
データを手にしたとき、データの理解のために、とりあえずデータを集計してみるということは多いです。
かっこよく言うと「探索的データ分析」(Exploratory data analysis)の1つです。
なんだかんだ言って、Excelで実施されている方も多いことでしょう。
なぜならば、RやPythonなどのツールで実施するのが、ちょっと面倒に感じる方が多いからです。面倒と感じる方の多くは、おそらく、ちょっとしたインタラクティブな集計が出来ないから、という理由も多いのではないかと思います。
では、RやPythonでExcelのピボットテーブルのような集計ができればいいだろう、ということで、前回「Rでインタラクティブにピボット集計」について話ししました。
ということで今回は、「Pythonでインタラクティブにピボット集計」です。
利用するライブラリー
利用するライブラリーのご紹介をします。
他にもあるかもしれませんが、インタラクティブにピボット集計するならという視点で考えると、以下です。
準備
先ずは、パッケージ「pivottablejs」をインストールしておきます。
以下、コードです。
pip install pivottablejs
Pythonの場合には、Jupyter Notebookを使いますので、Jupyter Notebook上でPythonが動かせる状態になってるものとしてお話しを進めます。
Jupyter Notebookをインストールされていない方は、インストールしておいてください。
以下、コードです。
pip install jupyter
サンプルデータとして、前回「Rでインタラクティブにピボット集計」と同じデータセット(warpbreaks)を使いたいため、Rのサンプルデータセットが使えるライブラリー「pydataset」をインストールしておきます。
pydatasetをインストールされていない方は、インストールしておいてください。
以下、コードです。
pip install pydataset
PyDataset
https://github.com/iamaziz/PyDataset
サンプルデータ
今回は、サンプルデータとしてRにあらかじめ用意されている「warpbreaks」(織機ごとの糸の切れ目の数)のデータに対し、ピボット集計してみます。
サンプルデータ「warpbreaks」は、ライブラリー「pydataset」を使うことで、データフレーム型としてPython上で利用することができます。
以下、コードです。
from pydataset import data
testData = data("warpbreaks")
どのようなデータなのか確かめたい場合には、以下のコードを入力し実行してください。
testData.info()
以下、実行結果です
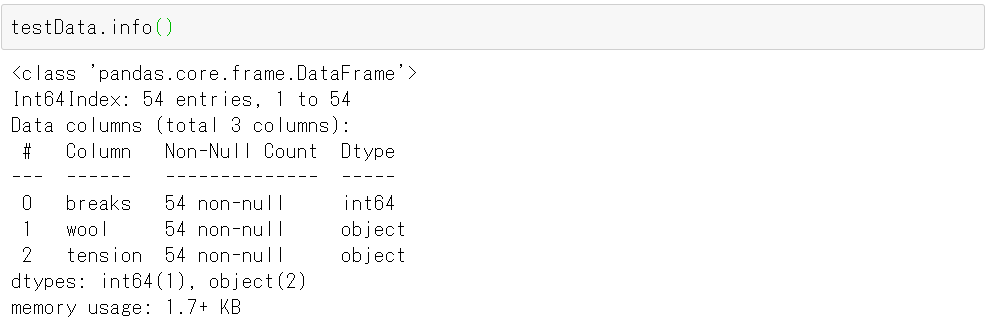
- breaks 切れ目の数
- wool ウールのタイプ (A or B)
- tension 張りの強さレベル (L, M, H)
ウールのタイプ (A or B)×張りの強さレベル (L, M, H)ごとに9つの織機のデータが取得されています。そのため、レコード数は54(=6×9)です。
ピボット集計の実行
では実際にピボット集計してみます。
以下、コードです。
# パッケージの読み込み
import pivottablejs
from pydataset import data #Rのサンプルデータセットを利用するためのもの
#データセット
testData = data("warpbreaks")
# ピボット集計実行
pivottablejs.pivot_ui(testData)
以下、実行結果です。

Jupyter Notebook上でインタラクティブに集計していきます。
カウント
次のように、表側と表頭を設定しデータをカウントしてみます。
- 表側 wool:ウールのタイプ (A or B)
- 表頭 tension:張りの強さレベル (L, M, H)
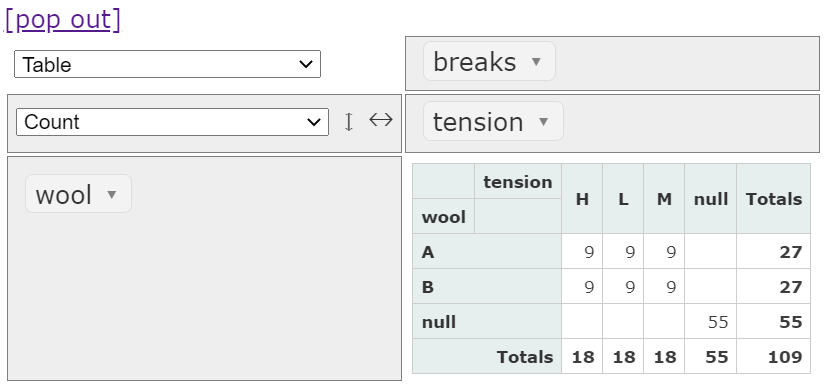
ウールのタイプ (A or B)×張りの強さレベル (L, M, H)ごとに9つの織機のデータがあることが分かります。
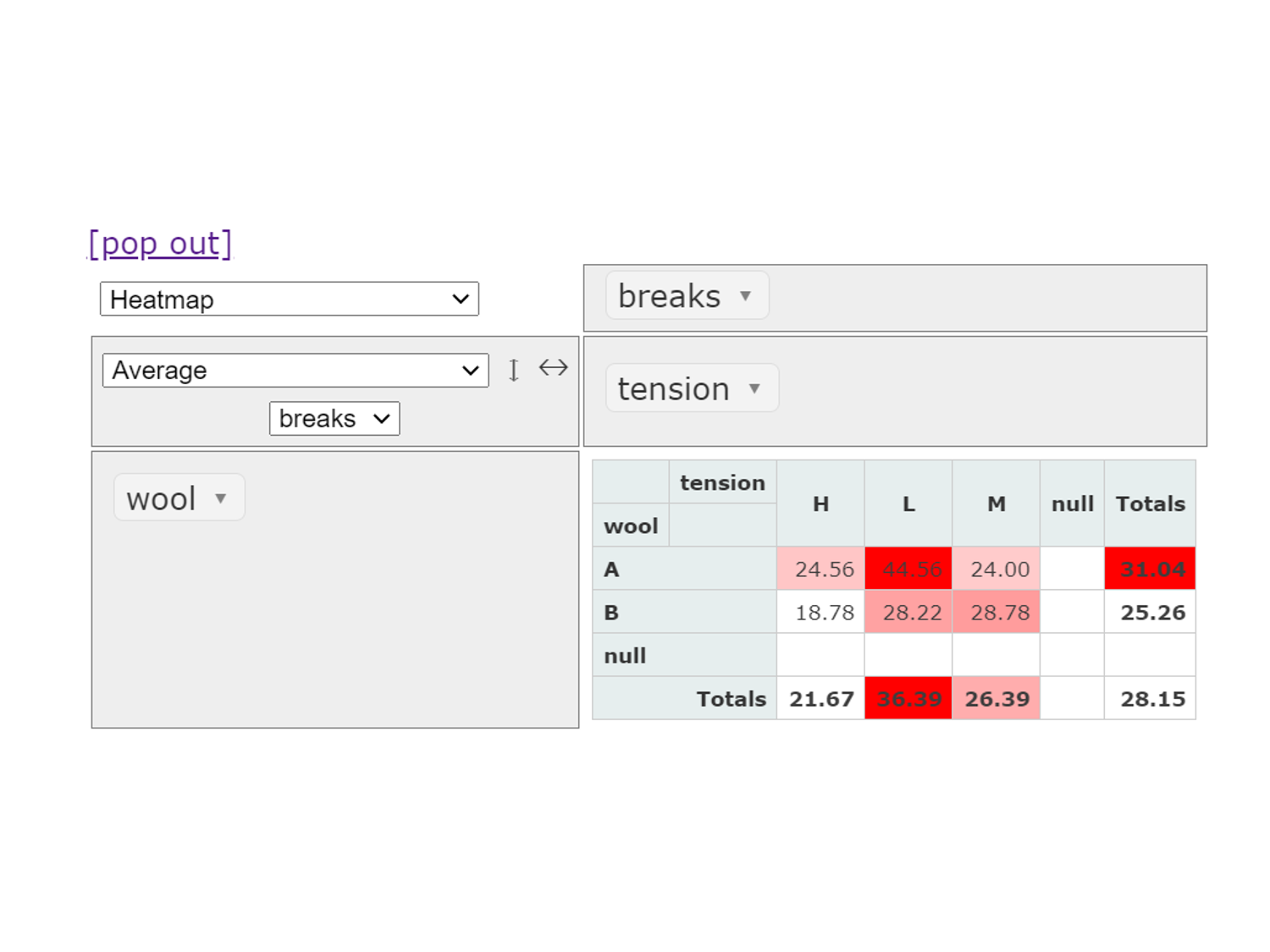
平均値
次に、ウールのタイプ (A or B)×張りの強さレベル (L, M, H)ごとにbreaks(切れ目の数)の平均値を集計してみます。

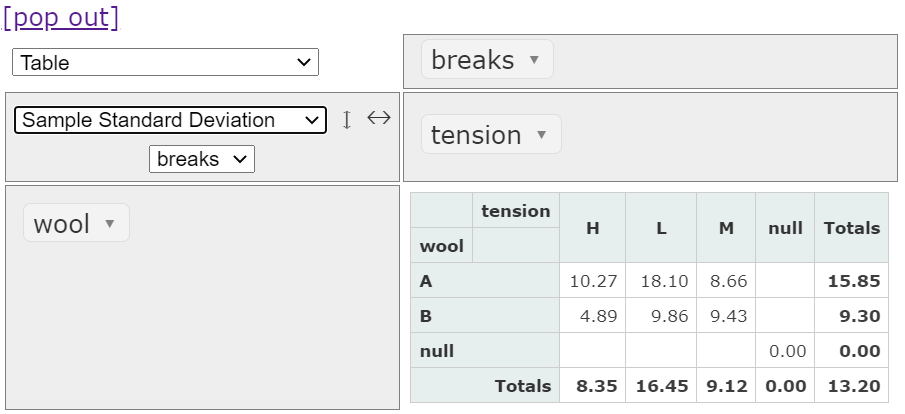
次に、標準偏差です。
グラフ表現
ウールのタイプ (A or B)×張りの強さレベル (L, M, H)ごとにbreaks(切れ目の数)の平均値に、棒グラフを追加したピボットテーブルです。
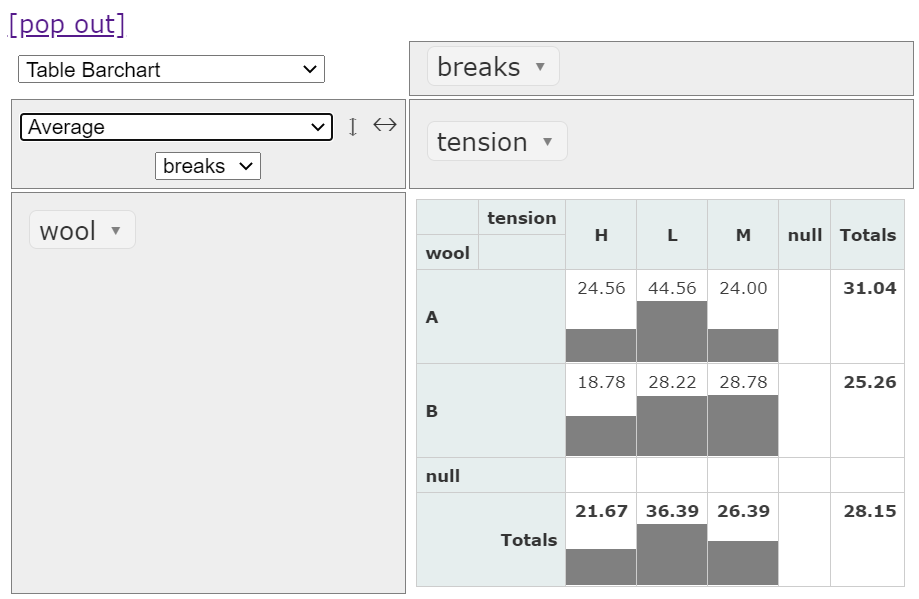
次に、ヒートマップで表現し直してみます。
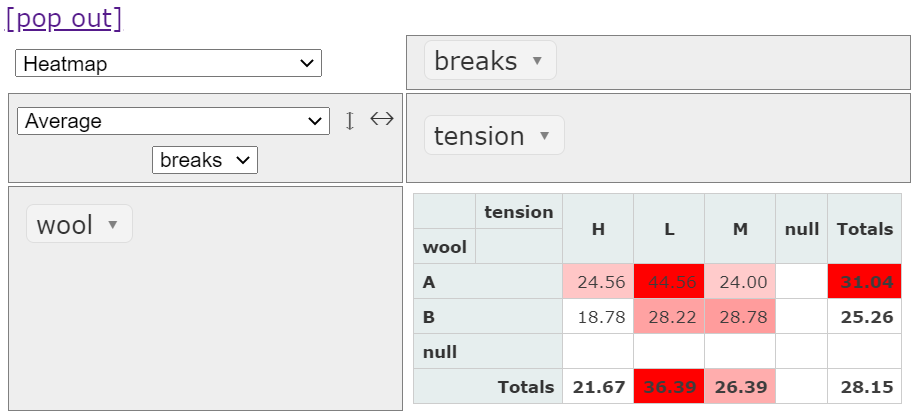
もっとたくさんの種類の集計ができます。興味のある方は、色々なデータで色々といじってみてください。