
発展途上ではありますが、個人的に注目している時系列解析のライブラリーがあります。Sktimeというライブラリーです。
名前から想像できる通り、Pythonの有名な機械学習ライブラリーScikit-learn(sklearn)の時系列版のようなものです。ちなみに、Scikit-learn(sklearn)は時系列データではなくクロスセクショナルデータと呼ばれるテーブルデータを相手にします。

Sktimeは、Scikit-learn(sklearn)のように、回帰問題や分類問題を扱うことができます。それが、時系列版になった感じです。しかも、Scikit-learn(sklearn)と連携して動かすことができます。
しかし、現段階では発展途上というか開発途上な感じで、マニュアルもところどころ「工事中」(2021年2月1日現在)となっています。
ということで今回は「時系列解析版Scikit-learn(sklearn)かもしれないライブラリー「Sktime」(Python)」という、中途半端なお話しをします。
sktimeについては、以下でもう少し広く複数回に渡り説明したいます。
Contents [hide]
Sktimeでできることの概要
現段階(2021年2月1日現在)では、以下の機能が提供されています。
例えば……
- 予測器・推定器の構築:時系列回帰や時系列分類、時系列予測のモデルを構築
- 変換器の構築:時系列変換、特徴量エンジニアリングなど
- パイプラインの構築:変換器と予測器の一連のつながりを構築
- モデルのチューニング
- モデルのアンサンブル化
……などです。
基本的には、Scikit-learn(sklearn)と同様に、以下の3つの機能がメインになります。
- transform:データを変換
- fit:学習データを使ってモデル構築
- predict:構築したモデルで予測
予測のための時系列の数理モデルは、主に2種類の作り方があります。
- 時系列解析用の数理モデルで構築する
- クロスセクショナルデータ(テーブルデータ)用の数理モデルで構築する
2番目の「クロスセクショナルデータ(テーブルデータ)用の数理モデルで構築する」は、Scikit-learn(sklearn)を活用したりします。
1番目の「時系列解析用の数理モデルで構築する」は、Scikit-learn(sklearn)にはないような時系列解析の数理モデルを実施します。
Sktimeで嬉しいことの1つは、時系列解析用の数理モデルでも、Scikit-learn(sklearn)に登場するような数理モデルでも、どちらでも数理モデルを構築することが可能なところです。
Sktimeのインストール
先ずは、Sktimeをインストールする必要があります。
以下、conda(Anacondaなどを使っている方)を使ったインストールをするときのコードです。
conda install -c conda-forge sktime
以下、Anacondaなどを使っていない方は、pipでインストールしてください。
pip install sktime
予測(Forecasting)
ここで簡単な例で、簡単な使い方を紹介します。
時系列解析と言えば、数値の予測です。
数値予測で使える時系列モデル
Sktimeの数値予測で使える時系列モデルは色々あります。
例えば……
- ARIMA
- Exponential Smoothing(指数平滑化法)
- ETS(Error-Trend-Seasonality、状態空間指数平滑化法)
- BATS/TBATS(Exponential smoothing state space model with Box-Cox transformation, ARMA errors, Trend and Seasonal components)
- Facebook Prophet
……などの鉄板の時系列モデルは、当然含んでいます。
後は、Scikit-learn(sklearn)の数理モデルを使うこともできますし、それらをアンサンブル化することもできます。
必要なライブラリーの読み込み
では、必要なライブラリーを早速読み込みたいと思います。
以下、コードです。
# 基本ライブラリー import numpy as np import pandas as pd # sktime系 from sktime.datasets import load_airline #サンプルデータ(航空機の乗客数) from sktime.forecasting.model_selection import temporal_train_test_split #時系列の学習データとテストデータの生成 from sktime.forecasting.arima import AutoARIMA #ARIMAモデル from sktime.forecasting.exp_smoothing import ExponentialSmoothing #ESモデル from sktime.forecasting.ets import AutoETS #ETSモデル from sktime.forecasting.tbats import TBATS #TBATSモデル from sktime.forecasting.compose import EnsembleForecaster #アンサンブル from sktime.utils.plotting import plot_series #グラフ化 from sktime.performance_metrics.forecasting import mean_absolute_percentage_error #予測精度MAPE
エラーが出る場合には、必要なライブラリーがインストールされていない可能性があります。もし、エラーメッセージが出たときは、エラーメッセージを解読し必要なライブラリーをインストールしておいてください。
サンプルデータ
Box and Jenkins (1976) の有名な時系列データであるAirline Passengers(飛行機乗客数)を使います。時系列解析のサンプルデータとしてよく利用されています。Sktimeに用意されています。
以下、コードです。
y = load_airline()
どのようなデータが入っているか確認してみます。
以下、コードです。
y
以下、実行結果です。

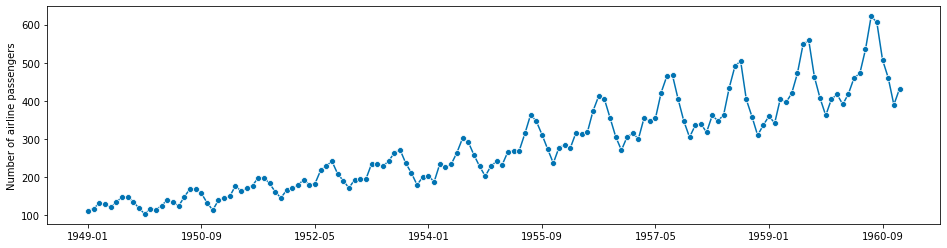
グラフ化してみます。
以下、コードです。
plot_series(y)
以下、実行結果です。
サンプルデータを、学習データ(train)とテストデータ(test)に分割したいと思います。
時系列データの場合、クロスセクショナルデータ(テーブルデータ)と異なり、ランダムにデータを抽出することはできません。隣り合ったデータ同士の間もしくは一連の関係性(例:周期性など)が意味を持ちます。
そのため、ある期間を境に、学習データ(train)とテストデータ(test)に分割します。今回は、直近3年間(36カ月間)のデータをテストデータ(test)にし、その前のデータを学習データ(train)にします。
以下、コードです。
y_train, y_test = temporal_train_test_split(y,test_size=36)
- y_train:学習データ
- y_test:テストデータ
分割したデータの中を見てみます。
以下、学習データを見るコードです。
y_train
以下、実行結果です。

以下、テストデータを見るコードです。
y_test
以下、実行結果です。

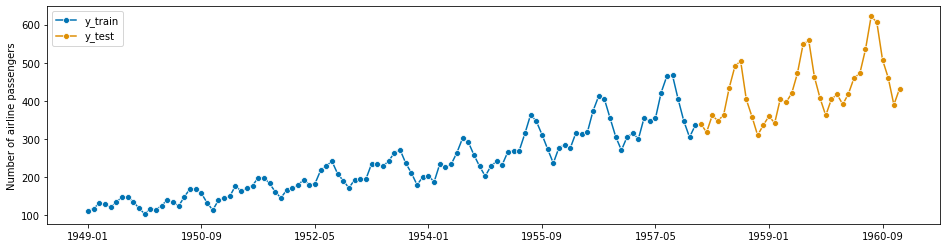
グラフで確認してみます。
以下、コードです。
plot_series(y_train, y_test, labels=["y_train", "y_test"])
以下、実行結果です。
このように、Sktimeには時系列データを扱うのに便利な機能が実装されております。他にも色々あります。日々進化しています。
次から、実際に時系列モデルを構築し、予測をしていきたいと思います。予測精度は、MAPE(平均絶対パーセント誤差)で見ていきます。MAPEは小さい方が良いです。
ARIMAモデル
時系列解析で最もメジャーで、実務で利用されている数理モデルの1つがARIMAモデルです。
日本だけでなく欧米などの諸外国の経済指標などでも、ARIMAモデルは季節調整などで活用されています。例えば、米国の国勢調査局 (Census Bureau)で開発されたX12-ARIMAやX13-ARIMAなどが、経済指標でよく使われています。
ARIMAモデルを作るとき、幾つかの次数(AR、I、MA、SAR、SI、SMA)を考える必要があります。今回は、自動で最適な次数を探索し設定するAuto-ARIMA(自動ARIMA)を使います。
以下、コードです。
# ARIMAモデル自動構築 forecaster = AutoARIMA(sp=12, suppress_warnings=True) forecaster.fit(y_train)
これで、ARIMAモデルが構築されました。次に予測です。
学習データ以降の3年間(36カ月間)を予測します。最初、予測期間の添え字を作り、そして予測します。
以下、コードです。
# 予測期間の添え字 fh = np.arange(len(y_test)) + 1 fh
以下、実行結果です。
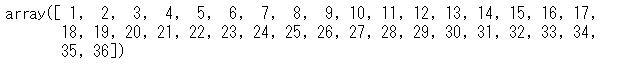
1から始まる添え字の列であることが分かります。この添え字を使い、予測を実施します。
以下、コードです。
# 予測実施 y_pred = forecaster.predict(fh)
これだけです。予測結果を見てみたいと思います。グラフ化します。
以下、コードです。
# 予測結果のグラフ化 plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
以下、実行結果です。
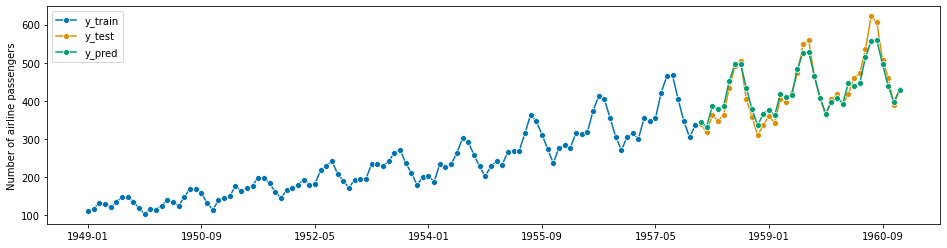
テストデータの予測精度を見てみます。
以下、コードです。
# 予測精度検証:MAPE(平均絶対パーセント誤差) mean_absolute_percentage_error(y_test, y_pred)
以下、実行結果です。
![]()
MAPEは4.1%です。
予測区間付きのグラフで描写します。
以下、コードです。
# 予測区間付き予測結果のグラフ
y_pred = forecaster.predict(fh)
pred_ints = forecaster.predict_interval(coverage=0.95)
fig, ax = plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
ax.fill_between(
ax.get_lines()[-1].get_xdata(),
pred_ints.iloc[:,0],
pred_ints.iloc[:,1],
alpha=0.2,
color=ax.get_lines()[-1].get_c(),
label=f"{0.95}% prediction intervals",
)
ax.legend()
以下、実行結果です。
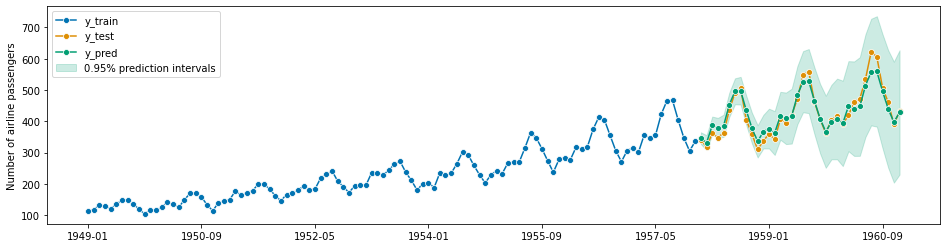
色々な時系列モデル
以下の4つの時系列モデルを構築し、予測精度の検証をします。
- ESモデル
- ETSモデル(Auto-ETS)
- TBATSモデル
- アンサンブルモデル(VotingRegressor、複数の予測器の平均を予測とする)
以下の流れで、一気に予測結果のグラフ化まで実施します。予測精度も出します。
モデル構築 → 予測 → 予測結果グラフ化 → 予測精度MAPE
ESモデル
Exponential Smoothing(指数平滑化法)です。
以下、コードです。
# ESモデル構築→予測→グラフ化→予測精度MAPE forecaster = ExponentialSmoothing(trend="add", seasonal="multiplicative", sp=12) model = forecaster.fit(y_train) y_pred = forecaster.predict(fh) plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]) mean_absolute_percentage_error(y_test, y_pred)
以下、実行結果です。
![]()
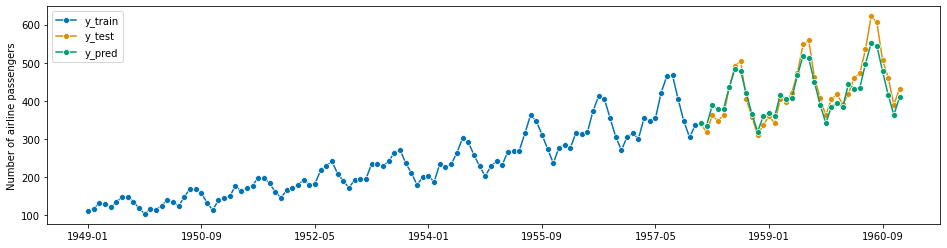
MAPEは5.1%です。
ETSモデル(Auto-ETS)
ETS(Error-Trend-Seasonality)です。状態空間モデルをベースにしている平滑化法のため、状態空間指数平滑化法(Exponential smoothing state space model)とも呼ばれています。
以下、コードです。
# ETSモデル自動構築→予測→グラフ化→予測精度MAPE forecaster = AutoETS(auto=True, sp=12, n_jobs=-1) model = forecaster.fit(y_train) y_pred = forecaster.predict(fh) plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]) mean_absolute_percentage_error(y_test, y_pred)
以下、実行結果です。
![]()
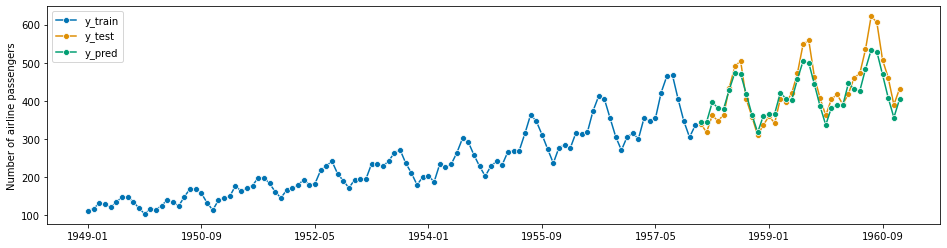
MAPEは6.2%です。
TBATSモデル
TBATS(Exponential smoothing state space model with Box-Cox transformation, ARMA errors, Trend and Seasonal components)です。
以下、コードです。
# TBATSモデル構築→予測→グラフ化→予測精度MAPE forecaster = TBATS(sp=12, use_trend=True, use_box_cox=False) forecaster.fit(y_train) y_pred = forecaster.predict(fh) plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]) mean_absolute_percentage_error(y_test, y_pred)
以下、実行結果です。
![]()
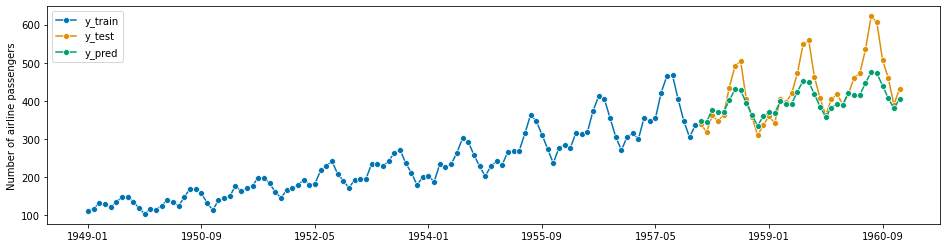
MAPEは8%です。
アンサンブルモデル
以下の4つの予測器のアンサンブルモデルを構築します。予測値は、4つの予測器の予測結果の平均値です。
- ARIMAモデル(Auto-ARIMA)
- ESモデル
- ETSモデル(Auto-ETS)
- TBATSモデル
以下、コードです。
# アンサンブルモデル構築→予測→グラフ化→予測精度MAPE
forecaster = EnsembleForecaster(
[
("ARIMA", AutoARIMA(sp=12, suppress_warnings=True)),
("ES",ExponentialSmoothing(trend="add", seasonal="multiplicative", sp=12)),
("ETS",AutoETS(auto=True, sp=12, n_jobs=-1)),
("TBATS",TBATS(sp=12, use_trend=True, use_box_cox=False))
]
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_test, y_pred)
以下、実行結果です。
![]()
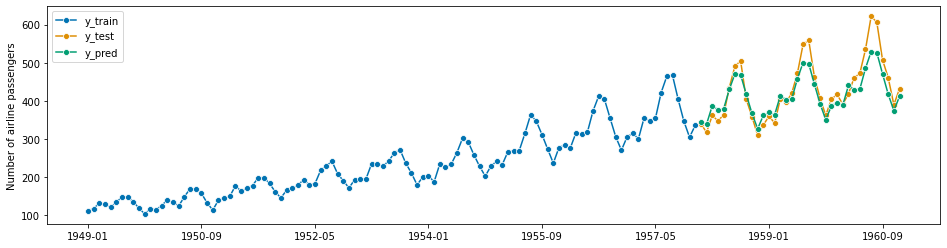
MAPEは5.6%です。
MAPEは小さい方が良いです。そう考えると、ARIMAモデル単体の予測器の予測精度が一番いいことになります。
まとめ
時系列解析のライブラリー「Sktime」を使った、時系列モデルを使った数値予測をする方法を、簡単に説明しました。
Pythonの有名な機械学習ライブラリーScikit-learn(sklearn)の時系列版のようなものです。Scikit-learn(sklearn)は時系列データではなくクロスセクショナルデータと呼ばれるテーブルデータを相手にします。
Sktimeは、Scikit-learn(sklearn)のように、回帰問題や分類問題を扱うことができます。それが、時系列版になった感じです。しかも、Scikit-learn(sklearn)と連携して動かすことができます。
sktimeについては、以下でもう少し広く複数回に渡り説明したいます。