
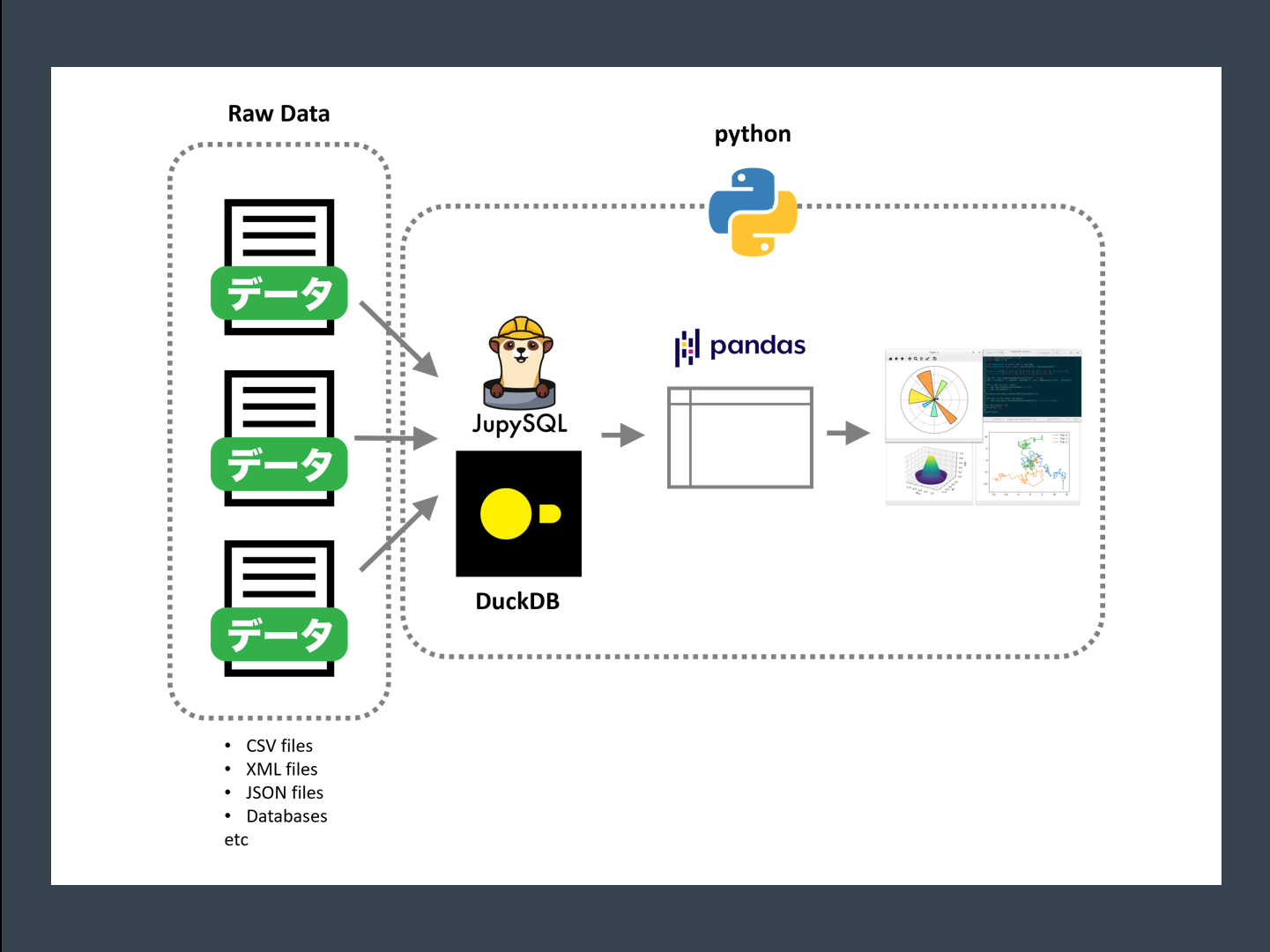
Jupyter NotebookやJupyter Labといった、Notebookでデータ分析業務をする人が、ここ数年で増えてきました。
Notebook上でデータ分析をするとき、外部のCSVファイルやDBのデータテーブルなどからデータセットを取得する必要があります。
よくあるのが、Pandasを利用し取得したデータセットをデータフレームに格納するケースです。
データ規模が大きいほど、ある問題が起こります。
例えば、メモリの消費の問題です。
データフレームに格納するということは、PCなどのメモリをそれだけ消費します。
多くの場合、読み込んだ直後のデータフレームは、そのままデータ分析に使えることは少なく、何かしらの加工なり処理がなされ整えられます。
ある程度整えられたデータセットの状態で、データフレームとして格納した方が、メモリの消費量は少なくてすみます。
他には、外部DBのパフォーマンス低下の問題もあります。
外部DBからデータセットを取得するとき、何かしらのSQLクエリを実行します。
そのクエリ実行はDBサイドで実施されるため、データベースサーバーに余計な負荷をかけることになります。
そのため、SQLクエリの実行をクライアントサイド(Jupyter Notebookサイド)で実施するのがいいでしょう。
ただ、Jupyter Notebookサイドで実施するにしても、PCのメモリを可能な限り節約したいものです。
それを可能にするのが、DuckDBとJupySQLの組み合わせです。
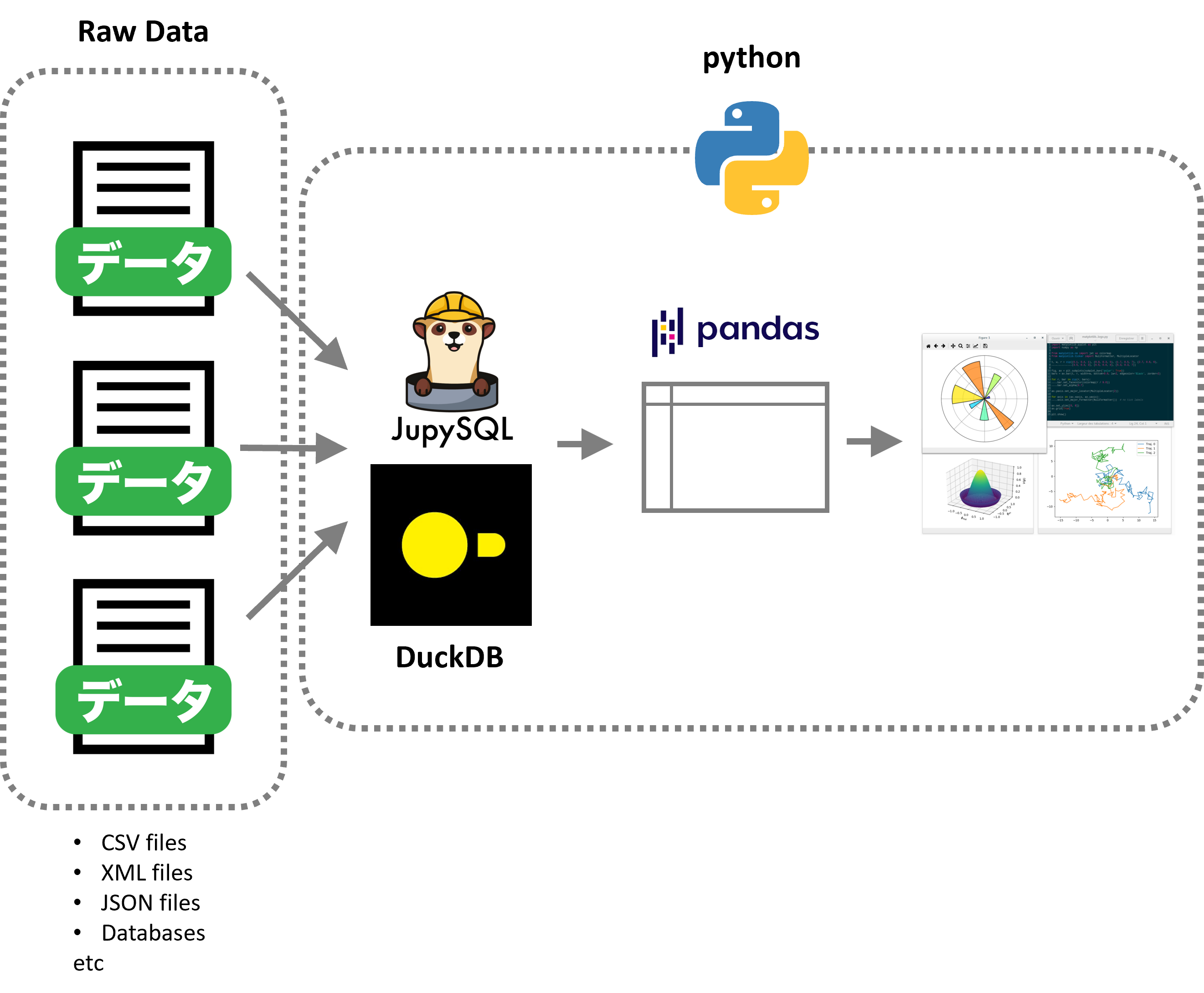
今回は、「Jupyter Notebook上でSQLをらくらく実行するJupySQL×DuckDB」というお話しをします。
DuckDBそのものについては、以下の記事で簡単に紹介していますので、気になる方は一読して頂ければと思います。
Contents [hide]
JupyLabのインストール
取り急ぎ、JupyLabライブラリー(パッケージ)をインストールしましょう。
今回は、DuckDBと統合し利用するので、DuckDBエンジンもインストールします。
以下、condaでインストールするときのコードです。
conda install -c conda-forge jupysql duckdb-engine
以下、pipでインストールするときのコードです。
pip install jupysql duckdb-engine
今回利用するサンプルデータ
DB(データベース)によくあるテーブルっぽいデータを今回利用します。
Kaggleに公開されている「フライト遅延データセット」です。
以下の弊社サイトのURLからもダウンロードできます。
2015 Flight Delays and Cancellations
https://www.salesanalytics.co.jp/1tzu
次の3つのデータテーブルからなります。
- airlines.csv(航空会社マスタテーブル)
- airports.csv(空港マスタテーブル)
- flights.csv(フライトのトランザクションデータテーブル)
このデータセットの中は、先ほど紹介した以下の記事でも見ていますので、気になる方はチラ見してください。
SQLを実行するときの3つのマジックコマンド
次のマジックコマンドを利用し、Notebook上でJupySQLを使っていきます。
- %sql: 1行のSQL命令文の実行
- %%sql:複数行のSQL命令文の実行(セル内がSQL環境になる)
- %sqlplot:グラフ表示
JupySQLの簡単な操作
JupySQLを利用する準備とDuckDBとの統合
先ずは、SQLのエクステンションを読み込みます。
以下、コードです。
# SQL 拡張機能をロード %load_ext sql
次に、「%sql」を使いインメモリ上のDuckDBに接続します。
以下、コードです。
# DuckDB インメモリ データベースを開始 %sql duckdb://
これで、準備は完了です。
DB内のテーブルを確認してみます。
以下、コードです。
# DB内のテーブルを確認 %sql SHOW TABLES
以下、実行結果です。

当然ですが、何もありません。
外部のCSVファイルに対しクエリを実行
外部のCSVファイルに対しSQLのクエリを実行してみます。
airports.csvを5レコード表示させます。
以下、コードです。
# 外部のcsvファイルに対しクエリを実行 %sql SELECT * FROM airports.csv LIMIT 5
以下、実行結果です。
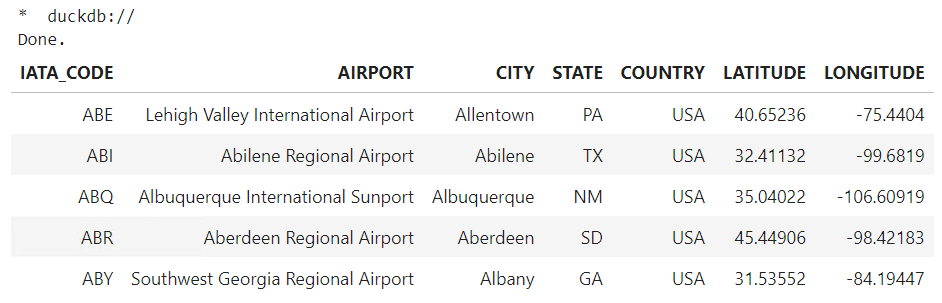
クエリの実行結果は「_」に一時的に格納されています。print文で確認してみます。
以下、コードです。
# クエリの実行結果をprint文で出力 print(_)
以下、実行結果です。
+-----------+-------------------------------------+-------------+-------+---------+----------+------------+ | IATA_CODE | AIRPORT | CITY | STATE | COUNTRY | LATITUDE | LONGITUDE | +-----------+-------------------------------------+-------------+-------+---------+----------+------------+ | ABE | Lehigh Valley International Airport | Allentown | PA | USA | 40.65236 | -75.4404 | | ABI | Abilene Regional Airport | Abilene | TX | USA | 32.41132 | -99.6819 | | ABQ | Albuquerque International Sunport | Albuquerque | NM | USA | 35.04022 | -106.60919 | | ABR | Aberdeen Regional Airport | Aberdeen | SD | USA | 45.44906 | -98.42183 | | ABY | Southwest Georgia Regional Airport | Albany | GA | USA | 31.53552 | -84.19447 | +-----------+-------------------------------------+-------------+-------+---------+----------+------------+
SQLが複雑というか長文になってしまうとき、どうしても複数行になってしまうことがあります。
このようなときは、「%%sql」です。セル内がSQL環境になります。
flights.csvファイルに対し、AIRLINEごとの件数をカウントし、それを降順で表示します。
以下、コードです。
%%sql
SELECT
count(*) as Count,
AIRLINE
FROM flights.csv
GROUP BY AIRLINE
ORDER BY Count DESC;
以下、実行結果です。

「_」に一時的に格納されている結果をprint文で確認してみます。
以下、コードです。
# クエリの実行結果をprint文で出力 print(_)
以下、実行結果です。
+---------+---------+ | Count | AIRLINE | +---------+---------+ | 1261855 | WN | | 875881 | DL | | 725984 | AA | | 588353 | OO | | 571977 | EV | | 515723 | UA | | 294632 | MQ | | 267048 | B6 | | 198715 | US | | 172521 | AS | | 117379 | NK | | 90836 | F9 | | 76272 | HA | | 61903 | VX | +---------+---------+
クエリの保存と実行
SQLのクエリを保存し、後で利用したり、他のテーブルと組み合わせ使ったりすることもあるでしょう。
先ほどのクエリを「flights_count」という名前を保存してみます。
以下、コードです。
%%sql --save flights_count --no-execute
SELECT
count(*) as Count,
AIRLINE
FROM flights.csv
GROUP BY AIRLINE
ORDER BY Count DESC
「%%sql」の後ろに「–save 〇〇」をつけることで「〇〇」という名で保存されます。
さらに、後ろに「–no-execute」を付けることで即時実行を回避しています。「–no-execute」を付けないと、保存されるとともにクエリも実行されます。
では次に、保存したクエリを使い、実行してみます。
以下、コードです。
%%sql --with flights_count SELECT * FROM flights_count;
以下、実行結果です。
クエリの実行結果を格納しDataFrameへ
クエリは実行したあと「_」に一時的に保存されますが、他のクエリを実行すると消え去ります。
実行結果をもう少し長く保持したいこともあります。
「%%sql」の後に「〇〇 <<」を付けることで、「〇〇」に結果が格納されます。
以下、コードです。
%%sql result <<
SELECT
count(*) as Count,
AIRLINE
FROM flights.csv
GROUP BY AIRLINE
ORDER BY Count DESC;
格納したクエリの実行結果を表示してみます。
以下、コードです。
# クエリの実行結果をprint文で出力 print(result)
以下、実行結果です。
+---------+---------+ | Count | AIRLINE | +---------+---------+ | 1261855 | WN | | 875881 | DL | | 725984 | AA | | 588353 | OO | | 571977 | EV | | 515723 | UA | | 294632 | MQ | | 267048 | B6 | | 198715 | US | | 172521 | AS | | 117379 | NK | | 90836 | F9 | | 76272 | HA | | 61903 | VX | +---------+---------+
DataFrameに変換し表示させてみます。
以下、コードです。
# DataFrameに変換し出力 print(result.DataFrame())
以下、実行結果です。
Count AIRLINE 0 1261855 WN 1 875881 DL 2 725984 AA 3 588353 OO 4 571977 EV 5 515723 UA 6 294632 MQ 7 267048 B6 8 198715 US 9 172521 AS 10 117379 NK 11 90836 F9 12 76272 HA 13 61903 VX
クエリの実行結果をCSVファイとして出力
クエリの実行結果をCSVファイルとして外部に出力したいこともあります。
以下、コードです。
%%sql
COPY(
SELECT
count(*) as Count,
AIRLINE
FROM flights.csv
GROUP BY AIRLINE
ORDER BY Count DESC
)
TO 'flights_count.csv' (HEADER, DELIMITER ',');
「flights_count.csv」というファイル名のCSVファイルが作成されたかと思います。
この外部に出力したCSVファイルを、逆に読み込んでみます。
以下、コードです。
%sql SELECT * FROM flights_count.csv
以下、実行結果です。
データテーブルを追加
ここで、DBの中を見てみます。
以下、コードです。
# DB内のテーブルを確認 %sql SHOW TABLES
以下、実行結果です。
空です。
外部データをSQLで操作しただけなので当然と言えば、当然です。
外部のCSVファイルから3つのテーブルを作成します。
以下、コードです。
%%sql CREATE TABLE airports AS SELECT * FROM airports.csv; CREATE TABLE airlines AS SELECT * FROM airlines.csv; CREATE TABLE flights AS SELECT * FROM flights.csv;
DBの中を確認してみます。
以下、コードです。
# DB内のテーブルを確認 %sql SHOW TABLES
以下、実行結果です。

3つのテーブルが存在することが分かります。
さらに、作成したテーブルから別のテーブルを作成してみます。
以下、コードです。
%%sql
CREATE TABLE flights_count AS
SELECT
count(*) as Count,
AIRLINE
FROM flights
GROUP BY AIRLINE
ORDER BY Count DESC;
DBの中を確認してみます。
以下、コードです。
# DB内のテーブルを確認 %sql SHOW TABLES
以下、実行結果です。

テーブルが4つになっていることが分かります。
DuckDBをファイルに残し後から使う
DuckDBをファイルとして保存
インメモリなDBであるDuckDBは、Notebookを終了させたりカーネルをリスタートさせたりすると、当然ですが消えてなくなります。インメモリだからです。
ファイルとして保存し後から使えないだろうかと考える人もいることでしょう。
ファイルとして保存するには、DuckDBを利用するスタート時点である設定をする必要があります。
例えば、「flight.duckdb」というファイル名で残すとします。
以下、コードです。
# # DuckDBをファイルとして保存 # # SQL 拡張機能をロード %load_ext sql # DBをファイルとして残す場合 %sql duckdb:///flight.duckdb
先ほどは、最初にDuckDB インメモリ データベースを開始するとき、「%sql duckdb://」でした。
しかし、今回は「%sql duckdb:///flight.duckdb」としています。要は、「%sql duckdb://」の後ろに「/ファイル名」とファイル名を指定しただけです。
この状態で、先ほどと同じ4つのテーブルを作成します。
以下、コードです。
%%sql
CREATE TABLE airports AS
SELECT *
FROM airports.csv;
CREATE TABLE airlines AS
SELECT *
FROM airlines.csv;
CREATE TABLE flights AS
SELECT *
FROM flights.csv;
CREATE TABLE flights_count AS
SELECT
count(*) as Count,
AIRLINE
FROM flights
GROUP BY AIRLINE
ORDER BY Count DESC;
以下、実行結果です。

先ほどまでと異なり、「* duckdb:///flight.duckdb」が表示されています。
念のため、DB内を見てみます。
以下、コードです。
# DB内のテーブルを確認 %sql SHOW TABLES
以下、実行結果です。

保存したDuckDBファイルへ接続し開始
最後に、保存したDuckDBのDBファイルを読み込んでみます。
開始時に次のようにします。
以下、コードです。
# # 保存したDuckDBファイルへ接続し開始 # # SQL 拡張機能をロード %load_ext sql # DuckDBファイルへ接続 %sql duckdb:///flight.duckdb
DB内を見てみます。
以下、コードです。
# DB内のテーブルを確認 %sql SHOW TABLES
以下、実行結果です。
まとめ
今回は、「Jupyter Notebook上でSQLをらくらく実行するJupySQL×DuckDB」というお話しをしました。
DuckDBをNotebook上でフル活用したいなら、JupySQLがとっても便利です。
興味を持った方は、試してみてください。