
データ分析を実施するとき、必ずと言っていいほど実施するのが、EDA(探索的データ分析)です。
Pythonだと、Pandasを使いEDAを実施する人も、多いのではないでしょうか。しかし、PythonでEDAを実施する場合、Excelのように目で見ながらデータをいじる感覚が弱くなります。
じゃぁ、Excelの色々な機能(ピボットやパワークエリ、データ分析など)を駆使してやれば、となるかもしれません。そういうと身も蓋もないので、Pandasで実施するEDAをグラフィカルな感じ実施する、PandasGUIを紹介します。
ノーコードで実施できます。
ということで、今回は「Python PandasGUIでExcelっぽい感じでグラフィカルにEDA(探索的データ分析)」というお話しをします。
ちなみに、Excelほどではないです。
同様のものというか、PandasGUI以上のものにbamboolibというものもありますが、今回は手軽にできるPandasGUIを紹介します。
Contents [hide]
では、早速インストール
まだ、PandasGUIをインストールされていない方は、インストールしてみましょう。
以下、コードです。
pip install pandasgui
出来ること
データフレーム型のデータセットに対し、現段階(2021/4/21)実施できる機能です。

- ① DateFrame:データの中身
- ② Filters:データ抽出(クエリ)
- ③ Statistics:統計的な指標
- ④ Grapher:グラフ化
- ⑤ Reshaper:ピボット集計など
日々進化しているので、変わっているかもしれません。できることがExcelっぽいですね。
ちなみに、結果をコピー&ペーストでExcelなどに簡単に貼り付け可能で、CSVファイルなどで簡単に吐き出せます。
サンプルデータ
サンプルデータは、みんな大好きアヤメ(iris)のデータセットになります。

PandasGUIに、サンプルデータとして準備されているからです。
アヤメ(iris)のデータセットの概要については、以下を参照ください。どういったデータセットなのかを、ちょっとだけ説明しています。
■データセットの概要説明
「予測モデルは機械学習パイプライン化しよう(Python)
https://www.salesanalytics.co.jp/datascience/datascience007/
必要ライブラリーの読み込み
準備が整ったので、必要ライブラリーを読み込みます。
以下、コードです。
# ライブラリー import pandas as pd from pandasgui import show from pandasgui.datasets import iris, all_datasets #サンプルデータ
PandasGUIを使ってみよう
以下、コードです。
# アヤメ(iris) show(iris)
以下のようなGUIが表示されます。
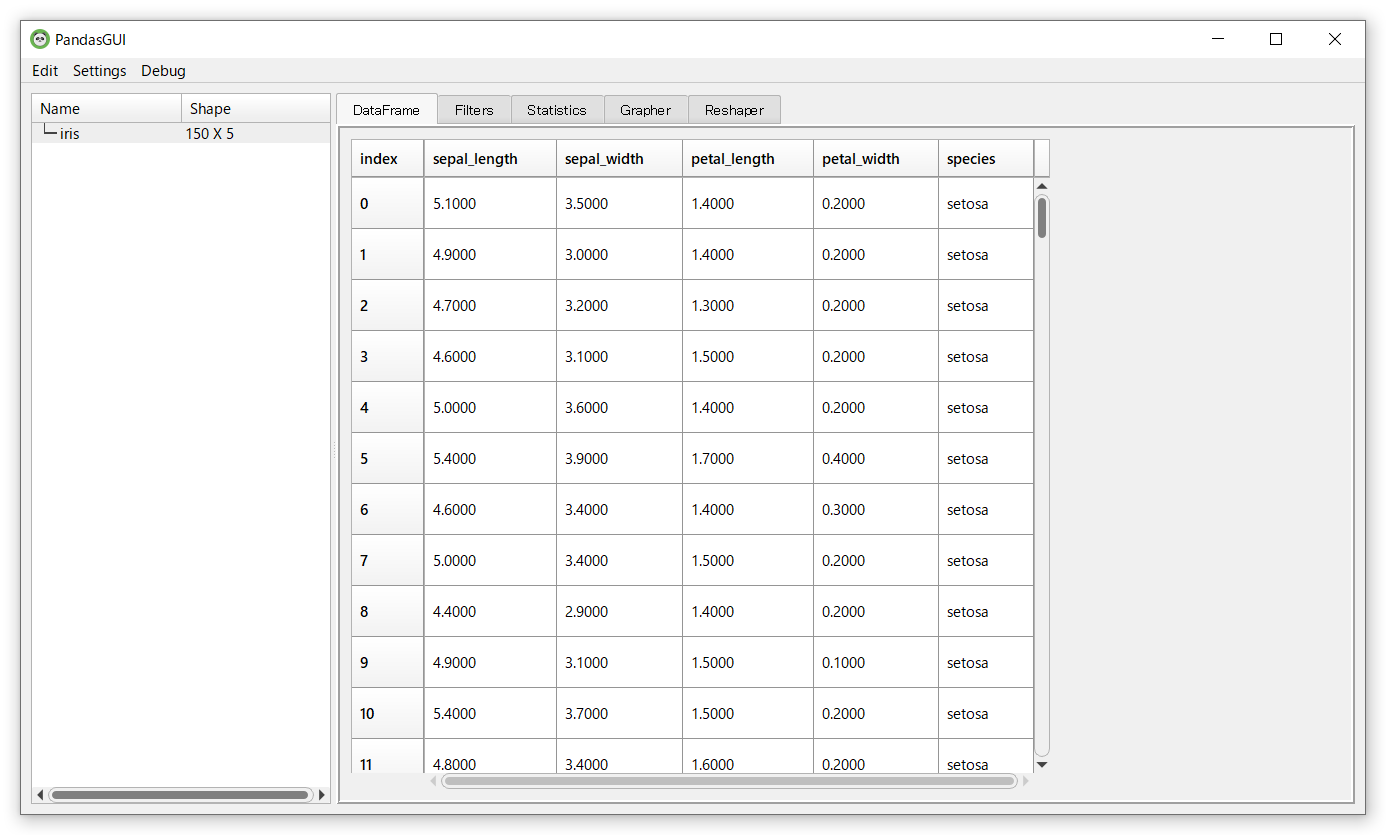
①DateFrame:データの中身
「DateFrame」タブをクリックすると、以下のように読み込んだデータセットが表示されます。
Excelのように、セルのデータの値を変更することができます(セルをダブルクリックして値を入力)。
変数名(カラム)をダブルクリックすると、その変数で昇順にソートされます。もう一度ダブルクリックすると降順にソートされます。もとに戻すには、「index」で昇順ソートにするともとに順番に戻ります。
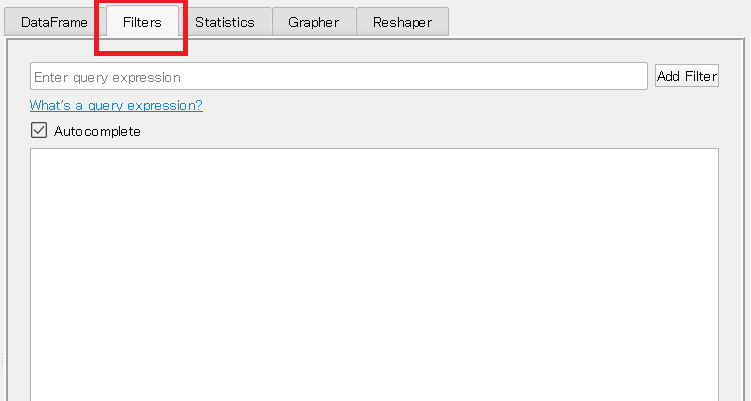
②Filters:データ抽出(クエリ)
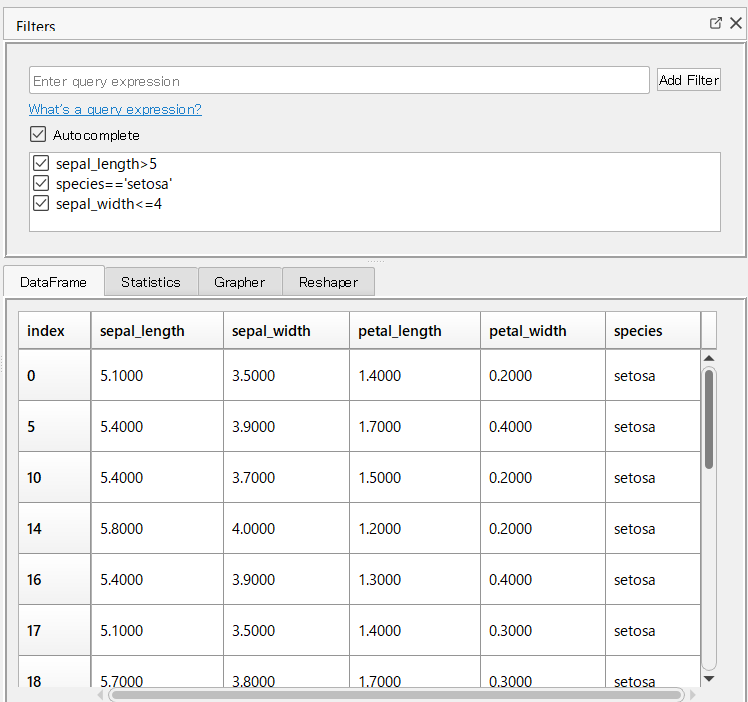
「Filters」タブをクリックすると、以下のようなデータ抽出するためのクエリを作成する画面が表示されます。
「Filters」でデータ抽出(クエリ)を実行したときに、データフレームがどう変化するのか見たいので、「Filters」タグをドラッグ&ドロップで移動し、「DateFrame」と「Filters」を分けて同時表示させたいと思います。
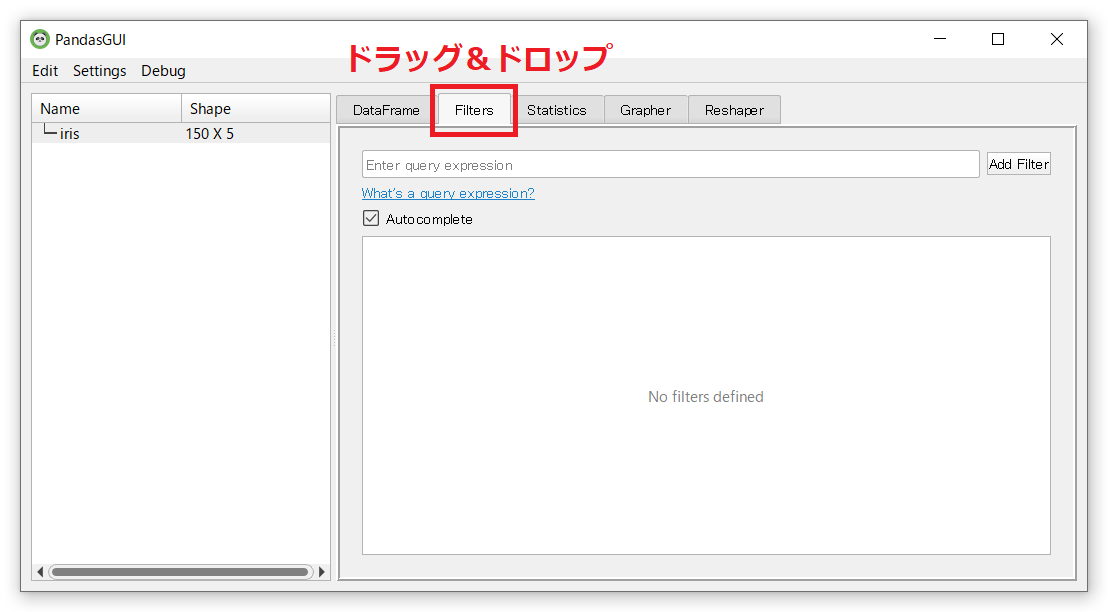
今回は、次のようにしました。上に「Filters」があり、データセットなどが下にある感じです。
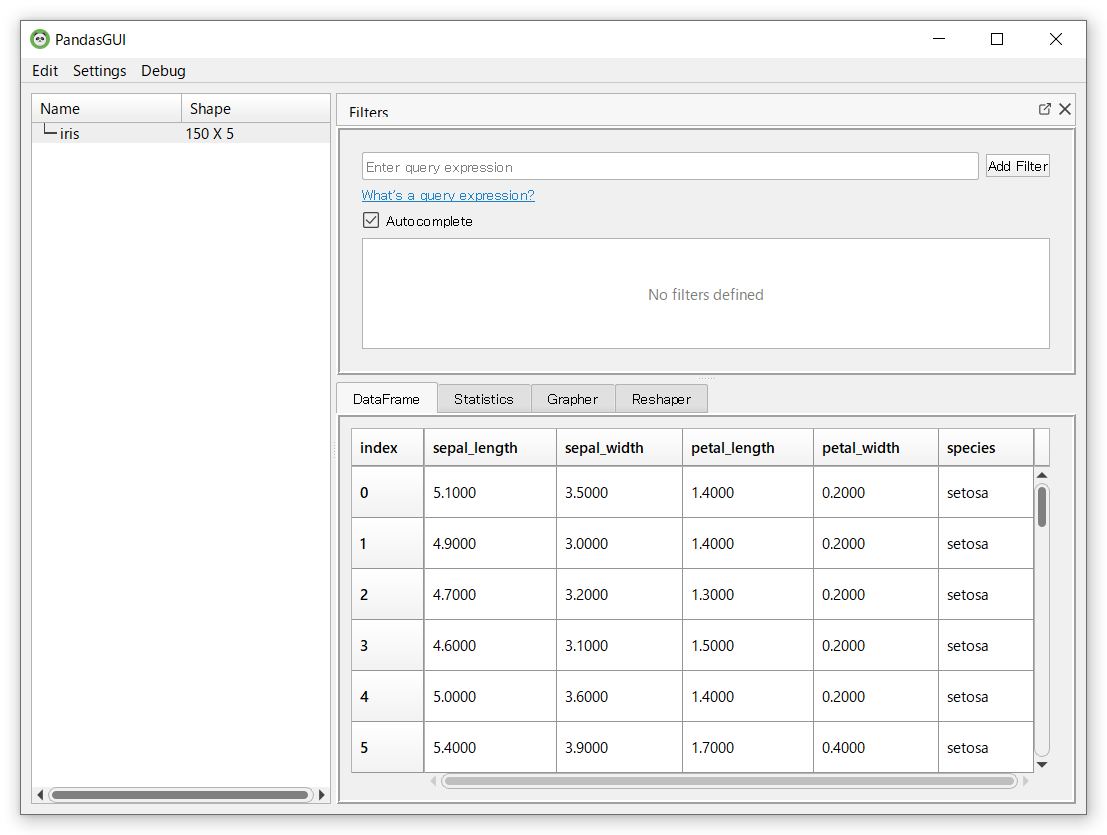
次の3つのクエリを作ってみました。
- sepal_length>5
- species==’setosa’
- sepal_width<=4
作り方は簡単です。次のように「Filters」の「Enter quer expression」のところに「sepal_length>5」と記載し「Add Filter」ボタンをクリックします。
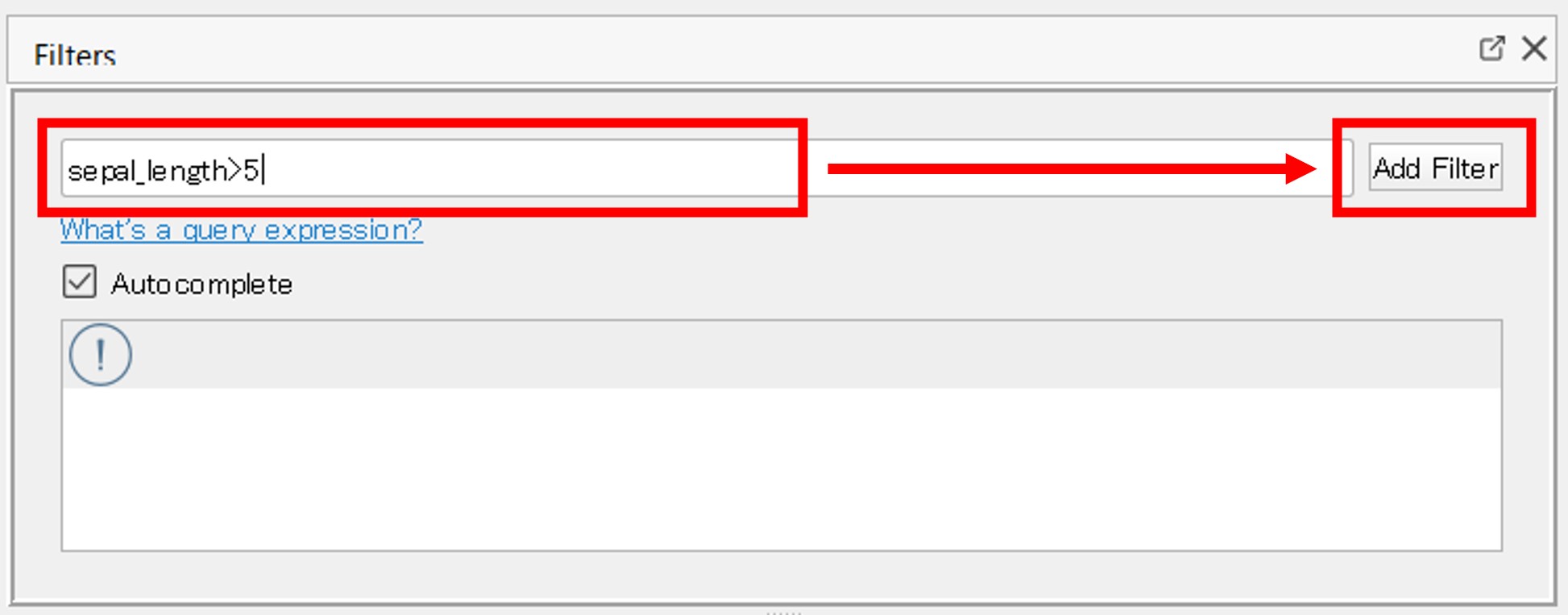
他の2つも作ってみましょう。
そうすると、作成されたクエリが、以下のように追加されます。クエリを有効にするときは、□にチェックを入れるだけです。
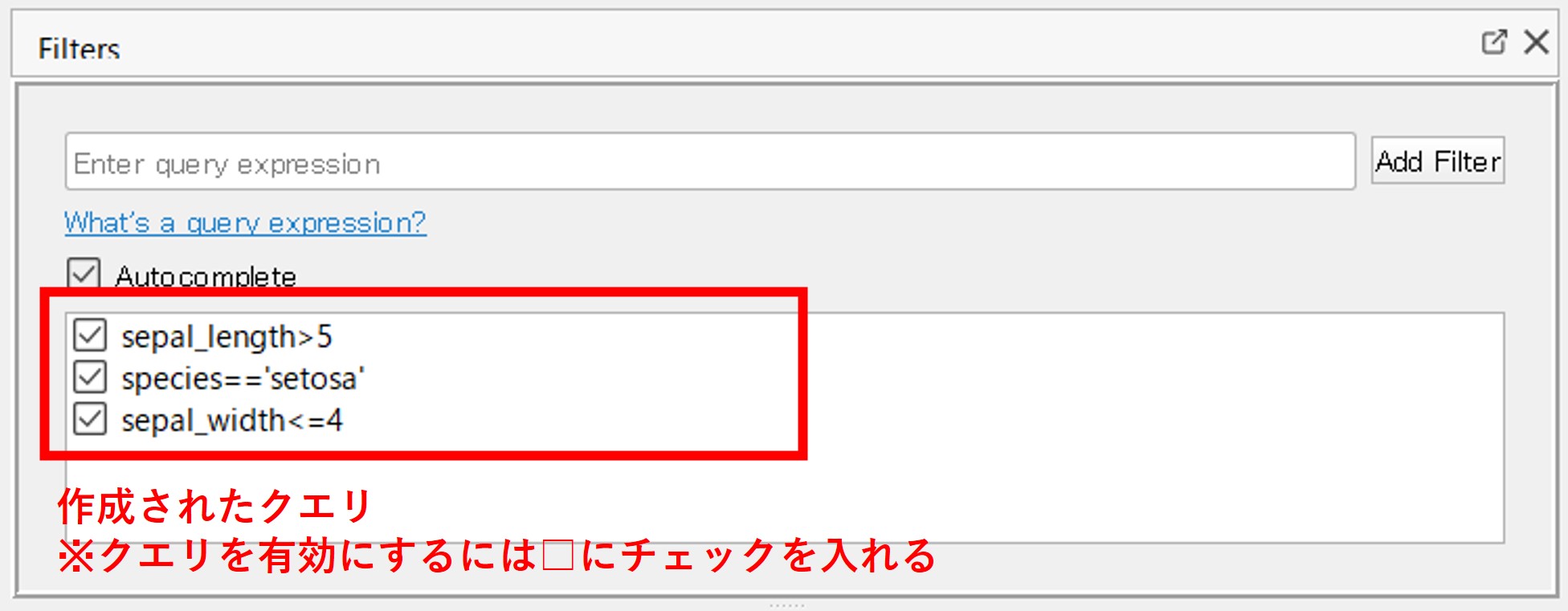
3つのクエリすべてにチェックを入れた結果、次のようになりました。
③Statistics:統計的な指標
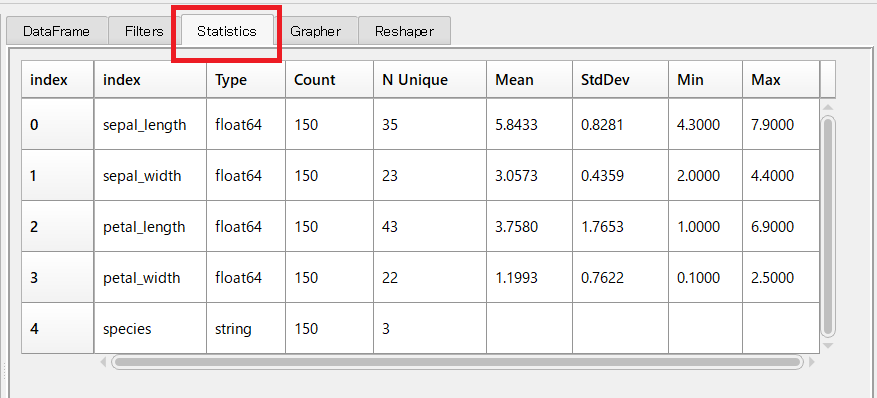
次に、各変数(カラム)の平均などの統計的な指標を見ていたいと思います。
「Statistics」タブをクリックすると、以下のような統計的指標の一覧が表示されます。
④Grapher:グラフ化
EDA(探索的データ分析)では、データをグラフ化し、データの特徴を視覚的に掴むことは多いです。
「Grapher」タブをクリックすると、以下のようなグラフを作成するための画面が表示されます。
例えば、散布図(Scatter)を作ってみたいと思います。
Scatterをクリックします。
x軸とy軸、プロットされる点のカラーを設定します。ドラッグ&ドロップで変数(カラム)を持ってきます。持ってきた変数(カラム)を削除する場合には、ダブルクリックします。
今回は、次にようにx軸とy軸、プロットされる点のカラーを設定しました。
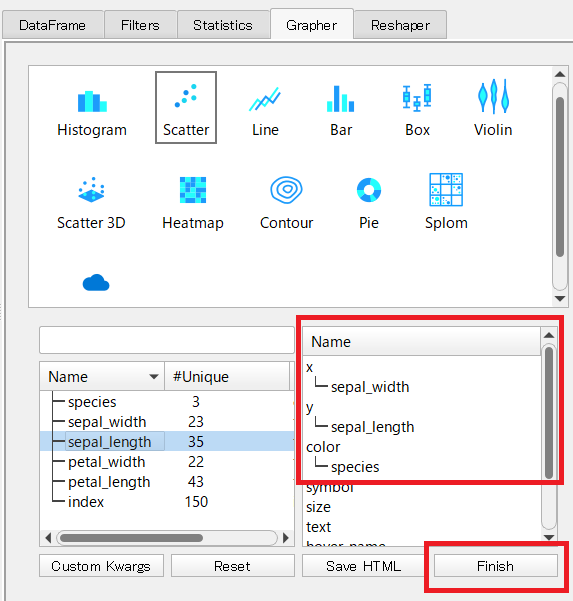
設定が終了したら、「Finish」ボタンをクリックします。
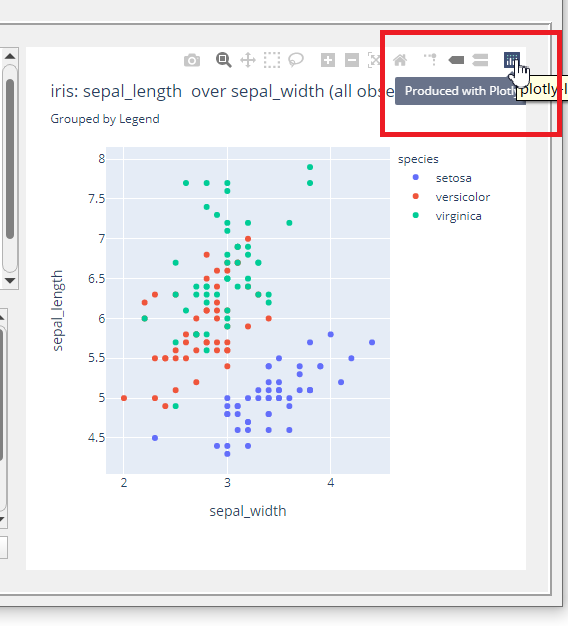
次にように表示されます。

グラフの右上にある「Produced with Plotly」をクリックすると、表示されているグラフを描くPythonのコードを記録することができます。
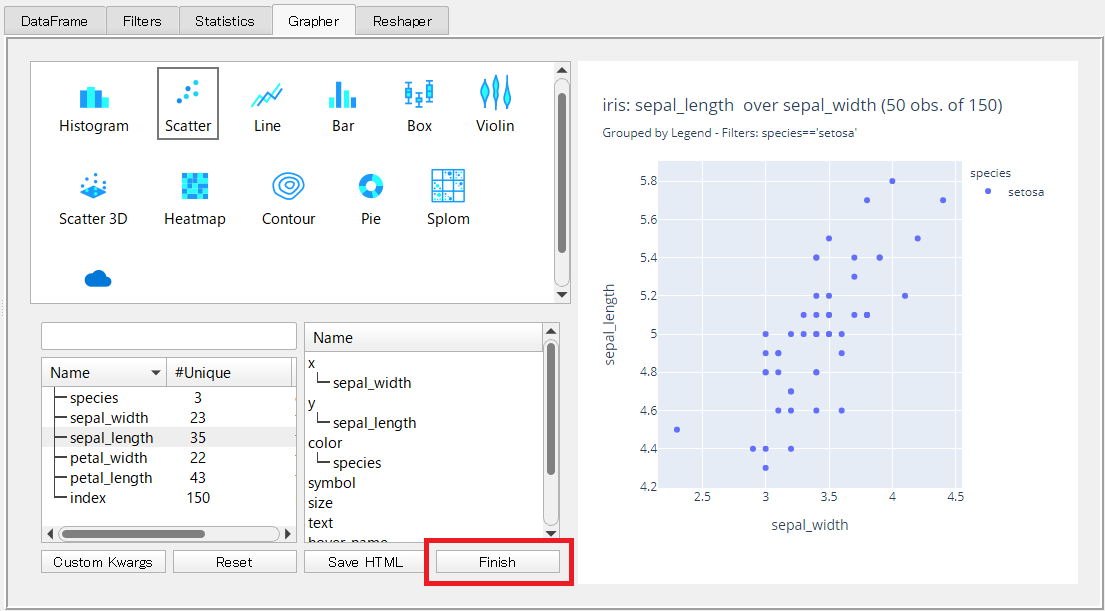
「Filters」でデータ抽出(クエリ)を実行すると、絞り込まれたデータでグラフが作成されます。
例えば、次にように「species==’setosa’」を有効にしグラフ表示したいと思います。

絞り込まれたデータでグラフを再表示する場合には、再度「Finish」ボタンをクリックします。
以下のようなグラフになりました。
⑤Reshaper:ピボット集計など
EDA(探索的データ分析)では、データをピボット集計し、データの特徴を視覚的に掴むことは多いです。
「Reshaper」タブをクリックすると、以下のようなピボット集計の設定をするための画面が表示されます。
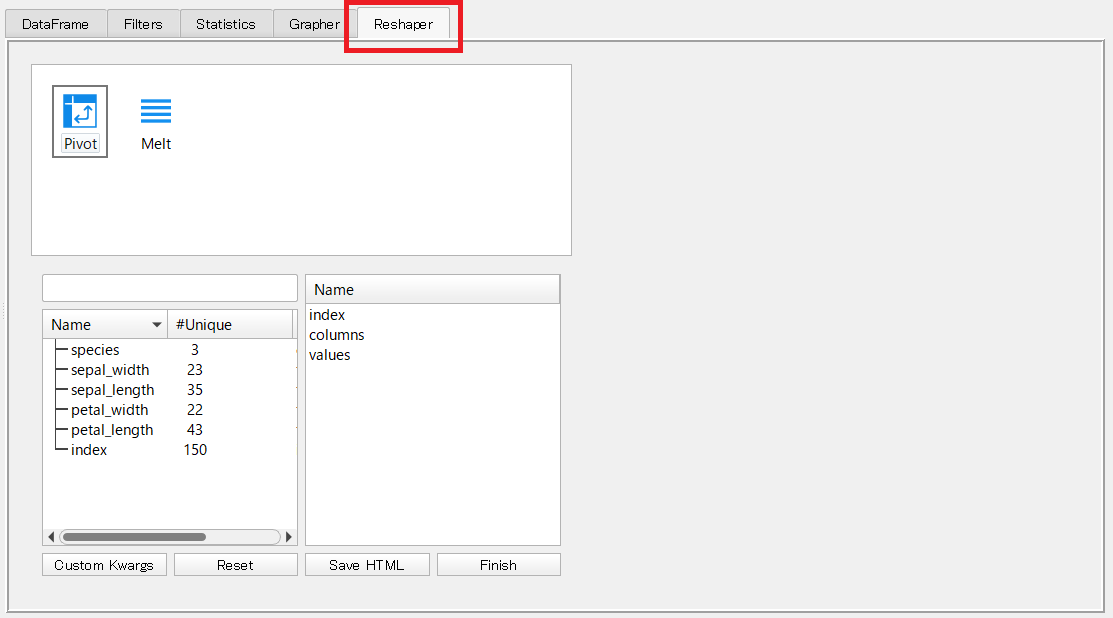
- index:表側
- columns:表頭
- values:集計対象
操作は、グラフ化のときとほぼ同じです。
今回、次にように設定しました。
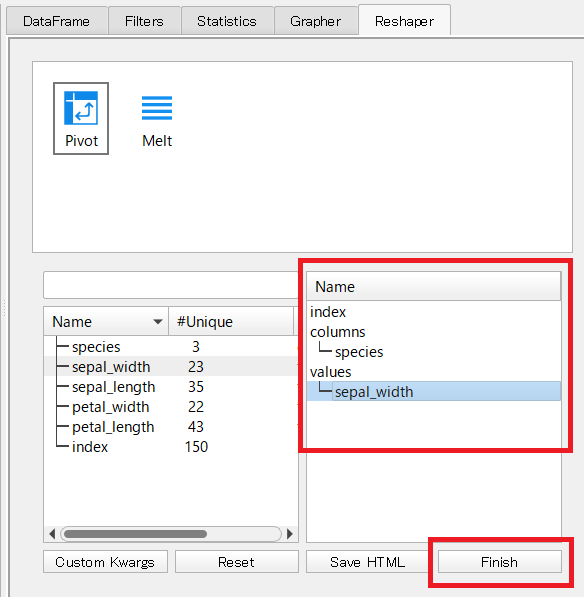
設定が終了したら、「Finish」ボタンをクリックします。
次にように表示されます。結果は、データフレーム型です。
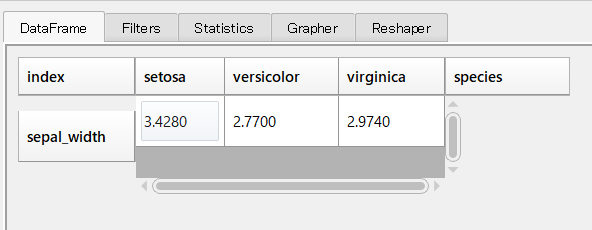
「Filters」でデータ抽出(クエリ)を実行すると、絞り込まれたデータで集計されます。
例えば、次にように「species==’setosa’」を有効にし集計したいと思います。
絞り込まれたデータで再集計する場合には、再度「Finish」ボタンをクリックします。
以下のような集計結果になりました。
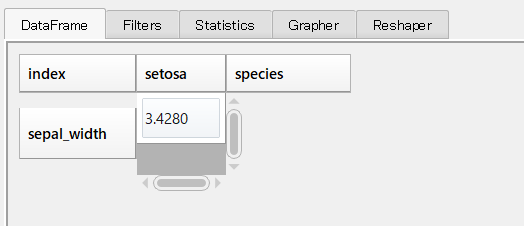
入出力
メニューバーにある「Edit」から、データを入出力したり、フィルターで抽出したデータや集計結果を出力することができます。
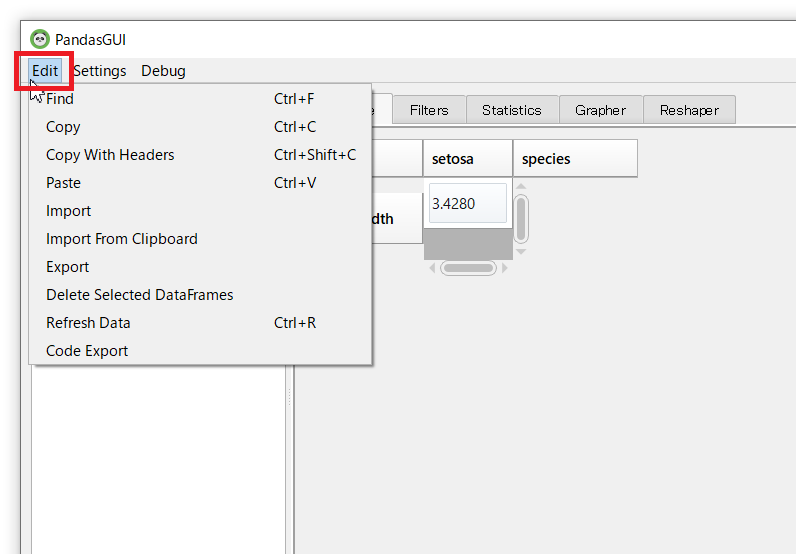
「Code Export」を選ぶと、実施した集計やグラフ作成(「Produced with Plotly」をクリックした場合)などのPyhtonコードを出力することができます。
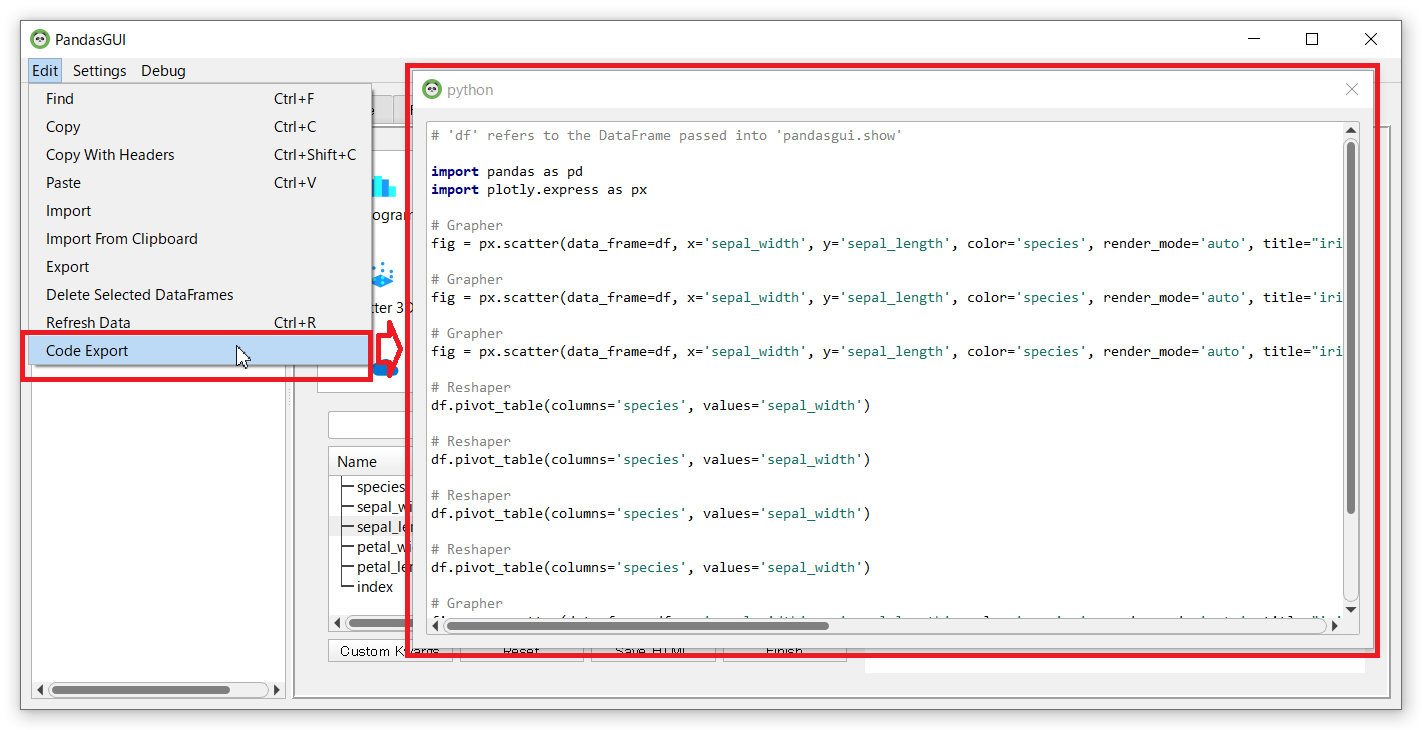
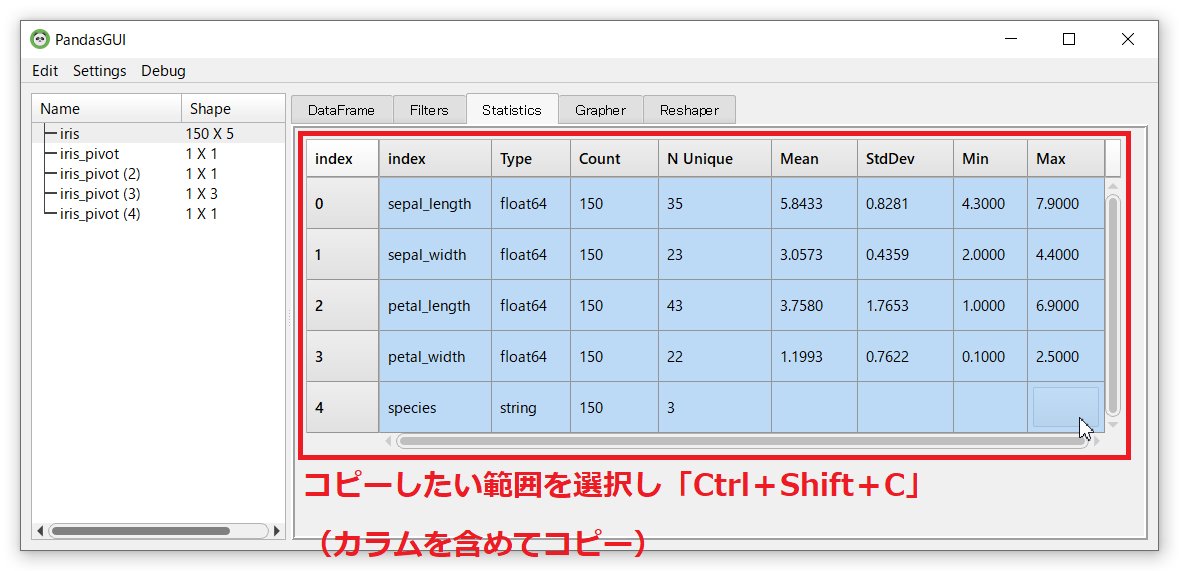
メニューバーにある「Edit」からではなく、フィルターで抽出したデータや集計結果を選択し、「Ctrl+C」(データのみコピー)もしくは「Ctrl+Shift+C」(カラムを含めてコピー)でコピーし、Excelなどにコピーしたデータを貼り付ける(「Ctrl+V」)ことができます。
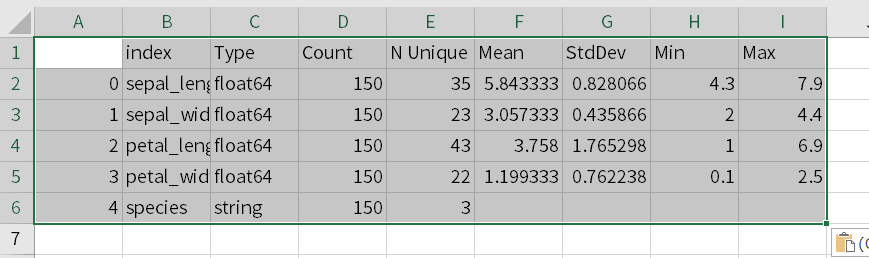
以下、Excelに張り付けた結果です(A1のセルを選択しCtrl+V)。
他にも、色々な便利な機能がありますので、試してみてください。日々進化しています。
サンプルデータすべて
複数のデータセットに対し、EDA(探索的データ分析)を実施することができます。
今回は、PandasGUIに含まれるすべてのサンプルデータ(all_datasets)を使っています。
以下、コードです。
# サンプルデータすべて show(**all_datasets)
以下、実行結果です。
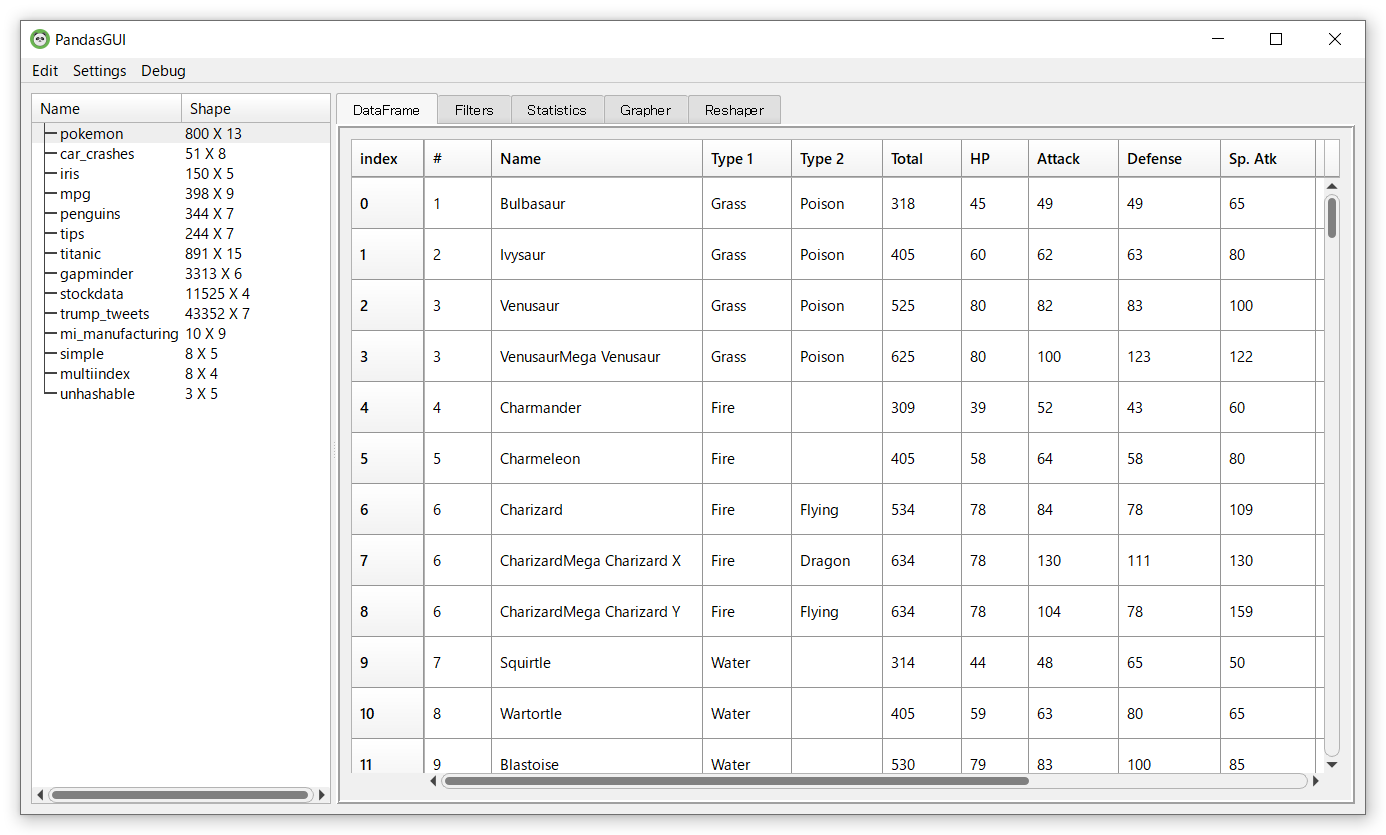
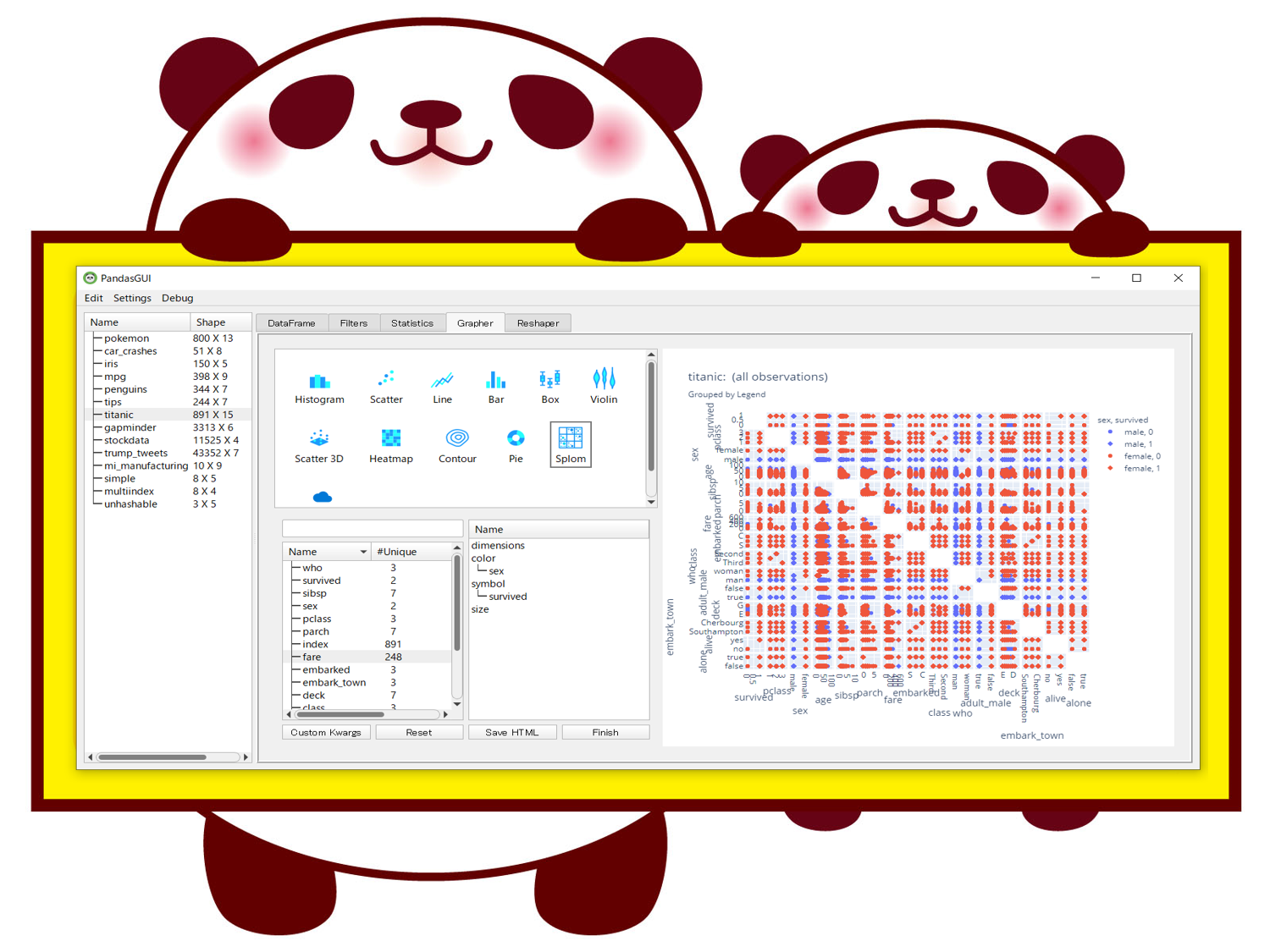
EDAを実施したいデータセットを選択すると切り替わります。以下の例は、タイタニック(titanic)に切り替えた場合です。
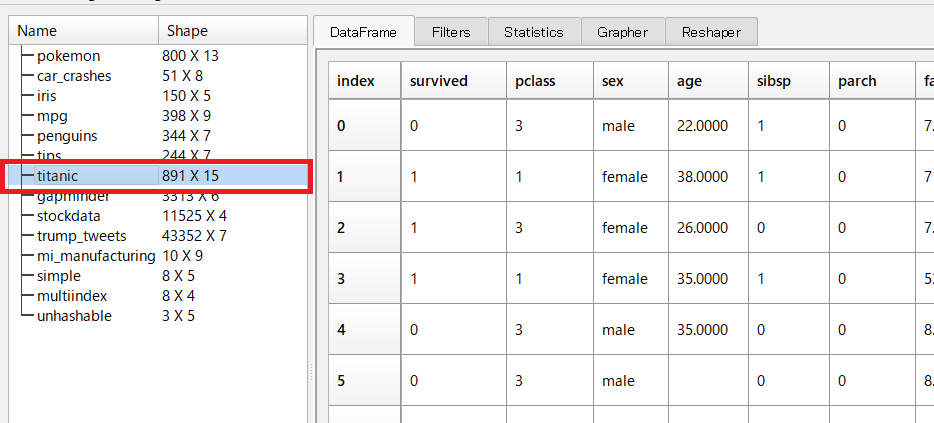
正直できる分析の種類はそれほど多くはないですが、Excelで実施するように手軽にできるのではないでしょうか。
まとめ
今回は「Python PandasGUIでExcelっぽい感じでグラフィカルにEDA(探索的データ分析)」というお話しをしました。
データ分析を実施するとき、必ずと言っていいほど実施するのが、EDA(探索的データ分析)です。
Pythonだと、Pandasを使いEDAを実施する人も、多いのではないでしょうか。
もっとグラフィカルにEDAしよう! ということで、今回はPython PandasGUIを紹介しました。
興味のある方は、試してみたください。本当に簡単にできます。