

Excelなどでセルに入っている数字を元に、セルを色分けしたり、棒グラフをセルの中に描いたりすることがります。
そのようなことを、pandasのデータフレームを、Jupyter Notebook上に表示させるときできないだろうか、と思った方もいるかもしれません。
知っている人にとっては大したお話しではありませんが、知らない人にとっては「そんなことできるんだぁー」という感じかと思います。
と言うことで、今回は「pandasデータフレームのJupyter上の出力表示をちょっと変える方法」というお話しです。
Contents [hide]
ライブラリーを読み込む
今回使用するサンプルデータを読み込みます。
以下、コードです。
# ライブラリーの読み込み import pandas as pd import numpy as np
サンプルデータの生成その1
今回利用するサンプルデータの1つを乱数を使って生成します。
以下、コードです。
# サンプルデータ生成 df = pd.DataFrame(np.random.randn(150, 150))
サンプルデータは、150行×150列(変数)のデータセットです。
どのようなデータなのか確認してみます。
以下、コードです。
# データセットの確認 df
以下、実行結果です。
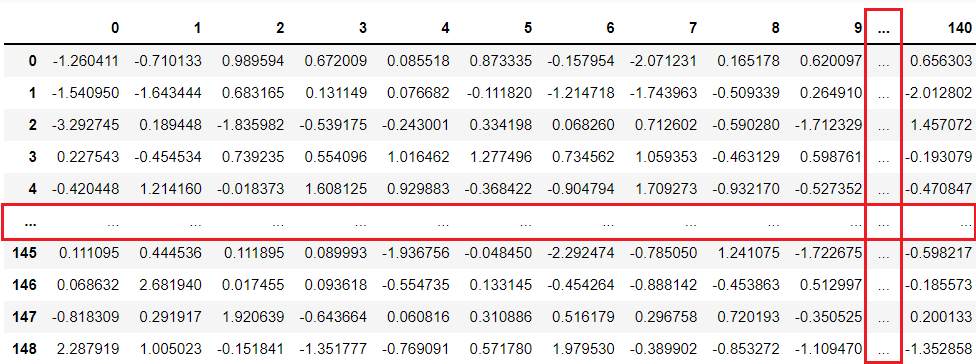
行と列の途中に「…」というのがあることに気づくことでしょう。
「…」は、表示できる最大の行数(デフォルトでは60行)や列数(デフォルトでは20列)を超えると登場します。要は、「…」でその間のデータの表示を省略しているのです。
この「…」の中を見たい、という方もいることでしょう。
表示できる最大の行数(デフォルトでは60行)や列数(デフォルトでは20列)を変更してしまえば見えます。
表示できる最大の行数と列数を変更する
では先ず、現在表示できる最大行数を見てみます。
以下、コードです。
# 表示できる行数の確認 pd.options.display.max_rows
以下、実行結果です。
![]()
表示できる最大の行数が60行(デフォルトの行数)であることが分かります。
最大行数の設定を変更してみます。
以下、コードです。
# 表示できる行数の変更 pd.options.display.max_rows = 150
本当に見えるようになったのか、確認してみます。
以下、コードです。
# 表示できる行数の確認 pd.options.display.max_rows
以下、実行結果です。
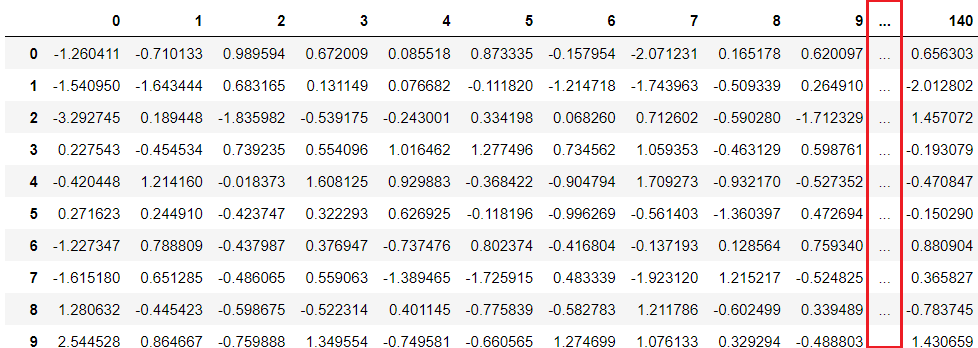
行側の「…」がなくなり、すべての行が見るようになりました。しかし、まだ列側に「…」があります。
現在表示できる最大列数を見てみます。
以下、コードです。
# 表示できる列数の確認 pd.options.display.max_columns
以下、実行結果です。
![]()
表示できる最大の行数が20列(デフォルトの列数)であることが分かります。
最大列数の設定を変更してみます。
以下、コードです。
# 表示できる行数の変更 pd.options.display.max_columns = 150
本当に見えるようになったのか、確認してみます。
以下、コードです。
# データセットの確認 df
以下、実行結果です。
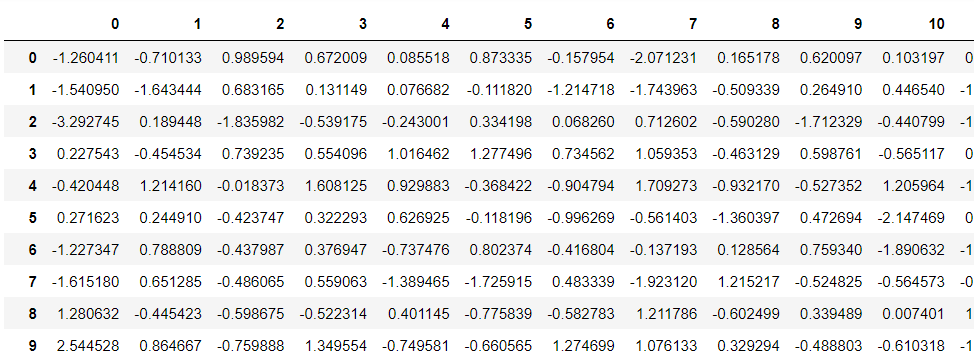
列側の「…」もなくなり、すべての列が見るようになりました。
infoで確認できる変数の上限を増やす
変数情報を確認するとき、infoメソッドを使う方は思います。
試しに先ほど作ったサンプルデータに対し実行します。
以下、コードです。
# 変数情報の確認 df.info()
以下、実行結果です。

いつもと出力が違う、と思われた方もいるかもしれません。
変数の数がある上限を超えると、infoメソッドは、変数(列)それぞれに対する情報を簡易表示するようになります。
その上限はいくつでしょうか?
以下、コードです。
# 変数情報を表示する最大列数(変数の数)の確認 pd.options.display.max_info_columns
以下、実行結果です。
![]()
これは、確認できる変数の上限が、100ということを表しています。この100はデフォルト値です。
この上限を増やすことができます。150に増やします。
以下、コードです。
# 変数情報を表示する最大列数(変数の数)の変更 pd.options.display.max_info_columns = 150
本当に見えるようになったのか、確認してみます。
以下、コードです。
# 変数情報の確認 df.info()
以下、実行結果です。
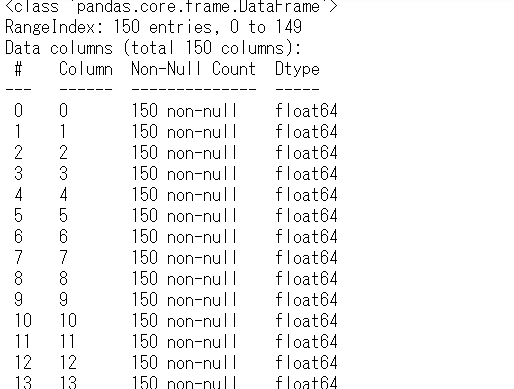
表示する小数点の桁数を増やしたい
先ほどからJupyter上で見ているデータは、小数点6位までしか見えていません。デフォルトでそうなっているからです。
本当にそうなっているのか確認してみます。
以下、コードです。
# 表示できる小数点の桁数の確認 pd.options.display.precision
以下、実行結果です。
![]()
この小数点の桁数の設定を変更することができます。10桁に増やしてみます。
以下、コードです。
# 表示できる小数点の桁数の変更 pd.options.display.precision = 10
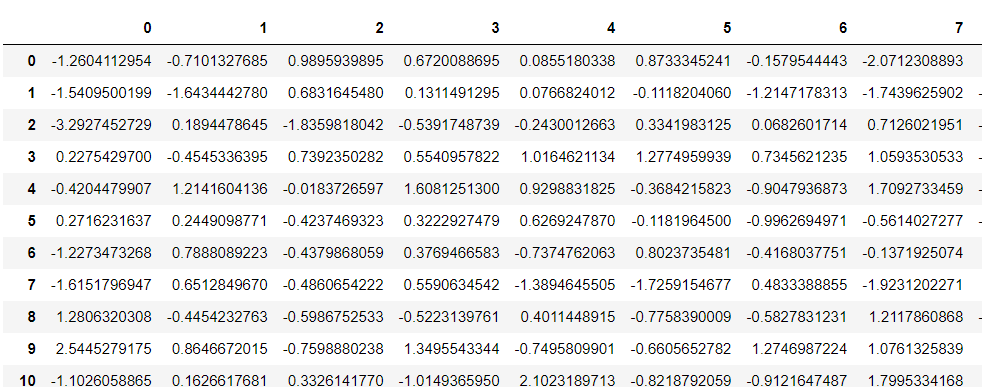
本当に桁数が増えたのか、確認してみます。
以下、コードです。
# データセットの確認 df
以下、実行結果です。
サンプルデータの生成その2
次に、ここまで利用していたサンプルデータよりも小さなデータセットを新たに作り、セルの色付けなど実施していきたいと思います。
ということで、新しいサンプルデータを乱数を使って生成します。
以下、コードです。
# サンプルデータ生成 df = pd.DataFrame(np.random.randn(10, 5))
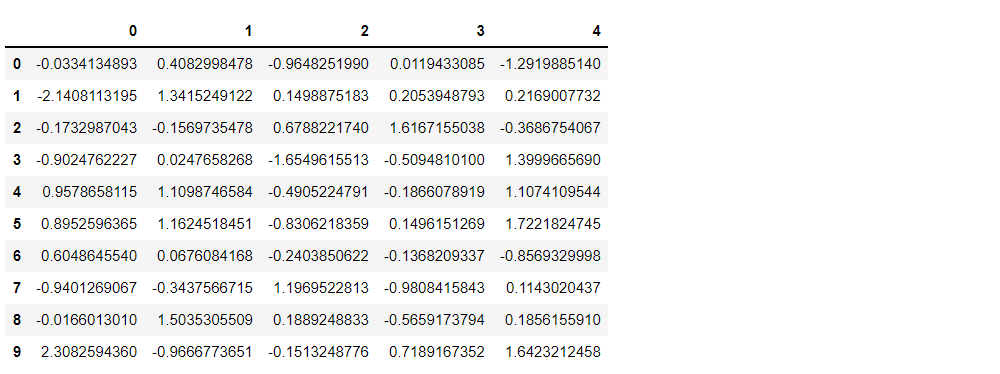
サンプルデータは、10行×5列(変数)のデータセットです。
どのようなデータなのか確認してみます。
以下、コードです。
# データセットの確認 df
以下、実行結果です。
セルの値のフォーマットの変更
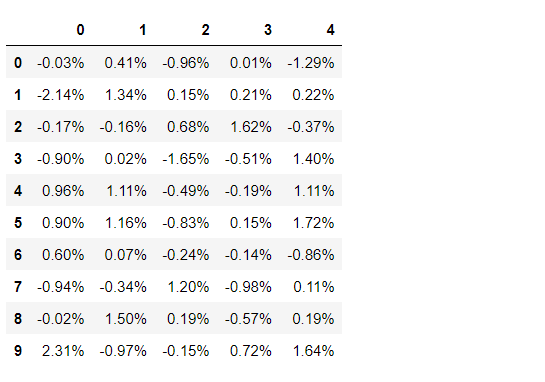
このデータセットに対し、小数点2桁まで表示し、その後ろに%を付けてみます。
以下、コードです。
# セルの値のフォーマットの変更(小数点2桁まで表示で、後ろに%を付ける)
pd.options.display.float_format = '{:.2f}%'.format
データセットを確認してみます。
以下、コードです。
# データセットの確認 df
以下、実行結果です。
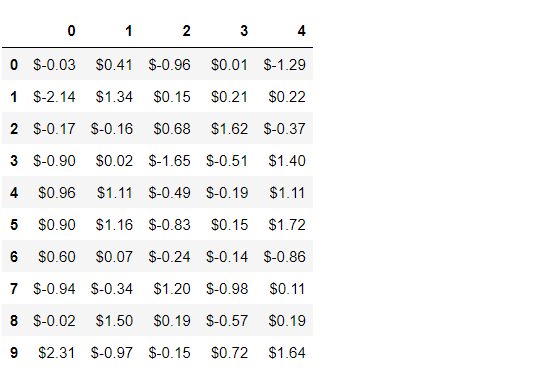
小数点2桁まで表示し、その前に$を付けてみます。
以下、コードです。
# 表示する値のフォーマットの変更(小数点2桁まで表示で、前に$を付ける)
pd.options.display.float_format = '${0:,.2f}'.format
データセットを確認してみます。
以下、コードです。
# データセットの確認 df
以下、実行結果です。
前後に何もつけず小数点2桁まで表示します。
以下、コードです。
# 表示する値のフォーマットの変更(小数点2桁まで表示)
pd.options.display.float_format = '{0:,.2f}'.format
データセットを確認してみます。
以下、コードです。
# データセットの確認 df
以下、実行結果です。
条件を設定しセルの色を変える
条件を設定しセルの色を変えることができます。
例えば、プラスの値の場合に青、マイナスの値の場合に赤、などです
以下、コードです。
# 条件を設定しセルの色を変える
df.style.where(lambda x: x > 0,
'background-color: red; color: white',
'background-color: blue; color: white')
以下、実行結果です。

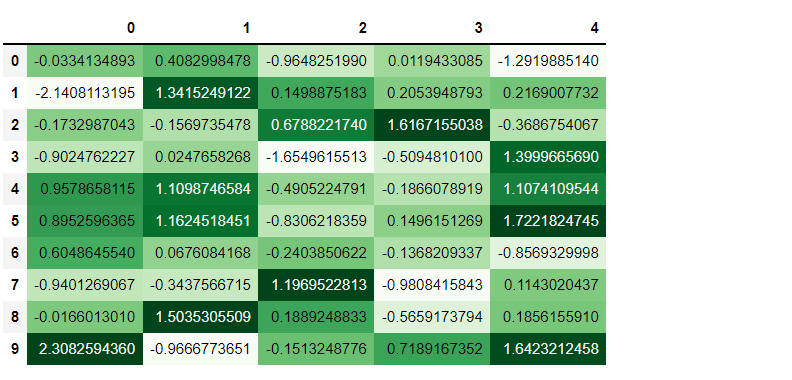
セルの値に応じて色に濃淡を付ける
セルの値に応じて色に濃淡(グラデーション)を付けることができます。
以下、コードです。
# セルの値に応じて色に濃淡を付ける df.style.background_gradient(cmap='Greens')
以下、実行結果です。
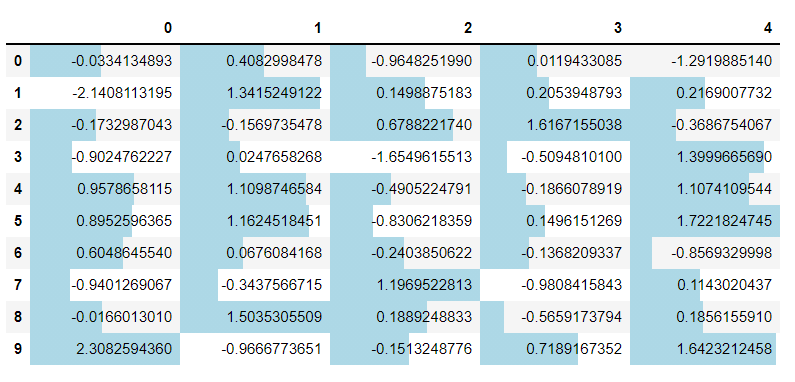
セルに値に応じた長さの棒グラフを表示させる
セルに値に応じた長さの棒グラフを表示させることができます。
以下、コードです。
# セルに値に応じた長さの棒グラフを表示させる df.style.bar(color = 'lightblue')
以下、実行結果です。
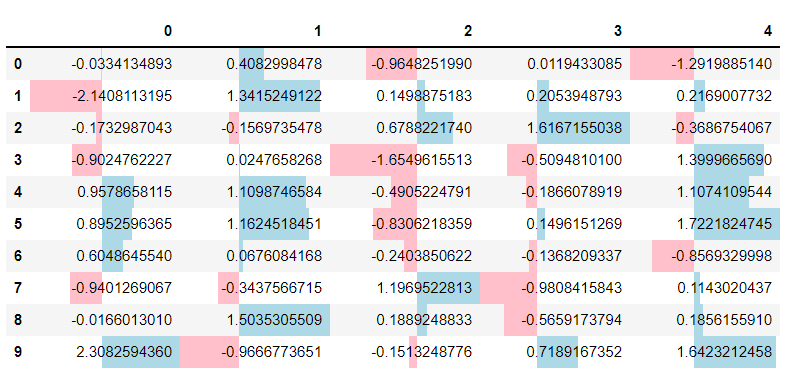
さらに、マイナスは左棒グラフ、プラスは右棒グラフという形で表現することもできます。
以下、コードです。
# セルに値に応じた長さの棒グラフを表示させる(マイナスは左棒グラフ、プラスは右棒グラフ) df.style.bar(align='mid', color=['pink', 'lightblue'])
以下、実行結果です。
各列の最大値と最小値に色を付ける
各列の最大値と最小値に色を付けることができます。
先ずは、最大値に色を付けてみます。
以下、コードです。
# 各列の最大値に色を付ける df.style.highlight_max(color='lightblue')
以下、実行結果です。
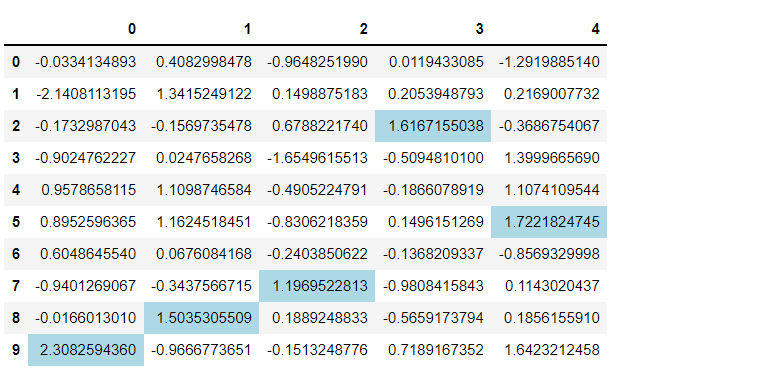
次に、最小値に色を付けてみます。
以下、コードです。
# 各列の最小値に色を付ける df.style.highlight_min(color='pink')
以下、実行結果です。
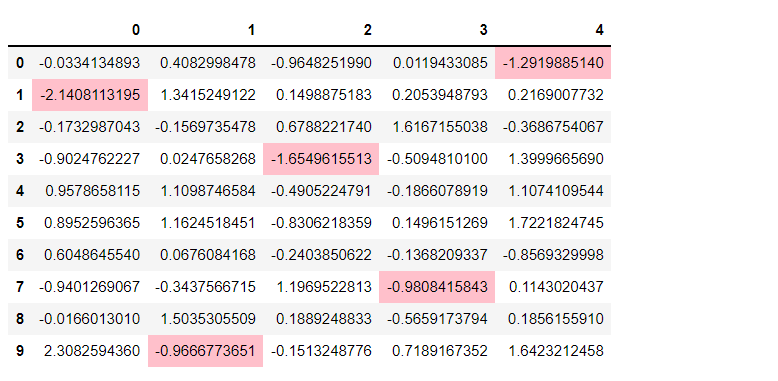
最後に、最大値と最小値の両方に色を付けて表示させてみます。
以下、コードです。
# 各列の最大値と最小値に色を付ける df.style \ .highlight_max(color='lightblue') \ .highlight_min(color='pink')
以下、実行結果です。
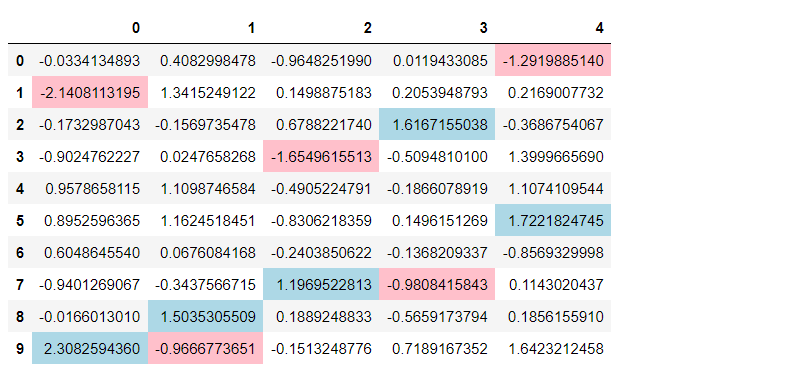
まとめ
今回は「pandasデータフレームのjupyter上の出力表示をちょっと変える方法」というお話しをしました。
単に、Jupyter上のデータフレームなどの出力フォーマットを変えるだけです。
今回は主要なものだけを紹介しました。
もっと色々なことができますので、興味のある方は調べて実施してみてください。