
データ分析で遊ぶとき、何かサンプルとなるデータセットはないか、探すこともあることでしょう。
そのとき重宝するのが、OpenMLのサンプルデータです。
Pythonですと、Scikit-learnの関数「sklearn.datasets.fetch_openml」で、簡単にOpenMLから、たくさんのサンプルデータを取得できます。
openmlというライブラリーを使っても取得できます。
今回は、「OpenMLのサンプルデータをPython上で取得し利用する方法」というお話しをします。
Contents [hide]
- OpenMLとは?
- OpenMLで、データセットを検索
- アヤメ(iris)のデータセット
- 売上(sales)のデータセット
- Scikit-learnで読み込む
- 準備
- アヤメのデータ(iris)
- データセットの読み込み
- 説明変数Xのみのデータセット
- 目的変数yのみのデータセット
- 説明変数Xと目的変数yが結合されたデータセット
- 車の販売データ(Car-sales)
- データセットの読み込み
- 説明変数Xのみのデータセット
- 目的変数yのみのデータセット
- 説明変数Xと目的変数yが結合されたデータセット
- openmlで読み込む
- 準備
- アヤメのデータ(iris)
- データセットの読み込み
- 説明変数Xと目的変数yを別々に取得
- 説明変数Xと目的変数yが結合されたデータセットを取得
- 車の販売データ(Car-sales)
- データセットの読み込み
- データセットの取得
- まとめ
OpenMLとは?
OpenMLは、機械学習の研究者がデータセットや機械学習のタスク、その実行結果などを共有するプラットフォームです。
サイト(https://www.openml.org/)を見ていただくと分かりますが、例えば……
- Datasets
- Tasks
- Flows
- Runs
……などがあります。

サンプルデータに関しては、当然ですがDatasetsです。
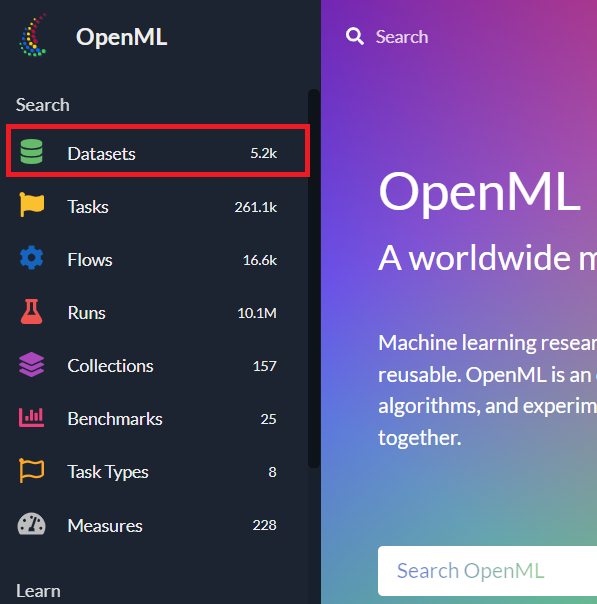
Tasksは、データセットを使ったタスクと評価方法などが記載されています。
Flowsは実装で、Runsがその結果です。
要は、データセットがたくさん共有されているだけではない、ということです。
とは言え、サンプルデータを取得する目的で利用する人が、多いように感じます。
OpenMLで、データセットを検索
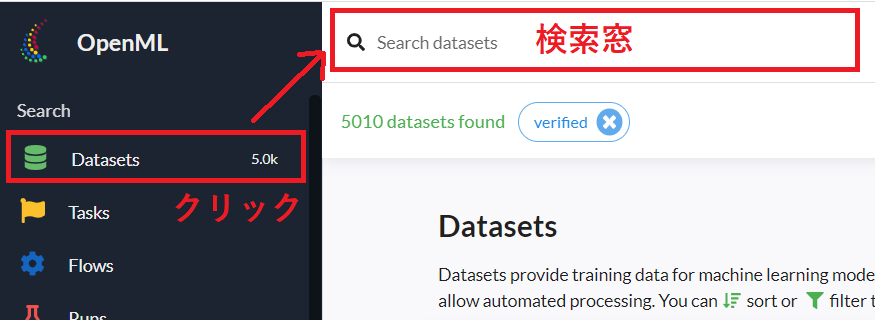
データセットを検索するときは、Datasetsをクリックし検索窓を表示させ、そこにキワードを入力し検索するだけです。
アヤメ(iris)のデータセット
例えば、みんな大好きアヤメ(iris)のデータセットを探してみます。
検索窓に「iris」と入力します。
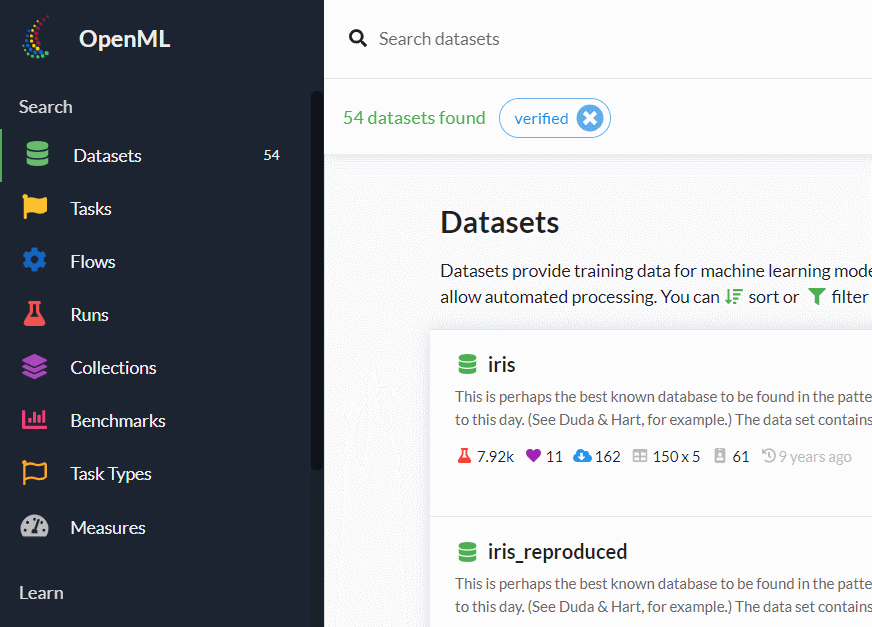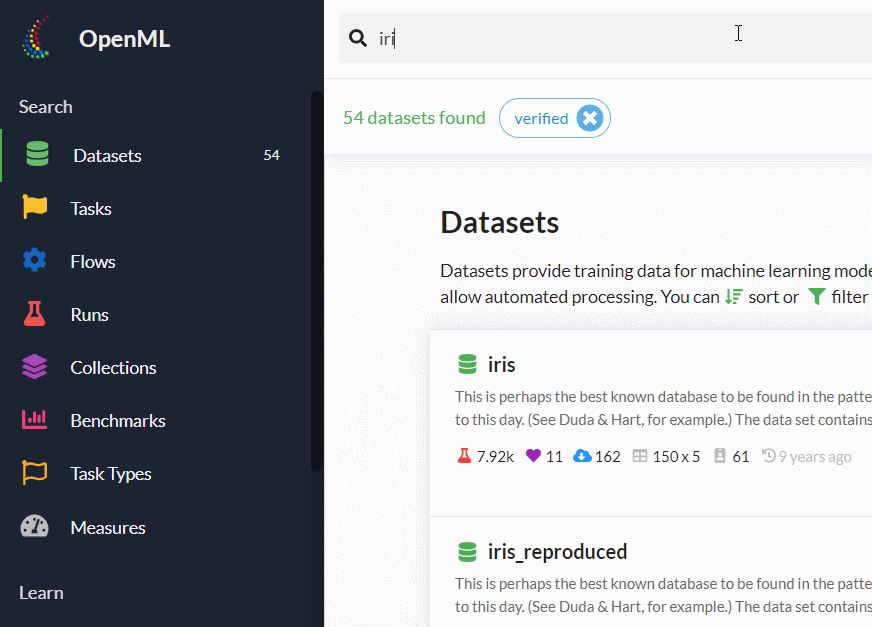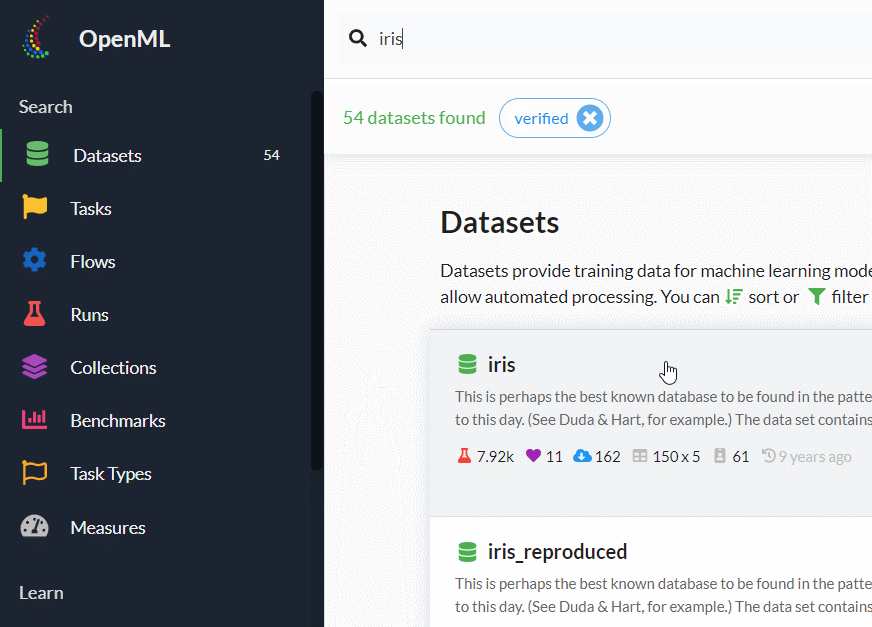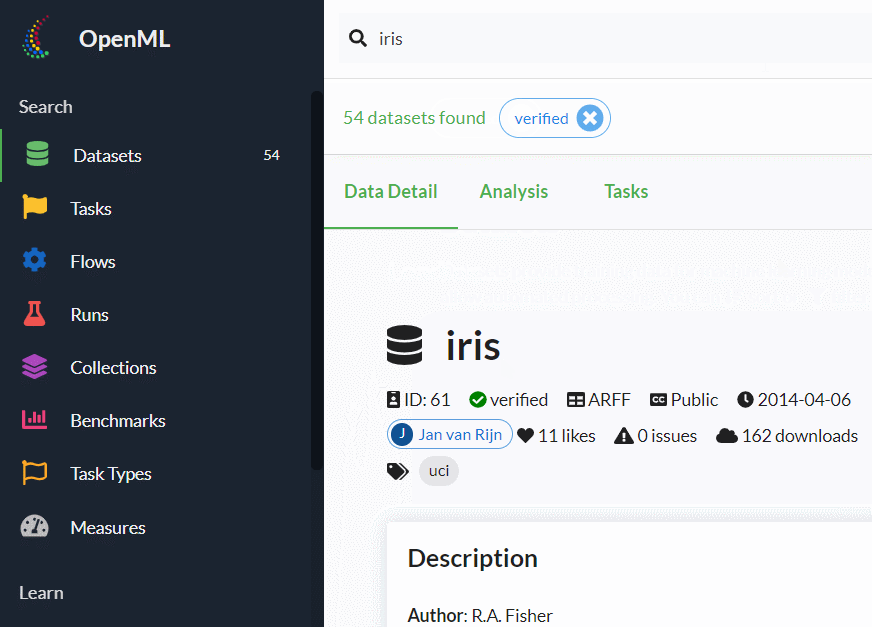
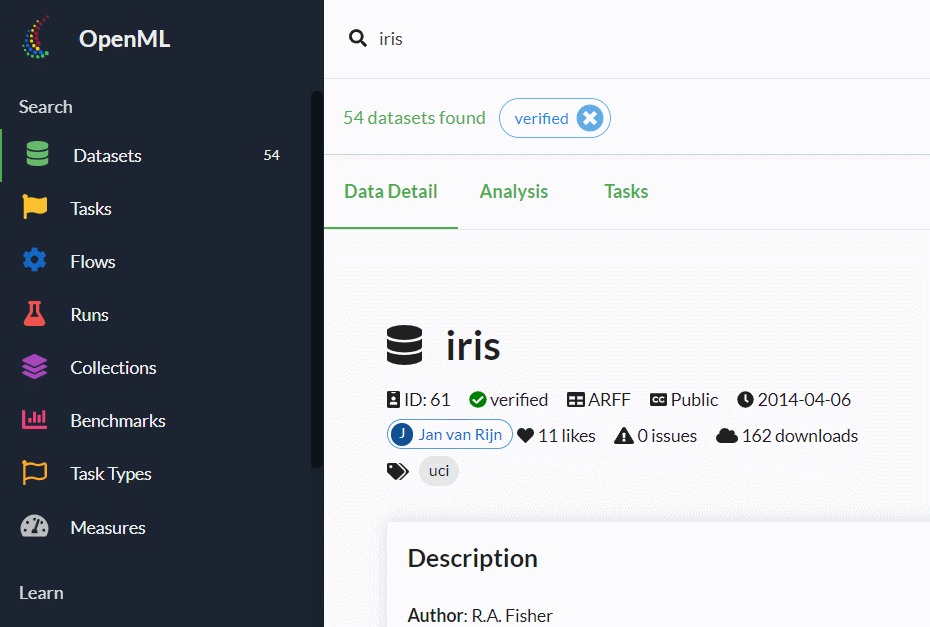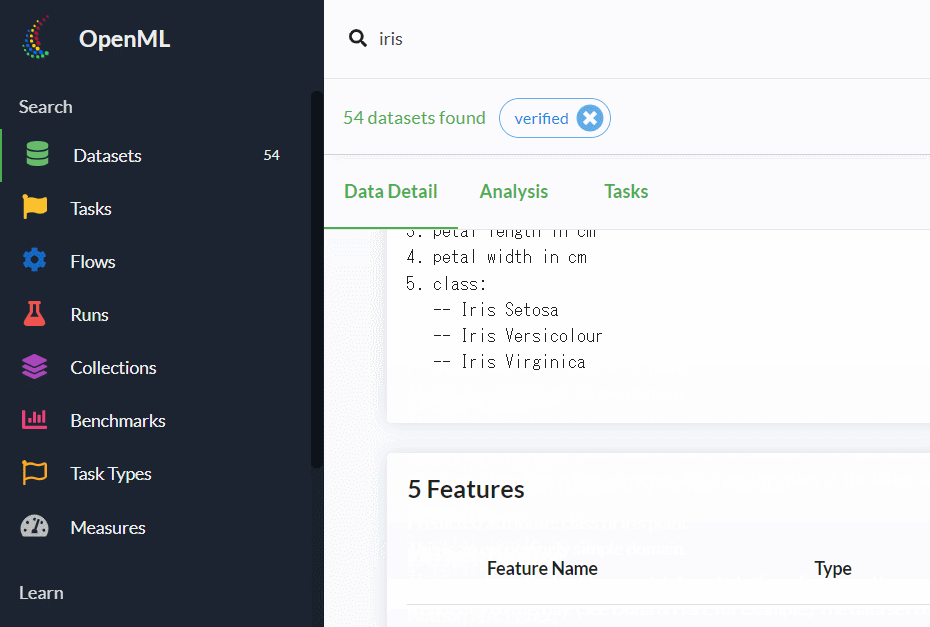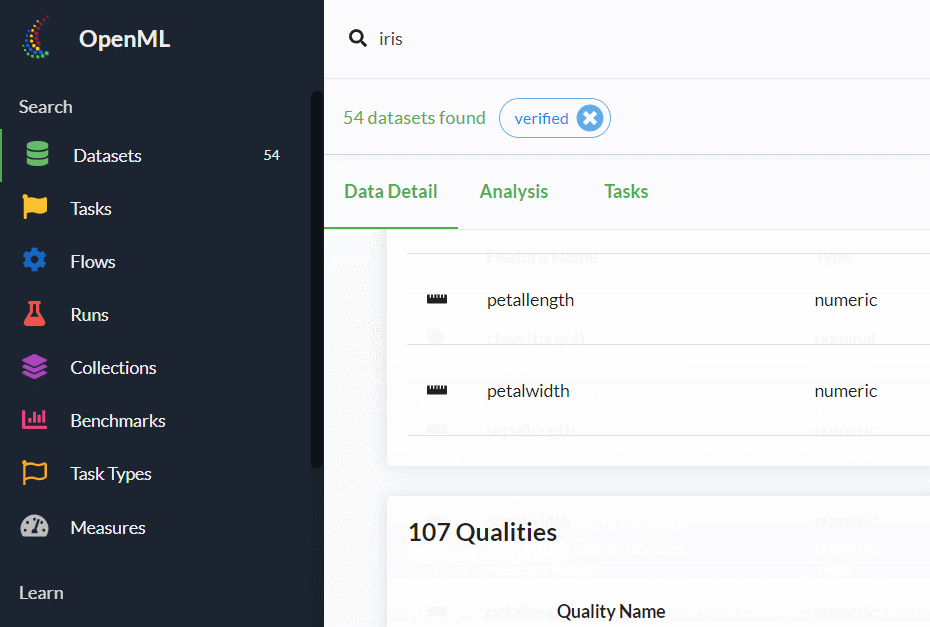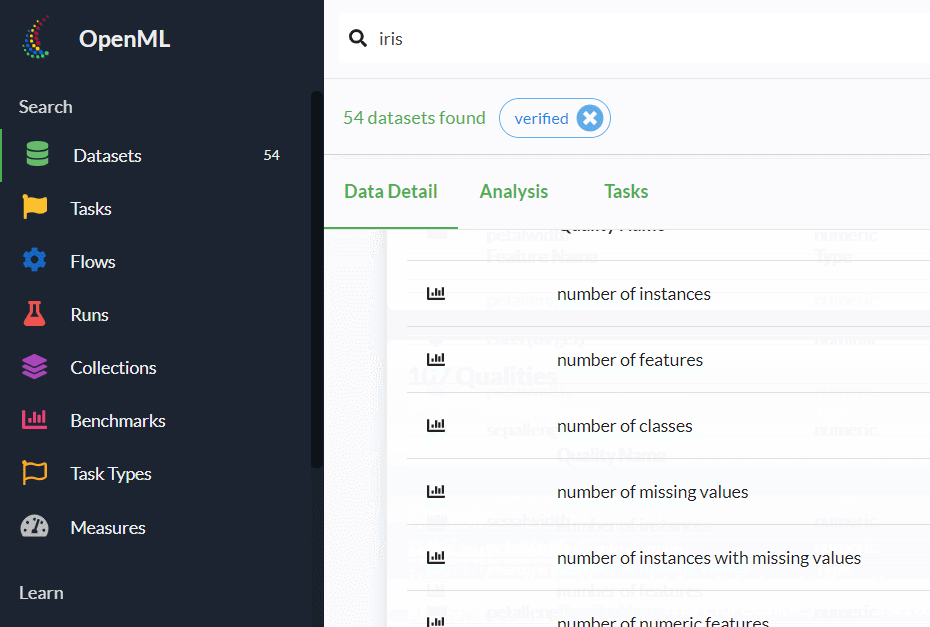
検索結果が出たら、それをクリックしどのようなデータセットなのを見ます。
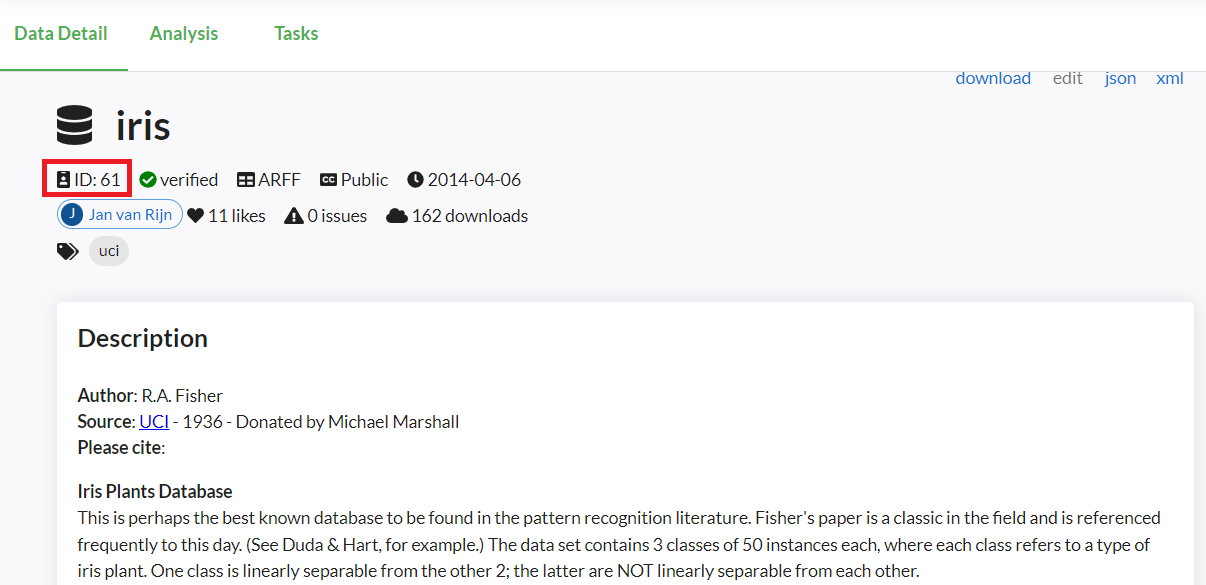
このデータセットをsklearn.datasets.fetch_openmlなどで呼び出すときに必要になるのが「ID」です。
アヤメ(iris)の場合には「ID:61」となっています。
下にスクロールすると、各変数の情報などが記載されていますので、ぜひ確認しておきましょう。
売上(sales)のデータセット
アヤメ(iris)のように有名なデータセットであれば、ダイレクトにデータセット名を検索窓に入力することで、入手できます。
多くの場合は、何らかの売上データを使ったデータ分析などをしたい場合、なんでもいいので売上データを入手したい、となるでしょう。
このようなとき、検索窓に「sales」と入力し検索すれば、salesに関するデータセットが検索結果として複数提示されます。
その中から、好みのデータセットを選ぶといいでしょう。
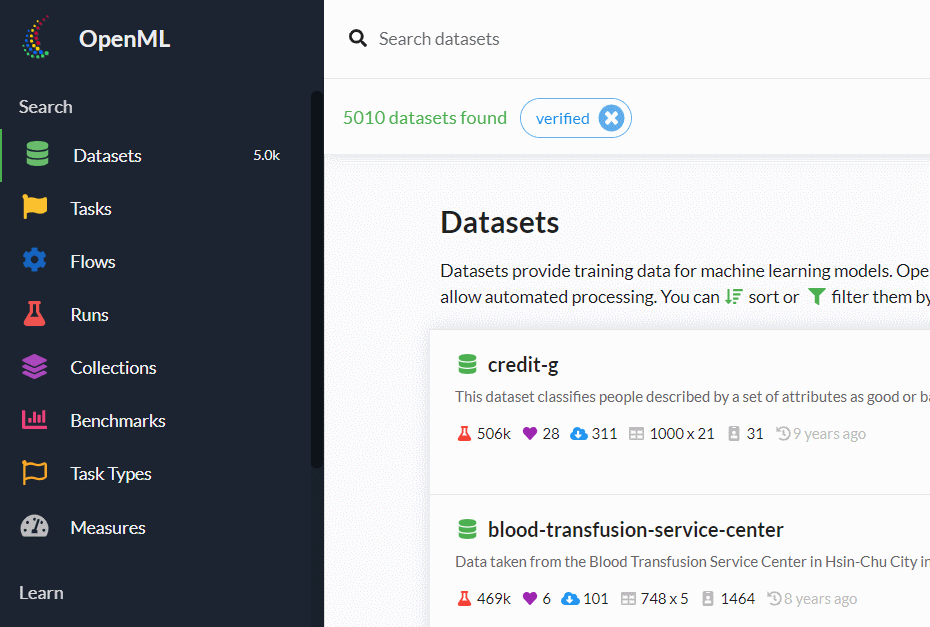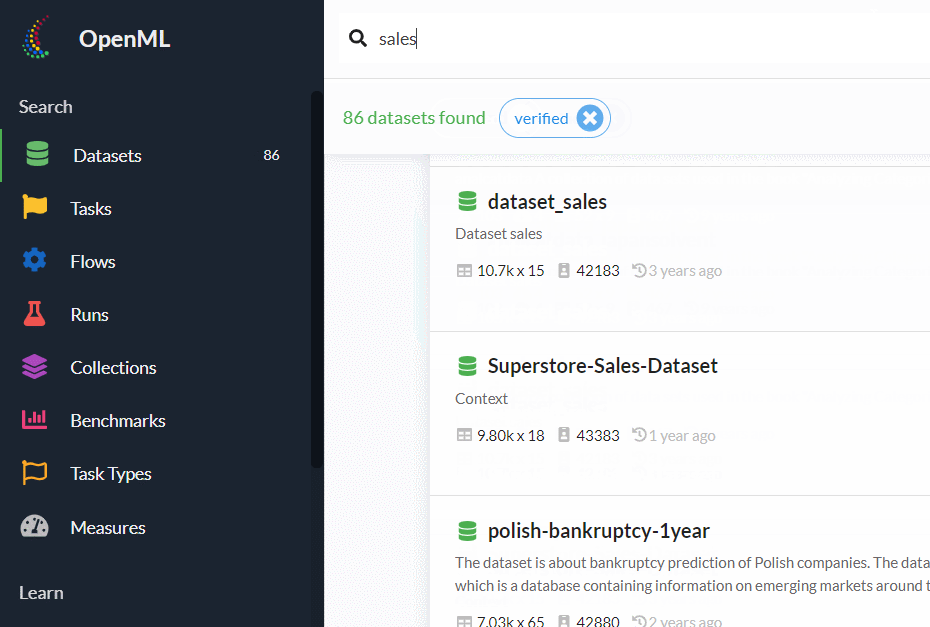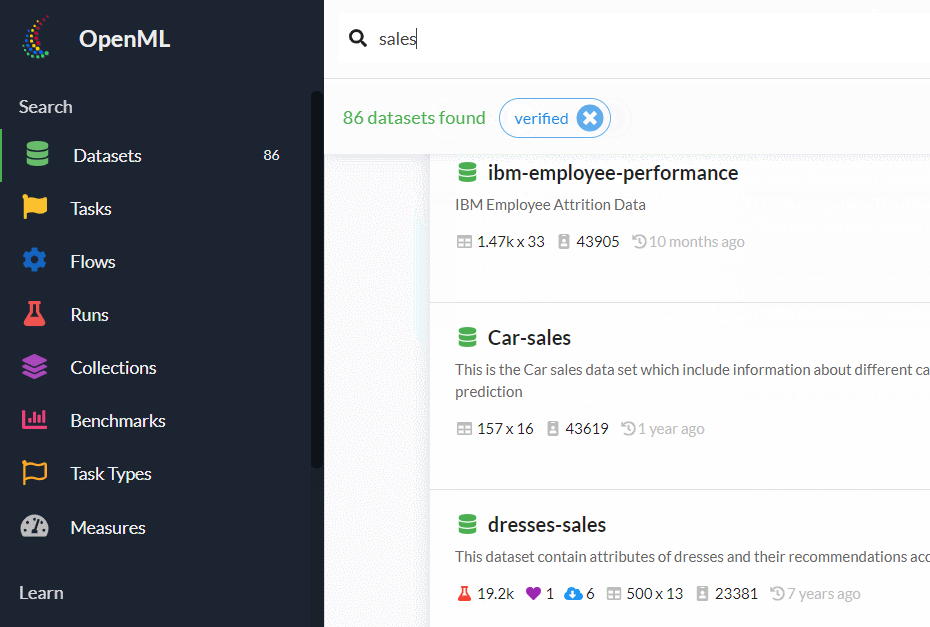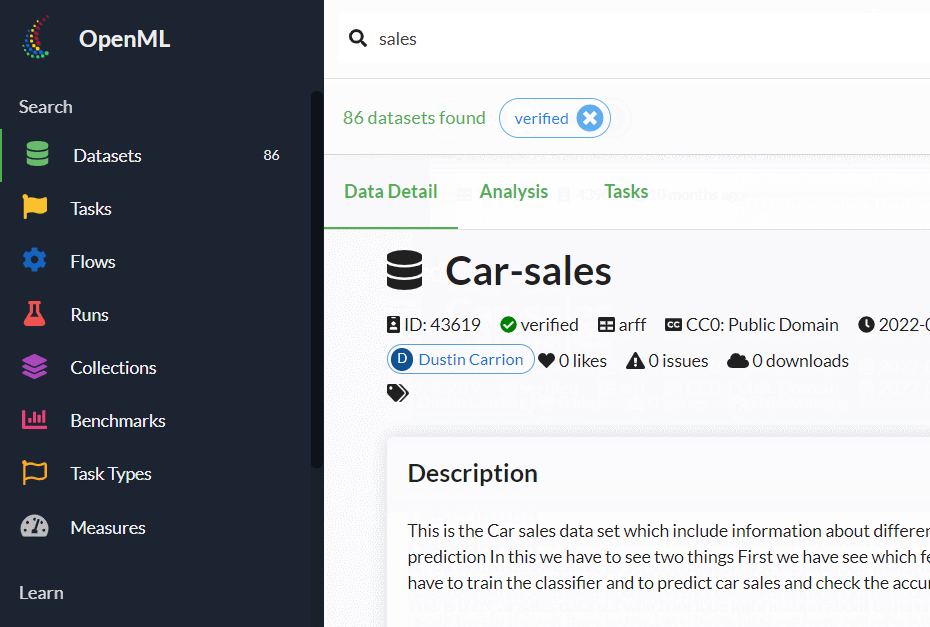
今回は、「Car-sales」というデータセットを選んでみました。
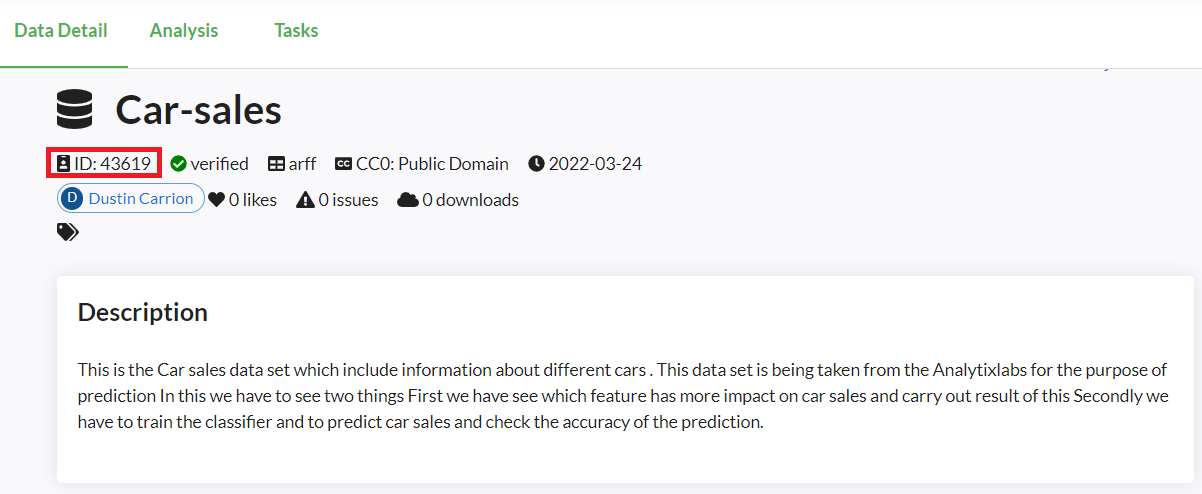
これは車の販売データで、いくつかの車に関する情報も変数として提供されています。
ちなみに、「ID:43619」です。
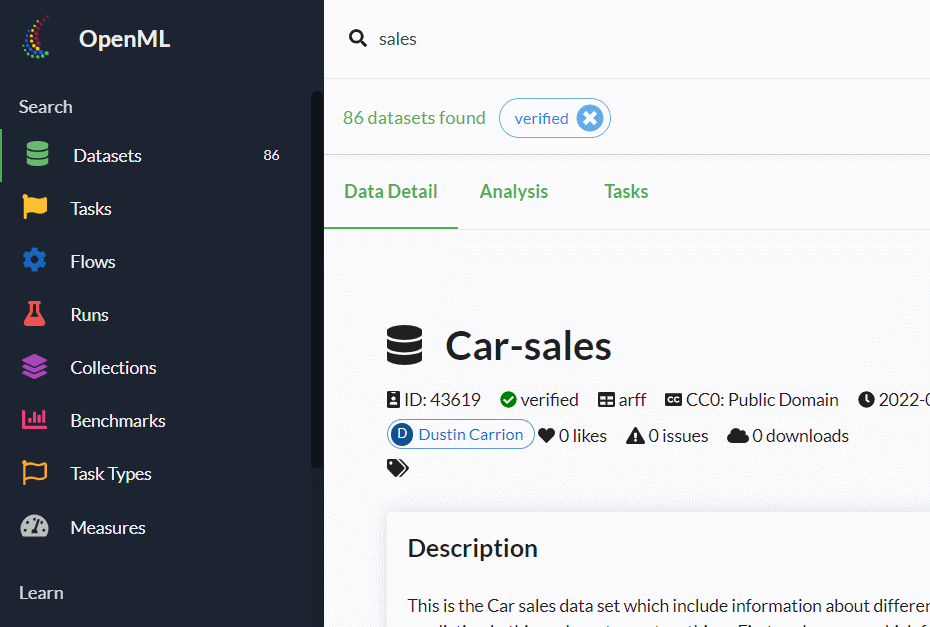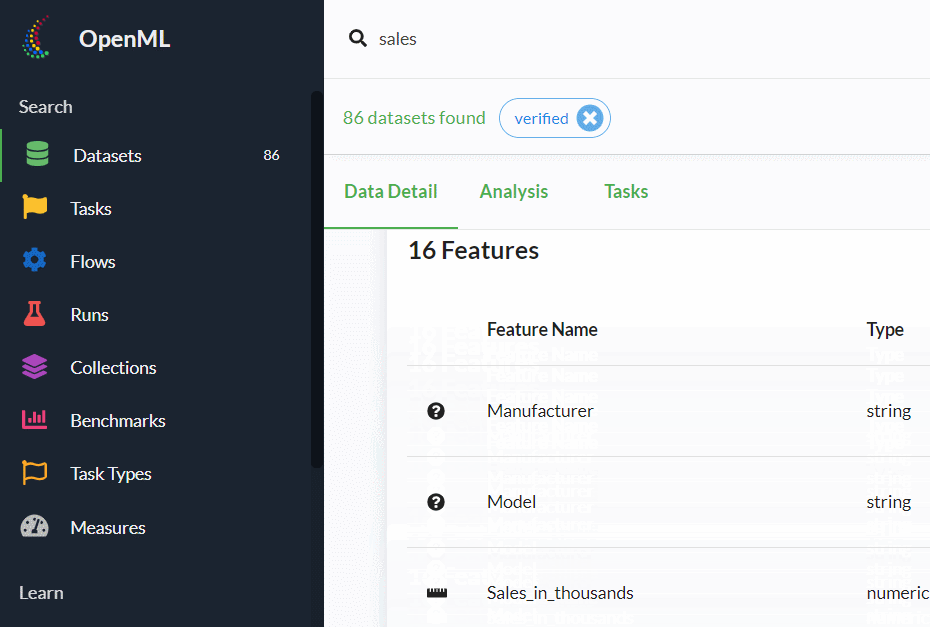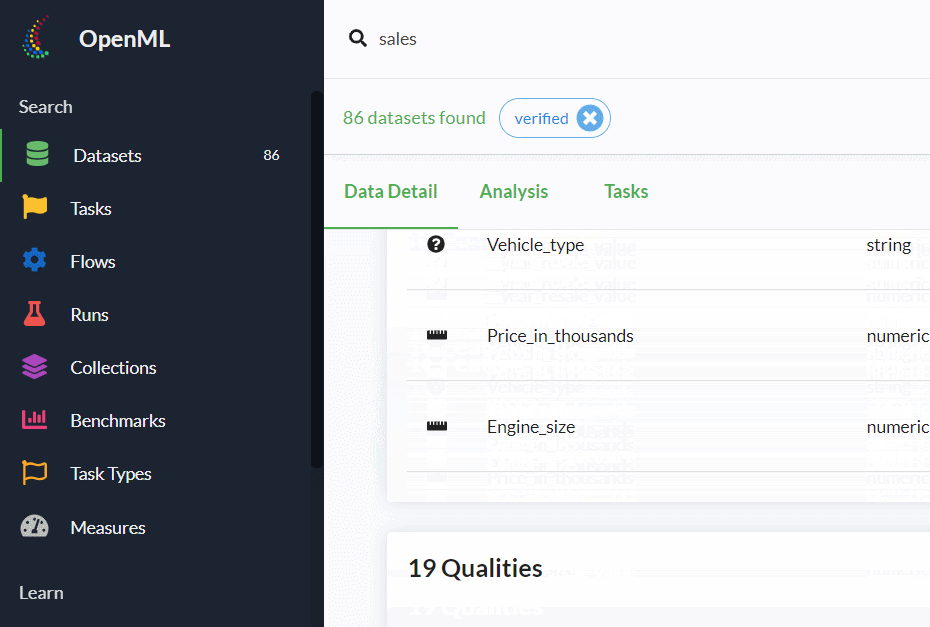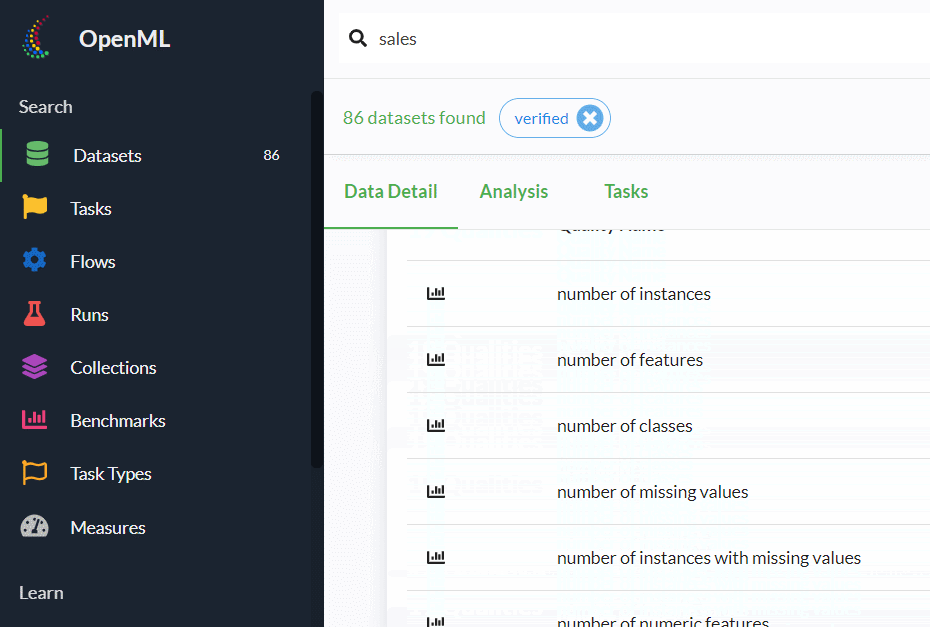
下にスクロールすると、各変数の情報などが記載されています。
Scikit-learnで読み込む
準備
まだScikit-learnをインストールしていない方は、インストールしておいてください。
condaでインストールするときは以下です。
conda install -c conda-forge scikit-learn
pipでインストールするときは以下です。
pip install scikit-learn
インストールが終了、もしくはすでにしているならば、OpenMLのデータセットを読み込むための関数「fetch_openml」を読み込みます。
以下、コードです。
from sklearn.datasets import fetch_openml
アヤメのデータ(iris)
データセットの読み込み
アヤメのデータ(iris)を読み込みます。
以下、コードです。
# データセットの読み込み dataset = fetch_openml(data_id=61, parser='auto')
アヤメのデータ(iris)のIDは「61」のため「data_id=61」としています。
先ず、datasetに格納されたデータセット(説明変数Xと目的変数y)の変数名を確認してみます。
説明変数Xです。
以下、コードです。
# 説明変数Xの変数名 dataset['feature_names']
以下、実行結果です。
['sepallength', 'sepalwidth', 'petallength', 'petalwidth']
目的変数yです。
以下、コードです。
# 目的変数yの変数名 dataset['target_names']
以下、実行結果です。
['class']
次に、datasetから次の3種類のデータセットを抜き出してみます。
- 説明変数Xのみのデータセット
- 目的変数yのみのデータセット
- 説明変数Xと目的変数yが結合されたデータセット
説明変数Xのみのデータセット
説明変数Xのみのデータセットです。
以下、コードです。
# 説明変数Xのみのデータセット X = dataset['data'] print(X) #確認
以下、実行結果です。
sepallength sepalwidth petallength petalwidth 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 3 4.6 3.1 1.5 0.2 4 5.0 3.6 1.4 0.2 .. ... ... ... ... 145 6.7 3.0 5.2 2.3 146 6.3 2.5 5.0 1.9 147 6.5 3.0 5.2 2.0 148 6.2 3.4 5.4 2.3 149 5.9 3.0 5.1 1.8 [150 rows x 4 columns]
目的変数yのみのデータセット
目的変数yのみのデータセットです。
以下、コードです。
# 目的変数yのみのデータセット y = dataset['target'] print(y) #確認
以下、実行結果です。
0 Iris-setosa
1 Iris-setosa
2 Iris-setosa
3 Iris-setosa
4 Iris-setosa
...
145 Iris-virginica
146 Iris-virginica
147 Iris-virginica
148 Iris-virginica
149 Iris-virginica
Name: class, Length: 150, dtype: category
Categories (3, object): ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']
説明変数Xと目的変数yが結合されたデータセット
説明変数Xと目的変数yが結合されたデータセットです。
以下、コードです。
# 説明変数Xと目的変数yが結合されたデータセット df = dataset['frame'] print(df) #確認
以下、実行結果です。
sepallength sepalwidth petallength petalwidth class 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa .. ... ... ... ... ... 145 6.7 3.0 5.2 2.3 Iris-virginica 146 6.3 2.5 5.0 1.9 Iris-virginica 147 6.5 3.0 5.2 2.0 Iris-virginica 148 6.2 3.4 5.4 2.3 Iris-virginica 149 5.9 3.0 5.1 1.8 Iris-virginica [150 rows x 5 columns]
車の販売データ(Car-sales)
データセットの読み込み
車の販売データ(Car-sales)を読み込みます。
以下、コードです。
# データセットの読み込み dataset = fetch_openml(data_id=43619, parser='auto')
車の販売データ(Car-sales)のIDは「43619」のため「data_id=43619」としています。
先ず、datasetに格納されたデータセット(説明変数Xと目的変数y)の変数名を確認してみます。
説明変数Xです。
以下、コードです。
# 説明変数Xの変数名 dataset['feature_names']
以下、実行結果です。
['Manufacturer', 'Model', 'Sales_in_thousands', '__year_resale_value', 'Vehicle_type', 'Price_in_thousands', 'Engine_size', 'Horsepower', 'Wheelbase', 'Width', 'Length', 'Curb_weight', 'Fuel_capacity', 'Fuel_efficiency', 'Latest_Launch', 'Power_perf_factor']
目的変数yです。
以下、コードです。
# 目的変数yの変数名 dataset['target_names']
以下、実行結果です。
[]
目的変数が設定されていないため、
次に、datasetから次の3種類のデータセットを抜き出してみます。
- 説明変数Xのみのデータセット
- 目的変数yのみのデータセット
- 説明変数Xと目的変数yが結合されたデータセット
説明変数Xのみのデータセット
説明変数Xのみのデータセットです。
以下、コードです。
# 説明変数Xのみのデータセット X = dataset['data'] print(X) #確認
以下、実行結果です。
Manufacturer Model Sales_in_thousands __year_resale_value \
0 Acura Integra 16.919 16.360
1 Acura TL 39.384 19.875
2 Acura CL 14.114 18.225
3 Acura RL 8.588 29.725
4 Audi A4 20.397 22.255
.. ... ... ... ...
152 Volvo V40 3.545 NaN
153 Volvo S70 15.245 NaN
154 Volvo V70 17.531 NaN
155 Volvo C70 3.493 NaN
156 Volvo S80 18.969 NaN
Vehicle_type Price_in_thousands Engine_size Horsepower Wheelbase \
0 Passenger 21.50 1.8 140.0 101.2
1 Passenger 28.40 3.2 225.0 108.1
2 Passenger NaN 3.2 225.0 106.9
3 Passenger 42.00 3.5 210.0 114.6
4 Passenger 23.99 1.8 150.0 102.6
.. ... ... ... ... ...
152 Passenger 24.40 1.9 160.0 100.5
153 Passenger 27.50 2.4 168.0 104.9
154 Passenger 28.80 2.4 168.0 104.9
155 Passenger 45.50 2.3 236.0 104.9
156 Passenger 36.00 2.9 201.0 109.9
Width Length Curb_weight Fuel_capacity Fuel_efficiency Latest_Launch \
0 67.3 172.4 2.639 13.2 28.0 2/2/2012
1 70.3 192.9 3.517 17.2 25.0 6/3/2011
2 70.6 192.0 3.470 17.2 26.0 1/4/2012
3 71.4 196.6 3.850 18.0 22.0 3/10/2011
4 68.2 178.0 2.998 16.4 27.0 10/8/2011
.. ... ... ... ... ... ...
152 67.6 176.6 3.042 15.8 25.0 9/21/2011
153 69.3 185.9 3.208 17.9 25.0 11/24/2012
154 69.3 186.2 3.259 17.9 25.0 6/25/2011
155 71.5 185.7 3.601 18.5 23.0 4/26/2011
156 72.1 189.8 3.600 21.1 24.0 11/14/2011
Power_perf_factor
0 58.280150
1 91.370778
2 NaN
3 91.389779
4 62.777639
.. ...
152 66.498812
153 70.654495
154 71.155978
155 101.623357
156 85.735655
[157 rows x 16 columns]
目的変数yのみのデータセット
目的変数yのみのデータセットです。
以下、コードです。
# 目的変数yのみのデータセット y = dataset['target'] print(y) #確認
以下、実行結果です。
None
車の販売データ(Car-sales)には、目的変数が設定されていないため、空のデータセットが返されます。
説明変数Xと目的変数yが結合されたデータセット
説明変数Xと目的変数yが結合されたデータセットです。
以下、コードです。
# 説明変数Xと目的変数yが結合されたデータセット df = dataset['frame'] print(df) #確認
以下、実行結果です。
Manufacturer Model Sales_in_thousands __year_resale_value \
0 Acura Integra 16.919 16.360
1 Acura TL 39.384 19.875
2 Acura CL 14.114 18.225
3 Acura RL 8.588 29.725
4 Audi A4 20.397 22.255
.. ... ... ... ...
152 Volvo V40 3.545 NaN
153 Volvo S70 15.245 NaN
154 Volvo V70 17.531 NaN
155 Volvo C70 3.493 NaN
156 Volvo S80 18.969 NaN
Vehicle_type Price_in_thousands Engine_size Horsepower Wheelbase \
0 Passenger 21.50 1.8 140.0 101.2
1 Passenger 28.40 3.2 225.0 108.1
2 Passenger NaN 3.2 225.0 106.9
3 Passenger 42.00 3.5 210.0 114.6
4 Passenger 23.99 1.8 150.0 102.6
.. ... ... ... ... ...
152 Passenger 24.40 1.9 160.0 100.5
153 Passenger 27.50 2.4 168.0 104.9
154 Passenger 28.80 2.4 168.0 104.9
155 Passenger 45.50 2.3 236.0 104.9
156 Passenger 36.00 2.9 201.0 109.9
Width Length Curb_weight Fuel_capacity Fuel_efficiency Latest_Launch \
0 67.3 172.4 2.639 13.2 28.0 2/2/2012
1 70.3 192.9 3.517 17.2 25.0 6/3/2011
2 70.6 192.0 3.470 17.2 26.0 1/4/2012
3 71.4 196.6 3.850 18.0 22.0 3/10/2011
4 68.2 178.0 2.998 16.4 27.0 10/8/2011
.. ... ... ... ... ... ...
152 67.6 176.6 3.042 15.8 25.0 9/21/2011
153 69.3 185.9 3.208 17.9 25.0 11/24/2012
154 69.3 186.2 3.259 17.9 25.0 6/25/2011
155 71.5 185.7 3.601 18.5 23.0 4/26/2011
156 72.1 189.8 3.600 21.1 24.0 11/14/2011
Power_perf_factor
0 58.280150
1 91.370778
2 NaN
3 91.389779
4 62.777639
.. ...
152 66.498812
153 70.654495
154 71.155978
155 101.623357
156 85.735655
[157 rows x 16 columns]
目的変数が設定されていないため、説明変数Xのみのデータセットの場合と、同じものが出力されます。
このように、OpenMLには目的変数の設定がなされていないものも、多々あります。
openmlで読み込む
ここまでは、Scikit-learnでOpenMLのデータセットを読み込んできました。
ここからは、OpenMLを読み込むためのライブラリーであるopenmlを使い、データセットを読み込んでみます。
ちなみに、openmlはデータセットだけでなく、OpenMLに公開されているタスクなども読み込めます。
準備
まだopenmlをインストールしていない方は、インストールしておいてください。
condaでインストールするときは以下です。
conda install -c conda-forge openml
pipでインストールするときは以下です。
pip install openml
インストールが終了、もしくはすでにしているならば、OpenMLのデータセットを読み込むために、openmlを読み込みます。
以下、コードです。
import openml
アヤメのデータ(iris)
データセットの読み込み
アヤメのデータ(iris)を読み込みます。
以下、コードです。
# データセットの読み込み dataset = openml.datasets.get_dataset(dataset_id=61)
アヤメのデータ(iris)のIDは「61」のため「dataset_id=61」としています。
先ず、datasetに格納されたデータセット(説明変数Xと目的変数y)の変数名を確認してみます。
説明変数Xです。
以下、コードです。
# データセットの変数名 dataset.features
以下、実行結果です。
{0: [0 - sepallength (numeric)],
1: [1 - sepalwidth (numeric)],
2: [2 - petallength (numeric)],
3: [3 - petalwidth (numeric)],
4: [4 - class (nominal)]}
目的変数yです。
以下、コードです。
# 目的変数yの変数名 dataset.default_target_attribute
以下、実行結果です。
'class'
次に、datasetから次の2タイプのデータセットを抜き出してみます。
- 説明変数Xと目的変数yを別々に取得
- 説明変数Xと目的変数yが結合されたデータセットを取得
説明変数Xと目的変数yを別々に取得
説明変数Xと目的変数yを別々に取得します。
ちなみに、目的変数を設定するターゲット(target)を、「target=dataset.default_target_attribute」のように、datasetの目的変数をそのまま設定しています。
ターゲット(target)に何も設定しないと、目的変数yは空になり、すべての変数が説明変数Xに格納されます。
以下、コードです。
# 説明変数Xと目的変数yを別々に取得
X, y, categorical_indicator, attribute_names = dataset.get_data(
target=dataset.default_target_attribute)
- X:説明変数のデータセット
- y:目的変数のデータセット
- categorical_indicator:Xの各変数がカテゴリカル変数かどうか(True or False)
- attribute_names:Xの各変数の名称
それぞれ見てみます。
Xの各変数の名称です。
以下、コードです。
# Xの各変数の名称 attribute_names
以下、実行結果です。
['sepallength', 'sepalwidth', 'petallength', 'petalwidth']
Xの各変数がカテゴリカル変数かどうかです。
以下、コードです。
# Xの各変数がカテゴリカル変数かどうか categorical_indicator
以下、実行結果です。
[False, False, False, False]
Xです。
以下、コードです。
# Xの確認 print(X)
以下、実行結果です。
sepallength sepalwidth petallength petalwidth 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 3 4.6 3.1 1.5 0.2 4 5.0 3.6 1.4 0.2 .. ... ... ... ... 145 6.7 3.0 5.2 2.3 146 6.3 2.5 5.0 1.9 147 6.5 3.0 5.2 2.0 148 6.2 3.4 5.4 2.3 149 5.9 3.0 5.1 1.8 [150 rows x 4 columns]
yです。
以下、コードです。
# yの確認 print(y)
以下、実行結果です。
0 Iris-setosa
1 Iris-setosa
2 Iris-setosa
3 Iris-setosa
4 Iris-setosa
...
145 Iris-virginica
146 Iris-virginica
147 Iris-virginica
148 Iris-virginica
149 Iris-virginica
Name: class, Length: 150, dtype: category
Categories (3, object): ['Iris-setosa' < 'Iris-versicolor' < 'Iris-virginica']
説明変数Xと目的変数yが結合されたデータセットを取得
説明変数Xと目的変数yが結合されたデータセットを取得します。
目的変数を設定するターゲット(target)に何も設定しないと、目的変数yは空になり、すべての変数が説明変数Xに格納されます。
以下、コードです。
# 説明変数Xと目的変数yが結合されたデータセットを取得 X, y, categorical_indicator, attribute_names = dataset.get_data()
- X:説明変数のデータセット
- y:目的変数のデータセット ※今回は空
- categorical_indicator:Xの各変数がカテゴリカル変数かどうか(True or False)
- attribute_names:Xの各変数の名称
それぞれ見てみます。
Xの各変数の名称です。
以下、コードです。
# Xの各変数の名称 attribute_names
以下、実行結果です。
['sepallength', 'sepalwidth', 'petallength', 'petalwidth', 'class']
Xの各変数がカテゴリカル変数かどうかです。
以下、コードです。
# Xの各変数がカテゴリカル変数かどうか categorical_indicator
以下、実行結果です。
[False, False, False, False, True]
Xです。
以下、コードです。
# Xの確認 print(X)
以下、実行結果です。
sepallength sepalwidth petallength petalwidth class 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa .. ... ... ... ... ... 145 6.7 3.0 5.2 2.3 Iris-virginica 146 6.3 2.5 5.0 1.9 Iris-virginica 147 6.5 3.0 5.2 2.0 Iris-virginica 148 6.2 3.4 5.4 2.3 Iris-virginica 149 5.9 3.0 5.1 1.8 Iris-virginica [150 rows x 5 columns]
yです。
以下、コードです。
# yの確認 print(y)
以下、実行結果です。
None
車の販売データ(Car-sales)
データセットの読み込み
車の販売データ(Car-sales)を読み込みます。
以下、コードです。
# データセットの読み込み dataset = openml.datasets.get_dataset(dataset_id=43619)
車の販売データ(Car-sales)のIDは「43619」のため「dataset_id=43619」としています。
先ず、datasetに格納されたデータセットの変数名を確認してみます。
ただ、車の販売データ(Car-sales)には目的変数が設定されていないため、説明変数Xのみ確認します。
以下、コードです。
# データセットの変数名 dataset.features
以下、実行結果です。
{0: [0 - Manufacturer (string)],
1: [1 - Model (string)],
2: [2 - Sales_in_thousands (numeric)],
3: [3 - __year_resale_value (numeric)],
4: [4 - Vehicle_type (string)],
5: [5 - Price_in_thousands (numeric)],
6: [6 - Engine_size (numeric)],
7: [7 - Horsepower (numeric)],
8: [8 - Wheelbase (numeric)],
9: [9 - Width (numeric)],
10: [10 - Length (numeric)],
11: [11 - Curb_weight (numeric)],
12: [12 - Fuel_capacity (numeric)],
13: [13 - Fuel_efficiency (numeric)],
14: [14 - Latest_Launch (string)],
15: [15 - Power_perf_factor (numeric)]}
データセットの取得
データセットを取得します。
目的変数が無いので、ターゲット(target)に何も設定しません。そのため目的変数yは空になり、すべての変数が説明変数Xに格納されます。
以下、コードです。
# データセットの取得 X, y, categorical_indicator, attribute_names = dataset.get_data()
- X:説明変数のデータセット
- y:目的変数のデータセット ※今回は空
- categorical_indicator:Xの各変数がカテゴリカル変数かどうか(True or False)
- attribute_names:Xの各変数の名称
それぞれ見てみます。
Xの各変数の名称です。
以下、コードです。
# Xの各変数の名称 attribute_names
以下、実行結果です。
['Manufacturer', 'Model', 'Sales_in_thousands', '__year_resale_value', 'Vehicle_type', 'Price_in_thousands', 'Engine_size', 'Horsepower', 'Wheelbase', 'Width', 'Length', 'Curb_weight', 'Fuel_capacity', 'Fuel_efficiency', 'Latest_Launch', 'Power_perf_factor']
Xの各変数がカテゴリカル変数かどうかです。
以下、コードです。
# Xの各変数がカテゴリカル変数かどうか categorical_indicator
以下、実行結果です。
[False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False]
Xです。
以下、コードです。
# Xの確認 print(X)
以下、実行結果です。
Manufacturer Model Sales_in_thousands __year_resale_value \
0 Acura Integra 16.919 16.360
1 Acura TL 39.384 19.875
2 Acura CL 14.114 18.225
3 Acura RL 8.588 29.725
4 Audi A4 20.397 22.255
.. ... ... ... ...
152 Volvo V40 3.545 NaN
153 Volvo S70 15.245 NaN
154 Volvo V70 17.531 NaN
155 Volvo C70 3.493 NaN
156 Volvo S80 18.969 NaN
Vehicle_type Price_in_thousands Engine_size Horsepower Wheelbase \
0 Passenger 21.50 1.8 140.0 101.2
1 Passenger 28.40 3.2 225.0 108.1
2 Passenger NaN 3.2 225.0 106.9
3 Passenger 42.00 3.5 210.0 114.6
4 Passenger 23.99 1.8 150.0 102.6
.. ... ... ... ... ...
152 Passenger 24.40 1.9 160.0 100.5
153 Passenger 27.50 2.4 168.0 104.9
154 Passenger 28.80 2.4 168.0 104.9
155 Passenger 45.50 2.3 236.0 104.9
156 Passenger 36.00 2.9 201.0 109.9
Width Length Curb_weight Fuel_capacity Fuel_efficiency Latest_Launch \
0 67.3 172.4 2.639 13.2 28.0 2/2/2012
1 70.3 192.9 3.517 17.2 25.0 6/3/2011
2 70.6 192.0 3.470 17.2 26.0 1/4/2012
3 71.4 196.6 3.850 18.0 22.0 3/10/2011
4 68.2 178.0 2.998 16.4 27.0 10/8/2011
.. ... ... ... ... ... ...
152 67.6 176.6 3.042 15.8 25.0 9/21/2011
153 69.3 185.9 3.208 17.9 25.0 11/24/2012
154 69.3 186.2 3.259 17.9 25.0 6/25/2011
155 71.5 185.7 3.601 18.5 23.0 4/26/2011
156 72.1 189.8 3.600 21.1 24.0 11/14/2011
Power_perf_factor
0 58.280150
1 91.370778
2 NaN
3 91.389779
4 62.777639
.. ...
152 66.498812
153 70.654495
154 71.155978
155 101.623357
156 85.735655
[157 rows x 16 columns]
まとめ
今回は、「OpenMLのサンプルデータをPython上で取得し利用する方法」というお話しをしました。
何かいいサンプルデータはないかな、と思ったらOpenMLの中から探してみてはいかがでしょうか。