
![[Python] StatsForecast による らくらく時系列予測](https://www.salesanalytics.co.jp/wp-content/uploads/2023/04/e7ea69c719ea8c9064c4ea612ea149c0.png)
ビジネスの世界の多くのデータは、時間的概念の紐づいた時系列データです。売上データやセンサーデータなどが、その典型例です。
時系列データの1つの用途として、予測というものがあります。
時系列系の予測モデルを構築できるPythonパッケージは色々あります。
その中でStatsForecastは、色々な統計学的な時系列系の予測モデルを構築することのできる、Pythonの時系列予測パッケージです。
色々な時系列予測モデルを構築し、一番予測精度のいい予測モデルを探すのに最適です。
さらに、複数の時系列予測モデルを組み合わせ構築する、時系列アンサンブル学習に最適です。
さらに、Pythonコードを高速化するnumbaというライブラリを使うことで、他のPythonの時系列系パッケージよりも高速で学習することを実現しています(たぶん)。
今回は、初歩の初歩ということで、StatsForecastの使い方を説明します。
Contents [hide]
StatsForecastとは
StatsForecastは、numbaを使用して高性能に最適化されたARIMAやETS、CES、Thetaなどの統計学系の1変量時系列予測モデルを構築できる、便利なPythonパッケージです。
例えば、次のような時系列予測モデルが含まれています(2023年4月15日現在)。
- ARIMAモデル
- AR
- ARMA
- ARIMA
- SARIMA
- SARIMAX など
- 指数平滑化モデル
- SimpleExponentialSmoothing
- SimpleExponentialSmoothingOptimized
- SeasonalExponentialSmoothing
- SeasonalExponentialSmoothingOptimized
- Holt
- HoltWinters など
- ベンチマークモデル
- HistoricAverage
- Naive
- RandomWalkWithDrift
- SeasonalNaive
- WindowAverage
- SeasonalWindowAverage など
- スパースモデル
- ADIDA
- CrostonClassic
- CrostonOptimized
- CrostonSBA
- IMAPA
- TSB など
- シータモデル
- Theta
- OptimizedTheta
- DynamicTheta
- DynamicOptimizedTheta など
- GARCHモデル
- GARCH
- ARCH など
さらに、ハイパーパラメータ調整を自動で実施する、以下の自動予測モデル構築機能があります(2023年4月15日現在)。
- AutoARIMA
- AutoETS
- AutoCES
- AutoTheta
このライブラリーを上手く使いこなすことで、統計学系の時系列予測モデルの多くを試すことができます。
一方、機械学習よりの時系列予測モデルは含まれていません。
パッケージのインストール
先ず、StatsForecastをインストールしていない方は、インストールして頂ければと思います。
以下、condaでインストールするときのコードです。
conda install -c conda-forge statsforecast
以下、pipでインストールするときのコードです。
pip install statsforecast
データ構造
StatsForecastで利用するデータセットに最低限必要な変数は以下です。
- unique_id:インデックス変数
- ds:日付(もしくは数値)変数
- y:1変量時系列データの変数(目的変数)
インデックス変数は、同じ1変量の時系列データ(目的変数)のとき、ある一定の数値にします。例えば、1です。
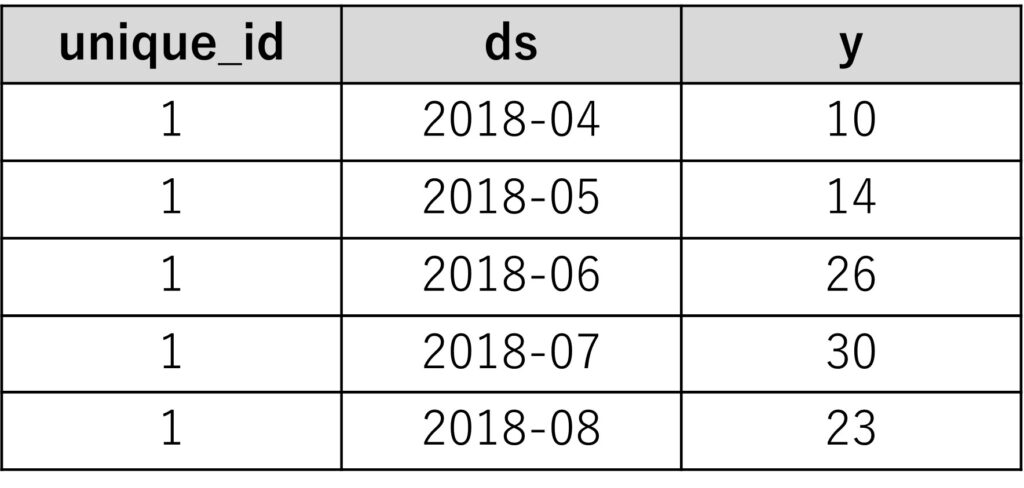
時系列データ(目的変数)が複数のとき、1つ目の1変量の時系列データ(目的変数)のインデックス変数の値を1に、2つ目の1変量の時系列データ(目的変数)のインデックス変数の値を2に、……といったように設定します。
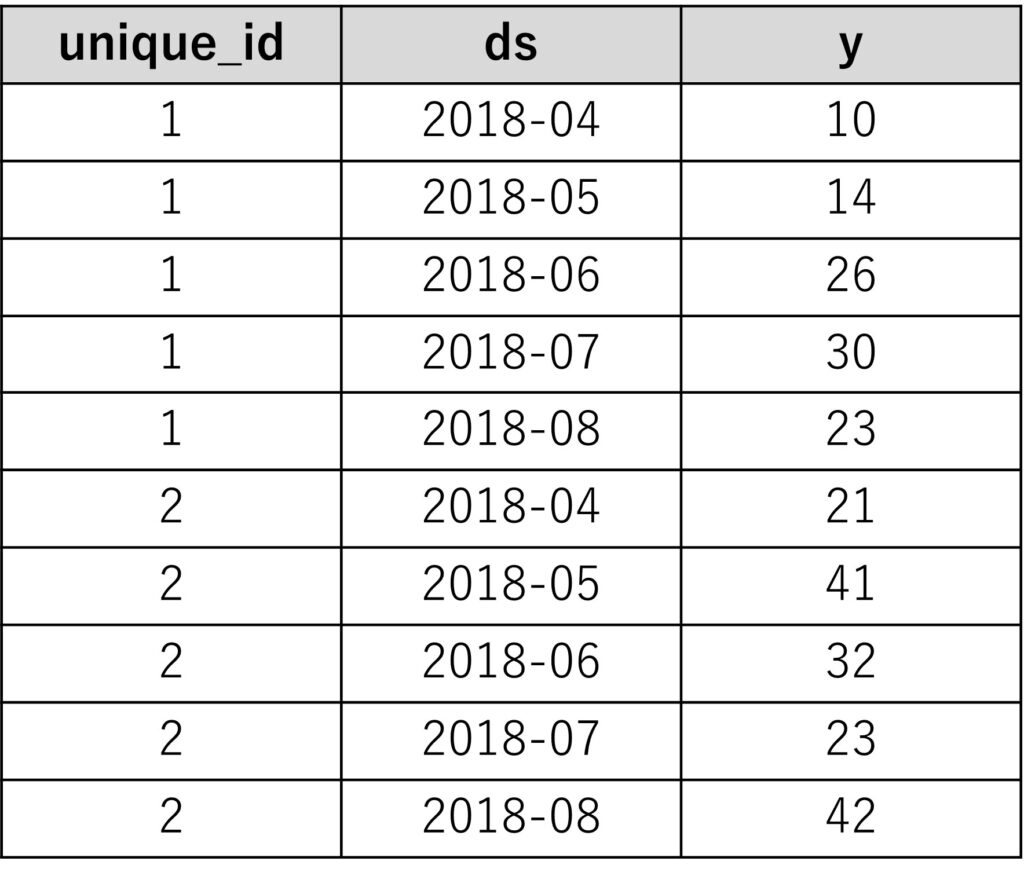
要は、目的変数yに相当する複数の時系列データ(目的変数)があるとき、横に付け加えるのではなく、縦に付け加えます。
今回利用するデータ
次の2つのデータセットを利用します。
- AirPassengers(飛行機乗客数)
- WineSales(ワイン販売数)
AirPassengers(飛行機乗客数)は、Box&Jenkinsの有名なデータで、1949年から1960年までの国際線航空旅客数の月次集計結果です。
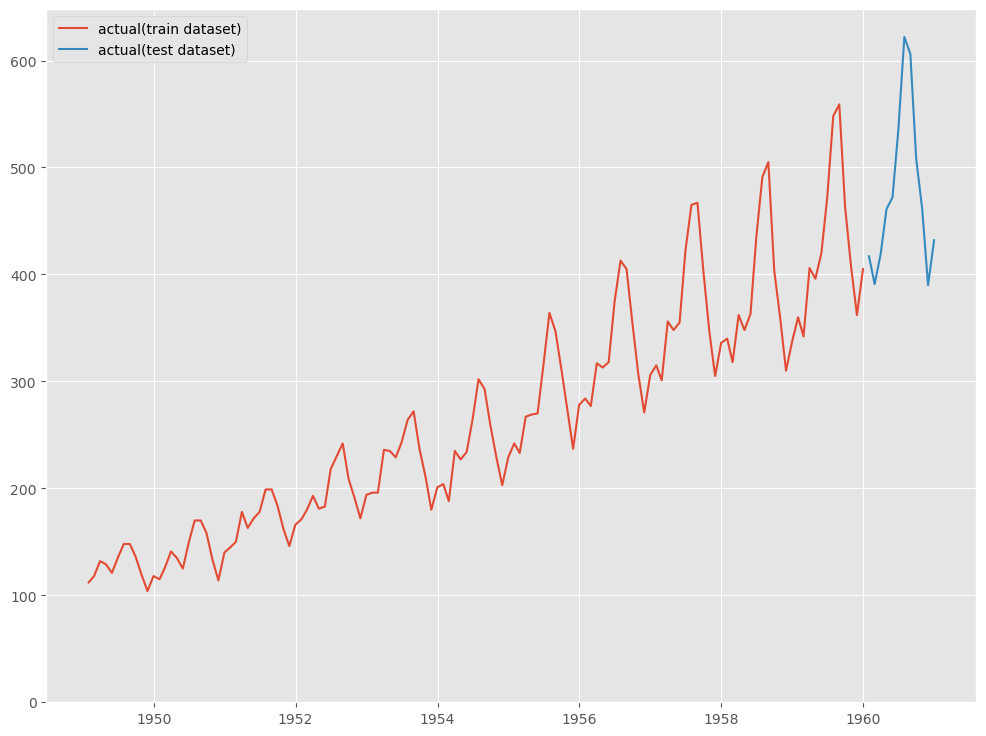
StatsForecastが、サンプルデータとして提供しているため、それをそのまま使います。
WineSales(ワイン販売数)は、R forecast パッケージに含まれている1980年1月~1994年8月までのワイン販売数の月次集計結果です。
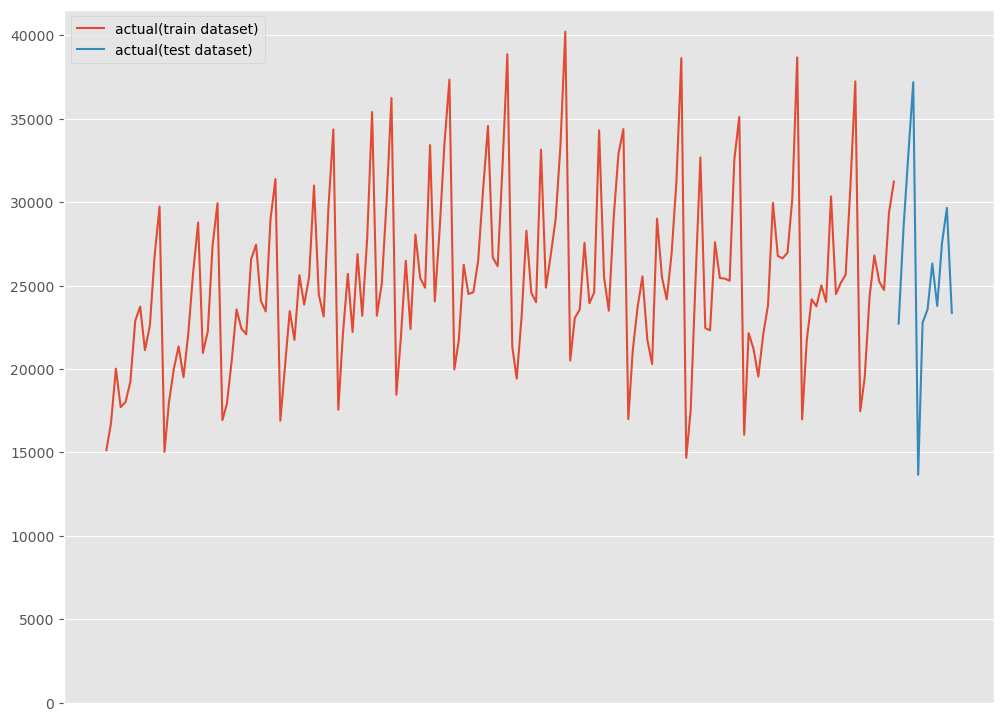
Rで提供されているサンプルデータは、statsmodelsのモジュールを使うことでPythonに読み込むことができます。詳細は以下の記事を参考にしてください。
今回構築するモデル
データセットごとに、次の6つの時系列予測モデルを構築します。
- AutoARIMA
- HoltWinters
- SeasonalNaive
- AutoTheta
- DynamicOptimizedTheta
- AutoETS
作り方は、次の2パターンです。
- ARIMAモデルをAutoARIMAで学習しテストする
- 複数モデル(6つ)を一気に学習しテストする
予測精度の評価指標
今回利用する予測精度の評価指標は、RMSE(二乗平均平方根誤差、Root Mean Squared Error)とMAE(平均絶対誤差、Mean Absolute Error)、MAPE(平均絶対パーセント誤差、Mean absolute percentage error)の3つです。
以下の記号を使い精度指標の説明をします。
■ 二乗平均平方根誤差(RMSE、Root Mean Squared Error)
■ 平均絶対誤差(MAE、Mean Absolute Error)
■ 平均絶対パーセント誤差(MAPE、Mean absolute percentage error)
必要なモジュールの読み込み
先ず、利用するモジュールを読み込みます。
以下、コードです。
#
# 必要なモジュールの読み込み
#
import pandas as pd
import numpy as np
import statsmodels.api as sm
from statsforecast import StatsForecast
from statsforecast.models import (
AutoARIMA,
HoltWinters,
AutoTheta,
AutoETS,
DynamicOptimizedTheta as DOT,
SeasonalNaive
)
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_percentage_error
import matplotlib.pyplot as plt
plt.style.use('ggplot') #グラフのスタイル
plt.rcParams['figure.figsize'] = [12, 9] # グラフサイズ設定
では、データセットごとに実施していきます。
AirPassengers(飛行機乗客数)
データの読み込み
データセットを読み込みます。
以下、コードです。
# # データの読み込み # from statsforecast.utils import AirPassengersDF df = AirPassengersDF print(df) #確認
以下、実行結果です。
unique_id ds y 0 1.0 1949-01-31 112.0 1 1.0 1949-02-28 118.0 2 1.0 1949-03-31 132.0 3 1.0 1949-04-30 129.0 4 1.0 1949-05-31 121.0 .. ... ... ... 139 1.0 1960-08-31 606.0 140 1.0 1960-09-30 508.0 141 1.0 1960-10-31 461.0 142 1.0 1960-11-30 390.0 143 1.0 1960-12-31 432.0 [144 rows x 3 columns]
学習データとテストデータ(直近12カ月間)へ分割します。
以下、コードです。
# # 学習データとテストデータ(直近12ヶ月間)へ分割 # # 学習データ df_train = df[:-12] # テストデータ df_test = df[-12:]
学習データを確認してみます。
以下、コードです。
# 学習データの確認 print(df_train)
以下、実行結果です。
unique_id ds y 0 1.0 1949-01-31 112.0 1 1.0 1949-02-28 118.0 2 1.0 1949-03-31 132.0 3 1.0 1949-04-30 129.0 4 1.0 1949-05-31 121.0 .. ... ... ... 127 1.0 1959-08-31 559.0 128 1.0 1959-09-30 463.0 129 1.0 1959-10-31 407.0 130 1.0 1959-11-30 362.0 131 1.0 1959-12-31 405.0 [132 rows x 3 columns]
テストデータを確認してみます。
以下、コードです。
# テストデータの確認 print(df_test)
以下、実行結果です。
unique_id ds y 132 1.0 1960-01-31 417.0 133 1.0 1960-02-29 391.0 134 1.0 1960-03-31 419.0 135 1.0 1960-04-30 461.0 136 1.0 1960-05-31 472.0 137 1.0 1960-06-30 535.0 138 1.0 1960-07-31 622.0 139 1.0 1960-08-31 606.0 140 1.0 1960-09-30 508.0 141 1.0 1960-10-31 461.0 142 1.0 1960-11-30 390.0 143 1.0 1960-12-31 432.0
グラフ化し確認してみます。
以下、コードです。
# グラフ化 fig, ax = plt.subplots() ax.plot(df_train.ds, df_train.y, label="actual(train dataset)") ax.plot(df_test.ds, df_test.y, label="actual(test dataset)") ax.set_ylim(ymin=0) ax.legend() plt.show()
以下、実行結果です。
ARIMAモデル(AutoARIMA)
AutoARIMAでARIMAモデルを自動構築します。
以下、コードです。
#
# ARIMAモデルの自動構築(AutoARIMA)
#
# インスタンス生成
sf = StatsForecast(
models = [AutoARIMA(season_length = 12)],
freq = 'M',
n_jobs=-1,
)
# 学習(学習データ)
sf.fit(df_train)
予測を実施します。
ちなみに、学習データ期間を予測するときは、テストデータ期間を予測するメソッド「forecast」の引数「fitted」を「fitted=True」とする必要があります。
以下、コードです。
# # 予測の実施 # # テストデータ期間 test_pred = sf.forecast(len(df_test),fitted=True) # 学習データ期間 train_pred = sf.forecast_fitted_values()
テストデータ期間の予測結果を確認します。
以下、コードです。
# テストデータの予測結果の確認 print(test_pred)
以下、実行結果です。
ds AutoARIMA unique_id 1.0 1960-01-31 424.160156 1.0 1960-02-29 407.081696 1.0 1960-03-31 470.860535 1.0 1960-04-30 460.913605 1.0 1960-05-31 484.900879 1.0 1960-06-30 536.903931 1.0 1960-07-31 612.903198 1.0 1960-08-31 623.903381 1.0 1960-09-30 527.903320 1.0 1960-10-31 471.903320 1.0 1960-11-30 426.903320 1.0 1960-12-31 469.903320
学習データ期間の予測結果を確認します。
以下、コードです。
# 学習データの予測結果の確認 print(train_pred)
以下、実行結果です。
ds y AutoARIMA unique_id 1.0 1949-01-31 112.0 111.935333 1.0 1949-02-28 118.0 117.966431 1.0 1949-03-31 132.0 131.966187 1.0 1949-04-30 129.0 128.977448 1.0 1949-05-31 121.0 120.989243 ... ... ... ... 1.0 1959-08-31 559.0 557.200195 1.0 1959-09-30 463.0 458.719971 1.0 1959-10-31 407.0 416.800049 1.0 1959-11-30 362.0 360.639893 1.0 1959-12-31 405.0 388.040039 [132 rows x 3 columns]
テストデータ期間の予測精度を見てみます。
以下、コードです。
#
# 精度指標(テストデータ)
#
print('RMSE:')
print(np.sqrt(mean_squared_error(df_test.y, test_pred.AutoARIMA)))
print('MAE:')
print(mean_absolute_error(df_test.y, test_pred.AutoARIMA))
print('MAPE:')
print(mean_absolute_percentage_error(df_test.y, test_pred.AutoARIMA))
以下、実行結果です。
RMSE: 23.955328353374384 MAE: 18.550587972005207 MAPE: 0.04187615687144095
グラフ化し見てみます。
以下、コードです。
# # グラフ化 # fig, ax = plt.subplots() ax.plot(df_train.ds, df_train.y, label="actual(train dataset)") ax.plot(df_test.ds, df_test.y, label="actual(test dataset)") ax.plot(df_train.ds, train_pred.AutoARIMA, linestyle="dotted", lw=2,color="m") ax.plot(df_test.ds, test_pred.AutoARIMA, label="AutoARIMA", linestyle="dotted", lw=2, color="m") ax.set_ylim(ymin=0) ax.legend() plt.show()
以下、実行結果です。
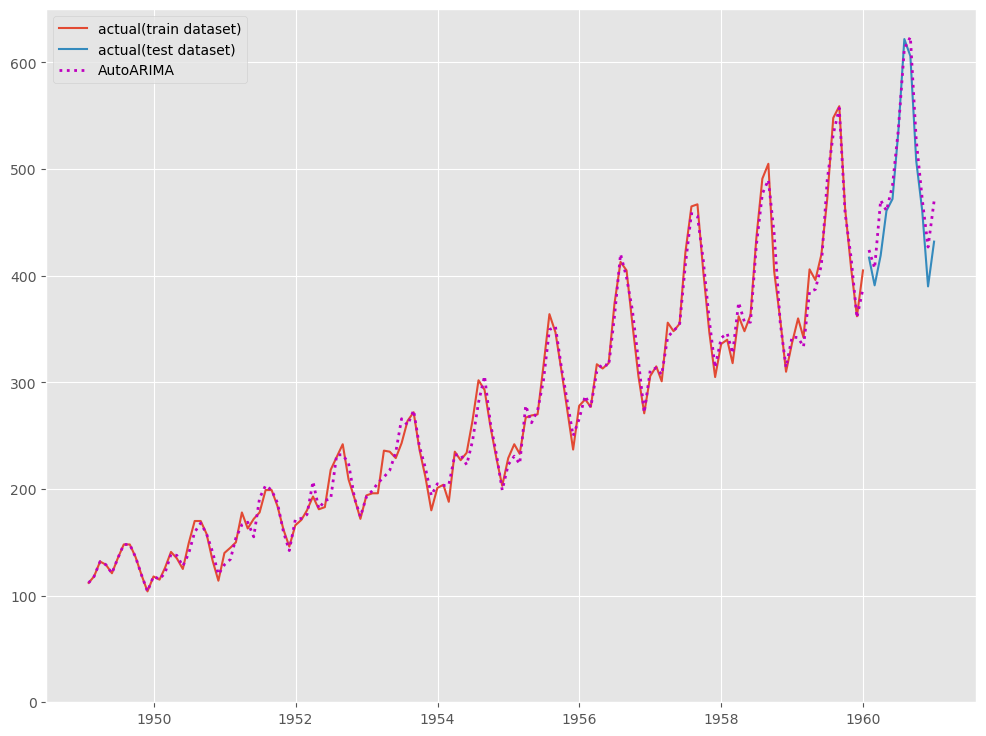
テストデータ期間のみ見てみます。
以下、コードです。
# # グラフ化 # fig, ax = plt.subplots() ax.plot(df_test.ds, df_test.y, label="actual(test dataset)") ax.plot(df_test.ds, test_pred.AutoARIMA, label="AutoARIMA", linestyle="dotted", lw=2, color="m") ax.set_ylim(ymin=0) ax.legend() plt.show()
以下、実行結果です。
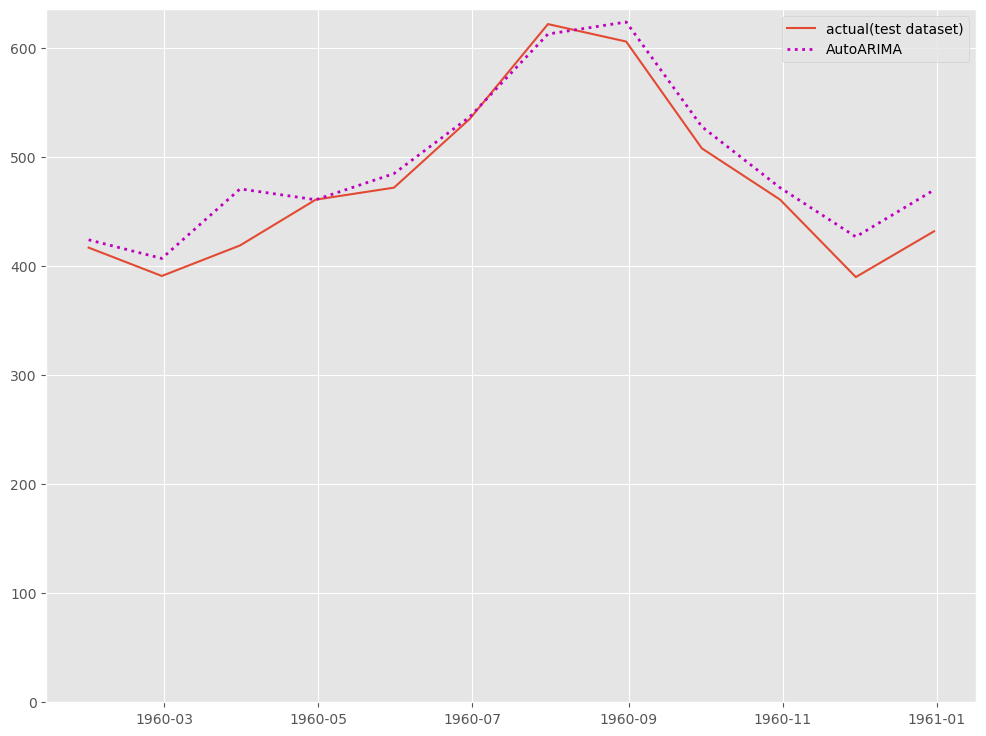
複数モデルの構築
6つの予測モデルを一気に構築していきます。
先ず、構築する予測モデルのアルゴリズムのリスト(モデルリスト)を作成します。
以下、コードです。
#
# モデルリストの作成
#
PERIOD = 12
models = [
AutoARIMA(season_length=PERIOD),
HoltWinters(season_length=PERIOD),
SeasonalNaive(season_length=PERIOD),
AutoTheta(season_length=PERIOD),
DOT(season_length=PERIOD),
AutoETS(season_length=PERIOD),
]
学習します。
以下、コードです。
#
# 時系列予測モデルの学習
#
# インスタンス生成
sf = StatsForecast(
models = models,
freq = 'M',
n_jobs=-1,
)
# 学習(学習データ)
sf.fit(df_train)
予測を実施します。
以下、コードです。
# # 予測の実施 # # テストデータ期間 test_pred = sf.forecast(len(df_test),fitted=True) # 学習データ期間 train_pred = sf.forecast_fitted_values()
テストデータ期間の予測結果を確認します。
以下、コードです。
# テストデータの予測結果の確認 print(test_pred)
以下、実行結果です。
ds AutoARIMA HoltWinters SeasonalNaive AutoTheta \
unique_id
1.0 1960-01-31 424.160156 409.680145 360.0 412.711884
1.0 1960-02-29 407.081696 390.044067 342.0 404.640472
1.0 1960-03-31 470.860535 448.929810 406.0 466.810883
1.0 1960-04-30 460.913605 435.445007 396.0 449.600372
1.0 1960-05-31 484.900879 454.699951 420.0 454.047760
1.0 1960-06-30 536.903931 507.904968 472.0 517.857727
1.0 1960-07-31 612.903198 577.622375 548.0 572.380127
1.0 1960-08-31 623.903381 581.996765 559.0 571.371643
1.0 1960-09-30 527.903320 479.946136 463.0 502.108032
1.0 1960-10-31 471.903320 421.522797 407.0 438.527100
1.0 1960-11-30 426.903320 373.590912 362.0 382.673859
1.0 1960-12-31 469.903320 410.594971 405.0 432.116119
DynamicOptimizedTheta AutoETS
unique_id
1.0 412.697632 406.651276
1.0 404.638550 401.732910
1.0 466.829071 456.289642
1.0 449.643433 440.870514
1.0 454.122589 440.333923
1.0 517.984802 496.866058
1.0 572.572754 545.839111
1.0 571.621704 544.672485
1.0 502.383270 477.034485
1.0 438.819733 412.423096
1.0 382.977936 357.949158
1.0 432.517731 402.032745
学習データ期間の予測結果を確認します。
以下、コードです。
# 学習データの予測結果の確認 print(train_pred)
以下、実行結果です。
ds y AutoARIMA HoltWinters SeasonalNaive \
unique_id
1.0 1949-01-31 112.0 111.935333 101.031303 NaN
1.0 1949-02-28 118.0 117.966431 121.179947 NaN
1.0 1949-03-31 132.0 131.966187 100.400383 NaN
1.0 1949-04-30 129.0 128.977448 133.717758 NaN
1.0 1949-05-31 121.0 120.989243 170.780991 NaN
... ... ... ... ... ...
1.0 1959-08-31 559.0 557.200195 534.102478 505.0
1.0 1959-09-30 463.0 458.719971 440.780396 404.0
1.0 1959-10-31 407.0 416.800049 398.959930 359.0
1.0 1959-11-30 362.0 360.639893 352.432892 310.0
1.0 1959-12-31 405.0 388.040039 383.878448 337.0
AutoTheta DynamicOptimizedTheta AutoETS
unique_id
1.0 139.609741 112.000000 117.015076
1.0 116.625908 118.412216 113.566177
1.0 137.604874 147.000076 131.018005
1.0 129.901550 130.821960 127.026939
1.0 132.176483 132.028900 127.687019
... ... ... ...
1.0 542.255676 542.561829 522.552612
1.0 488.454712 488.689178 470.984100
1.0 408.836548 408.544403 404.309082
1.0 355.613373 355.537415 351.848541
1.0 407.499939 407.586212 399.914581
[132 rows x 8 columns]
テストデータ期間の予測精度を見てみます。
以下、コードです。
#
# 精度指標(テストデータ)
#
for i in range(1,7) :
print(test_pred.columns[i])
print('\t'+'RMSE:'+'\t',
np.sqrt(mean_squared_error(df_test.y, test_pred.iloc[:,i])))
print('\t'+'MAE:'+'\t',
mean_absolute_error(df_test.y, test_pred.iloc[:,i]))
print('\t'+'MAPE:'+'\t',
mean_absolute_percentage_error(df_test.y, test_pred.iloc[:,i]))
以下、実行結果です。
AutoARIMA RMSE: 23.955328353374384 MAE: 18.550587972005207 MAPE: 0.04187615687144095 HoltWinters RMSE: 26.228497232379365 MAE: 23.490142822265625 MAPE: 0.048133214753029695 SeasonalNaive RMSE: 50.708316214732804 MAE: 47.833333333333336 MAPE: 0.09987532920823484 AutoTheta RMSE: 24.985179187610136 MAE: 19.35741424560547 MAPE: 0.03919984010285481 DynamicOptimizedTheta RMSE: 24.880112665705433 MAE: 19.263458251953125 MAPE: 0.03901936142148623 AutoETS RMSE: 40.08362053821043 MAE: 35.612475077311196 MAPE: 0.07206839292461678
グラフ化し見てみます。
以下、コードです。
# # グラフ化 # # グラフ用データ(学習データにテストデータ期間の予測結果を結合) pred = pd.concat([df_train,test_pred]).drop(['y','unique_id','ds'], axis=1) pred.index = df.ds # グラフ描写 fig, ax = plt.subplots() ax.plot(df_train.ds, df_train.y, label="actual(train dataset)") ax.plot(df_test.ds, df_test.y, label="actual(test dataset)") pred.plot(ax=ax, linestyle="dotted", lw=2) ax.set_ylim(ymin=0) ax.legend() plt.show()
以下、実行結果です。
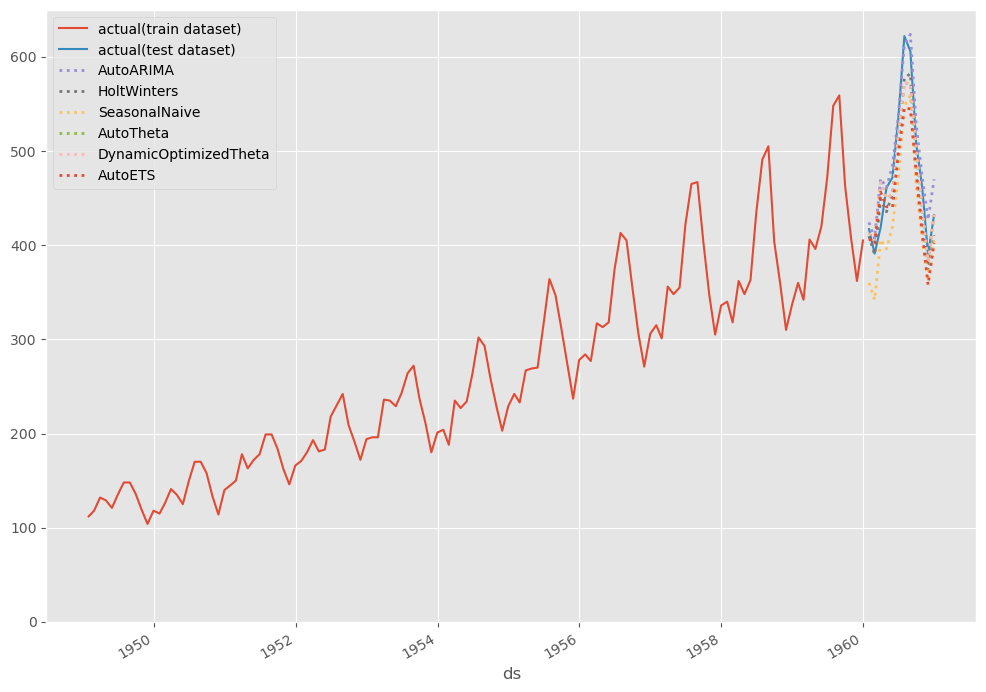
テストデータ期間のみ見てみます。
以下、コードです。
# # グラフ化 # # グラフ用データ(テストデータ期間のみ抽出) pred_test = pred[-12:] # グラフ描写 fig, ax = plt.subplots() ax.plot(df_test.ds, df_test.y, label="actual(test dataset)") pred_test.plot(ax=ax, linestyle="dotted", lw=2) ax.set_ylim(ymin=0) ax.legend() plt.show()
以下、実行結果です。
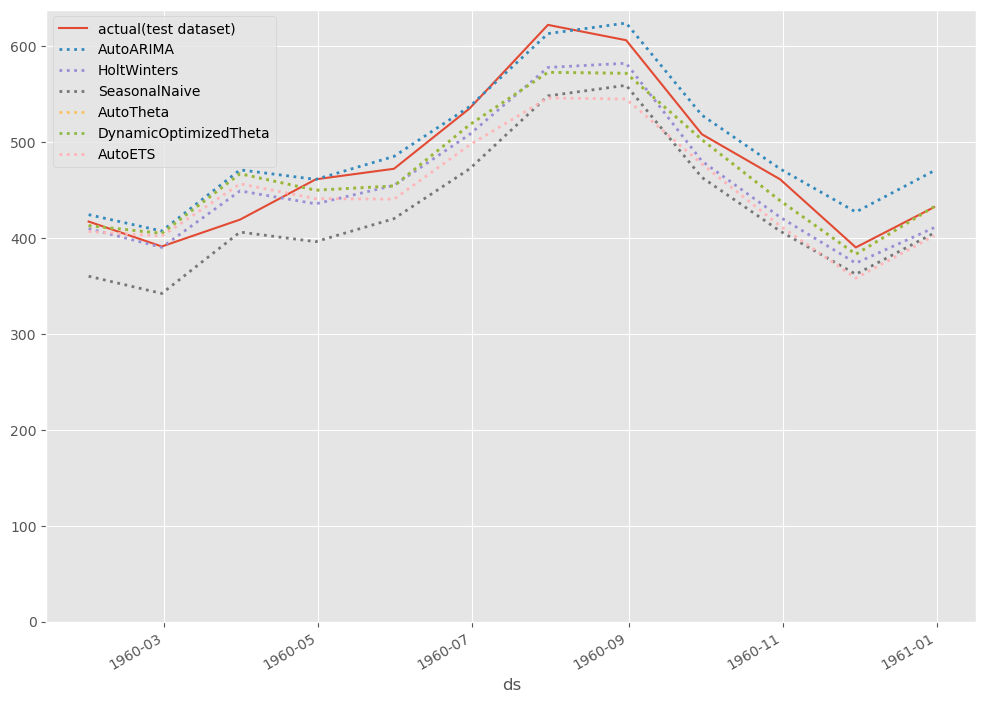
WineSales(ワイン販売数)
データの読み込み
データセットを読み込みます。
以下、コードです。
#
# データの読み込み
#
dataset = sm.datasets.get_rdataset('wineind', 'forecast')
print(dataset.data) #確認
以下、実行結果です。
time value 0 1980.000000 15136 1 1980.083333 16733 2 1980.166667 20016 3 1980.250000 17708 4 1980.333333 18019 .. ... ... 171 1994.250000 26323 172 1994.333333 23779 173 1994.416667 27549 174 1994.500000 29660 175 1994.583333 23356 [176 rows x 2 columns]
StatsForecastで扱える形式に整えます。
以下、コードです。
#
# StatsForecastで扱える形式に整える
#
df = pd.DataFrame(
{
'unique_id':1,
'ds': pd.date_range(start="1980/1/1",freq="m",periods=176),
'y': dataset.data.value,
},
)
print(df) #確認
以下、実行結果です。
unique_id ds y 0 1 1980-01-31 15136 1 1 1980-02-29 16733 2 1 1980-03-31 20016 3 1 1980-04-30 17708 4 1 1980-05-31 18019 .. ... ... ... 171 1 1994-04-30 26323 172 1 1994-05-31 23779 173 1 1994-06-30 27549 174 1 1994-07-31 29660 175 1 1994-08-31 23356 [176 rows x 3 columns]
学習データとテストデータ(直近12カ月間)へ分割します。
以下、コードです。
# # 学習データとテストデータ(直近12カ月間)へ分割 # # 学習データ df_train = df[:-12] # テストデータ df_test = df[-12:]
学習データを確認してみます。
以下、コードです。
# 学習データの確認 print(df_train)
以下、実行結果です。
unique_id ds y 0 1 1980-01-31 15136 1 1 1980-02-29 16733 2 1 1980-03-31 20016 3 1 1980-04-30 17708 4 1 1980-05-31 18019 .. ... ... ... 159 1 1993-04-30 26805 160 1 1993-05-31 25236 161 1 1993-06-30 24735 162 1 1993-07-31 29356 163 1 1993-08-31 31234 [164 rows x 3 columns]
テストデータを確認してみます。
以下、コードです。
# テストデータの確認 print(df_test)
以下、実行結果です。
unique_id ds y 164 1 1993-09-30 22724 165 1 1993-10-31 28496 166 1 1993-11-30 32857 167 1 1993-12-31 37198 168 1 1994-01-31 13652 169 1 1994-02-28 22784 170 1 1994-03-31 23565 171 1 1994-04-30 26323 172 1 1994-05-31 23779 173 1 1994-06-30 27549 174 1 1994-07-31 29660 175 1 1994-08-31 23356
グラフ化し確認してみます。
以下、コードです。
# グラフ化 fig, ax = plt.subplots() ax.plot(df_train.ds, df_train.y, label="actual(train dataset)") ax.plot(df_test.ds, df_test.y, label="actual(test dataset)") ax.axes.xaxis.set_visible(False) ax.set_ylim(ymin=0) ax.legend() plt.show()
以下、実行結果です。
ARIMAモデル(AutoARIMA)
AutoARIMAでARIMAモデルを自動構築します。
以下、コードです。
#
# ARIMAモデルの自動構築(AutoARIMA)
#
# インスタンス生成
sf = StatsForecast(
models = [AutoARIMA(season_length = 12)],
freq = 'M',
n_jobs=-1,
)
# 学習(学習データ)
sf.fit(df_train)
予測を実施します。
# # 予測の実施 # # テストデータ期間 test_pred = sf.forecast(len(df_test),fitted=True) # 学習データ期間 train_pred = sf.forecast_fitted_values()
テストデータ期間の予測結果を確認します。
以下、コードです。
# テストデータの予測結果の確認 print(test_pred)
以下、実行結果です。
ds AutoARIMA unique_id 1 1993-09-30 25720.443359 1 1993-10-31 26873.044922 1 1993-11-30 32086.277344 1 1993-12-31 37347.332031 1 1994-01-31 18447.267578 1 1994-02-28 21157.449219 1 1994-03-31 24839.212891 1 1994-04-30 26366.576172 1 1994-05-31 25126.273438 1 1994-06-30 24880.539062 1 1994-07-31 30162.029297 1 1994-08-31 30170.083984
学習データ期間の予測結果を確認します。
以下、コードです。
# 学習データの予測結果の確認 print(train_pred)
以下、実行結果です。
ds y AutoARIMA unique_id 1 1980-01-31 15136.0 15127.260742 1 1980-02-29 16733.0 16727.855469 1 1980-03-31 20016.0 20009.857422 1 1980-04-30 17708.0 17705.457031 1 1980-05-31 18019.0 18016.689453 ... ... ... ... 1 1993-04-30 26805.0 24846.925781 1 1993-05-31 25236.0 24363.072266 1 1993-06-30 24735.0 23898.470703 1 1993-07-31 29356.0 29871.386719 1 1993-08-31 31234.0 27069.568359 [164 rows x 3 columns]
テストデータ期間の予測精度を見てみます。
以下、コードです。
#
# 精度指標(テストデータ)
#
print('RMSE:')
print(np.sqrt(mean_squared_error(df_test.y, test_pred.AutoARIMA)))
print('MAE:')
print(mean_absolute_error(df_test.y, test_pred.AutoARIMA))
print('MAPE:')
print(mean_absolute_percentage_error(df_test.y, test_pred.AutoARIMA))
以下、実行結果です。
RMSE: 2815.3500207871384 MAE: 2050.9090169270835 MAPE: 0.09640424878808153
グラフ化し見てみます。
以下、コードです。
# # グラフ化 # fig, ax = plt.subplots() ax.plot(df_train.ds, df_train.y, label="actual(train dataset)") ax.plot(df_test.ds, df_test.y, label="actual(test dataset)") ax.plot(df_train.ds, train_pred.AutoARIMA, linestyle="dotted", lw=2,color="m") ax.plot(df_test.ds, test_pred.AutoARIMA, label="AutoARIMA", linestyle="dotted", lw=2, color="m") ax.axes.xaxis.set_visible(False) ax.set_ylim(ymin=0) ax.legend() plt.show()
以下、実行結果です。
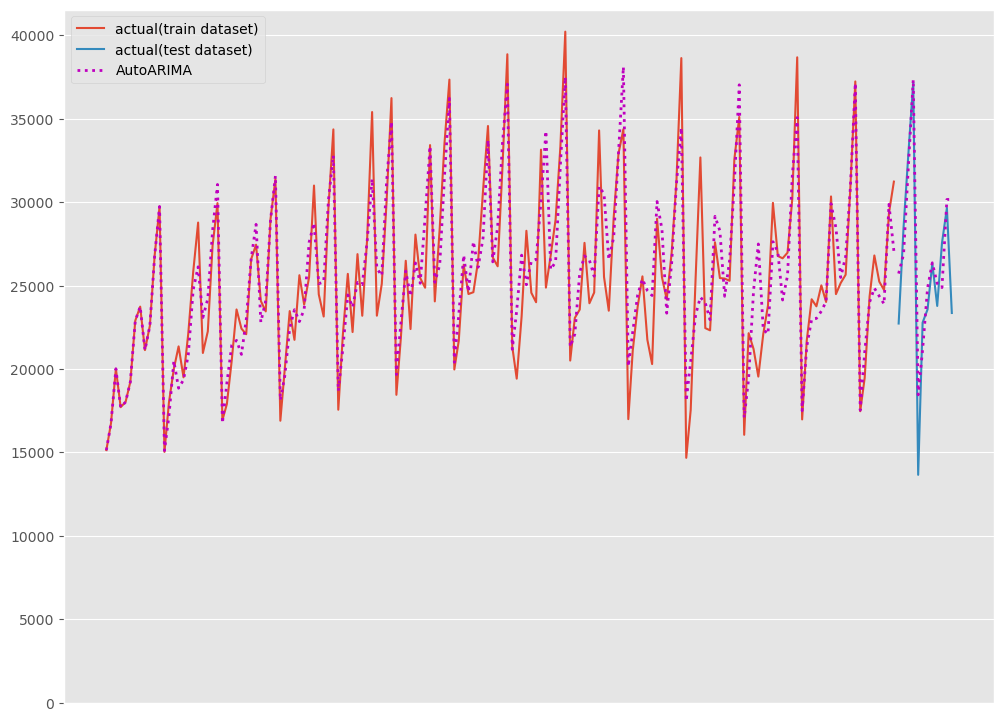
テストデータ期間のみ見てみます。
以下、コードです。
# # グラフ化 # fig, ax = plt.subplots() ax.plot(df_test.ds, df_test.y, label="actual(test dataset)") ax.plot(df_test.ds, test_pred.AutoARIMA, label="AutoARIMA", linestyle="dotted", lw=2, color="m") ax.set_ylim(ymin=0) ax.legend() plt.show()
以下、実行結果です。
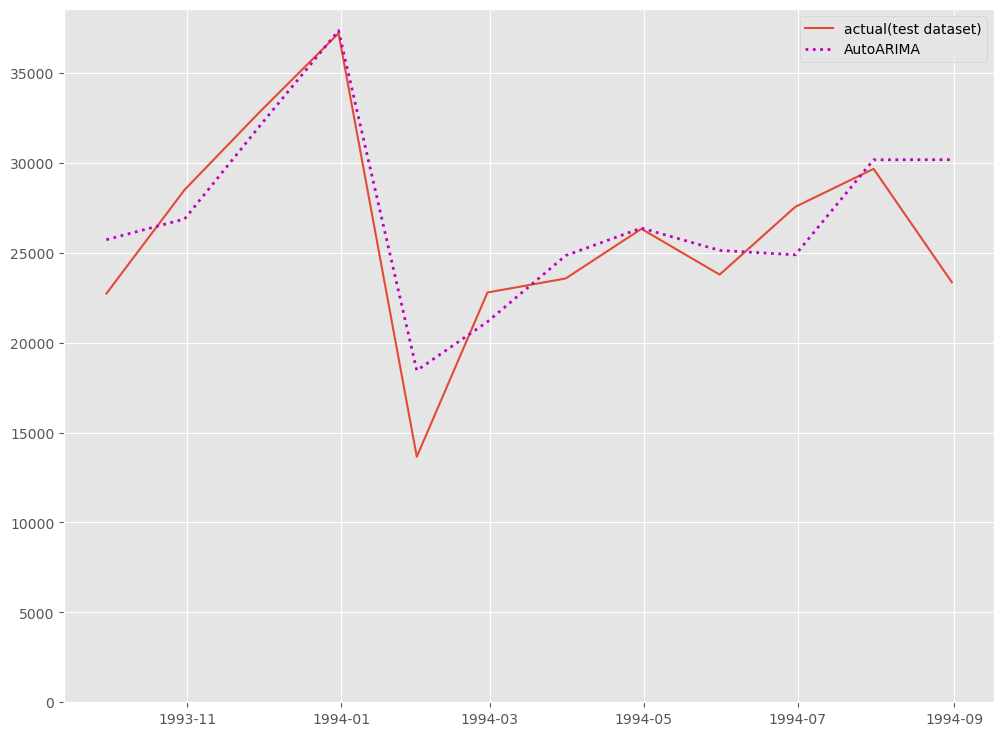
複数モデルの構築
6つの予測モデルを一気に構築していきます。
先ず、構築する予測モデルのアルゴリズムのリスト(モデルリスト)を作成します。
以下、コードです。
#
# モデルリストの作成
#
PERIOD = 12
models = [
AutoARIMA(season_length=PERIOD),
HoltWinters(season_length=PERIOD),
SeasonalNaive(season_length=PERIOD),
AutoTheta(season_length=PERIOD),
DOT(season_length=PERIOD),
AutoETS(season_length=PERIOD),
]
学習します。
以下、コードです。
#
# 時系列予測モデルの学習
#
# インスタンス生成
sf = StatsForecast(
models = models,
freq = 'M',
n_jobs=-1,
)
# 学習(学習データ)
sf.fit(df_train)
予測を実施します。
以下、コードです。
# # 予測の実施 # # テストデータ期間 test_pred = sf.forecast(len(df_test),fitted=True) # 学習データ期間 train_pred = sf.forecast_fitted_values()
テストデータ期間の予測結果を確認します。
以下、コードです。
# テストデータの予測結果の確認 print(test_pred)
以下、実行結果です。
ds AutoARIMA HoltWinters SeasonalNaive AutoTheta \
unique_id
1 1993-09-30 25720.443359 25806.755859 25156.0 25328.417969
1 1993-10-31 26873.044922 27066.654297 25650.0 26693.591797
1 1993-11-30 32086.277344 32444.990234 30923.0 31901.193359
1 1993-12-31 37347.332031 37168.160156 37240.0 36773.554688
1 1994-01-31 18447.267578 19518.896484 17466.0 18190.744141
1 1994-02-28 21157.449219 22328.550781 19463.0 21149.164062
1 1994-03-31 24839.212891 25611.074219 24352.0 24453.267578
1 1994-04-30 26366.576172 26311.923828 26805.0 25261.683594
1 1994-05-31 25126.273438 25911.855469 25236.0 24701.000000
1 1994-06-30 24880.539062 25576.244141 24735.0 24293.765625
1 1994-07-31 30162.029297 30888.460938 29356.0 29634.562500
1 1994-08-31 30170.083984 30876.755859 31234.0 29544.162109
DynamicOptimizedTheta AutoETS
unique_id
1 25353.738281 25200.136719
1 26719.343750 26651.212891
1 31930.863281 31660.291016
1 36806.496094 36425.386719
1 18206.416016 18212.419922
1 21166.671875 21052.523438
1 24472.685547 24393.921875
1 25280.900391 25375.265625
1 24718.972656 24501.708984
1 24310.640625 24180.208984
1 29654.179688 29449.763672
1 29562.757812 29938.888672
学習データ期間の予測結果を確認します。
以下、コードです。
# 学習データの予測結果の確認 print(train_pred)
以下、実行結果です。
ds y AutoARIMA HoltWinters SeasonalNaive \
unique_id
1 1980-01-31 15136.0 15127.260742 12973.968750 NaN
1 1980-02-29 16733.0 16727.855469 15914.354492 NaN
1 1980-03-31 20016.0 20009.857422 19257.726562 NaN
1 1980-04-30 17708.0 17705.457031 20022.988281 NaN
1 1980-05-31 18019.0 18016.689453 19488.566406 NaN
... ... ... ... ... ...
1 1993-04-30 26805.0 24846.925781 24965.792969 23757.0
1 1993-05-31 25236.0 24363.072266 24650.830078 25013.0
1 1993-06-30 24735.0 23898.470703 24332.656250 24019.0
1 1993-07-31 29356.0 29871.386719 29655.939453 30345.0
1 1993-08-31 31234.0 27069.568359 29610.015625 24488.0
AutoTheta DynamicOptimizedTheta AutoETS
unique_id
1 15136.000000 15136.000000 14614.176758
1 17591.060547 16819.916016 16969.451172
1 19290.421875 18583.732422 19627.498047
1 20545.875000 19840.787109 20476.300781
1 18619.939453 18108.027344 19422.121094
... ... ... ...
1 24550.865234 24536.003906 24657.693359
1 24228.806641 24232.750000 24076.099609
1 23929.789062 23940.388672 23907.376953
1 29290.353516 29308.763672 29248.238281
1 29208.222656 29224.103516 29745.482422
[164 rows x 8 columns]
テストデータ期間の予測精度を見てみます。
以下、コードです。
#
# 精度指標(テストデータ)
#
for i in range(1,7) :
print(test_pred.columns[i])
print('\t'+'RMSE:'+'\t',
np.sqrt(mean_squared_error(df_test.y, test_pred.iloc[:,i])))
print('\t'+'MAE:'+'\t',
mean_absolute_error(df_test.y, test_pred.iloc[:,i]))
print('\t'+'MAPE:'+'\t',
mean_absolute_percentage_error(df_test.y, test_pred.iloc[:,i]))
以下、実行結果です。
AutoARIMA RMSE: 2815.3500207871384 MAE: 2050.9090169270835 MAPE: 0.09640424878808153 HoltWinters RMSE: 3123.0757960277006 MAE: 2182.3562825520835 MAPE: 0.1050727559379744 SeasonalNaive RMSE: 3114.2218798066824 MAE: 2342.5833333333335 MAPE: 0.10455805468090233 AutoTheta RMSE: 2677.908377817492 MAE: 2025.0896809895833 MAPE: 0.0936110047613043 DynamicOptimizedTheta RMSE: 2680.885301527278 MAE: 2019.7062174479167 MAPE: 0.09354213357886888 AutoETS RMSE: 2771.792032215696 MAE: 2103.61865234375 MAPE: 0.09614448379415981
グラフ化し見てみます。
以下、コードです。
# # グラフ化 # # グラフ用データ(学習データにテストデータ期間の予測結果を結合) pred = pd.concat([df_train,test_pred]).drop(['y','unique_id','ds'], axis=1) pred.index = df.ds # グラフ描写 fig, ax = plt.subplots() ax.plot(df_train.ds, df_train.y, label="actual(train dataset)") ax.plot(df_test.ds, df_test.y, label="actual(test dataset)") pred.plot(ax=ax, linestyle="dotted", lw=2) ax.axes.xaxis.set_visible(False) ax.set_ylim(ymin=0) ax.legend() plt.show()
以下、実行結果です。
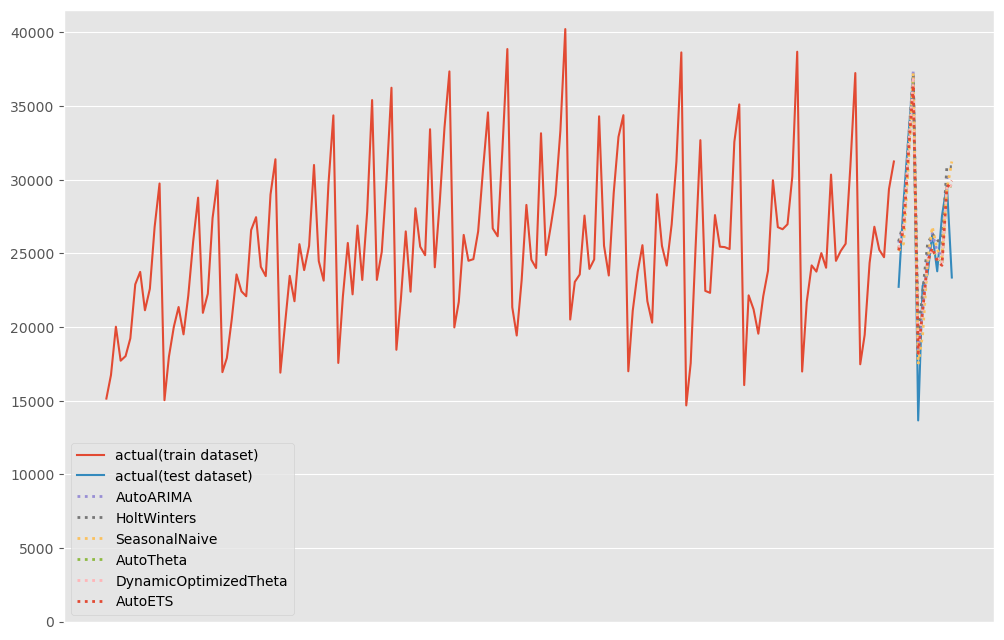
テストデータ期間のみ見てみます。
以下、コードです。
# # グラフ化 # # グラフ用データ(テストデータ期間のみ抽出) pred_test = pred[-12:] # グラフ描写 fig, ax = plt.subplots() ax.plot(df_test.ds, df_test.y, label="actual(test dataset)") pred_test.plot(ax=ax, linestyle="dotted", lw=2) ax.set_ylim(ymin=0) ax.legend() plt.show()
以下、実行結果です。
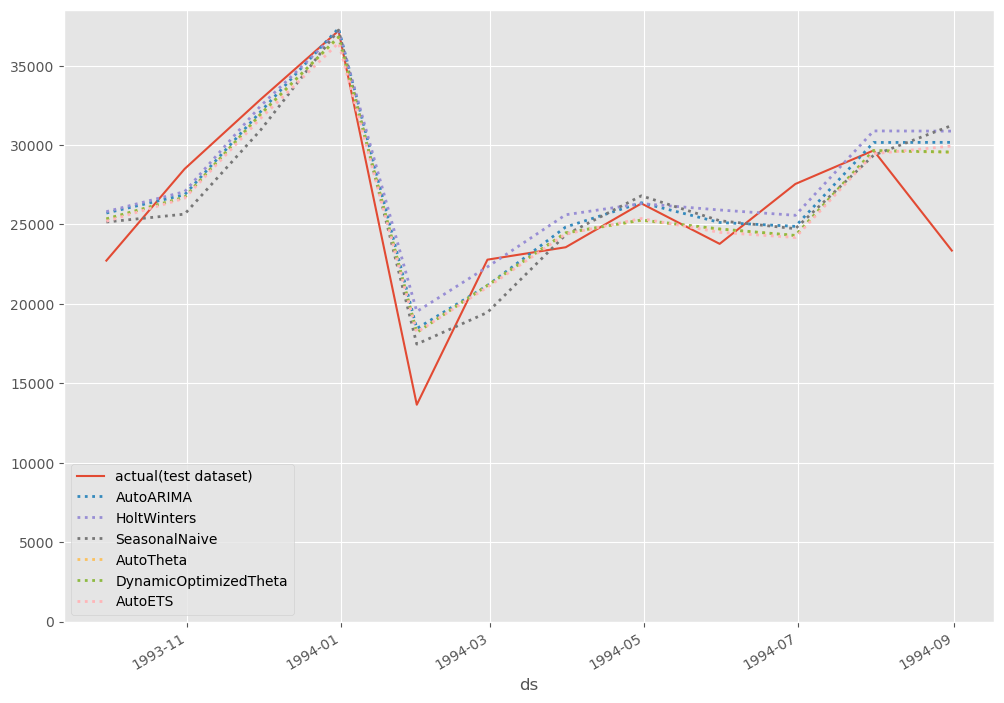
まとめ
今回は、初歩の初歩ということで、StatsForecastの使い方を説明しました。
色々な統計学系の時系列予測モデルを、さくっと作れることができます。
どのアルゴリズム(数理モデル)で予測モデルを構築すべきか悩まれたとき、試してみて頂ければと思います。