

H2O(エイチツーオー)は、H2O.ai社によって開発された、インメモリ型の機械学習プラットフォームです。
教師あり学習や教師なし学習などの機械学習系の数理モデルを構築することができます。
嬉しいのが、ノンコードで機械学習モデルを構築することのできるH2O FlowというGUI環境が用意されていることです。
さらに嬉しいことに、AutoML(自動機械学習)機能があるため、面倒なパラメータ調整などを全自動で実施してくれる機能がついています。
ノンコードな機械学習モデル構築を可能にする H2O Flow の簡単な使い方について、以下のような順番で説明していきます。
- その1 H2O Flow の起動
- その2 H2O Flow で実施する教師あり学習(回帰問題)
- その3 H2O Flow で実施する教師あり学習(分類問題)
- その4 H2O Flow で実施する自動機械学習AutoML(回帰問題)
- その5 H2O Flow で実施する自動機械学習AutoML(分類問題)
- その6 H2O Flow で実施する教師なし学習(次元削減・集約) ⇒ 今回
- その7 H2O Flow で実施する教師なし学習(異常検知)
- その8 H2O Flow で実施する教師なし学習(クラスタリング)
- その9 H2O Flow の保存と読込
前回は、その5 の「H2O Flow で実施する自動機械学習AutoML(分類問題)」について説明しました。
今回は、その6 の「H2O Flow で実施する教師なし学習(次元削減・集約)」について説明します。
次元削減・集約アルゴリズム
次元削減・集約とは、高次元の特徴量(データ)を低次元の特徴量(データ)で表現し直すことです。
伝統的には、特異値分解(SVD、Singular Value Decomposition)を活用した主成分分析(PCA、Principal Components Analysis)が有名です。
ここで登場するのは、以下の2つです。
- PCA:主成分分析(Principal Components Analysis)
- GLRM:一般化低ランクモデル(Generalized Low Rank Model)
GLRMは、PCAを発展させたようなもので、データに欠測値があっても問題ありません。
欠測値のある高次元の特徴量(データ)を相手にする場合、PCAは欠測のある特徴量を削除するか、欠測している部分を平均値などで補完する必要があります。
今回は、欠測値のある高次元の特徴量(データ)に対し、以下の2種類の次元削減・集約を実施します。
- PCAで次元削減・集約
- GLRMで次元削減・集約
H2O Flowの起動
まずは、H2O Flowの起動です。
「h2o.jar」というJARファイルをダブルクリックすることでH2O Flowが起動します。

もしくは、コマンドプロンプト上などで、「h2o.jar」ファイルのあるフォルダまで移動し、以下のコードを実行することでも実行できます。
java -jar h2o.jar
実行したら、ブラウザに以下のURLを入力しアクセスします。
そうすると、以下のようなH2O Flowの実行画面が表示されます。

今回利用するデータセット
東京都のGISデータ(町丁目単位 – 4747行×268変数)を利用します。以下の政府統計名・統計表名から作成しました。
| 政府統計名 | 統計表名 |
| 経済センサス基礎調査2014年 | 産業(大分類)別・従業者規模別全事業所数及び男女別従業者数 |
| 経営組織別民営事業所数及び従業者数 | |
| 経済センサス活動調査2016年 | 産業(大分類)別民営事業所数及び男女別従業者数 |
| 経営組織(4区分)別民営事業所数及び従業者数 | |
| 従業者規模(6区分)別民営事業所数及び従業者数 | |
| 国勢調査2015年 | 男女別人口総数及び世帯総数 |
| 年齢(5歳階級、4区分)別、男女別人口 | |
| 世帯人員別一般世帯数 | |
| 世帯の家族類型別一般世帯数 | |
| 住宅の種類・所有の関係別一般世帯数 | |
| 住宅の建て方別世帯数 | |
| 産業(大分類)別及び従業上の地位別就業者数 | |
| 職業(大分類)別就業者数 | |
| 世帯の経済構成別一般世帯数 |
CSVファイルは、以下からダウンロードできます。
tokyo_gis_dataset
https://www.salesanalytics.co.jp/6hse
Excelファイルは、以下からダウンロードできます。こちらに、変数定義などが記載されています。
tokyo_gis.xlsx
https://www.salesanalytics.co.jp/mvfi
データセットの一部は欠測しています。
データの読み込み
メニューから、[Data]⇒[Import Files…]を選択します。

以下のようなImport Filesの入力画面が現れます。
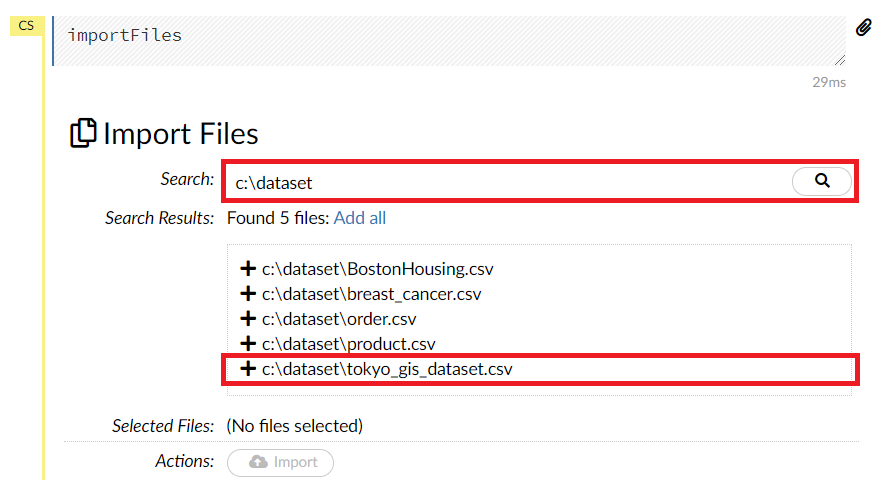
Searchにデータのあるフォルダ名(例 C:\dataset)などを入力し、虫眼鏡をクリックします。そうすると、そのフォルダ内にある候補ファイルが表示されます(例 C:\dataset\tokyo_gis_dataset.csv)ので、読み込みたいファイルの左側の「+」をクリックします。
一番下のActionのところにあるImportがアクティブになりますので、このImportをクリックします。
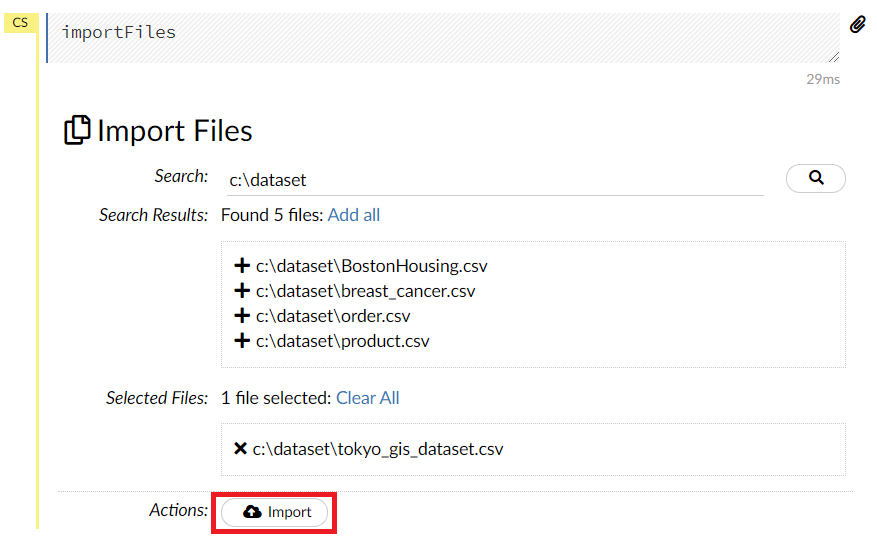
問題なければ、以下のような画面になり、Parse these files…がアクティブになりますので、このParse these files…をクリックします。
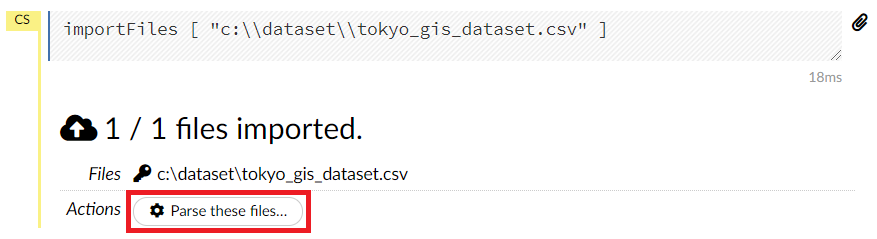
以下のような画面になります。
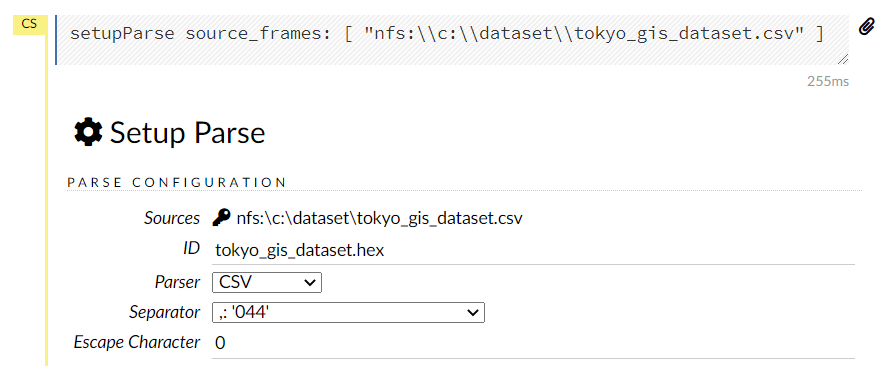
この画面を下にスクロールし、一番下のParseをクリックします。

データの読み込みが開始されます。
上手くデータが読み込めると、以下のような画面になり、Viewがアクティブになりますので、このViewをクリックします。

以下のような画面が表示されます。この画面上で、データの分割やモデル構築などを実施していきます。
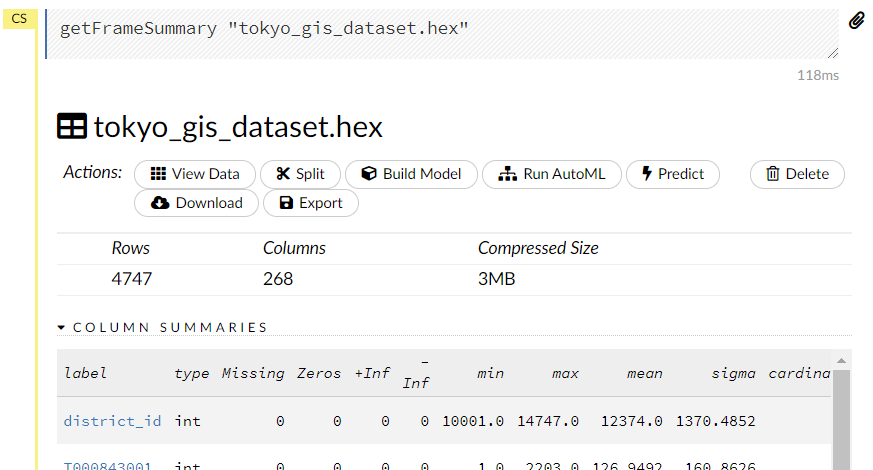
PCAで次元削減・集約
PCAモデルを構築し、高次元の特徴量(データ)を低次元の特徴量(データ)に次元削減・集約していきます。
Build Modelをクリックします。
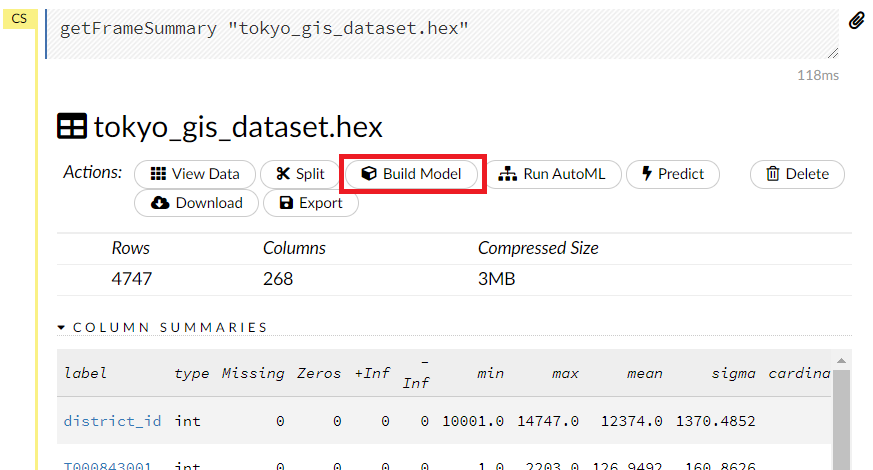
H2Oに実装されているモデル(アルゴリズム)が表示されますので、Principal Components Analysis を選択します。
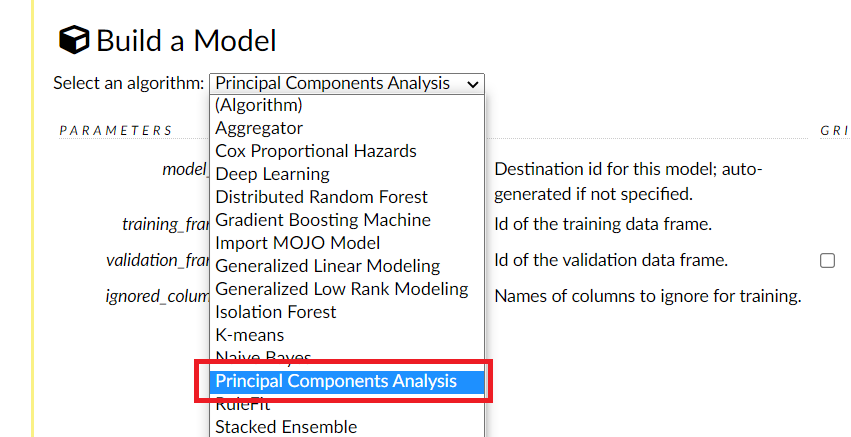
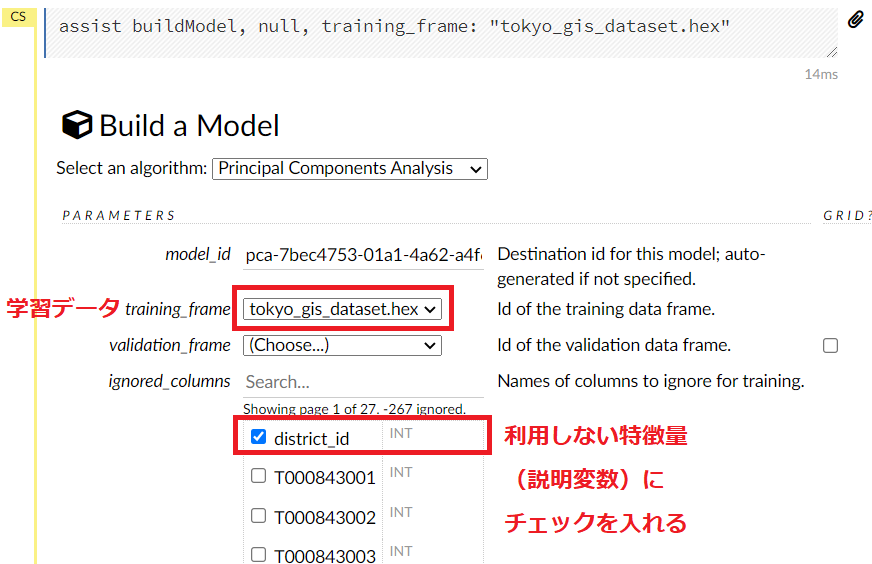
そうすると、選択したモデル(アルゴリズム)で学習し評価するための設定をするための画面が表示されます。
今回は、学習データ(例 tokyo_gis_dataset.hex)の指定と、使用しない特徴量の設定(変数「district_id」にチェックを入れる)します(他はデフォルトの設定のまま)。
この画面を下にスクロールすると、集約する次元数(主成分の数)を設定できる項目(k)が登場します。今回は、20変数に設定します。

さらに画面を下にスクロールしていくと、一番下にBuild Modelというボタンがあるので、このBuild Modelをクリックします。

学習が終了すると、以下のような画面になり、Viewがアクティブになりますので、このViewをクリックします。
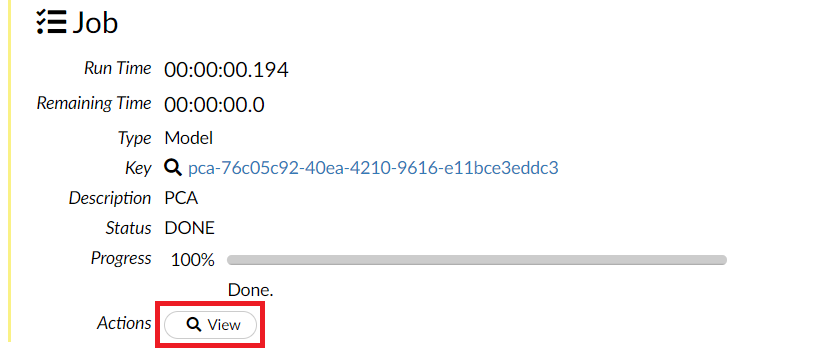
そうすると、学習結果を見るとこができます。Predict をクリックし次元削減・集約された低次元の特徴量(データ)を求めます。
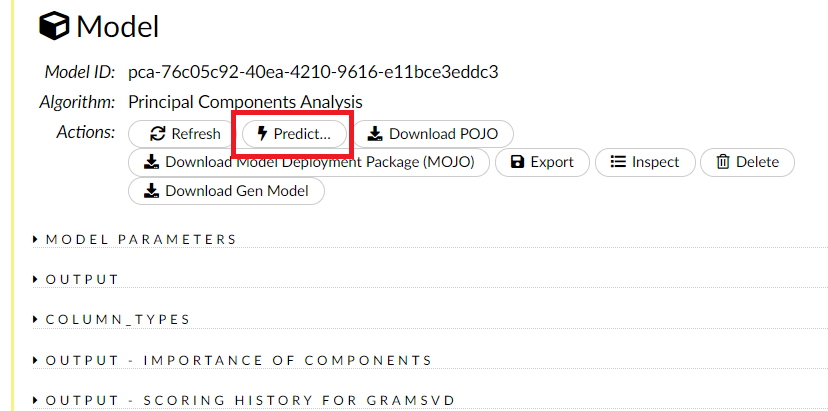
今回は、学習で利用したデータセットの低次元の特徴量(データ)を求めるため、Frameに学習に利用したデータセット(tokyo_gis_dataset.hex)を設定し、Predictをクリックします。
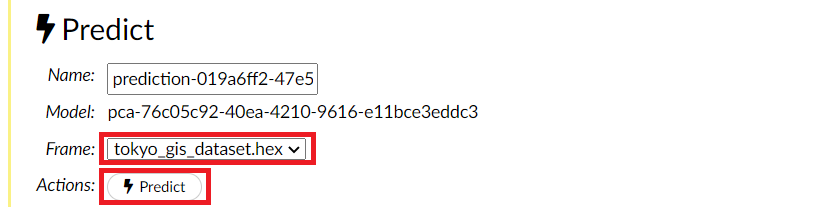
次元削減・集約された低次元の特徴量(データ)が出力されます。Predictionsの右側にリンクがあるのでクリックすると、次元削減・集約された低次元の特徴量(データ)を見ることができます。
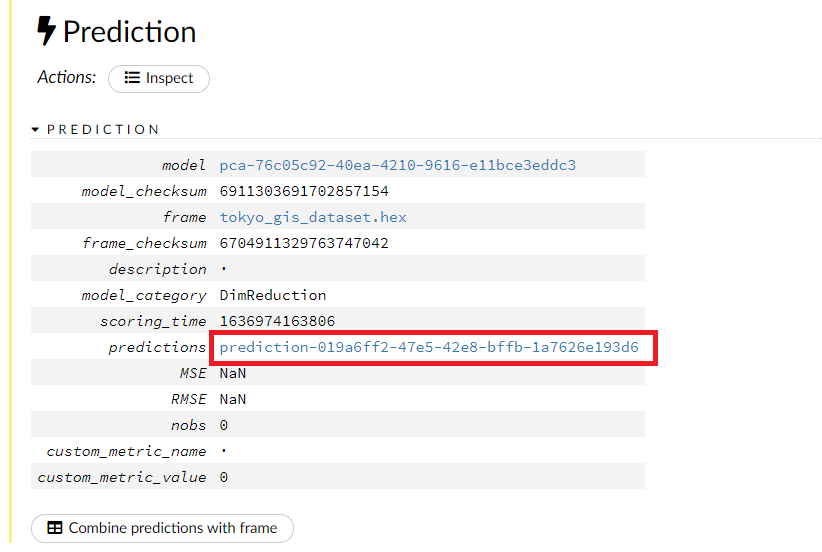
次元削減・集約された低次元の特徴量(データ)の変数の概要が見れます。欠測値(Missing)があることが分かります。
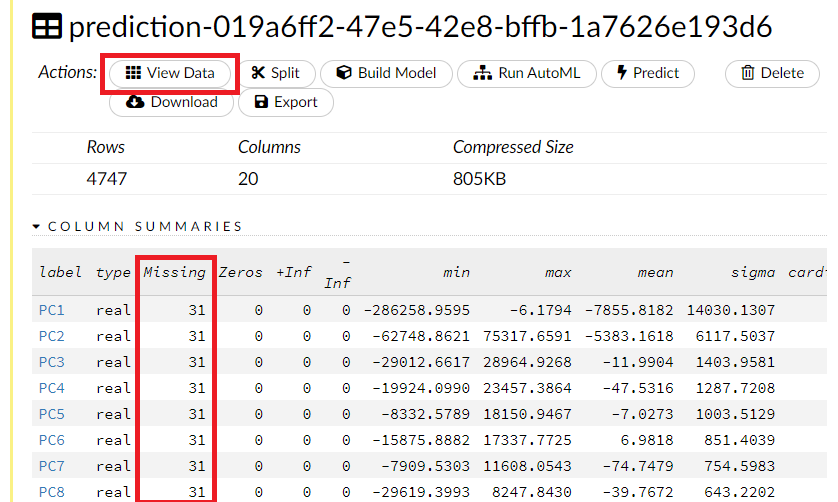
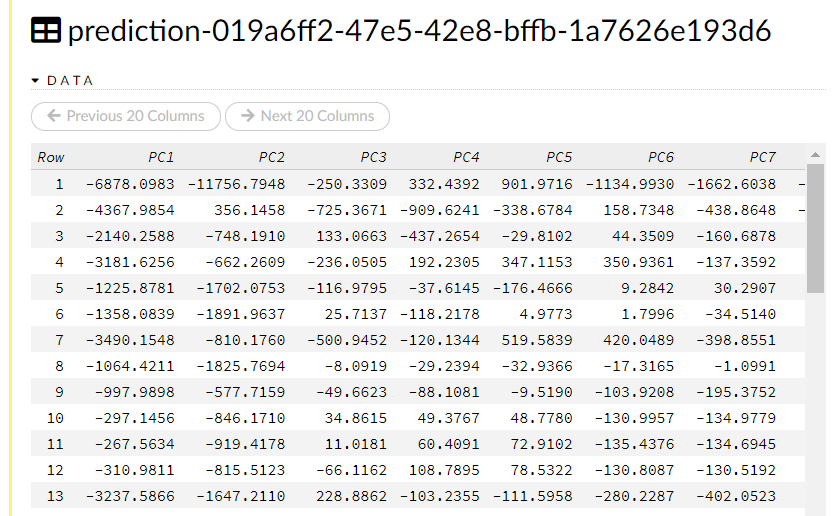
View Dataをクリックすると、以下のような次元削減・集約された低次元の特徴量(データ)が見れます。
ちなみに、H2O Flow上のデータセットは、メニューから、[Data]⇒[List All Frames]を選択することで表示されます。
今回は、次のようになっています。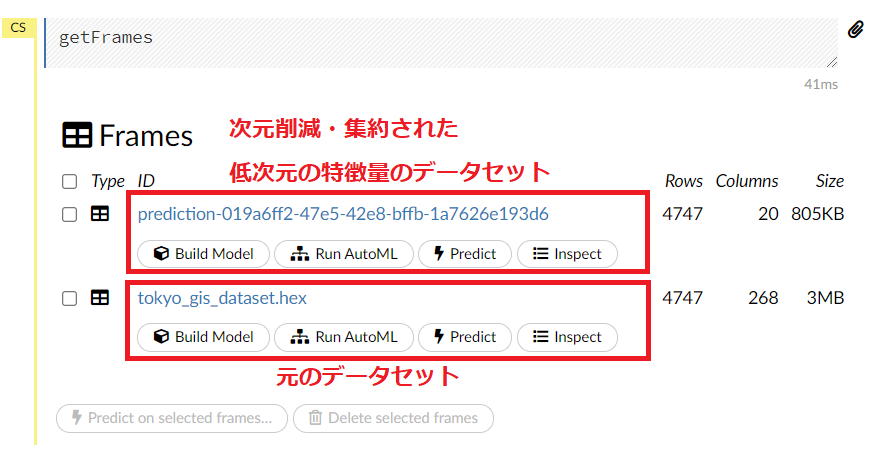
上のデータセットが、次元削減・集約された低次元の特徴量のデータセットで、下が元の高次元の特徴量のデータセットです。リンクをクリックすると、そのデータセットを見ることができます。
次に、元の高次元の特徴量のデータセットに対し、GLRMで次元削減・集約するために、下のデータセット(tokyo_gis_dataset.hex)をクリックし表示させます。
以下のように表示されます。
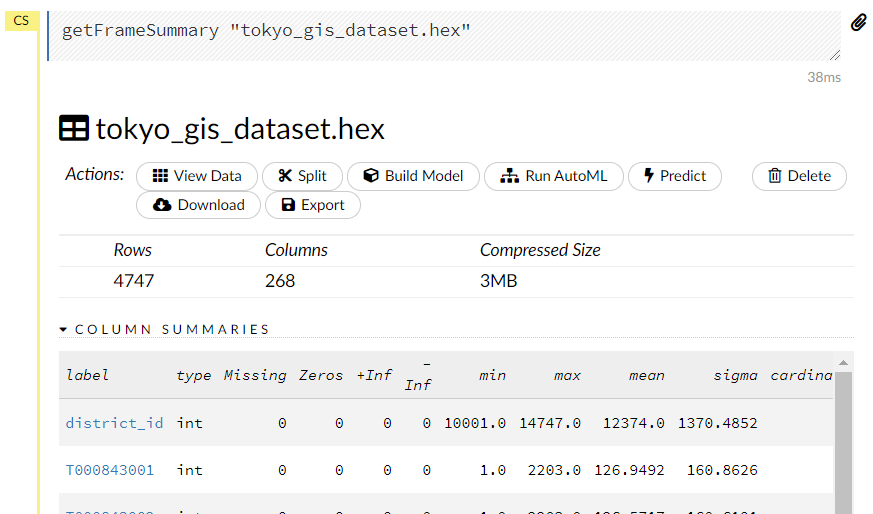
GLRMで次元削減・集約
GLRMのモデルを構築し、高次元の特徴量(データ)を低次元の特徴量(データ)に次元削減・集約していきます。
Build Modelをクリックします。
H2Oに実装されているモデル(アルゴリズム)が表示されますので、Generalized Low Rank Modeling を選択します。
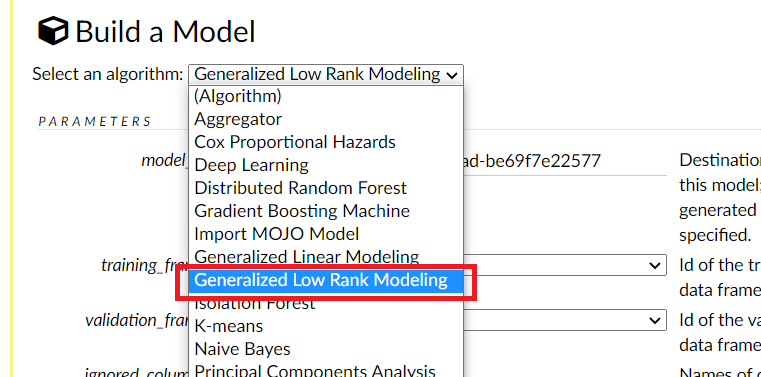
そうすると、選択したモデル(アルゴリズム)で学習し評価するための設定をするための画面が表示されます。
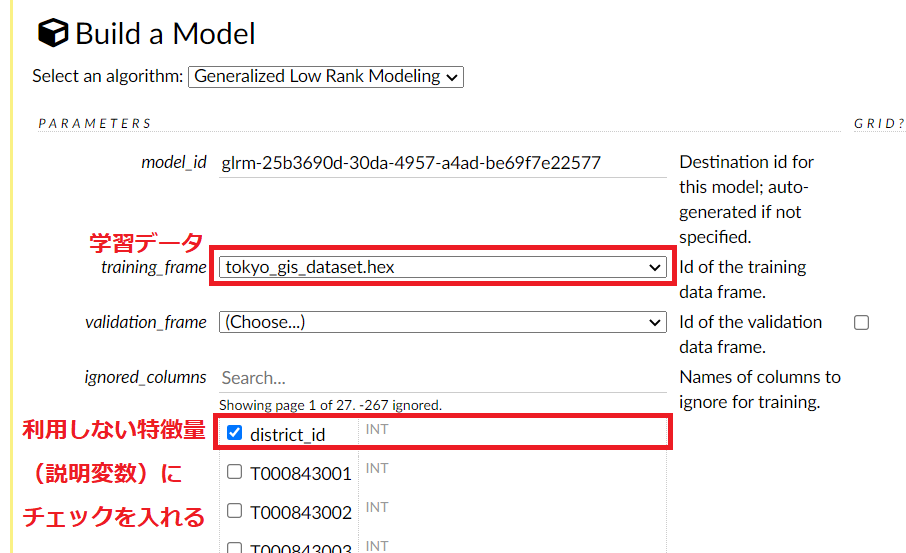
今回は、学習データ(例 tokyo_gis_dataset.hex)の指定と、使用しない特徴量の設定(変数「district_id」にチェックを入れる)します(他はデフォルトの設定のまま)。
この画面を下にスクロールすると、次元削減・集約された低次元の特徴量のデータセットの名称を設定する項目(representation_name)と集約する次元数を設定できる項目(k)が登場します。今回は、representation_nameを「PC」、kを「20」変数に設定します。
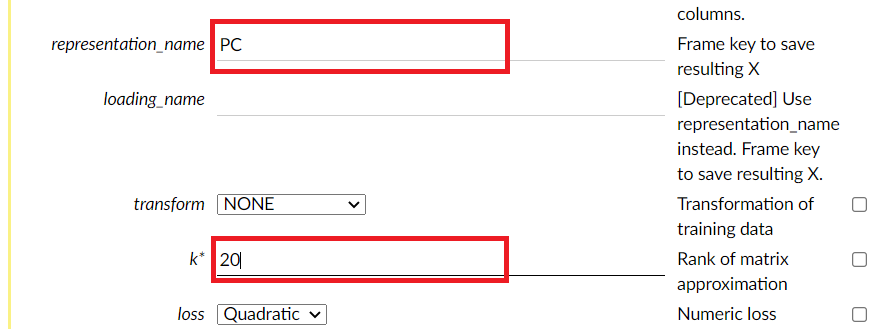
さらに画面を下にスクロールしていくと、一番下にBuild Modelというボタンがあるので、このBuild Modelをクリックします。
学習が終了すると、以下のような画面になり、Viewがアクティブになりますので、このViewをクリックします。
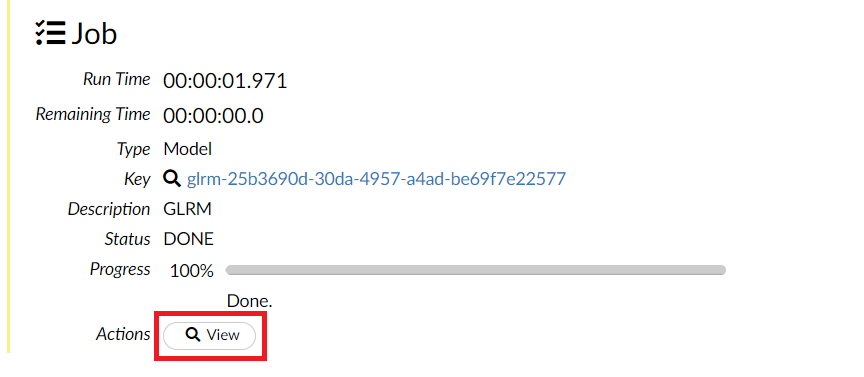
そうすると、学習結果を見るとこができます。
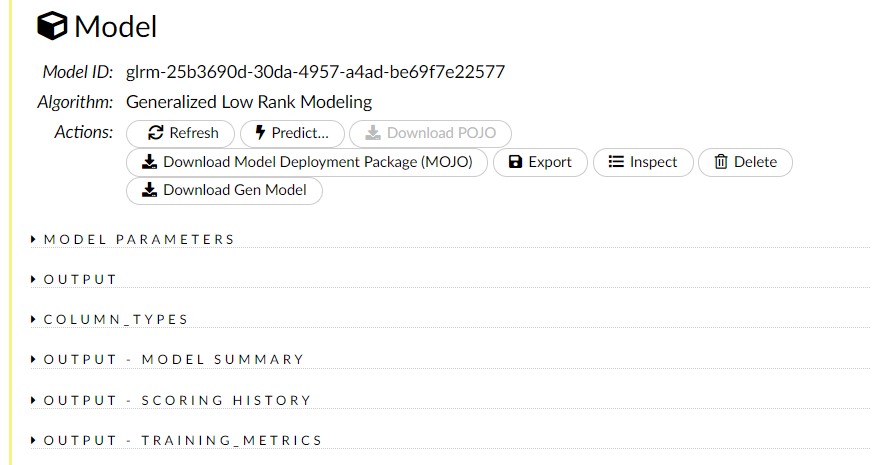
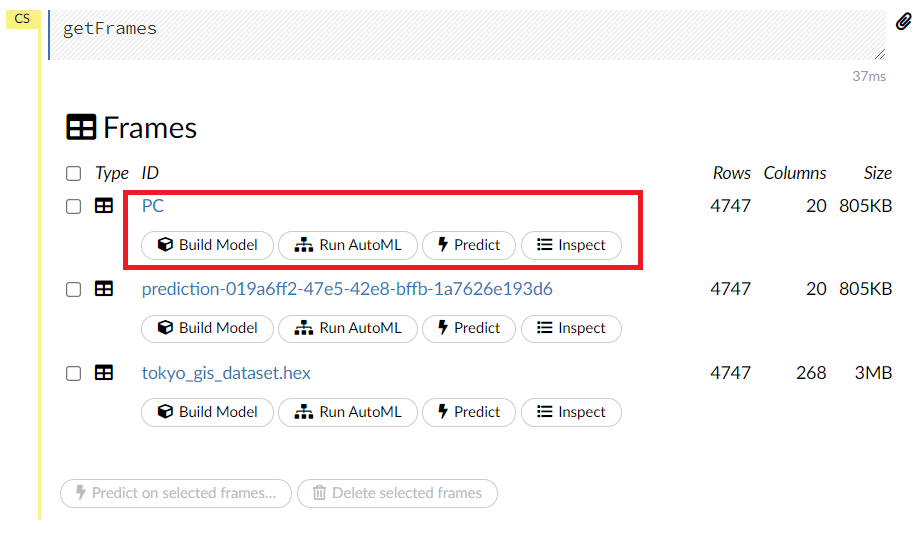
次元削減・集約された低次元の特徴量のデータセットは、すでに計算されデータセット(今回の場合は「PC」)として存在します。メニューから、[Data]⇒[List All Frames]を選択し、その求めた低次元の特徴量のデータセット(今回の場合は「PC」)を見てみます。
今回は、次のようになっています。低次元の特徴量のデータセット(今回の場合は「PC」)のリンクをクリックし、そのデータセットを見てみます。
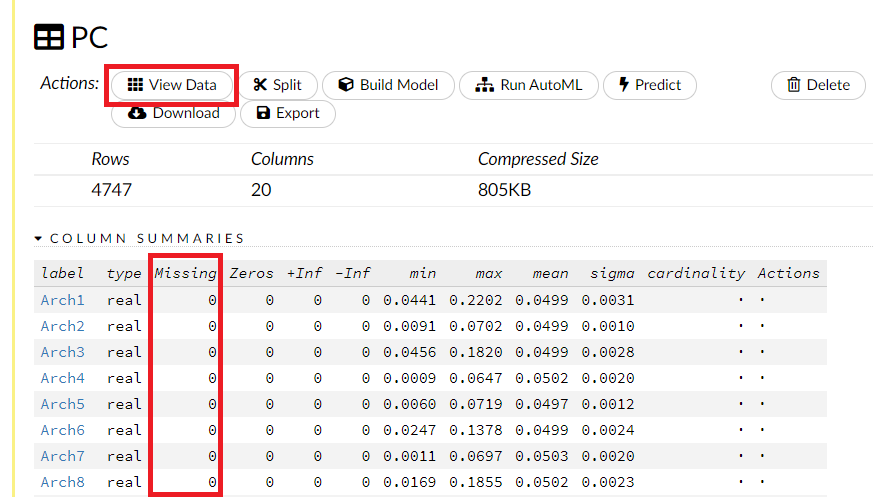
次元削減・集約された低次元の特徴量(データ)の変数の概要が見れます。欠測値(Missing)がないことが分かります。
PCAの場合は、元データに欠測値のあるケースは求めた低次元の特徴量(データ)も欠測します。GLRMの場合は、元データに欠測値があっても、求めた低次元の特徴量(データ)は欠測しません。もちろん、欠測状況にもよりますが……
View Dataをクリックすると、以下のような次元削減・集約された低次元の特徴量(データ)が見れます。
次回
今回は、その6の「H2O Flow で実施する教師なし学習(次元削減・集約)」について説明しました。
- その1 H2O Flow の起動
- その2 H2O Flow で実施する教師あり学習(回帰問題)
- その3 H2O Flow で実施する教師あり学習(分類問題)
- その4 H2O Flow で実施する自動機械学習AutoML(回帰問題)
- その5 H2O Flow で実施する自動機械学習AutoML(分類問題)
- その6 H2O Flow で実施する教師なし学習(次元削減・集約)
- その7 H2O Flow で実施する教師なし学習(異常検知) ⇒ 次回
- その8 H2O Flow で実施する教師なし学習(クラスタリング)
- その9 H2O Flow の保存と読込
次回は、その7の「H2O Flow で実施する教師なし学習(異常検知)」について説明します。