

データサイエンティストの利用する分析ツールと言えば、PythonとRです。
幸運なことに、両方には共通している部分も多いですが、中にはPythonにしか実装それていないパッケージや関数や機能、Rにしか実装されていないパッケージや関数や機能、などがあります。
そのため、Pythonで業務をしているデータサイエンティストは、Rのパッケージにある関数などを使いたい、と思うことがあることでしょう。
PythonのPython/R変換パッケージRPY2を使うことで可能になります。
![]()
ということで今回は、「RPY2でPythonからRの関数を使おう」というお話しをします。
Contents [hide]
インストール
Rを使うからには、Rをインストールしておく必要があります。
The Comprehensive R Archive Network
https://cran.r-project.org/
環境変数R_Homeを設定しましょう。環境変数の「値」は利用したいRのあるフォルダです。以下は例です。
- 変数:R_Home
- 値:C:\Program Files\R\R-4.2.0
PythonからRを使うパッケージであるRPY2をインストールします。
コマンドプロンプト上で以下のコードでインストールします。
pip install rpy2
これで準備は整いました。
RのスクリプトをPython上で実行する
RのスクリプトをPython上で実行するには、robjectsを使います。
先ず、必要なライブラリーを読み込みます。
以下、コードです。
import rpy2.robjects as robjects
次に、Rのスクリプトを記載していきます。3×5の演算をしています。
robjects.r('a <- 3')
robjects.r('b <- 5')
robjects.r('c <- a*b')
以下、実行結果です。

要は……
robjects.r(‘<Rのスクリプトを記載>’)
……ということです。
Rの関数を使った例も示しておきます。
以下、コードです。平均値を求めています。
robjects.r('a <- c(1,2,3,4,5,6)')
result = robjects.r('mean(a)')
print(result)
以下、実行結果です。
![]()
Python上のデータを、簡単にRに渡す方法も示します。
以下、コードです。assign関数でRに渡します。
a = 3
b = 5
robjects.r.assign('a', a)
robjects.r.assign('b', b)
result = robjects.r('c <- a*b')
print(result)
以下、実行結果です。
![]()
Rのスクリプトに慣れていれば、これだけで十分かもしれません。
ただ、配列やデータフレームなどの、まとまったデータセットを、PythonとRの間でやり取りを知っておいたほうがいいでしょう。
配列をRに渡す
NumPyの配列をRに渡します。さらに、Rに渡した配列を、Pythonに戻してみます。
先ず、必要なライブラリーを読み込みます。
import numpy as np from rpy2.robjects.conversion import py2rpy from rpy2.robjects import numpy2ri numpy2ri.activate()
次に、NumPyの配列を生成します。
以下、コードです。
# Pythonの配列を生成
py_array = np.array([[1,2,3,4,5],
[2,3,4,5,6],
[3,4,5,6,7],
])
# 確認
py_array
以下、実行結果です。

このNumPyの配列をRに渡します。
以下、コードです。
# Rに渡す
robjects.r.assign('r_array',
py2rpy(py_array))
Rの配列を、Pythonに渡します。
以下、コードです。
# Pythonに渡す
result = robjects.r('r_array')
# 確認
print(result)
以下、実行結果です。

データフレームをRに渡す
PandasのデータフレームをRに渡します。さらに、Rに渡した配列を、Pythonに戻してみます。
先ず、必要なライブラリーを読み込みます。
import pandas as pd from rpy2.robjects.conversion import localconverter from rpy2.robjects.conversion import py2rpy,rpy2py from rpy2.robjects import pandas2ri pandas2ri.activate()
先程生成したNumPyの配列を、データフレームに変換して使います。
以下、コードです。
# Pythonのデータフレームを生成 py_df = pd.DataFrame(py_array) py_df.columns = ['x1','x2','x3','x4','x5'] py_df.index = ['1','2','3'] # 確認 py_df
以下、実行結果です。

このPandasのデータフレームをRに渡します。
以下、コードです。
# Rに渡す
with localconverter(robjects.default_converter + pandas2ri.converter):
r_df = py2rpy(py_df)
Rのデータフレームを、Pythonに渡します。
以下、コードです。
# Pythonに渡す
with localconverter(robjects.default_converter + pandas2ri.converter):
py_df_2 = rpy2py(r_df)
# 確認
py_df_2
以下、実行結果です。

Rの関数をPython上で利用する(時系列ARIMAモデル例)
Rの関数をPython上で利用する方法を、時系列のARIMAモデルの構築で説明します。
サンプルデータ
今回利用する時系列データのデータセットは、Airline Passengers(飛行機乗客数)は、Box and Jenkins (1976) の有名な時系列データです。サンプルデータとして、よく利用されます。
弊社のHPからもダウンロードできます。
弊社のHP上のURLからダウンロード
https://www.salesanalytics.co.jp/591h
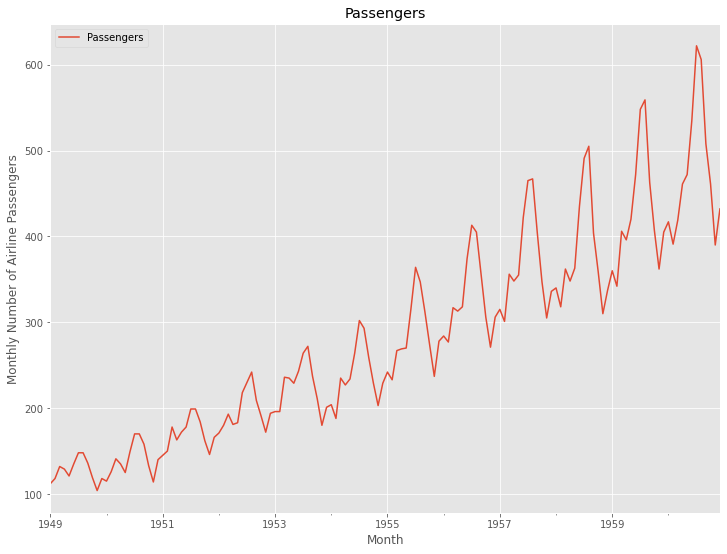
必要なライブラリーの読み込み
必要なライブラリーを読み込みます。
以下、コードです。
import pandas as pd
import numpy as np
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_percentage_error
import rpy2.robjects as robjects
from rpy2.robjects.packages import importr
from rpy2.robjects.conversion import py2rpy
from rpy2.robjects import numpy2ri
numpy2ri.activate()
import matplotlib.pyplot as plt
plt.style.use('ggplot') #グラフのスタイル
plt.rcParams['figure.figsize'] = [12, 9] # グラフサイズ設定
必要なデータの読み込み
必要なデータを読み込みます。
以下、コードです。
# データセットの読み込み
url='https://www.salesanalytics.co.jp/591h' #データセットのあるURL
df=pd.read_csv(url, #読み込むデータのURL
index_col='Month', #変数「Month」をインデックスに設定
parse_dates=True) #インデックスを日付型に設定
df.head() #確認
以下、実行結果です。
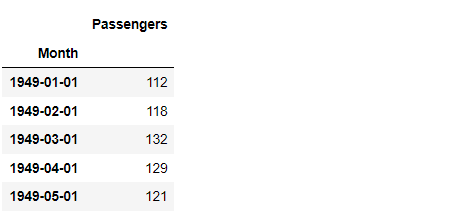
モデル構築で利用する学習データ(train)と、学習し求めた予測モデル(ARIMAモデル)の精度検証するテストデータ(test)に分けます。
後ろから12ヶ月間がテストデータで、それより前が学習データです。
以下、コードです。
# 学習データとテストデータ(直近12ヶ月間)に分割 train = df.iloc[:-12, :] #学習データ test = df.iloc[-12:, :] #テストデータ
必要なライブラリーのインストール
RもPythonと同じで、ライブラリーなどを追加でインストールすることで、機能を拡張することができます。
ARIMAモデルを自動構築する関数(auto.arima)がforecastというライブラリーの中にありますので、追加でforecastをインストールします。
以下、コードです。
utils = importr('utils')
utils.install_packages('forecast')
必要なときに、このライブラリーを読み込むことで利用することができます。
必要なライブラリーの読み込み
早速、先程インストールしたライブラリーforecastを利用したいので、読み込みます。
以下、コードです。
forecast_pkg = importr('forecast')
ARIMAモデルの自動構築
学習データ(train)をR用の時系列データに変換します。
以下、コードです。
# Rに渡す
robjects.r.assign('r_array',
py2rpy(train['Passengers'].values))
# Rの時系列オブジェクト生成
robjects.r('r_array <- ts(r_array, frequency=12)')
このデータを使い、ARIMAモデルを自動構築していきます。
以下、コードです。
# ARIMAモデル構築
arima_model = robjects.r('auto.arima(r_array, trace = TRUE)')
以下、実行結果です。
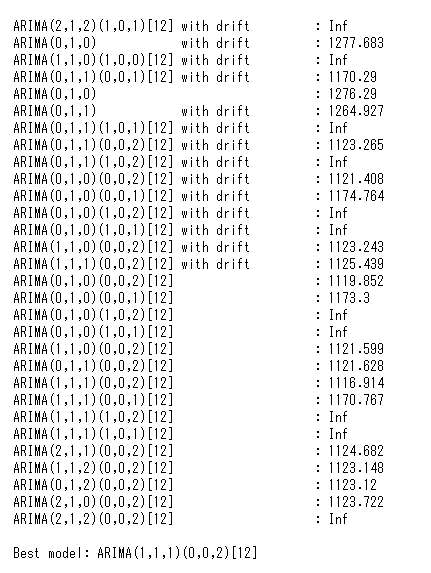
構築したARIMAモデルで予測
構築したARIMAモデルで、12ヶ月分を予測します。
以下、コードです。
forecasted = forecast_pkg.forecast(arima_model, h=12, level=(95.0))
このオブジェクト(forecasted)の中にある情報を確認してみます。
以下、コードです。
pd.DataFrame(forecasted.names)
以下、実行結果です。

必要最低限のものを説明します。
- 0 (method) :構築したARIMAモデル
- 3 (mean) :テストデータの予測値
- 8 (fitted) :学習データの予測値
どのようなARIMAモデルを構築したのかを確認してみます。
以下、コードです。
forecasted[0]
以下、実行結果です。

ARIMAモデルそのものの説明は、ここでは割愛します。興味のあるかたは、以下などを参考にしてください。
テストデータで精度検証
テストデータで精度検証します。
以下、コードです。
# テストデータで精度検証
pred = forecasted[3]
print('RMSE:')
print(np.sqrt(mean_squared_error(test, pred)))
print('MAE:')
print(mean_absolute_error(test, pred))
print('MAPE:')
print(mean_absolute_percentage_error(test, pred))
以下、実行結果です。

指標そのものの説明は、ここでは割愛します。興味のあるかたは、以下などを参考にしてください。
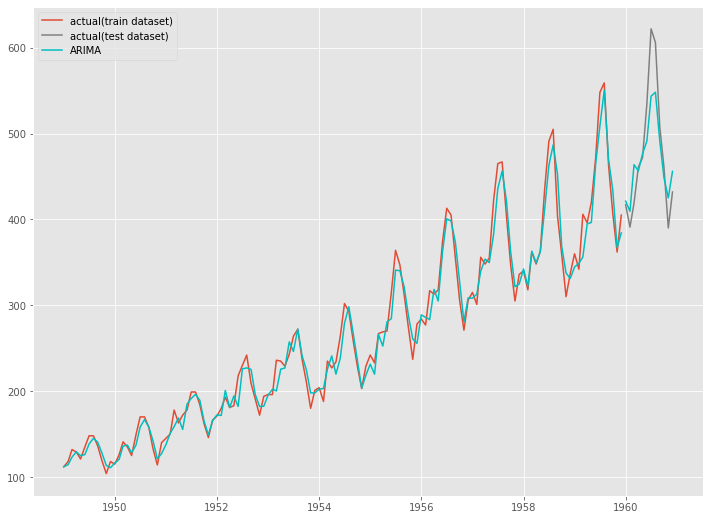
グラフをプロットし視覚的に確認します。
以下、コードです。
# グラフ化 fig, ax = plt.subplots() ax.plot(train.index, train.values, label="actual(train dataset)") ax.plot(test.index, test.values, label="actual(test dataset)", color="gray") ax.plot(train.index, forecasted[8], color="c") ax.plot(test.index, pred, label="ARIMA", color="c") plt.legend()
以下、実行結果です。
まとめ
今回は、「RPY2でPythonからRの関数を使おう」というお話しをしました。
興味のある方は、RPY2などをインストールし、Rにしか実装されていない関数などを利用してみてはいかがでしょうか。