
分析で利用するテーブルデータが少ないことがあります。
もう少し増やせないだろうか、と夢見ることも少なくないでしょう。
ここ最近、色々な生成AIが登場してきました。
そこで使われている技術の1つにGAN(敵対的生成ネットワーク)というものがあります。
GANそのものは2014年ごろに登場したもので、あらかじめ準備されたデータをもとに、擬似的なデータを生成することができます。
GANの技術を利用した画像生成AIが目立ちますが、テーブルデータを生成するGANもあります。
CTGAN(Conditional General Adversarial Networks)です。
今回は、Pythonを使いテーブルデータ生成AI CTGANで、簡単な例で使い方を説明します。
CTGANそのものを知りたい方は、以下を参考にしてください。
Contents [hide]
パッケージのインストール
ctgan
CTGAN をインストールします。
インストールしていない場合には、インストールしていただければと思います。
condaでインストールするときは、以下です。
conda install -c pytorch -c conda-forge ctgan
pipでインストールするときは、以下です。
pip install ctgan
sdv
この CTGAN を含めたデータ生成ライブラリーがあります。SDV です。
SDVを使うと、CTGANだけでなく他のテーブルデータ生成アルゴリズムを利用できるだけでなく、テーブルデータ生成を行う上での諸処理や補助機能が使え便利です。
SDVも合わせてインストールしておくことをお勧めします。
condaでインストールするときは、以下です。
conda install -c pytorch -c conda-forge sdv
pipでインストールするときは、以下です。
pip install sdv
ただ、CTGANとSDVで、若干使い方が異なるため、両方説明します。CTGANの方が使い方は簡単で、SDVの方が色々な設定ができます。
ちなみに、開発元はどちらも一緒です。
必要なモジュールとデータセットの読み込み
先ず、必要なモジュールを読み込みます。
以下、コードです。
# 基本モジュール
import pandas as pd
import numpy as np
# CTGAN
from ctgan import CTGAN
# SDV
from sdv.single_table import CTGANSynthesizer
from sdv.metadata import SingleTableMetadata
# 診断用
from sdv.evaluation.single_table import run_diagnostic
from sdv.evaluation.single_table import evaluate_quality
from sdv.evaluation.single_table import get_column_plot
# サンプルデータ取得用(sklearn.datasets)
from sklearn.datasets import fetch_openml
import warnings
warnings.simplefilter('ignore')
サンプルデータは、みんな大好きアヤメ(iris)のデータセットになります。

- Sepal Length: がく片の長さ
- Sepal Width: がく片の幅
- Petal Length: 花びらの長さ
- Petal Width: 花びらの幅
- Species: アヤメの種類(セトサ種・バージニカ種・バージカラー種)
データセットを読み込みます。
以下、コードです。
# データセットの読み込み dataset = fetch_openml(data_id=61, parser='auto') real_data = dataset['frame'] real_data.head() #確認
以下、実行結果です。
どのようなデータなのか見てみます。
以下、コードです。
real_data.info()
以下、実行結果です。
<class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepallength 150 non-null float64 1 sepalwidth 150 non-null float64 2 petallength 150 non-null float64 3 petalwidth 150 non-null float64 4 class 150 non-null category dtypes: category(1), float64(4) memory usage: 5.1 KB
「class」列は、category型の質的変数です。
現段階(2023年6月19日現在)では、質的変数はobject型でないと処理できないため、category型の質的変数をobject型の質的変数へ変換します。
以下、コードです。
# カテゴリー型をオブジェクト型に変換
category_columns = real_data.select_dtypes(include=['category']).columns
real_data[category_columns] = real_data[category_columns].astype('object')
念のため、確認します。
以下、コードです。
real_data.info()
以下、実行結果です。
<class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepallength 150 non-null float64 1 sepalwidth 150 non-null float64 2 petallength 150 non-null float64 3 petalwidth 150 non-null float64 4 class 150 non-null object dtypes: float64(4), object(1) memory usage: 6.0+ KB
CTGANでデータ生成
テーブルデータ生成AIを構築(学習)
元となるデータセットを読み込み、CTGANによるテーブルデータ生成AIを構築(学習)します。
以下、コードです。
# インスタンス生成 ctgan = CTGAN(epochs=10) # 学習 ctgan.fit(real_data, real_data.columns)
ちょっと時間がかかるかもしれませんが、これで学習は終了です。
テーブルデータを生成
この学習済みのテーブルデータ生成モデルを使い、サンプルデータを1,000レコード生成します。
以下、コードです。
# データ生成 synthetic_data = ctgan.sample(1000)
どのようなデータが生成されたのか、一部を確認してみます。
以下、コードです。
synthetic_data.head()
以下、実行結果です。

非常に簡単にデータを生成することが分かります。
データ生成モデルの保存と読み込み
学習し得られたデータ生成モデルを保存することができます。
以下、コードです。
# モデルを保存
ctgan.save('ctgan.pkl')
利用するときは、保存したファイルを呼び出して使います。
以下、コードです。
# モデルの読み込み
loaded = CTGAN.load('ctgan.pkl')
SDVのCTGANでデータ生成
メタデータを準備する
SDVのCTGANでデータ生成します。
こちらは、学習で利用するメタデータ(metadata)というものをあらかじめ作る必要があります。
メタデータ(metadata)とは、学習データの変数などの情報が記載されたもので、SDV用の形式が指定されています。
主に、変数(列)名とその型を指定しています。
例えば、型には次のようなものがあります。
- numerical(量)
- datetime(日時)
- categorical(質)
- boolean(True or False)
- id(キーとして利用する場合に指定)
メタデータ(metadata)を作ることを面倒に思うかもしれません。
安心して下さい。
学習データとして利用するデータフレームから、メタデータ(metadata)を自動で生成することができます。
以下、コードです。
# データフレームからメタデータを自動抽出 metadata = SingleTableMetadata() metadata.detect_from_dataframe(real_data)
念のため、確認します。
以下、コードです。
metadata
以下、実行結果です。
{
"columns": {
"sepallength": {
"sdtype": "numerical"
},
"sepalwidth": {
"sdtype": "numerical"
},
"petallength": {
"sdtype": "numerical"
},
"petalwidth": {
"sdtype": "numerical"
},
"class": {
"sdtype": "categorical"
}
},
"METADATA_SPEC_VERSION": "SINGLE_TABLE_V1"
}
おそらく問題はないと思いますが、修正した方がいい場合には、update_columnメソッドで修正します。
以下、構文です。
metadata.update_column(column_name=修正する変数名,sdtype=修正後の型)
今回は問題ないので、そのまま利用します。
テーブルデータ生成AIを構築(学習)
元となるデータセットを読み込み、SDVのCTGANによるテーブルデータ生成AIを構築(学習)します。
以下、コードです。
# インスタンス生成 ctgan = CTGANSynthesizer(metadata,epochs=10) # 学習 ctgan.fit(real_data)
テーブルデータを生成
この学習済みのテーブルデータ生成モデルを使い、サンプルデータを1,000レコード生成します。
以下、コードです。
# インスタンス生成 ctgan = CTGANSynthesizer(metadata,epochs=10) # 学習 ctgan.fit(real_data) # データ生成 synthetic_data = ctgan.sample(1000) # 生成したデータを確認 synthetic_data.head()
以下、実行結果です。
生成したデータの診断
生成したデータを診断結果します。
生成したデータが、元データの純粋なコピーであるか、元データの範囲に忠実であるかどうかなどを確認します。
以下、コードです。
diagnostic_report = run_diagnostic(
real_data=real_data,
synthetic_data=synthetic_data,
metadata=metadata)
以下、実行結果です。問題ないようです。
DiagnosticResults: SUCCESS: ✓ The synthetic data covers over 90% of the numerical ranges present in the real data ✓ The synthetic data covers over 90% of the categories present in the real data ✓ Over 90% of the synthetic rows are not copies of the real data ✓ The synthetic data follows over 90% of the min/max boundaries set by the real data
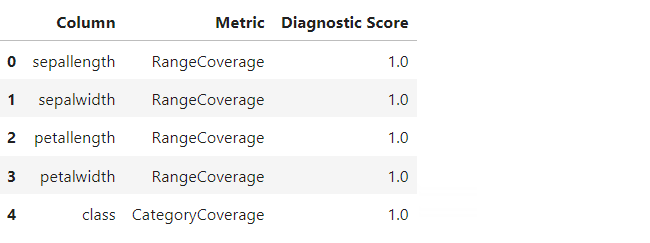
変数ごとに見てみます。Scoreは0以上1以下の値で、1に近いほど良いです。
以下、コードです。
diagnostic_report.get_details(property_name='Coverage')
以下、実行結果です。
次に、生成したデータが、元データをどの程度捉えているかを評価します。
以下、コードです。
quality_report = evaluate_quality(
real_data=real_data,
synthetic_data=synthetic_data,
metadata=metadata)
以下、実行結果です。Scoreは0%以上100%以下の値で、100%に近いほど良いです。
Overall Quality Score: 73.38% Properties: Column Shapes: 83.79% Column Pair Trends: 62.96%
変数ごとに見てみます。
以下、コードです。
quality_report.get_details(property_name='Column Shapes')
以下、実行結果です。Scoreは0以上1以下の値で、1に近いほど良いです。
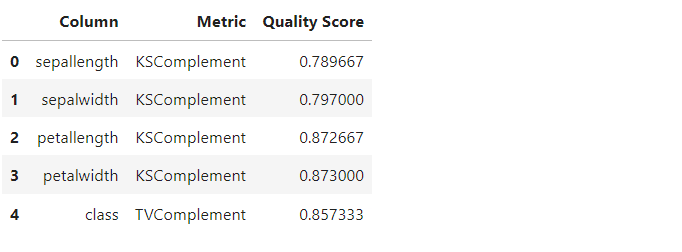
- KS Complement=1-Kolmogorov-Smirnov statistic
- TV Complement=1-Total Variation Distance
元データ(real_data)と生成したデータ(synthetic_data)を視覚的に比較する関数があります。
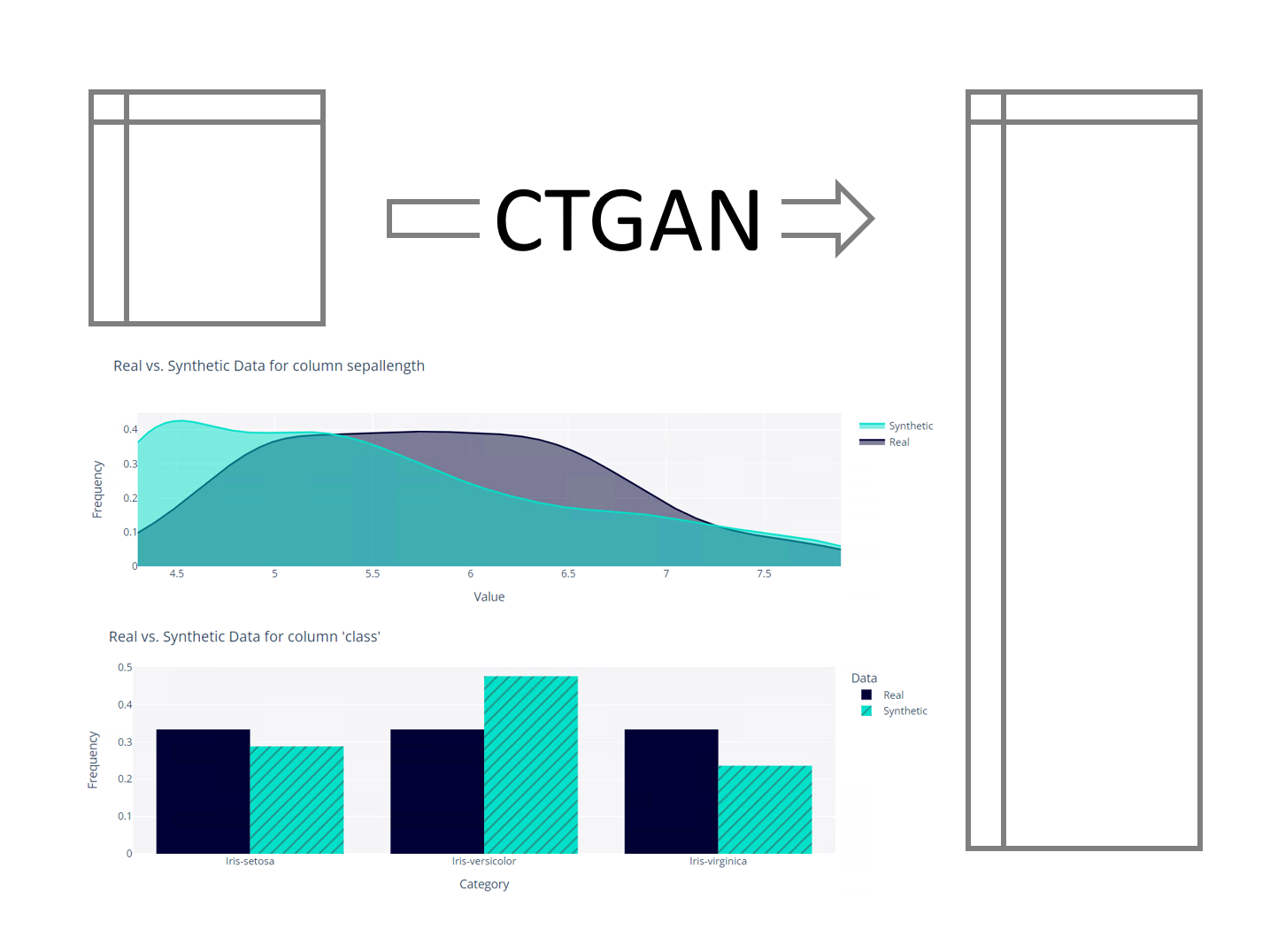
量的変数「sepallength」で見てみます。
以下、コードです。
fig = get_column_plot(
real_data=real_data,
synthetic_data=synthetic_data,
column_name='sepallength',
metadata=metadata
)
fig.show()
以下、実行結果です。
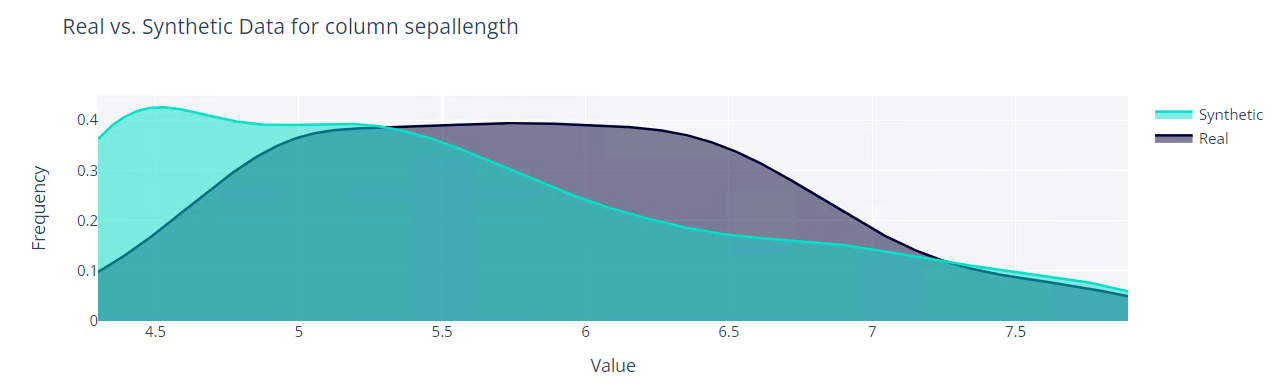
質的変数「class」で見てみます。
以下、コードです。
fig = get_column_plot(
real_data=real_data,
synthetic_data=synthetic_data,
column_name='class',
metadata=metadata
)
fig.show()
以下、実行結果です。
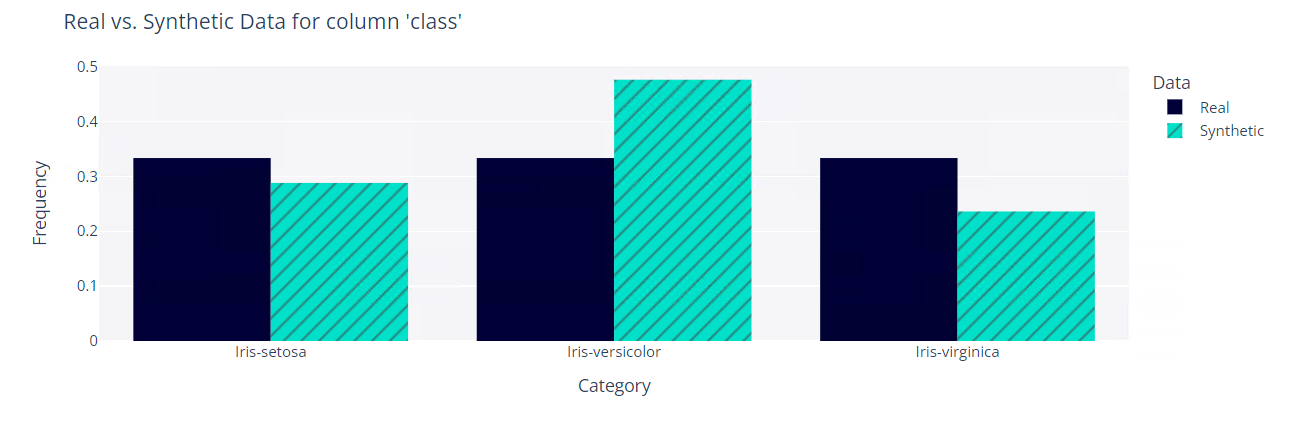
データ生成モデルの保存と読み込み
学習し得られたデータ生成モデルを保存することができます。
以下、コードです。
# モデルを保存
ctgan.save('ctgan.pkl')
利用するときは、保存したファイルを呼び出して使います。
以下、コードです。
# モデルの読み込み
loaded = CTGANSynthesizer.load('ctgan.pkl')
まとめ
今回は、Pythonを使いテーブルデータ生成AI CTGANで、簡単な例で使い方を説明しました。
SDVのCTGANの方が、メタデータ(metadata)が必要になるなど、やや面倒に感じたかもしれませんが、実はこちらの方が柔軟性があります。
さらに、SDVにはCTGAN以外のテーブルデータ生成アルゴリズムや、テーブルデータ生成を行う上での諸処理や補助機能が使え便利です。
SDVは、古典的な統計手法(GaussianCopula)によるテーブルデータ生成から、今回紹介した深層学習手法(CTGAN)、さらには単一テーブルだけでなく複数連結テーブルやシーケンシャルデータを生成することができます。
次回、個人ID付きなどの主キーのあるデータセットの生成の仕方について説明します。