
回帰問題や分類問題の予測モデルを構築するときに、色々なアルゴリズムで構築し比べたことがあるかと思います。
AutoML(自動機械学習)というわけではないですが、PythonのLazy Predictを使うと、1コードで色々なアルゴリズムで予測モデルを構築し比べることができます。
- 回帰問題用(数値を予測するモデル)のアルゴリズムが約40種類
- 分類問題用(分類を予測するモデル)のアルゴリズムが約30種類
と言うことで、「Lazy Predict(Python)で1コードで30以上の数理モデルの予測結果を得られる」というお話しというか、使い方を簡単に説明します。
Contents [hide]
インストール
以下でインストールできます。
pip install lazypredict
回帰問題
回帰問題|サンプルデータ
今回はscikit-learnから提供されているカリフォルニアの住宅価格データセットを使います。
目的変数yは、カリフォルニアの予測したい区画ごとの住宅価格の中央値です。
特徴量(説明変数X)は、次の8個です。
| 項目名 | 詳細 |
| MedInc | 予測したい区画の収入の中央値 |
| HouseAge | 予測したい区画の築年数 |
| AveRoom | 予測したい区画の家の部屋数の平均値 |
| AveBedrms | 予測したい区画の寝室の平均値 |
| Population | 予測したい区画の人口 |
| AveOccup | 予測したい区画の平均入居率 |
| Latitude | 予測したい区画の緯度 |
| Longitude | 予測したい区画の経度 |
回帰問題|ライブラリー読み込み
必要なライブラリーを読み込みます。
以下、コードです。
# ライブラリー読み込み from lazypredict.Supervised import LazyRegressor #Lazy Predict(回帰) from sklearn.datasets import fetch_california_housing #サンプルデータ from sklearn.model_selection import train_test_split #データ分割(学習データとテストデータ)
回帰問題|データセットの読み込みと分割
サンプルデータを読み込みます。
# データセット読み込み california_housing = fetch_california_housing(as_frame=True) X = california_housing.data y = california_housing.target
予測モデルを構築する学習データと、構築した予測モデルを検証するテストデータに分割します。
# データセットの分割(学習データとテストデータ)
X_train, X_test, y_train, y_test = train_test_split(X,
y,
train_size=0.5,
test_size=0.5,
random_state=42)
- 学習用のデータセット
- 学習用の特徴量をX_trainに格納
- 学習用の目的変数をy_trainに格闘
- テスト用のデータセット
- テスト用の特徴量をX_testに格納
- テスト用の目的変数をy_testに格闘
回帰問題|設定と実行
準備ができたので、Lazy Predict(回帰)を使い予測モデルを構築し検証していきます。
# Lazy Predict(回帰)の設定と実行 reg = LazyRegressor(ignore_warnings=True, predictions=True) #設定 models, predictions = reg.fit(X_train, X_test, y_train, y_test) #実行
たったこれだけです。設定で1コード、実行で1コードです。
以下、実行結果です。

「models」に検証結果が、「predictions」に各予測モデルの予測値が格納されています。
回帰問題|予測結果
先ず、構築した予測モデルの検証結果(テストデータ利用)を見てみます。
以下、コードです。
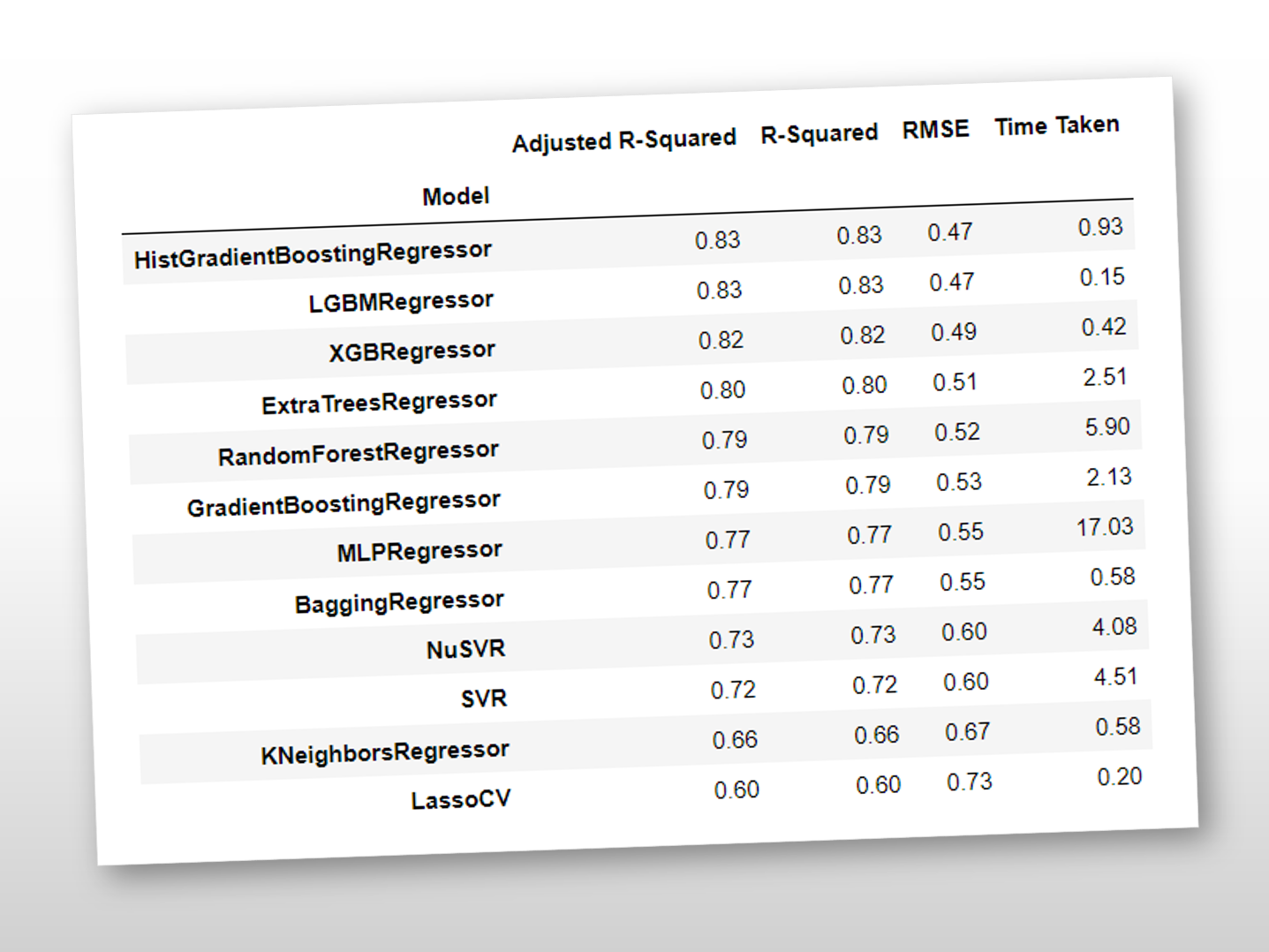
# 検証結果 models
以下、実行結果です。
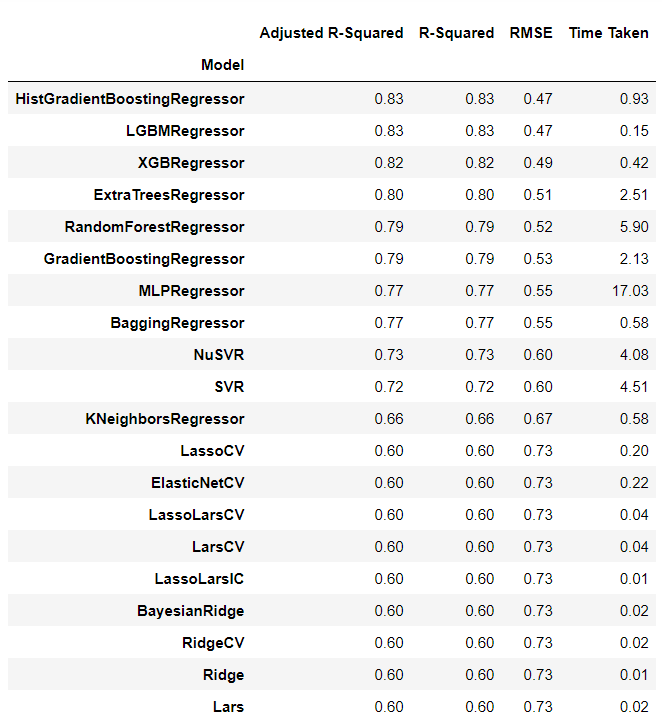
「HistGradientBoostingRegressor」「LGBMRegressor」「XGBRegressor」などのGradient Boosted Treesのフォレスト系のアルゴリズムで構築した予測モデルが、R2が80%以上と高精度であることが分かります。
これ以上の予測モデル構築するとき、「HistGradientBoostingRegressor」「LGBMRegressor」「XGBRegressor」に対しパラメータチューニングなどを実施するといいでしょう。ちなみに、この結果はパラメータチューニングしていない結果です。
次に、構築した各予測モデルの予測値を見てみます。
以下、コードです。
# 予測値 predictions
以下、実行結果です。
回帰問題|ソースコード全体
# ライブラリー読み込み
from lazypredict.Supervised import LazyRegressor #Lazy Predict(回帰)
from sklearn.datasets import fetch_california_housing #サンプルデータ
from sklearn.model_selection import train_test_split #データ分割(学習データとテストデータ)
# データセット読み込み
california_housing = fetch_california_housing(as_frame=True)
X = california_housing.data
y = california_housing.target
# データセットの分割(学習データとテストデータ)
X_train, X_test, y_train, y_test = train_test_split(X,
y,
train_size=0.5,
test_size=0.5,
random_state=42)
# Lazy Predict(回帰)の設定と実行
reg = LazyRegressor(ignore_warnings=True, predictions=True) #設定
models, predictions = reg.fit(X_train, X_test, y_train, y_test) #実行
# 検証結果
models
# 予測値
predictions
分類問題
分類問題|サンプルデータ
今回はscikit-learnから提供されている乳がんの診断結果を分類する問題を使います。
目的変数yは、画像の分類結果良性(=1)と悪性(=0)の2クラス値です。
特徴量(説明変数X)は、次の10個特徴量の平均値、標準偏差、最低値を算出し30個の特徴量にしています。
| 項目名 | 詳細 |
| radius | 細胞核の中心から外周までの距離 |
| texture | 画像のグレースケールの標準偏差 |
| perimeter | 細胞核周囲の長さ |
| area | 細胞核の面積 |
| smoothness | 細胞核の直径の局所分散値 |
| compactness | perimeter^2/area – 1.0で計算される値 |
| concavity | 輪郭の凹面度の重大度 |
| concave point | 輪郭の凹面部の数 |
| symmetry | 対称性 |
| fractal dimension | フラクタル次元 |
分類問題|ライブラリー読み込み
必要なライブラリーを読み込みます。
以下、コードです。
# ライブラリー読み込み from lazypredict.Supervised import LazyClassifier #Lazy Predict(分類) from sklearn.datasets import load_breast_cancer #サンプルデータ from sklearn.model_selection import train_test_split #データ分割(学習データとテストデータ)
分類問題|データセットの読み込みと分割
サンプルデータを読み込みます。
# データセット読み込み load_breast_cancer = load_breast_cancer(as_frame=True) X = load_breast_cancer.data y = load_breast_cancer.target
予測モデルを構築する学習データと、構築した予測モデルを検証するテストデータに分割します。
# データセットの分割(学習データとテストデータ)
X_train, X_test, y_train, y_test = train_test_split(X,
y,
train_size=0.5,
test_size=0.5,
random_state=42)
- 学習用のデータセット
- 学習用の特徴量をX_trainに格納
- 学習用の目的変数をy_trainに格闘
- テスト用のデータセット
- テスト用の特徴量をX_testに格納
- テスト用の目的変数をy_testに格闘
分類問題|設定と実行
準備ができたので、Lazy Predict(分類)を使い予測モデルを構築し検証していきます。
# Lazy Predict(分類)の設定と実行 clf = LazyClassifier(ignore_warnings=True, predictions=True) #設定 models, predictions = clf.fit(X_train, X_test, y_train, y_test) #実行
たったこれだけです。設定で1コード、実行で1コードです。
以下、実行結果です。

「models」に検証結果が、「predictions」に各予測モデルの予測値が格納されています。
分類問題|予測結果
先ず、構築した予測モデルの検証結果(テストデータ利用)を見てみます。
以下、コードです。
# 検証結果 models
以下、実行結果です。
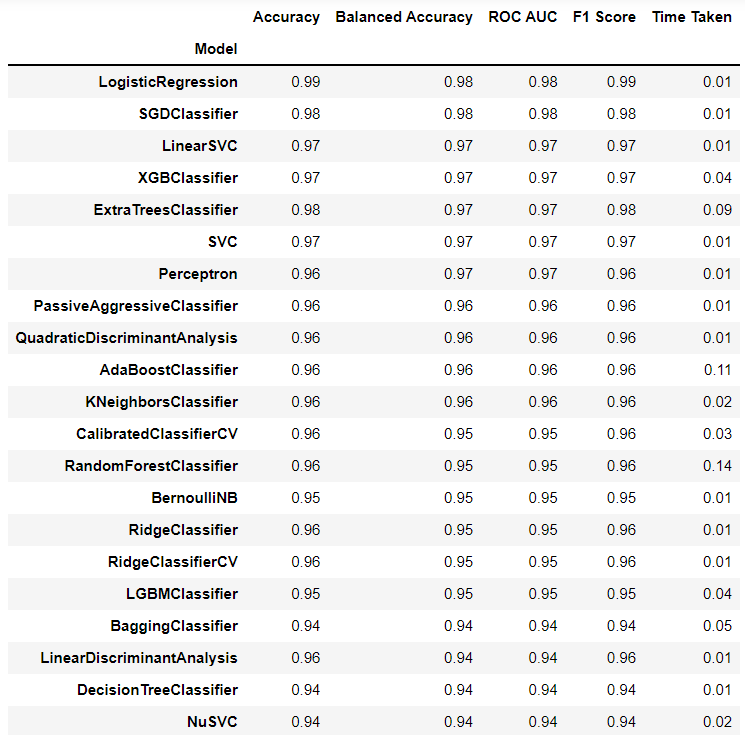
「LogisticRegression」「SGDClassifier」「LinearSVC」などの比較的シンプルなアルゴリズムで構築した予測モデルが、高精度であることが分かります。
今回の場合、特にパラメータチューニングなどは不必要でしょう。ちなみに、この結果はパラメータチューニングしていない結果です。
次に、構築した各予測モデルの予測値を見てみます。
以下、コードです。
# 予測値 predictions
以下、実行結果です。
分類問題|ソースコード全体
# ライブラリー読み込み
from lazypredict.Supervised import LazyClassifier #Lazy Predict(分類)
from sklearn.datasets import load_breast_cancer #サンプルデータ
from sklearn.model_selection import train_test_split #データ分割(学習データとテストデータ)
# データセット読み込み
load_breast_cancer = load_breast_cancer(as_frame=True)
X = load_breast_cancer.data
y = load_breast_cancer.target
# データセットの分割(学習データとテストデータ)
X_train, X_test, y_train, y_test = train_test_split(X,
y,
train_size=0.5,
test_size=0.5,
random_state=42)
# Lazy Predict(分類)の設定と実行
clf = LazyClassifier(ignore_warnings=True, predictions=True) #設定
models, predictions = clf.fit(X_train, X_test, y_train, y_test) #実行
# 検証結果
models
# 予測値
predictions
まとめ
今回は、「Lazy Predict(Python)で1コードで30以上の数理モデルの予測結果を得られる」というお話しというか、使い方を簡単に説明しました。
Lazy Predictを使うと、1コードで色々なアルゴリズムで予測モデルを構築し比べることができます。
正直、200以上の予測モデルを構築するアルゴリズムを備えたCaret(R)や、Caret(R)のPyhton版でありAutoMLサイドへ機能拡張したPyCaret(Python)の方が機能的に良さそうですが、手軽さで言えばLazy Predictが上でしょう。1行ですから。
Lazy Predict(Python)で味を占めたら、Caret(R)やPyCaret(Python)にもチャレンジしてみてください。