その原因を分析し、誤差のブレイクダウンを関係部門と共有します。
改善アクションとしては、特徴量の追加や制約の調整を検討します。
必要に応じてモデルの再学習や、制約重みの再チューニングを実施します。
このループを継続的に回すことで、システムの性能を維持・向上させることができます。
今回のまとめ
今回は、「時系列で未来を読み、最適化でビジネスを動かす」というお話しをしました。
時系列予測や数理最適化、Pythonなどのツールやモデルはあくまで手段に過ぎません。
本当に難しいのは、「データを根拠に意思決定する」文化を組織に根付かせることです。
小さな成功体験を積み重ね、関係者と結果を共有し、組織学習のサイクルを回す。それがデータ駆動型組織への最短ルートです。
まずは、Pythonなどで実現できるOS環境で、サンプルデータで動かしてみることから始めましょう。
Pythonなどで、Prophetで売上予測を試したり、PuLPで簡単な最適化問題を解いたりすることで、データ駆動型意思決定の第一歩を踏み出せます。