
予測モデルなどを構築するとき、パイプライン化することがあります。
もちろん、探索的なデータ分析でも、パイプラインを使いながら実施することもあります。
例えば、Rなどでは伝統的に、パイプラインを使いながら探索データ分析をします。しかし、そうでなければならないというわけでもありません。
一方で予測モデルは、機械学習パイプライン化したほうが、分かりやすいですし扱いやすいです。
今回は、「予測モデルは機械学習パイプライン化しよう(Python)」ということで、PythonのScikit-learn(sklearn)を使い、パイプラインの構築の仕方について簡単に説明します。
Contents [hide]
- パイプラインとは?
- 利用するデータ
- アヤメのデータ
- タイタニックのデータ
- ライブラリーの読み込み
- 機械学習パイプライン構築
- アヤメのデータでパイプライン
- アヤメ|データの見込みと確認
- アヤメ|パイプラインの定義
- アヤメ|パイプラインの構築と予測
- アヤメ|グリッドサーチでパイプラインの最適化その1(ロジスティック回帰)
- アヤメ|グリッドサーチでパイプラインの最適化その2(色々な分類器)
- アヤメ|ランダムサーチでパイプラインの最適化
- タイタニックのデータでパイプライン
- タイタニック|データの見込みと確認
- タイタニック|パイプラインの定義
- タイタニック|パイプラインの構築と予測
- タイタニック|グリッドサーチでパイプラインの最適化その1(ロジスティック回帰)
- タイタニック|グリッドサーチでパイプラインの最適化その2(色々な分類器)
- タイタニック|ランダムサーチでパイプラインの最適化
- まとめ
パイプラインとは?
「パイプライン」というキーワードは、色々な分野で使われています。今回の「パイプライン」(pipeline)は、「パイプライン処理」と呼ばれるコンピュータ用語です。
パイプライン処理とは、複数の処理プログラムを直列に連結し、ある処理プログラムの出力が次の処理プログラムの入力となるようにし、複数の処理プログラムを並行処理させる技術です。
ここでは、変換器(特徴量の生成と選択)と予測器(予測モデル)を直列に繋げたものを「パイプライン」と言います。
データセット
↓
処理プログラム(変換器)
↓
:
↓
処理プログラム(変換器)
↓
処理プログラム(予測器)
↓
予測結果
変換器(特徴量の生成と選択)は1つではなく複数の場合も多いです。
利用するデータ
今回は、みんな大好きアヤメのデータとタイタニックのデータを使います。
アヤメのデータ

「セトサ種」「バージニカ種」「バージカラー種」の3品種に関するデータです。
- Sepal Length: がく片の長さ
- Sepal Width: がく片の幅
- Petal Length: 花びらの長さ
- Petal Width: 花びらの幅
- Species: アヤメの種類(セトサ種・バージニカ種・バージカラー種)
Speciesが目的変数Yです。
アヤメの種類(Species)を他の変数で予測する問題(アヤメの種類を分類する問題)になります。
タイタニックのデータ

1912年に大西洋で氷山に衝突し沈没したタイタニック号の乗客者の生存状況に関するデータセットです。
- pclass: 旅客クラス(1=1等、2=2等、3=3等)
- name: 乗客の名前
- sex: 性別(male=男性、female=女性)
- age: 年齢
- sibsp: タイタニック号に同乗している兄弟(Siblings)や配偶者(Spouses)の数
- parch: タイタニック号に同乗している親(Parents)や子供(Children)の数
- ticket: チケット番号
- fare: 旅客運賃
- cabin: 客室番号
- embarked: 出港地(C=Cherbourg:シェルブール、Q=Queenstown:クイーンズタウン、S=Southampton:サウサンプトン)
- boat: 救命ボート番号
- body: 遺体収容時の識別番号
- home.dest: 自宅または目的地
- survived:生存状況(0=死亡、1=生存)
生存状況(survived)を他の変数で予測する問題(生存状況を分類する問題)になります。
今回使うのは、以下のデータです。
- pclass: 旅客クラス(1=1等、2=2等、3=3等)
- sex: 性別(male=男性、female=女性)
- age: 年齢
- sibsp: タイタニック号に同乗している兄弟(Siblings)や配偶者(Spouses)の数
- parch: タイタニック号に同乗している親(Parents)や子供(Children)の数
- fare: 旅客運賃
- survived:生存状況(0=死亡、1=生存)
survivedが目的変数Yです。
量的(ニューメリカル)特徴量は以下です。
- age: 年齢
- sibsp: タイタニック号に同乗している兄弟(Siblings)や配偶者(Spouses)の数
- parch: タイタニック号に同乗している親(Parents)や子供(Children)の数
- fare: 旅客運賃
質的(カテゴリカル)特徴量は以下です。
- pclass: 旅客クラス(1=1等、2=2等、3=3等)
- sex: 性別(male=男性、female=女性)
ライブラリーの読み込み
ライブラリーを読み込みます。
基本的なものばかりです。主に使うのはScikit-learn(sklearn)です。インストールされていない方は、インストールしておいてください。
では、以下ライブラリーを読み込むコードです。
# ライブラリーの読み込み ## 基礎ライブラリー import numpy as np import pandas as pd ## 例で利用するデータセット from sklearn.datasets import fetch_openml, load_iris ## 変換器 from sklearn.impute import SimpleImputer from sklearn.preprocessing import StandardScaler, OneHotEncoder, MinMaxScaler, RobustScaler ## 予測器(推定器) from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, AdaBoostClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC, LinearSVC ## パイプライン from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from sklearn import set_config ## データセット分割(学習データ・テストデータ) from sklearn.model_selection import train_test_split ## パラメータ調整 from sklearn.model_selection import GridSearchCV, RandomizedSearchCV, ParameterGrid ## 評価関数 from sklearn.metrics import accuracy_score, f1_score
機械学習パイプライン構築
では、アヤメのデータとタイタニックのデータを使って、パイプラインを構築していきます。
アヤメのデータでパイプライン
アヤメ|データの見込みと確認
先ずは、データの読み込みです。
以下、コードです。
# データセット読み込み X, y = load_iris(as_frame=True, return_X_y=True)
データの中を見てみます。
以下、コードです。
X
以下、実行結果です。
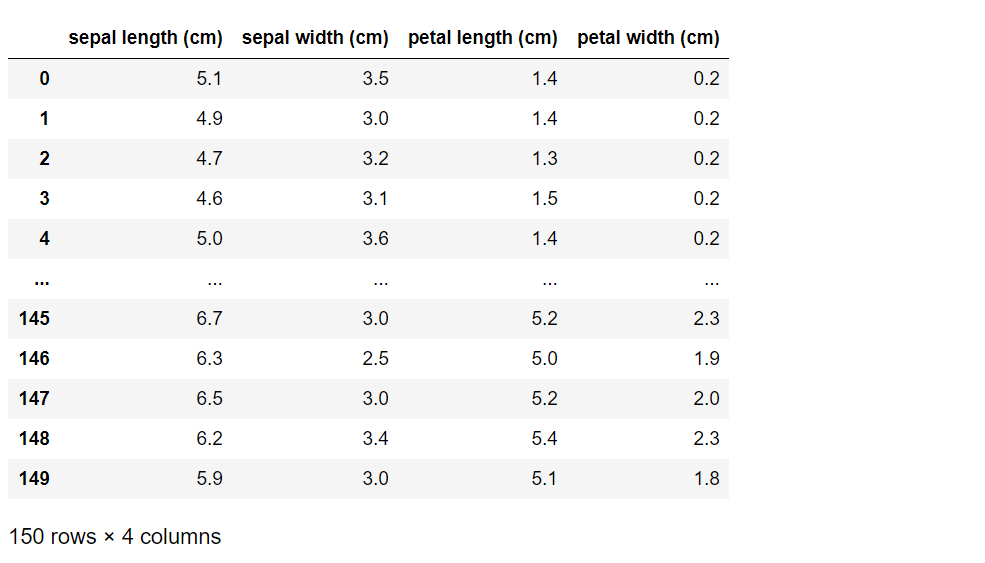
150行×4列のデータセットであることが分かります。
データセットの情報を見てみます。
以下、コードです。
X.info()
以下、実行結果です。
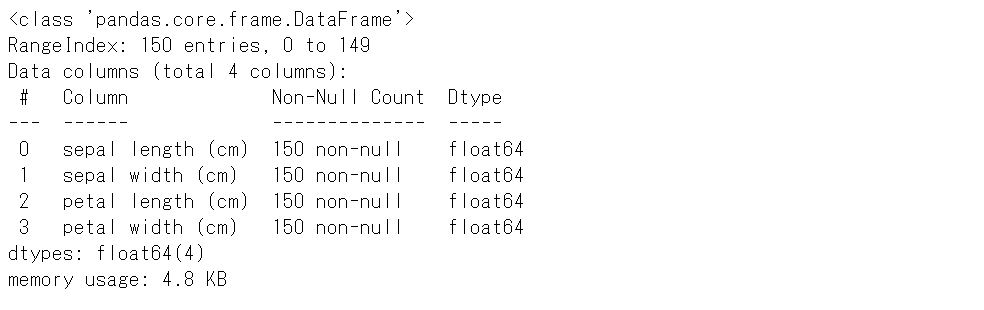
欠測値はなさそうです。
目的変数yのデータも見てみます。
以下、コードです。
y
以下、実行結果です。

アヤメ|パイプラインの定義
パイプラインを構築していきます。
- 変換器:StandardScaler(標準化)
- 予測器(推定器):Logistic Regression分類器(ロジスティック回帰)
変換器と予測器(推定器)をそれぞれで定義してから、繋げてパイプラインにします。
# パイプライン構築
## 特徴量
features = ["sepal length (cm)",
"sepal width (cm)",
"petal length (cm)",
"petal width (cm)"]
## 変換器パイプライン
### パイプライン定義
transformer = Pipeline(steps=[
("scaler", StandardScaler()) #特徴量を標準化
])
### 統合(特徴量‐>変換器)
preprocessor = ColumnTransformer(transformers=[
("transform", transformer, features)
])
## パイプライン全体:変換器パイプライン‐>予測器(推定器)
pipeline = Pipeline(steps=[
("preprocesser", preprocessor), #変換器パイプライン
("classifier", LogisticRegression()) #予測器(推定器)
])
どのようなパイプラインになったのか図解表示し、確認してみます。一時的に表示できるように設定し表示します。
以下、コードです。
# パイプライン表示 set_config(display='diagram') pipeline
以下、実行結果です。

以下のコードでパイプラインの図解を非表示にします。
set_config(display='None')
アヤメ|パイプラインの構築と予測
定義したパイプラインを学習データで構築し、テストデータを予測し精度検証していきます。
先ずは、データセットを学習データとテストデータに分割します。
以下、コードです。
# 学習データとテストデータに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
- X_train:学習データの特徴量
- X_test:テストデータの特徴量
- y_train:学習データの目的変数
- y_test:テストデータの目的変数
学習データでパイプラインを構築(学習)します。
以下、コードです。
# 学習データでパイプライン構築 pipeline.fit(X_train, y_train)
次に、学習データで構築(学習)したパイプラインを使い、テストデータで予測し精度検証します。精度指標は「正答率」(accuracy)です。
以下、コードです。
# テストデータで精度検証 y_test_pred = pipeline.predict(X_test) accuracy_score(y_test, y_test_pred)
以下、実行結果です。
![]()
テストデータの正答率は93%です。
アヤメ|グリッドサーチでパイプラインの最適化その1(ロジスティック回帰)
数理モデルは設定したパラメータによって、構築されるモデルが異なります。最適なパラメータを探すのが、パラメータ調整です。
パラメータ調整の方法は色々あります。最も簡単なのは、以下の2つです。
- グリッドサーチ:設定したパラメータ組み合わせをすべてに試し最適なものを探す
- ランダムサーチ:設定したパラメータ組み合わせをランダムに試し最適なものを探す
先ず、シンプルなグリッドサーチをします。
- 変換器(標準化):Standard Scaler or Min Max Scaler or Robust Scaler
- 予測器(推定器):Logistic Regression分類器のパラメータC(今回はL2正則化の強さ。C = 0.1 or 1.0 or 10.0 or 100.0)
要は、3つの標準化とパラメータC(今回はL2正則化の強さ)の組み合わせ(3×4=12パターン)すべてを試し最適なものを探します。
以下、グリッドサーチ設定のコードです。
# グリッドサーチの設定
param_grid = [
{
"preprocesser__transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__C": [0.1, 1.0, 10.0, 100.0],
"classifier": [LogisticRegression()]
}
]
grid_search = GridSearchCV(pipeline, param_grid, cv=10, verbose=3,n_jobs=-1)
グリッドサーチを実行します。
以下、コードです。
# グリッドサーチの実行 grid_search.fit(X_train, y_train)
処理が終了したら、グリッドサーチの結果(最適なパイプラインとその正答率)を見てみましょう。
以下、コードです。
# グリッドサーチの結果 print(grid_search.best_params_) #最適なパイプライン print(grid_search.best_score_) #正答率
以下、実行結果です。

構築されたのは、特徴量をStandart Scalarで標準化したデータを使いC=10で正則化したロジスティック回帰です。学習データに対する正答率は96%です。
テストデータで予測精度の検証をしましょう。
以下、コードです。
# テストデータで精度検証
y_test_pred = grid_search.predict(X_test)
print('accuracy:',accuracy_score(y_test, y_test_pred))
以下、実行結果です。
![]()
テストデータの正答率は95%です。
アヤメ|グリッドサーチでパイプラインの最適化その2(色々な分類器)
分類器が1つ(例では、ロジスティック回帰)である必要はありません。複数でも構いません。
分類器を以下の6種類に増やしグリッドサーチを実施してみます。
- LogisticRegression:ロジスティック回帰
- RandomForestClassifier:ランダムフォレスト分類器
- GradientBoostingClassifier:勾配ブースティング決定木
- AdaBoostClassifier:アダブースト分類器
- SVC:サポートベクターマシン(SVM)分類器
- LinearSVC:カーネルを利用しないSVM分類器
各分類器のパラメータ調整も実施します。
以下、コードです。
# グリッドサーチの設定その2
param_grid = [
{
"preprocesser__transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__C": [0.1, 1.0, 10.0, 100.0],
"classifier": [LogisticRegression()]
},
{
"preprocesser__transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__n_estimators": [10, 100, 1000],
"classifier": [RandomForestClassifier(), GradientBoostingClassifier(), AdaBoostClassifier()]
},
{
"preprocesser__transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__C": [1, 10, 100, 1000],
"classifier": [SVC(),LinearSVC()]
}
]
grid_search = GridSearchCV(pipeline, param_grid, cv=10, verbose=3,n_jobs=-1)
グリッドサーチを実行します。
以下、コードです。
# グリッドサーチの実行 grid_search.fit(X_train, y_train)
計算時間が長くなっているのが分かると思います。
処理が終了したら、グリッドサーチの結果(最適なパイプラインとその正答率)を見てみましょう。
以下、コードです。
# グリッドサーチの結果 print(grid_search.best_params_) #最適なパイプライン print(grid_search.best_score_) #正答率
以下、実行結果です。

構築されたのは、特徴量をMin Max Scalarで標準化したデータを使いC=1で正則化したSVM分類器で、学習データに対する正答率は97%です。
テストデータで予測精度の検証をしましょう。
以下、コードです。
# テストデータで精度検証
y_test_pred = grid_search.predict(X_test)
print('accuracy:',accuracy_score(y_test, y_test_pred))
以下、実行結果です。
![]()
テストデータの正答率は95%です。
アヤメ|ランダムサーチでパイプラインの最適化
通常グリッドサーチは膨大な時間が掛かるケースが多いので、さくっと実施したい場合や、グリッドサーチの前にちょっと試してみたい場合に利用するのは、ランダムサーチによるパイプライン最適化です。
先ほどのグリッドサーチで設定したものをそのまま使い、ランダムサーチを実施してみます。
以下、コードです。
# ランダムサーチの設定 ※「グリッドサーチの設定その2」と同じ
param_grid = [
{
"preprocesser__transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__C": [0.1, 1.0, 10.0, 100.0],
"classifier": [LogisticRegression()]
},
{
"preprocesser__transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__n_estimators": [10, 100, 1000],
"classifier": [RandomForestClassifier(), GradientBoostingClassifier(), AdaBoostClassifier()]
},
{
"preprocesser__transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__C": [1, 10, 100, 1000],
"classifier": [SVC(),LinearSVC()]
}
]
rand_search = RandomizedSearchCV(pipeline, param_grid, cv=10, verbose=3, n_jobs=-1, n_iter=10)
ランダムサーチを実行します。
以下、コードです。
# ランダムサーチの実行 rand_search.fit(X_train, y_train)
計算時間が短くなっているのが分かると思います。
処理が終了したら、ランダムサーチの結果(最適なパイプラインとその正答率)を見てみましょう。
以下、コードです。
# ランダムサーチの結果 print(rand_search.best_params_) #最適なパイプライン print(rand_search.best_score_) #正答率
以下、実行結果です。
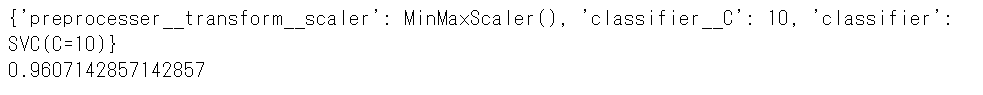
構築されたのは、特徴量をMin Max Scalarで標準化したデータを使いC=10で正則化したSVM分類器で、学習データに対する正答率は96%です。
テストデータで予測精度の検証をしましょう。
以下、コードです。
# テストデータで精度検証
y_test_pred = rand_search.predict(X_test)
print('accuracy:',accuracy_score(y_test, y_test_pred))
以下、実行結果です。
![]()
テストデータの正答率は97%です。
タイタニックのデータでパイプライン
タイタニック|データの見込みと確認
先ずは、データの読み込みです。
以下、コードです。
# データセット読み込み
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)
データの中を見てみます。
以下、コードです。
X
以下、実行結果です。
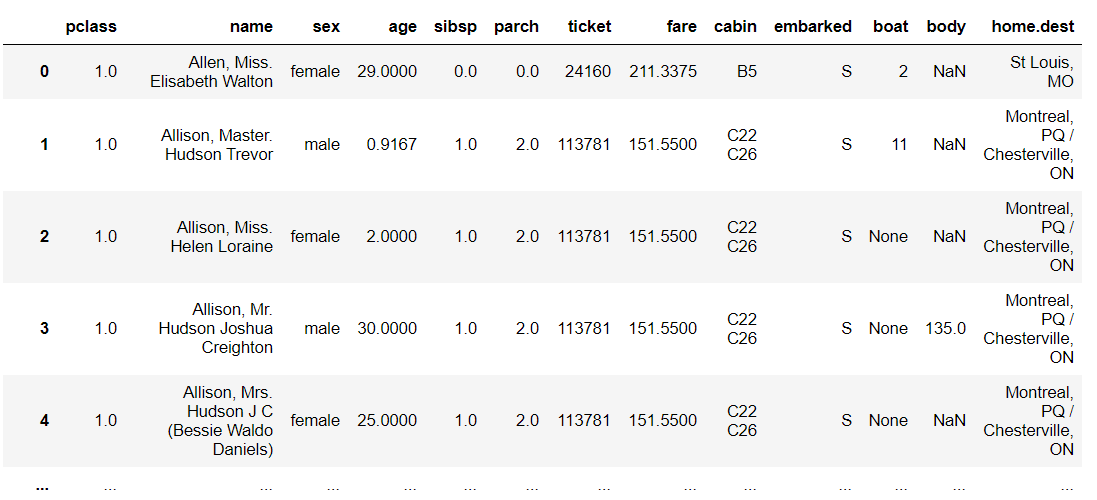
データセットの情報を見てみます。
以下、コードです。
X.info()
以下、実行結果です。
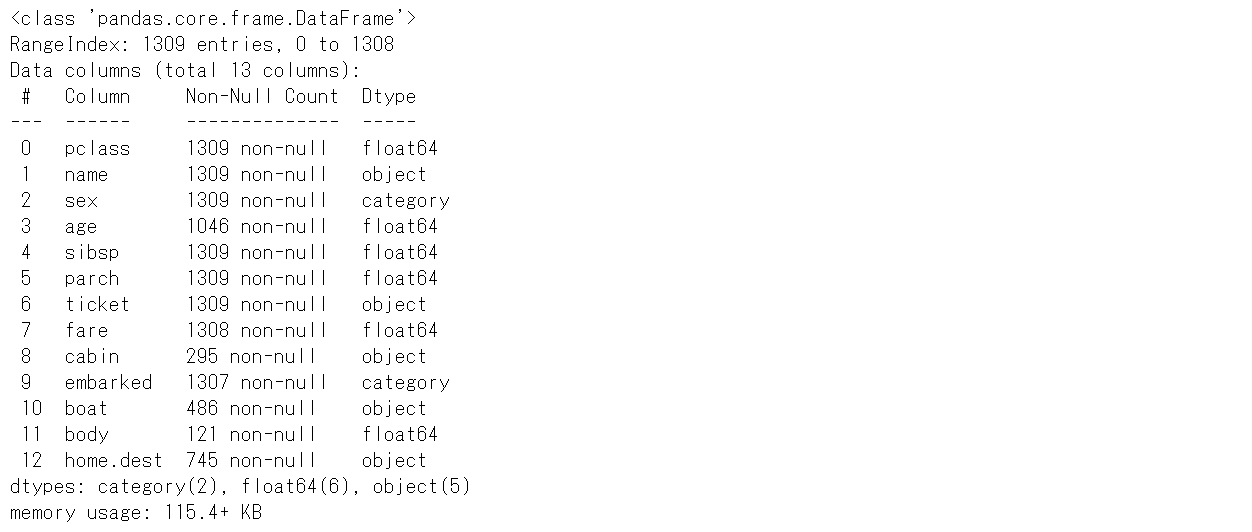
特徴量(変数)によって有効なデータの数が異なります。
例えば……
- pclass 1309
- age 1046
- cabin 295
どうも欠測値がありそうです。どのくらい欠測値あるのが確認してみます。
以下、コードです。
X.isnull().sum()
以下、実行結果です。

欠測値のある特徴量(変数)を使うときには、欠測値を補完する処理が必要になります。
目的変数yのデータも見てみます。
以下、コードです。
y
以下、実行結果です。

データの型がCategoryなので、数値に変換(厳密に言うと整数へ変換)します。
以下、コードです。
y = y.astype('int')
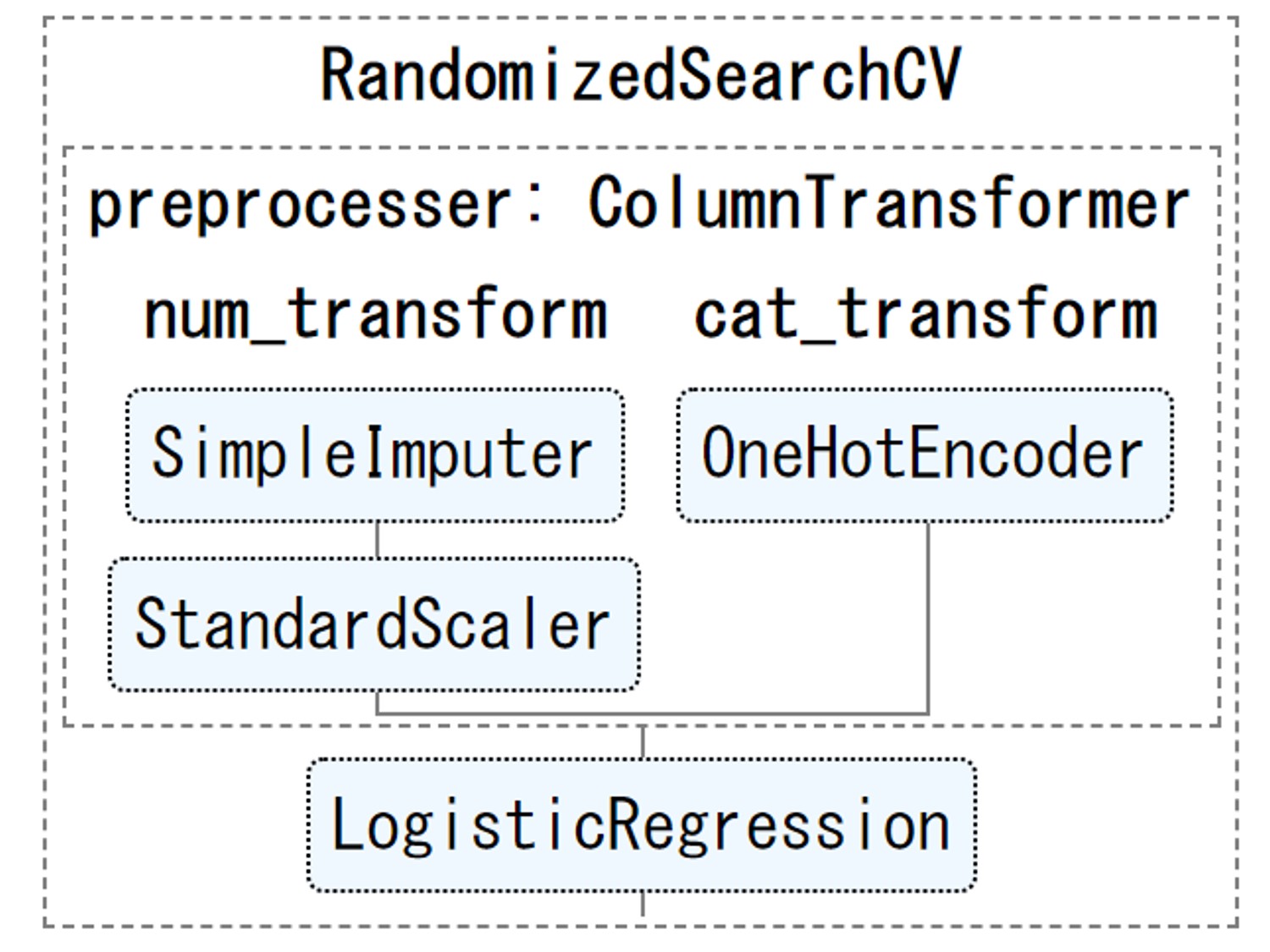
タイタニック|パイプラインの定義
パイプラインを構築していきます。
- 変換器(量的特徴量):欠測値を平均値で補完(SimpleImputer)し標準化(StandardScaler)
- 変換器(質的特徴量):カテゴリをダミーデータ(0-1データ)化(OneHotEncoder)
- 予測器(推定器):Logistic Regression分類器(ロジスティック回帰)
量的特徴量と質的特徴量で変換器が異なります。変換器と予測器(推定器)をそれぞれで定義してから、繋げてパイプラインにします。
以下、コードです。
# パイプライン構築
## 特徴量
### 量的(ニューメリカル)
numeric_features = ["age", "sibsp", "parch", "fare"]
### 質的(カテゴリカル)
categorical_features = ["sex", "pclass"]
## 変換器パイプライン
### 量的(ニューメリカル)
numeric_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="mean")), #欠測値補完
("scaler", StandardScaler()) #標準化
])
### 質的(カテゴリカル)
categorical_transformer = OneHotEncoder(handle_unknown="ignore") #ダミー(0-1データ)化
### 統合(特徴量‐>変換器)
preprocessor = ColumnTransformer(transformers=[
("num_transform", numeric_transformer, numeric_features), # 量的(ニューメリカル)
("cat_transform", categorical_transformer, categorical_features) # 質的(カテゴリカル)
])
## パイプライン全体:変換器パイプライン‐>予測器(推定器)
pipeline = Pipeline(steps=[("preprocesser", preprocessor), #変換器パイプライン
("classifier", LogisticRegression()) #予測器(推定器)
])
どのようなパイプラインになったのか図解表示し、確認してみます。一時的に表示できるように設定し表示します。
以下、コードです。
# パイプライン表示 set_config(display='diagram') pipeline
以下、実行結果です。

以下のコードでパイプラインの図解を非表示にします。
set_config(display='None')
タイタニック|パイプラインの構築と予測
定義したパイプラインを学習データで構築し、テストデータで予測することで精度検証していきます。
先ずは、データセットを学習データとテストデータに分割します。
以下、コードです。
# 学習データとテストデータに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
- X_train:学習データの特徴量
- X_test:テストデータの特徴量
- y_train:学習データの目的変数
- y_test:テストデータの目的変数
学習データでパイプラインを構築(学習)します。
以下、コードです。
# 学習データでパイプライン構築 pipeline.fit(X_train, y_train)
次に、学習データで構築(学習)したパイプラインを使い、テストデータで予測し精度検証します。精度指標は「正答率」(accuracy)と「Fスコア」(f1)です。
分類問題の指標に詳しくない方は、慣れていない方は、「正答率」(accuracy)だけ見ていきましょう。
以下、コードです。
# テストデータで精度検証
y_test_pred = pipeline.predict(X_test)
print('accuracy:',accuracy_score(y_test, y_test_pred))
print('f1:', f1_score(y_test, y_test_pred))
以下、実行結果です。

テストデータの正答率は74%です。
タイタニック|グリッドサーチでパイプラインの最適化その1(ロジスティック回帰)
先ず、シンプルなグリッドサーチをします。
- 量的特徴量の変換器:
- 変換器(欠測値補完):Mean or Median
- 変換器(標準化):Standard Scaler or Min Max Scaler or Robust Scaler
- 予測器(推定器):Logistic Regression分類器のパラメータC(今回はL2正則化の強さ。C = 0.1 or 1.0 or 10.0 or 100.0)
要は、2つの欠測値補完と3つの標準化とパラメータC(今回はL2正則化の強さ)の組み合わせ(2×3×4=24パターン)すべてを試し最適なものを探します。
以下、グリッドサーチ設定のコードです。
# グリッドサーチの設定
param_grid = [
{
"preprocesser__num_transform__imputer__strategy": ["mean", "median"],
"preprocesser__num_transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__C": [0.1, 1.0, 10.0, 100.0],
"classifier": [LogisticRegression()]
}
]
grid_search = GridSearchCV(pipeline, param_grid, cv=10, verbose=3,n_jobs=-1)
グリッドサーチを実行します。
以下、コードです。
# グリッドサーチの実行 grid_search.fit(X_train, y_train)
処理が終了したら、グリッドサーチの結果(最適なパイプラインとその正答率)を見てみましょう。
以下、コードです。
# グリッドサーチの結果 print(grid_search.best_params_) #最適なパイプライン print(grid_search.best_score_) #正答率
以下、実行結果です。

構築されたのは、特徴量の欠測値で補完し、その後にStandart Scalarで標準化したデータで使い、C=10で正則化したロジスティック回帰です。学習データに対する正答率は80%です。
テストデータで予測精度の検証をしましょう。
以下、コードです。
# テストデータで精度検証
y_test_pred = grid_search.predict(X_test)
print('accuracy:',accuracy_score(y_test, y_test_pred))
print('f1:', f1_score(y_test, y_test_pred))
以下、実行結果です。

テストデータの正答率は74%です。
タイタニック|グリッドサーチでパイプラインの最適化その2(色々な分類器)
分類器を以下の6種類に増やしグリッドサーチを実施してみます。
- LogisticRegression:ロジスティック回帰
- RandomForestClassifier:ランダムフォレスト分類器
- GradientBoostingClassifier:勾配ブースティング決定木
- AdaBoostClassifier:アダブースト分類器
- SVC:サポートベクターマシン(SVM)分類器
- LinearSVC:カーネルを利用しないSVM分類器
各分類器のパラメータ調整も実施します。
以下、コードです。
# グリッドサーチの設定その2
param_grid = [
{
"preprocesser__num_transform__imputer__strategy": ["mean", "median"],
"preprocesser__num_transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__C": [0.1, 1.0, 10.0, 100.0],
"classifier": [LogisticRegression()]
},
{
"preprocesser__num_transform__imputer__strategy": ["mean", "median"],
"preprocesser__num_transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__n_estimators": [10, 100, 1000],
"classifier": [RandomForestClassifier(), GradientBoostingClassifier(), AdaBoostClassifier()]
},
{
"preprocesser__num_transform__imputer__strategy": ["mean", "median"],
"preprocesser__num_transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__C": [1, 10, 100, 1000],
"classifier": [SVC(),LinearSVC()]
}
]
grid_search = GridSearchCV(pipeline, param_grid, cv=10, verbose=3,n_jobs=-1)
グリッドサーチを実行します。
以下、コードです。
# グリッドサーチの実行 grid_search.fit(X_train, y_train)
計算時間が長くなっているのが分かると思います。
処理が終了したら、グリッドサーチの結果(最適なパイプラインとその正答率)を見てみましょう。
以下、コードです。
# グリッドサーチの結果 print(grid_search.best_params_) #最適なパイプライン print(grid_search.best_score_) #正答率
以下、実行結果です。

構築されたのは、特徴量の欠測値で補完し、その後にStandart Scalarで標準化したデータで使い、C=1で正則化したSVM分類器です。学習データに対する正答率は82%です。
テストデータで予測精度の検証をしましょう。
以下、コードです。
# テストデータで精度検証
y_test_pred = grid_search.predict(X_test)
print('accuracy:',accuracy_score(y_test, y_test_pred))
print('f1:', f1_score(y_test, y_test_pred))
以下、実行結果です。

{kind=link}
タイタニック|ランダムサーチでパイプラインの最適化
通常グリッドサーチは膨大な時間が掛かるケースが多いので、さくっと実施したい場合や、グリッドサーチの前にちょっと試してみたい場合に利用するのは、ランダムサーチによるパイプライン最適化です。
先ほどのグリッドサーチで設定したものをそのまま使い、ランダムサーチを実施してみます。
以下、コードです。
# ランダムサーチの設定 ※「グリッドサーチの設定その2」と同じ
param_grid = [
{
"preprocesser__num_transform__imputer__strategy": ["mean", "median"],
"preprocesser__num_transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__C": [0.1, 1.0, 10.0, 100.0],
"classifier": [LogisticRegression()]
},
{
"preprocesser__num_transform__imputer__strategy": ["mean", "median"],
"preprocesser__num_transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__n_estimators": [10, 100, 1000],
"classifier": [RandomForestClassifier(), GradientBoostingClassifier(), AdaBoostClassifier()]
},
{
"preprocesser__num_transform__imputer__strategy": ["mean", "median"],
"preprocesser__num_transform__scaler": [StandardScaler(), MinMaxScaler(), RobustScaler()],
"classifier__C": [1, 10, 100, 1000],
"classifier": [SVC(),LinearSVC()]
}
]
rand_search = RandomizedSearchCV(pipeline, param_grid, cv=10, verbose=3, n_jobs=-1, n_iter=10)
ランダムサーチを実行します。
以下、コードです。
# ランダムサーチの実行 rand_search.fit(X_train, y_train)
計算時間が短くなっているのが分かると思います。
処理が終了したら、ランダムサーチの結果(最適なパイプラインとその正答率)を見てみましょう。
以下、コードです。
# ランダムサーチの結果 print(rand_search.best_params_) #最適なパイプライン print(rand_search.best_score_) #正答率
以下、実行結果です。

構築されたのは、特徴量の欠測値で補完し、その後にRobust Scalarで標準化したデータで使い、C=1で正則化したSVM分類器です。学習データに対する正答率は82%です。
テストデータで予測精度の検証をしましょう。
以下、コードです。
# テストデータで精度検証
y_test_pred = rand_search.predict(X_test)
print('accuracy:',accuracy_score(y_test, y_test_pred))
print('f1:', f1_score(y_test, y_test_pred))
以下、実行結果です。

テストデータの正答率は77%です。
まとめ
今回は、「予測モデルは機械学習パイプライン化しよう(Python)」ということで、PythonのScikit-learn(sklearn)を使い、パイプラインの構築の仕方について簡単に説明しました。
なんか面倒だな…… と思った方もいるかもしれませんが、パイプラインを含めたモデル構築を試行錯誤するとき、意外と便利です。運用上もパイプライン化されていると良いかと思います。
ただ、パイプラインを思い描くには、ある程度の経験が必要になります。どんなに慣れても、探索的なデータ分析を抜きにして、パイプラインを描くのは難しいと思います。
探索的データ分析ってなぁ~に、という方もいるかもしれませんので、別の機会にお話しします。