
データ分析や予測モデル構築などをやってみたいが……
- RやPythonだとの無料ツールはコーディングスキルがそれなりに必要になりハードルがある
- 有料ツールのSASやSPSSなどは使いやすそうだけど高額すぎる。
無料で使える使いやすさが有料級の分析ツールはないだろうか?
と言うことで、Radiantです。
Radiantは、ノーコードでビジネスデータ分析を可能にする無料で使える有料級Rパッケージです。
- その1:Radiantのインストール・起動・終了
- その2:Radiantのデータ読み込み
- その3:Radiantでデータ抽出(絞り込み)
- その4:RadiantでEDA(探索的データ分析)
- その4-1 グラフ作成
- その4-2 ピボット集計
- その4-3 記述統計量
- その5:Radiantで予測モデル構築
- その5-1 学習データとテストデータへの分割 ⇒ 今回
- その5-2 回帰問題(線形回帰・回帰木・XGBoost)
- その5-3 分類問題(ロジスティック回帰・ランダムフォレスト・ニューラルネット)
前回は、その4-3の「記述統計量」について簡単に説明しました。
今回は、その5の「Radiantで予測モデル構築」の「その5-1 学習データとテストデータへの分割」について簡単に説明します。
Contents [hide]
サンプルデータ
サンプルデータは、Radiantのサンプルデータである「ダイアモンド(diamonds)」と「タイタニック(titanic)」をそのまま使い、学習データとテストデータへ分割した場合の例を説明します。
- その5-2の「回帰問題(線形回帰・回帰木・XGBoost)」で、「ダイアモンド(diamonds)」を分割したて作った学習データとテストデータを使います
- その5-3の「分類問題(多項ロジスティック回帰・決定木・ニューラルネット)」で、「ダイアモンド(diamonds)」を分割したて作った学習データとテストデータを使います
ちなみに、「ダイアモンド(diamonds)」の方でやや詳しく説明します。
取り急ぎRadiantを起動
以下、コードです。
# 必要パッケージのロード library(radiant) # radiantの起動 radiant()
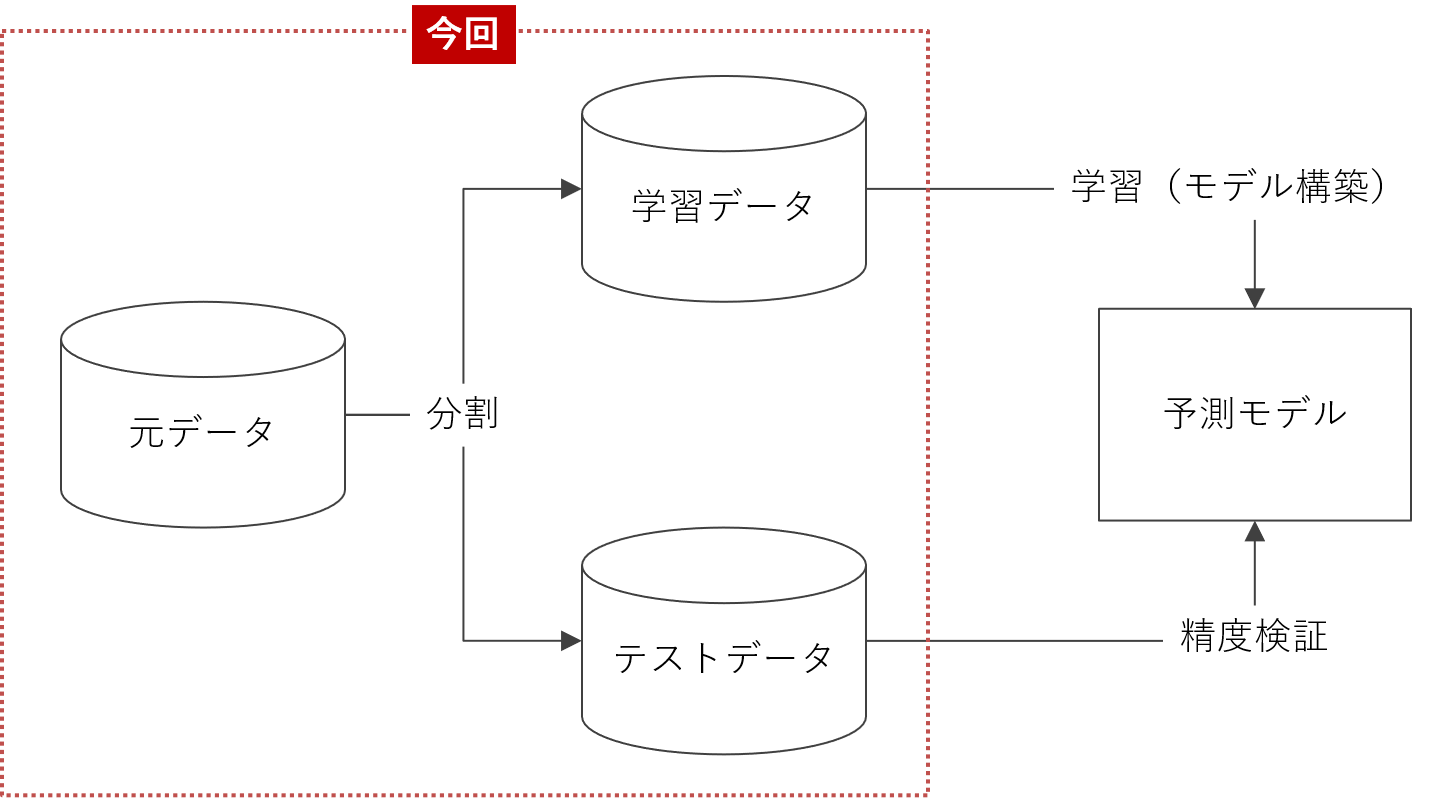
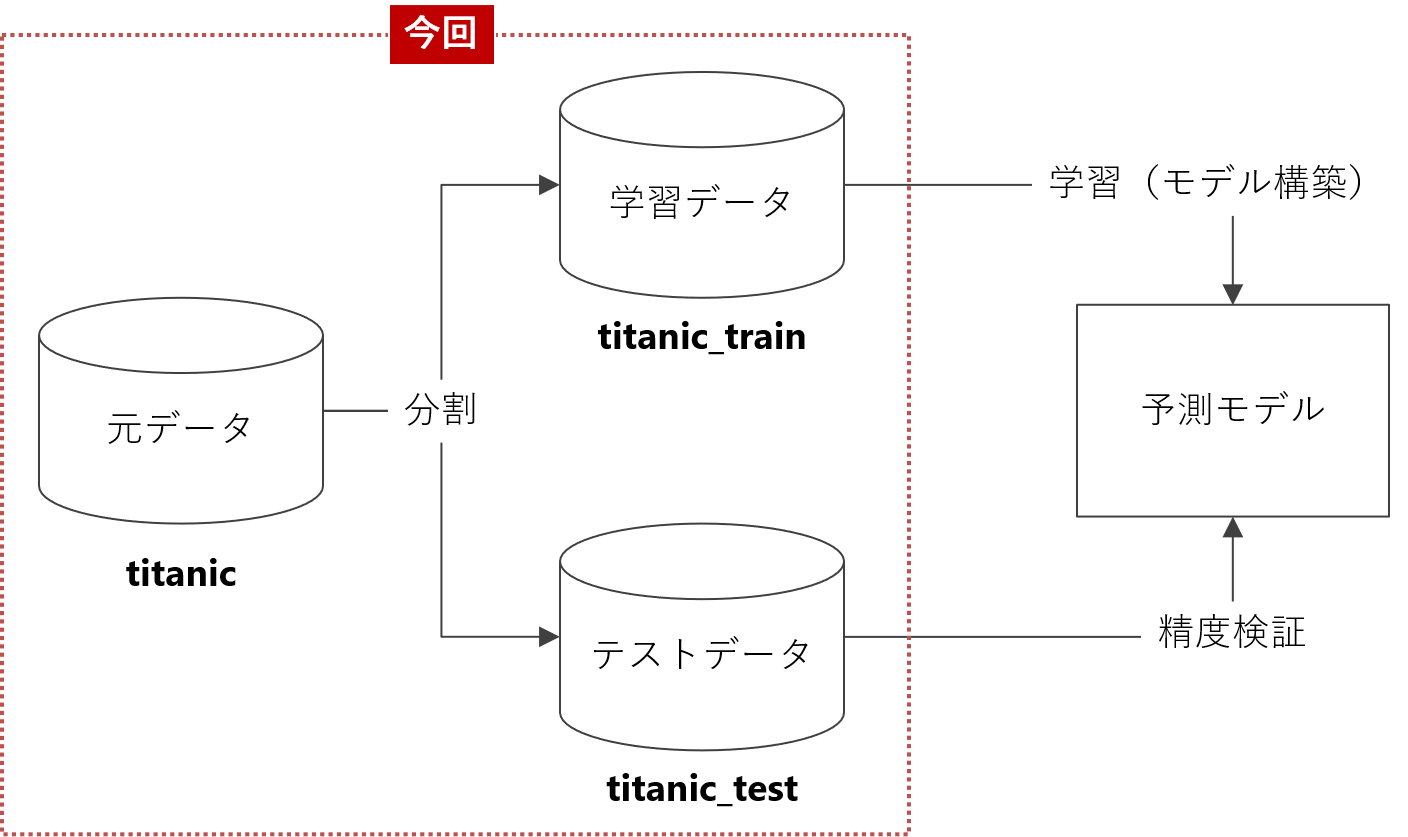
Radiantで学習データとテストデータに分割する流れ
以下、データを学習データとテストデータに分割する流れです。
- ①フラグ変数(training)の生成
- ②データ分割(学習データとテストデータ)
先ず、データを2つに分割する(学習データとテストデータ)ためのフラグ変数(training)を作ります。次に、作ったフラグ変数(training)を使い、学習データ(train)とテストデータ(test)に分割します。
ダイアモンド(diamonds)データを分割
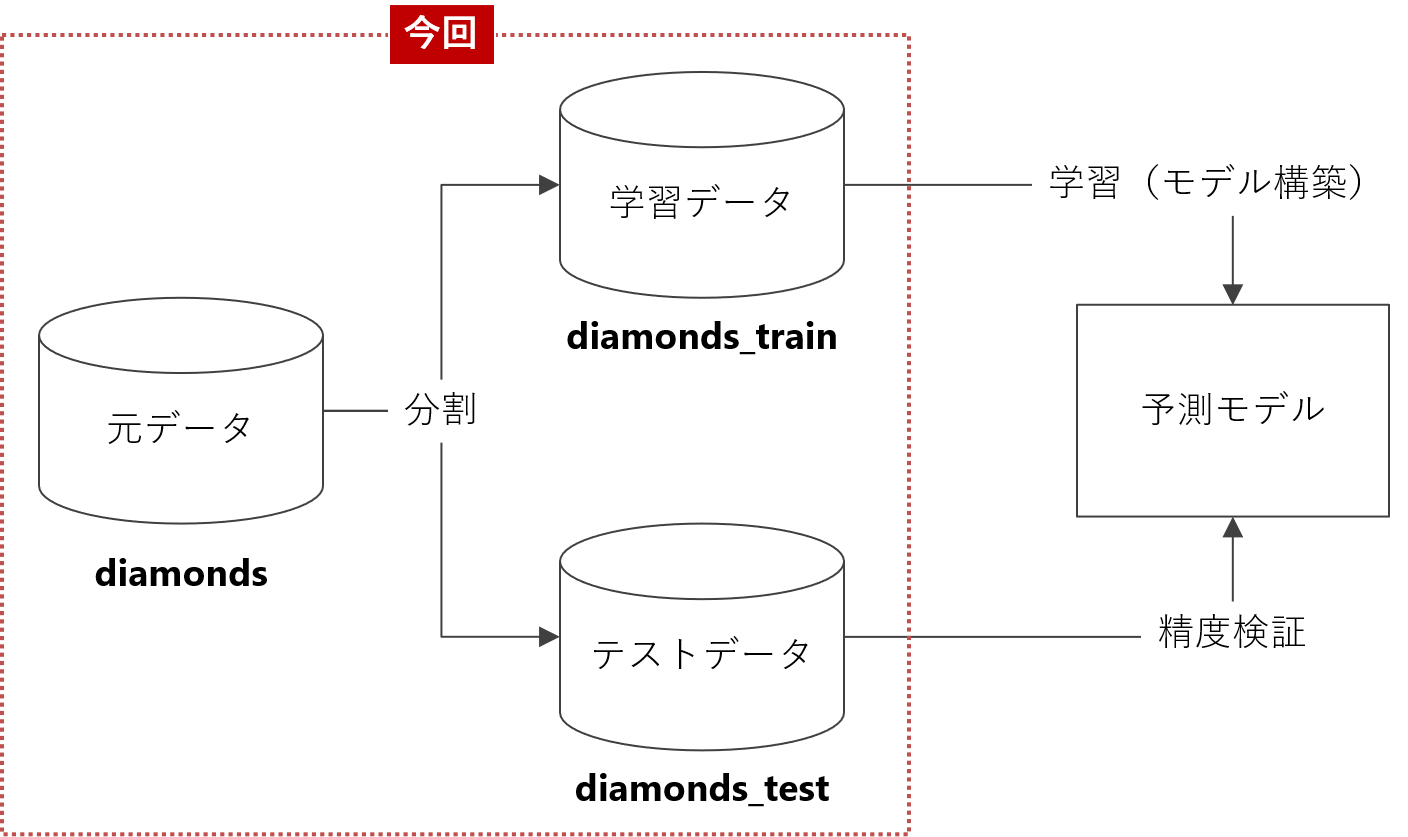
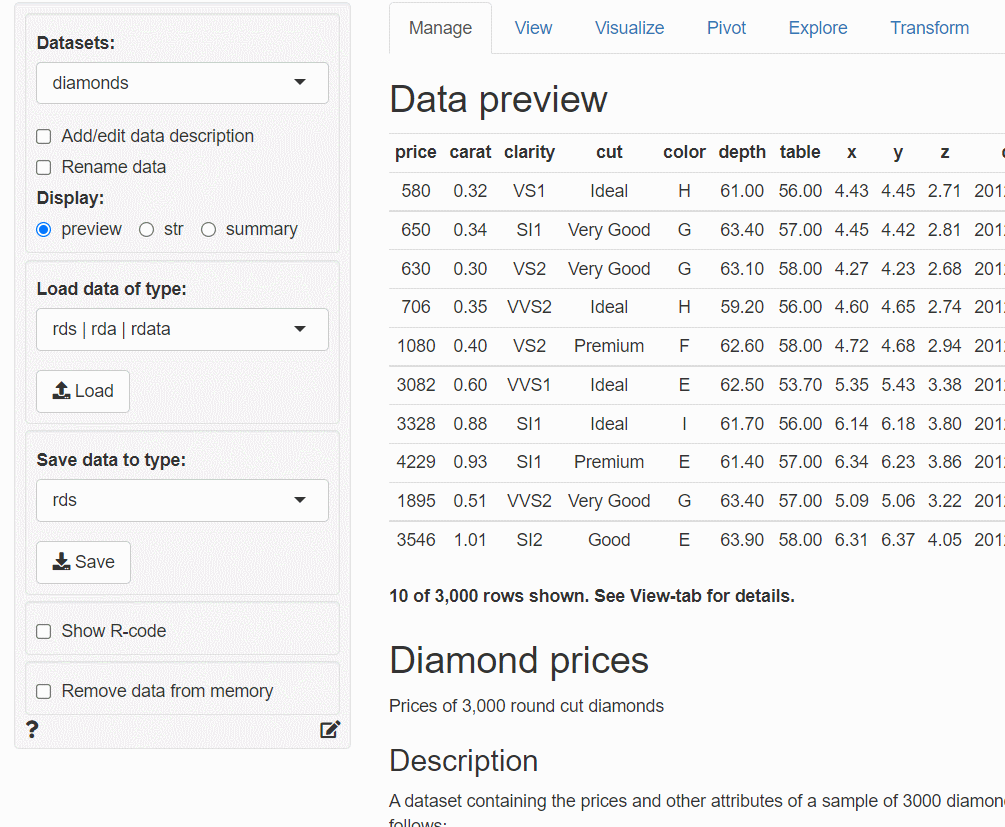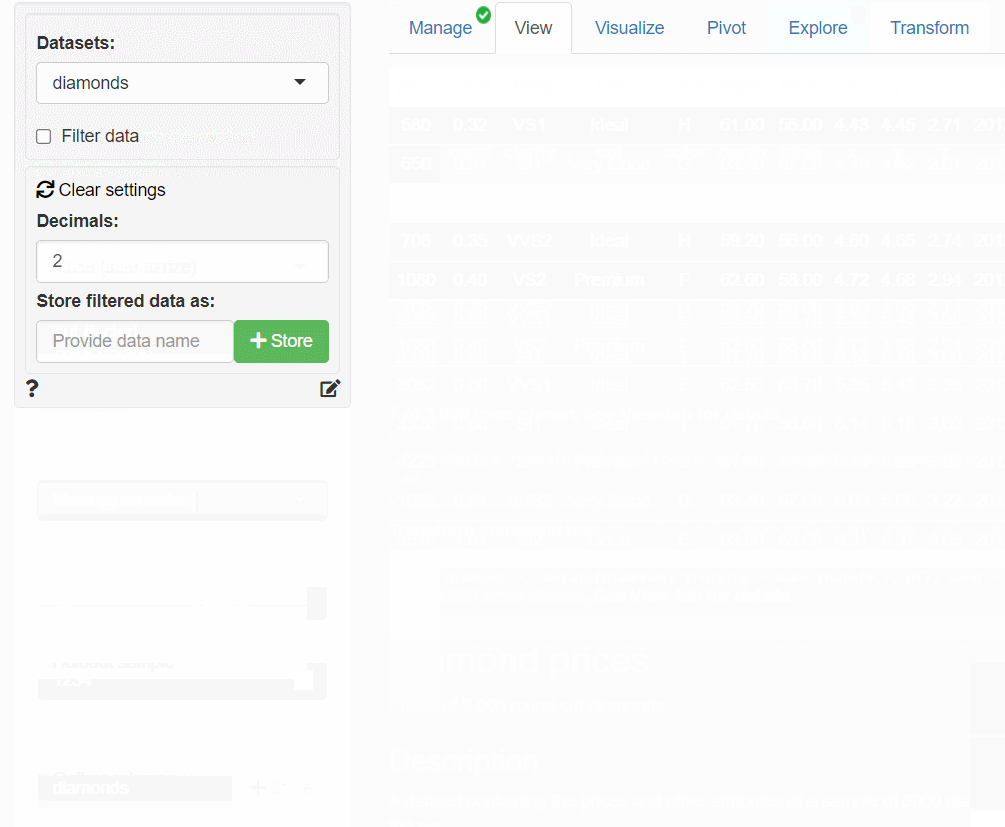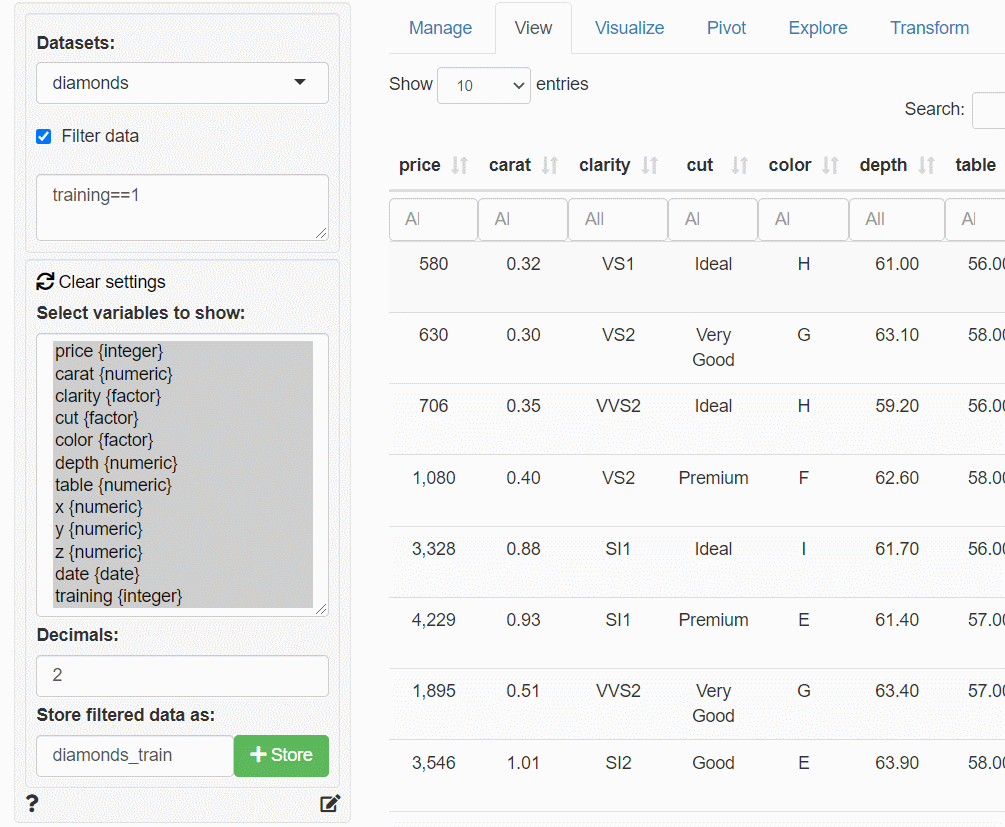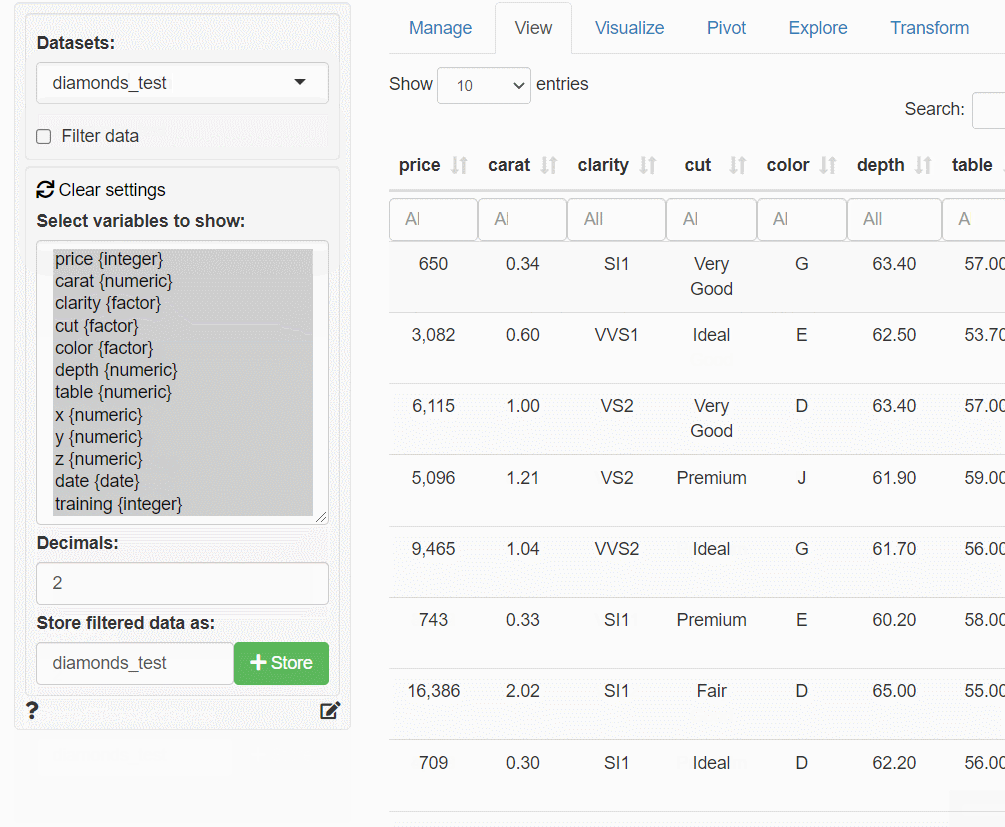
①フラグ変数(training)の生成
では、データを2つに分割する(学習データとテストデータ)ためのフラグ変数(training)を作ります。
メニューの「Transform」ボタンをクリックし、変数変換画面(Transform)を表示させます。
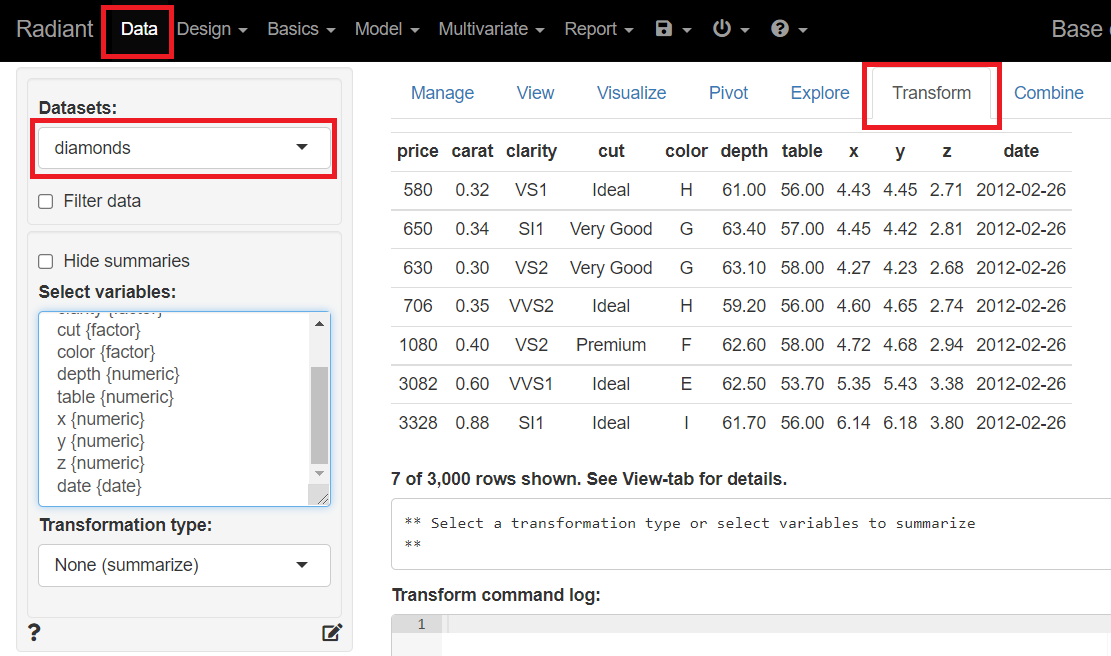
左下の「Transformation type」から「Training variable」を選択します。次のような画面が表示されるので、どのような分割をするのかを設定(例えば、Sizeで学習データの割合を指定)し、「Store changes in」の「+Store」ボタンをクリックし新変数「training」を追加します。
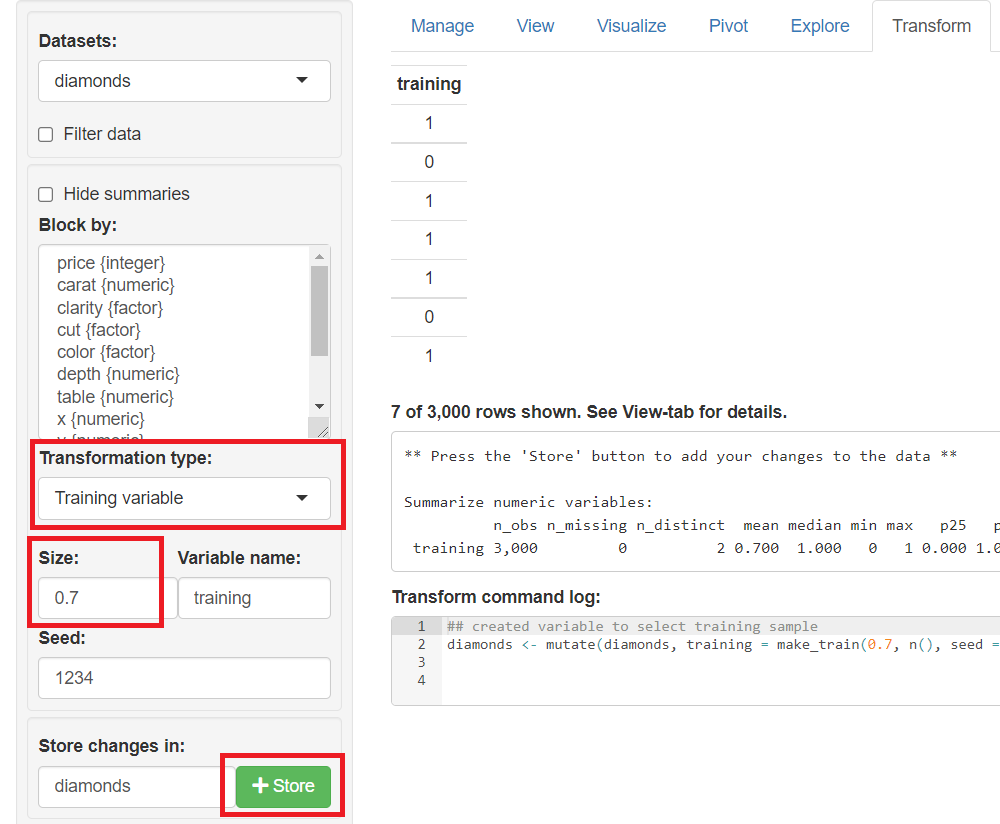
作成したフラグ変数(training)は、「0 or 1」の2値データです。
- 0:テストデータ
- 1:学習データ
②データ分割(学習データとテストデータ)
次に、作ったフラグ変数(training)を使い、学習データ(train)とテストデータ(test)に分割していきます。
メニューの「View」ボタンをクリックし、データの表示画面(View)を表示させます。
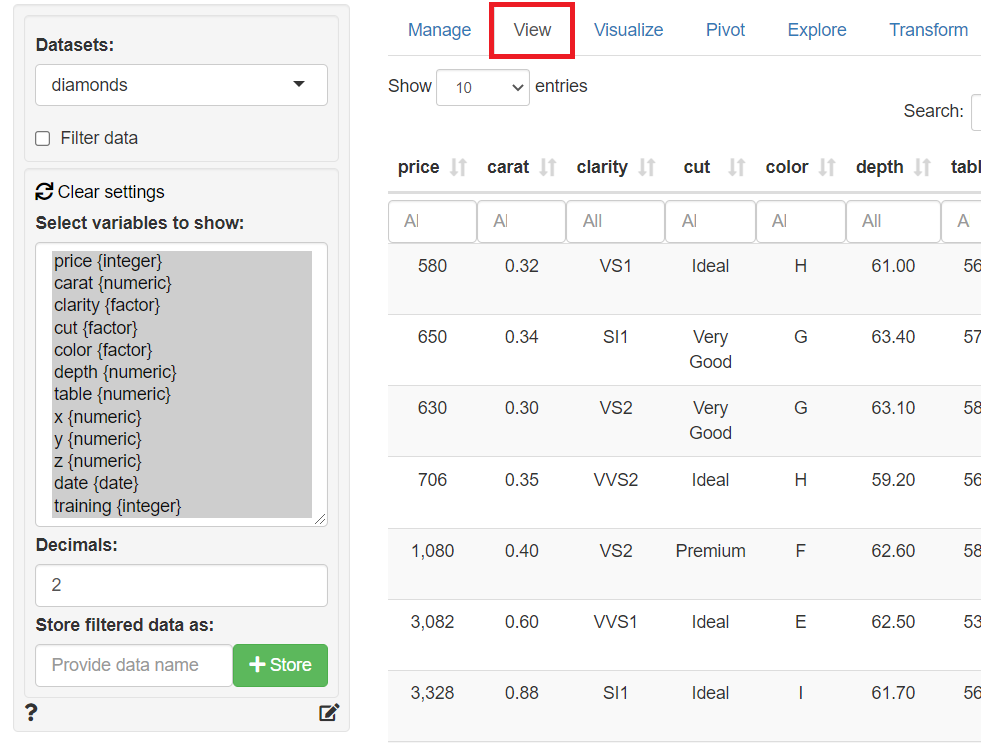
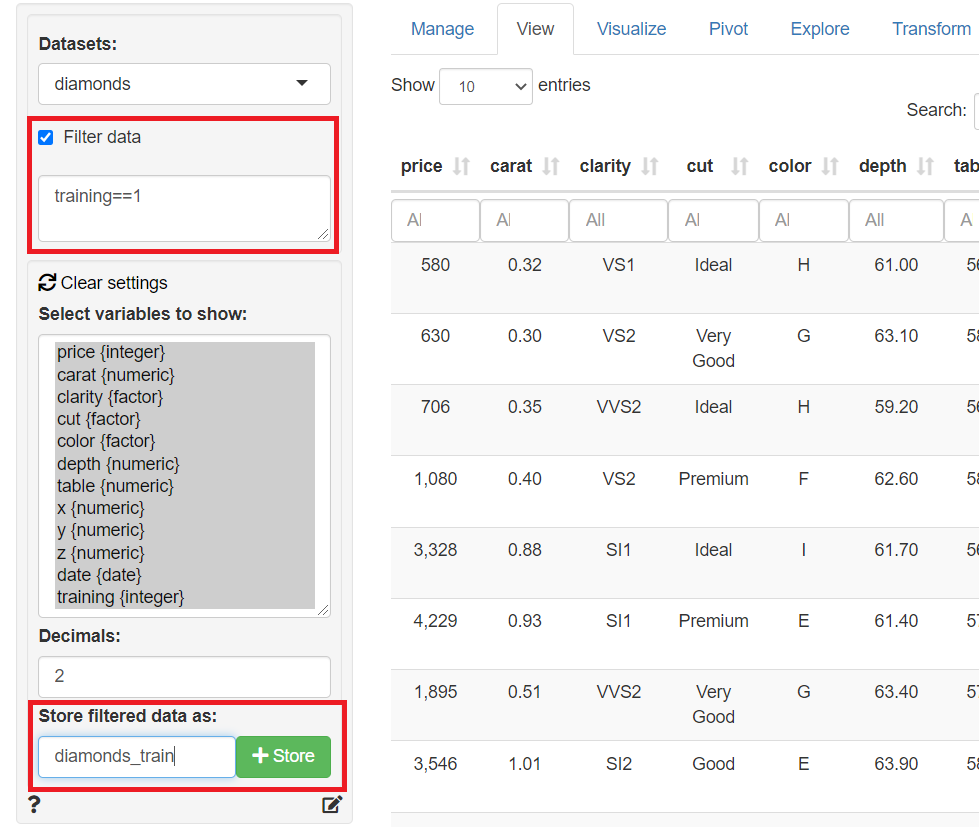
作成したフラグ変数(training)に対し、表示条件を指定し絞り込み、学習データ(train)のみを表示し保存します。「Store filtered data as」に「データセット名称」を指定し、右隣りにある「+Store」ボタンをクリックし保存します。
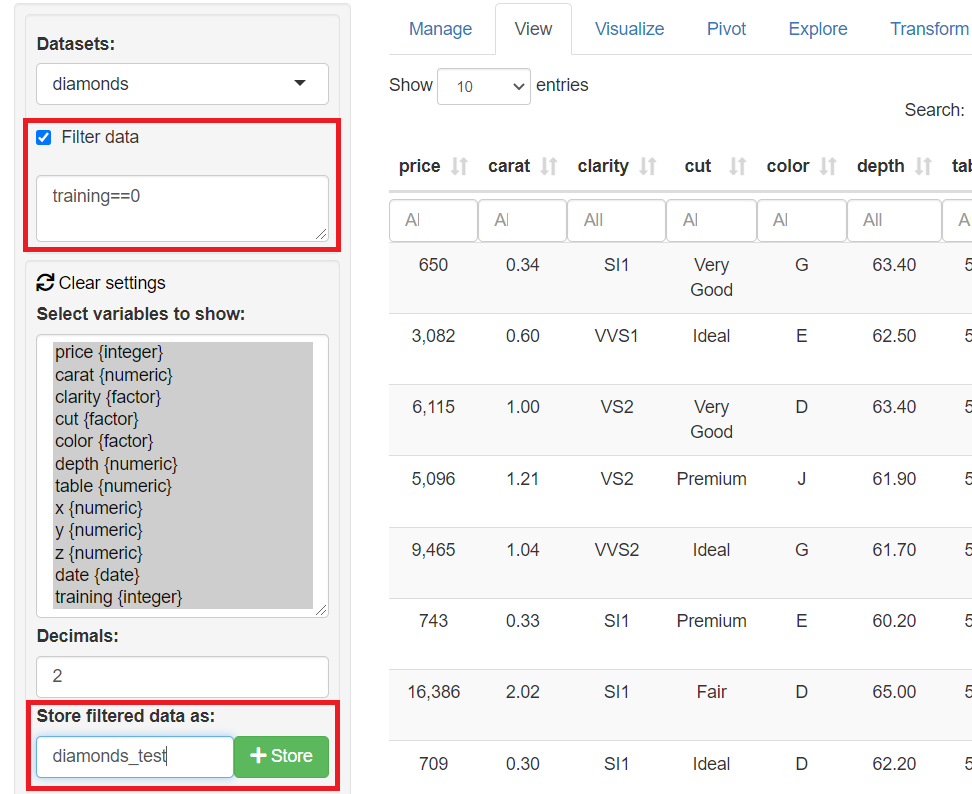
同様に、作成したフラグ変数(training)に対し、表示条件を指定し絞り込み、テストデータ(test)のみを表示し保存します。「Store filtered data as」に「データセット名称」を指定し、右隣りにある「+Store」ボタンをクリックし保存します。
以下は、今までの流れをまとめた画像(GIF)です。
その5-2の「回帰問題(線形回帰・回帰木・XGBoost)」で、この分割したデータを使います。
タイタニック(titanic)データを分割
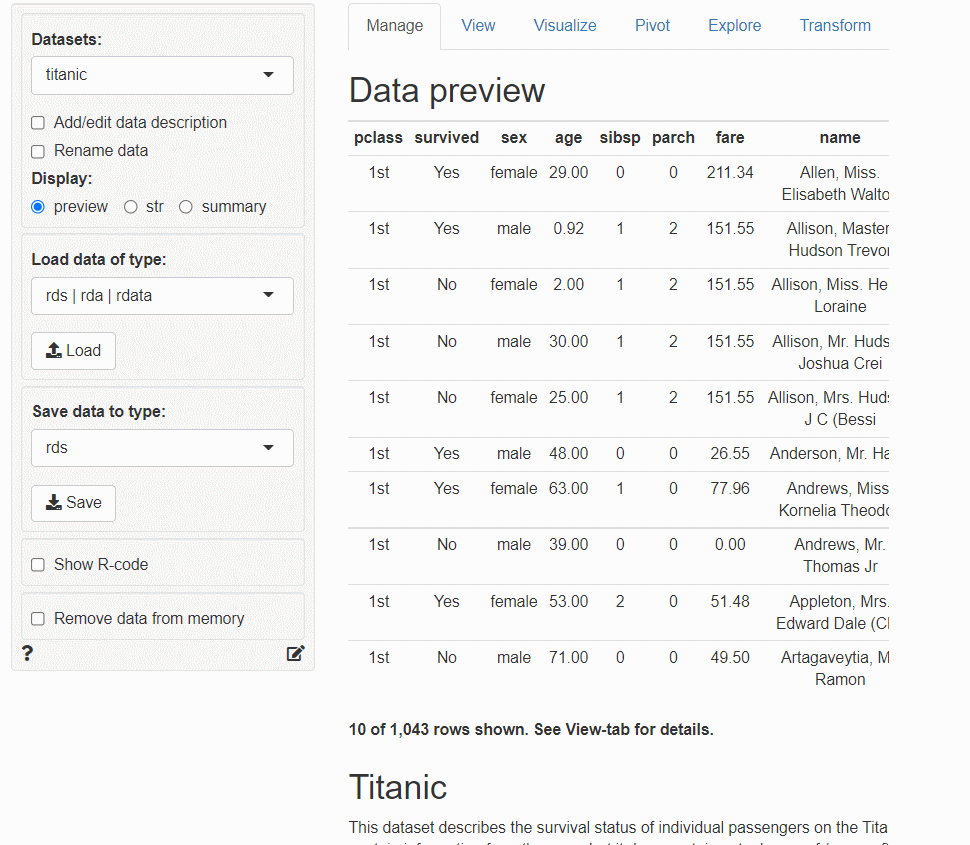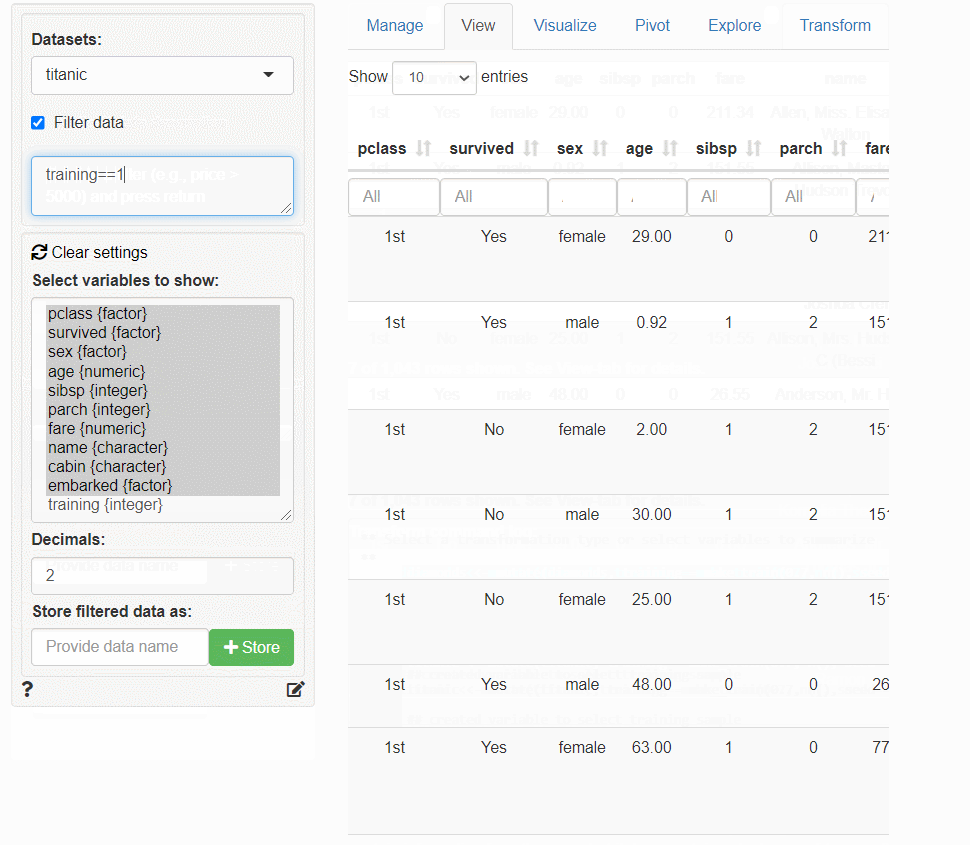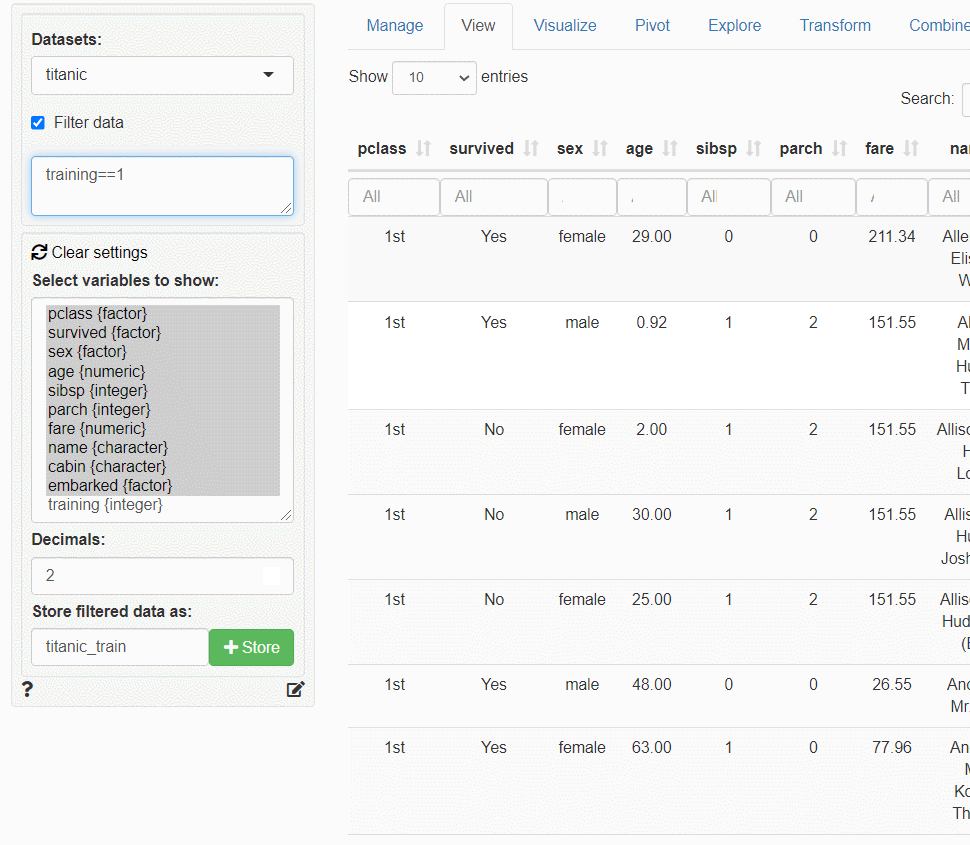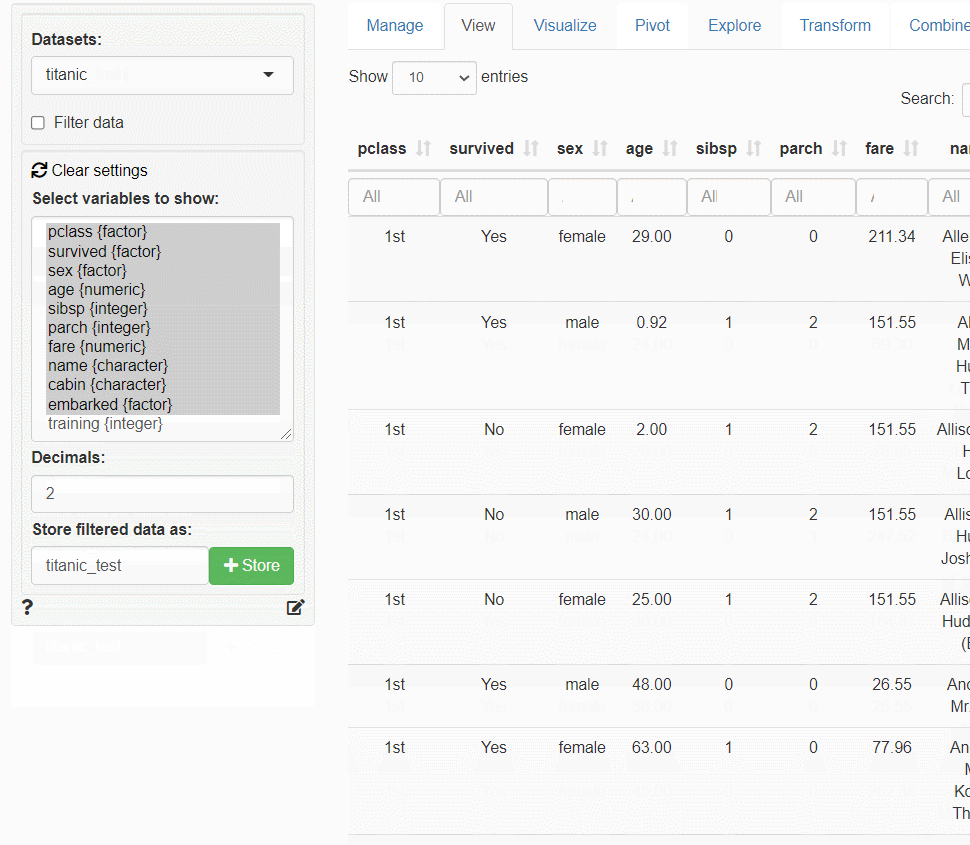
以下は、タイタニック(titanic)データを、学習データとテストデータに分割するまでの流れをまとめた画像(GIF)です。
その5-3の「分類問題(多項ロジスティック回帰・決定木・ニューラルネット)」で、この分割したデータを使います。
次回
今回は、その5の「Radiantで予測モデル構築」の「その5-1 学習データとテストデータへの分割」について簡単に説明しました。
- その1:Radiantのインストール・起動・終了
- その2:Radiantのデータ読み込み
- その3:Radiantでデータ抽出(絞り込み)
- その4:RadiantでEDA(探索的データ分析)
- その4-1 グラフ作成
- その4-2 ピボット集計
- その4-3 記述統計量
- その5:Radiantで予測モデル構築
- その5-1 学習データとテストデータへの分割
- その5-2 回帰問題(線形回帰・回帰木・XGBoost) ⇒ 次回
- その5-3 分類問題(ロジスティック回帰・ランダムフォレスト・ニューラルネット)
次回は、その5の「Radiantで予測モデル構築」の「その5-2 回帰問題(線形回帰・回帰木・XGBoost)」について説明します。