
本当に売上に貢献している広告は、どの広告か?
売上と広告媒体等との関係性をモデリングし、どの広告媒体が売上にどれほど貢献していたのか分析することができます。
それが、マーケティングミックスモデリング(MMM:Marketing Mix Modeling)です。
前回、「アドストック(Ad Stock)を考慮した線形回帰モデル」というお話しをしました。
ちなみに、アドストック(Ad Stock)を考慮するとは、飽和効果(収穫逓減)とキャリーオーバー(Carryover)効果を考慮するということです。
具体的には、Pythonのscikit-learn(sklearn)のパイプラインを、以下のように構築しました。
前回の、飽和モデルとキャリーオーバー効果モデルは非常にシンプルなものでした。今回は、ちょっと複雑な飽和モデルとキャリーオーバー効果モデルを利用します。
ということは、今回は「ちょっと複雑なアドストック(Ad Stock)を考慮した線形回帰モデル」というお話しをします。
Contents [hide]
利用するデータセット(前回と同じ)
今回利用するデータセットの変数です。
- Week:週
- Sales:売上
- TVCM:TV CMのコスト
- Newspaper:新聞の折り込みチラシのコスト
- Web:Web広告のコスト
以下からダウンロードできます。
今回利用するキャリーオーバー効果モデル
先ずは、前回のキャリーオーバー効果モデルの復習です。

広告などを打ったときが効果のピークで、徐々に効果が一定の割合で減衰していくモデルです。例えば、100あった効果が、次期に50になり、次々期に25になるといった具合です。この例の場合、50%の割合で効果が減衰しています。
しかし、広告などは、広告などを打ったときが効果のピークとは限りません。例えば、広告を打った数日後や数週間後に効果のピークが来ることもあります。
今回は、効果のピークが広告などを打ったときに限らないモデルを使います。
数式で表現すると、次のようになります。
ハイパーパラメータは、次の3つです。
- L(length):効果の続く期間 ※当期含む
- P(peak):ピークの時期(広告などを打った日の場合は0、次期は1、など)
- R(rate):減衰率
今回利用する飽和モデル
先ずは、前回の飽和モデルの復習です。
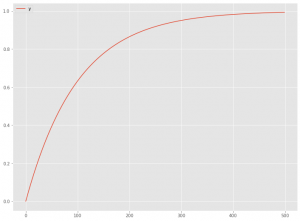
最もシンプルな指数関数
今回は、S字曲線を表現する関数でモデル化します。シグモイド関数やロジスティック曲線、ゴンペルツ曲線など色々あります。
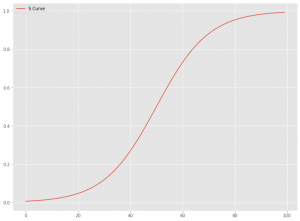
今回は、以下の数式で表現されたロジスティック曲線でモデル化します。
ハイパーパラメータは、次の4つです。
- K:上限パラメータ
- b:形状パラメータ
- c:形状パラメータ
- m:位置パラメータ
MMMの実施
必要なライブラリーの読み込み
必要なライブラリーを読み込みます。
以下、コードです。
import numpy as np
import pandas as pd
from scipy.signal import convolve2d
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score, TimeSeriesSplit
from sklearn import set_config
from sklearn.linear_model import LinearRegression
from optuna.integration import OptunaSearchCV
from optuna.distributions import UniformDistribution, IntUniformDistribution
import matplotlib.pyplot as plt
plt.style.use('ggplot') #グラフスタイル
plt.rcParams['figure.figsize'] = [12, 9] # グラフサイズ
#指数表記しない設定
np.set_printoptions(precision=3,suppress=True)
pd.options.display.float_format = '{:.3f}'.format
データセット(前回と同じ)
前回と同じデータセットを読み込みます。
以下、コードです。
# データセット読み込み
url = 'https://www.salesanalytics.co.jp/4zdt'
df = pd.read_csv(url,
parse_dates=['Week'],
index_col='Week'
)
# データ確認
print(df.info()) #変数の情報
print(df.head()) #データの一部
# 説明変数Xと目的変数yに分解
X = df.drop(columns=['Sales'])
y = df['Sales']
# グラフ化
y.plot()
X.plot()
以下、実行結果です。

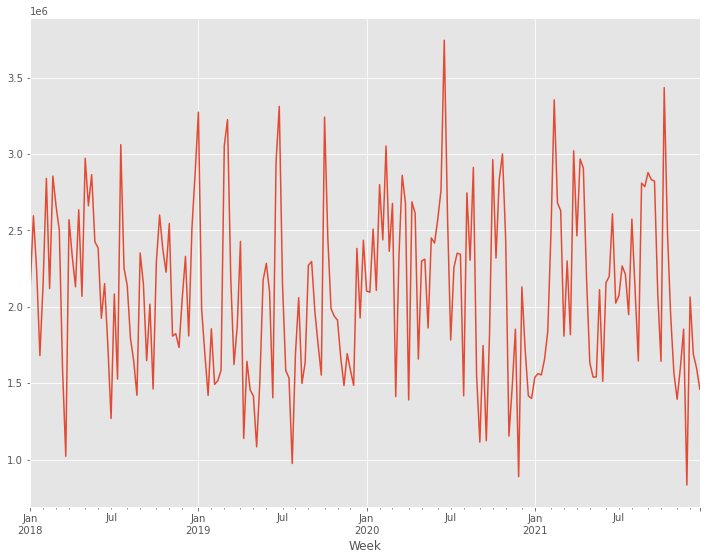
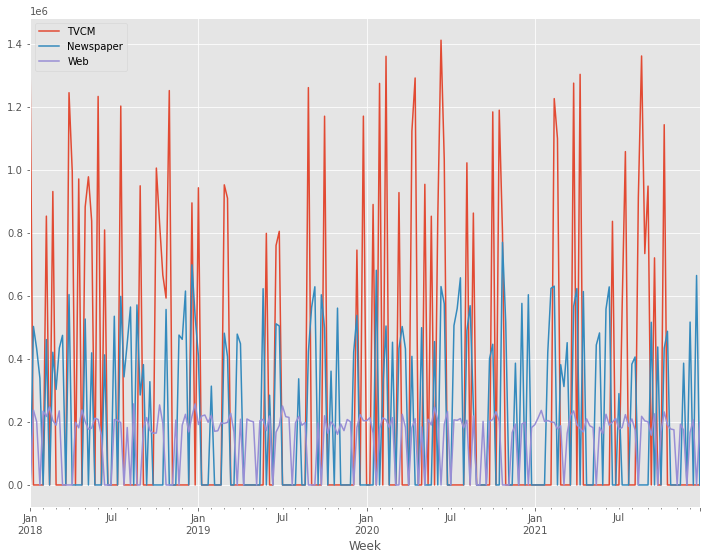
アドストックを考慮しない線形回帰モデル
アドストックを考慮しない線形回帰モデルを構築し、どの程度の精度を持ったものだったのかを見てみます。
ちなみに、前回と同じものです。
線形回帰モデルのインスタンスを作ります。
以下、コードです。
# 線形回帰モデルのインスタンス lr = LinearRegression()
線形回帰モデルが、どの程度の予測精度を持ったモデルになるのかを確かめるために、時系列のCV(クロスバリデーション)を実施します。今回は、デフォルトの5分割のCVです。
以下、コードです。
# クロスバリデーションで精度検証(R2)
np.mean(cross_val_score(lr,
X, y,
cv=TimeSeriesSplit()
)
)
以下、実行結果です。
![]()
全データでモデルを構築し、予測精度(
以下、コードです。
# 全データで精度検証(R2) lr.fit(X, y) lr.score(X, y)
以下、実行結果です。
![]()
アドストックの関数
以下の2つのモデル(変換器)の関数を定義し利用することで、アドストックを表現します。
- 飽和モデル
- キャリーオーバー効果モデル
飽和モデル
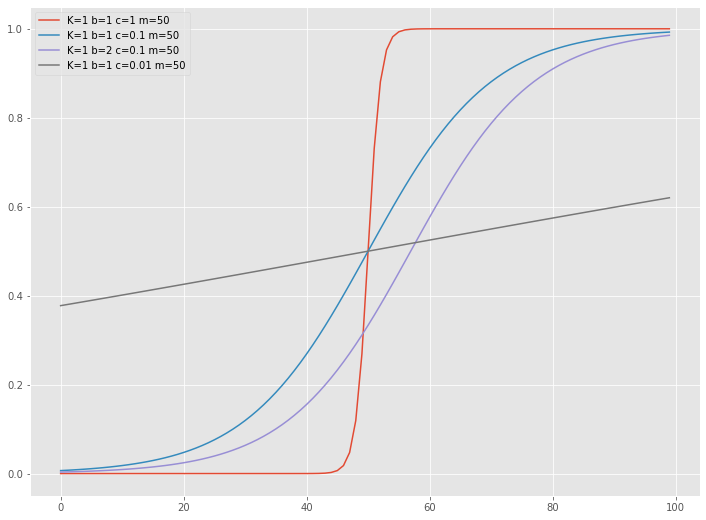
飽和モデル(関数)を定義します。今回利用するのは、以下のロジスティック曲線です。
ハイパーパラメータは、次の4つです。
- K:上限パラメータ
- b:形状パラメータ
- c:形状パラメータ
- m:位置パラメータ
以下、コードです。
# 飽和モデル(関数)の定義
def Saturation(X,K,b,c,m):
return K/(1+b*np.exp(-c*(X-m)))
この関数の実行例です。
以下、コードです。
# 飽和モデル(関数)の例 exp_dat = pd.DataFrame(range(100)) #入力データ exp_sat = pd.DataFrame(index=exp_dat.index) exp_sat['K=1 b=1 c=1 m=50'] = Saturation(exp_dat,1,1,1,50) exp_sat['K=1 b=1 c=0.1 m=50'] = Saturation(exp_dat,1,1,0.1,50) exp_sat['K=1 b=2 c=0.1 m=50'] = Saturation(exp_dat,1,2,0.1,50) exp_sat['K=1 b=1 c=0.01 m=50'] = Saturation(exp_dat,1,1,0.01,50) exp_sat.plot() #グラフ
以下、実行結果です。
キャリーオーバー効果モデル
キャリーオーバー効果モデル(関数)を定義します。今回利用するのは、効果のピークが広告などを打ったときに限らない以下のモデルです。
ハイパーパラメータは、次の3つです。
- L(length):効果の続く期間(広告などを打った日も含む)
- P(peak):ピークの時期(広告などを打った日の場合は0、次期は1、など)
- R(rate):減衰率
以下、コードです。
def Carryover(X: np.ndarray, length, peak, rate):
X = np.append(np.zeros(length-1), X)
Ws = np.zeros(length)
for l in range(length):
W = rate**((l-peak)**2)
Ws[length-1-l] = W
carryover_X = []
for i in range(length-1, len(X)):
X_array = X[i-length+1:i+1]
Xi = sum(X_array * Ws)/sum(Ws)
carryover_X.append(Xi)
return np.array(carryover_X)
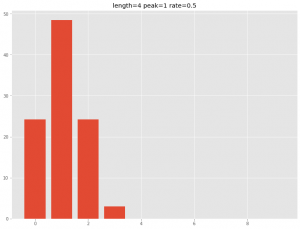
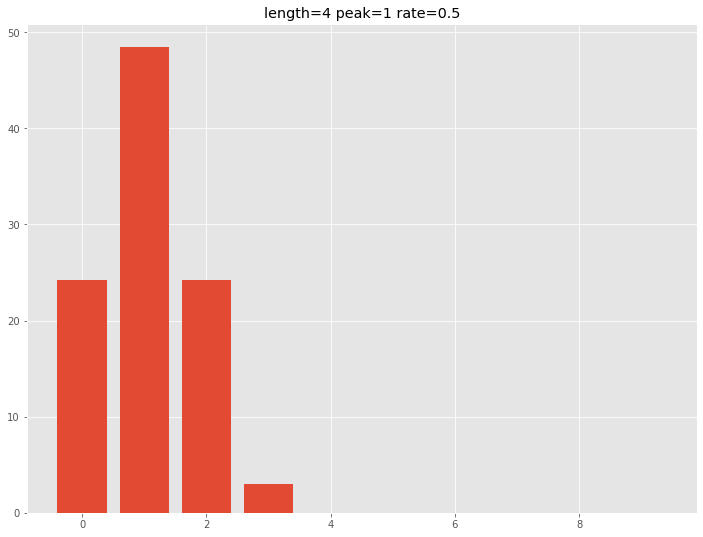
最初100でその後0であるシンプルなケースの、この関数の実行例です。
以下、コードです。
# キャリーオーバー効果モデル(関数)の例
## サンプルデータ
exp_dat = pd.DataFrame([100,0,0,0,0,0,0,0,0,0])
## キャリーオーバー効果
exp_co = Carryover(exp_dat, 4, 1, 0.5)
plt.bar(exp_dat.index,exp_co) #グラフ
plt.title('length=4 peak=1 rate=0.5')
以下、実行結果です。
アドストックを考慮した線形回帰モデル
パイパーパラメータを設定します。
以下、コードです。
# TVCMのハイパーパラメータの設定 TVCM_carryover_length = 5 TVCM_carryover_peak = 1 TVCM_carryover_rate = 0.5 TVCM_saturation_K = 1 TVCM_saturation_b = 1 TVCM_saturation_c = 0.1 TVCM_saturation_m = np.mean(X.TVCM) # Newspaperのハイパーパラメータの設定 Newspaper_carryover_length = 3 Newspaper_carryover_peak = 0 Newspaper_carryover_rate = 0.5 Newspaper_saturation_K = 1 Newspaper_saturation_b = 1 Newspaper_saturation_c = 0.1 Newspaper_saturation_m = np.mean(X.Newspaper) # Webのハイパーパラメータの設定 Web_carryover_length = 1 Web_carryover_peak = 0 Web_carryover_rate = 0.5 Web_saturation_K = 1 Web_saturation_b = 1 Web_saturation_c = 0.1 Web_saturation_m = np.mean(X.Web)
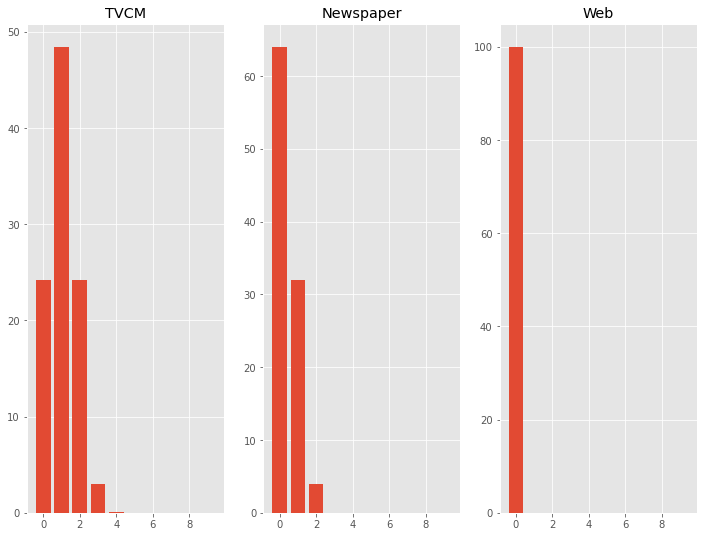
どのようなキャリーオーバー効果なのかを見てみます。
以下、コードです。
# キャリーオーバー効果モデルの出力例
## サンプルデータ
exp_dat = pd.DataFrame([100,0,0,0,0,0,0,0,0,0])
## キャリーオーバー効果
### TVCM
exp_co_TVCM= Carryover(
exp_dat,
TVCM_carryover_length,
TVCM_carryover_peak,
TVCM_carryover_rate
)
### Newspaper
exp_co_Newspaper = Carryover(
exp_dat,
Newspaper_carryover_length,
Newspaper_carryover_peak,
Newspaper_carryover_rate
)
### Web
exp_co_Web = Carryover(
exp_dat,
Web_carryover_length,
Web_carryover_peak,
Web_carryover_rate
)
## グラフ
fig, axes = plt.subplots(nrows=1, ncols=3, sharex=False)
### TVCM
axes[0].bar(exp_dat.index,
exp_co_TVCM
)
axes[0].set_title('TVCM')
### Newspaper
axes[1].bar(exp_dat.index,
exp_co_Newspaper
)
axes[1].set_title('Newspaper')
### Web
axes[2].bar(exp_dat.index,
exp_co_Web
)
axes[2].set_title('Web')
以下、実行結果です。
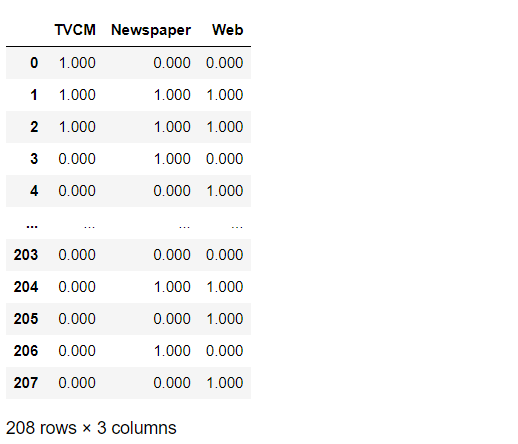
説明変数X(広告などのコスト)のデータに対し、キャリーオーバー効果モデルと飽和モデルを使い、学習器(線形回帰モデル)のインプットを作ります。
以下、コードです。
# TVの値の変換
X_TVCM = Saturation(Carryover(X[['TVCM']],
TVCM_carryover_length,
TVCM_carryover_peak,
TVCM_carryover_rate).reshape(-1,1),
TVCM_saturation_K,
TVCM_saturation_b,
TVCM_saturation_c,
TVCM_saturation_m
)
# Newspaperの値の変換
X_Newspaper = Saturation(Carryover(X[['Newspaper']],
Newspaper_carryover_length,
Newspaper_carryover_peak,
Newspaper_carryover_rate).reshape(-1,1),
Newspaper_saturation_K,
Newspaper_saturation_b,
Newspaper_saturation_c,
Newspaper_saturation_m
)
# Webの値の変換
X_Web = Saturation(Carryover(X[['Web']],
Web_carryover_length,
Web_carryover_peak,
Web_carryover_rate).reshape(-1,1),
Web_saturation_K,
Web_saturation_b,
Web_saturation_c,
Web_saturation_m
)
# 変換した値の結合(DataFrame型へ)
X_trans = pd.DataFrame(np.concatenate([X_TVCM,
X_Newspaper,
X_Web],
1))
X_trans.columns = ['TVCM','Newspaper','Web']
X_trans #確認
以下、実行結果です。
この説明変数Xを変換し作ったデータを使い、線形回帰モデルを作り精度検証してみます。
線形回帰モデルが、どの程度の予測精度を持ったモデルになるのかを確かめるために、時系列のCV(クロスバリデーション)を実施します。今回は、デフォルトの5分割のCVです。
以下、コードです。
# クロスバリデーションで精度検証(R2)
np.mean(cross_val_score(lr,
X_trans, y,
cv=TimeSeriesSplit()
)
)
以下、実行結果です。
![]()
全データでモデルを構築し、予測精度(
以下、コードです。
# 全データで精度検証(R2) lr.fit(X_trans, y) lr.score(X_trans, y)
以下、実行結果です。
![]()
アドストックを考慮した線形回帰モデル
(Optunaでハイパーパラメータチューニング)
変換器と学習器を繋いだパイプラインを作り、Optunaでハイパーパラメータ探索を実施し最適なモデルを作ります。
ハイパーパラメータは、変換器の以下の7つです。
- キャリーオーバー効果モデル
- L(length):効果の続く期間(広告などを打った日も含む)
- P(peak):ピークの時期(広告などを打った日の場合は0、次期は1、など)
- R(rate):減衰率
- 飽和モデル
- K:上限パラメータ
- b:形状パラメータ
- c:形状パラメータ
- m:位置パラメータ
パイプライン構築
飽和モデルとキャリーオーパー効果モデルを、パイプラインで利用できる変換器にします。
以下、コードです。
# Pipeline用変換器(飽和モデル)
class ExponentialSaturation(BaseEstimator, TransformerMixin):
# 初期化
def __init__(self, K=1.0, b=1.0, c=0.1, m=100.0):
self.K = K
self.b = b
self.c = c
self.m = m
# 学習
def fit(self, X, y=None):
return self
# 処理(入力→出力)
def transform(self, X):
return Saturation(X,self.K, self.b, self.c, self.m).reshape(-1,1)
# Pipeline用変換器(キャリーオーバー効果モデル)
class ExponentialCarryover(BaseEstimator, TransformerMixin):
# 初期化
def __init__(self, length=4, peak=1, rate=0.5):
self.length = length #ハイパーパラメータ
self.peak = peak #ハイパーパラメータ
self.rate = rate #ハイパーパラメータ
# 学習
def fit(self, X, y=None):
return self
# 処理(入力→出力)
def transform(self, X: np.ndarray):
return Carryover(X, self.length, self.peak, self.rate)
この変換器を使い、パイプラインを構築します。
以下、コードです。
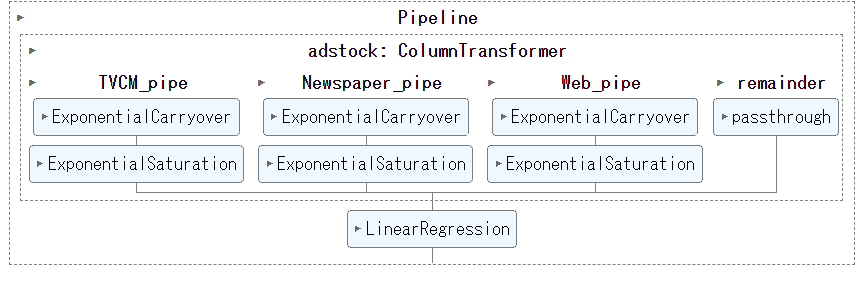
# Pipelineの構築
## 説明変数の変換部分(adstock)の定義
adstock = ColumnTransformer(
[
('TVCM_pipe', Pipeline([
('carryover', ExponentialCarryover()),
('saturation', ExponentialSaturation())
]), ['TVCM']),
('Newspaper_pipe', Pipeline([
('carryover', ExponentialCarryover()),
('saturation', ExponentialSaturation())
]), ['Newspaper']),
('Web_pipe', Pipeline([
('carryover', ExponentialCarryover()),
('saturation', ExponentialSaturation())
]), ['Web']),
],
remainder='passthrough'
)
## 説明変数の変換(adstock)→線形回帰モデル(regression)
MMM_pipe = Pipeline([
('adstock', adstock),
('regression', LinearRegression())
])
## パイプラインの確認
set_config(display='diagram')
MMM_pipe
以下、実行結果です。
パイパーパラメータ探索の実施
パイプラインを構築したので、パイパーパラメータを探索します。
以下、コードです。
# ハイパーパラメータの探索の設定
params = {
'adstock__TVCM_pipe__carryover__length': IntUniformDistribution(1, 7),
'adstock__TVCM_pipe__carryover__peak': IntUniformDistribution(0, 2),
'adstock__TVCM_pipe__carryover__rate': UniformDistribution(0, 1),
'adstock__TVCM_pipe__saturation__K': UniformDistribution(np.min(X.TVCM), np.max(X.TVCM)),
'adstock__TVCM_pipe__saturation__b': UniformDistribution(0, 10),
'adstock__TVCM_pipe__saturation__c': UniformDistribution(0, 1),
'adstock__TVCM_pipe__saturation__m': UniformDistribution(np.min(X.TVCM), np.max(X.TVCM)),
'adstock__Newspaper_pipe__carryover__length': IntUniformDistribution(1, 7),
'adstock__Newspaper_pipe__carryover__peak': IntUniformDistribution(0, 2),
'adstock__Newspaper_pipe__carryover__rate': UniformDistribution(0, 1),
'adstock__Newspaper_pipe__saturation__K': UniformDistribution(np.min(X.Newspaper), np.max(X.Newspaper)),
'adstock__Newspaper_pipe__saturation__b': UniformDistribution(0, 10),
'adstock__Newspaper_pipe__saturation__c': UniformDistribution(0, 1),
'adstock__Newspaper_pipe__saturation__m': UniformDistribution(np.min(X.Newspaper), np.max(X.Newspaper)),
'adstock__Web_pipe__carryover__length': IntUniformDistribution(1, 7),
'adstock__Web_pipe__carryover__peak': IntUniformDistribution(0, 2),
'adstock__Web_pipe__carryover__rate': UniformDistribution(0, 1),
'adstock__Web_pipe__saturation__K': UniformDistribution(np.min(X.Web), np.max(X.Web)),
'adstock__Web_pipe__saturation__b': UniformDistribution(0, 10),
'adstock__Web_pipe__saturation__c': UniformDistribution(0, 1),
'adstock__Web_pipe__saturation__m': UniformDistribution(np.min(X.Web), np.max(X.Web)),
}
# ハイパーパラメータ探索の設定
optuna_search = OptunaSearchCV(
estimator=MMM_pipe,
param_distributions=params,
n_trials=1000,
cv=TimeSeriesSplit(),
error_score='raise',
random_state=0
)
# 探索実施
optuna_search.fit(X, y)
探索結果を見てみます。
以下、コードです。
# 探索結果 optuna_search.best_params_

探索し得られたハイパーパラメータで、どのようなキャリーオーバー効果になるのかを見てみます。
以下、コードです。
# キャリーオーバー効果モデルの出力例
## サンプルデータ
exp_dat = pd.DataFrame([100,0,0,0,0,0,0,0,0,0])
## ハイパーパラメータ設定
### TVCM
TVCM_carryover_length = optuna_search.best_params_['adstock__TVCM_pipe__carryover__length']
TVCM_carryover_peak = optuna_search.best_params_['adstock__TVCM_pipe__carryover__peak']
TVCM_carryover_rate = optuna_search.best_params_['adstock__TVCM_pipe__carryover__rate']
### Newspaper
Newspaper_carryover_length = optuna_search.best_params_['adstock__Newspaper_pipe__carryover__length']
Newspaper_carryover_peak = optuna_search.best_params_['adstock__Newspaper_pipe__carryover__peak']
Newspaper_carryover_rate = optuna_search.best_params_['adstock__Newspaper_pipe__carryover__rate']
### Web
Web_carryover_length = optuna_search.best_params_['adstock__Web_pipe__carryover__length']
Web_carryover_peak = optuna_search.best_params_['adstock__Web_pipe__carryover__peak']
Web_carryover_rate = optuna_search.best_params_['adstock__Web_pipe__carryover__rate']
## キャリーオーバー効果
### TVCM
exp_co_TVCM= Carryover(
exp_dat,
TVCM_carryover_length,
TVCM_carryover_peak,
TVCM_carryover_rate,
)
### Newspaper
exp_co_Newspaper = Carryover(
exp_dat,
Newspaper_carryover_length,
Newspaper_carryover_peak,
Newspaper_carryover_rate,
)
### Web
exp_co_Web = Carryover(
exp_dat,
Web_carryover_length,
Web_carryover_peak,
Web_carryover_rate,
)
## グラフ
fig, axes = plt.subplots(nrows=1, ncols=3, sharex=False)
### TVCM
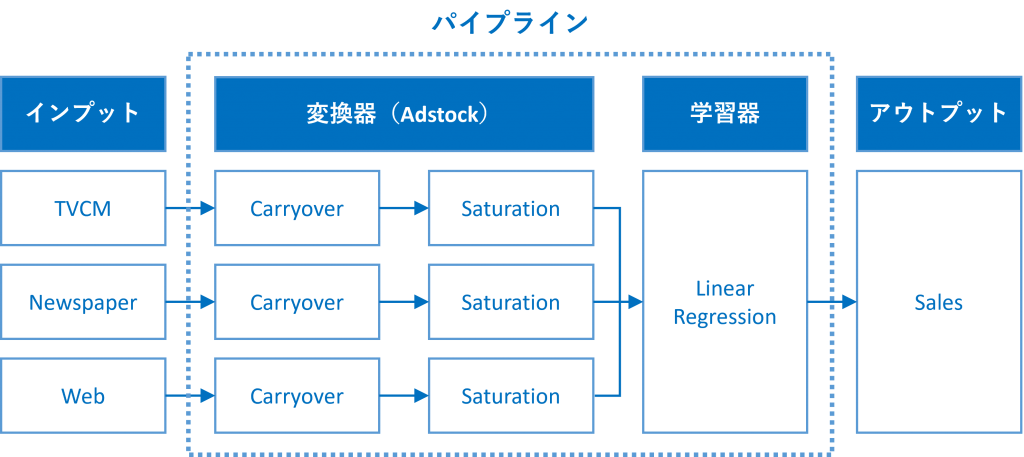
axes[0].bar(exp_dat.index,
exp_co_TVCM
)
axes[0].set_title('TVCM(y:logarithmic scale)')
axes[0].set_yscale('log')
axes[0].set_ylim(0, 100)
### Newspaper
axes[1].bar(exp_dat.index,
exp_co_Newspaper
)
axes[1].set_title('Newspaper')
### Web
axes[2].bar(exp_dat.index,
exp_co_Web
)
axes[2].set_title('Web')
以下、実行結果です。
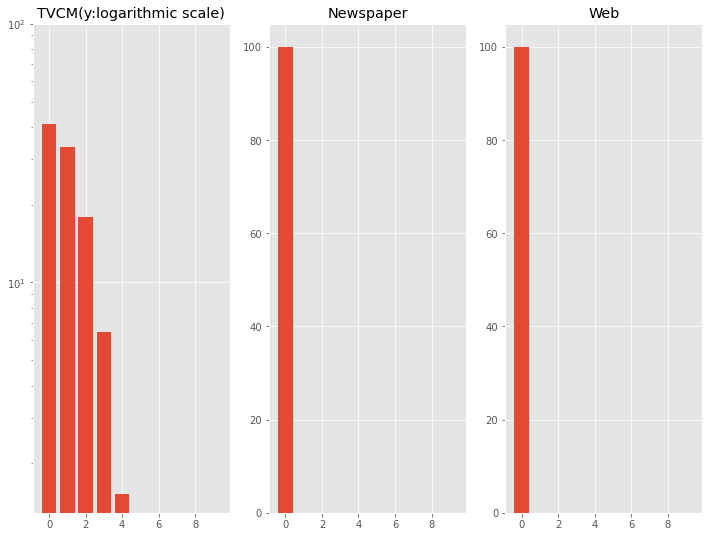
最適なハイパーパラメータでパイプラインを学習
パイプラインのインスタンスを作ります。
以下、コードです。
# パイプラインのインスタンス MMM_pipe_best = MMM_pipe.set_params(**optuna_search.best_params_)
線形回帰モデルが、どの程度の予測精度を持ったモデルになるのかを確かめるために、時系列のCV(クロスバリデーション)を実施します。今回は、デフォルトの5分割のCVです。
以下、コードです。
# クロスバリデーションで精度検証(R2)
np.mean(cross_val_score(MMM_pipe_best,
X, y,
cv=TimeSeriesSplit()
)
)
以下、実行結果です。
![]()
全データでモデルを構築し、予測精度(
以下、コードです。
# 全データで精度検証(R2) MMM_pipe_best.fit(X, y) MMM_pipe_best.score(X, y)
以下、実行結果です。
![]()
前回の線形回帰モデルに比べ、以下のように(
- CVの
- 全データ利用した場合の
どのような線形回帰モデルなのか(切片と回帰係数)を見てみます。
以下、コードです。
# 線形回帰モデルの切片と回帰係数
intercept = MMM_pipe_best.named_steps['regression'].intercept_ #切片
coef = MMM_pipe_best.named_steps['regression'].coef_ #回帰係数
# 回帰係数をデータフレーム化
weights = pd.Series(
coef,
index=X.columns
)
# 結果出力(切片と係数)
print('Intercept:\n', intercept, sep='')
print()
print('Coefficients:\n',weights, sep='')
以下、実行結果です。

売上貢献度の算出
学習し構築したパイプラインの変換器(adstock)を抽出します。
以下、コードです。
# Piplineの変換器(adstock)を抽出 adstock = MMM_pipe_best.named_steps['adstock']
説明変数を変換し、学習データのインプットデータを作ります。
以下、コードです。
# 説明変数Xの変換
X_trans = pd.DataFrame(adstock.transform(X),
index=X.
index,columns=X.columns)
先程求めた線形回帰式を使い、売上貢献度(補正前)を計算します。
以下、コードです。
# 貢献度(補正前) unadj_contribution = X_trans.mul(weights) #Xと係数を乗算 unadj_contribution = unadj_contribution.assign(Base=intercept) #切片の追加 unadj_contribution.head() #確認
以下、実行結果です。
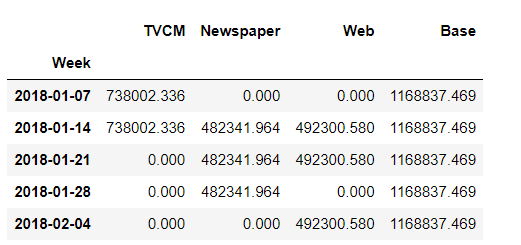
週ごとに各媒体の売上貢献度を合計すると、売上の予測値になります。
以下、コードです。
# 貢献度の合計(yの予測値) y_pred = unadj_contribution.sum(axis=1) y_pred.head() #確認
以下、実行結果です。

元の売上の実測値を見てみます。
以下、コードです。
y.head() #確認
以下、実行結果です。

予測値と実測値が乖離していることが分かります。この乖離をなくすために、補正係数(correction factor)を計算し、売上貢献度を補正します。
補正係数を計算します。
以下、コードです。
# 補正係数 correction_factor = y.div(y_pred, axis=0) correction_factor.head() #確認
以下、実行結果です。

この補正係数を使い、売上貢献度を補正します。
以下、コードです。
# 貢献度(補正後)
adj_contribution = (unadj_contribution
.mul(correction_factor, axis=0)
)
# 順番の変更
adj_contribution = adj_contribution[['Base', 'Web', 'Newspaper', 'TVCM']]
#確認
adj_contribution.head()
以下、実行結果です。
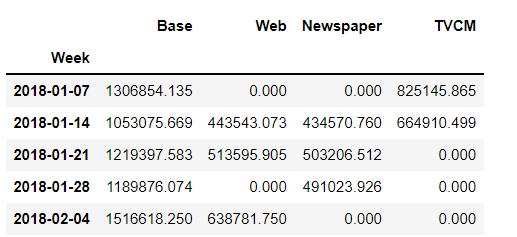
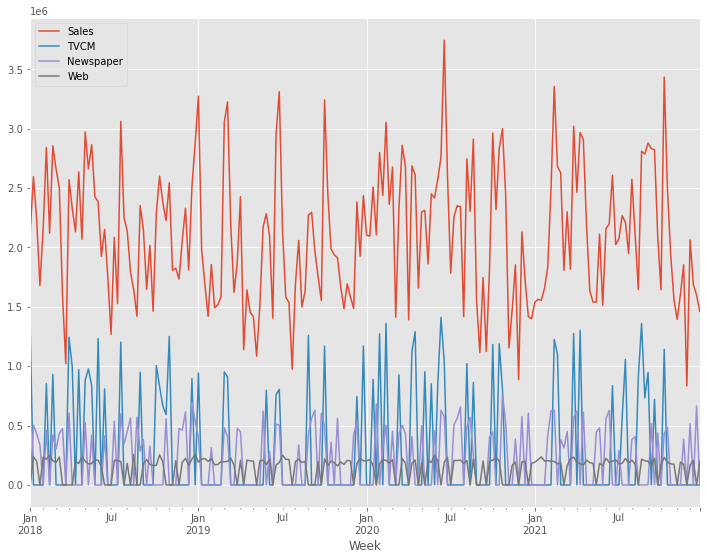
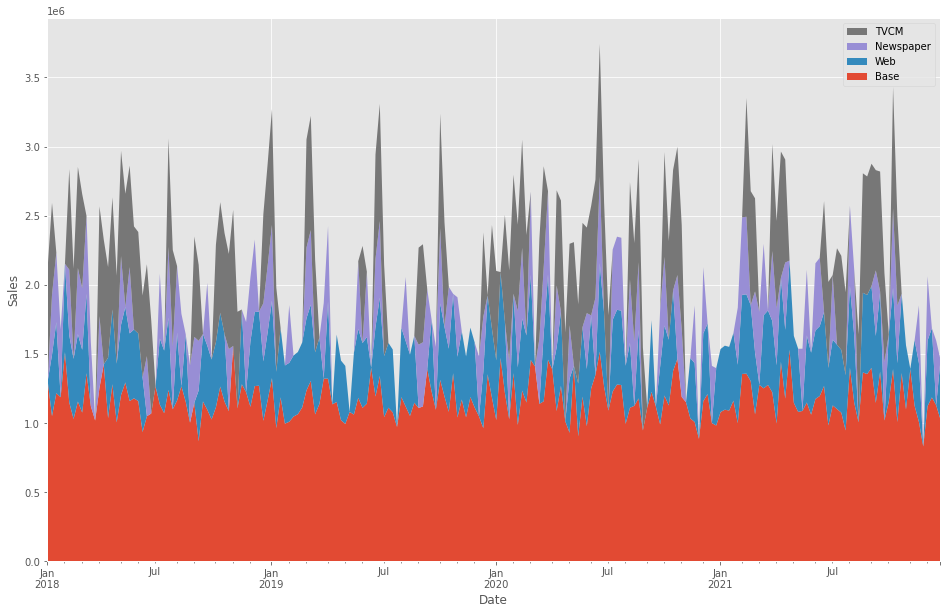
週×媒体別の売上貢献度が求められたので、積み上げグラフを作成し、どのような状況になっているのかを確認してみます。
以下、コードです。
# グラフ化
ax = (adj_contribution
.plot.area(
figsize=(16, 10),
linewidth=0,
ylabel='Sales',
xlabel='Date')
)
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles[::-1], labels[::-1])
以下、実行結果です。
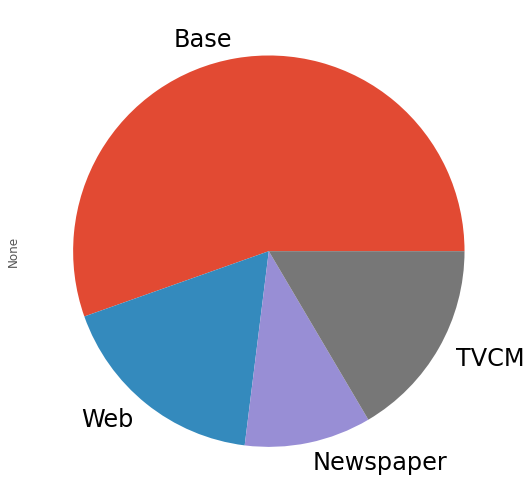
媒体別に全ての週の売上貢献度を合計し、媒体別の売上貢献度(円と構成比%)と、そのグラフを作り、何がどれほど売上に貢献したのかを見てみます。
以下、コードです。
# 媒体別の貢献度の合計
contribution_sum = adj_contribution.sum(axis=0)
#集計結果
print('売上貢献度(円):\n',
contribution_sum,
sep=''
)
print()
print('売上貢献度(構成比):\n',
contribution_sum/contribution_sum.sum(),
sep=''
)
#グラフ化
contribution_sum.plot.pie(fontsize=24)
以下、実行結果です。

費用対効果を見てみます。今回は媒体別にROIを計算します。
先ず、媒体別のコストを集計します。
以下、コードです。
# 各媒体のコストの合計 cost_sum = X.sum(axis=0) cost_sum #確認
以下、実行結果です。

先程求めた売上貢献度を使い、媒体別のROIを計算しグラフ化します。
以下、コードです。
# 各媒体のROIの計算
ROI = (contribution_sum.drop('Base', axis=0) - cost_sum)/cost_sum
#確認
print('ROI:\n', ROI, sep='')
# グラフ化
ROI.plot.bar(fontsize=24)
以下、実行結果です。

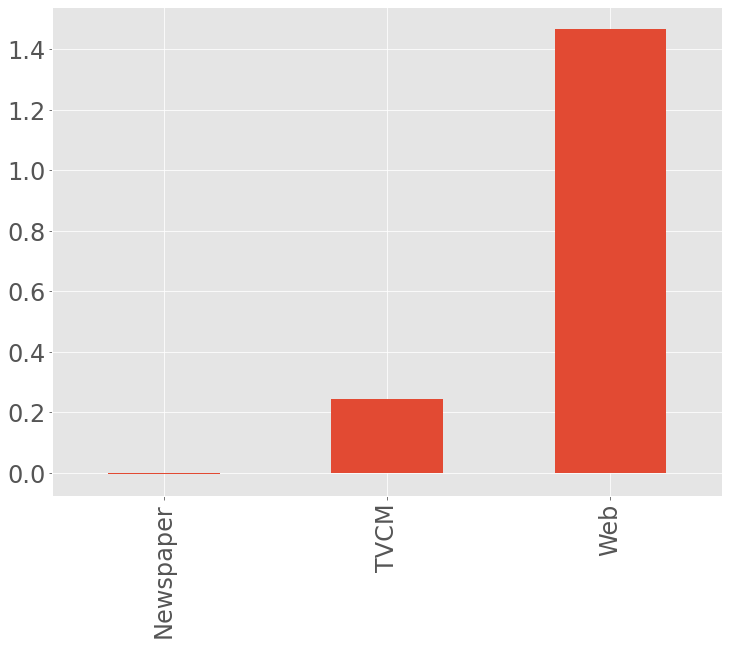
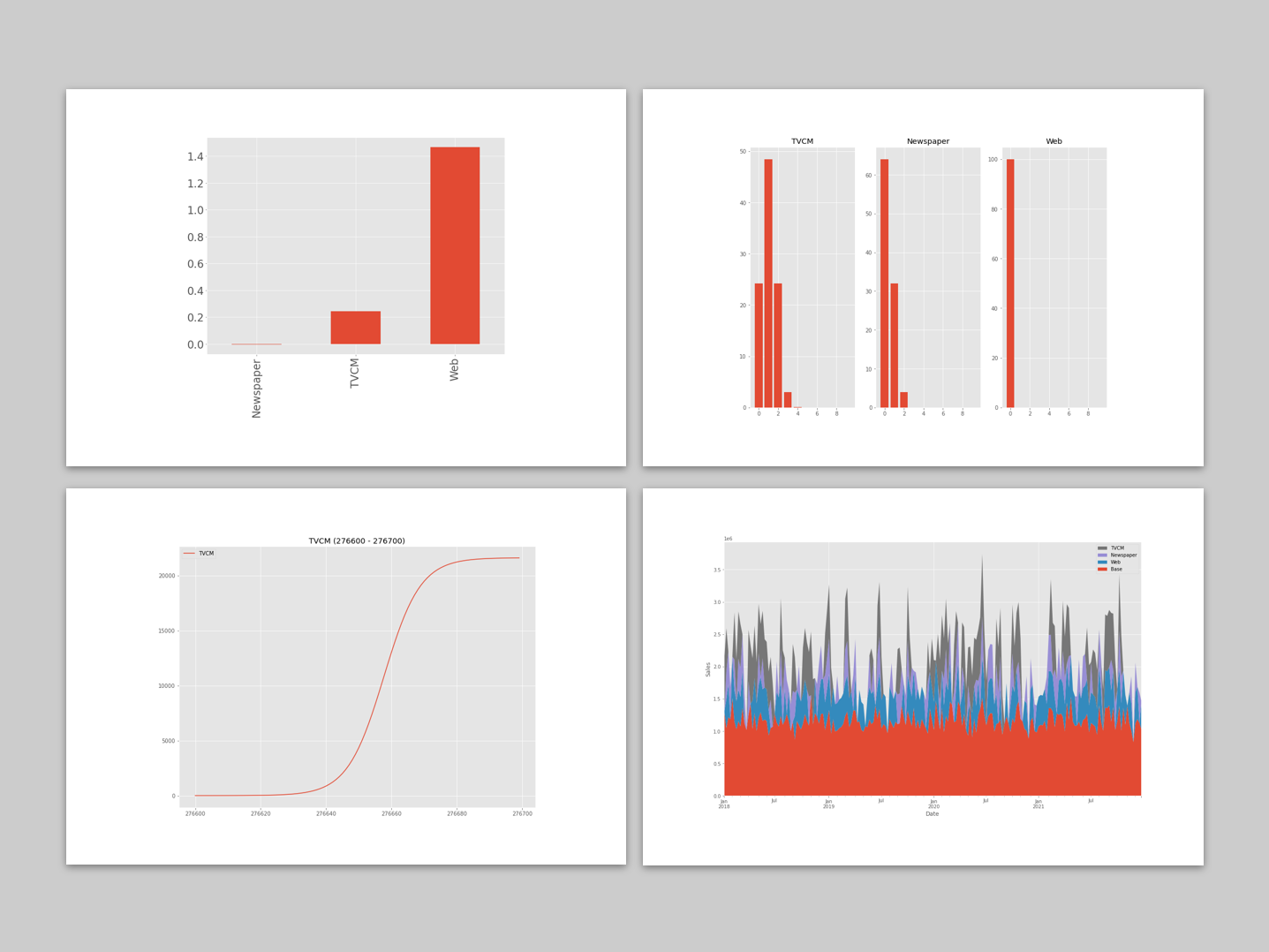
ROIは、値が大きいほど良く、最低限プラスの値である必要があります。少なくとも0以上である必要があります。
今までのモデルと比べ、大きな結論は同じです。Webが非常にいい、という結論です。
次回
今回は「ちょっと複雑なアドストック(Ad Stock)を考慮した線形回帰モデル」というお話しをしました。
前回と今回を含め、アドストック(Ad Stock)を表現する幾つかの関数を紹介しました。では、アドストック(Ad Stock)を表現する関数の中で、どれがいいのか、という疑問もあるかと思います。
2つの視点があります。
- 解釈
- 精度
「解釈」とは、アドストック(Ad Stock)を表現する関数が、違和感なく解釈可能なものかかどうか、というものです。
「精度」とは、目的変数Y(今回の場合:Sales)の予測値と実測値が近い値になっているかどうか、というものです。
「解釈」は現場感が重要です。PCなどで機械的にどうこう検討できるものではありません。
一方、「精度」は、PCなどで機械的に検討できます。最も精度の高いものを探索すればいいからです。
次回は、「最適なアドストック(Ad Stock)を探索しモデル構築」というお話しをします。
Pythonによるマーケティングミックスモデリング(MMM:Marketing Mix Modeling)超入門 その4最適なアドストック(Ad Stock)を探索しモデル構築