
EDA(探索的データ分析)と称して、大量のグラフを作成し意味のあるグラフを探しながら見ていくという作業は、昔から行われてきました。
その作業が少しでも楽でにでもなれば、ということで Lux というPythonライブラリーです。
![]()
https://lux-api.readthedocs.io/en/latest/
Lux を使ったEDA(探索的データ分析)は、Jupyter Notebook上で実施します。
Lux の面白いところは、EDA(探索的データ分析)の「深掘りアイデア」を刺激するかのような出力を提供し、どんどん深掘りししていくことができることです。
インテリジェントなアシスタントEDAライブラリと呼ばれる所以です。
ものすごいことをするわけではありません。相関の高い順に散布図を並べて出力したりと、非常に単純なものですが、非常に便利です。
と言うことで、今回は「EDAのスピードを上げるインテリジェントなアシスタントEDAライブラリー Python Lux」について簡単に紹介します。
Contents [hide]
インストールと準備
先ずは、インストールです。
以下、PyPIからインストールするときのコードです。
pip install lux-api
condaを使う場合は、以下でインストールできます。
conda install -c conda-forge lux-api
次に、Jupyter Notebookのセットアップをします。
以下のエクステンションを追加します。
jupyter nbextension install --py luxwidget jupyter nbextension enable --py luxwidget
以上で、準備は完了です。
Jupyter Notebook を起動し Lux を使ったEDA(探索的データ分析)を実施してみましょう。
サンプルデータ
サンプルデータとしてよく利用される「diamonds」を使います。ダイヤモンドの価格(price)とその他の属性が含まれています。

- price: price in US dollars
- carat: weight of the diamond
- clarity: measurement of how clear the diamond
- cut: quality of the cut
- color: diamond color
- depth: total depth percentage
- table: width of top of diamond relative to widest point
- x: length in mm
- y: width in mm
- z: depth in mm
サンプルデータ(CSV形式)は、以下からダウンロードできます。
DiamondData.csv
https://www.salesanalytics.co.jp/mj4p
必要なライブラリーとデータセットを読み込もう
以下、コードです。
url = 'https://www.salesanalytics.co.jp/mj4p' df = pd.read_csv(url)
データセットの情報を見てみます。
以下、コードです。
df.info()
以下、実行結果です。
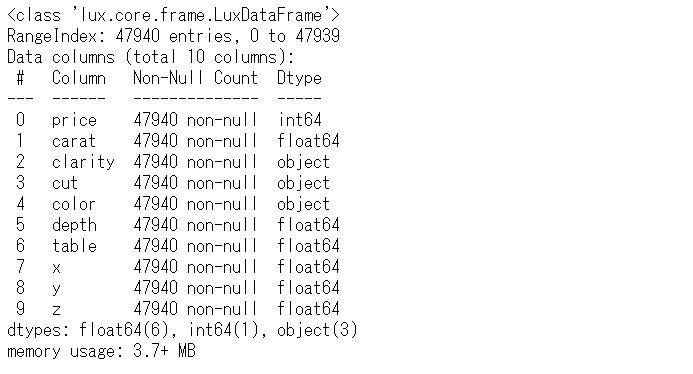
量的変数(floatとint)とカテゴリカル変数(object)が混在していることが分かります。
- 量的変数:
- price
- carat
- depth
- table
- x
- y
- z
- カテゴリカル変数:
- clarity
- cut
- color
Luxのウィジェットを見てみよう!
3種類のアウトプットが表示されます。
- Correlation(量的変数同士の散布図)
- Distribution(量的変数の分布、つまりヒストグラム)
- Occurrence(カテゴリカル変数の分布)
以下、コードです。
df
以下、実行結果です。
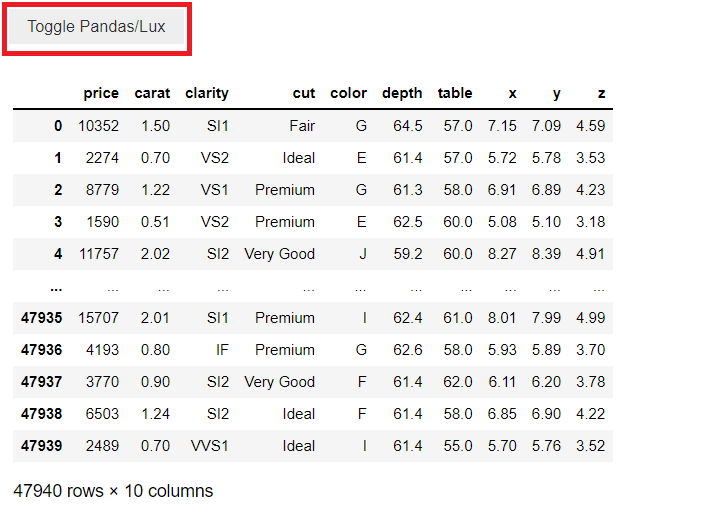
データセットが表示されます。
「Toggle Pandas/Lux」をクリックすると Lux によるEDAを開始することができます。
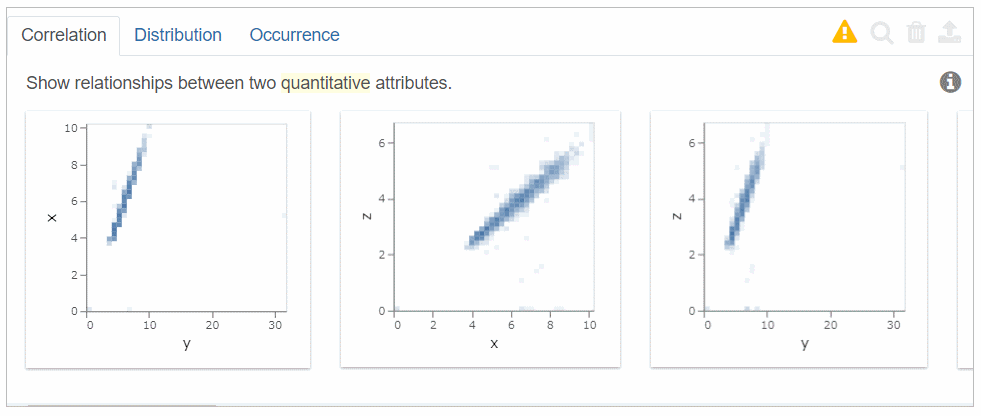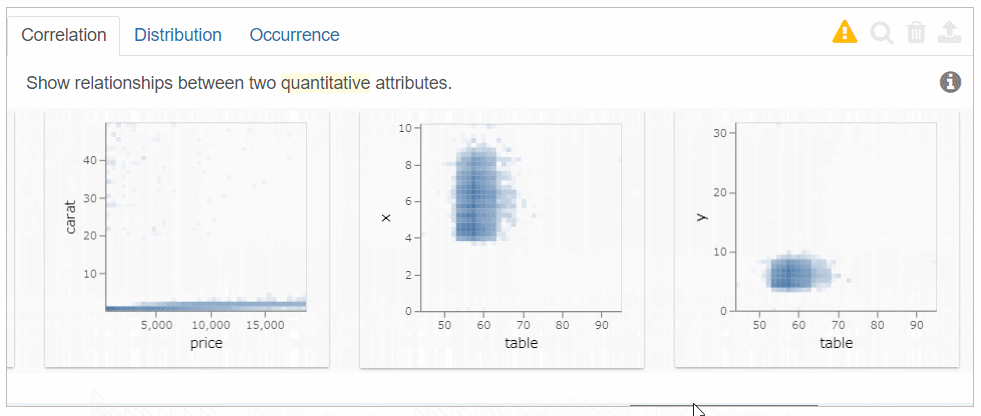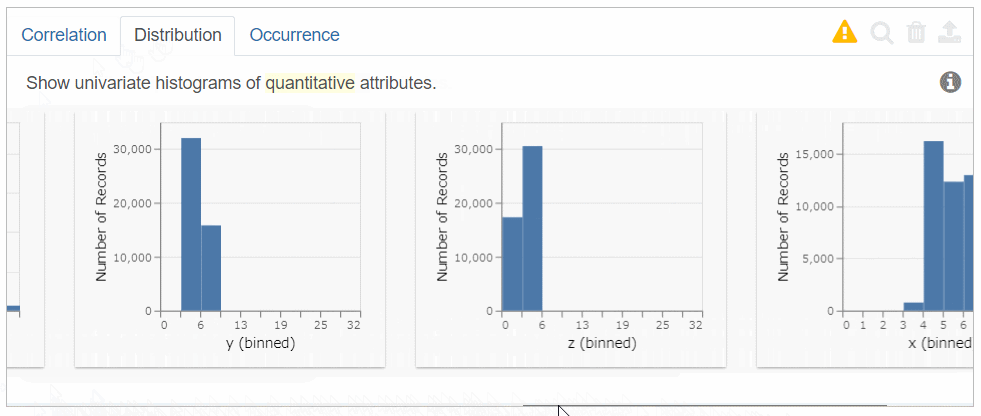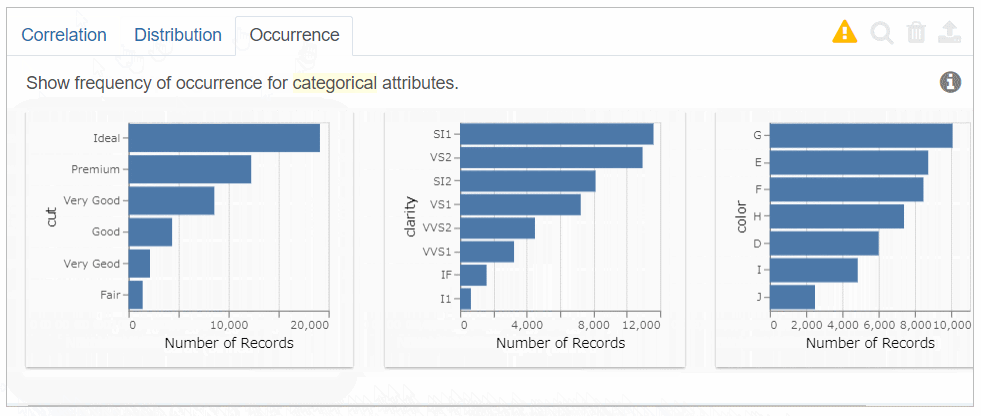
Correlationでは、左から相関の高い「量的変数同士の散布図」を順に表示します。
Distributionでは、左から歪度(skewness )の高い「量的変数の分布、つまりヒストグラム」を順に表示します。
Occurrenceでは、左から不均等な分布順に「カテゴリカル変数の分布」を表示します。
これだけでもありがたいですが、特定の変数やグラフを指定し、どんどん深掘りしていくことができます。
特定の変数を指定し見てみよう!
特定の変数を指定して、他の変数との関係性を見ていくことができます。
百聞は一見に如かずです。実行例を見てみましょう。
1変数を指定する
1変数を指定した場合には、その変数を固定し他の変数との関係性を、散布図や平均値、層別グラフなどを見ていきます。
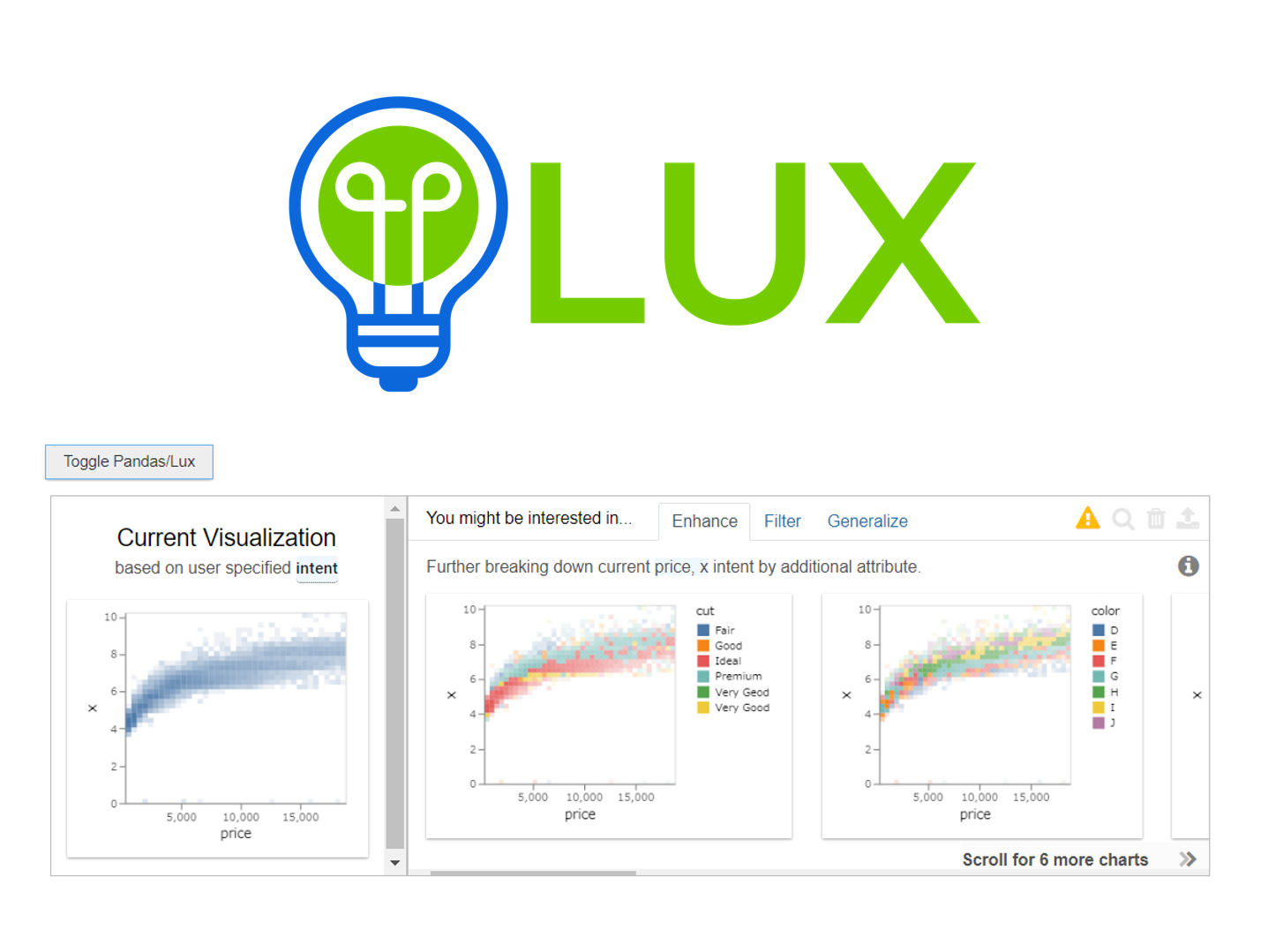
では、「intent」に「price」を指定し実行しています。
以下、コードです。
df.intent=["price"] df
以下、実行結果です。
「Toggle Pandas/Lux」をクリックし、Lux によるEDAを開始します。
気になるグラフがある場合、そのグラフを選択し「虫眼鏡マーク」をクリックすると、そのグラフと言うか変数が追加指定(intent対象の変数に追加)され、深掘りされていきます。
最初から、特定の変数を複数指定して分析をすることができます。
2変数を指定する
2変数を指定した場合には、その固定した2変数の散布図に対し、他の変数の値に応じて色分けしたりの濃淡をつけたり、層別散布図などを見ていきます。
では、「intent」に「price」と「x」を指定し実行しています。
以下、コードです。
df.intent=["price","x"] df
以下、実行結果です。
出力の保存
HTML形式で出力できます。
以下、コードです。
df.save_as_html("20210706.html")
ファイル名は好きな名称で構いません。拡張子として「html」を付けます。
まとめ
今回は「EDAのスピードを上げるインテリジェントなアシスタントEDAライブラリー Python Lux 」について簡単に紹介しました。
興味ある方は使ってっ見てください。
通常の半自動EDAなどと組み合わせると、いいかと思います。