
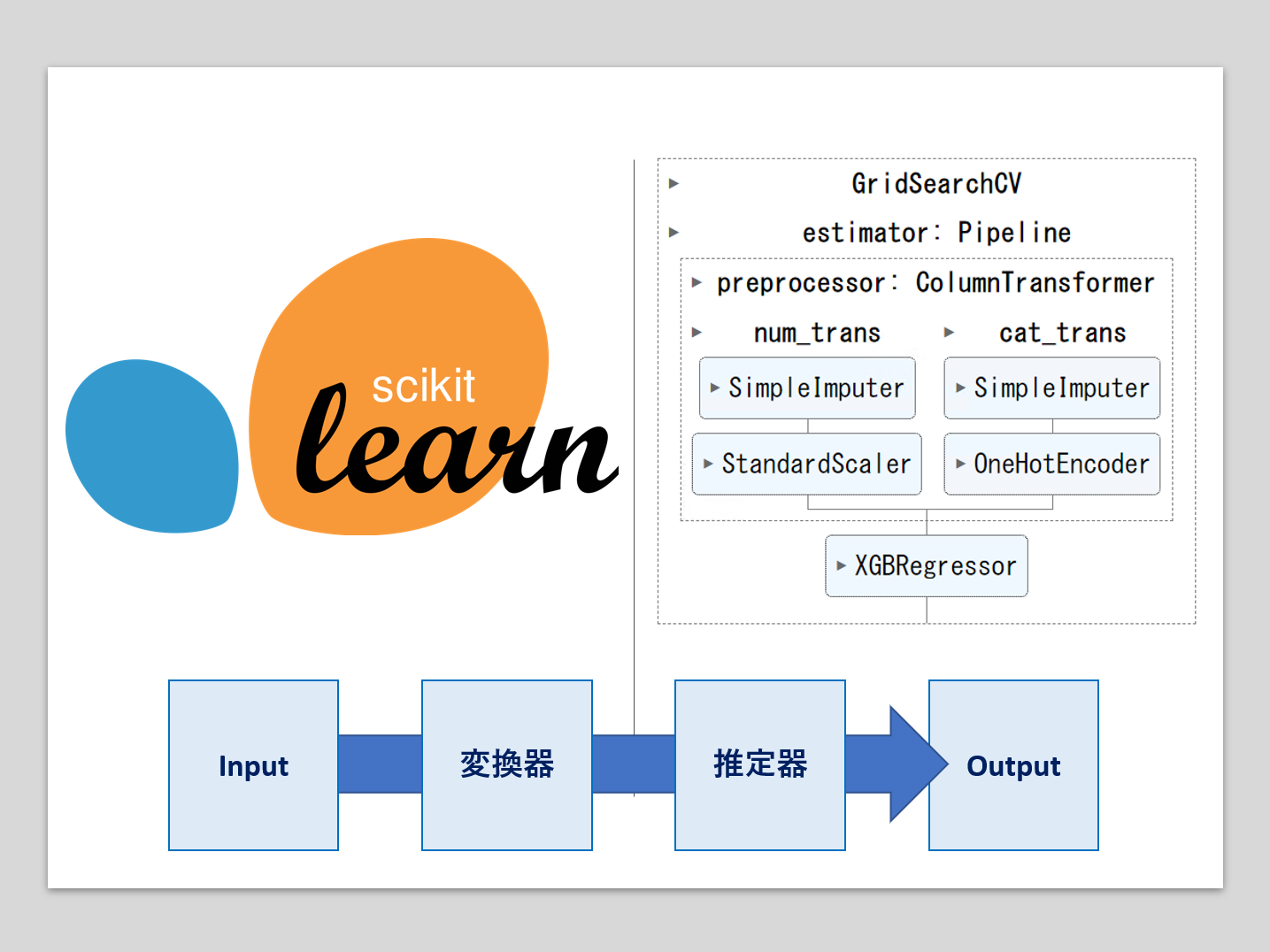
機械学習のパイプラインとは、複数の処理を直列に連結したものです。
最小構成は、1つの変換器と1つの推定器(予測器)を連結したものです。

- 変換器:特徴量X(説明変数)などの欠測値処理や変数変換などの、特徴量変換(Transformor)
- 推定器:線形回帰モデルやXGBoostなどの数理モデルを使い、目的変数yの予測を実施(Estimator)
多くの場合、Inputは特徴量(説明変数)Xで、Outputは目的変数yの予測値です。
前回は、機械学習パイプラインの構成要素である「変換器と推定器」から、シンプルな機械学習パイプラインの構築例を示しました。
登場した変換器は、scikit-learnの中にある既存のものです。
多くは既存の変換器で十分ですが、作りたい機械学習パイプラインによっては、自作の変換器(カスタマイズ変換器)を使いたいこともあります。
今回は、自作の変換器(カスタマイズ変換器)を、自作関数かららくらく作れるFunctionTransformerについて紹介します。
Contents [hide]
簡単な関数を作り変換器にする
必要なモジュールを読み込む
先ず、最低限必要なモジュールを読み込みます。
以下、コードです。
import numpy as np from sklearn.preprocessing import FunctionTransformer
簡単な関数を作る
では、簡単な関数を作り、変換器にしてみます。
先ず、簡単な関数を定義します。
以下、コードです。
def custom_func(X):
return(X*2)
入力したデータを2倍にする関数です。
この関数を使ってみます。
以下、コードです。
X = np.array([0,1,2,3,4]) print(custom_func(X))
以下、実行結果です。
[0 2 4 6 8]
FunctionTransformerで変換器を作る
次に、FunctionTransformerで、先程定義した関数を変換器にします。
以下、コードです。
cft = FunctionTransformer(custom_func)
変換器を使ってみる
FunctionTransformerで作った変換器cftも、次の変換器や推定器で使える標準的なメソッドが使えます。
- fit:学習
- transform:変換
- fit_transform:学習と変換を両方実施
- inverse_transform:逆変換
この変換器にデータを入力し利用してみます。
以下、コードです。
X_trans = cft.transform(X) print(X_trans)
以下、実行結果です。
[0 2 4 6 8]
パラメータ付き変換器
先ず、関数を定義します。argがパラメータです。
以下、コードです。
def custom_func_arg(X, arg):
return(X*arg)
この関数を使ってみます。
以下、コードです。arg=2です。
X = np.array([0,1,2,3,4]) arg = 2 print(custom_func_arg(X,arg))
以下、実行結果です。2倍されています。
[0 2 4 6 8]
以下、コードです。arg=3です。
X = np.array([0,1,2,3,4]) arg = 3 print(custom_func_arg(X,arg))
以下、実行結果です。3倍されています。
[ 0 3 6 9 12]
次に、変換器を作ります。
以下、コードです。
cft = FunctionTransformer(custom_func_arg,kw_args={'arg': 2})
kw_argsにパラメータの値を設定します。arg=2です。
この値は、後で変更することができます。
変換器にデータを入力し、使ってみます。
以下、コードです。
X_trans = cft.transform(X) print(X_trans)
以下、実行結果です。
[0 2 4 6 8]
パラメータargは、set_paramsメソッドで変更できます。
以下、コードです。
cft.set_params(kw_args={'arg': 3})
変換器にデータを入力し、使ってみます。
以下、コードです。
X_trans = cft.transform(X) print(X_trans)
以下、実行結果です。
[ 0 3 6 9 12]
パラメータargは、データ分析者が与えますが、Optunaなどのハイパーパラメータ調整用のライブラリーなどを使い、ある評価指標をもとに探索することができます。
逆変換付き変換器
逆変換を実施するためには、逆変換の関数を定義し設定しておく必要があります。
関数と定義するときに、逆変換の関数もセットで作ります。
以下、コードです。
# カスタム関数
def custom_func_arg(X, arg):
return(X*arg)
# 逆関数
def custom_func_arg_inv(X, arg):
return(X/arg)
次に、変換器を作ります。
以下、コードです。
cft = FunctionTransformer(
custom_func_arg, #カスタム関数
custom_func_arg_inv, #逆関数
kw_args={'arg': 3}, #カスタム関数のパラメータ
inv_kw_args = {'arg': 3} #逆関数のパラメータ
)
変換器にデータを入力し、使ってみます。
以下、コードです。
X_trans = cft.transform(X) print(X_trans)
以下、実行結果です。
[ 0 3 6 9 12]
この実行結果に対し、逆関数で元の数値に戻します。
以下、コードです。
X_trans_inv = cft.inverse_transform(X_trans) print(X_trans_inv)
以下、実行結果です。
[0. 1. 2. 3. 4.]
推定器と連携しパイプラインを学習しよう
利用するモジュールの読み込み
今回利用するモジュールを読み込みます。
以下、コードです。
# 基本的なモジュール import numpy as np import pandas as pd # データ分割用の関数 from sklearn.model_selection import train_test_split # 評価指標 from sklearn.metrics import r2_score # サンプルデータ from sklearn.datasets import fetch_california_housing # パイプライン構築のための道具 from sklearn.pipeline import make_pipeline from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer # 今回、変換器として利用 from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import OneHotEncoder from sklearn.impute import SimpleImputer # 今回、推定器として利用 import xgboost as xgb
データセットの読み込み
次に、今回利用するデータセットを読み込みます。
今回はscikit-learnから提供されているカリフォルニアの住宅価格データセットを使います。
以下、コードです。
# データセットの読み込み california_housing = fetch_california_housing(as_frame=True) # 特徴量(説明変数) X = california_housing.data # 目的変数 y = california_housing.target
目的変数は、カリフォルニアの予測したい区画ごとの住宅価格の中央値です。
特徴量(説明変数)が8個です。
| 項目名 | 詳細 |
| MedInc | 予測したい区画の収入の中央値 |
| HouseAge | 予測したい区画の築年数 |
| AveRoom | 予測したい区画の家の部屋数の平均値 |
| AveBedrms | 予測したい区画の寝室の平均値 |
| Population | 予測したい区画の人口 |
| AveOccup | 予測したい区画の平均入居率 |
| Latitude | 予測したい区画の緯度 |
| Longitude | 予測したい区画の経度 |
目的変数を見てみます。
以下、コードです。
print(y)
以下、実行結果です。
0 4.526
1 3.585
2 3.521
3 3.413
4 3.422
...
20635 0.781
20636 0.771
20637 0.923
20638 0.847
20639 0.894
Name: MedHouseVal, Length: 20640, dtype: float64
特徴量(説明変数)を見てみます。
以下、コードです。
print(X)
以下、実行結果です。
MedInc HouseAge AveRooms AveBedrms Population AveOccup Latitude \
0 8.3252 41.0 6.984127 1.023810 322.0 2.555556 37.88
1 8.3014 21.0 6.238137 0.971880 2401.0 2.109842 37.86
2 7.2574 52.0 8.288136 1.073446 496.0 2.802260 37.85
3 5.6431 52.0 5.817352 1.073059 558.0 2.547945 37.85
4 3.8462 52.0 6.281853 1.081081 565.0 2.181467 37.85
... ... ... ... ... ... ... ...
20635 1.5603 25.0 5.045455 1.133333 845.0 2.560606 39.48
20636 2.5568 18.0 6.114035 1.315789 356.0 3.122807 39.49
20637 1.7000 17.0 5.205543 1.120092 1007.0 2.325635 39.43
20638 1.8672 18.0 5.329513 1.171920 741.0 2.123209 39.43
20639 2.3886 16.0 5.254717 1.162264 1387.0 2.616981 39.37
Longitude
0 -122.23
1 -122.22
2 -122.24
3 -122.25
4 -122.25
... ...
20635 -121.09
20636 -121.21
20637 -121.22
20638 -121.32
20639 -121.24
[20640 rows x 8 columns]
学習データとテストデータに分割します。
以下、コードです。
# 学習データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.3,
random_state=123
)
学習データでパイプラインを学習し、学習済みのパイプラインをテストデータで検証します。
評価指標は、決定係数R2です。0から1の値をとり、1に近いほど良いとされています。
特徴量(説明変数)を変換対象とそれ以外に分けます
今回は、緯度・経度以外の変数に対し、
そのため、対数変換の対象となる特徴量(説明変数)と、そうでない特徴量(説明変数)に分けます。
以下、コードです。
feature1 = X.columns.values[:-2] #後ろから2番目までを除外 feature2 = X.columns.values[-2:] #後ろから2番目まで('Latitude', 'Longitude')
幸いにも、緯度・経度が後ろ2つの変数(列)のため、「後ろ2つより前」と「後ろ2つ」という指定の仕方で分けています。
実際に、列名が取得できているか確認してみます。
先ずは、対数変換の対象となる特徴量(説明変数)です。
以下、コードです。
print(feature1)
以下、実行結果です。
['MedInc' 'HouseAge' 'AveRooms' 'AveBedrms' 'Population' 'AveOccup']
次に、対数変換の対象とならない特徴量(説明変数)です。
以下、コードです。
print(feature2)
以下、実行結果です。
['Latitude' 'Longitude']
対数変換の対象となるかどうかで、変換器の使い方が異なります。
前回登場したColumnTransformerで、特徴量(説明変数)ごとに変換器を変えることができますので、今回も使います。
パイプラインの定義
関数を定義し、変換器を作ります。
以下、コードです。
# カスタム関数
def custom_func(X):
return(np.log1p(X))
# カスタム変換器
cft = FunctionTransformer(custom_func)
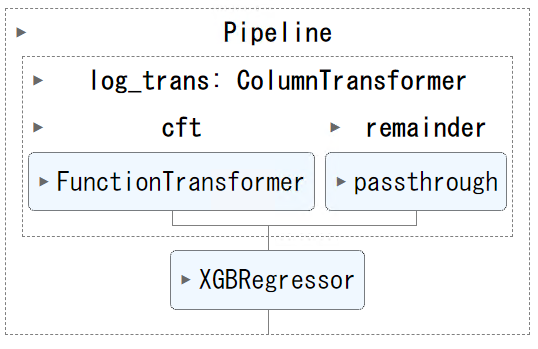
ColumnTransformerで、対数変換を施す特徴量(説明変数)と施さない特徴量(説明変数)を考慮した変換器を構築します。
以下、コードです。
# 変換器パイプラインの定義
log_trans = ColumnTransformer(
transformers=[("cft", cft, feature1)],
remainder = 'passthrough',
)
これは、対数変換を施す特徴量(説明変数)であるfeature1に対し対数変換を施し、それ以外の特徴量(説明変数)であるfeature2に対しては何もしない、という変換器パイプラインです。
この変換器を推定器と繋げパイプラインを構築します。今回は、推定器にXGBoostを使います。
以下、コードです。
# パイプラインの定義
num_pipeline = Pipeline(
steps=[
("log_trans", log_trans),
("regressor", xgb.XGBRegressor()),
]
)
学習とテスト
パイプラインを学習します。
以下、コードです。
# パイプラインの学習 num_pipeline.fit(X_train, y_train)
以下、実行結果です。
テストデータを使い検証してみます。
以下、コードです。
# 目的変数yの予測 pred_y = num_pipeline.predict(X_test) # R2(決定係数) r2_score(y_test, pred_y)
以下、実行結果です。
0.8364427822308688
今回のまとめ
今回は、自作の変換器(カスタマイズ変換器)を、自作関数かららくらく作れるFunctionTransformerについて紹介しました。
FunctionTransformerは非常に便利なものですが、もうちょっと複雑な処理をさせたい場合があります。
次回は、一から変換器などを作成する方法について説明します。
scikit-learnの機械学習パイプライン入門(その3:カスタム変換器 – Custom Transformer -)