

数理モデルを作る上で特徴量エンジニアリング(Feature Engineering)は地味に重要です。
例えば、より精度の高い予測モデルを構築したいのであれば、アルゴリズムのパラメータチューニングとともに特徴量エンジニアリング(Feature Engineering)に注力したほうがいいでしょう。
Pythonに幾つかの自動特徴量エンジニアリング(Automatic Feature Engineering)のためのパッケージがあります。
その中の1つに「AutoFeat」というものがあります。回帰問題と分類問題で利用できます。
前回は、回帰問題に対し「AutoFeat」を自動特徴量エンジニアリング(Automatic Feature Engineering)のお話しをしました。「AutoFeat」のインストール方法などを含め知りたい方は、以下の前回記事を参考にして頂ければと思います。
今回は、AutoFeatを使った「分類問題」での使用方法や手順などを簡単に説明します。
数理モデルのアルゴリズム
AutoFeatの分類問題に対するアルゴリズムは、ロジスティック回帰という分類問題で最もオーソドックスなものです。
ただ、AutoFeatはclass_weightというパラメータにbalancedと指定しています。分類問題のクラスの数に偏りがある場合に、クラスごとの重みを調整するどうかを指定するパラメータでデフォルトは「None」(無調整)です。
分類問題のクラスとは、例えば受注を予測するモデルの場合、受注と失注がクラスです(受注クラス・失注クラス)。どちらかのクラスの数が極端に少ない場合があります。例えば、10,000件中、受注が100件で失注が9,900件の場合です。すべて失注と予測すると、正答率は99%になります。永久に受注を予測できないモデルが出来上がります。このようなことにならないようクラスごとの重みを調整し、クラスの数に偏りを緩和する必要があります。そのやり方の1つが、「class_weight=’balanced’」とすることです。他にもやり方はありますが、本題とは無関係なので割愛します。
ちなみに、AutoFeatのロジスティック回帰はScikit-Learn(sklearn)のものを使っています。
データセット
今回はscikit-learnから提供されている乳がんの診断結果のデータセットを使います。
目的変数Yは、悪性クラスと良性クラスを表す以下の2値データです。
- 悪性(=0)
- 良性(=1)
特徴量は、以下の10変数です。
- radius:細胞核の中心から外周までの距離
- texture:画像のグレースケールの標準偏差
- perimeter:細胞核周囲の長さ
- area:細胞核の面積
- smoothness:細胞核の直径の局所分散値
- compactness:perimeter^2/area – 1.0で計算される値
- concavity:輪郭の凹面度の重大度
- concave point:輪郭の凹面部の数
- symmetry:対称性
構築するモデル
今回は、4つのモデルを構築してみます。
| 特徴量X | モデル構築 | |
| モデル1 | 元の特徴量 | ロジスティック回帰 |
| モデル2 | AutoFeatで自動生成した特徴量 | ロジスティック回帰 |
| モデル3 | 元の特徴量 | AutoML TPOTで自動構築 |
| モデル4 | AutoFeatで自動生成した特徴量 | AutoML TPOTで自動構築 |
AutoML(自動機械学習)やTPOTに関しては、以下を参考にして頂ければと思います。AutoML(自動機械学習)TPOTは、単により最適な予測モデルを自動構築するだけでなく、パイプライン全体を最適化するので、特徴量エンジニアリング(Feature Engineering)を一部自動化しています。
モデル1と2を構築し検証する
次の2つのモデルを学習データで構築し、構築したモデルをテストデータで精度検証(accuracy:正答率)します。
- モデル1:元の特徴量を使ったロジスティック回帰モデル
- モデル2:AutoFeatで自動生成した特徴量を使ったロジスティック回帰モデル
先ず、必要なライブラリーを読み込みます。
以下、コードです。
# ライブラリーの読み込み import pandas as pd from autofeat import AutoFeatClassifier from sklearn.model_selection import train_test_split from sklearn.datasets import load_breast_cancer from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score, confusion_matrix
次に、データセットを読み込みます。
以下、コードです。
# データセットの読み込み load_breast_cancer = load_breast_cancer(as_frame=True) X = load_breast_cancer.data y = load_breast_cancer.target
データセットを、学習データとテストデータに分割します。
以下、コードです。
# データセットの分割(学習データとテストデータ)
X_train, X_test, y_train, y_test = train_test_split(X,
y,
train_size=0.7,
test_size=0.3,
random_state=42)
- 学習データ
- 特徴量:X_train
- 目的変数:y_train
- テストデータ
- 特徴量:X_test
- 目的変数:y_test
AutoFeatの特徴量エンジニアリングのモデルを定義します。
以下、コードです。
# モデル定義 model = AutoFeatClassifier(verbose=1)
今回は分類問題なので「AutoFeatClassifier」です。
実行経過を表示させるverboseはデフォルトでは「0」(表示しない)ですが、ここでは簡易的な表示をさせるために「1」にしています。これらは何も設定しないとデフォルトの状態で実行されます。
では、自動特徴量エンジニアリング(Automatic Feature Engineering)を実行します。
以下、コードです。
# 特徴量生成(学習データ利用) X_train_feature_creation = model.fit_transform(X_train, y_train)
以下、実行結果です。

自動生成した特徴量は、X_train_feature_creationに格納しています。確認してみます。
以下、コードです。
X_train_feature_creation #確認用
以下、実行結果です。
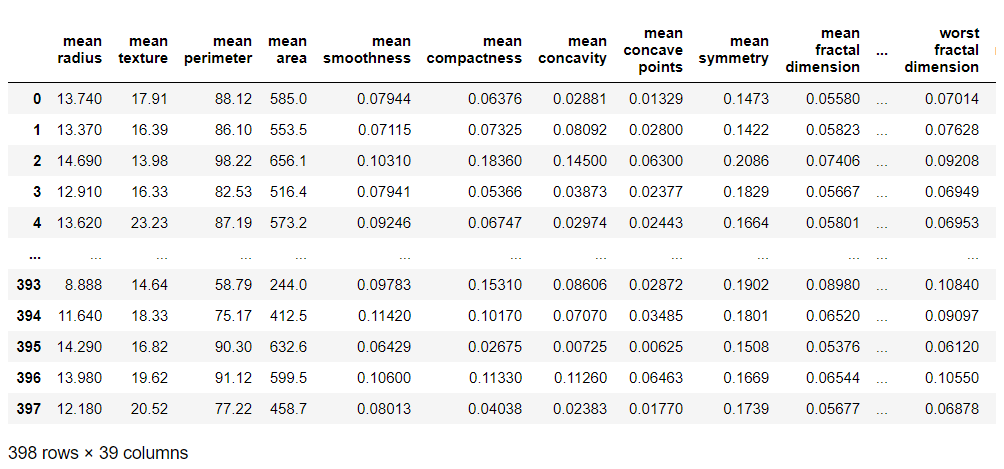
どのような特徴量が自動生成されたのかが分かると思います。
一覧で出してみます。
以下、コードです。
X_train_feature_creation.columns #生成された特徴量X
以下、実行結果です。

数を確認してみます。
以下、コードです。
print("number of features in X_train:", #元の特徴量Xの数
X_train.shape[1])
print("number of features in X_train_feature_creation:",
X_train_feature_creation.shape[1]) #新しい特徴量Xの数
以下、実行結果です。

元の特徴量は30個でしたが、AutoFeatによる特徴量の自動生成で9個の特徴量が新たに追加され、結果的に39個の特徴量になりました。
この自動生成した特徴量と同じ特徴量のテストデータを作ります。X_test_feature_creationに格納します。
以下、コードです。
# テストデータの特徴量生成 X_test_feature_creation = model.transform(X_test)
元の特徴量のデータセット(X_trainとy_train)と新たな特徴量のデータセット(X_train_feature_creationとy_train)で、ロジスティック回帰モデルを構築してみます。
以下、コードです。
# モデル構築 ## model_1 model_1 = LogisticRegression(class_weight='balanced') model_1.fit(X_train,y_train) ## model_2 model_2 = LogisticRegression(class_weight='balanced') model_2.fit(X_train_feature_creation, y_train)
では、テストデータを使いそれぞれのモデルの精度(accuracy:正答率)を比較してみたいと思います。
以下、コードです。
# 評価(accuracy, confusion matrix)
print("model_1 accuracy:%.4f" % accuracy_score(y_test,
model_1.predict(X_test)) )
print(confusion_matrix(y_pred=model_1.predict(X_test),
y_true=y_test))
print("model_2 accuracy:%.4f" % accuracy_score(y_test,
model_2.predict(X_test_feature_creation)))
print(confusion_matrix(y_pred=model_2.predict(X_test_feature_creation),
y_true=y_test))
以下、実行結果です。

model_1の「モデル1:元の特徴量を使ったロジスティック回帰モデル」です。accuracy(正答率)は97.08%です。

この段階で、非常に高精度です。特徴量の自動生成の成果はどうでしょうか?
model_2の「モデル2:AutoFeatで自動生成した特徴量を使ったロジスティック回帰モデル」の精度も高く、accuracy(正答率)は97.66%です。

AutoML(自動機械学習)TPOTでモデル構築(モデル3と4)
おまけの意味合いが強いですが、次の2つのモデルを学習データで構築し、構築したモデルをテストデータで精度検証(accuracy:正答率)します。
- モデル3:元の特徴量を使いAutoML(自動機械学習)TPOTで自動構築したモデル
- モデル4:AutoFeatで自動生成した特徴量を使ってAutoML(自動機械学習)TPOTで自動構築したモデル
どうなるでしょうか?
先ず、モデル3です。元の特徴量を使いモデルを自動構築します。
以下、コードです。
# 必要なライブラリの読み込み
from tpot import TPOTClassifier
# POTClassifierの設定
tpot = TPOTClassifier(scoring='accuracy',
generations=5,
population_size=50,
verbosity=2,
n_jobs=-1)
# モデル構築
tpot.fit(X_train, y_train)
# 評価(accuracy, confusion matrix)
print("accuracy: %.4f" % accuracy_score(y_test, tpot.predict(X_test)))
print(confusion_matrix(y_pred=tpot.predict(X_test),y_true=y_test))
以下、実行結果です。
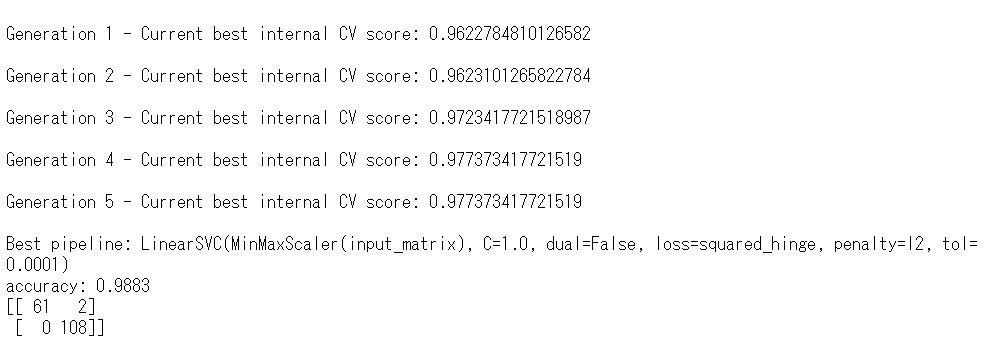
下のほうにaccuracy(正答率)があります。98.83%です。かなりいいですね。

次に、モデル4です。AutoFeatで自動生成した特徴量を使ってモデルを自動構築します。
以下、コードです。
# POTClassifierの設定
tpot2 = TPOTClassifier(scoring='accuracy',
generations=5,
population_size=50,
verbosity=2,
n_jobs=-1)
# モデル構築
tpot2.fit(X_train_feature_creation, y_train)
# 評価(accuracy, confusion matrix)
print("accuracy: %.4f" % accuracy_score(y_test, tpot2.predict(X_test_feature_creation)))
print(confusion_matrix(y_pred=tpot2.predict(X_test_feature_creation),y_true=y_test))
以下、実行結果です。
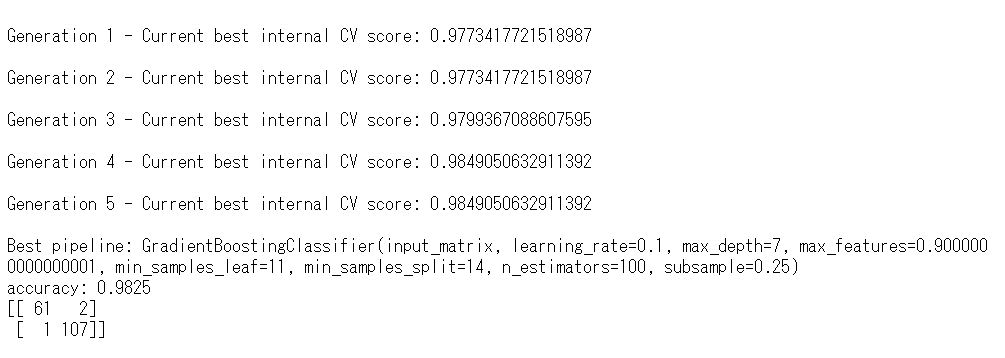
下のほうにaccuracy(正答率)があります。98.25%です。かなりいいですね。

正直、AutoML(自動機械学習)TPOTでモデル構築するなら、事前に特徴量を自動生成しなくてもよさそうですね(断言はできませんが……)。
まとめると、今回は次にようになりました。
| 特徴量X | モデル構築 | accuracy (正答率) |
|
| モデル1 | 元の特徴量 | ロジスティック回帰 | 97.08% |
| モデル2 | AutoFeatで自動生成した特徴量 | ロジスティック回帰 | 97.66% |
| モデル3 | 元の特徴量 | AutoML TPOTで自動構築 | 98.83% |
| モデル4 | AutoFeatで自動生成した特徴量 | AutoML TPOTで自動構築 | 98.25% |
次回
前回は分類問題で、今回は回帰問題でした。
人によっては、特徴量選択の機能だけ使いたい、という方もいるかもしれません。次回は、特徴量選択の機能だけ使う場合のやり方について、簡単に説明します。
PythonのAutoFeatを使った自動特徴量エンジニアリング(Automatic Feature Engineering)その3(特徴量選択だけ使う)