
機械学習系のモデルを構築するときに外せない作業の1つが、特徴量エンジニアリング(Feature Engineering)です。
特徴量エンジニアリングの主な作業は、特徴量生成と特徴量選択(変数選択)です。
FeatureWizは、Python上で動くscikit-learn(sklearn)互換の特徴量エンジニアリング環境で、Pythonで記述された並列計算用のオープンソースライブラリーDaskを活用することで、非常に大きなデータセットに対しより良いパフォーマンスを発揮するようになりました。
今回は、「大容量データにも対応した特徴量エンジニアリングライブラリーFeatureWiz(Python)」のお話しを、一般的な使い方を説明しながら、大容量データセットに対する場合にどうすればいいのかを、簡単に説明します。
Contents [hide]
- FeatureWiz の主な機能
- FeatureWiz ライブラリーのインストール
- 実施すること
- Boston house prices(回帰問題)
- Boston house prices|データセットの概要
- Boston house prices|ライブラリー読み込み
- Boston house prices|データセット読み込みと前処理
- Boston house prices|モデル設定
- Boston house prices|学習とテスト(全ての特徴量を利用)
- Boston house prices|特徴量選択(変数選択)
- Boston house prices|学習とテスト(選択特徴量を利用)
- 通信会社の顧客離反(分類問題)
- 通信会社の顧客離反|データセットの概要
- 通信会社の顧客離反|ライブラリー読み込み
- 通信会社の顧客離反|データセット読み込みと前処理
- 通信会社の顧客離反|モデル設定
- Boston house prices|学習とテスト(全ての特徴量を利用)
- 通信会社の顧客離反|特徴量選択(変数選択)
- 通信会社の顧客離反|学習とテスト(選択特徴量を利用)
- まとめ
FeatureWiz の主な機能
- 特徴量生成機能
- interactions:乗算による特徴量生成
- groupby:グループ集計(カテゴリカル変数で量的変数を集計)
- target:カテゴリカル変数のエンコーディング
- 特徴量選択機能
- SULOV:相関係数ベースの変数選択
- Recursive XGBoost:SULOV後にXGBoostを使用し最良の特徴量(変数)セットを探索
特徴量選択(変数選択)後、実務上どうしても必要な特徴量(変数)は、特徴量選択(変数選択)で弾かれたとしても採用してください。
FeatureWiz ライブラリーのインストール
コマンドプロンプト上で、pipでインストールするときのコードは以下です。
pip install xlrd pip install featurewiz --ignore-installed --no-deps
実施すること
データセットの全ての特徴量(説明変数)を使った予測精度と、FeatureWizで特徴量選択(変数選択)し絞り込んだ特徴量(説明変数)を使った予測精度を比較し、どの程度予測精度が悪化するのかを見ていきます。
- データセットの全ての特徴量(説明変数)を使った場合
- FeatureWizで特徴量選択(変数選択)し絞り込んだ特徴量(説明変数)を使った場合
今回は、木系の以下の3つの数理モデルを構築していきます。
- 決定木(tree): DecisionTreeRegressor、DecisionTreeClassifier
- ランダムフォレスト(RandomForest): RandomForestRegressor、RandomForestClassifier
- アダブースト(AdaBoost): AdaBoostRegressor、AdaBoostClassifier
後ろにRegressorというワードが付いているのが回帰問題用のモデル(目的変数Yが量的変数)で、後ろにClassifierというワードが付いているのが回帰問題用のモデル(目的変数Yが質的変数)です。
ランダムフォレストは決定木ベースのバギング系のアンサンブル学習モデルで、アダブーストは決定木ベースのブースティング系のアンサンブル学習モデルです。今回のアダブーストは、ランダムフォレストをベースに設定しています。
要は、アダブースト、ランダムフォレスト、決定木の順に、予測精度が高いことが予想されます。
モデルの話しはこれ以上詳しくは説明いたしません。興味のある方は調べて頂ければと思います。
サンプルデータとしては、以下の2つを使い説明します。
- Boston house pricesデータ:回帰問題用のサンプルデータ
- 通信会社の顧客離反データ:分類問題用のサンプルデータ
Boston house prices(回帰問題)
Boston house prices|データセットの概要
回帰問題でよく登場するみんな大好き「ボストン住宅価格(BostonHousing)」データセットです。
以下、データ項目です。
- CRIM: 犯罪率
- ZN: 広い家の割合(25,000平方フィートを超える区画に分類される住宅地の割合)
- INDUS: 非小売業の割合
- CHAS: 川と隣接(川に隣接している場合は1、そうでない場合は0)
- NOX: NOx濃度(0.1ppm単位)
- RM: 平均部屋数
- AGE: 古い家の割合(1940年より前に建てられた持ち家の割合)
- DIS: 主要施設への距離(5つあるボストン雇用センターまでの加重距離)
- RAD: 主要高速道路アクセス指数
- TAX: 固定資産税率(10,000ドル当たり)
- PTRATIO: 生徒と先生の比率
- B: 1000×(黒人割合- 0.63)の二乗
- LSTAT: 低所得者人口の割合
- MEDV:住宅価格の中央値(1000ドル単位)
項目数は14。
- 目的変数Y:一番下の「MEDV」(住宅価格)
- 説明変数X(特徴量):残り13つのデータすべて
要するに、「MEDV」(住宅価格)を他の変数で当てる問題です。
CSVファイルは、以下からダウンロードできます。
BostonHousing.csv
https://www.salesanalytics.co.jp/0leq
Boston house prices|ライブラリー読み込み
先ずは、ライブラリーの読み込みです。
以下、コードです。
# ライブラリーの読み込み import pandas as pd import numpy as np from featurewiz import featurewiz from sklearn.tree import DecisionTreeRegressor from sklearn.ensemble import RandomForestRegressor from sklearn.ensemble import AdaBoostRegressor from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import OrdinalEncoder from sklearn.preprocessing import LabelEncoder from sklearn.metrics import mean_absolute_percentage_error from sklearn.metrics import mean_absolute_error from sklearn.metrics import mean_squared_error import matplotlib.pyplot as plt
Boston house prices|データセット読み込みと前処理
データセットを読み込みます。
以下、コードです。
# データセットの読み込み data_path = 'https://www.salesanalytics.co.jp/0leq' df = pd.read_csv(data_path) df.head() #確認
以下、実行結果です。
データ状況を確認します。
以下、コードです。
# データセットの状況の確認 df.info()
以下、実行結果です。
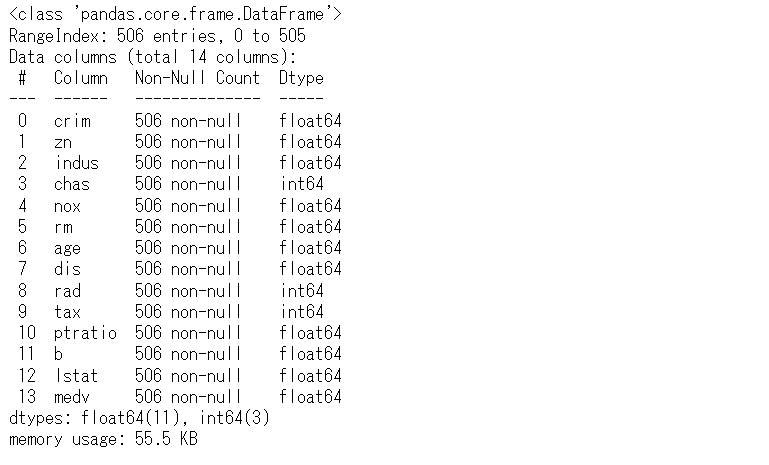
変数「chas」(川の隣かどうか? 1:Yes、0:No)が0-1の整数値の量的データ(ニューメリカルデータ)になっていますが、質的データ(カテゴリカルデータ)です。型変換します。
以下、コードです。
# chasの値変換(1:Yes、0:No)
df = df.replace({'chas':{1:'Yes', 0:'No'}})
df.head() #確認
以下、実行結果です。
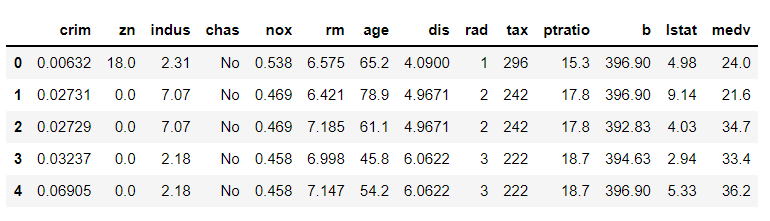
再度、データ状況を確認します。
以下、コードです。
# データセットの状況の確認 df.info()
以下、実行結果です。
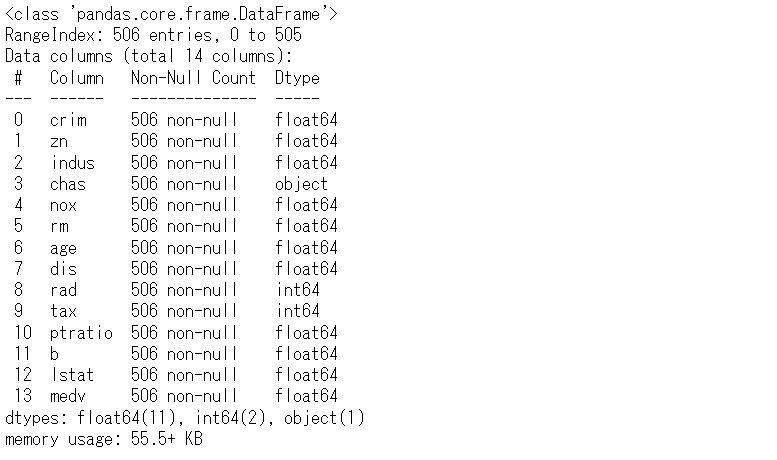
変数「chas」(川の隣かどうか? 1:Yes、0:No)がObject型(カテゴリカルデータの型の1つ)に変換されていることが分かります。
次に、モデル構築用の学習データと、構築したモデルを検証するテストデータに分割します。
以下、コードです。
# データセットの分割(学習データとテストデータ)
df_train, df_test = train_test_split(df,
test_size=0.3,
random_state=123)
量的データ(ニューメリカルデータ)を標準化します。学習データで標準化モデルを作り、それを学習データとテストデータに適用します。
以下、コードです。
# 標準化
scaler = StandardScaler()
df_train[df_train.drop(columns=["medv"]).select_dtypes("number").columns] = scaler.fit_transform(df_train.drop(columns=["medv"]).select_dtypes("number"))
df_test[df_test.drop(columns=["medv"]).select_dtypes("number").columns] = scaler.transform(df_test.drop(columns=["medv"]).select_dtypes("number"))
この学習データとテストデータを使って、モデル構築と精度検証を実施していきます。
Boston house prices|モデル設定
今回は、以下の3つの数理モデルを構築しますので、その設定を実施します。
- 決定木(tree): DecisionTreeRegressor
- ランダムフォレスト(RandomForest): RandomForestRegressor
- アダブースト(AdaBoost): AdaBoostRegressor
以下、コードです。
# 構築するモデル設定
models = {
'tree': DecisionTreeRegressor(random_state=123),
'RandomForest': RandomForestRegressor(random_state=123),
'AdaBoost': AdaBoostRegressor(RandomForestRegressor(random_state=123),
learning_rate=0.1,
n_estimators=100,
random_state=123)
}
Boston house prices|学習とテスト(全ての特徴量を利用)
データセットの全ての特徴量(説明変数)を使った場合です。
特徴量(説明変数)と目的変数に分け、質的データ(カテゴリカルデータ)を数値ラベル値に変換します。
以下、コードです。
# 学習データとテストデータ
X_train = df_train.drop(columns=["medv"])
y_train = df_train["medv"]
X_test = df_test.drop(columns=["medv"])
y_test = df_test["medv"]
# カテゴリカル変数をOrdinalEncoderで数値ラベルに変換
ordEnc = OrdinalEncoder()
X_train[X_train.select_dtypes("object").columns] \
= ordEnc.fit_transform(X_train.select_dtypes("object"))
X_test[X_test.select_dtypes("object").columns] \
= ordEnc.transform(X_test.select_dtypes("object"))
このデータを使い、学習データでモデル構築し、テストデータで構築したモデルの検証を、実施します。
以下、コードです。
# 結果を格納するハコ
scores = {}
# 予測モデル構築と精度検証
for model_name, model in models.items():
model.fit(X_train, y_train) #学習データで予測モデル構築
y_pred = model.predict(X_test) #テストデータの目的変数Yを予測
scores[(model_name, 'RMSE')] = np.sqrt(mean_squared_error(y_test, y_pred))
scores[(model_name, 'MAE')] = mean_absolute_error(y_test, y_pred)
scores[(model_name, 'MAPE')] = mean_absolute_percentage_error(y_test, y_pred)
scores[(model_name, 'R2')] = model.score(X_test,y_test)
# 出力
pd.Series(scores).unstack()
以下、実行結果です。
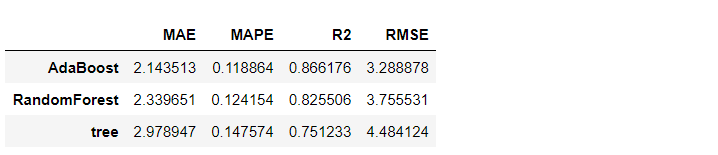
AdaBoostだけの結果を見ます。
- MAE:2.14
- MAPE:0.12
- R2:0.87
- RMSE:3.29
R2は決定係数です。
RMSE(二乗平均平方根誤差、Root Mean Squared Error)とMAE(平均絶対誤差、Mean Absolute Error)、MAPE(平均絶対パーセント誤差、Mean absolute percentage error)の定義は以下です。
以下の記号を使い精度指標の説明をします。
■ 二乗平均平方根誤差(RMSE、Root Mean Squared Error)
■ 平均絶対誤差(MAE、Mean Absolute Error)
■ 平均絶対パーセント誤差(MAPE、Mean absolute percentage error)
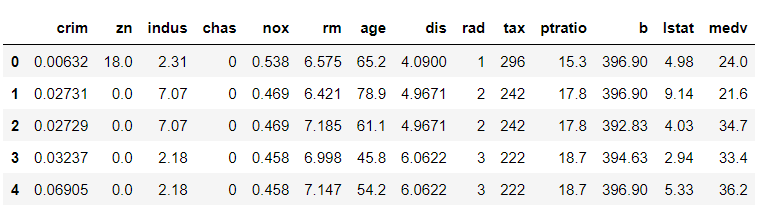
最後に、AdaBoostモデルで予測したテストデータの目的変数の予測値と実測値の散布図(横:予測値、縦:実測値)を出力してみます。
以下、コードです。
# AdaBoost散布図
y_pred = model.predict(X_test)
plt.scatter(y_test, y_pred)
plt.xlabel("True(y_test)")
plt.ylabel("Predicted(y_pred)")
plt.grid(True)
plt.show()
以下、実行結果です。
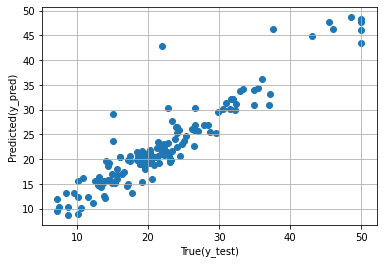
Boston house prices|特徴量選択(変数選択)
FeatureWizで特徴量選択(変数選択)し絞り込んだ特徴量(説明変数)を使った場合です。
では、FeatureWizを使い、自動特徴量エンジニアリングを実施します。
以下、コードです。
# 目的変数Y(ターゲット)の変数名
target = 'medv'
# 自動特徴量エンジニアリング実行
features = featurewiz(df_train,
target,
corr_limit=0.80,
dask_xgboost_flag=False,
nrows=None,
verbose=1,
test_data=df_test
)
「dask_xgboost_flag」を「True」にすると、Daskを使った高速化ができるようになります。データ行(サンプル数)が多いデータのとき、「nrows」にサンプリング数を指定すると、そのサンプル数で特徴量エンジニアリングが自動で実施されます。このようにして、大容量データに対し処理を高速化することができます。
以下、実行結果です。
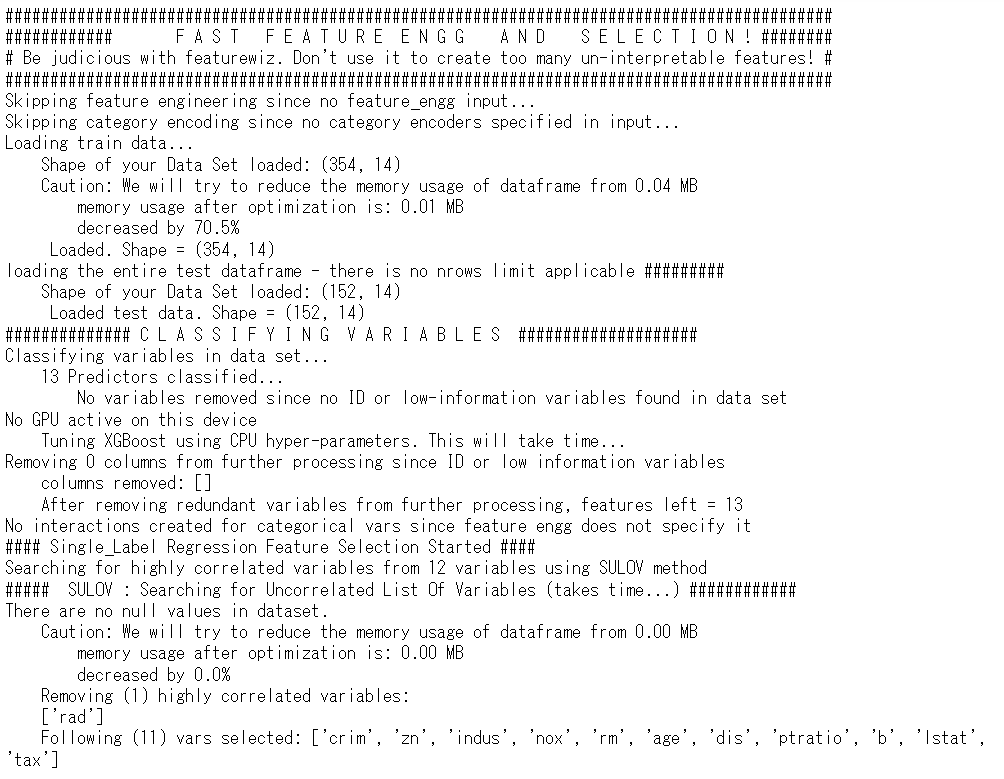
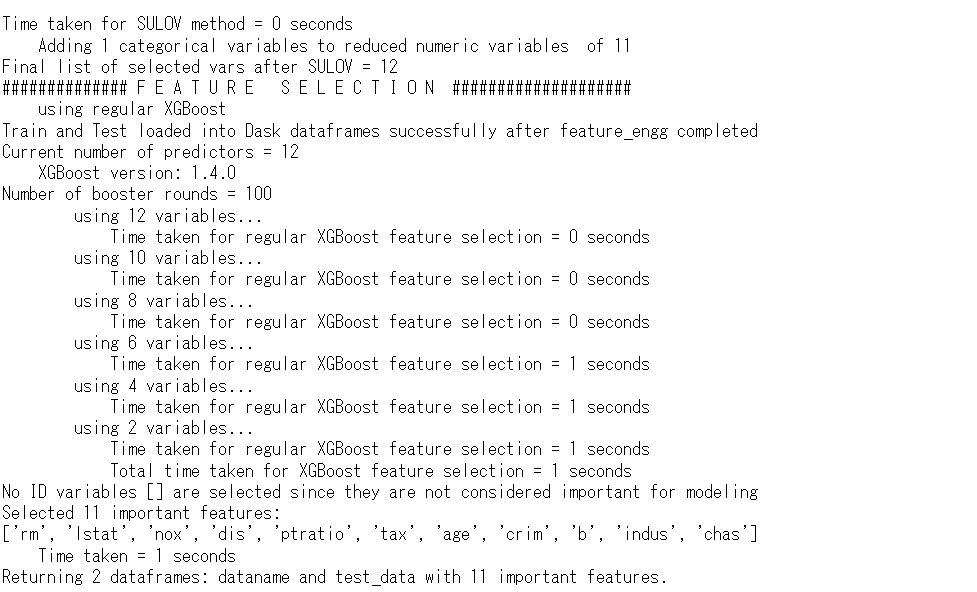
特徴量(説明変数)が13から11に減りました。
モデル構築したり予測精度検証したりするには、選択した特徴量(説明変数)のみのデータセットが必要になりますので、準備します。
以下、コードです。
# 選択した特徴量のみのデータ df_train_selected, df_test_selected = features
それぞれのデータセットの中を見てみます。
学習データを見てみます。以下、コードです。
# 学習データ(選択した特徴量+説明変数Y) df_train_selected.head()
以下、実行結果です。
テストデータを見てみます。以下、コードです。
# テストデータ(選択した特徴量) df_test_selected.head()
以下、実行結果です。
Boston house prices|学習とテスト(選択特徴量を利用)
特徴量(説明変数)と目的変数に分けます。
以下、コードです。
# 学習データとテストデータ X_train = df_train_selected.drop(columns=["medv"]) y_train = df_train_selected["medv"] X_test = df_test_selected y_test = df_test["medv"]
このデータを使い、学習データでモデル構築し、テストデータで構築したモデルの検証を、実施します。
以下、コードです。
# 結果を格納するハコ
scores = {}
# 予測モデル構築と精度検証
for model_name, model in models.items():
model.fit(X_train, y_train) #学習データで予測モデル構築
y_pred = model.predict(X_test) #テストデータの目的変数Yを予測
scores[(model_name, 'RMSE')] = np.sqrt(mean_squared_error(y_test, y_pred))
scores[(model_name, 'MAE')] = mean_absolute_error(y_test, y_pred)
scores[(model_name, 'MAPE')] = mean_absolute_percentage_error(y_test, y_pred)
scores[(model_name, 'R2')] = model.score(X_test,y_test)
# 出力
pd.Series(scores).unstack()
以下、実行結果です。
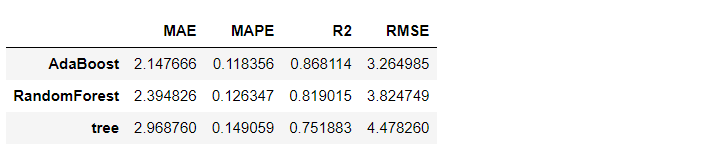
AdaBoostだけの結果を見ます。
- MAE:2.14 → 2.15
- MAPE:0.12 → 0.12
- R2:0.87 → 0.87
- RMSE:3.29 → 3.26
左が、データセットの全ての特徴量(説明変数)を使った予測精度です。
右が、FeatureWizで特徴量選択(変数選択)し絞り込んだ特徴量(説明変数)を使った予測精度です。
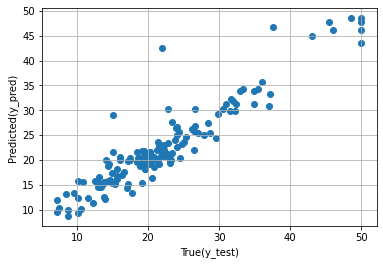
最後に、AdaBoostモデルで予測したテストデータの目的変数の予測値と実測値の散布図(横:予測値、縦:実測値)を出力してみます。
以下、コードです。
# AdaBoost散布図
y_pred = model.predict(X_test)
plt.scatter(y_test, y_pred)
plt.xlabel("True(y_test)")
plt.ylabel("Predicted(y_pred)")
plt.grid(True)
plt.show()
以下、実行結果です。
通信会社の顧客離反(分類問題)
通信会社の顧客離反|データセットの概要
通信会社の顧客の離反データ(Kaggleのサンプルデータ)を使います。以下のKaggleのページからCSVファイルをダウンロードしてお使いください。
Telco Customer Churn
目的変数Yは「離反」(Churn)です。
通信会社の顧客離反|ライブラリー読み込み
先ずは、ライブラリーの読み込みです。
以下、コードです。
# ライブラリーの読み込み import pandas as pd import numpy as np from featurewiz import featurewiz from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import AdaBoostClassifier from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import OrdinalEncoder from sklearn.preprocessing import LabelEncoder from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import f1_score from sklearn.metrics import plot_confusion_matrix
通信会社の顧客離反|データセット読み込みと前処理
データセットを読み込みます。
以下、コードです。
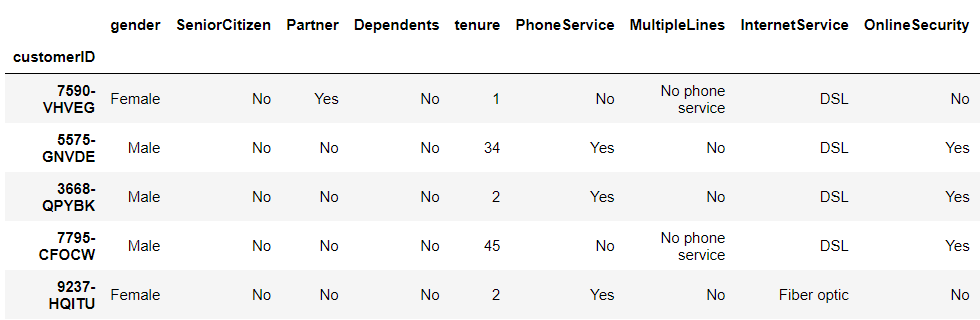
# データセットの読み込み data_path = 'C:\dataset\WA_Fn-UseC_-Telco-Customer-Churn.csv' df = pd.read_csv(data_path, index_col="customerID") df.head() #確認
PCのCドライブにあるフォルダ「dataset」に、「WA_Fn-UseC_-Telco-Customer-Churn.csv」というファイル名で格納した場合の例です。
以下、実行結果です。
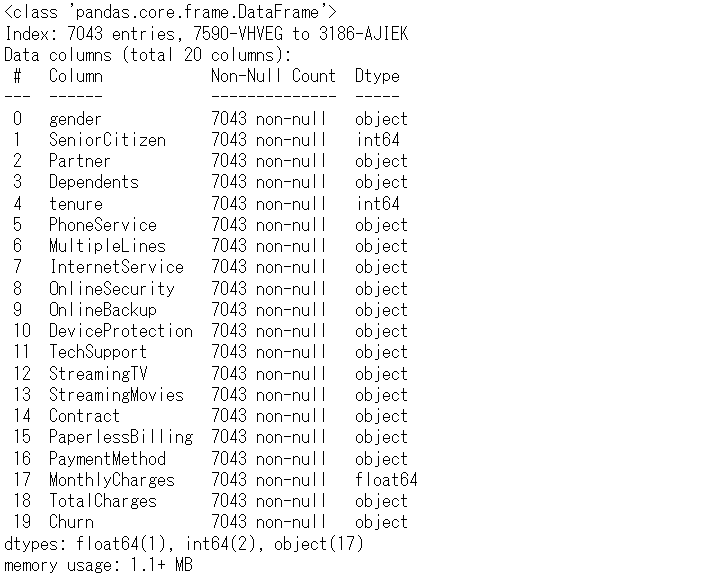
データ状況を確認します。
以下、コードです。
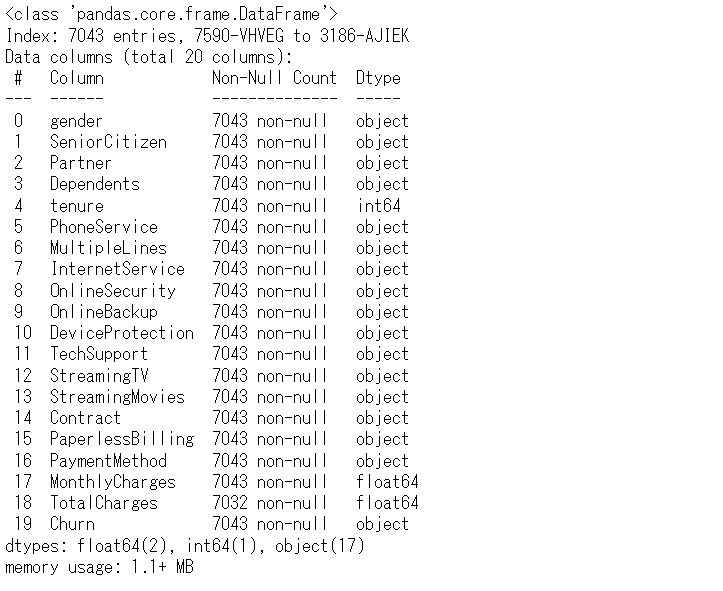
# データセットの状況の確認 df.info()
以下、実行結果です。
「TotalCharge」変数を数値型へ型変換し、「SeniorCitizen」の値変換(1:Yes、0:No)します。
以下、コードです。
# TotalChargesを型変換(数値型へ)
df.TotalCharges = pd.to_numeric(df.TotalCharges,
errors='coerce')
# SeniorCitizenの値変換(1:Yes、0:No)
df = df.replace({'SeniorCitizen':{1:'Yes', 0:'No'}})
df.head() #確認
以下、実行結果です。
再度、データ状況を確認します。
以下、コードです。
# データセットの状況の確認 df.info()
以下、実行結果です。
欠測データがありそうなので、確認してみます。
以下、コードです。
# 欠測状況の確認 df.isnull().sum()
以下、実行結果です。

欠測のある行を削除します。
以下、コードです。
# 欠測値のある行を削除する df = df.dropna(how='any')
再度、欠測状況を確認します。
以下、コードです。
# 欠測状況の確認 df.isnull().sum()
以下、実行結果です。

次に、モデル構築用の学習データと、構築したモデルを検証するテストデータに分割します。
以下、コードです。
# データセットの分割(学習データとテストデータ)
df_train, df_test = train_test_split(df,
test_size=0.3,
random_state=123)
量的データ(ニューメリカルデータ)を標準化します。学習データで標準化モデルを作り、それを学習データとテストデータに適用します。
以下、コードです。
# 標準化
scaler = StandardScaler()
df_train[df_train.select_dtypes("number").columns] = scaler.fit_transform(df_train.select_dtypes("number"))
df_test[df_test.select_dtypes("number").columns] = scaler.transform(df_test.select_dtypes("number"))
この学習データとテストデータを使って、モデル構築と精度検証を実施していきます。
通信会社の顧客離反|モデル設定
今回は、以下の3つの数理モデルを構築しますので、その設定を実施します。
- 決定木(tree): DecisionTreeClassifier
- ランダムフォレスト(RandomForest): RandomForestClassifier
- アダブースト(AdaBoost): AdaBoostClassifier
以下、コードです。
# 構築するモデル設定
models = {
'tree': DecisionTreeClassifier(random_state=123),
'RandomForest': RandomForestClassifier(random_state=123),
'AdaBoost': AdaBoostClassifier(RandomForestClassifier(random_state=123),
learning_rate=0.1,
n_estimators=100,
random_state=123)
}
Boston house prices|学習とテスト(全ての特徴量を利用)
データセットの全ての特徴量(説明変数)を使った場合です。
特徴量(説明変数)と目的変数に分け、質的データ(カテゴリカルデータ)を数値ラベル値に変換します。
以下、コードです。
# 学習データとテストデータ
X_train = df_train.drop(columns=["Churn"])
y_train = df_train["Churn"]
X_test = df_test.drop(columns=["Churn"])
y_test = df_test["Churn"]
# 目的変数Yを数値ラベル化
labEnc = LabelEncoder()
y_train = labEnc.fit_transform(y_train)
y_test = labEnc.transform(y_test)
# カテゴリカル変数をOrdinalEncoderで数値ラベルに変換
ordEnc = OrdinalEncoder()
X_train[X_train.select_dtypes("object").columns] = ordEnc.fit_transform(X_train.select_dtypes("object"))
X_test[X_test.select_dtypes("object").columns] = ordEnc.transform(X_test.select_dtypes("object"))
このデータを使い、学習データでモデル構築し、テストデータで構築したモデルの検証を、実施します。
以下、コードです。
# 結果を格納するハコ
scores = {}
# 予測モデル構築と精度検証
for model_name, model in models.items():
model.fit(X_train, y_train) #学習データで予測モデル構築
y_pred = model.predict(X_test) #テストデータの目的変数Yを予測
scores[(model_name, 'accuracy')] = model.score(X_test,y_test)
scores[(model_name, 'precision')] = precision_score(y_test,y_pred)
scores[(model_name, 'recall')] = recall_score(y_test,y_pred)
scores[(model_name, 'f1')] = f1_score(y_test,y_pred)
# 出力
pd.Series(scores).unstack()
以下、実行結果です。
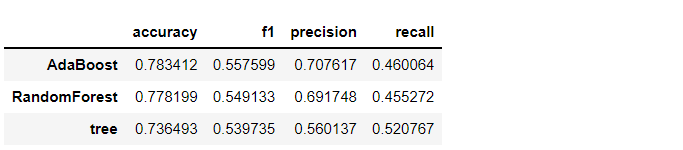
AdaBoostだけの結果を見ます。
- accuracy(正答率):0.78
- f1:0.55
- precision(適合率):0.71
- recall(再現率):0.26
Precisionは「正(例:離反)と予測したものが、どれだけ正しかったか?」を見る指標で、Recallは「実際に正(例:離反)であったもののうち、どれだけ正(例:離反)と予測できたか?」を見る指標で、F1はPrecisionとRecallの調和平均です。
PrecisionとRecallがトレードオフの関係があるので、そのバランスをとるときに採用する指標がf1になります。
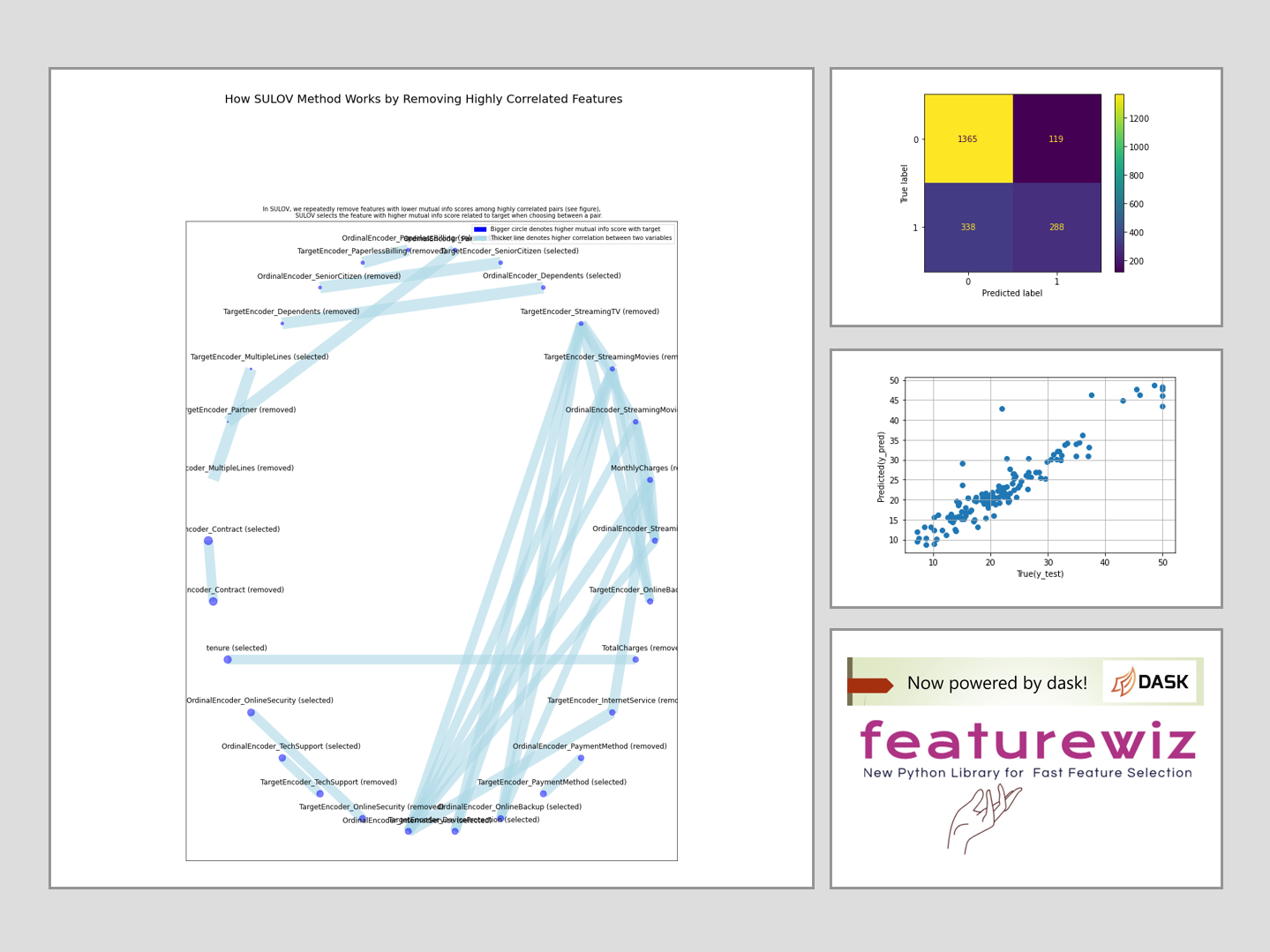
最後に、AdaBoostモデルで予測したテストデータの目的変数の予測値と実測値のCofution Matrix(混同行列)を出力してみます。
以下、コードです。
# AdaBoost confusion matrix plot_confusion_matrix(model, X_test, y_test)
以下、実行結果です。
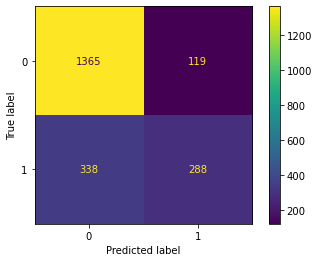
通信会社の顧客離反|特徴量選択(変数選択)
FeatureWizで特徴量選択(変数選択)し絞り込んだ特徴量(説明変数)を使った場合です。
FeatureWizを使い、自動特徴量エンジニアリングを実施します。
以下、コードです。
# 目的変数Y(ターゲット)の変数名
target = 'Churn'
# 自動特徴量エンジニアリング実行
features = featurewiz(df_train,
target,
corr_limit=0.70,
dask_xgboost_flag=False,
nrows=None,
verbose=1,
test_data=df_test
)
以下、実行結果です。
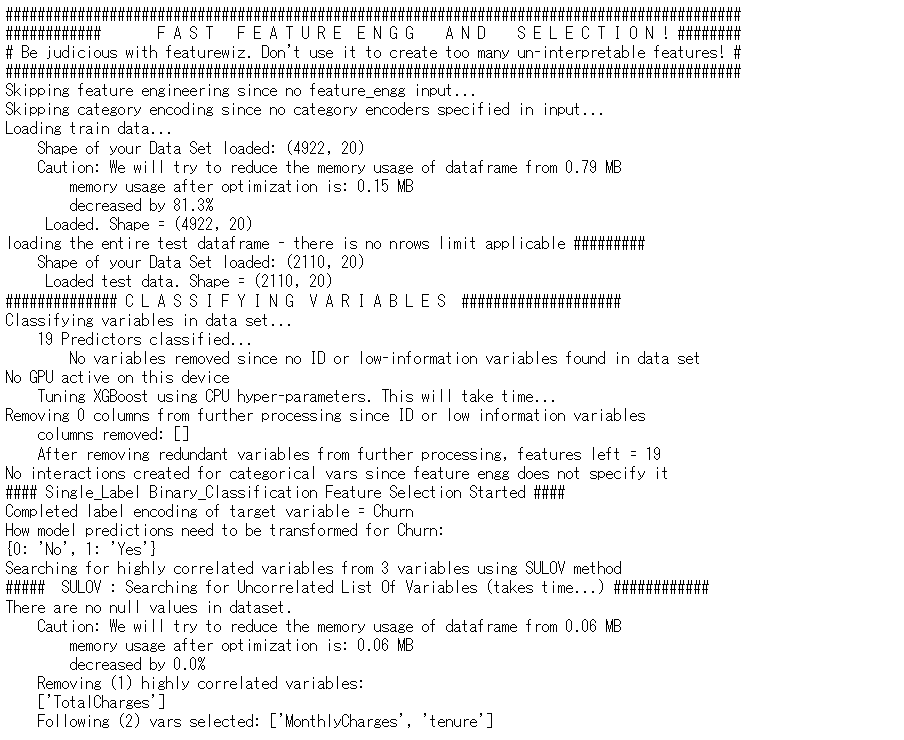
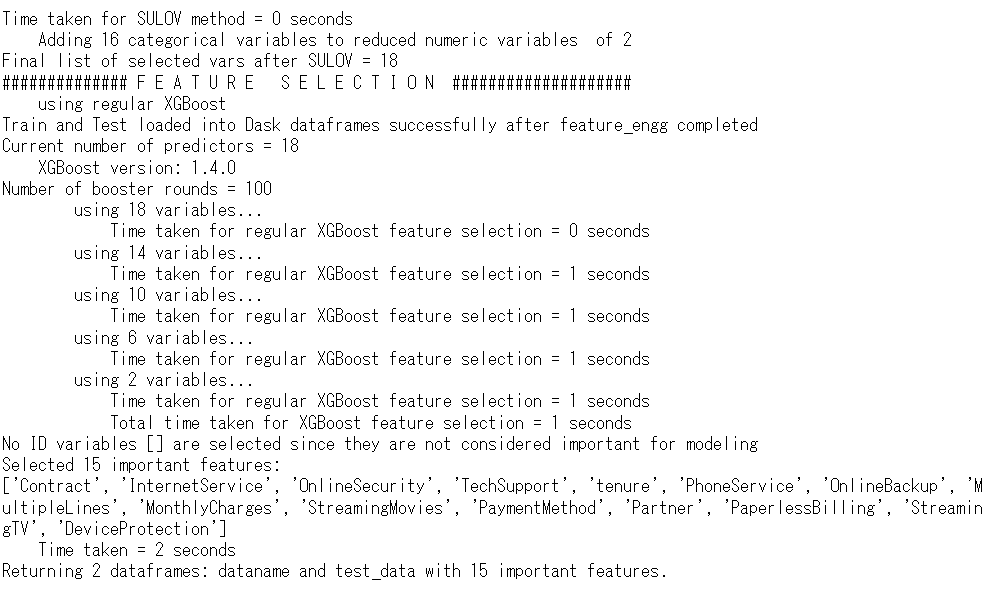
特徴量(説明変数)が19から15に減りました。
モデル構築したり予測精度検証したりするには、選択した特徴量(説明変数)のみのデータセットが必要になりますので、準備します。
以下、コードです。
# 選択した特徴量のみのデータ df_train_selected, df_test_selected = features
それぞれのデータセットの中を見てみます。
学習データを見てみます。以下、コードです。
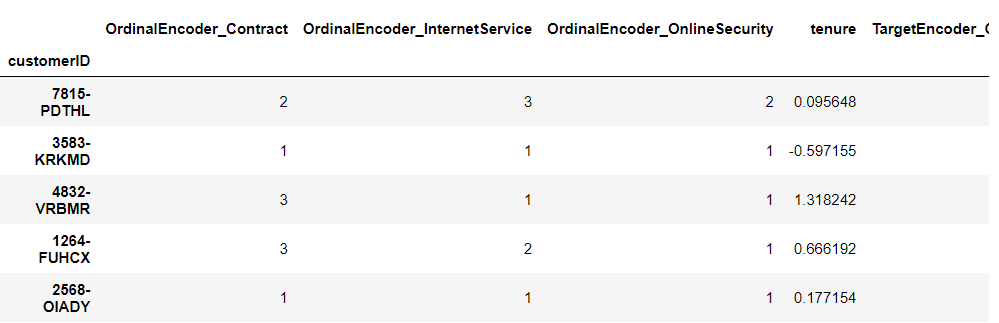
# 学習データ(選択した特徴量+説明変数Y) df_train_selected.head()
以下、実行結果です。
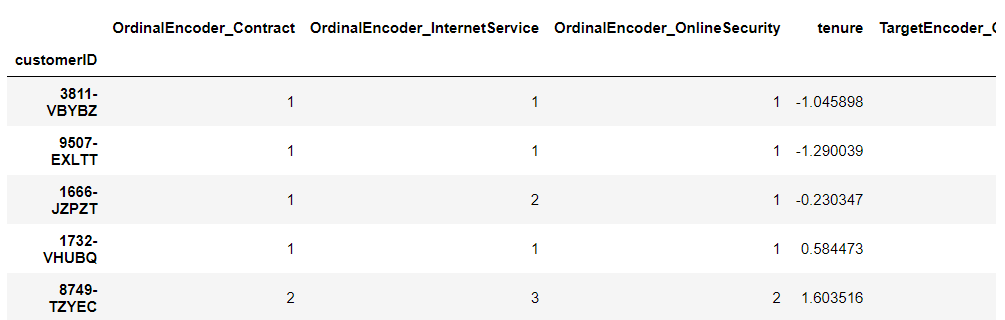
テストデータを見てみます。以下、コードです。
# テストデータ(選択した特徴量) df_test_selected.head()
以下、実行結果です。
通信会社の顧客離反|学習とテスト(選択特徴量を利用)
特徴量(説明変数)と目的変数に分けます。
以下、コードです。
# 学習データとテストデータ X_train = df_train_selected.drop(columns=["Churn"]) y_train = df_train_selected["Churn"] X_test = df_test_selected y_test = LabelEncoder().fit_transform(df_test.Churn)
このデータを使い、学習データでモデル構築し、テストデータで構築したモデルの検証を、実施します。
以下、コードです。
# 結果を格納するハコ
scores = {}
# 予測モデル構築と精度検証
for model_name, model in models.items():
model.fit(X_train, y_train) #学習データで予測モデル構築
y_pred = model.predict(X_test) #テストデータの目的変数Yを予測
scores[(model_name, 'accuracy')] = model.score(X_test,y_test)
scores[(model_name, 'precision')] = precision_score(y_test,y_pred)
scores[(model_name, 'recall')] = recall_score(y_test,y_pred)
scores[(model_name, 'f1')] = f1_score(y_test,y_pred)
# 出力
pd.Series(scores).unstack()
以下、実行結果です。
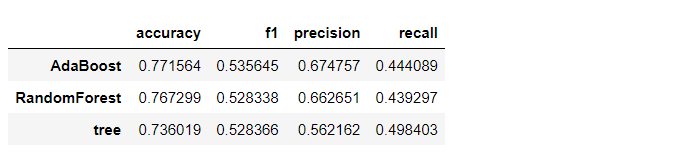
AdaBoostだけの結果を見ます。
- accuracy(正答率):0.78 → 0.77
- f1:0.56 → 0.54
- precision(適合率):0.71 → 0.67
- recall(再現率):0.46 → 0.44
左が、データセットの全ての特徴量(説明変数)を使った予測精度です。
右が、FeatureWizで特徴量選択(変数選択)し絞り込んだ特徴量(説明変数)を使った予測精度です。
最後に、AdaBoostモデルで予測したテストデータの目的変数の予測値と実測値のCofution Matrix(混同行列)を出力してみます。
以下、コードです。
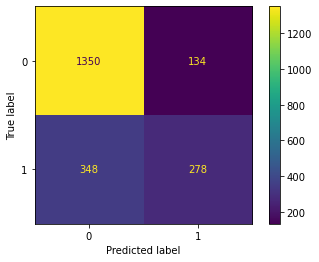
# AdaBoost confusion matrix plot_confusion_matrix(model, X_test, y_test)
以下、実行結果です。
まとめ
今回は、「大容量データにも対応した特徴量エンジニアリングライブラリーFeatureWiz(Python)」のお話しを、一般的な使い方を説明しながら、大容量データセットに対する場合にどうすればいいのかを、簡単に説明しました。
基本、FeatureWizの特徴量選択(変数選択)機能だけを使いました。
ちなみに、FeatureWizの特徴量生成機能を使い特徴量を増やし実施してみましたが、膨大な特徴量が新たに作成され、結果的に非常に時間が掛かりました。
いくつかのサンプルデータで試しましたが、劇的に精度が良くなることはありませんでした。ただ、良くなる可能性はあります。別の機会にお話しします。