
最近、機械学習系の数理モデルを構築する人も増えてきています。PythonですとScikit-Learn(sklearn)を使う人が多いようです。
では、Rではどうか? となりますが、Rで似たようなものですと、Caret(Classification And Regression Training)かmlr3、Tidymodelsあたりでしょう。
その中で、Caretは構築できる数理モデルが200種類を超え(2021年4月30日現在)、線形回帰モデルから、決定木系、ニューラルネット系と幅広いです。

もちろん、数理モデル構築以外の、前処理やデータの可視化、データセット分割(学習データとテストデータ)などの、機械学習系の数理モデルを構築するための道具が一式揃っています。
最近では、Python版のCaretであるPyCaretなども開発されています。こちらは、ややAutoML(自動機械学習)の方向性に舵を切っている感じです。
![]()
RのCaretのすべてを説明することは無謀なので、2回(回帰問題と分類問題)に分けてお話しします。
と言うことで今回は、「R Caret によるシンプルな機械学習モデリング その1(回帰問題編)」というお話しをします。
基本の「キ」ぐらいなお話しになります。
Contents [hide]
R Caretとは?
Rには様々な機械学習のパッケージがありますが、面倒なことにパッケージごとに使い方が異なったりします。
それを統一的に扱るようにしたのが、Caret(Classification And Regression Training)です。
そのため、どのようなアルゴリズムを使い予測モデルを構築したほうがいいのか、と迷ったらCaretを使うと便利です。
色々なアルゴリズムを試せるからです。
Caretには、単に多くのアルゴリズムを扱えると言うだけでなく、機械学習に必要な機能が一式揃っています。
- 前処理
- データ分割(学習データとテストデータ)
- 特徴量選択
- モデル学習
- モデル評価
- パラメータチューニング
- 予測
など
インストール
では、Caretパッケージのインストールです。
以下、コードです。
install.packages("caret", dependencies = c("Depends", "Suggests"))
今回は、Caret以外に以下のライブラリーも使いますので、必要な方はインストールして下さい。
- readr
- dplyr
- summarytools
- RANN
- skimr
- doParallel
主に使う3つの関数
Caret では主に、次の3つの関数を使います。
- createDataPartition関数:学習データとテストデータに分ける
- train関数:学習する
- predict関数:予測する
train関数の中で、色々な設定をします。
- formula:モデル式
- data:学習データ
- method:アルゴリズム
- preProcess:データの前処理
- tuneLength:パラメータチューニングの数
- tuneGrid:パラメータチューニングの範囲
- trControl:クロスバリデーションなどの諸設定
基本、「method」の設定を変えることで、数理モデルのアルゴリズムを変えることができます。
ちなみに、パラメータチューニングの際には、通常はtuneGridを使います。ただ、どのように設定すればいいのか分からないこともあるかと思います。そのときは、tuneLengthにパラメータチューニングの数を指定すると、caretはいい塩梅にその指定した数の中でパラメータチューニングします。
構築できる数理モデル(アルゴリズム)
構築できる数理モデルは200種類を超えています。正確に言うと、アルゴリズムの種類が200種類を超えています。
R Caret:Available Models
https://topepo.github.io/caret/available-models.html
見て頂くと分かる通り、同じ数理モデルのものが複数含まれています。例えば、上の方を眺めるとAdaBoostが複数あることが分かります。
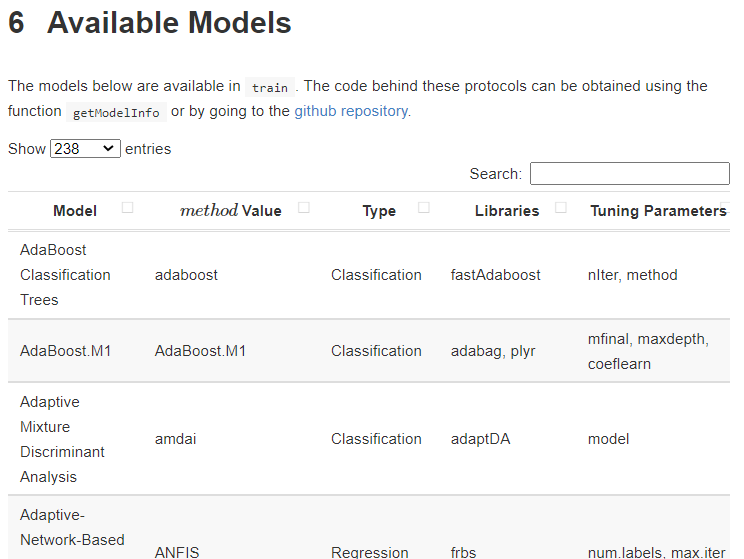
数理モデルの名称が同じでも、元になっているライブラリーが異なっています。ライブラリーが異なると言うことは、実装プログラムやそもそもの計算アルゴリズムが異なっていることを意味します。
アルゴリズムが異なると言うことは、チューニングできるパラメータも異なります。
どのアルゴリズムが正しく、どのアルゴリズムが間違っている、というものではありません。それぞれが正しいのです。
日々アルゴリズムは改良が加えられ、日々新しいアルゴリズムが誕生しています。
利用するデータセット
サンプルデータとしてよく利用される「diamonds」を使います。ダイヤモンドの価格(price)が目的変数で、その他の属性が説明変数(特徴量)です。

- price: price in US dollars
- carat: weight of the diamond
- clarity: measurement of how clear the diamond
- cut: quality of the cut
- color: diamond color
- depth: total depth percentage
- table: width of top of diamond relative to widest point
- x: length in mm
- y: width in mm
- z: depth in mm
サンプルデータ(CSV形式)は、以下からダウンロードできます。
全体の流れ
全体の流れです。
- データ読み込み
- データ分割(学習データとテストデータ)
- データの前処理
- 予測モデル構築(学習データ利用)
- 構築したモデルの検証(テストデータ)
今回は、次の3つのアルゴリズムで予測モデルを構築し検証します。
- 線形回帰
- XGBoost
- ニューラルネットワーク
データ読み込み
では、早速データセットを読み込みます。
以下、コードです。Caret は、計算時間が掛かるケースが多いので、並列化演算するように設定しています。必須ではありません。
# # ライブラリー読み込み ---- # library(caret) library(readr) library(dplyr) library(summarytools) library(RANN) library(skimr) library(doParallel) # # 並列化演算 ---- # cl <- makePSOCKcluster(8) registerDoParallel(cl) # # データセットの読み込みと確認 ---- # ## 読み込み url = "https://www.salesanalytics.co.jp/wpv6" dataset = read_csv(url) ## 各変数の状況確認 skim(dataset) dfSummary(dataset) %>% view()
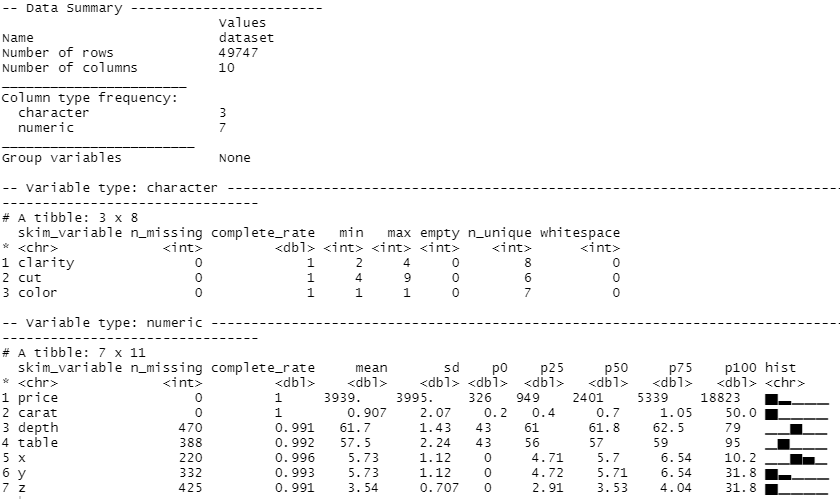
以下、実行結果(skimの出力)です。
以下、実行結果(dfSummaryの出力)です。クリックすると別のHTMLページが開きます。
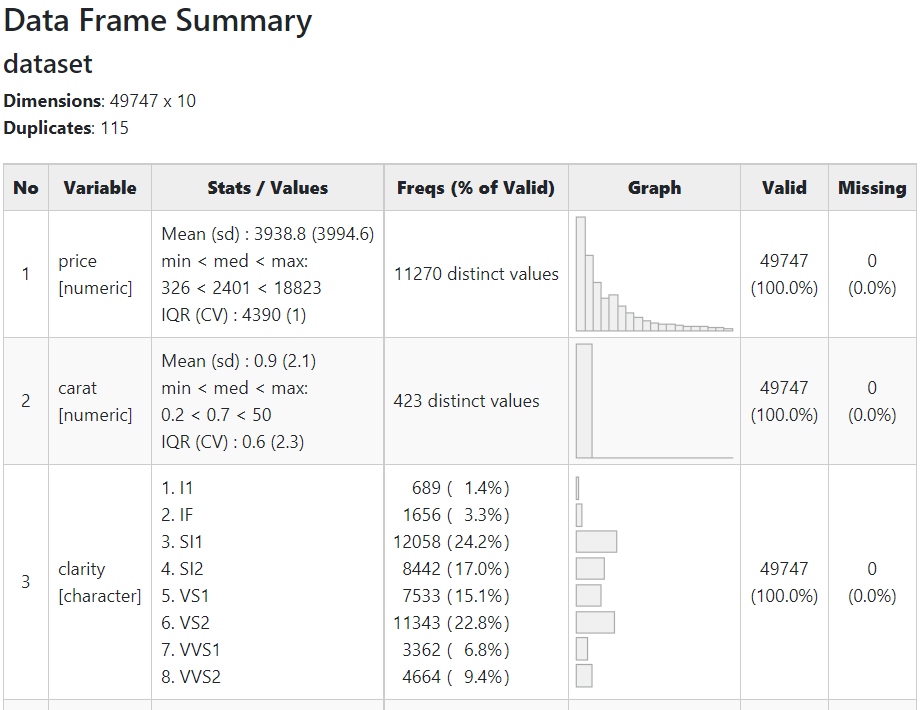
量的変数とカテゴリカル変数が混在し、さらに幾つかの変数に欠測値(missing)があることが分かります。
データ分割(学習データとテストデータ)
読み込んだデータセットを、モデルを構築するときに利用する学習データと、構築したモデルを検証するためのテストデータに分割します。
以下、コードです。
# # データ分割 ---- # ## データ分割用の行番号生成 set.seed(100) trainNum <- createDataPartition(dataset$price, p=0.8, list=FALSE) ## 学習データ dataset_train <- dataset[trainNum,] y_train = dataset_train[,1] #目的変数 X_train = dataset_train[,-1] #説明変数(特徴量) ## テストデータ dataset_test <- dataset[-trainNum,] y_test = dataset_test[,1] #目的変数 X_test = dataset_test[,-1] #説明変数(特徴量)
データの前処理
次の3つの前処理を実施し、データセットを整えます。
- 欠測値の補完
- 量的変数の正規化
- カテゴリカル変数のダミー変数化(One-Hot Encoding)
学習データで前処理用のモデルを構築し、それを使い学習データとテストデータの前処理を実施します。
ちなみに、Rの場合、Pythonと異なりカテゴリカル変数をカテゴリカルデータ(factor型)として認識し、ダミー変数化しなくても問題ないアルゴリズムが多いですが、念のためダミー変数化しておきます。
欠測値の補完
今回は、k近傍法(k-nearest neighbor algorithm)で欠測値補完をします。
以下、コードです。
#
# 欠測値補完 ----
#
## 欠測値補完モデルの構築
missingdata_model <- preProcess(as.data.frame(X_train),
method='knnImpute')
## 学習データの欠測値補完
X_train <- predict(missingdata_model,
newdata = X_train)
## テストデータの欠測値補完
X_test <- predict(missingdata_model,
newdata = X_test)
量的変数の正規化
今回は、通常の正規化(平均値で引き標準偏差で割る)をします。
以下、コードです。
#
# 正規化(量的変数) ----
#
## 正規化モデルの構築
range_model <- preProcess(X_train, method = c("center", "scale"))
## 学習データの正規化
X_train <- predict(range_model, newdata = X_train)
## テストデータの正規化
X_test <- predict(range_model, newdata = X_test)
カテゴリカル変数のダミー変数化(One-Hot Encoding)
今回は、通常のダミー変数化(カテゴリの数だけ0-1変数を作るOne-Hot Encoding)をします。
以下、コードです。
#
# ダミー変数化(カテゴリカル変数) ----
#
## ダミー変数化モデルの構築
dummies_model <- dummyVars(~.,
data=X_train,
fullRank = TRUE)
## 学習データのダミー変数化
X_train <- data.frame(predict(dummies_model,
newdata = X_train))
## テストデータのダミー変数化
X_test <- data.frame(predict(dummies_model,
newdata = X_test))
前処理状況の確認
これで前処理は終了です。確認してみます。
以下、コードです。
# # 各変数の状況確認 ---- # ## 学習データ skim(X_train) ## テストデータ skim(X_test)
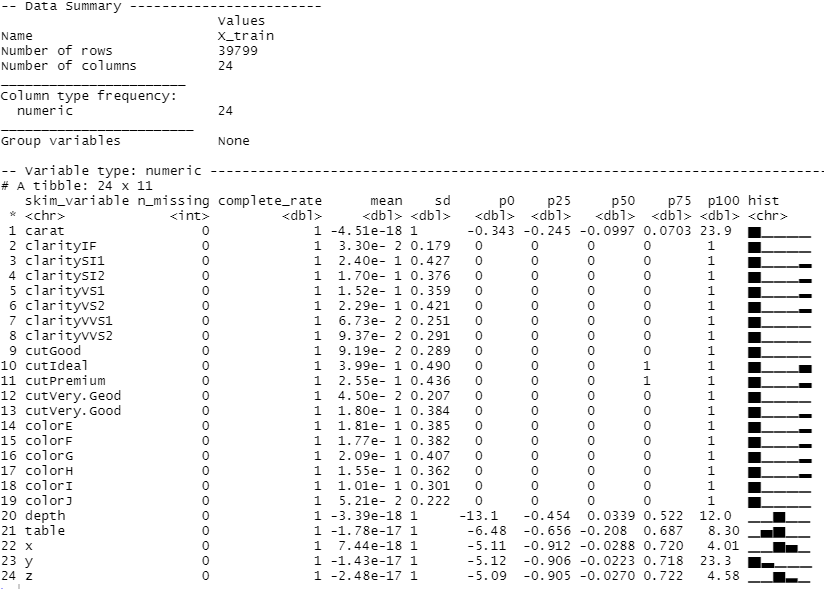
以下、実行結果(学習データ)です。
以下、実行結果(テストデータ)です。
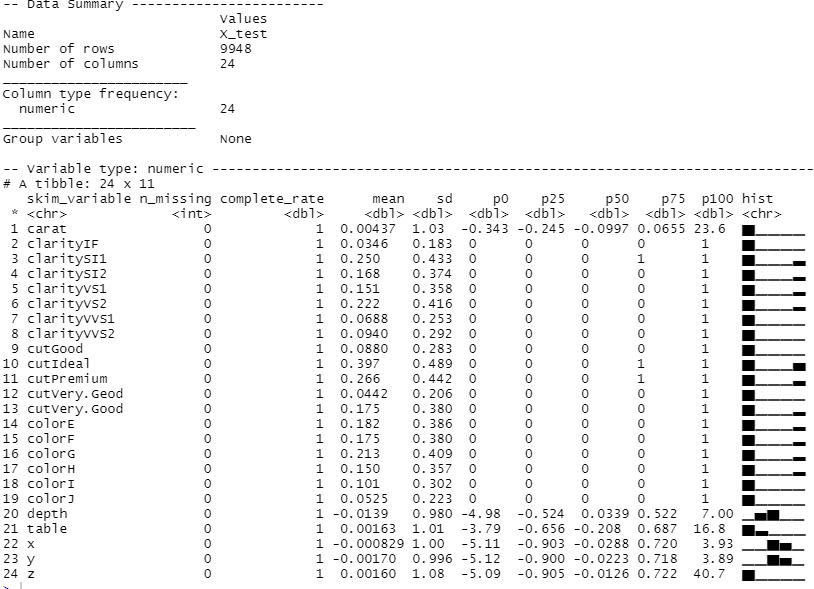
学習データとテストデータとも、欠測値が補完され、カテゴリカル変数もダミー変数化されたことが分かると思います。
このデータセットを使い、モデルを構築し検証していきます。
モデルを構築し検証
train関数を使いモデルを構築します。
繰り返しになりますが、train関数の中で、以下の設定をします。
- formula:モデル式
- data:学習データ
- method:アルゴリズム
- preProcess:データの前処理
- tuneLength:パラメータチューニングの数
- tuneGrid:パラメータチューニングの範囲
- trControl:クロスバリデーションなどの諸設定
基本、「method」の設定を変えることで、数理モデルのアルゴリズムを変えることができます。今回は、次の3つのアルゴリズムで予測モデルを構築し検証します。
- 線形回帰
- XGBoost
- ニューラルネットワーク
線形回帰
最も一般的な線形回帰です。
以下、コードです。
#
# Linear model ----
#
## モデルの学習(学習データ)
model_rlm <- train(
price ~ .,
data = cbind(y_train, X_train),
method = 'rlm',
tuneGrid = expand.grid(intercept=c('TRUE','FALSE'),
psi=c('huber','hampel','bisquare')),
trControl = trainControl(method = 'cv',
number = 10)
)
## 学習結果の確認
model_rlm
varImp(model_rlm, scale = TRUE)
## モデルの検証(テストデータ)
pred_rlm <- predict(model_rlm, X_test)
postResample(pred = pred_rlm, obs = y_test$price)
最初のモデルですので、簡単に説明を加えます。
今回は、ロバスト線形回帰(Robust Linear Model)を使っています。
method = 'rlm'
チューニングできるパラメータは、以下の2つです。
- intercept
- psi
interceptの設定は以下の2種類あります。
- TRUE
- FALSE
psiの設定は以下の3種類あります。
- huber
- hampel
- bisquare
今回はパラメータチューニングの設定を、次のようにしました。
tuneGrid = expand.grid(intercept=c('TRUE','FALSE'),psi=c('huber','hampel','bisquare'))
今回はモデル学習時に、10分割のCV(クロスバリデーション)を実施するようにしています。
trControl = trainControl(method = 'cv', number = 10)
次に出力した結果を見ていきます。
- 学習結果の確認(学習データ)
- モデルの検証(テストデータ)
先ずは、学習結果の確認(学習データ)です。
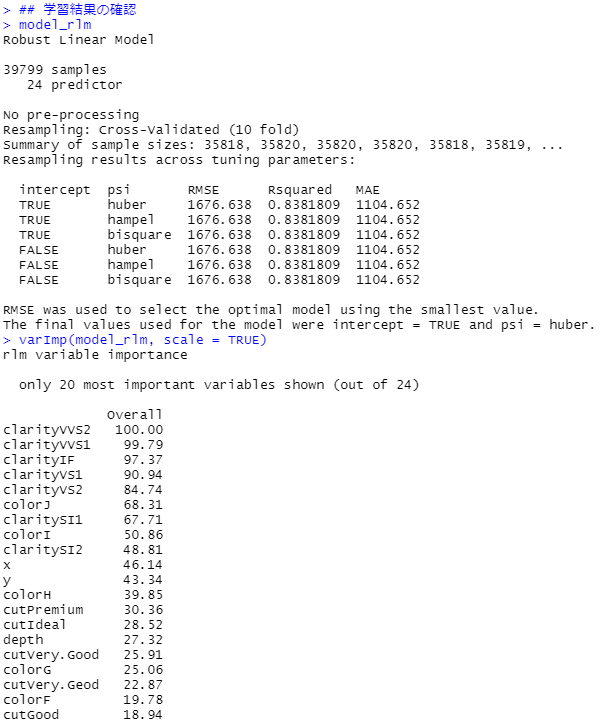
次に、モデルの検証(テストデータ)です。

R2(決定係数)が約83%で、MAE(平均絶対誤差、Mean Absolute Error)が約1113です。実際の価格と予測した価格の差が、平均して1,000円程度あるということです。
そこそこ精度が高い予測モデルです。
XGBoost
以下、コードです。
#
# XGBoost ----
#
## モデルの学習(学習データ)
model_xgb <- train(
price ~ .,
data = cbind(y_train, X_train),
method = 'xgbLinear',
tuneLength = 3,
trControl = trainControl(method = 'cv',
number = 10)
)
## 学習結果の確認
model_xgb
varImp(model_xgb, scale = TRUE)
## モデルの検証(テストデータ)
pred_xgb <- predict(model_xgb, X_test)
postResample(pred = pred_xgb, obs = y_test$price)
「tuneGrid」に何を設定すればいいのか分からない(各パラメータの検討範囲が分からない)場合には、今回のように「tuneLength」で設定するといいでしょう。
今回は、それぞれ3通りのパラメータを適応しています。
tuneLength = 3
チューニングできるパラメータは以下の4つです。
- nrounds
- lambda
- alpha
- eta
したがって、3×3×3×3 = 81通りのパラメタの組み合わせで検討されます。
次に出力した結果を見ていきます。
- 学習結果の確認(学習データ)
- モデルの検証(テストデータ)
先ずは、学習結果の確認(学習データ)です。
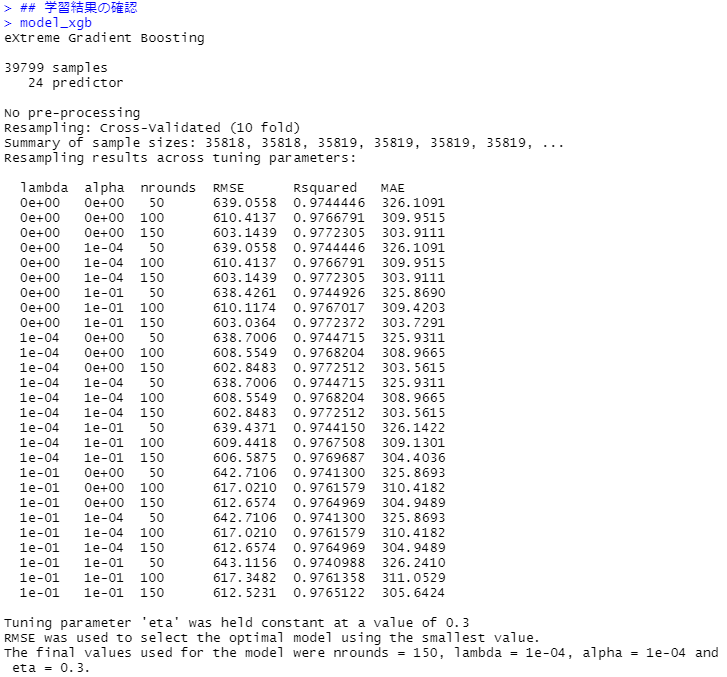

次に、モデルの検証(テストデータ)です。

R2(決定係数)が約98%で、MAE(平均絶対誤差、Mean Absolute Error)が約306です。実際の価格と予測した価格の差が、平均して306円程度あるということです。
かなり高精度な予測モデルです。
ニューラルネットワーク
以下、コードです。
#
# Neural Network ----
#
## モデルの学習(学習データ)
model_nnet <- train(
price ~ .,
data = cbind(y_train, X_train),
method = "nnet",
tuneGrid = expand.grid(size=c(1:10),
decay=seq(0.1, 1, 10)),
trControl = trainControl(method = 'cv',
number = 10),
linout = TRUE
)
## 学習結果の確認
model_nnet
varImp(model_nnet, scale = TRUE)
## モデルの検証(テストデータ)
pred_nnet <- predict(model_nnet, X_test)
postResample(pred = pred_nnet, obs = y_test$price)
今回は回帰問題に対するニューラルネットワークですので「linout = TRUE」が必要になります。分類問題の場合は「linout = FALSE」です。
次に出力した結果を見ていきます。
- 学習結果の確認(学習データ)
- モデルの検証(テストデータ)
先ずは、学習結果の確認(学習データ)です。
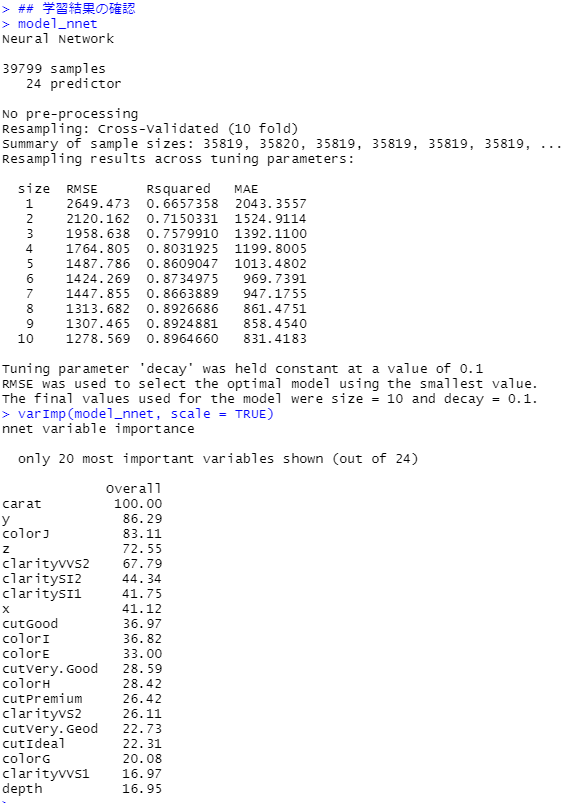
次に、モデルの検証(テストデータ)です。

R2(決定係数)が約86%で、MAE(平均絶対誤差、Mean Absolute Error)が約964です。実際の価格と予測した価格の差が、平均して964円程度あるということです。
そこそこ精度が高い予測モデルです。
コード全体
#
# ライブラリー読み込み ----
#
library(caret)
library(readr)
library(dplyr)
library(summarytools)
library(RANN)
library(skimr)
library(doParallel)
#
# 並列化演算 ----
#
cl <- makePSOCKcluster(8)
registerDoParallel(cl)
#
# データセットの読み込みと確認 ----
#
## 読み込み
url = "https://www.salesanalytics.co.jp/wpv6"
dataset = read_csv(url)
## 各変数の状況確認
skim(dataset)
dfSummary(dataset) %>% view()
#
# データ分割 ----
#
## データ分割用の行番号生成
set.seed(100)
trainNum <- createDataPartition(dataset$price, p=0.8, list=FALSE)
## 学習データ
dataset_train <- dataset[trainNum,]
y_train = dataset_train[,1]
X_train = dataset_train[,-1]
## テストデータ
dataset_test <- dataset[-trainNum,]
y_test = dataset_test[,1]
X_test = dataset_test[,-1]
#
# 欠測値補完 ----
#
## 欠測値補完モデルの構築
missingdata_model <- preProcess(as.data.frame(X_train),
method='knnImpute')
## 学習データの欠測値補完
X_train <- predict(missingdata_model,
newdata = X_train)
## テストデータの欠測値補完
X_test <- predict(missingdata_model,
newdata = X_test)
#
# 正規化(量的変数) ----
#
## 正規化モデルの構築
range_model <- preProcess(X_train, method = c("center", "scale"))
## 学習データの正規化
X_train <- predict(range_model, newdata = X_train)
## テストデータの正規化
X_test <- predict(range_model, newdata = X_test)
#
# ダミー変数化(カテゴリカル変数) ----
#
## ダミー変数化モデルの構築
dummies_model <- dummyVars(~.,
data=X_train,
fullRank = TRUE)
## 学習データのダミー変数化
X_train <- data.frame(predict(dummies_model,
newdata = X_train))
## テストデータのダミー変数化
X_test <- data.frame(predict(dummies_model,
newdata = X_test))
#
# 各変数の状況確認 ----
#
## 学習データ
skim(X_train)
## テストデータ
skim(X_test)
#
# Linear model ----
#
## モデルの学習(学習データ)
model_rlm <- train(
price ~ .,
data = cbind(y_train, X_train),
method = 'rlm',
tuneGrid = expand.grid(intercept=c('TRUE','FALSE'),
psi=c('huber','hampel','bisquare')),
trControl = trainControl(method = 'cv',
number = 10)
)
## 学習結果の確認
model_rlm
varImp(model_rlm, scale = TRUE)
## モデルの検証(テストデータ)
pred_rlm <- predict(model_rlm, X_test)
postResample(pred = pred_rlm, obs = y_test$price)
#
# XGBoost ----
#
## モデルの学習(学習データ)
model_xgb <- train(
price ~ .,
data = cbind(y_train, X_train),
method = 'xgbLinear',
tuneLength = 3,
trControl = trainControl(method = 'cv',
number = 10)
)
## 学習結果の確認
model_xgb
varImp(model_xgb, scale = TRUE)
## モデルの検証(テストデータ)
pred_xgb <- predict(model_xgb, X_test)
postResample(pred = pred_xgb, obs = y_test$price)
#
# Neural Network ----
#
model_nnet <- train(
price ~ .,
data = cbind(y_train, X_train),
method = "nnet",
tuneGrid = expand.grid(size=c(1:10),
decay=seq(0.1, 1, 10)),
trControl = trainControl(method = 'cv',
number = 10),
linout = TRUE
)
## 学習結果の確認
model_nnet
varImp(model_nnet, scale = TRUE)
## モデルの検証(テストデータ)
pred_nnet <- predict(model_nnet, X_test)
postResample(pred = pred_nnet, obs = y_test$price)
まとめ
今回は、「R Caret によるシンプルな機械学習モデリング その1(回帰問題編)」というお話しをしました。
Caret には、機械学習に必要なツールも一式整っています。さらに、200を超える色々なアルゴリズムを試せます。
今回は回帰問題でしたので、次回は分類問題を扱います。