
本当に売上に貢献している広告は、どの広告か?
売上と広告媒体等との関係性をモデリングし、どの広告媒体が売上にどれほど貢献していたのか分析することができます。
それが、マーケティングミックスモデリング(MMM:Marketing Mix Modeling)です。
ただ、多くの広告・販促は似たような時期に集中し実施することが多く、結果的にマルチコという線形回帰モデルを構築しうる上で非常に良くない現象が起こる危険があります。
Ridge回帰や主成分回帰(PCR)、PLS回帰などいつくか方法があります。
前回まで3回(その8~10)は、主成分回帰(PCR)の方法についてお話ししました。
今回からは3回に分けて、PLS回帰でモデルを構築する方法についてお話しします。
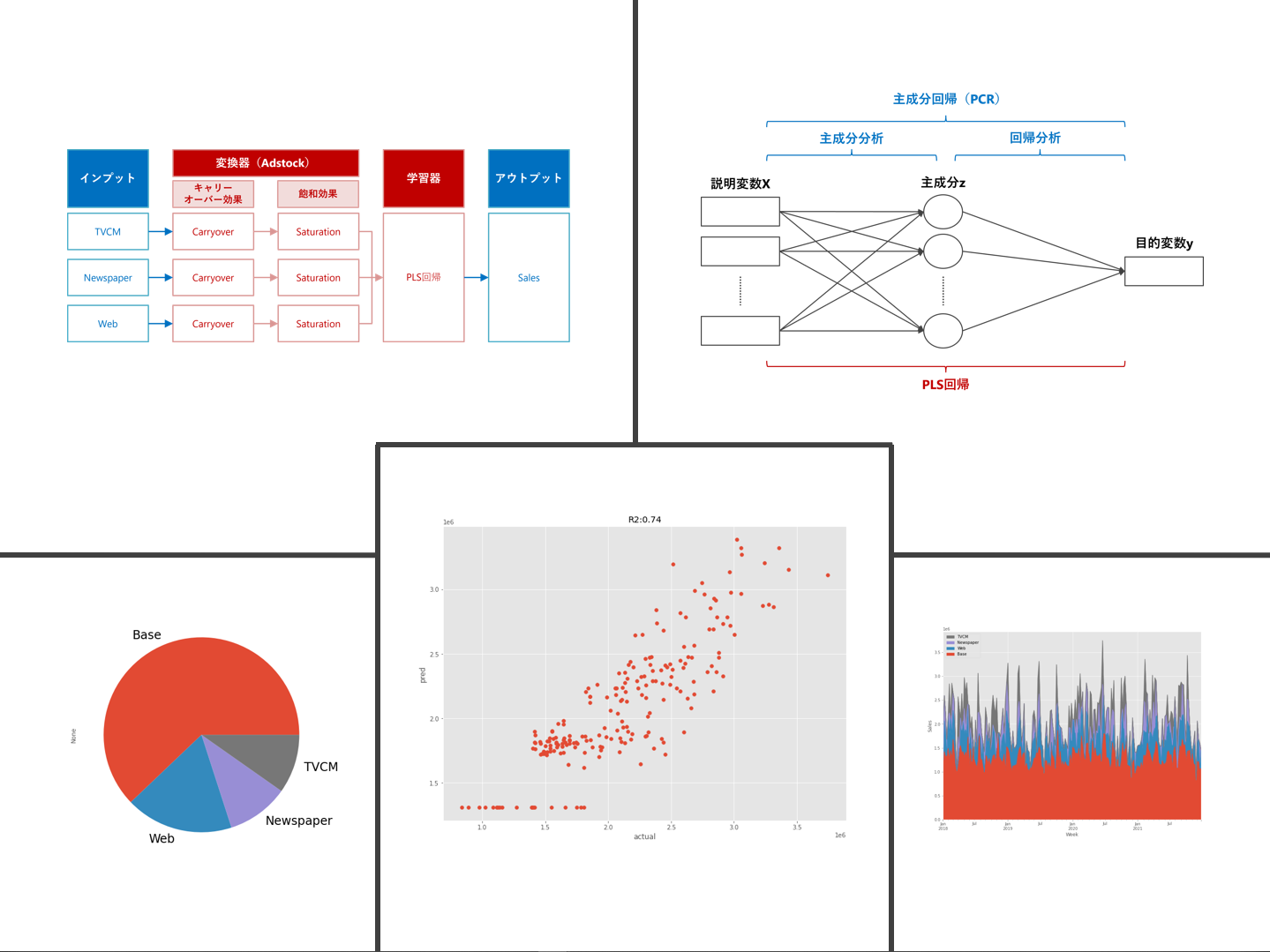
- ① AdStock非考慮 → 今回
- ② シンプルなAdStock考慮
- ③ 色々なAdStock考慮
今回は、色々なAdStockを考慮したPLS回帰によるモデル構築についてお話しします。
ちなみに、アドストック(Ad Stock)を考慮するとは、飽和効果(収穫逓減)とキャリーオーバー(Carryover)効果を考慮するということです。具体的には、Pythonのscikit-learn(sklearn)のパイプラインを、以下のように構築しました。
Contents [hide]
PLS回帰とは?
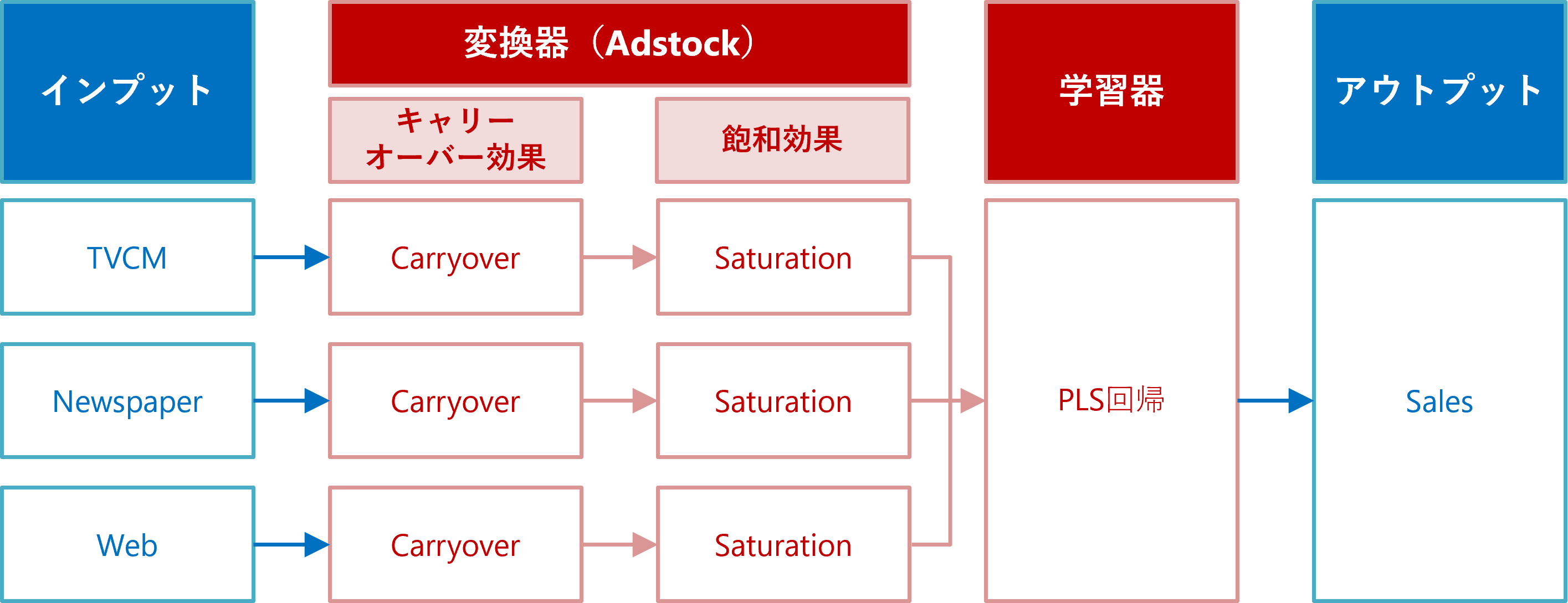
回帰モデルを構築するとき、マルチコという推定した係数がおかしくなる現象が起こることがあります。その原因の1つが、相関の高い説明変数同士の存在です。主成分分析は、相関の高い説明変数同士を取りまとめ主成分という新しい変数を生成します。その主成分同士の相関は低くなります。
主成分回帰(PCR)とは、元の説明変数Xに対し主成分分析を実施し主成分得点(変換後のデータ)を求め、その主成分得点を使い線形回帰モデルを構築する手法です。要は、主成分分析×線形回帰という2つの数理モデルの組み合わせたものです。
似たような手法に、部分的最小2乗回帰(PLS)があります。
違いは……
- PCR:主成分が、主成分の分散が最大になるように作成
- PLS:主成分が、目的変数Yと主成分の共分散が最大になるように作成
主成分回帰(PCR)もPLS回帰も、主成分が作られることは同じですが、主成分回帰(PCR)が説明変数だけで作られるのに対し、PLS回帰は目的変数との関係性も考慮して作られます。
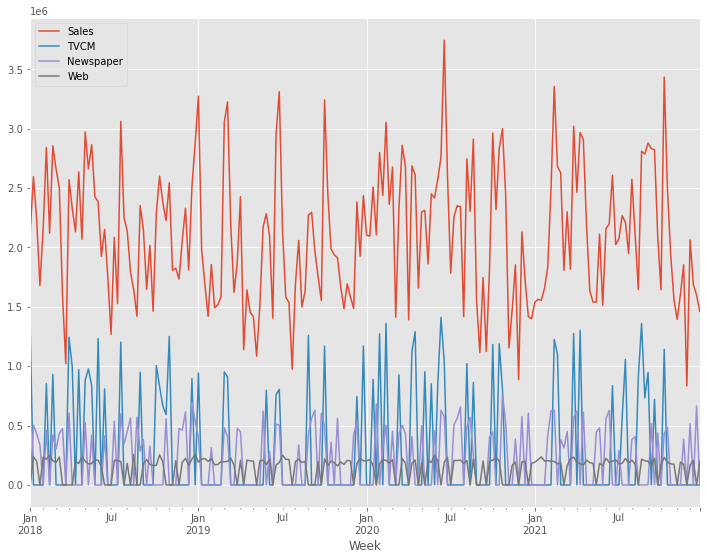
利用するデータセット(前回と同じ)
今回利用するデータセットの変数です。
- Week:週
- Sales:売上
- TVCM:TV CMのコスト
- Newspaper:新聞の折り込みチラシのコスト
- Web:Web広告のコスト
以下からダウンロードできます。
ハイパーパラメーター:主成分の数
PLS回帰には、主成分回帰(PCR)と同様にハイパーパラメータとして主成分の数というものがあり、モデル構築者が与える必要があります。
今回は、ハイパーパラメータチューニング用のライブラリーであるOptunaを利用し、最適な主成分の数を探索し、その値を利用しMMMを構築します。
ライブラリーやデータセットなどの読み込み
先ずは、必要なライブラリーとデータセットを読み込みます。前回までと同じです。
必要なライブラリーの読み込み
必要なライブラリーを読み込みます。
以下、コードです。
import numpy as np
import pandas as pd
from sklearn.cross_decomposition import PLSRegression
from sklearn.pipeline import Pipeline
from sklearn.model_selection import TimeSeriesSplit
from optuna.distributions import IntUniformDistribution
from sklearn import set_config
from optuna.integration import OptunaSearchCV
from optuna.distributions import UniformDistribution
import matplotlib.pyplot as plt
plt.style.use('ggplot') #グラフスタイル
plt.rcParams['figure.figsize'] = [12, 9] # グラフサイズ
データセット(前回と同じ)の読み込み
前回と同じデータセットを読み込みます。
以下、コードです。
# データセット読み込み
url = 'https://www.salesanalytics.co.jp/4zdt'
df = pd.read_csv(url,
parse_dates=['Week'],
index_col='Week'
)
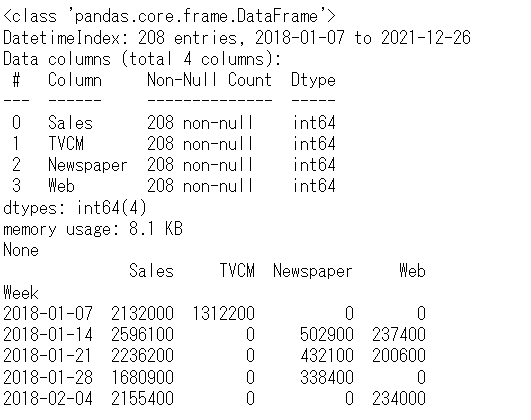
# データ確認
print(df.info()) #変数の情報
print(df.head()) #データの一部
# 説明変数Xと目的変数yに分解
X = df.drop(columns=['Sales'])
y = df['Sales']
以下、実行結果です。
ハイパーパラメータ探索
PLSの最適な主成分の数の値を探索します。
以下、コードです。
#
# ハイパーパラメータ探索
#
# PLS回帰のインスタンス生成
MMM=PLSRegression()
# 探索するハイパーパラメータ範囲の設定
params = {
'n_components':IntUniformDistribution(1, 3),
}
# ハイパーパラメータ探索の設定
optuna_search = OptunaSearchCV(
estimator=MMM,
param_distributions=params,
n_trials=1000,
cv=TimeSeriesSplit(),
random_state=123,
)
# 探索実施
optuna_search.fit(X, y)
# 探索結果
optuna_search.best_params_
以下、実行結果です。最適な主成分の数です。
![]()
この値を主成分の数に設定し、MMMを全データで構築します。
モデルの構築と予測
最適ハイパーパラメータで学習
以下、コードです。
# # 最適ハイパーパラメータで学習 # # パイプラインのインスタンス MMM_best = MMM.set_params(**optuna_search.best_params_) # 全データで学習 MMM_best.fit(X, y) # R2(決定係数) MMM_best.score(X, y)
以下、実行結果です。R2(決定係数)の値です。
![]()
予測の実施
以下、コードです。
#
# 予測の実施
#
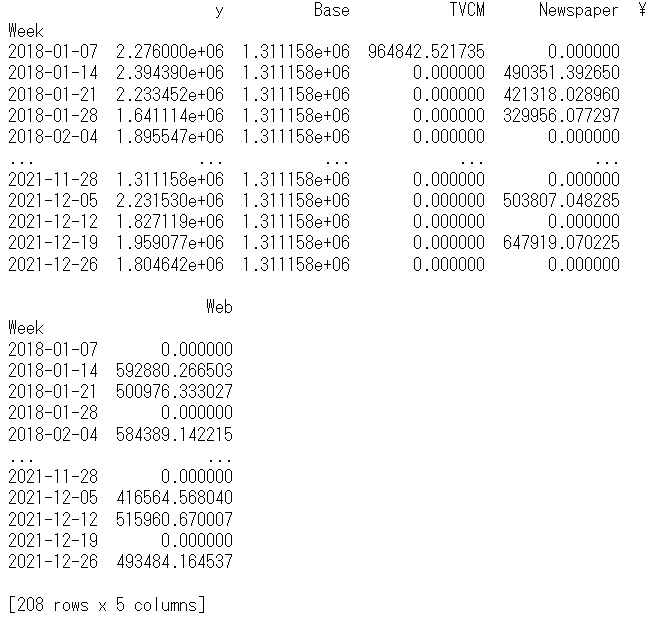
# 目的変数y(売上)の予測
pred = pd.DataFrame(MMM_best.predict(X),
index=X.index,
columns=['y'])
# 各媒体による売上の予測
## 値がすべて0の説明変数
X_ = X.copy()
X_.iloc[:,:]=0
## Base
pred['Base'] = MMM_best.predict(X_)
## 媒体
for i in range(len(X.columns)):
X_.iloc[:,:]=0
X_.iloc[:,i]=X.iloc[:,i]
pred[X.columns[i]] = MMM_best.predict(X_)[:,0] - pred['Base']
print(pred) #確認
以下、実行結果です。y = Base + TVCM + Newspaper + Webです。
貢献度とマーケティングROIの算定
貢献度の算定
以下、コードです。
#
# 貢献度の算定
#
# 予測値の補正
correction_factor = y.div(pred['y'], axis=0) #補正係数
pred_adj = pred.mul(correction_factor, axis=0) #補正後の予測値
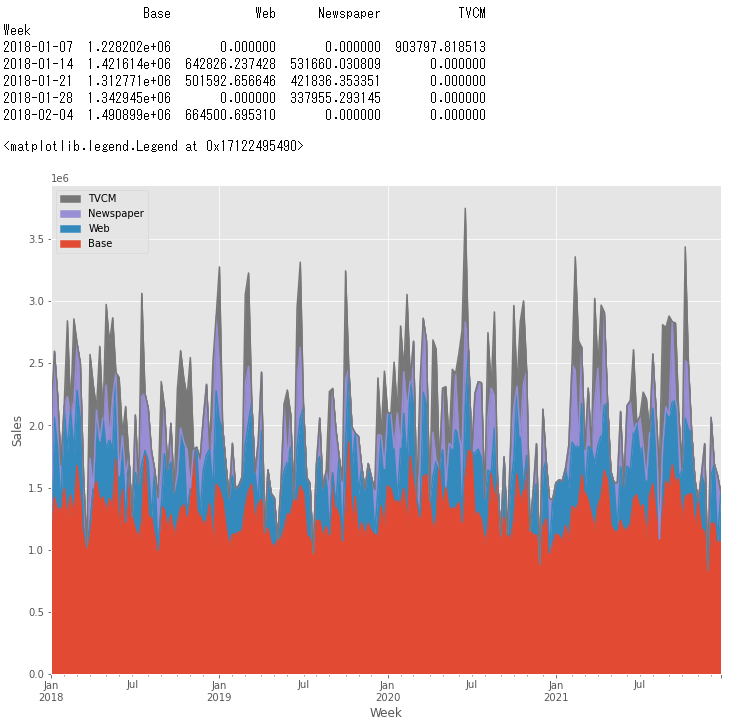
# 各媒体の貢献度だけ抽出
contribution = pred_adj[['Base', 'Web', 'Newspaper', 'TVCM']]
print(contribution.head()) #確認
# グラフ化
ax = (contribution
.plot.area(
ylabel='Sales',
xlabel='Week')
)
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles[::-1], labels[::-1])
以下、実行結果です。
貢献度の構成比の算出します。
以下、コードです。
#
# 貢献度の構成比の算出
#
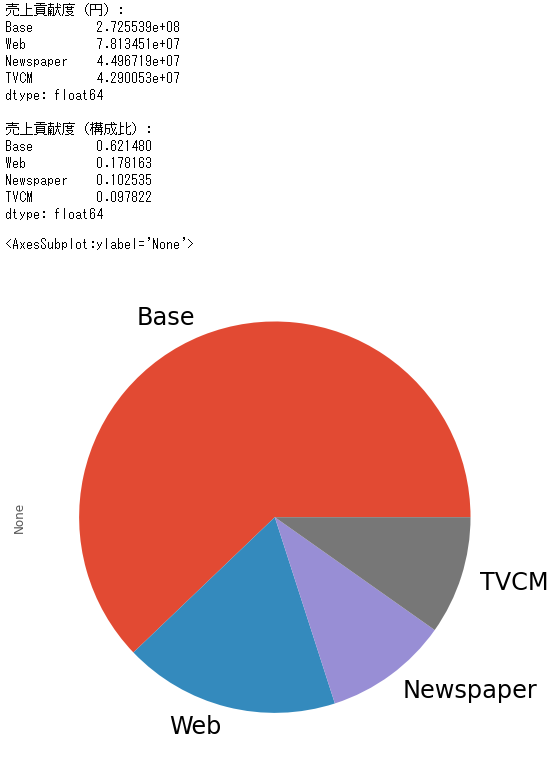
# 媒体別の貢献度の合計
contribution_sum = contribution.sum(axis=0)
# 集計結果の出力
print('売上貢献度(円):\n',
contribution_sum,
sep=''
)
print()
print('売上貢献度(構成比):\n',
contribution_sum/contribution_sum.sum(),
sep=''
)
# グラフ化
contribution_sum.plot.pie(fontsize=24)
以下、実行結果です。
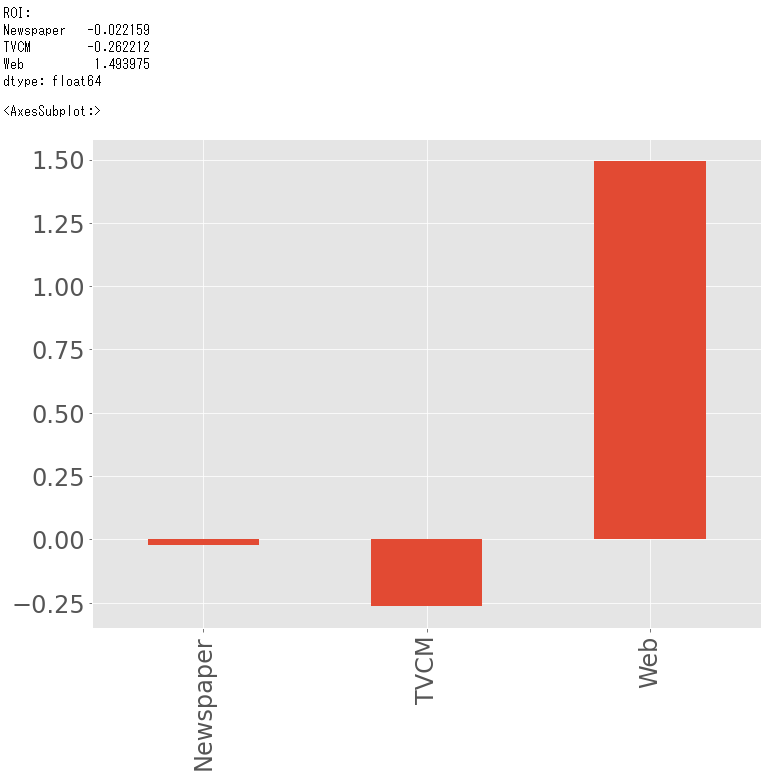
マーケティングROIの算定
以下、コードです。
#
# マーケティングROIの算定
#
# 各媒体のコストの合計
cost_sum = X.sum(axis=0)
# 各媒体のROIの計算
ROI = (contribution_sum.drop('Base', axis=0) - cost_sum)/cost_sum
print('ROI:\n', ROI, sep='') #確認
# グラフ化
ROI.plot.bar(fontsize=24)
以下、実行結果です。
まとめ
今回は、AdStockを考慮しないPLS回帰によるモデル構築についてお話ししました。
- AdStock非考慮 → 今回
- シンプルなAdStock考慮 → 次回
- 色々なAdStock考慮
次回は、シンプルなAdStockを考慮したPLS回帰によるモデル構築についてお話しします。
Pythonによるマーケティングミックスモデリング(MMM:Marketing Mix Modeling)超入門 その12PLS回帰モデルでMMM②(シンプルなAdStock考慮)